Books, Courses & Certifications
Teachers From Mexico Give English Learners a Boost in Small Texas School District

Wendy Lopez Elizondo traveled more than 800 miles last year to face her biggest professional challenge — teaching in the United States. Armed with just two suitcases and far away from her Mexican home, Lopez Elizondo came to Crain Elementary School in Victoria, Texas, to work in the district’s bilingual program.
“I wanted to support bilingual students, children who, like me, speak Spanish at home. But leaving my family and comfort zone in Mexico was not easy,” said Lopez Elizondo, who had already taught for four years in Mexico.
She worried about how she would fit in with American culture, whether she would be effective in her new job, and even how well she would connect with her students. Although Lopez Elizondo has dual citizenship in the United States and Mexico, she had spent all but one year of her life in Mexico. She even worried about her English, noting that while she speaks her second language well, using it “professionally every day was intimidating at first.”
Now, nearing the end of Victoria’s school year, Lopez Elizondo calls her first year a success, highlighting a period full of acceptance, kindness, new friends, and, most importantly, effectiveness at her job.
“The students light up when they realize that I understand their language and culture. It creates a real connection,” she said.
It’s a high stakes fight to educate bilingual children in Victoria, and Texas as a whole. Because of a change in a state rule, the number of bilingual students in this small city has soared 40 percent in the last two years.
While more than 300 school districts in the state report a paucity of bilingual teachers, the situation in Victoria is even more acute. The 13,000-student district faces stiff competition for these teachers from better-paying schools in bigger cities. (Victoria is about two hours southwest of Houston and two hours southeast of San Antonio.)
Unique Exchange Program
So, three years ago Victoria created a program with the Mexican college Escuela Normal Superior de Jalisco, where school graduates could take some additional courses and apply to teach in Victoria. The program began with just one teacher two years ago, but this year Lopez Elizondo and four other teachers came to Victoria to work. Four worked at Crain’s bilingual program while the fifth worked in the district’s special education department.
Creating this program was more than a way to give the district’s growing number of bilingual students help in their home language, said Roberto Rosas, the district’s director of multilingual education. The teachers bring a “unique cultural perspective to the classroom,” helping students learn about customs, traditions, and perspectives from Mexico, he said.
Using foreign teachers isn’t new in Texas. Indeed, there are more than 200 such teachers in the state today and Victoria will add three teachers from Spain to its schools next year. What is different about Victoria’s agreement with this Guadalajara college is the two combined to create a mini-three-course program that aims to help teachers better understand education philosophy in the United States while getting candidates ready for the cultural changes they will face. This program also helps establish a potential pipeline of bilingual teachers for a district.
“Nobody is doing something like this,” Rosas said. “The international components are tricky.”
The program has been “quite appealing” to recent graduates, said Ma. Lorena Lòpez Angulo, the director of Escuela. Teachers are interested in working in a different educational landscape that emphasizes more technology, teamwork and a focus on student results.
Teachers typically use a J-1 visa from the State Department to be allowed to work in the United States. The Visiting International Teachers program allows foreign teachers to stay in the U.S. for three years with the ability to extend that stay for another two years.
“We want to do this as an exchange, not a brain drain,” Rosas said, noting that returning teachers can infuse Mexican education with some lessons learned in Victoria.
Immigration Uncertainty
But circumstances have changed since the program was created. The Trump administration has made immigration one of its biggest issues, revoking visas for more than an estimated 1,800 international students by mid-April.
The uncertainty around immigration, as well as a new superintendent in Victoria, puts the program’s future in doubt. But Rosas said all five teachers in Victoria this year will return for a second year.
While the program’s other Mexican teachers support the project and its goals, “they prefer to remain out of the public spotlight at this time,” Rosas said. Lopez Elizondo explained that at the beginning of the year, she didn’t know the other four teachers in the program. Since then, they have become friends.
“We’re going through the same thing; I can understand how they feel,” she said.
Outside of what they brought with them, the Mexican teachers all started with empty apartments, Lopez Elizondo said, but within two weeks they were stocked with furniture, mattresses, dishes and other items, thanks to donations from Victoria teachers.
“We’ve gotten a lot of help since the first minute we were here,” she added. Just getting back and forth to school proved a challenge because public transportation is scarce in Victoria. The group of five ended up carpooling with other teachers and recently two of the teachers from Mexico were able to “barely” buy a car, Lopez Elizondo said.
Lopez Elizondo said she’s been impressed with the elementary school’s students who helped her assimilate.
“My English was a little rough when I first came,” she admitted.
While most of the children she works with in fifth grade speak Spanish in their homes, she said the ones who know English better push their classmates to continue learning the new language.
Learning From Each Other
There are many differences between education in Texas and Mexico, Lopez Elizondo said, including the number of resources students in Victoria have. All these elementary students have Chromebooks and teachers in Victoria have interactive whiteboards and they receive professional development.
In Mexico, Lopez Elizondo faced classes of about 35 students each, with one group attending school from 7 a.m. to 1 p.m., while the other learners went in the afternoon. At Crain she works with about 22 students, and she frequently monitors their work through assignments and tests to keep “a lot more track” of students’ growth, she added.
Mexico emphasizes a strong teacher-led instruction model with an emphasis on structured content delivery, Lòpez Angulo said. The American education model leans to student-centered learning, critical thinking and the use of diverse resources for independent exploration, she added.
Bilingual education continues to be a growing need for both countries, however. When Texas officials mandated that school officials ask students the main language spoken in their household when enrolling, the number identified as bilingual jumped.
But Lòpez Angulo said the demand for English is rising throughout her country. Once visiting teachers finish their stint teaching in Victoria, they can use their understanding of bilingual learning to help Mexican students, she added.
Reflecting on her first year, Lopez Elizondo said the experience offered lasting cultural benefits.
“One thing that surprised me was how open and eager the students were to learn about my culture,” she said. “They love when I share traditions or stories from Mexico. It makes them feel proud of their backgrounds, too. I’ve grown; not just as a teacher, but as a person.”
Retrieval Augmented Generation (RAG) is a fundamental approach for building advanced generative AI applications that connect large language models (LLMs) to enterprise knowledge. However, crafting a reliable RAG pipeline is rarely a one-shot process. Teams often need to test dozens of configurations (varying chunking strategies, embedding models, retrieval techniques, and prompt designs) before arriving at a solution that works for their use case. Furthermore, management of high-performing RAG pipeline involves complex deployment, with teams often using manual RAG pipeline management, leading to inconsistent results, time-consuming troubleshooting, and difficulty in reproducing successful configurations. Teams struggle with scattered documentation of parameter choices, limited visibility into component performance, and the inability to systematically compare different approaches. Additionally, the lack of automation creates bottlenecks in scaling the RAG solutions, increases operational overhead, and makes it challenging to maintain quality across multiple deployments and environments from development to production.
In this post, we walk through how to streamline your RAG development lifecycle from experimentation to automation, helping you operationalize your RAG solution for production deployments with Amazon SageMaker AI, helping your team experiment efficiently, collaborate effectively, and drive continuous improvement. By combining experimentation and automation with SageMaker AI, you can verify that the entire pipeline is versioned, tested, and promoted as a cohesive unit. This approach provides comprehensive guidance for traceability, reproducibility, and risk mitigation as the RAG system advances from development to production, supporting continuous improvement and reliable operation in real-world scenarios.
Solution overview
By streamlining both experimentation and operational workflows, teams can use SageMaker AI to rapidly prototype, deploy, and monitor RAG applications at scale. Its integration with SageMaker managed MLflow provides a unified platform for tracking experiments, logging configurations, and comparing results, supporting reproducibility and robust governance throughout the pipeline lifecycle. Automation also minimizes manual intervention, reduces errors, and streamlines the process of promoting the finalized RAG pipeline from the experimentation phase directly into production. With this approach, every stage from data ingestion to output generation operates efficiently and securely, while making it straightforward to transition validated solutions from development to production deployment.
For automation, Amazon SageMaker Pipelines orchestrates end-to-end RAG workflows from data preparation and vector embedding generation to model inference and evaluation all with repeatable and version-controlled code. Integrating continuous integration and delivery (CI/CD) practices further enhances reproducibility and governance, enabling automated promotion of validated RAG pipelines from development to staging or production environments. Promoting an entire RAG pipeline (not just an individual subsystem of the RAG solution like a chunking layer or orchestration layer) to higher environments is essential because data, configurations, and infrastructure can vary significantly across staging and production. In production, you often work with live, sensitive, or much larger datasets, and the way data is chunked, embedded, retrieved, and generated can impact system performance and output quality in ways that are not always apparent in lower environments. Each stage of the pipeline (chunking, embedding, retrieval, and generation) must be thoroughly evaluated with production-like data for accuracy, relevance, and robustness. Metrics at every stage (such as chunk quality, retrieval relevance, answer correctness, and LLM evaluation scores) must be monitored and validated before the pipeline is trusted to serve real users.
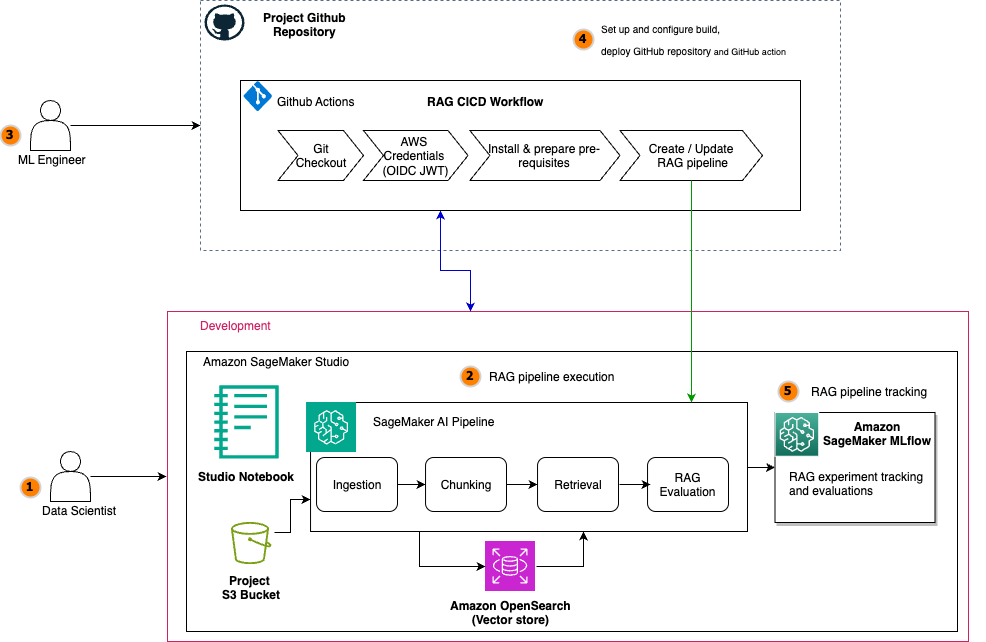
The following diagram illustrates the architecture of a scalable RAG pipeline built on SageMaker AI, with MLflow experiment tracking seamlessly integrated at every stage and the RAG pipeline automated using SageMaker Pipelines. SageMaker managed MLflow provides a unified platform for centralized RAG experiment tracking across all pipeline stages. Every MLflow execution run whether for RAG chunking, ingestion, retrieval, or evaluation sends execution logs, parameters, metrics, and artifacts to SageMaker managed MLflow. The architecture uses SageMaker Pipelines to orchestrate the entire RAG workflow through versioned, repeatable automation. These RAG pipelines manage dependencies between critical stages, from data ingestion and chunking to embedding generation, retrieval, and final text generation, supporting consistent execution across environments. Integrated with CI/CD practices, SageMaker Pipelines enable seamless promotion of validated RAG configurations from development to staging and production environments while maintaining infrastructure as code (IaC) traceability.
For the operational workflow, the solution follows a structured lifecycle: During experimentation, data scientists iterate on pipeline components within Amazon SageMaker Studio notebooks while SageMaker managed MLflow captures parameters, metrics, and artifacts at every stage. Validated workflows are then codified into SageMaker Pipelines and versioned in Git. The automated promotion phase uses CI/CD to trigger pipeline execution in target environments, rigorously validating stage-specific metrics (chunk quality, retrieval relevance, answer correctness) against production data before deployment. The other core components include:
- Amazon SageMaker JumpStart for accessing the latest LLM models and hosting them on SageMaker endpoints for model inference with the embedding model
huggingface-textembedding-all-MiniLM-L6-v2and text generation modeldeepseek-llm-r1-distill-qwen-7b. - Amazon OpenSearch Service as a vector database to store document embeddings with the OpenSearch index configured for k-nearest neighbors (k-NN) search.
- The Amazon Bedrock model
anthropic.claude-3-haiku-20240307-v1:0as an LLM-as-a-judge component for all the MLflow LLM evaluation metrics. - A SageMaker Studio notebook for a development environment to experiment and automate the RAG pipelines with SageMaker managed MLflow and SageMaker Pipelines.
You can implement this agentic RAG solution code from the GitHub repository. In the following sections, we use snippets from this code in the repository to illustrate RAG pipeline experiment evolution and automation.
Prerequisites
You must have the following prerequisites:
- An AWS account with billing enabled.
- A SageMaker AI domain. For more information, see Use quick setup for Amazon SageMaker AI.
- Access to a running SageMaker managed MLflow tracking server in SageMaker Studio. For more information, see the instructions for setting up a new MLflow tracking server.
- Access to SageMaker JumpStart to host LLM embedding and text generation models.
- Access to the Amazon Bedrock foundation models (FMs) for RAG evaluation tasks. For more details, see Subscribe to a model.
SageMaker MLFlow RAG experiment
SageMaker managed MLflow provides a powerful framework for organizing RAG experiments, so teams can manage complex, multi-stage processes with clarity and precision. The following diagram illustrates the RAG experiment stages with SageMaker managed MLflow experiment tracking at every stage. This centralized tracking offers the following benefits:
- Reproducibility: Every experiment is fully documented, so teams can replay and compare runs at any time
- Collaboration: Shared experiment tracking fosters knowledge sharing and accelerates troubleshooting
- Actionable insights: Visual dashboards and comparative analytics help teams identify the impact of pipeline changes and drive continuous improvement
The following diagram illustrates the solution workflow.
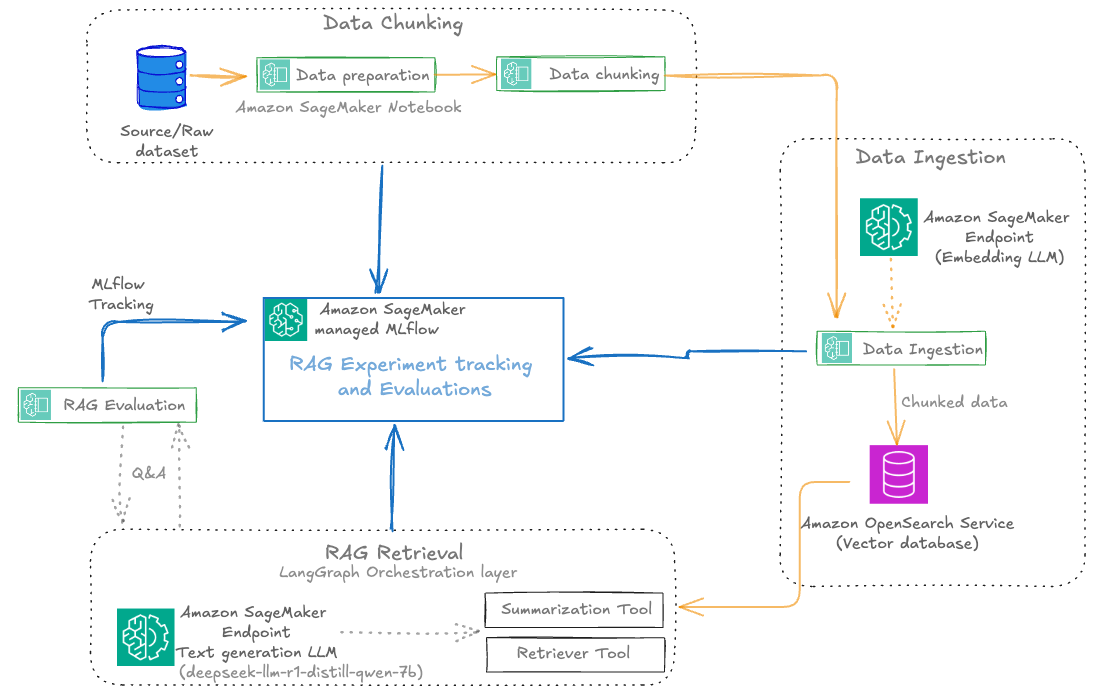
Each RAG experiment in MLflow is structured as a top-level run under a specific experiment name. Within this top-level run, nested runs are created for each major pipeline stage, such as data preparation, data chunking, data ingestion, RAG retrieval, and RAG evaluation. This hierarchical approach allows for granular tracking of parameters, metrics, and artifacts at every step, while maintaining a clear lineage from raw data to final evaluation results.
The following screenshot shows an example of the experiment details in MLflow.
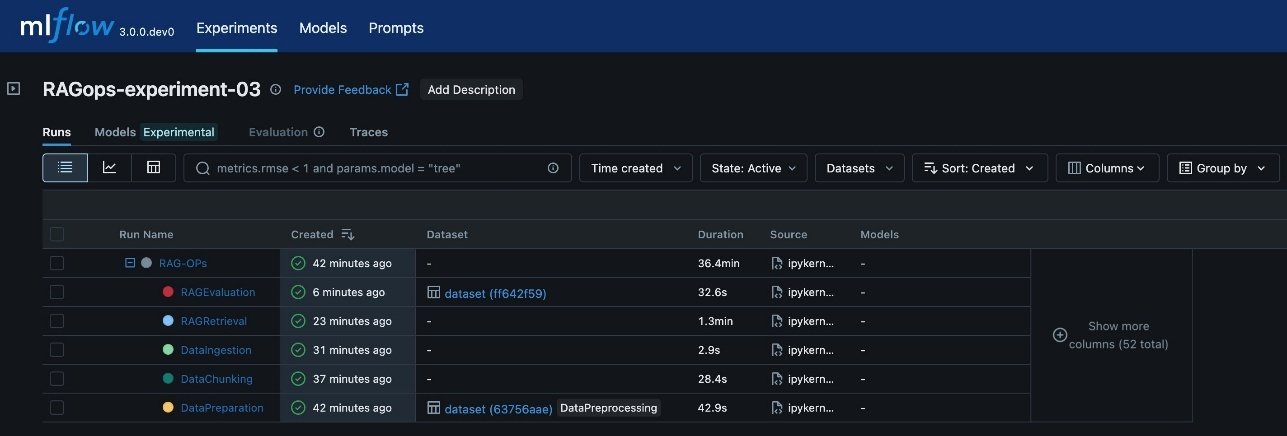
The various RAG pipeline steps defined are:
- Data preparation: Logs dataset version, preprocessing steps, and initial statistics
- Data chunking: Records chunking strategy, chunk size, overlap, and resulting chunk counts
- Data ingestion: Tracks embedding model, vector database details, and document ingestion metrics
- RAG retrieval: Captures retrieval model, context size, and retrieval performance metrics
- RAG evaluation: Logs evaluation metrics (such as answer similarity, correctness, and relevance) and sample results
This visualization provides a clear, end-to-end view of the RAG pipeline’s execution, so you can trace the impact of changes at any stage and achieve full reproducibility. The architecture supports scaling to multiple experiments, each representing a distinct configuration or hypothesis (for example, different chunking strategies, embedding models, or retrieval parameters). MLflow’s experiment UI visualizes these experiments side by side, enabling side-by-side comparison and analysis across runs. This structure is especially valuable in enterprise settings, where dozens or even hundreds of experiments might be conducted to optimize RAG performance.
We use MLflow experimentation throughout the RAG pipeline to log metrics and parameters, and the different experiment runs are initialized as shown in the following code snippet:
RAG pipeline experimentation
The key components of the RAG workflow are ingestion, chunking, retrieval, and evaluation, which we explain in this section. The MLflow dashboard makes it straightforward to visualize and analyze these parameters and metrics, supporting data-driven refinement of the chunking stage within the RAG pipeline.

Data ingestion and preparation
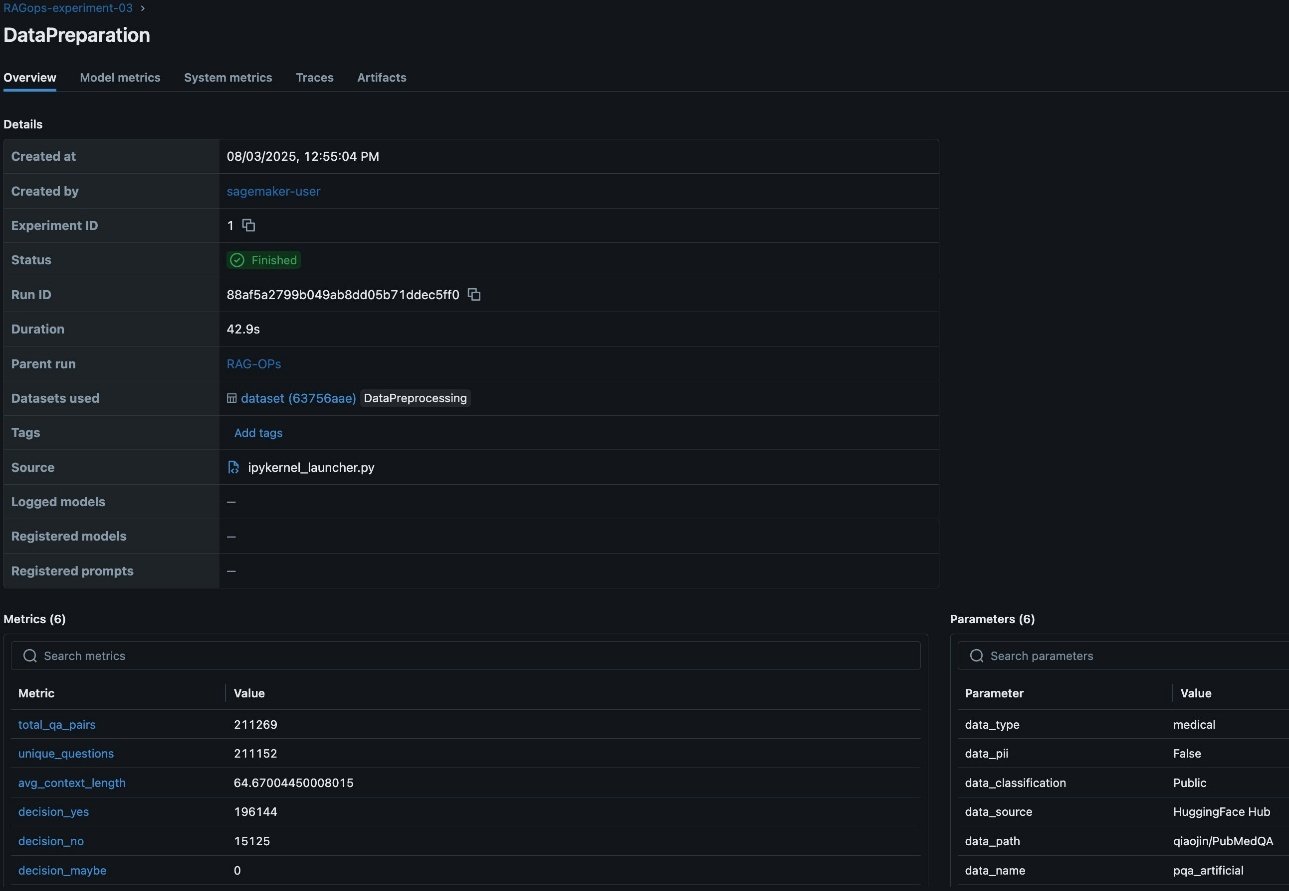
In the RAG workflow, rigorous data preparation is foundational to downstream performance and reliability. Tracking detailed metrics on data quality, such as the total number of question-answer pairs, the count of unique questions, average context length, and initial evaluation predictions, provides essential visibility into the dataset’s structure and suitability for RAG tasks. These metrics help validate the dataset is comprehensive, diverse, and contextually rich, which directly impacts the relevance and accuracy of the RAG system’s responses. Additionally, logging critical RAG parameters like the data source, detected personally identifiable information (PII) types, and data lineage information is vital for maintaining compliance, reproducibility, and trust in enterprise environments. Capturing this metadata in SageMaker managed MLflow supports robust experiment tracking, auditability, efficient comparison, and root cause analysis across multiple data preparation runs, as visualized in the MLflow dashboard. This disciplined approach to data preparation lays the groundwork for effective experimentation, governance, and continuous improvement throughout the RAG pipeline. The following screenshot shows an example of the experiment run details in MLflow.
Data chunking
After data preparation, the next step is to split documents into manageable chunks for efficient embedding and retrieval. This process is pivotal, because the quality and granularity of chunks directly affect the relevance and completeness of answers returned by the RAG system. The RAG workflow in this post supports experimentation and RAG pipeline automation with both fixed-size and recursive chunking strategies for comparison and validations. However, this RAG solution can be expanded to many other chucking techniques.
FixedSizeChunkerdivides text into uniform chunks with configurable overlapRecursiveChunkersplits text along logical boundaries such as paragraphs or sentences
Tracking detailed chunking metrics such as total_source_contexts_entries, total_contexts_chunked, and total_unique_chunks_final is crucial for understanding how much of the source data is represented, how effectively it is segmented, and whether the chunking approach is yielding the desired coverage and uniqueness. These metrics help diagnose issues like excessive duplication or under-segmentation, which can impact retrieval accuracy and model performance.
Additionally, logging parameters such as chunking_strategy_type (for example, FixedSizeChunker), chunking_strategy_chunk_size (for example, 500 characters), and chunking_strategy_chunk_overlap provide transparency and reproducibility for each experiment. Capturing these details in SageMaker managed MLflow helps teams systematically compare the impact of different chunking configurations, optimize for efficiency and contextual relevance, and maintain a clear audit trail of how chunking decisions evolve over time. The MLflow dashboard makes it straightforward to visualize and analyze these parameters and metrics, supporting data-driven refinement of the chunking stage within the RAG pipeline. The following screenshot shows an example of the experiment run details in MLflow.

After the documents are chunked, the next step is to convert these chunks into vector embeddings using a SageMaker embedding endpoint, after which the embeddings are ingested into a vector database such as OpenSearch Service for fast semantic search. This ingestion phase is crucial because the quality, completeness, and traceability of what enters the vector store directly determine the effectiveness and reliability of downstream retrieval and generation stages.
Tracking ingestion metrics such as the number of documents and chunks ingested provides visibility into pipeline throughput and helps identify bottlenecks or data loss early in the process. Logging detailed parameters, including the embedding model ID, endpoint used, and vector database index, is essential for reproducibility and auditability. This metadata helps teams trace exactly which model and infrastructure were used for each ingestion run, supporting root cause analysis and compliance, especially when working with evolving datasets or sensitive information.
Retrieval and generation
For a given query, we generate an embedding and retrieve the top-k relevant chunks from OpenSearch Service. For answer generation, we use a SageMaker LLM endpoint. The retrieved context and the query are combined into a prompt, and the LLM generates an answer. Finally, we orchestrate retrieval and generation using LangGraph, enabling stateful workflows and advanced tracing:
With the GenerativeAI agent defined with LangGraph framework, the agentic layers are evaluated for each iteration of RAG development, verifying the efficacy of the RAG solution for agentic applications. Each retrieval and generation run is logged to SageMaker managed MLflow, capturing the prompt, generated response, and key metrics and parameters such as retrieval performance, top-k values, and the specific model endpoints used. Tracking these details in MLflow is essential for evaluating the effectiveness of the retrieval stage, making sure the returned documents are relevant and that the generated answers are accurate and complete. It is equally important to track the performance of the vector database during retrieval, including metrics like query latency, throughput, and scalability. Monitoring these system-level metrics alongside retrieval relevance and accuracy makes sure the RAG pipeline delivers correct and relevant answers and meets production requirements for responsiveness and scalability. The following screenshot shows an example of the Langraph RAG retrieval tracing in MLflow.

RAG Evaluation
Evaluation is conducted on a curated test set, and results are logged to MLflow for quick comparison and analysis. This helps teams identify the best-performing configurations and iterate toward production-grade solutions. With MLflow you can evaluate the RAG solution with heuristics metrics, content similarity metrics and LLM-as-a-judge. In this post, we evaluate the RAG pipeline using advanced LLM-as-a-judge MLflow metrics (answer similarity, correctness, relevance, faithfulness):
The following screenshot shows an RAG evaluation stage experiment run details in MLflow.

You can use MLflow to log all metrics and parameters, enabling quick comparison of different experiment runs. See the following code for reference:
By using MLflow’s evaluation capabilities (such as mlflow.evaluate()), teams can systematically assess retrieval quality, identify potential gaps or misalignments in chunking or embedding strategies, and compare the performance of different retrieval and generation configurations. MLflow’s flexibility allows for seamless integration with external libraries and evaluation libraries such as RAGAS for comprehensive RAG pipeline assessment. RAGAS is an open source library that provide tools specifically for evaluation of LLM applications and generative AI agents. RAGAS includes the method ragas.evaluate() to run evaluations for LLM agents with the choice of LLM models (evaluators) for scoring the evaluation, and an extensive list of default metrics. To incorporate RAGAS metrics into your MLflow experiments, refer to the following GitHub repository.
Comparing experiments
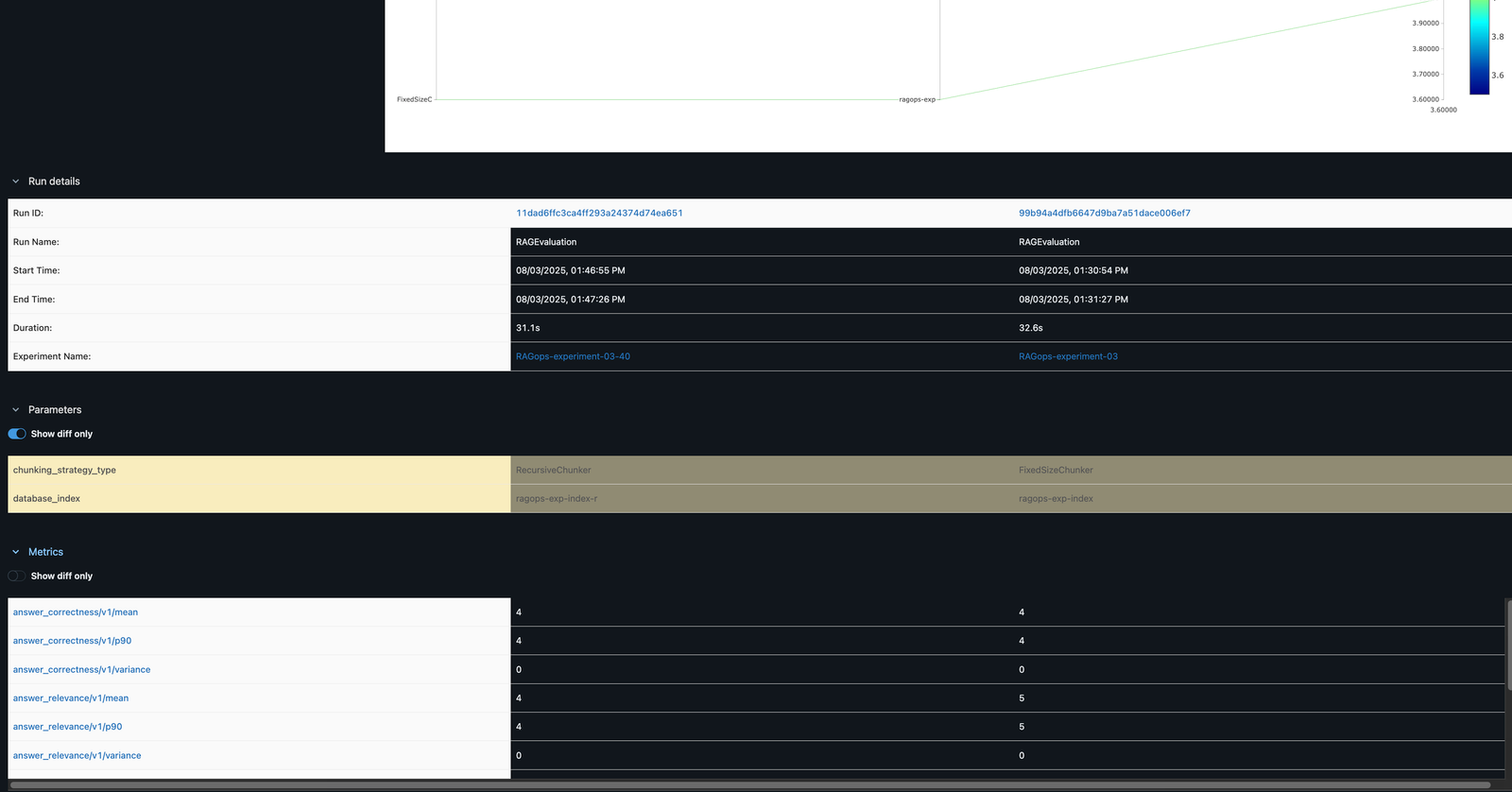
In the MLflow UI, you can compare runs side by side. For example, comparing FixedSizeChunker and RecursiveChunker as shown in the following screenshot reveals differences in metrics such as answer_similarity (a difference of 1 point), providing actionable insights for pipeline optimization.
Automation with Amazon SageMaker pipelines
After systematically experimenting with and optimizing each component of the RAG workflow through SageMaker managed MLflow, the next step is transforming these validated configurations into production-ready automated pipelines. Although MLflow experiments help identify the optimal combination of chunking strategies, embedding models, and retrieval parameters, manually reproducing these configurations across environments can be error-prone and inefficient.
To produce the automated RAG pipeline, we use SageMaker Pipelines, which helps teams codify their experimentally validated RAG workflows into automated, repeatable pipelines that maintain consistency from development through production. By converting the successful MLflow experiments into pipeline definitions, teams can make sure the exact same chunking, embedding, retrieval, and evaluation steps that performed well in testing are reliably reproduced in production environments.
SageMaker Pipelines offers a serverless workflow orchestration for converting experimental notebook code into a production-grade pipeline, versioning and tracking pipeline configurations alongside MLflow experiments, and automating the end-to-end RAG workflow. The automated Sagemaker pipeline-based RAG workflow offers dependency management, comprehensive custom testing and validation before production deployment, and CI/CD integration for automated pipeline promotion.
With SageMaker Pipelines, you can automate your entire RAG workflow, from data preparation to evaluation, as reusable, parameterized pipeline definitions. This provides the following benefits:
- Reproducibility – Pipeline definitions capture all dependencies, configurations, and executions logic in version-controlled code
- Parameterization – Key RAG parameters (chunk sizes, model endpoints, retrieval settings) can be quickly modified between runs
- Monitoring – Pipeline executions provide detailed logs and metrics for each step
- Governance – Built-in lineage tracking supports full audibility of data and model artifacts
- Customization – Serverless workflow orchestration is customizable to your unique enterprise landscape, with scalable infrastructure and flexibility with instances optimized for CPU, GPU, or memory-intensive tasks, memory configuration, and concurrency optimization
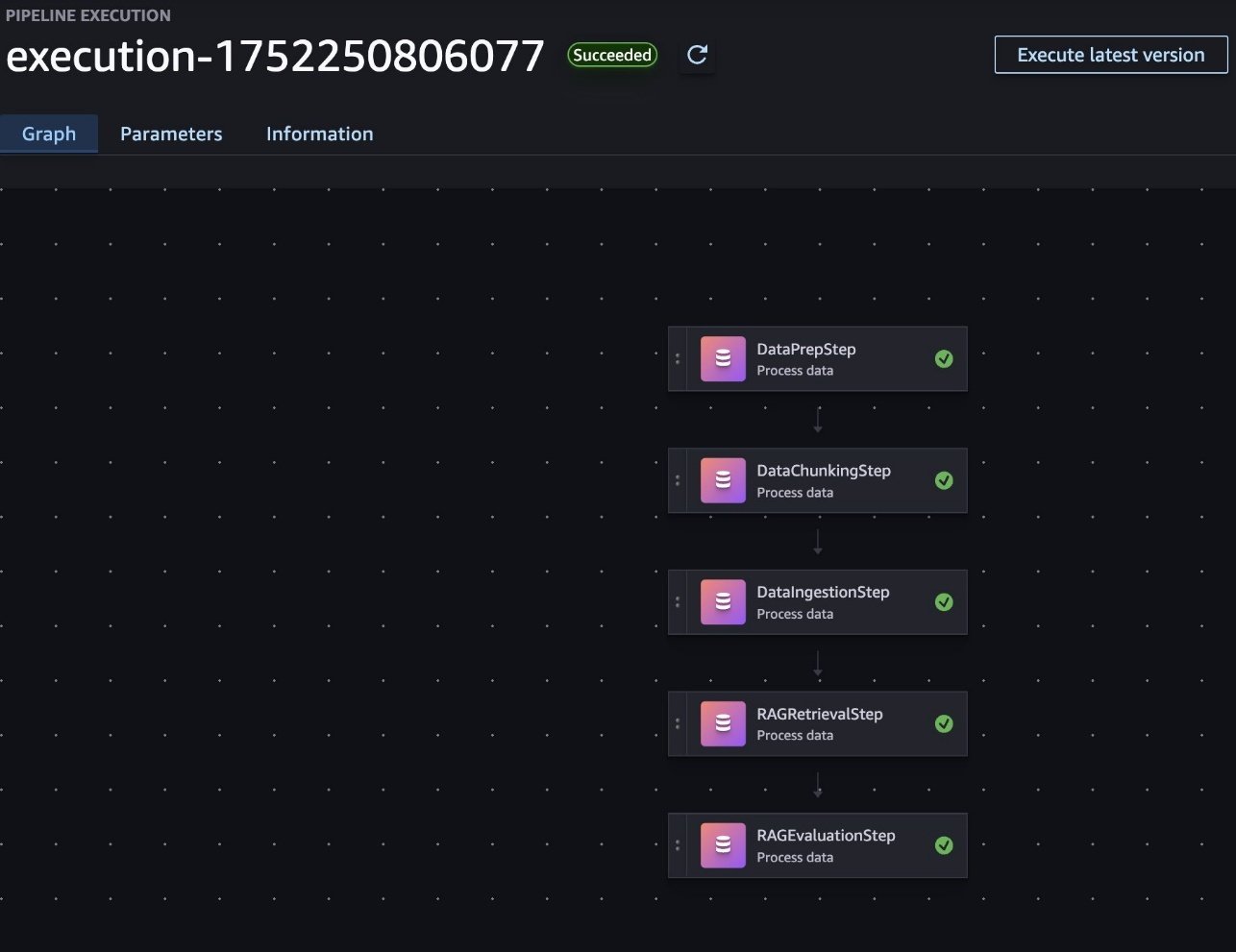
To implement a RAG workflow in SageMaker pipelines, each major component of the RAG process (data preparation, chunking, ingestion, retrieval and generation, and evaluation) is included in a SageMaker processing job. These jobs are then orchestrated as steps within a pipeline, with data flowing between them, as shown in the following screenshot. This structure allows for modular development, quick debugging, and the ability to reuse components across different pipeline configurations.
The key RAG configurations are exposed as pipeline parameters, enabling flexible experimentation with minimal code changes. For example, the following code snippets showcase the modifiable parameters for RAG configurations, which can be used as pipeline configurations:
In this post, we provide two agentic RAG pipeline automation approaches to building the SageMaker pipeline, each with own benefits: single-step SageMaker pipelines and multi-step pipelines.
The single-step pipeline approach is designed for simplicity, running the entire RAG workflow as one unified process. This setup is ideal for straightforward or less complex use cases, because it minimizes pipeline management overhead. With fewer steps, the pipeline can start quickly, benefitting from reduced execution times and streamlined development. This makes it a practical option when rapid iteration and ease of use are the primary concerns.
The multi-step pipeline approach is preferred for enterprise scenarios where flexibility and modularity are essential. By breaking down the RAG process into distinct, manageable stages, organizations gain the ability to customize, swap, or extend individual components as needs evolve. This design enables plug-and-play adaptability, making it straightforward to reuse or reconfigure pipeline steps for various workflows. Additionally, the multi-step format allows for granular monitoring and troubleshooting at each stage, providing detailed insights into performance and facilitating robust enterprise management. For enterprises seeking maximum flexibility and the ability to tailor automation to unique requirements, the multi-step pipeline approach is the superior choice.
CI/CD for an agentic RAG pipeline
Now we integrate the SageMaker RAG pipeline with CI/CD. CI/CD is important for making a RAG solution enterprise-ready because it provides faster, more reliable, and scalable delivery of AI-powered workflows. Specifically for enterprises, CI/CD pipelines automate the integration, testing, deployment, and monitoring of changes in the RAG system, which brings several key benefits, such as faster and more reliable updates, version control and traceability, consistency across environments, modularity and flexibility for customization, enhanced collaboration and monitoring, risk mitigation, and cost savings. This aligns with general CI/CD benefits in software and AI systems, emphasizing automation, quality assurance, collaboration, and continuous feedback essential to enterprise AI readiness.
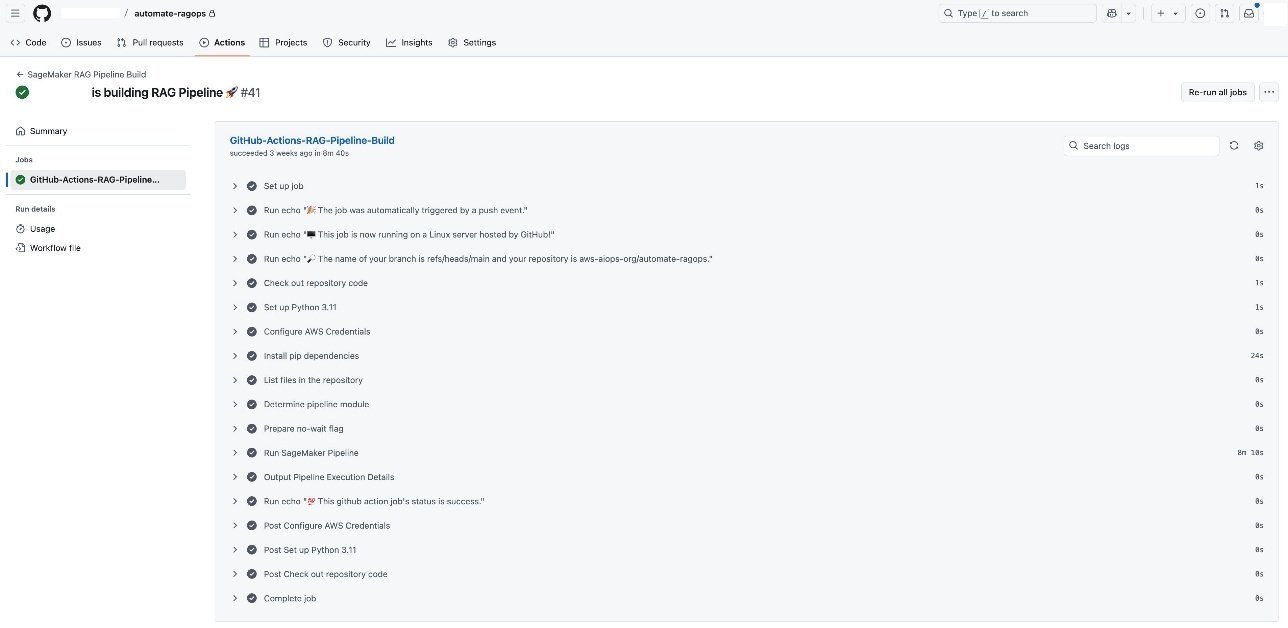
When your SageMaker RAG pipeline definition is in place, you can implement robust CI/CD practices by integrating your development workflow and toolsets already enabled at your enterprise. This setup makes it possible to automate code promotion, pipeline deployment, and model experimentation through simple Git triggers, so changes are versioned, tested, and systematically promoted across environments. For demonstration, in this post, we show the CI/CD integration using GitHub Actions and by using GitHub Actions as the CI/CD orchestrator. Each code change, such as refining chunking strategies or updating pipeline steps, triggers an end-to-end automation workflow, as shown in the following screenshot. You can use the same CI/CD pattern with your choice of CI/CD tool instead of GitHub Actions, if needed.
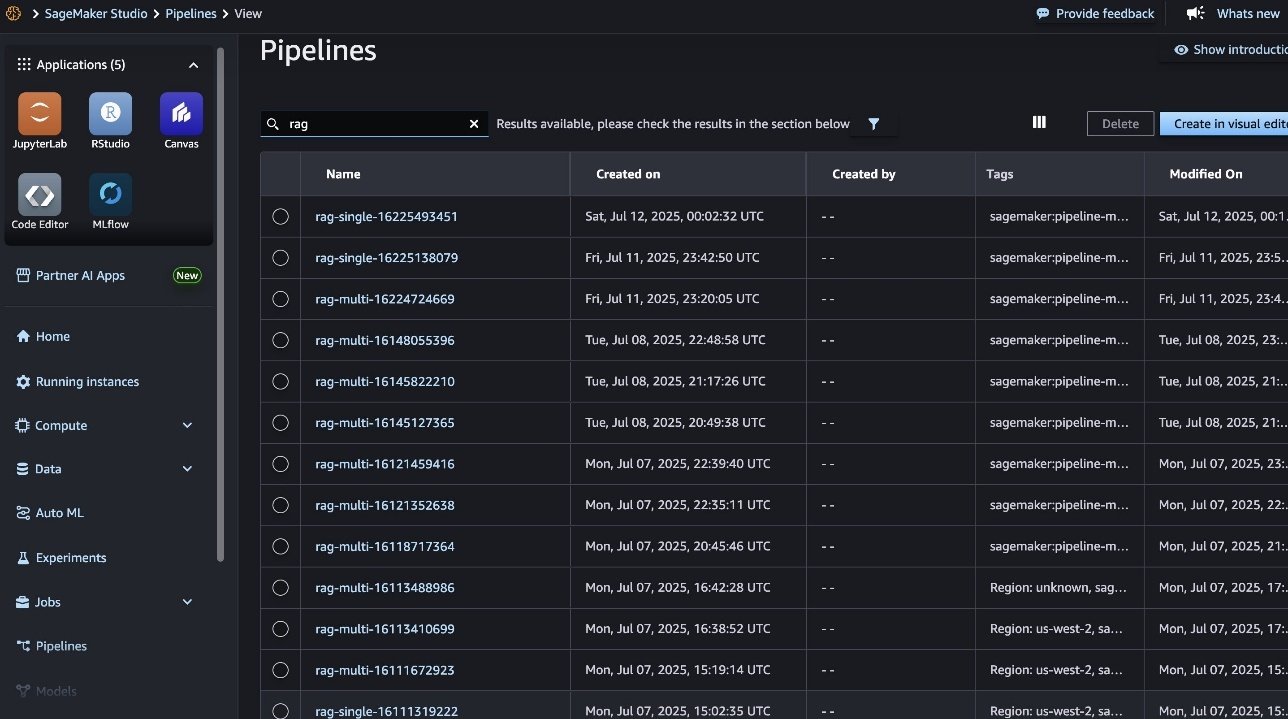
Each GitHub Actions CI/CD execution automatically triggers the SageMaker pipeline (shown in the following screenshot), allowing for seamless scaling of serverless compute infrastructure.
Throughout this cycle, SageMaker managed MLflow records every executed pipeline (shown in the following screenshot), so you can seamlessly review results, compare performance across different pipeline runs, and manage the RAG lifecycle.
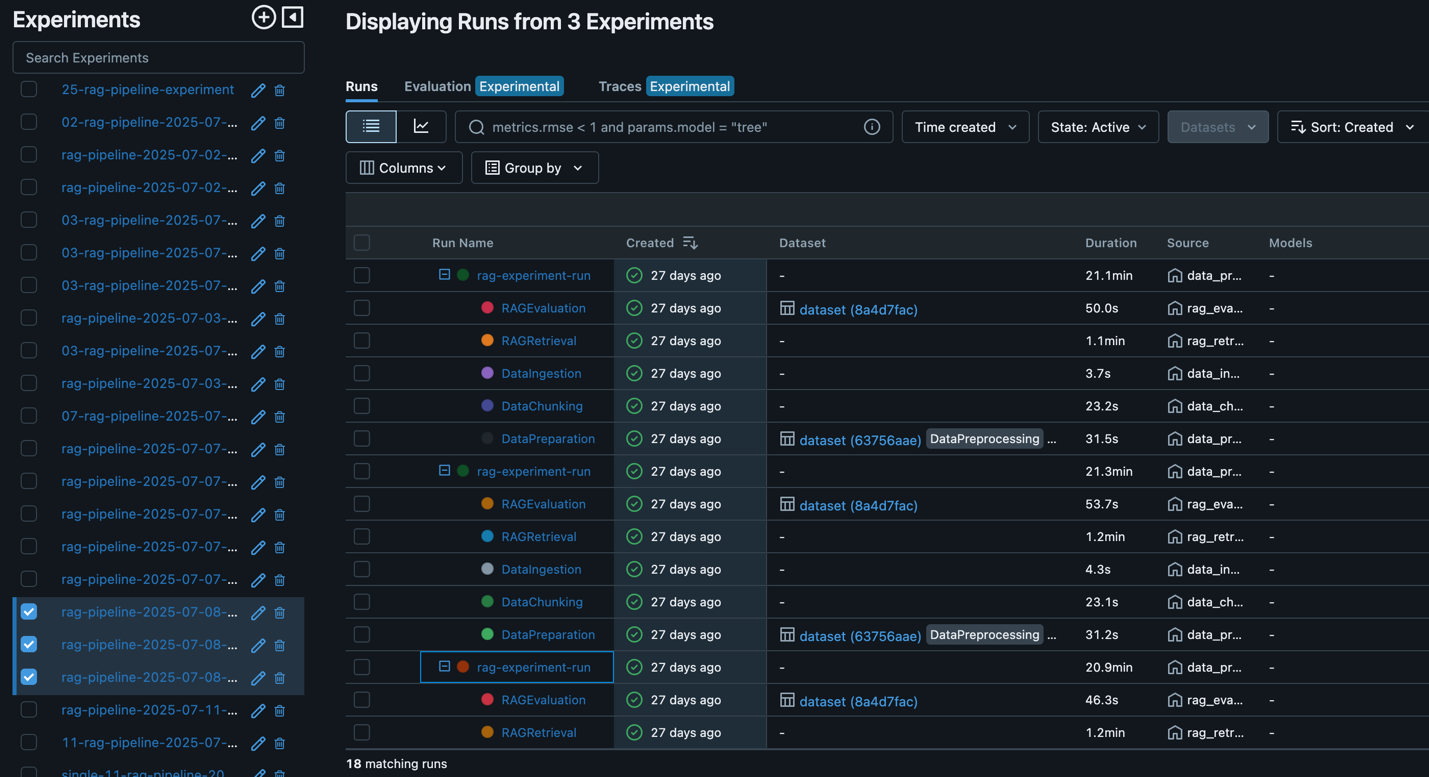
After an optimal RAG pipeline configuration is determined, the new desired configuration (Git version tracking captured in MLflow as shown in the following screenshot) can be promoted to higher stages or environments directly through an automated workflow, minimizing manual intervention and reducing risk.

Clean up
To avoid unnecessary costs, delete resources such as the SageMaker managed MLflow tracking server, SageMaker pipelines, and SageMaker endpoints when your RAG experimentation is complete. You can visit the SageMaker Studio console to destroy resources that aren’t needed anymore or call appropriate AWS APIs actions.
Conclusion
By integrating SageMaker AI, SageMaker managed MLflow, and Amazon OpenSearch Service, you can build, evaluate, and deploy RAG pipelines at scale. This approach provides the following benefits:
- Automated and reproducible workflows with SageMaker Pipelines and MLflow, minimizing manual steps and reducing the risk of human error
- Advanced experiment tracking and comparison for different chunking strategies, embedding models, and LLMs, so every configuration is logged, analyzed, and reproducible
- Actionable insights from both traditional and LLM-based evaluation metrics, helping teams make data-driven improvements at every stage
- Seamless deployment to production environments, with automated promotion of validated pipelines and robust governance throughout the workflow
Automating your RAG pipeline with SageMaker Pipelines brings additional benefits: it enables consistent, version-controlled deployments across environments, supports collaboration through modular, parameterized workflows, and supports full traceability and auditability of data, models, and results. With built-in CI/CD capabilities, you can confidently promote your entire RAG solution from experimentation to production, knowing that each stage meets quality and compliance standards.
Now it’s your turn to operationalize RAG workflows and accelerate your AI initiatives. Explore SageMaker Pipelines and managed MLflow using the solution from the GitHub repository to unlock scalable, automated, and enterprise-grade RAG solutions.
About the authors
 Sandeep Raveesh is a GenAI Specialist Solutions Architect at AWS. He works with customers through their AIOps journey across model training, generative AI applications like agents, and scaling generative AI use cases. He also focuses on Go-To-Market strategies, helping AWS build and align products to solve industry challenges in the generative AI space. You can find Sandeep on LinkedIn.
Sandeep Raveesh is a GenAI Specialist Solutions Architect at AWS. He works with customers through their AIOps journey across model training, generative AI applications like agents, and scaling generative AI use cases. He also focuses on Go-To-Market strategies, helping AWS build and align products to solve industry challenges in the generative AI space. You can find Sandeep on LinkedIn.
 Blake Shin is an Associate Specialist Solutions Architect at AWS who enjoys learning about and working with new AI/ML technologies. In his free time, Blake enjoys exploring the city and playing music.
Blake Shin is an Associate Specialist Solutions Architect at AWS who enjoys learning about and working with new AI/ML technologies. In his free time, Blake enjoys exploring the city and playing music.
Books, Courses & Certifications
Gies College of Business Wins the Coursera Trailblazer Award for Online Education: Voices of Learners at Gies

Gies College of Business at the University of Illinois has been honored with the Trailblazer Award at the September 2025 Coursera Connect conference, recognizing its bold leadership in reshaping online education. From launching the very first degree with Coursera to pioneering tools like Coursera Coach and AI avatars, Gies has consistently pushed the boundaries of what’s possible in accessible, high-quality business education.
Today, learners around the world can pursue three Gies Business master’s degrees online in conjunction with Coursera: the Master of Business Administration (iMBA), Master of Science in Management (iMSM), and Master of Science in Accountancy (iMSA), as well as access stackable open content in AI, reflecting the school’s commitment to staying innovative and meeting students wherever they are. Yet the truest reflection of this trailblazing spirit comes from its global learners whose voices showcase the impact, community, and transformative nature that define the Gies Business.
Flexible Learning for Diverse Lifestyles
Chelsea Doman, a single mother of four, found the Gies iMBA to be the perfect fit for her busy life. “When I saw Illinois had an online MBA with Coursera, it was like the heavens opened,” she says. The program’s structure allowed her to balance family, work, and studies without the need for a GMAT score. Chelsea emphasizes the value of learning for personal growth, stating, “I did it for the joy of learning, a longtime goal, a holistic business understanding.”
Similarly, Tom Fail, who pursued the iMBA while working in EdTech, appreciated the program’s blend of online flexibility and in-person networking opportunities. He notes, “With this program, you get to blend the benefits of networking and having a hands-on experience that you’d get from an in-person program, with the flexibility of an online program.”
Global Community and Real-World Application
Ishpinder Kailey, an Australia-based learner, leveraged the iMBA to transition from a background in chemistry to a leadership role in business strategy. “This degree gave me the confidence to lead my business from the front.” She also highlights the program’s global reach and collaborative environment: “The professors are exceptional, and the peer learning from a global cohort is a tremendous asset.”
Joshua David Tarfa, a Nigeria-based senior product manager who recently graduated from the 12-month MS in Management (iMSM) degree program, found immediate applicability of his coursework to his professional role. He shares, “From the very beginning, I could apply what I was learning. I remember taking a strategic management course and using concepts from it immediately at work.”
A Commitment to Lifelong Learning and Connection
For many learners, the Gies experience extends far beyond graduation. Dennis Harlow describes how the iMSA program connected him to a global network: “Even though it’s online, I felt like I was part of a community. The connections I made with peers and instructors have been amazing.” Similarly, Patrick Surrett emphasizes the flexibility and ongoing engagement of the program: “I believe in lifelong learning and this program made it possible. It truly is online by design.” Together, their experiences reflect Gies’ dedication to fostering lifelong learning and a supportive global community.
Online with Gies Business: A Degree That Works for You
Congratulations to Gies College of Business on earning the esteemed Trailblazer Award. This recognition reflects not only the school’s pioneering approach to online education but also the achievements and experiences of its learners. From balancing family and careers to pursuing personal growth and professional impact, Gies students around the world continue to thrive in a flexible, rigorous, and supportive environment. Their stories are a testament to the community, innovation, and opportunity that define what it means to learn with Gies.
Interested in an online degree with the University of Illinois Gies College of Business? Check out the programs here→

AWS Certified AI Practitioner
Amazon’s AWS Certified AI Practitioner certification validates your knowledge of AI, machine learning (ML), and generative AI concepts and use cases, as well as your ability to apply those in an enterprise setting. The exam covers the fundamentals of AI and ML, generative AI, applications of foundation models, and guidelines for responsible use of AI, as well as security, compliance, and governance for AI solutions. It’s targeted at business analysts, IT support professionals, marketing professionals, product and project managers, line-of-business or IT managers, and sales professionals. It’s an entry-level certification and there are no prerequisites to take the exam.
Cost: $100
Certified Generative AI Specialist (CGAI)
Offered through the Chartered Institute of Professional Certifications, the Certified Generative AI Specialist (CGAI) certification is designed to teach you the in-depth knowledge and skills required to be successful with generative AI. The course covers principles of generative AI, data acquisition and preprocessing, neural network architectures, natural language processing (NLP), image and video generation, audio synthesis, and creative AI applications. On completing the learning modules, you will need to pass a chartered exam to earn the CGAI designation.
-

 Business2 weeks ago
Business2 weeks agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-
Tools & Platforms1 month ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy2 months ago
Ethics & Policy2 months agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences4 months ago
Events & Conferences4 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers2 months ago
Jobs & Careers2 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Education2 months ago
Education2 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Education2 months ago
Education2 months agoMacron says UK and France have duty to tackle illegal migration ‘with humanity, solidarity and firmness’ – UK politics live | Politics
-

 Funding & Business2 months ago
Funding & Business2 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi