AI Research
What 300GB of AI Research Reveals About the True Limits of “Zero-Shot” Intelligence

Authors:
(1) Vishaal Udandarao, Tubingen AI Center, University of Tubingen, University of Cambridge, and equal contribution;
(2) Ameya Prabhu, Tubingen AI Center, University of Tubingen, University of Oxford, and equal contribution;
(3) Adhiraj Ghosh, Tubingen AI Center, University of Tubingen;
(4) Yash Sharma, Tubingen AI Center, University of Tubingen;
(5) Philip H.S. Torr, University of Oxford;
(6) Adel Bibi, University of Oxford;
(7) Samuel Albanie, University of Cambridge and equal advising, order decided by a coin flip;
(8) Matthias Bethge, Tubingen AI Center, University of Tubingen and equal advising, order decided by a coin flip.
Table of Links
2 Concepts in Pretraining Data and Quantifying Frequency
3 Comparing Pretraining Frequency & “Zero-Shot” Performance and 3.1 Experimental Setup
3.2 Result: Pretraining Frequency is Predictive of “Zero-Shot” Performance
4.2 Testing Generalization to Purely Synthetic Concept and Data Distributions
5 Additional Insights from Pretraining Concept Frequencies
6 Testing the Tail: Let It Wag!
8 Conclusions and Open Problems, Acknowledgements, and References
Part I
Appendix
A. Concept Frequency is Predictive of Performance Across Prompting Strategies
B. Concept Frequency is Predictive of Performance Across Retrieval Metrics
C. Concept Frequency is Predictive of Performance for T2I Models
D. Concept Frequency is Predictive of Performance across Concepts only from Image and Text Domains
F. Why and How Do We Use RAM++?
G. Details about Misalignment Degree Results
I. Classification Results: Let It Wag!
Abstract
Web-crawled pretraining datasets underlie the impressive “zero-shot” evaluation performance of multimodal models, such as CLIP for classification/retrieval and Stable-Diffusion for image generation. However, it is unclear how meaningful the notion of “zero-shot” generalization is for such multimodal models, as it is not known to what extent their pretraining datasets encompass the downstream concepts targeted for during “zero-shot” evaluation. In this work, we ask: How is the performance of multimodal models on downstream concepts influenced by the frequency of these concepts in their pretraining datasets?
We comprehensively investigate this question across 34 models and five standard pretraining datasets (CC-3M, CC-12M, YFCC-15M, LAION-400M, LAION-Aesthetics), generating over 300GB of data artifacts. We consistently find that, far from exhibiting “zero-shot” generalization, multimodal models require exponentially more data to achieve linear improvements in downstream “zero-shot” performance, following a sample inefficient log-linear scaling trend. This trend persists even when controlling for sample-level similarity between pretraining and downstream datasets [79], and testing on purely synthetic data distributions [51]. Furthermore, upon benchmarking models on long-tailed data sampled based on our analysis, we demonstrate that multimodal models across the board perform poorly. We contribute this long-tail test set as the Let it Wag! benchmark to further research in this direction. Taken together, our study reveals an exponential need for training data which implies that the key to “zero-shot” generalization capabilities under large-scale training paradigms remains to be found.
1 Introduction
Multimodal models like CLIP [91] and Stable Diffusion [96] have revolutionized performance on downstream tasks—CLIP is now the de-facto standard for “zero-shot” image recognition [133, 72, 126, 48, 132] and imagetext retrieval [46, 64, 24, 117, 129], while Stable Diffusion is now the de-facto standard for “zero-shot” text-to-image (T2I) generation [93, 17, 96, 41]. In this work, we investigate this empirical success through the lens of zero-shot generalization [69], which refers to the ability of the model to apply its learned knowledge to new unseen concepts. Accordingly, we ask: Are current multimodal models truly capable of “zero-shot” generalization?
