Events & Conferences
Two new approaches to synthesizing speech with appropriate prosody

At ICASSP 2021, the Amazon text-to-speech team presented two new papers about synthesizing speech from text with contextually appropriate prosody — the rhythm, emphasis, melody, duration, and loudness of speech.
Text-to-speech (TTS) is a one-to-many problem where a single piece of text may have more than one appropriate prosodic rendition. Determining the prosody of a piece of text is a non-trivial problem, but it can increase the naturalness of synthesized speech considerably.
The approaches we describe in the two papers share a general philosophy, but the ways in which they tackle the problem are fundamentally different.
One of our papers, “Prosodic representation learning and contextual sampling for neural text-to-speech”, introduces Kathaka, a model trained using a novel two-stage approach. In the first stage, the model learns a distribution of the prosody of all the speech samples in the training data by exploiting a variational learning approach. In stage two, the model learns to sample from this distribution based on semantic and syntactic characteristics of the texts associated with the speech samples.
According to listener studies using the industry-standard MUSHRA (multiple stimuli with hidden reference and anchor) methodology, the speech produced by Kathaka improved over the baseline TTS model by 13.2% in terms of naturalness.
The other paper, “CAMP: A two-stage approach to modelling prosody in context”, introduces CAMP, the context-aware model of prosody. Like Kathaka, CAMP is trained using a two-stage approach. In the first stage, CAMP learns a representation of prosody for every word of each speech sample in the training data in a non-variational way. In stage two, the model learns to predict these learned representations based on the semantic and syntactic characteristics of the associated texts.
According listener studies with MUSHRA evaluations, the speech produced by CAMP improved over the baseline TTS model by 26% in terms of naturalness.
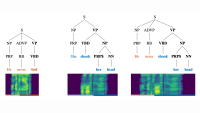
Kathaka
Since TTS is a one-to-many problem, where the same text can be said in different ways, TTS models often synthesize speech with neutral prosody. This decreases the naturalness of synthesized speech, as there is no relation between the prosody and what is being said.
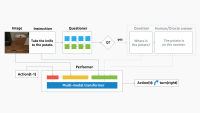
Kathaka’s two-stage learning approach tackles this problem by exploiting the semantics and syntax of the text. The Kathaka architecture has two encoders: one, the reference encoder, takes a mel-spectrogram (a snapshot of the frequency spectrum) of the speech signal as input; the other takes the associated text, represented as a sequence of phonemes, the smallest units of speech.
Based on the mel-spectrogram, the reference encoder outputs the parameters of a prosody distribution (the mean and variance, µ and σ in the diagram above), and a sample is selected from that distribution. This sample, along with the phoneme encoding, is used to synthesize a new mel-spectrogram. The model is an autoencoder, meaning that it’s trained to output the same mel-spectrogram given to the reference encoder as input.
At inference time, of course, mel-spectrograms aren’t available as input, as they are to be synthesized. Thus, in step two, we train “Samplers”, which predict the parameters of the prosody distribution directly from the text.
To encode the text, we use a BERT model, which is pretrained to provide contextual word embeddings — representations of words as vectors in a multidimensional space — that capture semantic and some syntactic information about the text. We also apply graph neural networks to syntax parse trees of the text, to produce representations of just the texts’ syntactic information.
From these representations, the Sampler learns to predict the parameters of the prosody distribution. At inference time, a sample from this distribution is used in place of the sampled point from the reference encoder to synthesize the mel-spectrogram.
In order to evaluate the efficacy of Kathaka, we compared it to our neural-text-to-speech (NTTS) baseline and showed a statistically significant 13.2% increase in naturalness.
CAMP
CAMP uses a similar two-step approach to training, but instead of learning a distribution of prosodies, it learns specific mappings between individual words and prosodic representations, conditioned on semantic and syntactic features of the text.
In stage one, CAMP learns word-level representations of prosody using a word-level reference encoder. This encoder takes a mel-spectrogram as input and produces a word-level representation of the speech sample’s prosody. This word-level representation is then aligned with the phonemes that constitute the word, which, again, are encoded by a separate encoder. Both sets of features are then used to synthesize a mel-spectrogram as output, and the training target is the same mel-spectrogram that the reference encoder took as input. Through this process, CAMP learns word-level prosodic representations.
In stage two, CAMP uses semantic and syntactic information from the input texts to predict the word-level prosody representations learned in stage one. To encode the text, we again use BERT embeddings, and we also use word-level syntax tags such as (1) part of speech (POS); (2) word class (“open” words such as nouns or verbs, which can proliferate indefinitely, versus “closed” words such as pronouns and articles, which are fixed and limited); (3) noun structure; and (4) punctuation structure. This information is then used to predict the word-level prosody representations learned in stage one.
As with Kathaka, during inference, we replace the prosody representations from the reference encoder with the representations predicted from the syntactic and semantic content of the input text.
Compared to our NTTS baseline, CAMP showed a statistically significant 26% increase in naturalness.



















- We’re sharing how Meta is applying machine learning (ML) and diversity algorithms to improve notification quality and user experience.
- We’ve introduced a diversity-aware notification ranking framework to reduce uniformity and deliver a more varied and engaging mix of notifications.
- This new framework reduces the volume of notifications and drives higher engagement rates through more diverse outreach.
Notifications are one of the most powerful tools for bringing people back to Instagram and enhancing engagement. Whether it’s a friend liking your photo, another close friend posting a story, or a suggestion for a reel you might enjoy, notifications help surface moments that matter in real time.
Instagram leverages machine learning (ML) models to decide who should get a notification, when to send it, and what content to include. These models are trained to optimize for user positive engagement such as click-through-rate (CTR) – the probability of a user clicking a notification – as well as other metrics like time spent.
However, while engagement-optimized models are effective at driving interactions, there’s a risk that they might overprioritize the product types and authors someone has previously engaged with. This can lead to overexposure to the same creators or the same product types while overlooking other valuable and diverse experiences.
This means people could miss out on content that would give them a more balanced, satisfying, and enriched experience. Over time, this can make notifications feel spammy and increase the likelihood that people will disable them altogether.
The real challenge lies in finding the right balance: How can we introduce meaningful diversity into the notification experience without sacrificing the personalization and relevance people on Instagram have come to expect?
To tackle this, we’ve introduced a diversity-aware notification ranking framework that helps deliver more diverse, better curated, and less repetitive notifications. This framework has significantly reduced daily notification volume while improving CTR. It also introduces several benefits:
- The extensibility of incorporating customized soft penalty (demotion) logic for each dimension, enabling more adaptive and sophisticated diversity strategies.
- The flexibility of tuning demotion strength across dimensions like content, author, and product type via adjustable weights.
- The integration of balancing personalization and diversity, ensuring notifications remain both relevant and varied.
The Risks of Notifications without Diversity
The issue of overexposure in notifications often shows up in two major ways:
Overexposure to the same author: People might receive notifications that are mostly about the same friend. For example, if someone often interacts with content from a particular friend, the system may continue surfacing notifications from that person alone – ignoring other friends they also engage with. This can feel repetitive and one-dimensional, reducing the overall value of notifications.
Overexposure to the same product surface: People might mostly receive notifications from the same product surface such as Stories, even when Feed or Reels could provide value. For example, someone may be interested in both reel and story notifications but has recently interacted more often with stories. Because the system heavily prioritizes past engagement, it sends only story notifications, overlooking the person’s broader interests.
Introducing Instagram’s Diversity-Aware Notification Ranking Framework
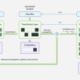
Instagram’s diversity-aware notification ranking framework is designed to enhance the notification experience by balancing the predicted potential for user engagement with the need for content diversity. This framework introduces a diversity layer on top of the existing engagement ML models, applying multiplicative penalties to the candidate scores generated by these models, as figure1, below, shows.
The diversity layer evaluates each notification candidate’s similarity to recently sent notifications across multiple dimensions such as content, author, notification type, and product surface. It then applies carefully calibrated penalties—expressed as multiplicative demotion factors—to downrank candidates that are too similar or repetitive. The adjusted scores are used to re-rank the candidates, enabling the system to select notifications that maintain high engagement potential while introducing meaningful diversity. In the end, the quality bar selects the top-ranked candidate that passes both the ranking and diversity criteria.
Mathematical Formulation
Within the diversity layer, we apply a multiplicative demotion factor to the base relevance score of each candidate. Given a notification candidate 𝑐, we compute its final score as the product of its base ranking score and a diversity demotion multiplier:

where R(c) represents the candidate’s base relevance score, and D(c) ∈ [0,1] is a penalty factor that reduces the score based on similarity to recently sent notifications. We define a set of semantic dimensions (e.g., author, product type) along which we want to promote diversity. For each dimension i, we compute a similarity signal pi(c) between candidate c and the set of historical notifications H, using a maximal marginal relevance (MMR) approach:

where simi(·,·) is a predefined similarity function for dimension i. In our baseline implementation, pi(c) is binary: it equals 1 if the similarity exceeds a threshold 𝜏i and 0 otherwise.
The final demotion multiplier is defined as:
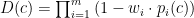
where each wi ∈ [0,1] controls the strength of demotion for its respective dimension. This formulation ensures that candidates similar to previously delivered notifications along one or more dimensions are proportionally down-weighted, reducing redundancy and promoting content variation. The use of a multiplicative penalty allows for flexible control across multiple dimensions, while still preserving high-relevance candidates.
The Future of Diversity-Aware Ranking
As we continue evolving our notification diversity-aware ranking system, a next step is to introduce more adaptive, dynamic demotion strategies. Instead of relying on static rules, we plan to make demotion strength responsive to notification volume and delivery timing. For example, as a user receives more notifications—especially of similar type or in rapid succession—the system progressively applies stronger penalties to new notification candidates, effectively mitigating overwhelming experiences caused by high notification volume or tightly spaced deliveries.
Longer term, we see an opportunity to bring large language models (LLMs) into the diversity pipeline. LLMs can help us go beyond surface-level rules by understanding semantic similarity between messages and rephrasing content in more varied, user-friendly ways. This would allow us to personalize notification experiences with richer language and improved relevance while maintaining diversity across topics, tone, and timing.

Every day, millions of customers search for books in various formats (audiobooks, e-books, and physical books) across Amazon and Audible. Traditional keyword autocomplete suggestions, while helpful, usually require several steps before customers find their desired content. Audible took on the challenge of making book discovery more intuitive and personalized while reducing the number of steps to purchase.
We developed an instant visual autocomplete system that enhances the search experience across Amazon and Audible. As the user begins typing a query, our solution provides visual previews with book covers, enabling direct navigation to relevant landing pages instead of the search result page. It also delivers real-time personalized format recommendations and incorporates multiple searchable entities, such as book pages, author pages, and series pages.
Our system needed to understand user intent from just a few keystrokes and determine the most relevant books to display, all while maintaining low latency for millions of queries. Using historical search data, we match keystrokes to products, transforming partial inputs into meaningful search suggestions. To ensure quality, we implemented confidence-based filtering mechanisms, which are particularly important for distinguishing between general queries like “mystery” and specific title searches. To reflect customers’ most recent interests, the system applies time-decay functions to long historical user interaction data.
To meet the unique requirements of each use case, we developed two distinct technical approaches. On Audible, we deployed a deep pairwise-learning-to-rank (DeepPLTR) model. The DeepPLTR model considers pairs of books and learns to assign a higher score to the one that better matches the customer query.
The DeepPLTR model’s architecture consists of three specialized towers. The left tower factors in contextual features and recent search patterns using a long-short-term-memory model, which processes data sequentially and considers its prior decisions when issuing a new term in the sequence. The middle tower handles keyword and item engagement history. The right tower factors in customer taste preferences and product descriptions to enable personalization. The model learns from paired examples, but at runtime, it relies on books’ absolute scores to assemble a ranked list.
For Amazon, we implemented a two-stage modeling approach involving a probabilistic information-retrieval model to determine the book title that best matches each keyword and a second model that personalizes the book format (audiobooks, e-books, and physical books). This dual-strategy approach maintains low latency while still enabling personalization.
In practice, a customer who types “dungeon craw” in the search bar now sees a visual recommendation for the book Dungeon Crawler Carl, complete with book cover, reducing friction by bypassing a search results page and sending the customer directly to the product detail page. On Audible, the system also personalizes autocomplete results and enriches the discovery experience with relevant connections. These include links to the author’s complete works (Matt Dinniman’s author page) and, for titles that belong to a series, links to the full collection (such as the Dungeon Crawler Carl series).
On Amazon, when the customer clicks on the title, the model personalizes the right book-format (audiobooks, e-books, physical books) recommendation and directs the customer to the right product detail page.
In both cases, after the customer has entered a certain number of keystrokes, the system employs a model to detect customer intent (e.g., book title intent for Amazon or author intent for Audible) and determine which visual widget should be displayed.
Audible and Amazon books’ visual autocomplete provides customers with more relevant content more rapidly than traditional autocomplete, and its direct navigation reduces the number of steps to find and access desired books — all while handling millions of queries at low latency.
This technology is not just about making book discovery easier; it is laying the foundation for future improvements in search personalization and visual discovery across Amazon’s ecosystem.
Acknowledgements: Jiun Kim, Sumit Khetan, Armen Stepanyan, Jack Xuan, Nathan Brothers, Eddie Chen, Vincent Lee, Soumy Ladha, Justine Luo, Yuchen Zeng, David Torres, Gali Deutsch, Chaitra Ramdas, Christopher Gomez, Sharmila Tamby, Melissa Ma, Cheng Luo, Jeffrey Jiang, Pavel Fedorov, Ronald Denaux, Aishwarya Vasanth, Azad Bajaj, Mary Heer, Adam Lowe, Jenny Wang, Cameron Cramer, Emmanuel Ankrah, Lydia Diaz, Suzette Islam, Fei Gu, Phil Weaver, Huan Xue, Kimmy Dai, Evangeline Yang, Chao Zhu, Anvy Tran, Jessica Wu, Xiaoxiong Huang, Jiushan Yang

Modern warehouses rely on complex networks of sensors to enable safe and efficient operations. These sensors must detect everything from packages and containers to robots and vehicles, often in changing environments with varying lighting conditions. More important for Amazon, we need to be able to detect barcodes in an efficient way.
The Amazon Robotics ID (ARID) team focuses on solving this problem. When we first started working on it, we faced a significant bottleneck: optimizing sensor placement required weeks or months of physical prototyping and real-world testing, severely limiting our ability to explore innovative solutions.
To transform this process, we developed Sensor Workbench (SWB), a sensor simulation platform built on NVIDIA’s Isaac Sim that combines parallel processing, physics-based sensor modeling, and high-fidelity 3-D environments. By providing virtual testing environments that mirror real-world conditions with unprecedented accuracy, SWB allows our teams to explore hundreds of configurations in the same amount of time it previously took to test just a few physical setups.
Camera and target selection/positioning
Sensor Workbench users can select different cameras and targets and position them in 3-D space to receive real-time feedback on barcode decodability.
Three key innovations enabled SWB: a specialized parallel-computing architecture that performs simulation tasks across the GPU; a custom CAD-to-OpenUSD (Universal Scene Description) pipeline; and the use of OpenUSD as the ground truth throughout the simulation process.
Parallel-computing architecture
Our parallel-processing pipeline leverages NVIDIA’s Warp library with custom computation kernels to maximize GPU utilization. By maintaining 3-D objects persistently in GPU memory and updating transforms only when objects move, we eliminate redundant data transfers. We also perform computations only when needed — when, for instance, a sensor parameter changes, or something moves. By these means, we achieve real-time performance.
Visualization methods
Sensor Workbench users can pick sphere- or plane-based visualizations, to see how the positions and rotations of individual barcodes affect performance.
This architecture allows us to perform complex calculations for multiple sensors simultaneously, enabling instant feedback in the form of immersive 3-D visuals. Those visuals represent metrics that barcode-detection machine-learning models need to work, as teams adjust sensor positions and parameters in the environment.
CAD to USD
Our second innovation involved developing a custom CAD-to-OpenUSD pipeline that automatically converts detailed warehouse models into optimized 3-D assets. Our CAD-to-USD conversion pipeline replicates the structure and content of models created in the modeling program SolidWorks with a 1:1 mapping. We start by extracting essential data — including world transforms, mesh geometry, material properties, and joint information — from the CAD file. The full assembly-and-part hierarchy is preserved so that the resulting USD stage mirrors the CAD tree structure exactly.
To ensure modularity and maintainability, we organize the data into separate USD layers covering mesh, materials, joints, and transforms. This layered approach ensures that the converted USD file faithfully retains the asset structure, geometry, and visual fidelity of the original CAD model, enabling accurate and scalable integration for real-time visualization, simulation, and collaboration.
OpenUSD as ground truth
The third important factor was our novel approach to using OpenUSD as the ground truth throughout the entire simulation process. We developed custom schemas that extend beyond basic 3-D-asset information to include enriched environment descriptions and simulation parameters. Our system continuously records all scene activities — from sensor positions and orientations to object movements and parameter changes — directly into the USD stage in real time. We even maintain user interface elements and their states within USD, enabling us to restore not just the simulation configuration but the complete user interface state as well.
This architecture ensures that when USD initial configurations change, the simulation automatically adapts without requiring modifications to the core software. By maintaining this live synchronization between the simulation state and the USD representation, we create a reliable source of truth that captures the complete state of the simulation environment, allowing users to save and re-create simulation configurations exactly as needed. The interfaces simply reflect the state of the world, creating a flexible and maintainable system that can evolve with our needs.
Application
With SWB, our teams can now rapidly evaluate sensor mounting positions and verify overall concepts in a fraction of the time previously required. More importantly, SWB has become a powerful platform for cross-functional collaboration, allowing engineers, scientists, and operational teams to work together in real time, visualizing and adjusting sensor configurations while immediately seeing the impact of their changes and sharing their results with each other.
New perspectives
In projection mode, an explicit target is not needed. Instead, Sensor Workbench uses the whole environment as a target, projecting rays from the camera to identify locations for barcode placement. Users can also switch between a comprehensive three-quarters view and the perspectives of individual cameras.
Due to the initial success in simulating barcode-reading scenarios, we have expanded SWB’s capabilities to incorporate high-fidelity lighting simulations. This allows teams to iterate on new baffle and light designs, further optimizing the conditions for reliable barcode detection, while ensuring that lighting conditions are safe for human eyes, too. Teams can now explore various lighting conditions, target positions, and sensor configurations simultaneously, gleaning insights that would take months to accumulate through traditional testing methods.

Looking ahead, we are working on several exciting enhancements to the system. Our current focus is on integrating more-advanced sensor simulations that combine analytical models with real-world measurement feedback from the ARID team, further increasing the system’s accuracy and practical utility. We are also exploring the use of AI to suggest optimal sensor placements for new station designs, which could potentially identify novel configurations that users of the tool might not consider.
Additionally, we are looking to expand the system to serve as a comprehensive synthetic-data generation platform. This will go beyond just simulating barcode-detection scenarios, providing a full digital environment for testing sensors and algorithms. This capability will let teams validate and train their systems using diverse, automatically generated datasets that capture the full range of conditions they might encounter in real-world operations.
By combining advanced scientific computing with practical industrial applications, SWB represents a significant step forward in warehouse automation development. The platform demonstrates how sophisticated simulation tools can dramatically accelerate innovation in complex industrial systems. As we continue to enhance the system with new capabilities, we are excited about its potential to further transform and set new standards for warehouse automation.
-

 Business6 days ago
Business6 days agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-
Tools & Platforms3 weeks ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy1 month ago
Ethics & Policy1 month agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences4 months ago
Events & Conferences4 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers2 months ago
Jobs & Careers2 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Education2 months ago
Education2 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Funding & Business2 months ago
Funding & Business2 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi
-

 Education2 months ago
Education2 months agoMacron says UK and France have duty to tackle illegal migration ‘with humanity, solidarity and firmness’ – UK politics live | Politics