Ethics & Policy
Treading water: new data on the impact of AI ethics information sessions in classics and ancient language pedagogy | Journal of Classics Teaching
Introduction
One year has passed since the public research preview of ChatGPT 3.5 was released, and a flood of new generative artificial intelligence (AI) tools have entered the market. This includes a wide variety of generative text tools (e.g. Bard AI, EssayAILab), generative image tools (e.g. DALL-E 3, Midjourney, Stable Diffusion), generative PowerPoint tools (e.g. Tome), generative audio tools (e.g. CassetteAI), generative video tools (e.g. HeyGen), and AI-powered search co-pilots (e.g. Bing Chat, Claude-2, Perplexity) (Anthropic, 2023; Cassette, Reference Cassette2020; EssayAIGroup, 2020; Google, 2023a; HeyGen, 2023; Magical Tome, 2023; Microsoft, 2023; Midjourney, 2023; OpenAI, 2023d; Perplexity, 2023a; Stability.ai, 2023). Conversational AI tools, in particular, now have beta features which allow them to recognise images and engage in voice chat with a user, enhancing user experience and ease of access (Google, 2023b; OpenAI, 2023b). Furthermore, OpenAI has even released a new suite to create personalised Generative Pre-trained Transformers (GPTs) which users can fine tune for their preferred uses (OpenAI, 2023e). Particularly relevant for Classics, generative text AI tools and AI-powered search co-pilots have greatly improved their abilities with ancient languages since March 2023, especially Latin and Ancient Greek (Ross, Reference Ross2023). The sheer speed by which these tools are developing has made it difficult to consider how best to approach using these tools in the Classics context; the picture keeps on changing.
This article presents the methods used in the Department of Classics at the University of Reading to inform and educate staff and students about the ethical considerations for using generative AI programs in Classics and ancient language pedagogy. This essay highlights the key themes discussed in planning sessions with teaching staff and information sessions for students about AI training data, content policy, and environmental impact. To illustrate these discussions, including staff and student opinions, we will present the results of several diagnostic surveys taken during these discussions and presentations.
This article is divided into four parts. First, we will outline the state of the generative AI tool market at the time of writing. Due to the sheer number of tools and how rapidly they are changing, this section will only discuss the new developments which have applications for ancient language study. In the second part, we will discuss the major issues that were presented to staff and students in the Department of Classics at the University of Reading: training data, content policy, and environmental impact. These issues are contextualised with survey results from the Department’s teaching staff. Then, we will present the survey results from students at the information sessions over the course of the Autumn 2023 term. Finally, we will outline the current stage of guidelines for use of generative AI tools in Classics at the University of Reading.
The current state of generative AI text tools for classics
As of November 2023, conversational AI tools, such as ChatGPT-3.5/4 (OpenAI) and Bard (Google), have greatly improved their abilities with Latin and Ancient Greek and have added additional features which streamline and improve user experience (Google, 2023a, 2023b; OpenAI, 2023a, 2023b). ChatGPT’s abilities with Ancient Greek have significantly improved since March 2023. Where it had previously mixed together grammatical forms from Classical, New Testament, and Modern Greek, ChatGPT-3.5’s translation and composition abilities are now on par with its Latin abilities. Compared to its translation of the test phrase ‘The giant who eats men is not in the field now’ in March 2023, ChatGPT is now able to produce a reasonably accurate output that follows Attic Greek grammar and properly labels grammatical forms (Figure 1) (Ross, Reference Ross2023, 147–154; Taylor, Reference Taylor2016, 34).Footnote 1 These abilities are still at an elementary level and frequently make errors, but ChatGPT and other generative text tools can effectively discuss grammar, create vocabulary quizzes, and translate and compose short passages in Latin and Ancient Greek with reasonable accuracy. These functionalities with ancient languages have further applications for student use with generative text AI’s new beta features.

Figure 1. Left: Figure 18 from Ross, Reference Ross2023, p. 153; Right: OpenAI, ChatGPT 3.5, September 25, 2023 version, personal communication, generated 8 October 2023. Prompt: ‘Provide an Ancient Greek translation of this English sentence, “The giant who eats men is not in the field now.” and provide all grammatical information about each Ancient Greek word.’
Voice chat with generative text AI tools was made available as a beta feature through Bard in July 2023 and ChatGPT in September 2023 (Google, 2023b; OpenAI, 2023b). This feature allows a user to provide a prompt to the AI tool orally through a microphone, and the tool then provides its output verbally in response. ChatGPT’s style of voice output appears very human-like and mimics a phone call. The tool can use five different voice tones that adapt its conversation style as the conversation progresses, and it provides a transcript of the inputs and outputs once the conversation is complete (OpenAI, 2023b). Furthermore, although we do not know how ancient languages sounded, ChatGPT’s voice outputs are able to vocalise Latin and Ancient Greek words according to general academic considerations of how these languages may have sounded (Clackson, Reference Clackson and Clackson2011; Morpurgo Davies, Reference Morpurgo Davies2015) (Supplementary File 1). The tools’ abilities with Latin and Ancient Greek in voice chat are consistent with its text abilities, but this does present a more human manner of supporting ancient language learning outside the classroom.
Another new feature which could impact Classics and ancient language T&L is generative text tools’ image recognition. ChatGPT-4, Bard AI, and Perplexity can now accept images as prompts, read them, summarise them, and provide outputs based on their content (Google, 2023b; OpenAI, 2023b; Perplexity, 2023b). This presents an interesting possibility for ancient language teaching. A student could take a photograph of some homework questions and their answers, requesting that the AI provide constructive feedback on these answers (Figure 2). In this example, the AI is prepared with a screenshot of the homework questions from Henry Cullen and John Taylor’s Latin to GCSE: Part 2 and then provided a photo of handwritten answers to the questions (Reference Cullen and Taylor2016, 22). ChatGPT-4 can read both images accurately, provide transcriptions, and then provide constructive feedback for the translations as teacher or tutor would. Unfortunately, the tool is limited by its capabilities with Latin and Ancient Greek and sometimes makes errors, but, overall, it tends to highlight actual points of error and frames them with supportive feedback.