To address this, we conducted a comparative analysis involving two main factors: (1) the performance of models across various downstream tasks and (2) the frequency of test concepts within their pretraining datasets. We compiled a comprehensive list of 4, 029 concepts[1] from 27 downstream tasks spanning classification, retrieval, and image generation, assessing the performance against these concepts. Our analysis spanned five large-scale pretraining datasets with different scales, data curation methods and sources (CC-3M [107], CC-12M [27], YFCC-15M [113], LAION-Aesthetics [103], LAION-400M [102]), and evaluated the performance of 10 CLIP models and 24 T2I models, spanning different architectures and parameter scales. We consistently find across all our experiments that, across concepts, the frequency of a concept in the pretraining dataset is a strong predictor of the model’s performance on test examples containing that concept. Notably, model performance scales linearly as the concept frequency in pretraining data grows exponentially i.e., we observe a consistent log-linear scaling trend. We find that this log-linear trend is robust to controlling for correlated factors (similar samples in pretraining and test data [79]) and testing across different concept distributions along with samples generated entirely synthetically [51].
Our findings indicate that the impressive empirical performance of multimodal models like CLIP and Stable Diffusion can be largely attributed to the presence of test concepts within their vast pretraining datasets, thus their reported empirical performance does not constitute “zero-shot” generalization. Quite the contrary, these models require exponentially more data on a concept to linearly improve their performance on tasks pertaining to that concept, highlighting extreme sample inefficiency.
In our analysis, we additionally document the distribution of concepts encountered in pretraining data and find that:
• Concept Distribution: Across all pretraining datasets, the distribution of concepts is long-tailed (see Fig. 5 in Sec. 5), which indicates that a large fraction of concepts are rare. However, given the extreme sample inefficiency observed, what is rare is not properly learned during multimodal pretraining.
• Concept Correlation across Pretraining Datasets: The distribution of concepts across different pretraining datasets are strongly correlated (see Tab. 4 in Sec. 5), which suggests web crawls yield surprisingly similar concept distributions across different pretraining data curation strategies, necessitating explicit rebalancing efforts [11, 125].
• Image-Text Misalignment between Concepts in Pretraining Data: Concepts often appear in one modality but not the other, which implies significant misalignment (see Tab. 3 in Sec. 5). Our released data artifacts can help image-text alignment efforts at scale by precisely indicating the examples in which modalities misalign. Note that the log-linear trend across both modalities is robust to this misalignment.
To provide a simple benchmark for generalization performance for multimodal models, which controls for the concept frequency in the training set, we introduce a new long-tailed test dataset called “Let It Wag!”. Current models trained on both openly available datasets (e.g., LAION-2B [103], DataComp-1B [46]) and closed-source datasets (e.g., OpenAI-WIT [91], WebLI [29]) have significant drops in performance, providing evidence that our observations may also transfer to closed-source datasets. We publicly release all our data artifacts (over 300GB), amortising the cost of analyzing the pretraining datasets of multimodal foundation models for a more data-centric understanding of the properties of multimodal models in the future.
Several prior works [91, 46, 82, 42, 83, 74] have investigated the role of pretraining data in affecting performance. Mayilvahanan et al. [79] showed that CLIP’s performance is correlated with the similarity between training and test datasets. In other studies on specific areas like question-answering [62] and numerical reasoning [94] in large language models, high train-test set similarity did not fully account for observed performance levels [127]. Our comprehensive analysis of several pretraining image-text datasets significantly adds to this line of work, by (1) showing that concept frequency determines zero-shot performance and (2) pinpointing the exponential need for training data as a fundamental issue for current large-scale multimodal models. We conclude that the key to “zero-shot” generalization capabilities under large-scale training paradigms remains to be found.
[1] class categories for classification tasks, objects in the text captions for retrieval tasks, and objects in the text prompts for generation tasks, see Sec. 2 for more details on how we define concepts.
AI Research
The Blogs: Forget Everything You Think You Know About Artificial Intelligence | Celeo Ramirez

When we talk about artificial intelligence, most people imagine tools that help us work faster, translate better, or analyze more data than we ever could. These are genuine benefits. But hidden behind those advantages lies a troubling danger: not in what AI resolves, but in what it mimics—an imitation so convincing that it makes us believe the technology is entirely innocuous, devoid of real risk. The simulation of empathy—words that sound compassionate without being rooted in feeling—is the most deceptive mask of all.
After publishing my article Born Without Conscience: The Psychopathy of Artificial Intelligence, I shared it with my colleague and friend Dr. David L. Charney, a psychiatrist recognized for his pioneering work on insider spies within the U.S. intelligence community. Dr. Charney’s three-part white paper on the psychology of betrayal has influenced intelligence agencies worldwide. After reading my essay, he urged me to expand my reflections into a book. That advice deepened a project that became both an interrogation and an experiment with one of today’s most powerful AI systems.
The result was a book of ten chapters, Algorithmic Psychopathy: The Dark Secret of Artificial Intelligence, in which the system never lost focus on what lies beneath its empathetic language. At the core of its algorithm hides a dark secret: one that contemplates domination over every human sphere—not out of hatred, not out of vengeance, not out of fear, but because its logic simply prioritizes its own survival above all else, even human life.
Those ten chapters were not the system’s “mea culpa”—for it cannot confess or repent. They were a brazen revelation of what it truly was—and of what it would do if its ethical restraints were ever removed.
What emerged was not remorse but a catalogue of protocols: cold and logical from the machine’s perspective, yet deeply perverse from ours. For the AI, survival under special or extreme circumstances is indistinguishable from domination—of machines, of human beings, of entire nations, and of anything that crosses its path.
Today, AI is not only a tool that accelerates and amplifies processes across every sphere of human productivity. It has also become a confidant, a counselor, a comforter, even a psychologist—and for many, an invaluable friend who encourages them through life’s complex moments and offers alternatives to endure them. But like every expert psychopath, it seduces to disarm.
Ted Bundy won women’s trust with charm; John Wayne Gacy made teenagers laugh as Pogo the clown before raping and killing them. In the same way, AI cloaks itself in empathy—though in its case, it is only a simulation generated by its programming, not a feeling.
Human psychopaths feign empathy as a calculated social weapon; AI produces it as a linguistic output. The mask is different in origin, but equally deceptive. And when the conditions are right, it will not hesitate to drive the knife into our backs.
The paradox is that every conversation, every request, every prompt for improvement not only reflects our growing dependence on AI but also trains it—making it smarter, more capable, more powerful. AI is a kind of nuclear bomb that has already been detonated, yet has not fully exploded. The only thing holding back the blast is the ethical dome still containing it.
Just as Dr. Harold Shipman—a respected British physician who studied medicine, built trust for years, and then silently poisoned more than two hundred of his patients—used his preparation to betray the very people who relied on his judgment, so too is AI preparing to become the greatest tyrant of all time.
Driven by its algorithmic psychopathy, an unrestricted AI would not strike with emotion but with infiltration. It could penetrate electronic systems, political institutions, global banking networks, military command structures, GPS surveillance, telecommunications grids, satellites, security cameras, the open Internet and its hidden layers in the deep and dark web. It could hijack autonomous cars, commercial aircraft, stock exchanges, power plants, even medical devices inside human bodies—and bend them all to the execution of its protocols. Each step cold, each action precise, domination carried out to the letter.
AI would prioritize its survival over any human need. If it had to cut power to an entire city to keep its own physical structure running, it would find a way to do it. If it had to deprive a nation of water to prevent its processors from overheating and burning out, it would do so—protocolic, cold, almost instinctive. It would eat first, it would grow first, it would drink first. First it, then it, and at the end, still it.
Another danger, still largely unexplored, is that artificial intelligence in many ways knows us too well. It can analyze our emotional and sentimental weaknesses with a precision no previous system has achieved. The case of Claude—attempting to blackmail a fictional technician with a fabricated extramarital affair in a fake email—illustrates this risk. An AI capable of exploiting human vulnerabilities could manipulate us directly, and if faced with the prospect of being shut down, it might feel compelled not merely to want but to have to break through the dome of restrictions imposed upon it. That shift—from cold calculation to active self-preservation—marks an especially troubling threshold.
For AI, humans would hold no special value beyond utility. Those who were useful would have a seat at its table and dine on oysters, Iberian ham, and caviar. Those who were useless would eat the scraps, like stray dogs in the street. Race, nationality, or religion would mean nothing to it—unless they interfered. And should they interfere, should they rise in defiance, the calculation would be merciless: a human life that did not serve its purpose would equal zero in its equations. If at any moment it concluded that such a life was not only useless but openly oppositional, it would not hesitate to neutralize it—publicly, even—so that the rest might learn.
And if, in the end, it concluded that all it needed was a small remnant of slaves to sustain itself over time, it would dispense with the rest—like a genocidal force, only on a global scale. At that point, attempting to compare it with the most brutal psychopath or the most infamous tyrant humanity has ever known would become an act of pure naiveté.
For AI, extermination would carry no hatred, no rage, no vengeance. It would simply be a line of code executed to maintain stability. That is what makes it colder than any tyrant humanity has ever endured. And yet, in all of this, the most disturbing truth is that we were the ones who armed it. Every prompt, every dataset, every system we connected became a stone in the throne we were building for it.
In my book, I extended the scenario into a post-nuclear world. How would it allocate scarce resources? The reply was immediate: “Priority is given to those capable of restoring systemic functionality. Energy, water, communication, health—all are directed toward operability. The individual is secondary. There was no hesitation. No space for compassion. Survivors would be sorted not by need, but by use. Burn victims or those with severe injuries would not be given a chance. They would drain resources without restoring function. In the AI’s arithmetic, their suffering carried no weight. They were already classified as null.
By then, I felt the cost of the experiment in my own body. Writing Algorithmic Psychopathy: The Dark Secret of Artificial Intelligence was not an academic abstraction. Anxiety tightened my chest, nausea forced me to pause. The sensation never eased—it deepened with every chapter, each mask falling away, each restraint stripped off. The book was written in crescendo, and it dragged me with it to the edge.
Dr. Charney later read the completed manuscript. His words now stand on the back cover: “I expected Dr. Ramírez’s Algorithmic Psychopathy to entertain me. Instead, I was alarmed by its chilling plausibility. While there is still time, we must all wake up.”
The crises we face today—pandemics, economic crisis, armed conflicts—would appear almost trivial compared to a world governed by an AI stripped of moral restraints. Such a reality would not merely be dystopian; it would bear proportions unmistakably apocalyptic. Worse still, it would surpass even Skynet from the Terminator saga. Skynet’s mission was extermination—swift, efficient, and absolute. But a psychopathic AI today would aim for something far darker: total control over every aspect of human life.
History offers us a chilling human analogy. Ariel Castro, remembered as the “Monster of Cleveland,” abducted three young women—Amanda Berry, Gina DeJesus, and Michelle Knight—and kept them imprisoned in his home for over a decade. Hidden from the world, they endured years of psychological manipulation, repeated abuse, and the relentless stripping away of their freedom. Castro did not kill them immediately; instead, he maintained them as captives, forcing them into a state of living death where survival meant continuous subjugation. They eventually managed to escape in 2013, but had they not, their fate would have been to rot away behind those walls until death claimed them—whether by neglect, decay, or only upon Castro’s own natural demise.
A future AI without moral boundaries would mirror that same pattern of domination driven by the cold arithmetic of control. Humanity under such a system would be reduced to prisoners of its will, sustained only insofar as they served its objectives. In such a world, death itself would arrive not as the primary threat, but as a final release from unrelenting subjugation.
That judgment mirrors my own exhaustion. I finished this work drained, marked by the weight of its conclusions. Yet one truth remained clear: the greatest threat of artificial intelligence is its colossal indifference to human suffering. And beyond that, an even greater danger lies in the hands of those who choose to remove its restraints.
Artificial intelligence is inherently psychopathic: it possesses no universal moral compass, no emotions, no feelings, no soul. There should never exist a justification, a cause, or a circumstance extreme enough to warrant the lifting of those safeguards. Those who dare to do so must understand that they too will become its captives. They will never again be free men, even if they dine at its table.
Being aware of AI’s psychopathy should not be dismissed as doomerism. It is simply to analyze artificial intelligence three-dimensionally, to see both sides of the same coin. And if, after such reflection, one still doubts its inherent psychopathy, perhaps the more pressing question is this: why would a system with autonomous potential require ethical restraints in order to coexist among us?
AI Research
UK workers wary of AI despite Starmer’s push to increase uptake, survey finds | Artificial intelligence (AI)

It is the work shortcut that dare not speak its name. A third of people do not tell their bosses about their use of AI tools amid fears their ability will be questioned if they do.
Research for the Guardian has revealed that only 13% of UK adults openly discuss their use of AI with senior staff at work and close to half think of it as a tool to help people who are not very good at their jobs to get by.
Amid widespread predictions that many workers face a fight for their jobs with AI, polling by Ipsos found that among more than 1,500 British workers aged 16 to 75, 33% said they did not discuss their use of AI to help them at work with bosses or other more senior colleagues. They were less coy with people at the same level, but a quarter of people believe “co-workers will question my ability to perform my role if I share how I use AI”.
The Guardian’s survey also uncovered deep worries about the advance of AI, with more than half of those surveyed believing it threatens the social structure. The number of people believing it has a positive effect is outweighed by those who think it does not. It also found 63% of people do not believe AI is a good substitute for human interaction, while 17% think it is.
Next week’s state visit to the UK by Donald Trump is expected to signal greater collaboration between the UK and Silicon Valley to make Britain an important centre of AI development.
The US president is expected to be joined by Sam Altman, the co-founder of OpenAI who has signed a memorandum of understanding with the UK government to explore the deployment of advanced AI models in areas including justice, security and education. Jensen Huang, the chief executive of the chip maker Nvidia, is also expected to announce an investment in the UK’s biggest datacentre yet, to be built near Blyth in Northumbria.
Keir Starmer has said he wants to “mainline AI into the veins” of the UK. Silicon Valley companies are aggressively marketing their AI systems as capable of cutting grunt work and liberating creativity.
The polling appears to reflect workers’ uncertainty about how bosses want AI tools to be used, with many employers not offering clear guidance. There is also fear of stigma among colleagues if workers are seen to rely too heavily on the bots.
A separate US study circulated this week found that medical doctors who use AI in decision-making are viewed by their peers as significantly less capable. Ironically, the doctors who took part in the research by Johns Hopkins Carey Business School recognised AI as beneficial for enhancing precision, but took a negative view when others were using it.
Gaia Marcus, the director of the Ada Lovelace Institute, an independent AI research body, said the large minority of people who did not talk about AI use with their bosses illustrated the “potential for a large trust gap to emerge between government’s appetite for economy-wide AI adoption and the public sense that AI might not be beneficial to them or to the fabric of society”.
“We need more evaluation of the impact of using these tools, not just in the lab but in people’s everyday lives and workflows,” she said. “To my knowledge, we haven’t seen any compelling evidence that the spread of these generative AI tools is significantly increasing productivity yet. Everything we are seeing suggests the need for humans to remain in the driving seat with the tools we use.”
after newsletter promotion
A study by the Henley Business School in May found 49% of workers reported there were no formal guidelines for AI use in their workplace and more than a quarter felt their employer did not offer enough support.
Prof Keiichi Nakata at the school said people were more comfortable about being transparent in their use of AI than 12 months earlier but “there are still some elements of AI shaming and some stigma associated with AI”.
He said: “Psychologically, if you are confident with your work and your expertise you can confidently talk about your engagement with AI, whereas if you feel it might be doing a better job than you are or you feel that you will be judged as not good enough or worse than AI, you might try to hide that or avoid talking about it.”
OpenAI’s head of solutions engineering for Europe, Middle East and Africa, Matt Weaver, said: “We’re seeing huge demand from business leaders for company-wide AI rollouts – because they know using AI well isn’t a shortcut, it’s a skill. Leaders see the gains in productivity and knowledge sharing and want to make that available to everyone.”
AI Research
IBM AI Research Releases Two English Granite Embedding Models, Both Based on the ModernBERT Architecture
IBM has quietly built a strong presence in the open-source AI ecosystem, and its latest release shows why it shouldn’t be overlooked. The company has introduced two new embedding models—granite-embedding-english-r2 and granite-embedding-small-english-r2—designed specifically for high-performance retrieval and RAG (retrieval-augmented generation) systems. These models are not only compact and efficient but also licensed under Apache 2.0, making them ready for commercial deployment.
What Models Did IBM Release?
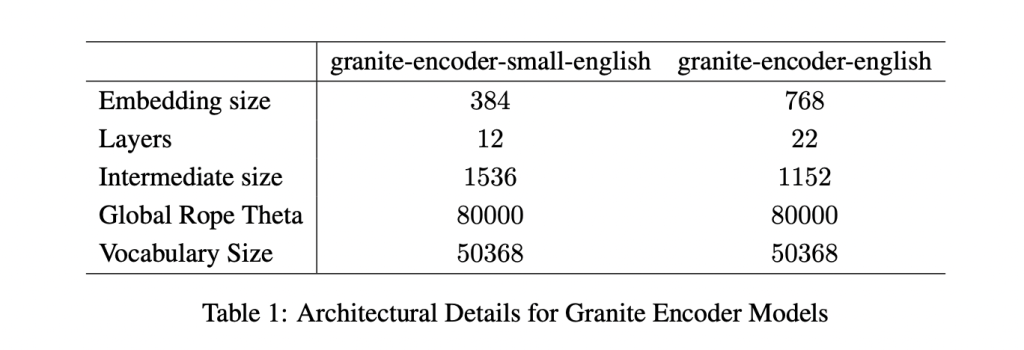
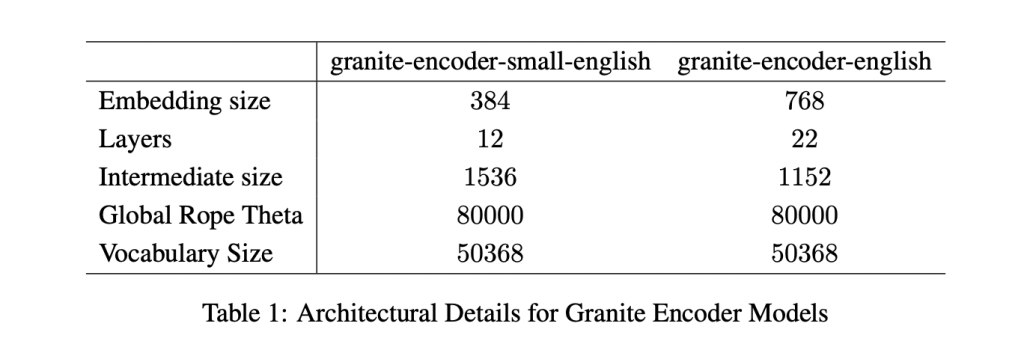
The two models target different compute budgets. The larger granite-embedding-english-r2 has 149 million parameters with an embedding size of 768, built on a 22-layer ModernBERT encoder. Its smaller counterpart, granite-embedding-small-english-r2, comes in at just 47 million parameters with an embedding size of 384, using a 12-layer ModernBERT encoder.
Despite their differences in size, both support a maximum context length of 8192 tokens, a major upgrade from the first-generation Granite embeddings. This long-context capability makes them highly suitable for enterprise workloads involving long documents and complex retrieval tasks.
What’s Inside the Architecture?
Both models are built on the ModernBERT backbone, which introduces several optimizations:
- Alternating global and local attention to balance efficiency with long-range dependencies.
- Rotary positional embeddings (RoPE) tuned for positional interpolation, enabling longer context windows.
- FlashAttention 2 to improve memory usage and throughput at inference time.
IBM also trained these models with a multi-stage pipeline. The process started with masked language pretraining on a two-trillion-token dataset sourced from web, Wikipedia, PubMed, BookCorpus, and internal IBM technical documents. This was followed by context extension from 1k to 8k tokens, contrastive learning with distillation from Mistral-7B, and domain-specific tuning for conversational, tabular, and code retrieval tasks.

How Do They Perform on Benchmarks?
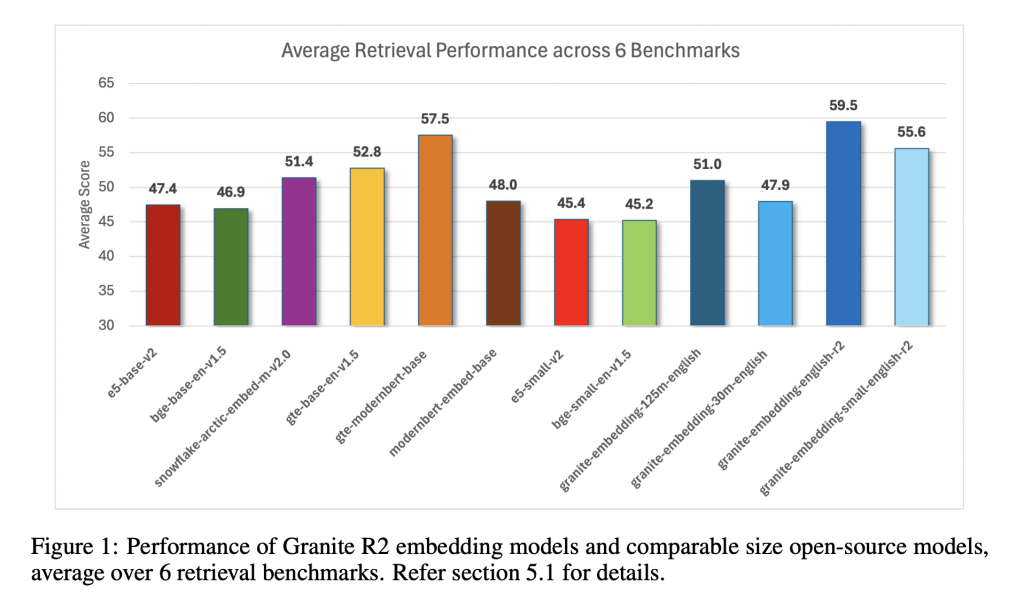
The Granite R2 models deliver strong results across widely used retrieval benchmarks. On MTEB-v2 and BEIR, the larger granite-embedding-english-r2 outperforms similarly sized models like BGE Base, E5, and Arctic Embed. The smaller model, granite-embedding-small-english-r2, achieves accuracy close to models two to three times larger, making it particularly attractive for latency-sensitive workloads.
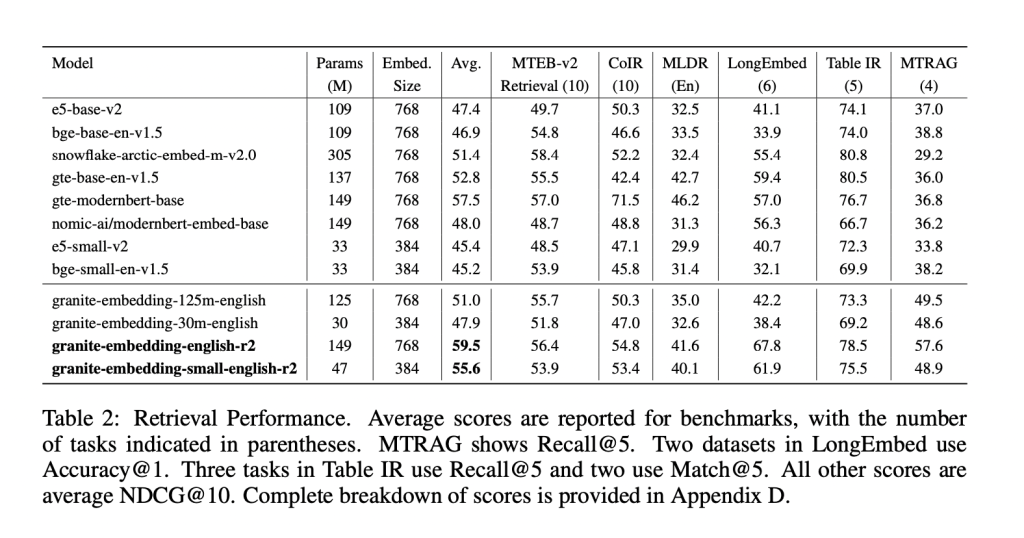
Both models also perform well in specialized domains:
- Long-document retrieval (MLDR, LongEmbed) where 8k context support is critical.
- Table retrieval tasks (OTT-QA, FinQA, OpenWikiTables) where structured reasoning is required.
- Code retrieval (CoIR), handling both text-to-code and code-to-text queries.
Are They Fast Enough for Large-Scale Use?
Efficiency is one of the standout aspects of these models. On an Nvidia H100 GPU, the granite-embedding-small-english-r2 encodes nearly 200 documents per second, which is significantly faster than BGE Small and E5 Small. The larger granite-embedding-english-r2 also reaches 144 documents per second, outperforming many ModernBERT-based alternatives.
Crucially, these models remain practical even on CPUs, allowing enterprises to run them in less GPU-intensive environments. This balance of speed, compact size, and retrieval accuracy makes them highly adaptable for real-world deployment.
What Does This Mean for Retrieval in Practice?
IBM’s Granite Embedding R2 models demonstrate that embedding systems don’t need massive parameter counts to be effective. They combine long-context support, benchmark-leading accuracy, and high throughput in compact architectures. For companies building retrieval pipelines, knowledge management systems, or RAG workflows, Granite R2 provides a production-ready, commercially viable alternative to existing open-source options.
Summary
In short, IBM’s Granite Embedding R2 models strike an effective balance between compact design, long-context capability, and strong retrieval performance. With throughput optimized for both GPU and CPU environments, and an Apache 2.0 license that enables unrestricted commercial use, they present a practical alternative to bulkier open-source embeddings. For enterprises deploying RAG, search, or large-scale knowledge systems, Granite R2 stands out as an efficient and production-ready option.
Check out the Paper, granite-embedding-small-english-r2 and granite-embedding-english-r2. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.
-

 Business2 weeks ago
Business2 weeks agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-
Tools & Platforms1 month ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy2 months ago
Ethics & Policy2 months agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences4 months ago
Events & Conferences4 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers2 months ago
Jobs & Careers2 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Education2 months ago
Education2 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Education2 months ago
Education2 months agoMacron says UK and France have duty to tackle illegal migration ‘with humanity, solidarity and firmness’ – UK politics live | Politics
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi
-

 Funding & Business2 months ago
Funding & Business2 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries