AI Research
Salesforce AI Research Launches Enterprise Simulation Environment

This quarter, Salesforce AI Research unveiled an enterprise simulation environment to test agents ability to perform in realistic business scenarios, supported the launch of a new benchmarking tool to measure agents across enterprise use cases, and enhanced Data Cloud with advanced consolidation capabilities that leverage small and large language models to autonomously unify data. From impr oving data quality to setting new standards in measuring agentic performance, these innovations are fueling product breakthroughs that tackle today’s most pressing challenges for CIOs and IT leaders, giving businesses the trust and tools they need to evolve into agentic enterprises –organizations that embrace digital labor and use AI to work alongside humans.
Simulating Enterprise Environments with CRMArena-Pro
Pilots don’t learn to fly in a storm; they train in flight simulators that push them to prepare in the most extreme challenges. Similarly, surgeons test their skills in high-risk procedures on synthetic models and cadavers before ever operating on a human, and athletes perfect their plays in drills and scrimmages ahead of a big game. In every high-stakes field, skills and consistencies are honed not through live action, but through deliberate preparation in a space where failure is a learning tool, not a costly mistake.
AI agents benefit from simulation testing and training too, preparing them to handle the unpredictability of daily business scenarios in advance of their deployment. Building on the original CRMArena, which focused on single-turn B2C service tasks, Salesforce AI Research has now unveiled CRMArena-Pro which tests agent performance in complex, multi-turn, multi-agent scenarios such as sales forecasting, service case triage, and CPQ processes. By using synthetic data, enabling safe API calls to relevant systems, and enforcing strict safeguards to protect PII, CRMArena-Pro creates a rigorous, context-rich simulated enterprise environment framework to test not only whether an agent works, but whether it can operate accurately, efficiently, and consistently at scale across enterprise-specific use cases.
Acting much like a digital twin or metaverse of a business, these environments go beyond simple test beds, capturing the full complexity of enterprise operations. Salesforce AI Research is advancing AI agent training with these simulations, enabling businesses to test agents in situations like customer service escalations or supply chain disruptions, before ever going live. By incorporating real-world “noise,” enterprises can better evaluate performance, strengthen resilience against edge cases, and bridge the gap between training and live operations, resulting in AI agents that are not only capable, but consistent, trustworthy, and agentic enterprise-ready.
Measuring Agent Readiness with the Agentic Benchmark for CRM
With new models and updates emerging daily, enterprises face a growing dilemma of which model, or combination of models, is best suited to help power agents in real-world business settings. The answer can’t come from hype cycles or raw size alone; it requires a rigorous way to measure how agents perform within specific business workflows.
Salesforce introduced the new Agentic Benchmark for CRM, the first benchmarking tool designed to evaluate AI agents not on generic capabilities, but in the contexts that matter most to businesses, including customer service, field service, marketing, and sales. The benchmark measures agents across five essential enterprise metrics—accuracy, cost, speed, trust and safety, and sustainability—offering a comprehensive, data-driven assessment of their readiness for real-world deployment.
Sustainability, the newest metric in the agentic measurement tool, is a key marker of an agent’s enterprise readiness. This measure highlights the relative environmental impact of AI systems, which can demand significant computational resources. By aligning model size with the specific level of intelligence required to complete an enterprise-specific task, businesses can minimize their footprint and determine their AI sustainability, all while achieving the caliber of performance they need. By cutting through model overload, the benchmark gives businesses a clear, data-driven way to pair the right models with the right agents, ensuring consistent, trustworthy, and enterprise-grade performance.
MCP-Eval and MCP-Universe are two additional complementary benchmarks published by Salesforce AI Research this quarter designed to measure agents at different levels of rigor and tracks LLMs as they interact with MCP servers in the real world use case environments. MCP-Eval provides scalable, automatic evaluation through synthetic tasks, making it well-suited for testing across a wide range of MCP servers. MCP-Universe, on the other hand, introduces challenging real-world tasks with execution-based evaluators that stress-test agents in complex scenarios and offers an extendable framework for building and evaluating agents. Together, they form a powerful toolkit: MCP-Eval for broad, initial assessments, and MCP-Universe for deeper diagnosis and debugging.
This dual approach is especially critical for enterprises, as the research found most state-of-the-art LLMs on the market today still face key limitations that hold them back from enterprise-grade performance — from long-context challenges, where models lose track of information in complex inputs, to unknown-tool challenges, where they fail to adapt seamlessly to unfamiliar systems. By leveraging MCP-Universe and MCP-Eval, enterprises can gain a clear view of where agents break down and refine their frameworks or tool integrations accordingly. And with a platform that layers in context, enhanced reasoning, and trust guardrails, organizations can move beyond DIY experimentation to deliver agents ready for real-world business impact.
Consolidating Data with Account Matching
At the heart of reliable, scalable AI agent performance is high-quality, unified data that enables context-aware, accurate, and compliant decision-making. Unified data allows agents to understand context, follow business rules, and make decisions that align with organizational goals. However, this has long been a challenge for businesses, as enterprise data is rarely clean or well-organized. Customer records are often duplicated across departments, fields are incomplete, and inconsistent formatting and naming conventions make it difficult to reconcile data across systems.
To tackle this, the Salesforce AI Research and product teams partnered to fine-tune large and small language models and power Account Matching, a capability that autonomously identifies and unifies accounts across scattered, inconsistent datasets. Instead of treating “The Example Company, Inc.” and “Example Co.” as separate entities, the system can now use AI to recognize them as the same and consolidate them into a single, authoritative record. Unlike static, rule-based systems that require heavy manual setup, Account Matching reconciles millions of records in real time with measurable accuracy improvements.
These are the kinds of breakthroughs driving real ROI for customers today. In just the first month, one customer’s proprietary tool that utilizes Account Matching unified more than a million accounts with a 95% match success rate, reducing average handling time by 30 minutes. Powered by fine-tuned small and large language models and identity resolution rules (account name plus website, address, or phone number), the tool automatically matches accounts across business units, surfaces a flow in each org for sellers to connect, and routes only the top 5% of complex cases to humans. By helping sellers quickly find counterparts covering the same or similar accounts, the solution eliminates duplicative work, accelerates sales cycles, and prevents missed opportunities. Best of all, the entire solution was implemented without the need for hard coding, lowering costs and dramatically improving efficiency.
With Account Matching, businesses have access to clean, unified data that powers AI agents with confidence, enabling smarter automation, richer personalization, and faster decisions at scale.

















AI isn’t here to replace jobs, it’s here to eliminate outdated practices and empower entrepreneurs to innovate faster and smarter than ever before.


Summary: A new AI system developed by computer scientists automatically screens open-access journals to identify potentially predatory publications. These journals often charge high fees to publish without proper peer review, undermining scientific credibility.
The AI analyzed over 15,000 journals and flagged more than 1,000 as questionable, offering researchers a scalable way to spot risks. While the system isn’t perfect, it serves as a crucial first filter, with human experts making the final calls.
Key Facts
- Predatory Publishing: Journals exploit researchers by charging fees without quality peer review.
- AI Screening: The system flagged over 1,000 suspicious journals out of 15,200 analyzed.
- Firewall for Science: Helps preserve trust in research by protecting against bad data.
Source: University of Colorado
A team of computer scientists led by the University of Colorado Boulder has developed a new artificial intelligence platform that automatically seeks out “questionable” scientific journals.
The study, published Aug. 27 in the journal “Science Advances,” tackles an alarming trend in the world of research.
Daniel Acuña, lead author of the study and associate professor in the Department of Computer Science, gets a reminder of that several times a week in his email inbox: These spam messages come from people who purport to be editors at scientific journals, usually ones Acuña has never heard of, and offer to publish his papers—for a hefty fee.
Such publications are sometimes referred to as “predatory” journals. They target scientists, convincing them to pay hundreds or even thousands of dollars to publish their research without proper vetting.
“There has been a growing effort among scientists and organizations to vet these journals,” Acuña said. “But it’s like whack-a-mole. You catch one, and then another appears, usually from the same company. They just create a new website and come up with a new name.”
His group’s new AI tool automatically screens scientific journals, evaluating their websites and other online data for certain criteria: Do the journals have an editorial board featuring established researchers? Do their websites contain a lot of grammatical errors?
Acuña emphasizes that the tool isn’t perfect. Ultimately, he thinks human experts, not machines, should make the final call on whether a journal is reputable.
But in an era when prominent figures are questioning the legitimacy of science, stopping the spread of questionable publications has become more important than ever before, he said.
“In science, you don’t start from scratch. You build on top of the research of others,” Acuña said. “So if the foundation of that tower crumbles, then the entire thing collapses.”
The shake down
When scientists submit a new study to a reputable publication, that study usually undergoes a practice called peer review. Outside experts read the study and evaluate it for quality—or, at least, that’s the goal.
A growing number of companies have sought to circumvent that process to turn a profit. In 2009, Jeffrey Beall, a librarian at CU Denver, coined the phrase “predatory” journals to describe these publications.
Often, they target researchers outside of the United States and Europe, such as in China, India and Iran—countries where scientific institutions may be young, and the pressure and incentives for researchers to publish are high.
“They will say, ‘If you pay $500 or $1,000, we will review your paper,’” Acuña said. “In reality, they don’t provide any service. They just take the PDF and post it on their website.”
A few different groups have sought to curb the practice. Among them is a nonprofit organization called the Directory of Open Access Journals (DOAJ).
Since 2003, volunteers at the DOAJ have flagged thousands of journals as suspicious based on six criteria. (Reputable publications, for example, tend to include a detailed description of their peer review policies on their websites.)
But keeping pace with the spread of those publications has been daunting for humans.
To speed up the process, Acuña and his colleagues turned to AI. The team trained its system using the DOAJ’s data, then asked the AI to sift through a list of nearly 15,200 open-access journals on the internet.
Among those journals, the AI initially flagged more than 1,400 as potentially problematic.
Acuña and his colleagues asked human experts to review a subset of the suspicious journals. The AI made mistakes, according to the humans, flagging an estimated 350 publications as questionable when they were likely legitimate. That still left more than 1,000 journals that the researchers identified as questionable.
“I think this should be used as a helper to prescreen large numbers of journals,” he said. “But human professionals should do the final analysis.”
A firewall for science
Acuña added that the researchers didn’t want their system to be a “black box” like some other AI platforms.
“With ChatGPT, for example, you often don’t understand why it’s suggesting something,” Acuña said. “We tried to make ours as interpretable as possible.”
The team discovered, for example, that questionable journals published an unusually high number of articles. They also included authors with a larger number of affiliations than more legitimate journals, and authors who cited their own research, rather than the research of other scientists, to an unusually high level.
The new AI system isn’t publicly accessible, but the researchers hope to make it available to universities and publishing companies soon. Acuña sees the tool as one way that researchers can protect their fields from bad data—what he calls a “firewall for science.”
“As a computer scientist, I often give the example of when a new smartphone comes out,” he said.
“We know the phone’s software will have flaws, and we expect bug fixes to come in the future. We should probably do the same with science.”
About this AI and science research news
Author: Daniel Strain
Source: University of Colorado
Contact: Daniel Strain – University of Colorado
Image: The image is credited to Neuroscience News
Original Research: Open access.
“Estimating the predictability of questionable open-access journals” by Daniel Acuña et al. Science Advances
Abstract
Estimating the predictability of questionable open-access journals
Questionable journals threaten global research integrity, yet manual vetting can be slow and inflexible.
Here, we explore the potential of artificial intelligence (AI) to systematically identify such venues by analyzing website design, content, and publication metadata.
Evaluated against extensive human-annotated datasets, our method achieves practical accuracy and uncovers previously overlooked indicators of journal legitimacy.
By adjusting the decision threshold, our method can prioritize either comprehensive screening or precise, low-noise identification.
At a balanced threshold, we flag over 1000 suspect journals, which collectively publish hundreds of thousands of articles, receive millions of citations, acknowledge funding from major agencies, and attract authors from developing countries.
Error analysis reveals challenges involving discontinued titles, book series misclassified as journals, and small society outlets with limited online presence, which are issues addressable with improved data quality.
Our findings demonstrate AI’s potential for scalable integrity checks, while also highlighting the need to pair automated triage with expert review.
AI Research
Researchers Unlock 210% Performance Gains In Machine Learning With Spin Glass Feature Mapping
Quantum machine learning seeks to harness the power of quantum mechanics to improve artificial intelligence, and a new technique developed by Anton Simen, Carlos Flores-Garrigos, and Murilo Henrique De Oliveira, all from Kipu Quantum GmbH, alongside Gabriel Dario Alvarado Barrios, Juan F. R. Hernández, and Qi Zhang, represents a significant step towards realising that potential. The researchers propose a novel feature mapping technique that utilises the complex dynamics of a quantum spin glass to identify subtle patterns within data, achieving a performance boost in machine learning models. This method encodes data into a disordered quantum system, then extracts meaningful features by observing its evolution, and importantly, the team demonstrates performance gains of up to 210% on high-dimensional datasets used in areas like drug discovery and medical diagnostics. This work marks one of the first demonstrations of quantum machine learning achieving a clear advantage over classical methods, potentially bridging the gap between theoretical quantum supremacy and practical, real-world applications.
The core idea is to leverage the quantum dynamics of these annealers to create enhanced feature spaces for classical machine learning algorithms, with the goal of achieving a quantum advantage in performance. Key findings include a method to map classical data into a quantum feature space, allowing classical machine learning algorithms to operate on richer data. Researchers found that operating the annealer in the coherent regime, with annealing times of 10-40 nanoseconds, yields the best and most stable performance, as longer times lead to performance degradation.
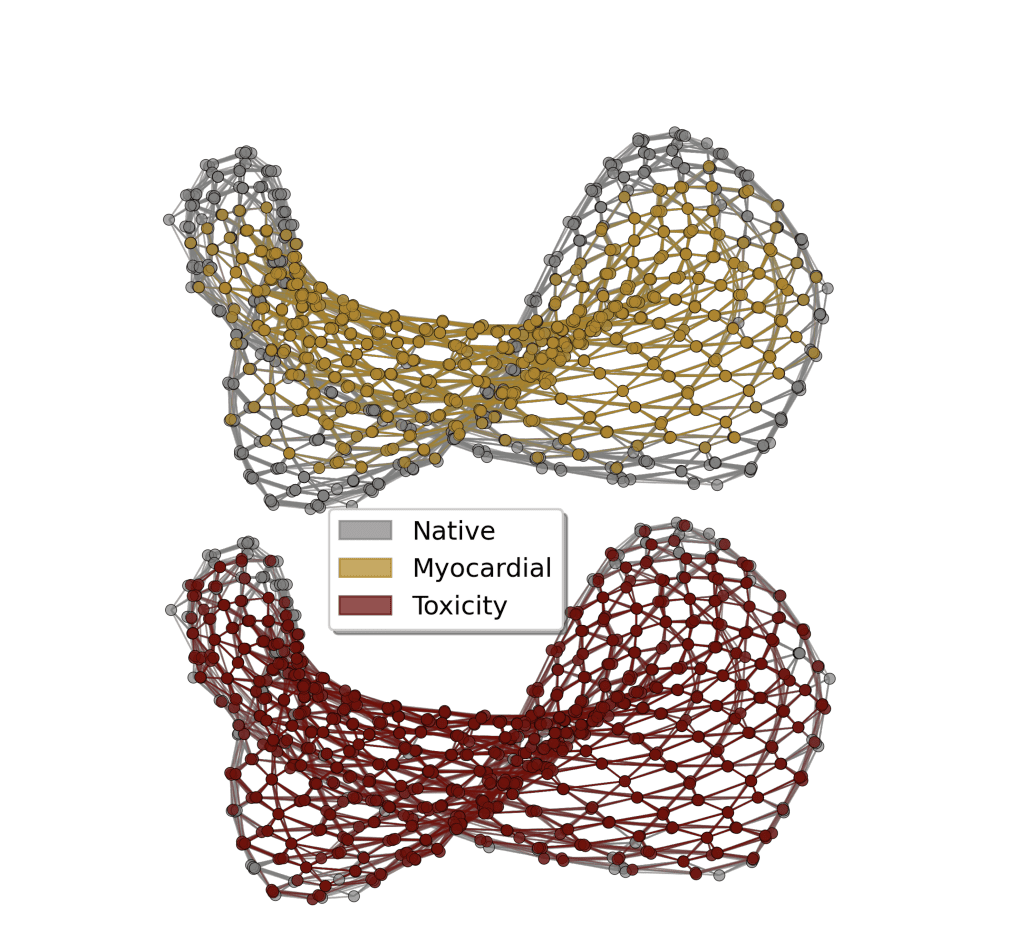
The method was tested on datasets related to toxicity prediction, myocardial infarction complications, and drug-induced autoimmunity, suggesting potential performance gains compared to purely classical methods. Kipu Quantum has launched an industrial quantum machine learning service based on these findings, claiming to achieve quantum advantage. The methodology involves encoding data into qubits, programming the annealer to evolve according to its quantum dynamics, extracting features from the final qubit state, and feeding this data into classical machine learning algorithms. Key concepts include quantum annealing, analog quantum computing, feature engineering, quantum feature maps, and the coherent regime. The team encoded information from datasets into a disordered quantum system, then used a process called “quantum quench” to generate complex feature representations. Experiments reveal that machine learning models benefit most from features extracted during the fast, coherent stage of this quantum process, particularly when the system is near a critical dynamic point. This analog quantum feature mapping technique was benchmarked on high-dimensional datasets, drawn from areas like drug discovery and medical diagnostics.
Results demonstrate a substantial performance boost, with the quantum-enhanced models achieving up to a 210% improvement in key metrics compared to state-of-the-art classical machine learning algorithms. Peak classification performance was observed at annealing times of 20-30 nanoseconds, a regime where quantum entanglement is maximized. The technique was successfully applied to datasets related to molecular toxicity, myocardial infarction complications, and drug-induced autoimmunity, using algorithms including support vector machines, random forests, and gradient boosting. By encoding data into a disordered quantum system and extracting features from its evolution, the researchers demonstrate performance improvements in applications including molecular toxicity classification, diagnosis of heart attack complications, and detection of drug-induced autoimmune responses. Comparative evaluations consistently show gains in precision, recall, and area under the curve, achieving improvements of up to 210% in certain metrics. Researchers found that optimal performance is achieved when the quantum system operates in a coherent regime, with longer annealing times leading to performance degradation due to decoherence. Further research is needed to explore more complex quantum feature encodings, adaptive annealing schedules, and broader problem domains. Future work will also investigate implementation on digital quantum computers and explore alternative analog quantum hardware platforms, such as neutral-atom quantum systems, to expand the scope and impact of this method.
-
Tools & Platforms3 weeks ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy1 month ago
Ethics & Policy1 month agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences3 months ago
Events & Conferences3 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers2 months ago
Jobs & Careers2 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Business1 day ago
Business1 day agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-

 Funding & Business2 months ago
Funding & Business2 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries
-

 Education2 months ago
Education2 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi
-

 Jobs & Careers2 months ago
Jobs & Careers2 months agoAstrophel Aerospace Raises ₹6.84 Crore to Build Reusable Launch Vehicle