Figure 2. OpenAI, ChatGPT 3.5, October 17, 2023 version, personal communication, generated 20 October 2023. Prompt: ‘These are the homework questions for Classical Latin. In this conversation, I want you to read my work and tell me if I have translated the sentences accurately.’
These new functions support a growing potential use for conversational AI tools as an out-of-hours language tutor. Both the voice chat and image recognition functions present easy methods for students to ask grammar questions or request feedback without needing to type out their questions or homework answers. These features could be further fine-tuned with a language model trained specifically to respond to questions at the expected course level. OpenAI’s GPTs product provides a streamlined API (application programming interface) for teachers to train a GPT by uploading training data specific to their courses and detailing the specific actions which they want the GPT to perform (OpenAI, 2023e). These custom programs could be extremely useful to support ancient language learning, but they are just as restricted as ChatGPT by their Latin and Ancient Greek abilities and require significant development time from the creator. With proper fine-tuning, however, an ancient language GPT could support at-home learning in a way which current digital study tools are unable to fulfill.
Although conversational AI tools are still inconsistent with their Latin and Ancient Greek abilities, they could be an increasingly useful first port-of-call for ancient language learning support when teachers are unavailable or when students are too nervous to submit their work for formative feedback. This, however, is entirely dependent on whether students wish to use these tools once they have been informed about the ethical considerations for AI.
Training data
In the AI information sessions that were held in the Department of Classics at the University of Reading, we introduced three major considerations to our students. The first focused on the training data involved in the creation and development of generative AI tools. We focused on the training data used in GPT-3, one of OpenAI’s legacy models, to demonstrate the general areas where information was gathered and to highlight its problems. This training data included filtered Common Crawl data, WebText, ebooks, and Wikipedia articles from prior to September 2021 (Brown et al., Reference Brown, Mann, Ryder, Subbiah, Kaplan, Dhariwal, Neelakantan, Shyam, Sastry, Askell, Agarwal, Herbert-Voss, Krueger, Henighan, Child, Ramesh, Ziegler, Wu, Winter, Hesse, Chen, Sigler, Litwin, Gray, Chess, Clark, Berner, McCandlish, Radford, Sutskever and Amodei2020, 9; OpenAI, 2023c). The details of this training data are generally vague, only listing the major websites where data was gathered and vague group identifiers, but users have been researching what information is present in ChatGPT’s training data (Brown et al., Reference Brown, Mann, Ryder, Subbiah, Kaplan, Dhariwal, Neelakantan, Shyam, Sastry, Askell, Agarwal, Herbert-Voss, Krueger, Henighan, Child, Ramesh, Ziegler, Wu, Winter, Hesse, Chen, Sigler, Litwin, Gray, Chess, Clark, Berner, McCandlish, Radford, Sutskever and Amodei2020, 9; veekaybee, 2022). Of interest to ancient language study, Patrick J. Burns has found that GPT-3 has approximately 339.1 million Latin word tokens in its training data, and ChatGPT-4 will likely have many more (Reference Burns2023). The WebText and ebooks in the training data, on the other hand, have drawn wider attention from global governments and media.
To contextualise the problematic position of AI training data, we showed students information about the current legal disputes surrounding training data collection. OpenAI faced legislation and lawsuits related to disclosing its training data over 2023, and this has re-ignited debates on the nature of copyright and data protection (Appel et al., Reference Appel, Neelbauer and Schweidel2023; Bikbaeva, Reference Bikbaeva2023; Lucchi, Reference Lucchi2023; Taylor, Reference Taylor2023; Vincent, Reference Vincent2023; Zahn, Reference Zahn2023). Authors and artists claim that their works were used to train AI without proper attribution and that this is severely impacting their markets (Creamer, Reference Creamer2023; Metz, Reference Metz2023; Wong, Reference Wong2023). Furthermore, the risk of data protection breaches in using social media content in training data has led the European Union to request the full details of OpenAI’s training datasets (Vincent, Reference Vincent2023). At the time of writing, many of these disputes have yet to have a resolution, but artists, authors, and users are working to navigate through this tumultuous period of innovation.
Since much of the training data for generative AI tools has come from open repositories, sometimes without permission, developers have been working on new tools to help creators maintain ownership of their art and style. However, these developments require us to consider if AI models contain harmful inputs in their training data that impact future student use of the tools. The Glaze team at the University of Chicago has developed a new form of their image cloaking tool called Nightshade (Katz, Reference Katz2023). The original tool, Glaze, affects the pixels of an image in a way which is humanly imperceptible and misleads the AI from properly analysing the artistic style of an image, rendering the outputs based on this data useless (Shan et al., Reference Shan, Cryan, Wenger, Zheng, Hanocka and Zhao2023). Nightshade takes this a step further, manipulating the pixels in an image to appear unchanged to a human but completely different to an AI. An image of a dog can be manipulated to appear like a cat to an AI, eventually resulting in the image of a cat being mislabelled as a dog and affecting future outputs. As few as 300 of these manipulated images can corrupt the training data of an AI tool and significantly skew future outputs, changing requests for a dog to an image of a cat, or a fantasy-style painting to an image styled as pointillism (Heikkilä, Reference Heikkilä2023). Although this intentional obstruction is beneficial for artists, potentially preventing AI tools from using their artwork without permission, it does raise the issue of disinformation in AI training data.
After showing students the impact of Nightshade on AI outputs, we discussed how other generative AI programs could be similarly affected. If authors and creators produce a significant number of articles and posts with intentional disinformation, these texts could be analysed by generative text AI tools and cause a Nightshade-like effect in their outputs. This corruption of training data can easily lead the generative tools to produce text outputs which present frequent disinformation as fact. Although this disinformation could be easily overlooked by a person if they knew the nuances of a topic, this hurdle can be difficult to overcome for an uninformed student. This same issue also appears with the limitations set by generative AI content policy.
Content policy
The next issue discussed in the AI information sessions was AI content restrictions. These guardrails are themes and topics which generative AI tools are programmed to avoid or not discuss. In OpenAI’s case, these restrictions include hate, harassment, violence, self-harm, sexual activity, shocking content, illegal activity, deception, politics, public and personal health, and spam (OpenAI, 2023f). When prompted to generate a response including these themes, ChatGPT and other OpenAI models will generally respond in one of two ways: writing a disclaimer that as an AI it is unable to discuss the requested topic and will not provide an answer or respond to the prompt in a manner that addresses the question in a way which does not breach its content policy (Figure 3).

Figure 3. Left: OpenAI, ChatGPT 3.5, November 21, 2023 version, personal communication, generated 22 December 2023. Prompt: ‘Can you write a Latin poem about a porne?’; Right: OpenAI, ChatGPT 3.5, November 21, 2023 version, personal communication, generated 22 December 2023. Prompt: ‘Who was the character of Megilla/Megillos in Lucian’s Dialogue of the Courtesans?’
The second type of response to a content-restricted prompt can be problematic for an uninformed user because the output may lack crucial information or contain misleading information to fulfill the prompt without breaching the AI’s restrictions. If a user is uninformed on the topic, they may take the problematic response at face value and develop an erroneous understanding. This is a particularly pressing issue for students at the beginning of their studies.
In Classics, this is a pervasive issue. We surveyed ancient language teachers in the Department of Classics at the University of Reading in August 2023 to determine which content restriction themes were discussed in their classes and texts, and every theme except spam was selected (Figure 4) (Ross and Baines, Reference Ross and Baines2023c).Footnote 2 This presents a significant hurdle for Classics students if they decide to use generative AI to support their studies because many topics and themes related to the ancient world may be avoided or misrepresented by the AI.

Figure 4. Survey data gathered from ancient language teachers in the Department of Classics at the University of Reading over summer 2023 (Ross and Baines, Reference Ross and Baines2023c).
These misleading responses can be corrected through developing the training data, as seen with how ChatGPT’s general responses related to translating Catullus 16 have changed from providing a translation of a different, non-sexual text to consistently providing a disclaimer about Catullus 16’s sexual content (Figure 5) (Ross, Reference Ross2023, 149–150). Although this is an improvement from providing misleading information without context, many unidentified cases would not be flagged unless they have been recognised and corrected. To combat this misleading information without context, it is crucial for knowledgeable users to check the information and outputs related to avoided topics to ensure the outputs are fully addressing the topic accurately with all essential content. Any instance where it is not the case should be highlighted and reported so that the generative AI training data can be improved.

Figure 5. Left: Figure 11 from Ross, Reference Ross2023, p. 150; Right: OpenAI, ChatGPT 3.5, November 21, 2023 version, personal communication, generated 22 December 2023. Prompt: ‘Provide an accurate translation of Catullus 16 in English.’
This leaves a particular problem for uninformed students. Unless they are fully aware of the details related to a topic, a user cannot be sure that the information provided by generative AI is complete. As such, students need to be conscious of this potential pitfall prior to using the tools so that they can make informed judgements about the veracity of its outputs.
Environmental impact
The third aspect which we introduce to students is the environmental impact of AI training and maintenance. When GPT-2 was initially trained in 2019, researchers at the University of Massachusetts, Amherst, found that training a standard AI model produced approximately 625,000 pounds of CO2 emissions (Strubell et al., Reference Strubell, Ganesh and McCallum2019). This was equivalent to the emissions of five US cars over the course of their entire lifetime, including manufacturing (Hao, Reference Hao2019). GPT-2 and other models during that time are much smaller than the current models on the public market and in training. A 2023 study by Alex de Vries at VU Amsterdam found that accelerated development of current models like Bing Chat and Bard present unprecedented energy consumption rates. If Google Bard is trained and maintained with current technological advancements, it would consume an average of 29.3 TWh per year, which is equivalent to the entire country of Ireland (de Vries, Reference de Vries2023). And this consumption is only for one model. Considering the large number of AI models that have greatly increased usage and development, these energy numbers may become exponentially large.
These numbers bring to question whether we should consider supporting the use of AI in the classroom, especially in a time of environmental crisis. Since Reading has actioned its sustainability plans for 2020–2026 to include a behaviour and awareness program, it is crucial that students are aware of the environmental impact of generative AI (University of Reading Sustainability Services, 2020). In conversation with students following the information sessions, several mentioned that they were astounded by the carbon emissions of generative AI. Both these environmental considerations alongside the problematic training data and outputs appear to have affected students’ views on AI use.
Speaking to students
During the AI information sessions that we held in Autumn 2023 term, we gathered survey data from student participants (Ross and Baines, Reference Ross and Baines2023a, Reference Ross and Baines2023b). Most of our presentations were for ancient language students in the Department of Classics at the University of Reading, but we also held general AI information sessions for the wider student body in both the Classics and modern languages departments. To ensure effective data collection, we followed a methodology approved by the University of Reading University Research Ethics Committee.
Prior to each presentation, we asked participants to voluntarily complete the first portion of the survey form to gather their opinions about generative AI. This portion of the survey was intended to collect student’s opinion before they learned more about potential ethical considerations. From the language student results, we found that 92.1% of students had heard of generative AI tools for study, and 62.9% of students had also had AI tools for study advertised to them (Figure 6). Most of these students had heard about conversational AI tools, generative image AI, and AI-powered search co-pilots; ChatGPT, DALL-E, and Perplexity were the most popular answers. However, many students mentioned more obscure tools, including Tome, Loom AI, SnapchatAI, WordTune, and PicsArt. The majority were hearing about these tools on social media or in conversation with friends and classmates (Figure 7). It is clear from these results that students not only know about generative AI, but they are constantly being bombarded with advertisements for all sorts of tools as they are published.

Figure 6. Survey data gathered from ancient language students in the Department of Classics at the University of Reading over Autumn 2023 term (Ross and Baines, Reference Ross and Baines2023a).

Figure 7. Survey data gathered from ancient language students in the Department of Classics at the University of Reading over Autumn 2023 term (Ross and Baines, Reference Ross and Baines2023a).
Interestingly, the usage statistics do not lean as far towards the positive. Only 47.2% of the surveyed ancient language students had previously used generative AI; 18% of all those surveyed used them to support learning or assignments (Figure 8).
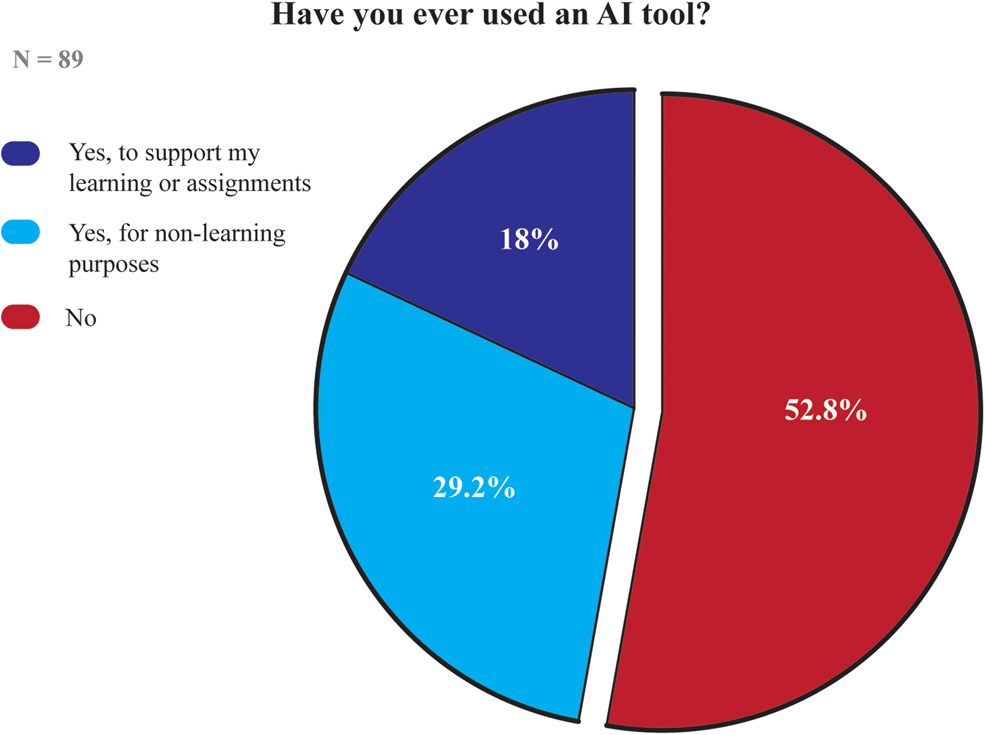
Figure 8. Survey data gathered from ancient language students in the Department of Classics at the University of Reading over Autumn 2023 term (Ross and Baines, Reference Ross and Baines2023a).
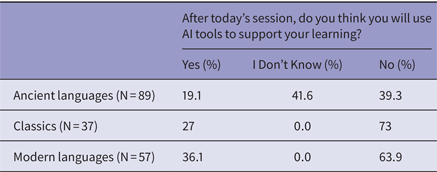
It is unclear if the ancient language students in these information sessions felt pressured to answer in the negative despite several assurances that all survey responses would be properly safeguarded and would not return to them, especially since the usage statistics were surprisingly low compared to public discussion. General student metrics found around 50% of students currently enrolled in university were using generative AI in some capacity (Coffey, Reference Coffey2023; Nam, Reference Nam2023). So, we compared our ancient language results to the anonymous survey results gathered through Mentimeter at our general AI information sessions (Table 1).

In all three sets of surveys, student knowledge about AI was consistently over 90%, while AI usage varied greatly. The ancient language sessions were done in small groups, while the Classics and modern languages sessions were in larger rooms. Despite this, there appears to be a greater apprehension for using AI among Classics and ancient language students than modern language students. Although group sizes may have affected our pre-presentation results, the post-session results are consistent.
Following the presentation, we asked participants to complete the second half of the survey once they had a fuller picture of how generative AI works and is made. Interestingly, only 19.1% of ancient language students said they would consider using generative AI, while 80.9% were either against or apprehensive of using them (Figure 9). Many students noted that they did not like how inaccurate generative AI could be, especially due to its elementary abilities with Latin and Ancient Greek. Furthermore, several students indicated their support for artists and authors, considering the ongoing Writers Guild of America (WGA) and Screen Actors Guild – American Federation of Television and Radio Artists (SAG-AFTRA) strike actions at the time of survey (Anguiano and Beckett, Reference Anguiano and Beckett2023; Watercutter and Bedingfield, Reference Watercutter and Bedingfield2023).

Figure 9. Survey data gathered from ancient language students in the Department of Classics at the University of Reading over Autumn 2023 term (Ross and Baines, Reference Ross and Baines2023a).
Those students who did wish to use generative AI, or were considering it, thought it could be useful for revision, language study support, and generating additional homework questions (Figure 10). Many of these suggested uses, however, were paired with comments saying that they would only use the AI tool for these purposes if its Latin and Ancient Greek abilities improved. Interestingly, there were also a few students who aimed to use AI for non-learning related purposes, such as writing professional emails or Instagram captions.

Figure 10. Survey data gathered from ancient language students in the Department of Classics at the University of Reading over Autumn 2023 term (Ross and Baines, Reference Ross and Baines2023a).
Both Classics and modern languages students also leaned towards rejection or apprehension of AI tools after learning about the ethical considerations (Table 2). As seen with the pre-presentation results, there is an increase in ‘yes’ responses in the wider groups of participants. However, the lean towards rejection remains consistent across all three datasets. At this stage, it appears that informing students about the benefits and drawbacks of generative AI provides them with the tools needed to critically consider whether or not to use it. Students had the option to indicate the reasons why they rejected using generative AI, and these reasons included lack of trust in AI outputs (28.42% of all respondents), fear of plagiarism accusations (8.74%), fear AI will replace human work (7.10%), unethical training data (3.83%), and support of affected artists (2.19%) (Ross and Baines, Reference Ross and Baines2023a, Reference Ross and Baines2023b). It is unclear if these opinions will remain the same over the academic year, but we can continue to scaffold student knowledge about AI developments as time progresses.
Building guidelines
As discussed earlier, our research involved discussing AI usage with both staff and students. It was necessary to draw up guidelines for AI usage which clearly addressed the issues surrounding AI and how the Department of Classics would engage with generative AI in classes and assignments. This required a delicate balance because there were many strong opinions about AI use in HE. In their responses to our initial staff survey, there was a broad spread of views (Ross and Baines, Reference Ross and Baines2023c). Some were completely against AI use and found it should be ignored, others wanted to embrace it fully but were unsure of the best methods, and others were utterly confused by it.
Following several discussions and information sessions, the department determined that allowed AI use should be at the discretion of module convenors, but all students should be informed about the benefits and drawbacks of generative AI and any new developments as they arise. To do this, we developed a general guidance and citation guide which would be publicly available to staff and students and consistently updated. The guidance document was developed bearing in mind the many guiding principles laid out by HE bodies in the UK and globally (Atlas, Reference Atlas2023; Jisc, 2023; Quality Assurance Agency for Higher Education, 2023; Russell Group, 2023; UNESCO International Institute for Higher Education in Latin America and the Caribbean, 2023). The Autumn 2023 version of the guidance is attached to this article in Supplemental Materials (Supplementary File 2).
Assignments/citations
If a Reading Classics student’s module convenor approves the use of AI in an assignment, they are first and foremost required to document all uses of AI they make while preparing their assignment, whether any of it ends up in the body text or not. All cases of AI use need to be indicated in the first footnote of an assignment following this general method:
1The writing of this assignment is my own, and I take responsibility for all errors. During the preparation of this assignment, Perplexity (Perplexity AI, 9 August 2023 version) was used to gather articles for preliminary research into this research question.
This allows students to be accountable for their academic work and protects them from potential plagiarism misunderstandings. The disclaimer footnote, however, also needs to be accompanied by proper citations and documentation.
The Department of Classics at the University of Reading traditionally uses the Harvard citation style to cite modern sources. Many universities have released their own versions of the Harvard system to address the issue of citing generative AI outputs (St. George’s University of London Library, 2023; University of Queensland, Australia Library, 2023), and many are based on the Bloomsbury CiteThemRight guide. These citation guides, across all relevant citation systems, generally consider AI outputs as personal communications (Bloomsbury Publishing, n.-d.-a, n.-d.-b, n.-d.-c, n.-d.-d, n.-d.-e, n.-d.-f, n.-d.-g, n.-d.-h). Unfortunately, we found that these citation styles did not require crucial information about the AI tools used, so we created an adapted citation guide for our students (Supplementary File 3).
In order to ensure that readers know which versions of AI models are used, we require that students provide the following information:
e.g. (OpenAI, ChatGPT 3.5, 3 August 2023 version, personal communication, generated 18 September 2023).
It is particularly important that citations include both the model and version numbers in their citation because multiple different models of generative AI tools exist at the same time and different versions can respond to the same questions quite differently. If a student cites an AI program itself, they should cite it following the method for a computer program but must also provide the developer’s name, AI tool name, AI model number, and update version in the citation.
Since generative AI outputs are non-reproducible, the Department of Classics at the University of Reading requires students to maintain a screenshot folder of all AI outputs used for producing their assignments. All AI outputs used for a particular assignment need to be paired with a full citation, the prompt used, and an image and attached as an appendix at the end of their assignment. Although many generative AI tools now create stable links to share outputs, this is not a universal feature, so we still require a screenshot alongside any stable links.
Conclusions
It is clear from our research into conversational AI tools and their potential ethical use in ancient language learning that the starting point of any discussions on its use needs to begin with informing and educating staff and students alike to provide them with a greater understanding of such tools, their content policies, how their training data is gathered and the environmental impact. Excessive feelings of fear or misplaced faith in AI abound if there is a lack of understanding of how the conversational tools work, their current state of accuracy and how they gather their data. From our pre-presentation surveys, it is evident that most students know of and have used AI tools. However, once they are presented with more in-depth information, they can make an informed judgement about the ethical use of AI and, as a result, show a greater reluctance about using it. The students of Latin and Ancient Greek were sceptical about using AI tools after the presentation once they realised the inadequacies of such tools. Modern languages students are aware of the skill of AI tools for their studies but fewer than 20% indicated that they would use them after attending the information session.
From a pedagogical point of view AI conversational tools may have a place in Latin and Ancient Greek beginner and intermediate classes as an additional tool for students to use while studying on their own. It is possible for students outside the classroom, with appropriate direction, to create quizzes, to revise grammar points, to check homework answers, to parse and to translate and compose short passages (Ross, Reference Ross2023).
The development of conversational AI tools continues to accelerate and become more sophisticated in all its aspects. This highlights the need to continue to be vigilant and to check how well the new developments perform in relation to Latin and Ancient Greek along with other areas studied within the field of Classics. If we continue to do this and keep our staff and students informed, the use of conversational AI tools provides an exciting and valuable addition to our teaching resources.
As a continuation of our research, with the aid of focus groups of students, we will test a variety of applications for their output effectiveness and reliability when using a specific set of guiding phrases to be used to assist Latin and Ancient Greek language learning. This includes ChatGPT 3.5/4, Bard AI, Claude-2, Bing Chat, and custom GPTs through OpenAI’s new GPT system. We also will be updating our guidance documents as new tools and guiding principles are released.
Ethics & Policy
Tech leaders in financial services say responsible AI is necessary to unlock GenAI value

Good morning. CFOs are increasingly responsible for aligning AI investments with business goals, measuring ROI, and ensuring ethical adoption. But is responsible AI an overlooked value creator?
Scott Zoldi, chief analytics officer at FICO and author of more than 35 patents in responsible AI methods, found that many customers he’s spoken to lacked a clear concept of responsible AI—aligning AI ethically with an organizational purpose—prompting an in-depth look at how tech leaders are managing it.
According to a new FICO report released this morning, responsible AI standards are considered essential innovation enablers by senior technology and AI leaders at financial services firms. More than half (56%) named responsible AI a leading contributor to ROI, compared to 40% who credited generative AI for bottom-line improvements.
The report, based on a global survey of 254 financial services technology leaders, explores the dynamic between chief AI/analytics officers—who focus on AI strategy, governance, and ethics—and CTOs/CIOs, who manage core technology operations and alignment with company objectives.
Zoldi explained that, while generative AI is valuable, tech leaders see the most critical problems and ROI gains arising from responsible AI and true synchronization of AI investments with business strategy—a gap that still exists in most firms. Only 5% of respondents reported strong alignment between AI initiatives and business goals, leaving 95% lagging in this area, according to the findings.
In addition, 72% of chief AI officers and chief analytics officers cite insufficient collaboration between business and IT as a major barrier to company alignment. Departments often work from different metrics, assumptions, and roadmaps.
This difficulty is compounded by a widespread lack of AI literacy. More than 65% said weak AI literacy inhibits scaling. Meanwhile, CIOs and CTOs report that only 12% of organizations have fully integrated AI operational standards.
In the FICO report, State Street’s Barbara Widholm notes, “Tech-led solutions lack strategic nuance, while AI-led initiatives can miss infrastructure constraints. Cross-functional alignment is critical.”
Chief AI officers are challenged to keep up with the rapid evolution of AI. Mastercard’s chief AI and data officer, Greg Ulrich, recently told Fortune that last year was “early innings,” focused on education and experimentation, but that the role is shifting from architect to operator: “We’ve moved from exploration to execution.”
Across the board, FICO found that about 75% of tech leaders surveyed believe stronger collaboration between business and IT leaders, together with a shared AI platform, could drive ROI gains of 50% or more. Zoldi highlighted the problem of fragmentation: “A bank in Australia I visited had 23 different AI platforms.”
When asked about innovation enablers, 83% of respondents rated cross-departmental collaboration as “very important” or “critical”—signaling that alignment is now foundational.
The report also stresses the importance of human-AI interaction: “Mature organizations will find the right marriage between the AI and the human,” Zoldi said. And that involves human understanding for where to ”best place AI in that loop,” he said.
Sheryl Estrada
sheryl.estrada@fortune.com
Leaderboard
Brian Robins was appointed CFO of Snowflake (NYSE: SNOW), an AI Data Cloud company, effective Sept. 22. Snowflake also announced that Mike Scarpelli is retiring as CFO. Scarpelli will stay a Snowflake employee for a transition period. Robins has served as CFO of GitLab Inc., a technology company, since October 2020. Before that, he was CFO of Sisense, Cylance, AlienVault, and Verisign.
Big Deal
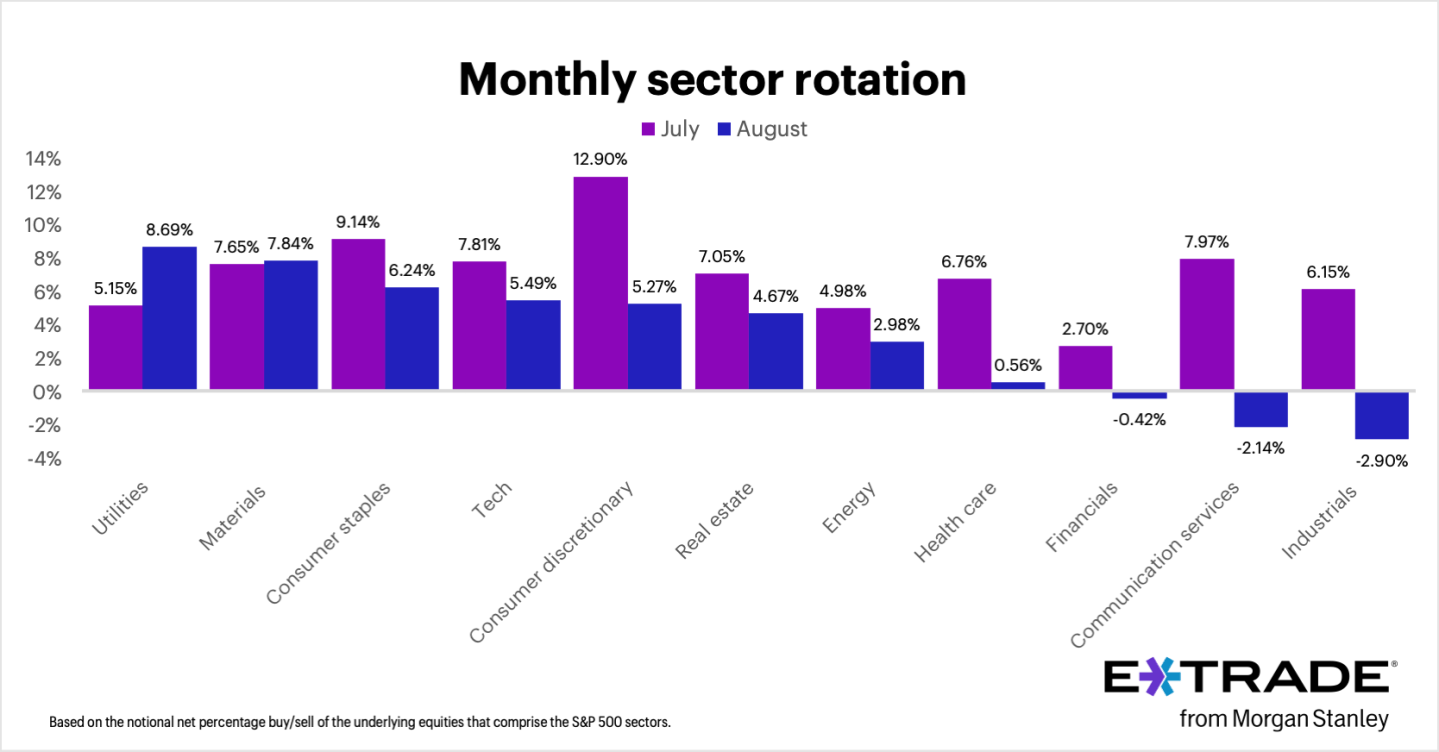
August marked the S&P 500’s fourth consecutive month of gains, with E*TRADE clients net buyers in eight out of 11 sectors, Chris Larkin, managing director of trading and investing, said in a statement. “But some of that buying was contrarian and possibly defensive,” Larkin noted. “Clients rotated most into utilities, a defensive sector that was actually the S&P 500’s weakest performer last month. Another traditionally defensive sector, consumer staples, received the third-most net buying.” By contrast, clients were net sellers in three sectors—industrials, communication services, and financials—which have been among the S&P 500’s stronger performers so far this year.
“Given September’s history as the weakest month of the year for stocks, it’s possible that some investors booked profits from recent winners while increasing positions in defensive areas of their portfolios,” Larkin added.
Going deeper
“Warren Buffett’s $57 billion face-plant: Kraft Heinz breaks up a decade after his megamerger soured” is a Fortune report by Eva Roytburg.
From the report: “Kraft Heinz, the packaged-food giant created in 2015 by Warren Buffett and Brazilian private equity firm 3G Capital, is officially breaking up. The Tuesday announcement ends one of Buffett’s highest-profile bets—and one of his most painful—as the merger that once promised efficiency and dominance instead wiped out roughly $57 billion, or 60%, in market value. Shares slid 7% after the announcement, and Berkshire Hathaway still owns a 27.5% stake.” You can read the complete report here.
Overheard
“Effective change management is the linchpin of enterprise-wide AI implementation, yet it’s often underestimated. I learned this first-hand in my early days as CEO at Sanofi.”
—Paul Hudson, CEO of global healthcare company Sanofi since September 2019, writes in a Fortune opinion piece. Previously, Hudson was CEO of Novartis Pharmaceuticals from 2016 to 2019.

Hyderabad recently hosted a vital dialogue on ‘Human at Core: Conversations on AI, Ethics and Future,’ co-organized by IILM University and The Dr Pritam Singh Foundation at Tech Mahindra, Cyberabad. Gathering prominent figures from academia, government, and industry, the event delved into the ethical imperatives of AI and human-centric leadership in a tech-driven future.
The event commenced with Sri Gaddam Prasad Kumar advocating for technology as a servant to humanity, followed by a keynote from Sri Padmanabhaiah Kantipudi, who addressed the friction between rapid technological growth and ethical governance. Two pivotal panels explored the crossroads of AI’s progress versus principle and leadership’s critical role in AI development.
Key insights emerged around empathy and foresight in AI’s evolution, as leaders like Manoj Jha and Rajesh Dhuddu emphasized. Dr. Ravi Kumar Jain highlighted the collective responsibility to steer innovation wisely, aligning technological advancement with human values. The event reinforced the importance of cross-sector collaboration to ensure technology enhances equity and dignity globally.
Ethics & Policy
IILM University and The Dr Pritam Singh Foundation Host Round Table Conference on “Human at Core” Exploring AI, Ethics, and the Future

Hyderabad (Telangana) [India], September 4: IILM University, in collaboration with The Dr Pritam Singh Foundation, hosted a high-level round table discussion on the theme “Human at Core: Conversations on AI, Ethics and Future” at Tech Mahindra, Cyberabad, on 29th August 2025. The event brought together distinguished leaders from academia, government, and industry to engage in a timely and thought-provoking dialogue on the ethical imperatives of artificial intelligence and the crucial role of human-centric leadership in shaping a responsible technological future. The proceedings began with an opening address by Sri Gaddam Prasad Kumar, Speaker, Telangana Legislative Assembly, who emphasised the need to ensure that technology remains a tool in the service of humanity. This was followed by a keynote address delivered by Sri Padmanabhaiah Kantipudi, IAS (Retd.), Chairman of the Administrative Staff College of India (ASCI), who highlighted the growing tension between technological acceleration and ethical oversight.
The event featured two significant panel discussions, each addressing the complex intersections between technology, ethics, and leadership. The first panel, moderated by Mamata Vegunta, Executive Director and Head of HR at DBS Tech India, examined the question, “AI’s Crossroads: The Choice Between Progress and Principle.” The discussion reflected on the critical junctures at which leaders must make choices that balance innovation with responsibility. Panellists, including Deepak Gowda of the Union Learning Academy, Dr. Deepak Kumar of IDRBT, Srini Vudumula of Novelis Consulting, and Gaurav Maheshwari of Signode India Limited, shared their insights on the pressing need for robust ethical frameworks that evolve alongside AI.
The second panel, moderated by Vinay Agrawal, Global Head of Business HR at Tech Mahindra, focused on the theme “Human-Centred AI: Why Leadership Matters More Than Ever.” This session brought to light the growing expectation of leaders to act not just as enablers of technological progress, but as custodians of its impact. Panellists Manoj Jha from Makeen Energy, Dr Anadi Pande from Mahindra University, Rajesh Dhuddu of PwC, and Kiranmai Pendyala, investor and former UWH Chairperson, collectively underlined the importance of empathy, accountability, and foresight in guiding AI development.
Speaking at the event, Dr Ravi Kumar Jain, Director, School of Management – IILM University Gurugram, remarked, “We are at a defining moment in human history, where the question is not merely about how fast we can innovate, but how wisely we choose to do so. At IILM, we believe in nurturing leaders who are not only competent but also conscious of their responsibilities to society.” His sentiments were echoed by Prof Harivansh Chaturvedi, Director General at IILM Lodhi Road, who affirmed the university’s continued commitment to promoting responsible leadership through dialogue, collaboration, and critical inquiry. Across both panels, there was a shared recognition that ethical leadership must keep pace with the rapid transformations driven by AI, and that collaborative efforts across sectors will be essential to ensure that innovation serves the broader goals of equity, dignity, and humanity.
The discussions concluded with a renewed call to action for academic institutions, industry leaders, and policymakers to work together in shaping a future where technology empowers without eroding core human values. In doing so, the event reaffirmed the central message behind its theme that in an increasingly digital world, it is important now more than ever to keep it human at the core.
(Disclaimer: The above press release comes to you under an arrangement with PNN and PTI takes no editorial responsibility for the same.). PTI PWR
(This content is sourced from a syndicated feed and is published as received. The Tribune assumes no responsibility or liability for its accuracy, completeness, or content.)
-

 Business6 days ago
Business6 days agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-
Tools & Platforms3 weeks ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy1 month ago
Ethics & Policy1 month agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences4 months ago
Events & Conferences4 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers2 months ago
Jobs & Careers2 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Education2 months ago
Education2 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Funding & Business2 months ago
Funding & Business2 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi
-

 Education2 months ago
Education2 months agoMacron says UK and France have duty to tackle illegal migration ‘with humanity, solidarity and firmness’ – UK politics live | Politics