Connect with us



The first draft of this blog post was generated by Amazon Nova Pro, based on detailed instructions from Amazon Science editors and multiple examples of prior...
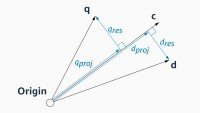
Many machine learning (ML) applications involve embedding data in a representation space, where the geometric relationships between embeddings carry semantic content. Performing a useful task often...


Vision-language models, which map images and text to a common representational space, have demonstrated remarkable performance on a wide range of multimodal AI tasks. But they’re...


Recent foundation models — such as large language models — have achieved state-of-the-art performance by learning to reconstruct randomly masked-out text or images. Without any human...


Many recent advances in artificial intelligence are the result of representation learning: a machine learning model learns to represent data items as vectors in a multidimensional...



Amazon’s papers at this year’s International Conference on Computer Vision, organized by topic. 3-D HAL3D: Hierarchical active learning for fine-grained 3D part labelingFenggen Yu, Yiming Qian,...



At this year’s Conference on Computer Vision and Pattern Recognition (CVPR), Prime Video presented four papers that indicate the broad range of cutting-edge problems we work...


Amazon’s contributions to this year’s European Conference on Computer Vision (ECCV) reflect the diversity of the company’s research interests. Below is a quick guide to the...



This year, the Amazon Search team had two papers accepted at the Conference on Computer Vision and Pattern Recognition (CVPR), both focusing on image-text feature alignment,...


Graphs are an information-rich way to represent data. A graph consists of nodes — typically represented by circles — and edges — typically represented as line...