
3D rendering—the process of converting three-dimensional models into two-dimensional images—is a foundational technology in computer graphics, widely used across gaming, film, virtual reality, and architectural visualization. Traditionally, this process has depended on physics-based techniques like ray tracing and rasterization, which simulate light behavior through mathematical formulas and expert-designed models.
Now, thanks to advances in AI, especially neural networks, researchers are beginning to replace these conventional approaches with machine learning (ML). This shift is giving rise to a new field known as neural rendering.
Neural rendering combines deep learning with traditional graphics techniques, allowing models to simulate complex light transport without explicitly modeling physical optics. This approach offers significant advantages: it eliminates the need for handcrafted rules, supports end-to-end training, and can be optimized for specific tasks. Yet, most current neural rendering methods rely on 2D image inputs, lack support for raw 3D geometry and material data, and often require retraining for each new scene—limiting their generalizability.
RenderFormer: Toward a general-purpose neural rendering model
To overcome these limitations, researchers at Microsoft Research have developed RenderFormer, a new neural architecture designed to support full-featured 3D rendering using only ML—no traditional graphics computation required. RenderFormer is the first model to demonstrate that a neural network can learn a complete graphics rendering pipeline, including support for arbitrary 3D scenes and global illumination, without relying on ray tracing or rasterization. This work has been accepted at SIGGRAPH 2025 and is open-sourced on GitHub (opens in new tab).
Architecture overview
As shown in Figure 1, RenderFormer represents the entire 3D scene using triangle tokens—each one encoding spatial position, surface normal, and physical material properties such as diffuse color, specular color, and roughness. Lighting is also modeled as triangle tokens, with emission values indicating intensity.
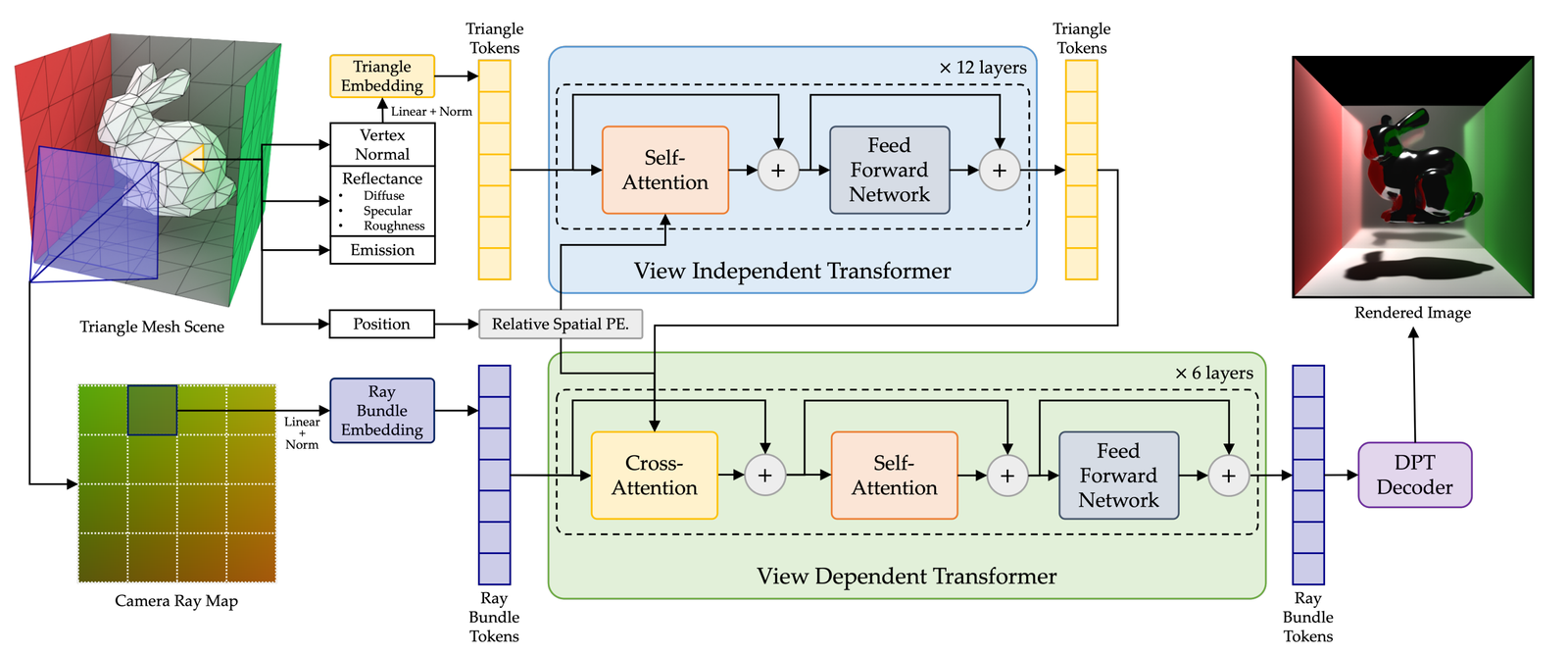
To describe the viewing direction, the model uses ray bundle tokens derived from a ray map—each pixel in the output image corresponds to one of these rays. To improve computational efficiency, pixels are grouped into rectangular blocks, with all rays in a block processed together.
The model outputs a set of tokens that are decoded into image pixels, completing the rendering process entirely within the neural network.
PODCAST SERIES
AI Testing and Evaluation: Learnings from Science and Industry
Discover how Microsoft is learning from other domains to advance evaluation and testing as a pillar of AI governance.
Dual-branch design for view-independent and view-dependent effects
The RenderFormer architecture is built around two transformers: one for view-independent features and another for view-dependent ones.
- The view-independent transformer captures scene information unrelated to viewpoint, such as shadowing and diffuse light transport, using self-attention between triangle tokens.
- The view-dependent transformer models effects like visibility, reflections, and specular highlights through cross-attention between triangle and ray bundle tokens.
Additional image-space effects, such as anti-aliasing and screen-space reflections, are handled via self-attention among ray bundle tokens.
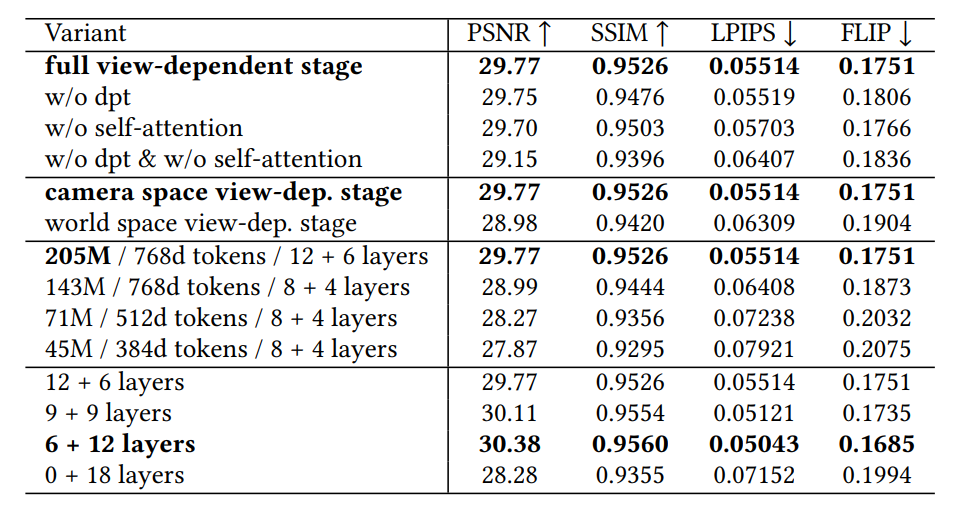
To validate the architecture, the team conducted ablation studies and visual analyses, confirming the importance of each component in the rendering pipeline.
To test the capabilities of the view-independent transformer, researchers trained a decoder to produce diffuse-only renderings. The results, shown in Figure 2, demonstrate that the model can accurately simulate shadows and other indirect lighting effects.

The view-dependent transformer was evaluated through attention visualizations. For example, in Figure 3, the attention map reveals a pixel on a teapot attending to its surface triangle and to a nearby wall—capturing the effect of specular reflection. These visualizations also show how material changes influence the sharpness and intensity of reflections.

Training methodology and dataset design
RenderFormer was trained using the Objaverse dataset, a collection of more than 800,000 annotated 3D objects that is designed to advance research in 3D modeling, computer vision, and related fields. The researchers designed four scene templates, populating each with 1–3 randomly selected objects and materials. Scenes were rendered in high dynamic range (HDR) using Blender’s Cycles renderer, under varied lighting conditions and camera angles.
The base model, consisting of 205 million parameters, was trained in two phases using the AdamW optimizer:
- 500,000 steps at 256×256 resolution with up to 1,536 triangles
- 100,000 steps at 512×512 resolution with up to 4,096 triangles
The model supports arbitrary triangle-based input and generalizes well to complex real-world scenes. As shown in Figure 4, it accurately reproduces shadows, diffuse shading, and specular highlights.

RenderFormer can also generate continuous video by rendering individual frames, thanks to its ability to model viewpoint changes and scene dynamics.
Looking ahead: Opportunities and challenges
RenderFormer represents a significant step forward for neural rendering. It demonstrates that deep learning can replicate and potentially replace the traditional rendering pipeline, supporting arbitrary 3D inputs and realistic global illumination—all without any hand-coded graphics computations.
However, key challenges remain. Scaling to larger and more complex scenes with intricate geometry, advanced materials, and diverse lighting conditions will require further research. Still, the transformer-based architecture provides a solid foundation for future integration with broader AI systems, including video generation, image synthesis, robotics, and embodied AI.
Researchers hope that RenderFormer will serve as a building block for future breakthroughs in both graphics and AI, opening new possibilities for visual computing and intelligent environments.




















