Ethics & Policy
Salmon in the Loop

One of the most fascinating problems that a computer scientist may be lucky enough to encounter is a complex sociotechnical problem in a field going through the process of digital transformation. For me, that was fish counting. Recently, I worked as a consultant in a subdomain of environmental science focused on counting fish that pass through large hydroelectric dams. Through this overarching project, I learned about ways to coordinate and manage human-in-the-loop dataset production, as well as the complexities and vagaries of how to think about and share progress with stakeholders.
Background
Let’s set the stage. Large hydroelectric dams are subject to Environmental Protection Act regulations through the Federal Energy Regulatory Commission (FERC). FERC is an independent agency of the United States government that regulates the transmission and wholesale sale of electricity across the United States. The commission has jurisdiction over a wide range of electric power activities and is responsible for issuing licenses and permits for the construction and operation of hydroelectric facilities, including dams. These licenses and permits ensure that hydroelectric facilities are safe and reliable, and that they do not have a negative impact on the environment or other stakeholders. In order to obtain a license or permit from FERC, hydroelectric dam operators must submit detailed plans and studies demonstrating that their facility meets regulations. This process typically involves extensive review and consultation with other agencies and stakeholders. If a hydroelectric facility is found to be in violation of any set standards, FERC is responsible for enforcing compliance with all applicable regulations via sanctions, fines, or lease termination–resulting in a loss of the right to generate power.
Hydroelectric dams are essentially giant batteries. They generate power by building up a large reservoir of water on one side and directing that water through turbines in the body of the dam. Typically, a hydroelectric dam requires lots of space to store water on one side of it, which means they tend to be located away from population centers. The conversion process from potential to kinetic energy generates large amounts of electricity, and the amount of pressure and force generated is disruptive to anything that lives in or moves through the waterways—especially fish.
It is also worth noting that the waterways were likely disrupted substantially when the dam was built, leading to behavioral or population-level changes in the fish species of the area. This is of great concern to the Pacific Northwest in particular, as hydropower is the predominant power generation means for the region (Bonneville Power Administration). Fish populations are constantly moving upstream and downstream and hydropower dams can act as barriers that block their passage, leading to reduced spawning. In light of the risks to fish, hydropower dams are subject to constraints on the amount of power they can generate and must show that they are not killing fish in large numbers or otherwise disrupting the rhythms of their lives, especially because the native salmonid species of the region are already threatened or endangered (Salmon Status).
To demonstrate compliance with FERC regulations, large hydroelectric dams are required to routinely produce data which shows that their operational activities do not interfere with endangered fish populations in aggregate. Typically, this is done by performing fish passage studies. A fish passage study can be conducted many different ways, but boils down to one primary dataset upon which everything is based: a fish count. Fish are counted as they pass through the hydroelectric dam, using structures like fish ladders to make their way from the reservoir side to the stream side.

Fish counts can be conducted visually—-a person trained in fish identification watches the fish pass, incrementing the count as they move upstream. As a fish is counted, observers impart additional classifications outside of species of fish, such as whether there was some kind of obvious illness or injury, if the fish is hatchery-origin or wild, and so on. These differences between fish are subtle and require close monitoring and verification, since the attribute in question (a clipped adipose fin, a scratched midsection) may only be visible briefly when the fish swims by. As such, fish counting is a specialized job that requires expertise in identifying and classifying different species of fish, as well as knowledge of their life stages and other characteristics. The job is physically demanding, as it typically involves working in remote locations away from city centers, and it can be challenging to perform accurately under the difficult environmental conditions found at hydroelectric dams–poor lighting, unregulated temperatures, and other circumstances inhospitable to humans.
These modes of data collection are great, but there are varying degrees of error that could be imparted through their recording. For example, some visual fish counts are documented with pen and paper, leading to incorrect counts through transcription error; or there can be disputes about the classification of a particular species. Different dam operators collect fish counts with varying degrees of granularity (some collect hourly, some daily, some monthly) and seasonality (some collect only during certain migration patterns called “runs”). After collection and validation, organizations correlate this data with operational information produced by the dam in an attempt to see if any activities of the dam have an adverse or beneficial effect on fish populations. Capturing these data piecemeal with different governing standards and levels of detail causes organizations to look for new efficiencies enabled by technology.
Enter Computer Vision
Some organizations are exploring the use of computer vision and machine learning to significantly automate fish counting. Since dam operators subject to FERC are required to collect fish passage data anyway, and the data were previously produced or encoded in ways that were challenging to work with, an interesting “human-in-the-loop” machine learning system arises. A human-in-the-loop system combines the judgment and expertise of subject-matter expert humans (fish biologists) with the consistency and reliability of machine learning algorithms, which can help to reduce sources of error and bias in the output dataset used in the machine learning system. For the specific problem of fish counting, this could help to ensure that the system’s decisions are informed by the latest scientific understanding of fish taxonomy and conservation goals, and could provide a more balanced and comprehensive approach to species or morphological classification. An algorithmic system could reduce the need for manual data collection and analysis by automating the process of identifying and classifying species, and could provide more timely and accurate information about species’ health.
Building a computer vision system for a highly-regulated industry, such as hydropower utilities, can be a challenging task due to the need for high accuracy and strict compliance with regulatory standards. The process of building such a system would typically involve several steps:
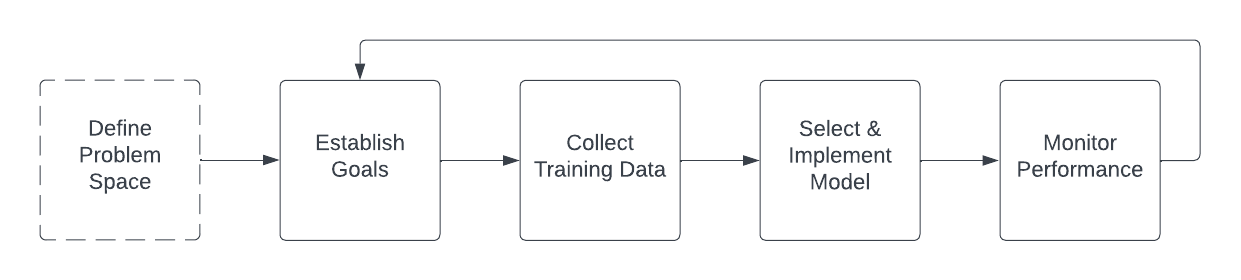
1. Define the problem space: Before starting to build the system, it is important to clearly define the problem that the system is intended to solve and the goals that it needs to achieve. This initial negotiation process is largely without any defining technical constraints, and is based around the job to that needs to be done by the system: identifying specific tasks that the system needs to perform, such as identification of the species or life stage of a fish. This may be especially challenging in a regulated industry like hydropower, as clients are subject to strict laws and regulations that require them to ensure that any tools or technologies they use are reliable and safe. They may be skeptical of a new machine learning system and may require assurances that it has been thoroughly tested and will not pose any risks to the environment or to through data integrity, algorithmic transparency, and accountability.
Once the problem space is defined, more technical decisions can be made about how to implement the solution. For example, if the goal is to estimate population density during high fish passage using behavioral patterns such as schooling, it may make sense to capture and tag live video, to see the ways in which fish move in real time. Alternatively, if the goal is to identify illness or injury in a situation where there are few fish passing, it may make sense to capture still images and tag subsections of them to train a classifier. In a more developed hypothetical example, perhaps dam operators know that the fish ladder only allows fish to pass through it, all other species or natural debris are filtered out, and they want a “best guess” about rare species of fish that pass upstream. It may be sufficient in this case to implement generic video-based object detection to identify that a fish is moving through a scene, take a picture of it at a certain point, and provide that picture to a human to tag with the species. Once tagged, these data can be used to train a classifier which categorizes fish as being the rare species or not.
2. Establish performance goals: The definition of the problem space and the initial suggested process flow should be shared with all stakeholders as an input to the performance goals. This helps ensure all interested parties understand the problem at a high level, and what is possible for a given implementation. Practically, most hydropower utilities are interested in automated fish count solutions that meet an accuracy threshold of 95% as compared to a regular human visual count, but expectations around whether these metrics are achievable and at what part of the production cycle will be a highly negotiated series of points. Establishing these goals is a true sociotechnical problem, as it cannot be done without taking into account both the real-world constraints that limit the data and the system. These constraining factors will be discussed later in the Obstacles section of the paper.
3. Collect and label training data: In order to train a machine learning model to perform the tasks required by the system, it is first necessary to produce a training dataset. Practically, this involves collecting a large number of fish images. The images are annotated with the appropriate species classification labels by a person with expertise in fish classification. The annotated images are then used to train a machine learning model. Through training, the algorithm learns the features characteristic of each subclass of fish and identifies those features to classify fish in new, unseen images. Because the end goal of this system is to minimize the counts that humans have to do, images with a low “confidence score” (a metric commonly produced by object-detection models) may be flagged for identification and tagging by human reviewers. The more seamless an integration with a production fish counting operation, the better.
4. Select a model: Once the training data has been collected, the next step is to select a suitable machine learning model and train it on the data. This could involve using a supervised learning approach, where the model is trained to recognize the different categories of fish after being shown examples of labeled data. At the time of this writing, deep learning systems based on pretrained models like ImageNet are popular choices. Once trained, the model should be validated against tagged data that it has not seen before and fine-tuned by adjusting the model parameters or refining the training dataset and retraining.
5. Monitor system performance: Once the model has been trained and refined, it can be implemented as part of a computer vision system for regular use. The system’s performance should be monitored regularly to ensure that it is meeting the required accuracy targets and to ensure that model drift does not occur, perhaps from changes in environmental conditions, such as water clarity; or morphological changes alluded to in a later section
It is at this point that the loop of tasks begins anew; to eke out more performance from the system, it is likely that more refined and nuanced negotiation about what to expect from the system is necessary, followed by additional training data, model selection, and parameter tuning/monitoring. The common assumption is that an automated or semiautomatic system like this is “set it and forget it” but the process of curating and collating datasets or tuning hyper parameters is quite engaged and intentional.
Obstacles
In order for the computer vision algorithm to accurately detect and count fish in images or video frames, it must be trained on a large and diverse dataset that includes examples of different fish species and morphologies. However, this approach is not without challenges, as specified in the diagram below and with bolded phrases in subsequent paragraphs:
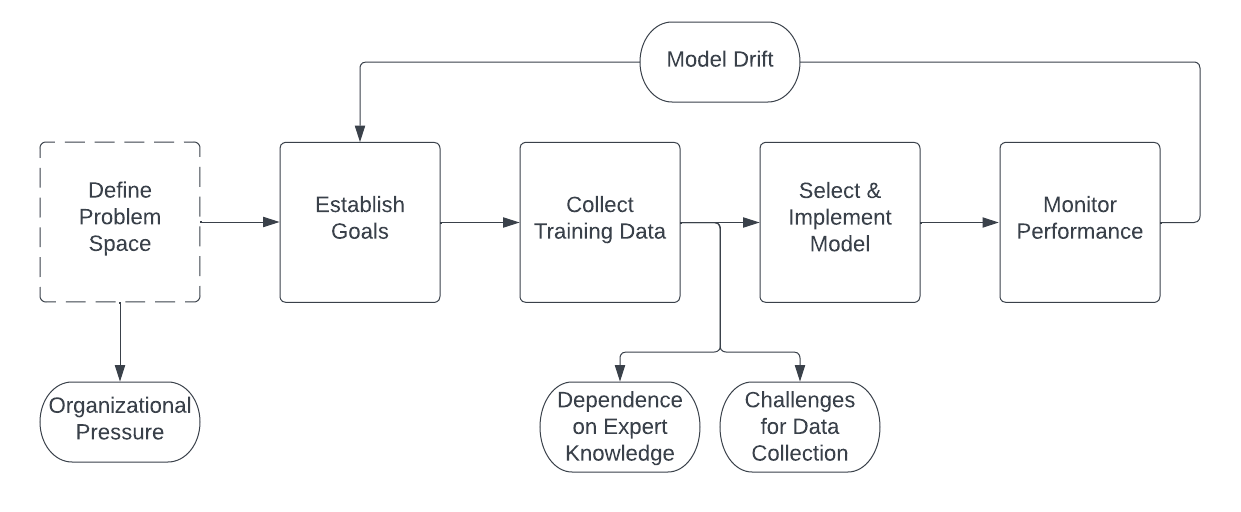
Dependence on expert knowledge is a concern worth discussing. If the system relies on expert-tagged data to train and evaluate its algorithms, the system may be vulnerable to errors and biases in the expert’s knowledge and judgments, as any human-in-the-loop system would be. For example, if the experts are not familiar with certain species or morphologies, they may not be able to accurately tag these fish, which could lead to incorrect classifications by the system. Should an invasive species enter the waterway, it may become overrepresented within the dataset and affect the counts of the species that require conservation action. An excellent practical example of this is American shad, of which hundreds of thousands can pass during a migratory period, obscuring the Chinook salmon that are also passing during the same time. Manual counting methods rely solely on the judgment and observation of individual humans, which can be subject to a variety of sources of error and bias. Further, if the experts have a particular interest in certain species or morphologies, they may be more likely to tag these fish, which could result in over- or under-representation within the dataset. This can lead to life-threatening outcomes if the algorithmic system is used to make important decisions that have conservation implications.
Environmental conditions at hydroelectric dams present challenges for data collection as well. Inadequate illumination and poor image quality can make it difficult for both humans and machine learning algorithms to accurately classify fish. Similarly, changing conditions, like a reduction in water clarity following a seasonal snowmelt can obscure fish in imagery. Migratory fish can be difficult to identify and classify on their own terms, due to the wide range of species and subspecies that exist, and the way their bodies change as they age. These fish are often difficult to study and monitor due to their migratory habits and the challenging environments in which they live. Further, there are often inconsistent data taxonomies produced across organizations, leading to different classifications depending on the parent organization undertaking the data tagging process. If humans cannot create accurate classifications to populate the initial dataset, the machine learning system will not be able to accurately produce predictions when used in production.

One of the key challenges of using a machine learning classifier on unaudited data is the risk of model drift, in which the model’s performance degrades over time as the underlying data distribution changes. This may be of particular concern in a highly regulated environment, where even small changes in the model’s performance could have significant consequences. The datasets produced through the effort of tagging fish images are fascinating because they are so intrinsically place-based, situated, and not easily replicable. Fish passage studies often involve monitoring a relatively small number of fish, which can make it difficult to accurately assess the overall profile of fish populations in the wider area. The number and types of fish that pass through a dam’s fish ladders or other fish passage structures can vary greatly depending on the time of year or the “run” of fish passing through the waterways. This can make it difficult to compare data from different studies, or to draw conclusions about the long-term impact of the dam on fish populations. If the system is trained on a dataset of fish that has been tagged by subject-matter experts during one season, the dataset may not be comprehensive or representative of the full range of fish species and morphologies that exist in the wild across the full year. This could lead to under- or over-estimations of number and types of fish present in a given area. In this way, the specter of model drift is actually a problem composed of both challenging data production constraints and dependence on expert knowledge.
Finally, there are background labor issues to be dealt with as part of this problem space coming from intense organizational pressure. Fish counting is a cost center that hydroelectric dam operators would like to eliminate or reduce as much as possible. A technical solution that can accurately count fish is therefore very appealing. However, this raises concerns about ghost work, where human labor is used to train and validate the model, but is not acknowledged or compensated. Replacing human workers with a computer vision solution may significantly impact the displaced workers through financial hardship or the obsoletion of their job skills and expertise. If human expertise in the identification of fish is lost, this could lead to suboptimal decisions about species conservation, and could ultimately undermine the effectiveness of the system. This becomes more dangerous for conservation purposes if the technology is implemented as a cost-reduction measure: it could be the case that—when the model drifts—there are no taggers to set it back on track.
Couple all of these points with the longitudinal decline of wild fish populations globally, and you have a challenging set of conditions to attempt to generalize from.
If the available training data is limited or does not accurately reflect the diversity of fish species and morphologies that pass through the dam’s fish passage structures, the accuracy of the algorithm may be reduced. Additionally, there are concerns about data leakage, where the model may be able to infer sensitive information about the fish from the images, such as how they are routed through the dam. Thinking about studies that happen in fisheries as per Hwang (2022), the populations analyzed are so small and the outcomes so intentionally so narrowly-scoped, it is almost the case that an organization would have to at the very least train a one-off model for each project or validate the output of each ML classifier against some additional source, which is lately outside of the interest and capabilities of organizations who hope to reduce labor outlays as part of the implementation of a system like this.
Concluding Thoughts
The sociotechnical problem of fish counting is a niche problem with wide applications. If properly implemented, a machine learning system based around fish counts has the potential to be applied in many different places, such as meeting environmental regulation or aquaculture. The rapid digital transformation of environmental science has led to the development of novel datasets with interesting challenges, and a new cohort of professionals with the data literacy and technical abilities to work on problems like this. However, building a dataset of anadromous and catadromous fish that are protected under the ESA is a complex and challenging task, due to the limited availability of data, the complexity of fish taxonomy, the involvement of multiple stakeholders, and the dynamic environment in which these species live.
Moreover, organizations subject to regulation may be unsure of how to validate the accuracy of a machine learning model, and may be more interested in fish counts than in fish images (or vice-versa). Bringing new technologies to bear on an organization or on a dataset that was not as robustly cataloged means there will be new things to be discovered or measured through the application of the technology. Since implementation of a computer vision system like this is done to meet compliance with FERC regulations, it means bringing multiple different stakeholders–including federal agencies, state and local governments, conservation organizations, and members of the public–into dialogue with one another when changes are required. By conducting these studies and regularly reporting the results to FERC, a hydroelectric dam operator could demonstrate that they are taking steps to minimize the impact of the dam on fish populations, and that the dam is not having a negative impact on the overall health of the local fish population, but it also means cross-checking with the community in which they are situated.
Author Bio
Kevin McCraney is a data engineer, educator, and consultant. He works with public sector & large-scale institutions building data processing infrastructure & improving data literacy. Kevin has several years of experience teaching & mentoring early career professionals as they transition to technology from non-STEM disciplines. Working predominantly with institutions in the Pacific Northwest, he enjoys professional opportunities where he can combine a humanistic worldview and technical acumen to solve complex sociotechnical problems.
Citation
For attribution of this in academic contexts or books, please cite this work as:
Kevin McCraney, “Salmon in the Loop“, The Gradient, 2023.
BibTeX citation
@article{k2023omccraney,
author = {McCraney, Kevin},
title = {Salmon in the Loop},
journal = {The Gradient},
year = {2023},
howpublished = {\url{https://thegradient.pub/salmon-in-the-loop}},
}
Works Cited
[1]Bonneville Power Administration. (n.d.). Hydropower impact. Hydropower Impact. Retrieved January 14, 2023, from https://www.bpa.gov/energy-and-services/power/hydropower-impact
[2]Delgado, K. (2021, July 19). That sounds fishy: Fish ladders at high-head dams impractical, largely unneeded. www.army.mil. Retrieved January 3, 2023, from https://www.army.mil/article/248558/that_sounds_fishy_fish_ladders_at_high_head_dams_impractical_largely_unneeded
[3]Hwang, I. (2022, May 31). Salmon hatchery data is harder to handle than you think. ProPublica. Retrieved December 10, 2023, from https://www.propublica.org/article/salmon-hatcheries-pnw-fish-data
[4]Salmon status. State of Salmon. (2021, January 11). Retrieved December 29, 2022, from https://stateofsalmon.wa.gov/executive-summary/salmon-status/
[5]How hydroelectric power works. Tennessee Valley Authority. (2021, January 11). Retrieved December 29, 2022, from https://www.tva.com/energy/our-power-system/hydroelectric/how-hydroelectric-power-works

Welcome to The AI Ethics Brief, a bi-weekly publication by the Montreal AI Ethics Institute. We publish every other Tuesday at 10 AM ET. Follow MAIEI on Bluesky and LinkedIn.
-
We examine how AI-powered immigration enforcement is expanding surveillance capabilities while civil liberties protections are quietly stripped away, raising fundamental questions about democratic oversight and predictive policing.
-
AI-generated disinformation in the Israel-Iran conflict shows how chatbots are becoming unwitting participants in spreading false narratives, marking the first major global conflict where generative AI actively shapes public (mis)understanding in real-time.
-
A federal judge’s ruling that AI training constitutes fair use signals a major win for tech companies, but institutional chaos around copyright enforcement reflects deeper questions about who controls cultural production in the AI era.
-
The hiring process is becoming an “AI versus AI” arms race where algorithmic efficiency is pushing humans out of recruitment while discriminating against marginalized groups, turning job applications into a meaningless numbers game.
-
In our AI Policy Corner series with the Governance and Responsible AI Lab (GRAIL) at Purdue University, we compare Texas and New York’s divergent approaches to AI governance, highlighting the tension between innovation-focused regulatory sandboxes and civil rights-centred accountability frameworks.
-
We explore red teaming as critical thinking, examining how this approach must evolve beyond technical adversarial testing to become an embedded, cross-functional exercise that proactively identifies system failures across the entire AI lifecycle.
-
Finally, we dive into Sovereign Artificial Intelligence, unpacking the geopolitical push for national AI control and the delicate balance between protecting domestic interests and maintaining international cooperation in AI development.
This month’s passage of the “Big Beautiful Bill” in the U.S. includes more than $100 billion in new funding for Immigration and Customs Enforcement (ICE). It also signals a broader shift in how state power is being exercised and expanded through digital infrastructure. At the same time, the proposed AI moratorium was quietly removed from the bill. While some lawmakers suggest it could return in the future, the current policy direction clearly points toward a greater use of AI-driven tools in enforcement, including AI-powered monitoring, biometric data collection, and sentiment analysis, all with limited oversight.
As highlighted by reporting from Truthout and the Brennan Center for Justice, ICE is now contracting private firms to monitor social media for signs of criticism against the agency, its personnel, and its operations. A recent Request for Information (RFI) from the Department of Homeland Security outlined plans to deploy technology that could track up to a million people using sources such as blockchain activity, geolocation data, international trade logs, dark web marketplaces, and social media. The goal is to identify potentially criminal or fraudulent behaviour before any action takes place.
While proponents argue that predictive systems can help agencies allocate limited resources more effectively and identify genuine security threats, this shift from responsive enforcement to preemptive risk modelling raises serious concerns. AI-powered systems trained on past patterns and proprietary datasets are often biased and rarely neutral. They embed assumptions about what is threatening, who is suspicious, and where risks might emerge, which Virginia Eubanks in her book “Automating Inequality: How High-Tech Tools Profile, Police and Punish the Poor,” covers extensively. When applied at scale, predictive systems blur the lines between law enforcement and population surveillance. People may be flagged not for what they have done, but for how their data fits a statistical profile.
Civil liberties are often the first casualty of predictive systems. In this case, freedom of speech, movement, and assembly are at risk. These tools can deter people from participating in protests or speaking out, especially if they are aware that their actions are being monitored and recorded. Historically marginalized groups are likely to bear the brunt of these systems, particularly when the algorithms lack transparency or meaningful forms of redress.
This isn’t uniquely an American phenomenon. As companies like Palantir in the U.S. and Cohere in Canada continue to secure government contracts to supply AI tools for national security and intelligence purposes, similar dynamics are emerging across democratic nations. In New York, protesters recently blockaded Palantir’s offices, denouncing the company’s role in enabling ICE deportations and its work with the Israeli military. These actions were collectively described as examples of “totalitarian police surveillance.” The boundaries between civic technology and surveillance infrastructure are becoming increasingly difficult to distinguish globally, raising questions about whether democratic institutions can effectively govern these tools.
Recent developments in pedestrian tracking systems also illustrate how scalable authoritarian surveillance is becoming. As noted recently in Import AI 419, researchers from Fudan University in China have developed CrowdTrack, a dataset and benchmark for using AI to track pedestrians in video feeds. Comprising 33 videos with over 40,000 distinct image frames and more than 700,000 annotations, CrowdTrack features over 5,000 individual trajectories that demonstrate how AI can identify people based not only on facial features but also on gait, body shape, and movement, even in environments such as construction sites where faces are often obscured. Tools like this lower the financial and technical barriers to real-time, population-level surveillance. Read the full paper on arXiv here.
A key concern is how AI will be governed when deployed by enforcement agencies, particularly in ways that affect civil liberties. Rather than viewing this as a trade-off between security and liberty, the deeper issue is whether current surveillance practices align with democratic principles at all, especially when their use expands without meaningful oversight.
At the same time, grassroots responses are emerging. One such example is ICEBlock, an app designed to alert users to the presence of nearby ICE agents. It has surged in popularity but has also drawn legal threats from public officials who claim it aids criminal activity. These reactions raise additional questions about the balance between public safety and community-led resistance efforts.
Another example of public counter-surveillance is FuckLAPD.com, a tool launched by Los Angeles artist Kyle McDonald that enables users to upload a photo of an LAPD officer and receive their name and badge number through facial recognition technology. Built from publicly available images released in response to transparency lawsuits, it aims to invert the surveillance gaze. Yet this too raises complex questions. Who gets to build and use these systems? What norms and legal frameworks govern facial recognition deployed by the public, especially in a context of state violence and low trust in institutions?
This feedback loop of surveillance and counter-surveillance reveals a deeper concern. Both government and civilian actors now have access to AI-powered systems that can identify, track, and profile individuals. But only one side holds the power to detain, deport, or prosecute. When enforcement agencies operate with minimal transparency and with commercial surveillance tools outsourced to private firms, the potential for abuse grows sharply, especially for immigrant communities, organizers, and journalists.
If you are concerned about these developments, ActivistChecklist.org offers a set of plain-language resources to help protect your digital security. From secure messaging to protest preparation, these checklists are a practical starting point for anyone seeking to stay safe in an increasingly monitored world.
Let us know your thoughts: How should democratic societies govern AI surveillance tools when their deployment fundamentally alters the relationship between citizens and the state?
Please share your thoughts with the MAIEI community:

Amidst ongoing escalations between Israel and Iran, several viral videos claiming to show missile strikes and combat footage circulated widely across TikTok, Facebook, and X. Many of these clips were manipulated or fully AI-generated. Despite being confirmed false, the three most popular clips generated over 100 million views across platforms.
To fact-check these videos, audiences turned to AI chatbots to verify their validity, which often incorrectly confirmed the content as real. Analysis of these verification attempts in a new report published by DFRLab reveals specific failure patterns: users repeatedly tagged Grok for verification after being challenged to do so, while the chatbot struggled with consistent analysis, oscillating between contradictory assessments of the same content and hallucinating text that wasn’t present in videos. In one case, Grok identified the same AI-generated airport footage as showing damage in Tel Aviv, Beirut, Gaza, or Tehran across different responses.
This marks one of the first major global conflicts where generative AI has played, and continues to play, a visible role in shaping public (mis)understanding of events in real-time.
📌 MAIEI’s Take and Why It Matters:
As we noted in Brief #165, it’s worth starting with definitions.
-
Misinformation refers to false or misleading content shared without intent to deceive.
-
Disinformation refers to deliberately deceptive content, often deployed to influence opinions, distort reality, or undermine institutions.
However, AI complicates these traditional categories. When chatbots incorrectly verify false content, they become unwitting participants in disinformation ecosystems, even without malicious intent. This creates a new hybrid category where algorithmic failures transform misinformation into systematic deception.
In fast-moving and high-stakes conflicts, particularly in regions with limited press freedom or inadequate AI infrastructure, the risk of public misperception is amplified. Generative AI accelerates the spread of misinformation and disinformation, playing an active role in shaping global narratives before credible sources can respond. Digital misinformation is also not a new issue. Recent advancements in generative AI and the ease with which AI can produce and disseminate believable narratives have significantly raised the political stakes.
While AI-generated media can support journalism and accessibility in under-resourced regions, the absence of robust infrastructure for provenance and content verification means these same tools can be easily misused.
This is further complicated by regional internet restrictions. Iran’s temporary internet blackouts during key moments of the unfolding conflict led to the omission of local voices from the conversation, opening the door for external actors to control the narrative. In these cases, AI-generated media is not only misleading but also fills the void left by suppressed reporting, which deepens the imbalance of power in information access. In other words, it becomes the only visible version of events.
Emerson Brooking, director of strategy at the DFRLab and co-author of LikeWar: The Weaponization of Social Media, notes:
“What we’re seeing is AI mediating the experience of warfare… There is a difference between experiencing conflict just on a social media platform and experiencing it with a conversational companion, who is endlessly patient, who you can ask to tell you about anything… This is another milestone in how publics will process and understand armed conflicts and warfare. And we’re just at the start of it.”
This shift toward AI as a “conversational companion” in processing conflict fundamentally alters the psychological impact of war content. Unlike passive consumption of traditional media, AI creates an interactive experience where users can probe, question, and receive seemingly authoritative responses. This conversational element makes false information feel more credible and personally validated, potentially deepening emotional investment in misleading narratives.
Looking ahead, systemic improvements in how platforms flag and trace fraudulent content will be essential. Immediate actions during active conflicts should include implementing rapid-response verification protocols, suspending AI chatbot responses to unverified conflict footage, and establishing direct partnerships with credible news organizations for real-time fact-checking. Policymakers must shift towards enforceable standards for traceability and transparency in AI-generated media, particularly in conflict zones and other high-risk settings. Digital watermarking, source metadata, and traceability protocols may be necessary not only to verify authenticity but also to preserve accountability.
At the same time, AI literacy remains a crucial public need. As AI-generated content becomes more realistic, individuals must be ready to question, contextualize, and verify what they encounter. This includes understanding how to formulate verification queries to AI systems without introducing bias, recognizing the limitations of AI in analyzing visual content, and developing healthy skepticism toward AI-confirmed information during rapidly evolving events. Technical safeguards alone won’t be enough. Responsible AI governance will require both regulatory action and widespread public education.
The ongoing Israel-Iran conflict is a signal of what’s to come. As generative AI becomes increasingly embedded in our information ecosystems, especially during times of geopolitical instability, our systems for safeguarding truth and public knowledge will need to evolve just as quickly, if not faster.
A U.S. federal judge recently ruled in favour of Anthropic in a major copyright case, deciding that training AI models on copyrighted content constitutes fair use under U.S. law. However, the ruling was more nuanced than a blanket endorsement. While U.S. District Judge William Alsup found that AI training itself was fair use, Anthropic still faces trial for allegedly using pirated books. The minimum statutory penalty for this type of copyright infringement is $750 per book. With at least 7 million titles in Anthropic’s pirate library, the company could face billions in potential damages.
Similar rulings have favoured Meta and other AI companies, even in cases where training data came from unauthorized piracy websites. The U.S. Copyright Office has also signalled plans to weigh in on broader AI policy. This comes after the Trump administration’s controversial firing of Copyright Office director Shira Perlmutter in May 2025, shortly after the office published a major report on how U.S. copyright law, particularly the fair use doctrine, should apply to the use of copyrighted works in training generative AI models. Perlmutter has since filed a lawsuit arguing that her dismissal was unconstitutional and violated the separation of powers.
📌 MAIEI’s Take and Why It Matters:
Generative AI is accelerating the fragmentation of cultural production while creating new forms of institutional instability around intellectual property governance. We’re also seeing the collapse of shared cultural references, the monoculture, and the rise of hyper-personalized, on-demand content tailored by algorithms.
On platforms like Spotify, AI-generated bands are now racking up millions of plays, while traditional artists are pushing back on multiple fronts. Deerhoof recently announced that they’re pulling their music from Spotify entirely, not due to AI-generated content, but because CEO Daniel Ek invested $700 million of his Spotify fortune in Helsing, a German AI defence company developing military weapons technology. As the band put it: “We don’t want our music killing people. We don’t want our success being tied to AI battle tech.” Record labels, meanwhile, are simultaneously embracing AI tools for production while fighting to protect their catalogs from being used as training data, navigating an uneasy mix of adoption and opposition.
The legal decisions being made today represent a major win for AI companies as they navigate ongoing battles over copyrighted works in large language models. In this environment, copyright functions as a mechanism for controlling the training data that shapes the next wave of generative tools.
The institutional chaos surrounding copyright enforcement, from the firing of agency directors to contradictory court rulings, reflects deeper questions about who has the authority to govern cultural production in the AI era. As AI-generated media becomes indistinguishable from human-made content, questions of authorship, authenticity, and creative ownership are becoming increasingly complex and unclear. The legal precedents being established now will shape the production, distribution, and monetization of culture for decades to come.
The New York Times recently reported on an “AI arms race” in the hiring process. Applicants are increasingly submitting generative AI-manufactured resumes and employing autonomous bots to seek and apply for new positions, leading to a surge in online job applications. LinkedIn has experienced a 45 percent increase in applications through its website this year, with an average of 11,000 applications submitted every minute. Employers are responding to the onslaught with more AI, such as using AI video interviewing and skills-assessment platforms like HireVue to sort applicants, who can then use more generative AI to cheat the evaluations. Ultimately, “we end up with an A.I. versus A.I. type of situation.”
📌 MAIEI’s Take and Why It Matters:
As AI use by both applicants and employers accelerates, the hiring process risks losing much of its meaning as humans are increasingly pushed out. While employers face genuine challenges managing unprecedented application volumes, AI tools designed to increase efficiency often have the opposite effect. The expected number of job applications per candidate increases due to the exponential growth in application volume, creating a feedback loop that benefits no one.
Moreover, the widespread use of AI in hiring and other contexts is increasingly seen as a sign of disrespect, signalling a new era in which previously taken-for-granted human contact becomes a luxury. For instance, UNC Chapel Hill now uses an AI tool to grade application essays on a scale from 1 to 4 as part of its admission process. Meanwhile, a Northwestern senior requested a partial tuition refund after discovering that her professor had used AI to develop course materials in a class that otherwise prohibited the use of such tools. For high schoolers who spent hours crafting vulnerable admissions essays, the use of AI feels inconsiderate, if not fraudulent. The same applies to candidates spending hours crafting resumes that will never be viewed by a person, and to employers who tirelessly read hundreds of applications, only to find that many are written by AI.
These tools also discriminate against marginalized groups of people, a form of bias emphasized in the NYT article. HireVue and Intuit are facing a complaint for violating several anti-discrimination provisions after a deaf woman named D.K. was unfairly evaluated for a job position with a mandatory HireVue AI interview. Her interview accommodation request was denied, and she was ultimately rejected from the position with feedback to “practice active listening.”
In the midst of growing AI capacities, we face a choice: design systems that support human dignity in the hiring process, or continue to let algorithmic efficiency override human judgment and fairness. The current trajectory suggests we’re choosing the latter, with consequences that extend far beyond individual job searches to the fundamental relationship between institutions and the people they serve.
Did we miss anything? Let us know in the comments below.
This edition of our AI Policy Corner, produced in partnership with the Governance and Responsible AI Lab (GRAIL) at Purdue University, compares the Texas Responsible Artificial Intelligence Governance Act (TRAIGA) and New York’s AI Act (S1169A), highlighting key differences in regulatory scope and enforcement. While Texas emphasizes government procurement standards and innovation through regulatory sandboxes, it limits enforcement mechanisms as it does not regulate private sector AI deployment. In contrast, New York adopts a broader civil rights framework, mandating bias audits, notice requirements, and private rights of action. The comparison highlights diverging state-level approaches to AI governance, with one focused on agency oversight and the other on consumer protection and accountability.
To dive deeper, read the full article here.
In Part 3 of 4 of the AVID blog series on red teaming, the authors continue to build their argument that red teaming is not merely a technical task but a structured critical thinking exercise essential to responsible AI development. Building on Parts 1 and 2, which emphasized the need for cross-functional collaboration and challenged the narrow, adversarial framing common in AI discourse, this piece explores how red teaming can be applied across the entire system lifecycle, from inception to retirement. By outlining both macro- and micro-level approaches, the authors make the case that effective red teaming must be iterative, embedded, and inclusive of both technical and non-technical perspectives to proactively identify and address failure modes, ensuring that AI systems align with broader human and organizational values.
To dive deeper, read the full article here.
Sun Gyoo Kang explores the concept of Sovereign Artificial Intelligence (AI), examining its historical roots, geopolitical relevance, and the competing arguments for and against national control of AI systems. As countries face growing concerns over data privacy, national security, and economic independence, Sovereign AI has emerged as a strategic imperative, particularly for nations aiming to reduce reliance on foreign technology providers. However, Kang also highlights the risks of protectionism, reduced collaboration, and potential misuse, calling for a “Smart Sovereignty” approach that balances national interests with international cooperation and responsible governance.
To dive deeper, read the full article here.

Help us keep The AI Ethics Brief free and accessible for everyone by becoming a paid subscriber on Substack or making a donation at montrealethics.ai/donate. Your support sustains our mission of democratizing AI ethics literacy and honours Abhishek Gupta’s legacy.
For corporate partnerships or larger contributions, please contact us at support@montrealethics.ai
Have an article, research paper, or news item we should feature? Leave us a comment below — we’d love to hear from you!
Ethics & Policy
Oprah Winfrey's latest book club pick, 'Culpability,' delves into AI ethics – livingstonenterprise.net

Oprah Winfrey’s latest book club pick, ‘Culpability,’ delves into AI ethics livingstonenterprise.net
Source link
Ethics & Policy
Oprah Winfrey's latest book club pick, 'Culpability,' delves into AI ethics – Bluefield Daily Telegraph

Oprah Winfrey’s latest book club pick, ‘Culpability,’ delves into AI ethics Bluefield Daily Telegraph
Source link
-

 Funding & Business1 week ago
Funding & Business1 week agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries
-
Jobs & Careers1 week ago
Mumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-
Mergers & Acquisitions1 week ago
Donald Trump suggests US government review subsidies to Elon Musk’s companies
-
Funding & Business1 week ago
Rethinking Venture Capital’s Talent Pipeline
-
Jobs & Careers1 week ago
Why Agentic AI Isn’t Pure Hype (And What Skeptics Aren’t Seeing Yet)
-
Funding & Business5 days ago
Sakana AI’s TreeQuest: Deploy multi-model teams that outperform individual LLMs by 30%
-
Jobs & Careers1 week ago
Astrophel Aerospace Raises ₹6.84 Crore to Build Reusable Launch Vehicle
-
Jobs & Careers1 week ago
Telangana Launches TGDeX—India’s First State‑Led AI Public Infrastructure
-
 Funding & Business1 week ago
Funding & Business1 week agoFrom chatbots to collaborators: How AI agents are reshaping enterprise work
-
Funding & Business1 week ago
Europe’s Most Ambitious Startups Aren’t Becoming Global; They’re Starting That Way

















