Books, Courses & Certifications
Raiza Martin on Building AI Applications for Audio – O’Reilly

/
Audio is being added to AI everywhere: both in multimodal models that can understand and generate audio and in applications that use audio for input. Now that we can work with spoken language, what does that mean for the applications that we can develop? How do we think about audio interfaces—how will people use them, and what will they want to do? Raiza Martin, who worked on Google’s groundbreaking NotebookLM, joins Ben Lorica to discuss how she thinks about audio and what you can build with it.
About the Generative AI in the Real World podcast: In 2023, ChatGPT put AI on everyone’s agenda. In 2025, the challenge will be turning those agendas into reality. In Generative AI in the Real World, Ben Lorica interviews leaders who are building with AI. Learn from their experience to help put AI to work in your enterprise.
Check out other episodes of this podcast on the O’Reilly learning platform.
Timestamps
- 0:00: Introduction to Raiza Martin, who cofounded Huxe and formerly led Google’s NotebookLM team. What made you think this was the time to trade the comforts of big tech for a garage startup?
- 1:01: It was a personal decision for all of us. It was a pleasure to take NotebookLM from an idea to something that resonated so widely. We realized that AI was really blowing up. We didn’t know what it would be like at a startup, but we wanted to try. Seven months down the road, we’re having a great time.
- 1:54: For the 1% who aren’t familiar with NotebookLM, give a short description.
- 2:06: It’s basically contextualized intelligence, where you give NotebookLM the sources you care about and NotebookLM stays grounded to those sources. One of our most common use cases was that students would create notebooks and upload their class materials, and it became an expert that you could talk with.
- 2:43: Here’s a use case for homeowners: put all your user manuals in there.
- 3:14: We have had a lot of people tell us that they use NotebookLM for Airbnbs. They put all the manuals and instructions in there, and users can talk to it.
- 3:41: Why do people need a personal daily podcast?
- 3:57: There are a lot of different ways that I think about building new products. On one hand, there are acute pain points. But Huxe comes from a different angle: What if we could try to build very delightful things? The inputs are a little different. We tried to imagine what the average person’s daily life is like. You wake up, you check your phone, you travel to work; we thought about opportunities to make something more delightful. I think a lot about TikTok. When do I use it? When I’m standing in line. We landed on transit time or commute time. We wanted to do something novel and interesting with that space in time. So one of the first things was creating really personalized audio content. That was the provocation: What do people want to listen to? Even in this short time, we’ve learned a lot about the amount of opportunity.
- 6:04: Huxe is mobile first, audio first, right? Why audio?
- 6:45: Coming from our learnings from NotebookLM, you learn fundamentally different things when you change the modality of something. When I go on walks with ChatGPT, I just talk about my day. I noticed that was a very different interaction from when I type things out to ChatGPT. The flip side is less about interaction and more about consumption. Something about the audio format made the types of sources different as well. The sources we uploaded to NotebookLM were different as a result of wanting audio output. By focusing on audio, I think we’ll learn different use cases than the chat use cases. Voice is still largely untapped.
- 8:24: Even in text, people started exploring other form factors: long articles, bullet points. What kinds of things are available for voice?
- 8:49: I think of two formats: one passive and one interactive. With passive formats, there are a lot of different things you can create for the user. The things you end up playing with are (1) what is the content about and (2) how flexible is the content? Is it short, long, malleable to user feedback? With interactive content, maybe I’m listening to audio, but I want to interact with it. Maybe I want to join in. Maybe I want my friends to join in. Both of those contexts are new. I think this is what’s going to emerge in the next few years. I think we’ll learn that the types of things we will use audio for are fundamentally different from the things we use chat for.
- 10:19: What are some of the key lessons to avoid from smart speakers?
- 10:25: I’ve owned so many of them. And I love them. My primary use for the smart speakers is still a timer. It’s expensive and doesn’t live up to the promise. I just don’t think the technology was ready for what people really wanted to do. It’s hard to think about how that could have worked without AI. Second, one of the most difficult things about audio is that there is no UI. A smart speaker is a physical device. There’s nothing that tells you what to do. So the learning curve is steep. So now you have a user who doesn’t know what they can use the thing for.
- 12:20: Now it can do so much more. Even without a UI, the user can just try things. But there’s a risk in that it still requires input from the user. How do we think about a system that is so supportive that you don’t have to come up with how to make it work? That’s the challenge from the smart speaker era.
- 12:56: It’s interesting that you point out the UI. With a chatbot you have to type something. With a smart speaker, people started getting creeped out by surveillance. So, will Huxe surveil me?
- 13:18: I think there’s something simple about it, which is the wake word. Because smart speakers are triggered by wake words, they are always on. If the user says something, it’s probably picking it up, and it’s probably logged somewhere. With Huxe, we want to be really careful about where we believe consumer readiness is. You want to push a little bit but not too far. If you push too far, people get creeped out.
- 14:32: For Huxe, you have to turn it on to use it. It’s clunky in some ways, but we can push on that boundary and see if we can push for something that’s more ambiently on. We’re starting to see the emergence of more tools that are always on. There are tools like Granola and Cluely: They’re always on, looking at your screen, transcribing your audio. I’m curious—are we ready for technology like that? In real life, you can probably get the most utility from something that is always on. But whether consumers are ready is still TBD.
- 15:25: So you’re ingesting calendars, email, and other things from the users. What about privacy? What are the steps you’ve taken?
- 15:48: We’re very privacy focused. I think that comes from building NotebookLM. We wanted to make sure we were very respectful of user data. We didn’t train on any user data; user data stayed private. We’re taking the same approach with Huxe. We use the data you share with Huxe to improve your personal experience. There’s something interesting in creating personal recommendation models that don’t go beyond your usage of the app. It’s a little harder for us to build something good, but it respects privacy, and that’s what it takes to get people to trust.
- 17:08: Huxe may notice that I have a flight tomorrow and tell me that the flight is delayed. To do so, it has had to contact an external service, which now knows about my flight.
- 17:26: That’s a good point. I think about building Huxe like this: If I were in your pocket, what would I do? If I saw a calendar that said “Ben has a flight,” I can check that flight without leaking your personal information. I can just look up the flight number. There are a lot of ways you can do something that provides utility but doesn’t leak data to another service. We’re trying to understand things that are much more action oriented. We try to tell you about weather, about traffic; these are things we can do without stepping on user privacy.
- 18:38: The way you described the system, there’s no social component. But you end up learning things about me. So there is the potential for building a more sophisticated filter bubble. How do you make sure that I’m ingesting things beyond my filter bubble?
- 19:08: It comes down to what I believe a person should or shouldn’t be consuming. That’s always tricky. We’ve seen what these feeds can do to us. I don’t know the correct formula yet. There’s something interesting about “How do I get enough user input so I can give them a better experience?” There’s signal there. I try to think about a user’s feed from the perspective of relevance and less from an editorial perspective. I think the relevance of information is probably enough. We’ll probably test this once we start surfacing more personalized information.
- 20:42: The other thing that’s really important is surfacing the correct controls: I like this; here’s why. I don’t like this; why not? Where you inject tension in the system, where you think the system should push back—that takes a little time to figure out how to do it right.
- 21:01: What about the boundary between giving me content and providing companionship?
- 21:09: How do we know the difference between an assistant and a companion? Fundamentally the capabilities are the same. I don’t know if the question matters. The user will use it how the user intends to use it. That question matters most in the packaging and the marketing. I talk to people who talk about ChatGPT as their best friend. I talk to others who talk about it as an employee. On a capabilities level, they’re probably the same thing. On a marketing level, they’re different.
- 22:22: For Huxe, the way I think about this is which set of use cases you prioritize. Beyond a simple conversation, the capabilities will probably start diverging.
- 22:47: You’re now part of a very small startup. I assume you’re not building your own models; you’re using external models. Walk us through privacy, given that you’re using external models. As that model learns more about me, how much does that model retain over time? To be a really good companion, you can’t be clearing that cache every time I log out.
- 23:21: That question pertains to where we store data and how it’s passed off. We opt for models that don’t train on the data we send them. The next layer is how we think about continuity. People expect ChatGPT to have knowledge of all the conversations you have.
- 24:03: To support that you have to build a very durable context layer. But you don’t have to imagine that all of that gets passed to the model. A lot of technical limitations prevent you from doing that anyway. That context is stored at the application layer. We store it, and we try to figure out the right things to pass to the model, passing as little as possible.
- 25:17: You’re from Google. I know that you measure, measure, measure. What are some of the signals you measure?
- 25:40: I think about metrics a little differently in the early stages. Metrics in the beginning are nonobvious. You’ll get a lot of trial behavior in the beginning. It’s a little harder to understand the initial user experience from the raw metrics. There are some basic metrics that I care about—the rate at which people are able to onboard. But as far as crossing the chasm (I think of product building as a series of chasms that never end), you look for people who really love it, who rave about it; you have to listen to them. And then the people who used the product and hated it. When you listen to them, you discover that they expected it to do something and it didn’t. It let them down. You have to listen to these two groups, and then you can triangulate what the product looks like to the outside world. The thing I’m trying to figure out is less “Is it a hit?” but “Is the market ready for it? Is the market ready for something this weird?” In the AI world, the reality is that you’re testing consumer readiness and need, and how they are evolving together. We did this with NotebookLM. When we showed it to students, there was zero time between when they saw it and when they understood it. That’s the first chasm. Can you find people who understand what they think it is and feel strongly about it?
- 28:45: Now that you’re outside of Google, what would you want the foundation model builders to focus on? What aspects of these models would you like to see improved?
- 29:20: We share so much feedback with the model providers—I can provide feedback to all the labs, not just Google, and that’s been fun. The universe of things right now is pretty well known. We haven’t touched the space where we’re pushing for new things yet. We always try to drive down latency. It’s a conversation—you can interrupt. There’s some basic behavior there that the models can get better at. Things like tool-calling, making it better and parallelizing it with voice model synthesis. Even just the diversity of voices, languages, and accents; that sounds basic, but it’s actually pretty hard. Those top three things are pretty well known, but it will take us through the rest of the year.
- 30:48: And narrowing the gap between the cloud model and the on-device model.
- 30:52: That’s interesting too. Today we’re making a lot of progress on the smaller on-device models, but when you think of supporting an LLM and a voice model on top of it, it actually gets a little bit hairy, where most people would just go back to commercial models.
- 31:26: What’s one prediction in the consumer AI space that you would make that most people would find surprising?
- 31:37: A lot of people use AI for companionship, and not in the ways that we imagine. Almost everyone I talk to, the utility is very personal. There are a lot of work use cases. But the emerging side of AI is personal. There’s a lot more area for discovery. For example, I use ChatGPT as my running coach. It ingests all of my running data and creates running plans for me. Where would I slot that? It’s not productivity, but it’s not my best friend; it’s just my running coach. More and more people are doing these complicated personal things that are closer to companionship than enterprise use cases.
- 33:02: You were supposed to say Gemini!
- 33:04: I love all of the models. I have a use case for all of them. But we all use all the models. I don’t know anyone who only uses one.
- 33:22: What you’re saying about the nonwork use cases is so true. I come across so many people who treat chatbots as their friends.
- 33:36: I do it all the time now. Once you start doing it, it’s a lot stickier than the work use cases. I took my dog to get groomed, and they wanted me to upload his rabies vaccine. So I started thinking about how well it’s protected. I opened up ChatGPT, and spent eight minutes talking about rabies. People are becoming more curious, and now there’s an immediate outlet for that curiosity. It’s so much fun. There’s so much opportunity for us to continue to explore that.
- 34:48: Doesn’t this indicate that these models will get sticky over time? If I talk to Gemini a lot, why would I switch to ChatGPT?
- 35:04: I agree. We see that now. I like Claude. I like Gemini. But I really like the ChatGPT app. Because the app is a good experience, there’s no reason for me to switch. I’ve talked to ChatGPT so much that there’s no way for me to port my data. There’s data lock-in.
Retrieval Augmented Generation (RAG) is a fundamental approach for building advanced generative AI applications that connect large language models (LLMs) to enterprise knowledge. However, crafting a reliable RAG pipeline is rarely a one-shot process. Teams often need to test dozens of configurations (varying chunking strategies, embedding models, retrieval techniques, and prompt designs) before arriving at a solution that works for their use case. Furthermore, management of high-performing RAG pipeline involves complex deployment, with teams often using manual RAG pipeline management, leading to inconsistent results, time-consuming troubleshooting, and difficulty in reproducing successful configurations. Teams struggle with scattered documentation of parameter choices, limited visibility into component performance, and the inability to systematically compare different approaches. Additionally, the lack of automation creates bottlenecks in scaling the RAG solutions, increases operational overhead, and makes it challenging to maintain quality across multiple deployments and environments from development to production.
In this post, we walk through how to streamline your RAG development lifecycle from experimentation to automation, helping you operationalize your RAG solution for production deployments with Amazon SageMaker AI, helping your team experiment efficiently, collaborate effectively, and drive continuous improvement. By combining experimentation and automation with SageMaker AI, you can verify that the entire pipeline is versioned, tested, and promoted as a cohesive unit. This approach provides comprehensive guidance for traceability, reproducibility, and risk mitigation as the RAG system advances from development to production, supporting continuous improvement and reliable operation in real-world scenarios.
Solution overview
By streamlining both experimentation and operational workflows, teams can use SageMaker AI to rapidly prototype, deploy, and monitor RAG applications at scale. Its integration with SageMaker managed MLflow provides a unified platform for tracking experiments, logging configurations, and comparing results, supporting reproducibility and robust governance throughout the pipeline lifecycle. Automation also minimizes manual intervention, reduces errors, and streamlines the process of promoting the finalized RAG pipeline from the experimentation phase directly into production. With this approach, every stage from data ingestion to output generation operates efficiently and securely, while making it straightforward to transition validated solutions from development to production deployment.
For automation, Amazon SageMaker Pipelines orchestrates end-to-end RAG workflows from data preparation and vector embedding generation to model inference and evaluation all with repeatable and version-controlled code. Integrating continuous integration and delivery (CI/CD) practices further enhances reproducibility and governance, enabling automated promotion of validated RAG pipelines from development to staging or production environments. Promoting an entire RAG pipeline (not just an individual subsystem of the RAG solution like a chunking layer or orchestration layer) to higher environments is essential because data, configurations, and infrastructure can vary significantly across staging and production. In production, you often work with live, sensitive, or much larger datasets, and the way data is chunked, embedded, retrieved, and generated can impact system performance and output quality in ways that are not always apparent in lower environments. Each stage of the pipeline (chunking, embedding, retrieval, and generation) must be thoroughly evaluated with production-like data for accuracy, relevance, and robustness. Metrics at every stage (such as chunk quality, retrieval relevance, answer correctness, and LLM evaluation scores) must be monitored and validated before the pipeline is trusted to serve real users.
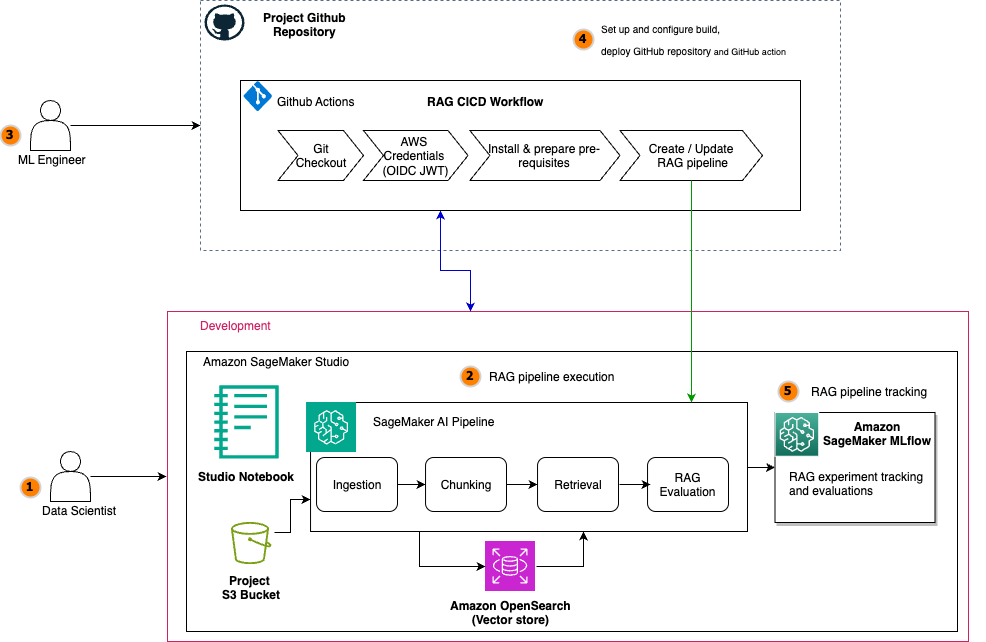
The following diagram illustrates the architecture of a scalable RAG pipeline built on SageMaker AI, with MLflow experiment tracking seamlessly integrated at every stage and the RAG pipeline automated using SageMaker Pipelines. SageMaker managed MLflow provides a unified platform for centralized RAG experiment tracking across all pipeline stages. Every MLflow execution run whether for RAG chunking, ingestion, retrieval, or evaluation sends execution logs, parameters, metrics, and artifacts to SageMaker managed MLflow. The architecture uses SageMaker Pipelines to orchestrate the entire RAG workflow through versioned, repeatable automation. These RAG pipelines manage dependencies between critical stages, from data ingestion and chunking to embedding generation, retrieval, and final text generation, supporting consistent execution across environments. Integrated with CI/CD practices, SageMaker Pipelines enable seamless promotion of validated RAG configurations from development to staging and production environments while maintaining infrastructure as code (IaC) traceability.
For the operational workflow, the solution follows a structured lifecycle: During experimentation, data scientists iterate on pipeline components within Amazon SageMaker Studio notebooks while SageMaker managed MLflow captures parameters, metrics, and artifacts at every stage. Validated workflows are then codified into SageMaker Pipelines and versioned in Git. The automated promotion phase uses CI/CD to trigger pipeline execution in target environments, rigorously validating stage-specific metrics (chunk quality, retrieval relevance, answer correctness) against production data before deployment. The other core components include:
- Amazon SageMaker JumpStart for accessing the latest LLM models and hosting them on SageMaker endpoints for model inference with the embedding model
huggingface-textembedding-all-MiniLM-L6-v2and text generation modeldeepseek-llm-r1-distill-qwen-7b. - Amazon OpenSearch Service as a vector database to store document embeddings with the OpenSearch index configured for k-nearest neighbors (k-NN) search.
- The Amazon Bedrock model
anthropic.claude-3-haiku-20240307-v1:0as an LLM-as-a-judge component for all the MLflow LLM evaluation metrics. - A SageMaker Studio notebook for a development environment to experiment and automate the RAG pipelines with SageMaker managed MLflow and SageMaker Pipelines.
You can implement this agentic RAG solution code from the GitHub repository. In the following sections, we use snippets from this code in the repository to illustrate RAG pipeline experiment evolution and automation.
Prerequisites
You must have the following prerequisites:
- An AWS account with billing enabled.
- A SageMaker AI domain. For more information, see Use quick setup for Amazon SageMaker AI.
- Access to a running SageMaker managed MLflow tracking server in SageMaker Studio. For more information, see the instructions for setting up a new MLflow tracking server.
- Access to SageMaker JumpStart to host LLM embedding and text generation models.
- Access to the Amazon Bedrock foundation models (FMs) for RAG evaluation tasks. For more details, see Subscribe to a model.
SageMaker MLFlow RAG experiment
SageMaker managed MLflow provides a powerful framework for organizing RAG experiments, so teams can manage complex, multi-stage processes with clarity and precision. The following diagram illustrates the RAG experiment stages with SageMaker managed MLflow experiment tracking at every stage. This centralized tracking offers the following benefits:
- Reproducibility: Every experiment is fully documented, so teams can replay and compare runs at any time
- Collaboration: Shared experiment tracking fosters knowledge sharing and accelerates troubleshooting
- Actionable insights: Visual dashboards and comparative analytics help teams identify the impact of pipeline changes and drive continuous improvement
The following diagram illustrates the solution workflow.
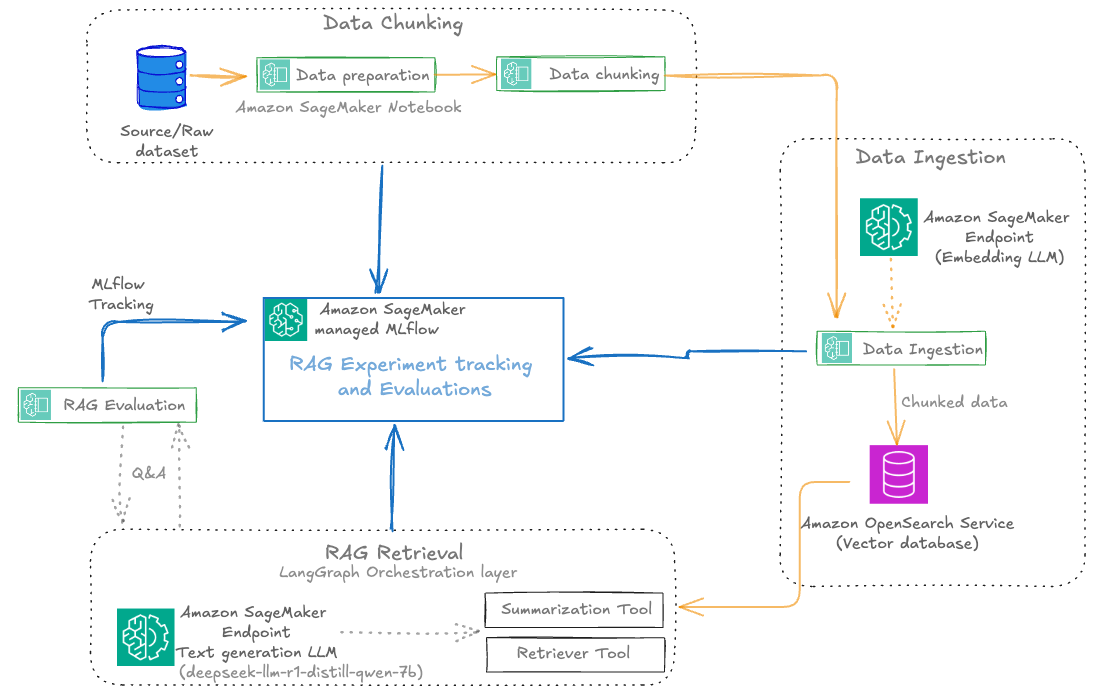
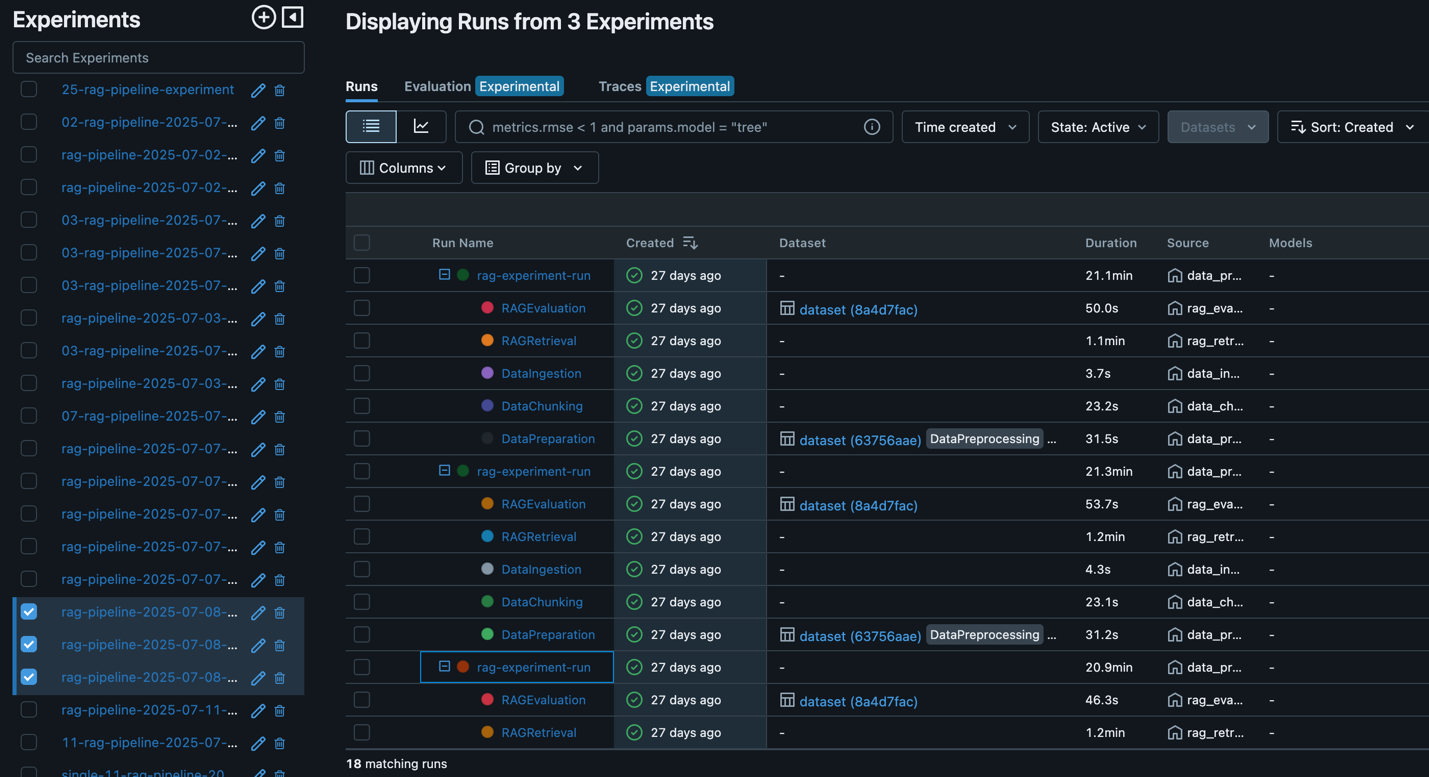
Each RAG experiment in MLflow is structured as a top-level run under a specific experiment name. Within this top-level run, nested runs are created for each major pipeline stage, such as data preparation, data chunking, data ingestion, RAG retrieval, and RAG evaluation. This hierarchical approach allows for granular tracking of parameters, metrics, and artifacts at every step, while maintaining a clear lineage from raw data to final evaluation results.
The following screenshot shows an example of the experiment details in MLflow.
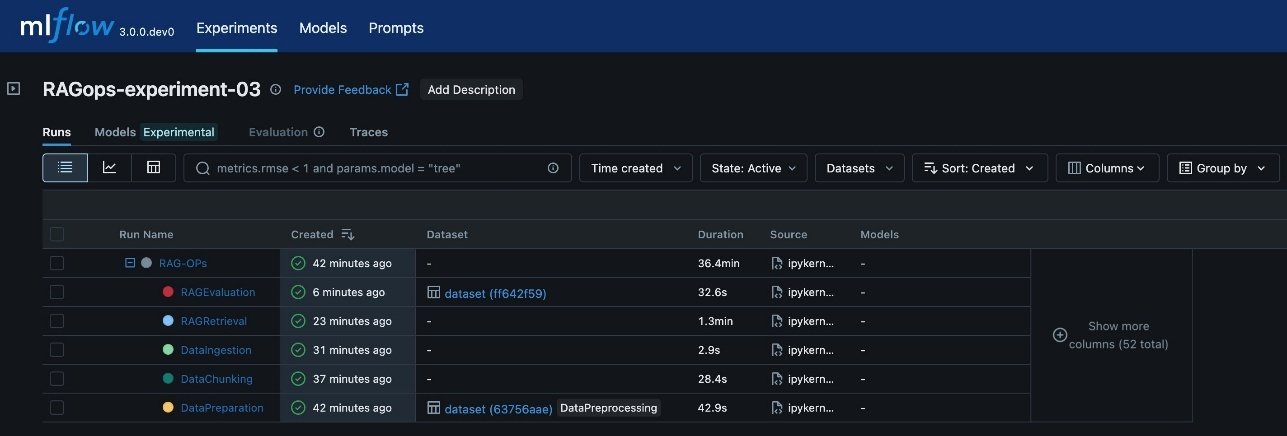
The various RAG pipeline steps defined are:
- Data preparation: Logs dataset version, preprocessing steps, and initial statistics
- Data chunking: Records chunking strategy, chunk size, overlap, and resulting chunk counts
- Data ingestion: Tracks embedding model, vector database details, and document ingestion metrics
- RAG retrieval: Captures retrieval model, context size, and retrieval performance metrics
- RAG evaluation: Logs evaluation metrics (such as answer similarity, correctness, and relevance) and sample results
This visualization provides a clear, end-to-end view of the RAG pipeline’s execution, so you can trace the impact of changes at any stage and achieve full reproducibility. The architecture supports scaling to multiple experiments, each representing a distinct configuration or hypothesis (for example, different chunking strategies, embedding models, or retrieval parameters). MLflow’s experiment UI visualizes these experiments side by side, enabling side-by-side comparison and analysis across runs. This structure is especially valuable in enterprise settings, where dozens or even hundreds of experiments might be conducted to optimize RAG performance.
We use MLflow experimentation throughout the RAG pipeline to log metrics and parameters, and the different experiment runs are initialized as shown in the following code snippet:
RAG pipeline experimentation
The key components of the RAG workflow are ingestion, chunking, retrieval, and evaluation, which we explain in this section. The MLflow dashboard makes it straightforward to visualize and analyze these parameters and metrics, supporting data-driven refinement of the chunking stage within the RAG pipeline.

Data ingestion and preparation
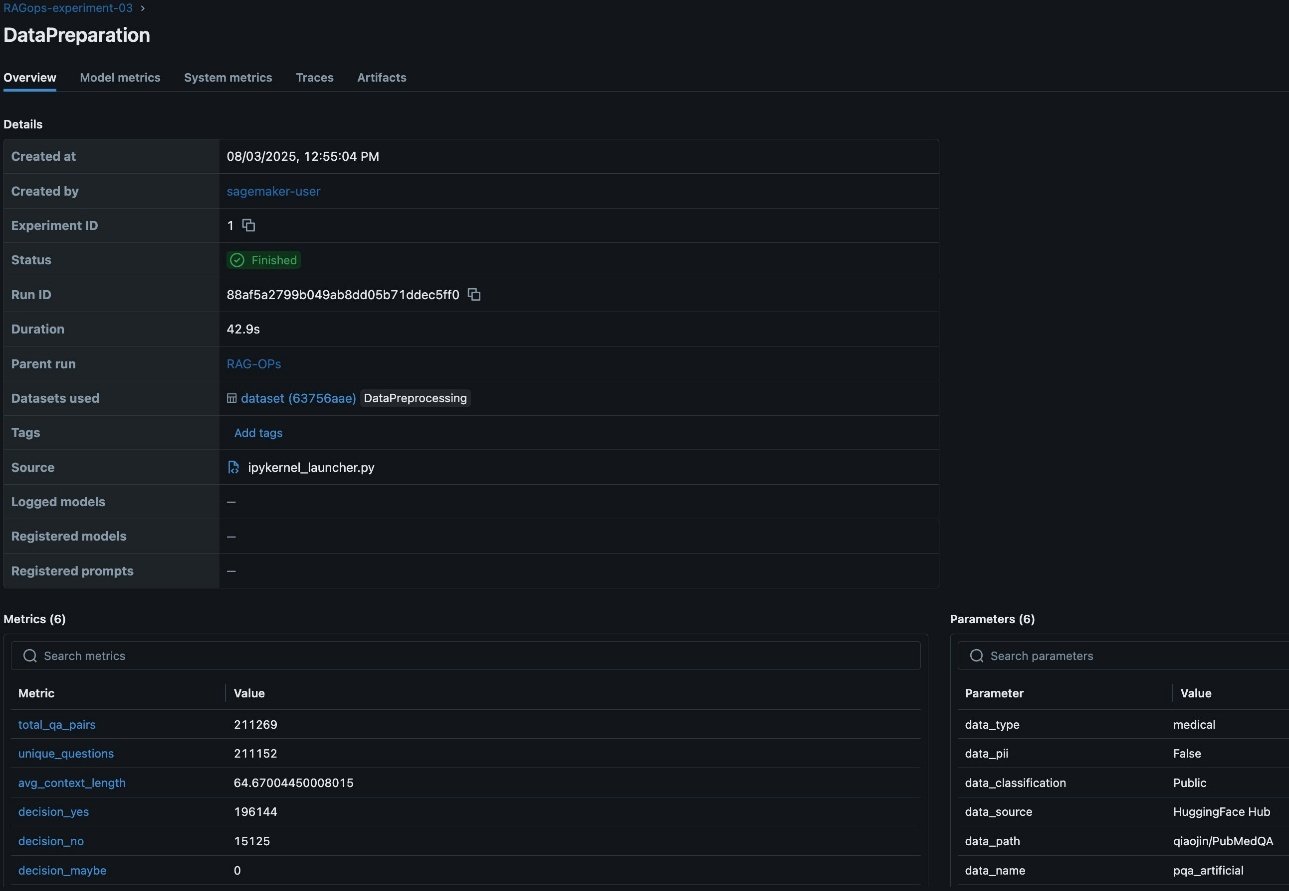
In the RAG workflow, rigorous data preparation is foundational to downstream performance and reliability. Tracking detailed metrics on data quality, such as the total number of question-answer pairs, the count of unique questions, average context length, and initial evaluation predictions, provides essential visibility into the dataset’s structure and suitability for RAG tasks. These metrics help validate the dataset is comprehensive, diverse, and contextually rich, which directly impacts the relevance and accuracy of the RAG system’s responses. Additionally, logging critical RAG parameters like the data source, detected personally identifiable information (PII) types, and data lineage information is vital for maintaining compliance, reproducibility, and trust in enterprise environments. Capturing this metadata in SageMaker managed MLflow supports robust experiment tracking, auditability, efficient comparison, and root cause analysis across multiple data preparation runs, as visualized in the MLflow dashboard. This disciplined approach to data preparation lays the groundwork for effective experimentation, governance, and continuous improvement throughout the RAG pipeline. The following screenshot shows an example of the experiment run details in MLflow.
Data chunking
After data preparation, the next step is to split documents into manageable chunks for efficient embedding and retrieval. This process is pivotal, because the quality and granularity of chunks directly affect the relevance and completeness of answers returned by the RAG system. The RAG workflow in this post supports experimentation and RAG pipeline automation with both fixed-size and recursive chunking strategies for comparison and validations. However, this RAG solution can be expanded to many other chucking techniques.
FixedSizeChunkerdivides text into uniform chunks with configurable overlapRecursiveChunkersplits text along logical boundaries such as paragraphs or sentences
Tracking detailed chunking metrics such as total_source_contexts_entries, total_contexts_chunked, and total_unique_chunks_final is crucial for understanding how much of the source data is represented, how effectively it is segmented, and whether the chunking approach is yielding the desired coverage and uniqueness. These metrics help diagnose issues like excessive duplication or under-segmentation, which can impact retrieval accuracy and model performance.
Additionally, logging parameters such as chunking_strategy_type (for example, FixedSizeChunker), chunking_strategy_chunk_size (for example, 500 characters), and chunking_strategy_chunk_overlap provide transparency and reproducibility for each experiment. Capturing these details in SageMaker managed MLflow helps teams systematically compare the impact of different chunking configurations, optimize for efficiency and contextual relevance, and maintain a clear audit trail of how chunking decisions evolve over time. The MLflow dashboard makes it straightforward to visualize and analyze these parameters and metrics, supporting data-driven refinement of the chunking stage within the RAG pipeline. The following screenshot shows an example of the experiment run details in MLflow.

After the documents are chunked, the next step is to convert these chunks into vector embeddings using a SageMaker embedding endpoint, after which the embeddings are ingested into a vector database such as OpenSearch Service for fast semantic search. This ingestion phase is crucial because the quality, completeness, and traceability of what enters the vector store directly determine the effectiveness and reliability of downstream retrieval and generation stages.
Tracking ingestion metrics such as the number of documents and chunks ingested provides visibility into pipeline throughput and helps identify bottlenecks or data loss early in the process. Logging detailed parameters, including the embedding model ID, endpoint used, and vector database index, is essential for reproducibility and auditability. This metadata helps teams trace exactly which model and infrastructure were used for each ingestion run, supporting root cause analysis and compliance, especially when working with evolving datasets or sensitive information.
Retrieval and generation
For a given query, we generate an embedding and retrieve the top-k relevant chunks from OpenSearch Service. For answer generation, we use a SageMaker LLM endpoint. The retrieved context and the query are combined into a prompt, and the LLM generates an answer. Finally, we orchestrate retrieval and generation using LangGraph, enabling stateful workflows and advanced tracing:
With the GenerativeAI agent defined with LangGraph framework, the agentic layers are evaluated for each iteration of RAG development, verifying the efficacy of the RAG solution for agentic applications. Each retrieval and generation run is logged to SageMaker managed MLflow, capturing the prompt, generated response, and key metrics and parameters such as retrieval performance, top-k values, and the specific model endpoints used. Tracking these details in MLflow is essential for evaluating the effectiveness of the retrieval stage, making sure the returned documents are relevant and that the generated answers are accurate and complete. It is equally important to track the performance of the vector database during retrieval, including metrics like query latency, throughput, and scalability. Monitoring these system-level metrics alongside retrieval relevance and accuracy makes sure the RAG pipeline delivers correct and relevant answers and meets production requirements for responsiveness and scalability. The following screenshot shows an example of the Langraph RAG retrieval tracing in MLflow.

RAG Evaluation
Evaluation is conducted on a curated test set, and results are logged to MLflow for quick comparison and analysis. This helps teams identify the best-performing configurations and iterate toward production-grade solutions. With MLflow you can evaluate the RAG solution with heuristics metrics, content similarity metrics and LLM-as-a-judge. In this post, we evaluate the RAG pipeline using advanced LLM-as-a-judge MLflow metrics (answer similarity, correctness, relevance, faithfulness):
The following screenshot shows an RAG evaluation stage experiment run details in MLflow.

You can use MLflow to log all metrics and parameters, enabling quick comparison of different experiment runs. See the following code for reference:
By using MLflow’s evaluation capabilities (such as mlflow.evaluate()), teams can systematically assess retrieval quality, identify potential gaps or misalignments in chunking or embedding strategies, and compare the performance of different retrieval and generation configurations. MLflow’s flexibility allows for seamless integration with external libraries and evaluation libraries such as RAGAS for comprehensive RAG pipeline assessment. RAGAS is an open source library that provide tools specifically for evaluation of LLM applications and generative AI agents. RAGAS includes the method ragas.evaluate() to run evaluations for LLM agents with the choice of LLM models (evaluators) for scoring the evaluation, and an extensive list of default metrics. To incorporate RAGAS metrics into your MLflow experiments, refer to the following GitHub repository.
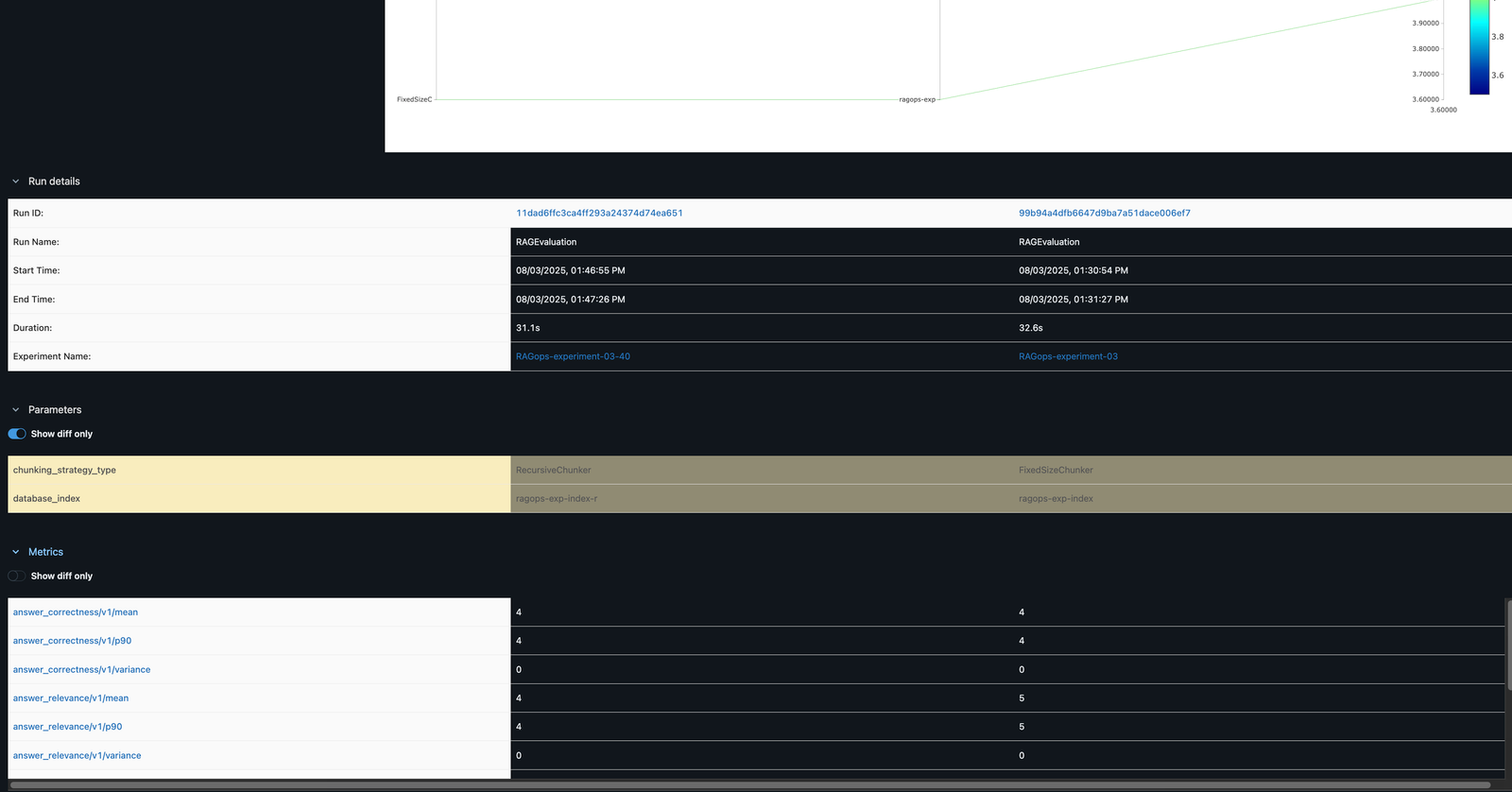
Comparing experiments
In the MLflow UI, you can compare runs side by side. For example, comparing FixedSizeChunker and RecursiveChunker as shown in the following screenshot reveals differences in metrics such as answer_similarity (a difference of 1 point), providing actionable insights for pipeline optimization.
Automation with Amazon SageMaker pipelines
After systematically experimenting with and optimizing each component of the RAG workflow through SageMaker managed MLflow, the next step is transforming these validated configurations into production-ready automated pipelines. Although MLflow experiments help identify the optimal combination of chunking strategies, embedding models, and retrieval parameters, manually reproducing these configurations across environments can be error-prone and inefficient.
To produce the automated RAG pipeline, we use SageMaker Pipelines, which helps teams codify their experimentally validated RAG workflows into automated, repeatable pipelines that maintain consistency from development through production. By converting the successful MLflow experiments into pipeline definitions, teams can make sure the exact same chunking, embedding, retrieval, and evaluation steps that performed well in testing are reliably reproduced in production environments.
SageMaker Pipelines offers a serverless workflow orchestration for converting experimental notebook code into a production-grade pipeline, versioning and tracking pipeline configurations alongside MLflow experiments, and automating the end-to-end RAG workflow. The automated Sagemaker pipeline-based RAG workflow offers dependency management, comprehensive custom testing and validation before production deployment, and CI/CD integration for automated pipeline promotion.
With SageMaker Pipelines, you can automate your entire RAG workflow, from data preparation to evaluation, as reusable, parameterized pipeline definitions. This provides the following benefits:
- Reproducibility – Pipeline definitions capture all dependencies, configurations, and executions logic in version-controlled code
- Parameterization – Key RAG parameters (chunk sizes, model endpoints, retrieval settings) can be quickly modified between runs
- Monitoring – Pipeline executions provide detailed logs and metrics for each step
- Governance – Built-in lineage tracking supports full audibility of data and model artifacts
- Customization – Serverless workflow orchestration is customizable to your unique enterprise landscape, with scalable infrastructure and flexibility with instances optimized for CPU, GPU, or memory-intensive tasks, memory configuration, and concurrency optimization
To implement a RAG workflow in SageMaker pipelines, each major component of the RAG process (data preparation, chunking, ingestion, retrieval and generation, and evaluation) is included in a SageMaker processing job. These jobs are then orchestrated as steps within a pipeline, with data flowing between them, as shown in the following screenshot. This structure allows for modular development, quick debugging, and the ability to reuse components across different pipeline configurations.
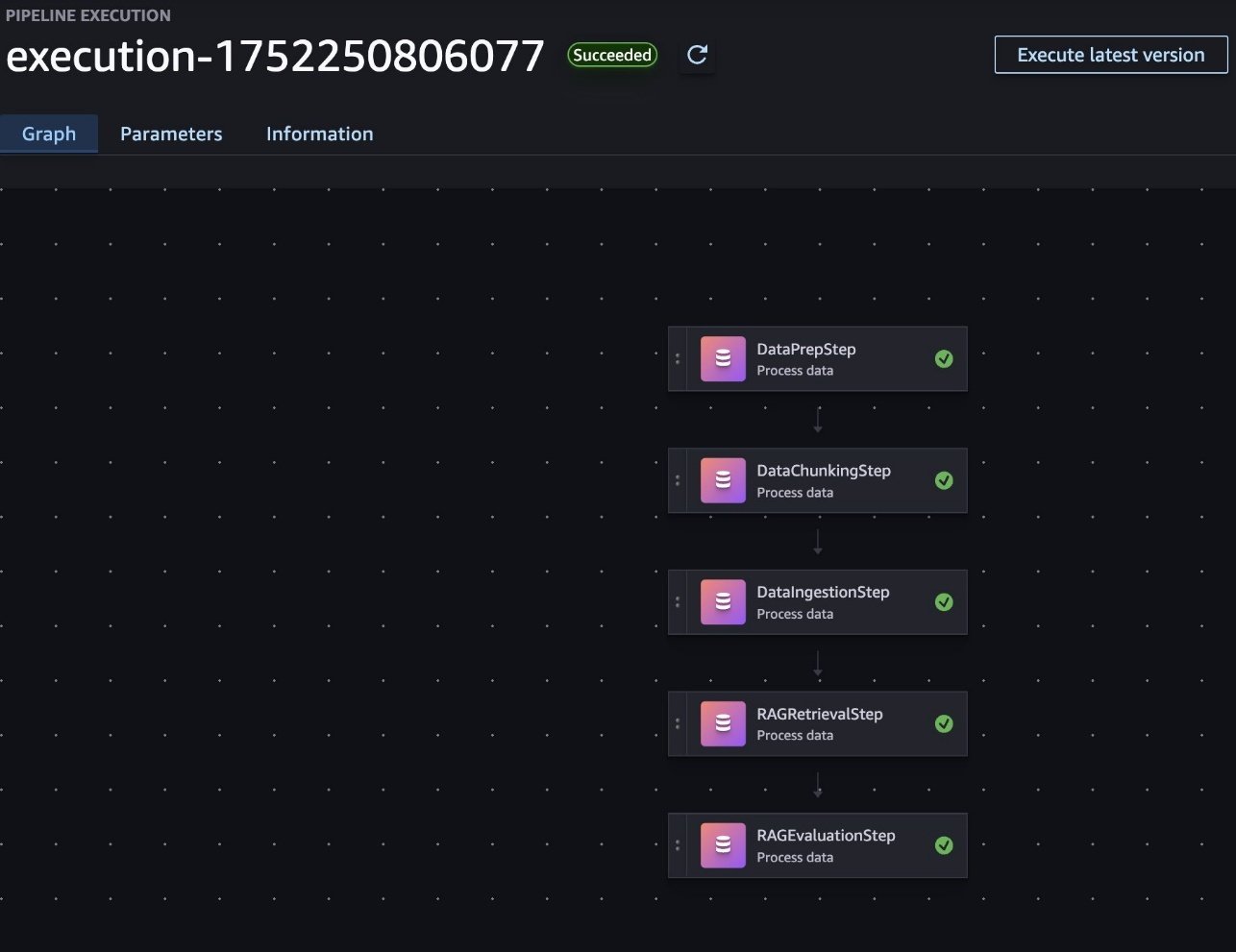
The key RAG configurations are exposed as pipeline parameters, enabling flexible experimentation with minimal code changes. For example, the following code snippets showcase the modifiable parameters for RAG configurations, which can be used as pipeline configurations:
In this post, we provide two agentic RAG pipeline automation approaches to building the SageMaker pipeline, each with own benefits: single-step SageMaker pipelines and multi-step pipelines.
The single-step pipeline approach is designed for simplicity, running the entire RAG workflow as one unified process. This setup is ideal for straightforward or less complex use cases, because it minimizes pipeline management overhead. With fewer steps, the pipeline can start quickly, benefitting from reduced execution times and streamlined development. This makes it a practical option when rapid iteration and ease of use are the primary concerns.
The multi-step pipeline approach is preferred for enterprise scenarios where flexibility and modularity are essential. By breaking down the RAG process into distinct, manageable stages, organizations gain the ability to customize, swap, or extend individual components as needs evolve. This design enables plug-and-play adaptability, making it straightforward to reuse or reconfigure pipeline steps for various workflows. Additionally, the multi-step format allows for granular monitoring and troubleshooting at each stage, providing detailed insights into performance and facilitating robust enterprise management. For enterprises seeking maximum flexibility and the ability to tailor automation to unique requirements, the multi-step pipeline approach is the superior choice.
CI/CD for an agentic RAG pipeline
Now we integrate the SageMaker RAG pipeline with CI/CD. CI/CD is important for making a RAG solution enterprise-ready because it provides faster, more reliable, and scalable delivery of AI-powered workflows. Specifically for enterprises, CI/CD pipelines automate the integration, testing, deployment, and monitoring of changes in the RAG system, which brings several key benefits, such as faster and more reliable updates, version control and traceability, consistency across environments, modularity and flexibility for customization, enhanced collaboration and monitoring, risk mitigation, and cost savings. This aligns with general CI/CD benefits in software and AI systems, emphasizing automation, quality assurance, collaboration, and continuous feedback essential to enterprise AI readiness.
When your SageMaker RAG pipeline definition is in place, you can implement robust CI/CD practices by integrating your development workflow and toolsets already enabled at your enterprise. This setup makes it possible to automate code promotion, pipeline deployment, and model experimentation through simple Git triggers, so changes are versioned, tested, and systematically promoted across environments. For demonstration, in this post, we show the CI/CD integration using GitHub Actions and by using GitHub Actions as the CI/CD orchestrator. Each code change, such as refining chunking strategies or updating pipeline steps, triggers an end-to-end automation workflow, as shown in the following screenshot. You can use the same CI/CD pattern with your choice of CI/CD tool instead of GitHub Actions, if needed.
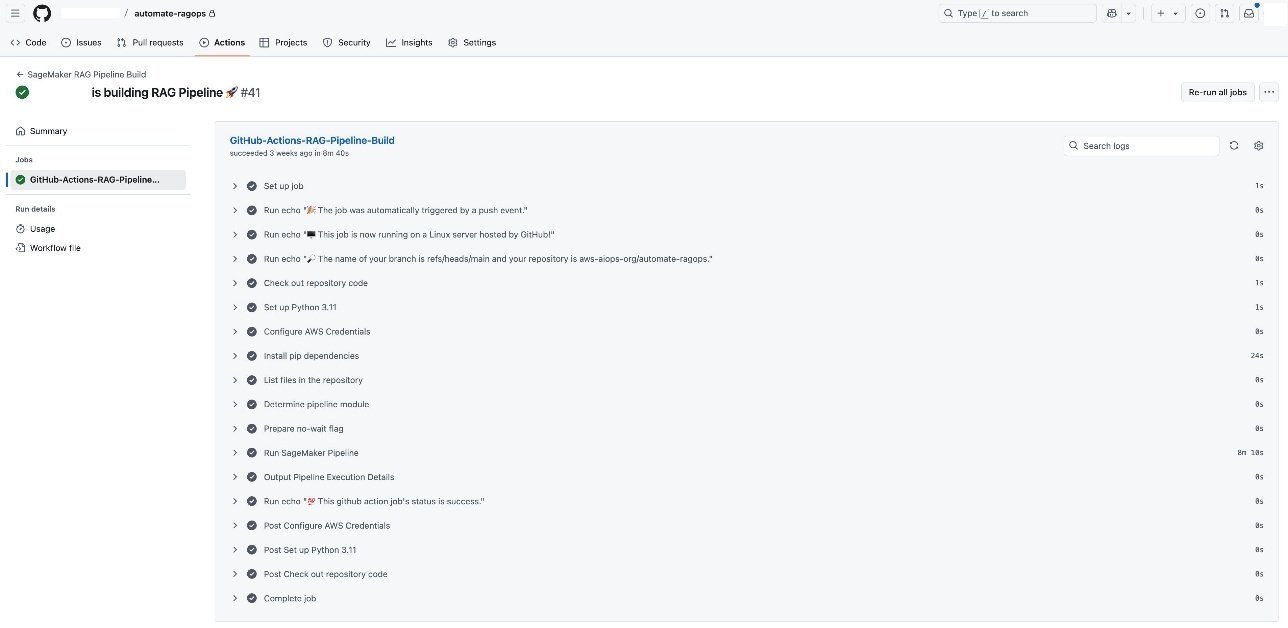
Each GitHub Actions CI/CD execution automatically triggers the SageMaker pipeline (shown in the following screenshot), allowing for seamless scaling of serverless compute infrastructure.
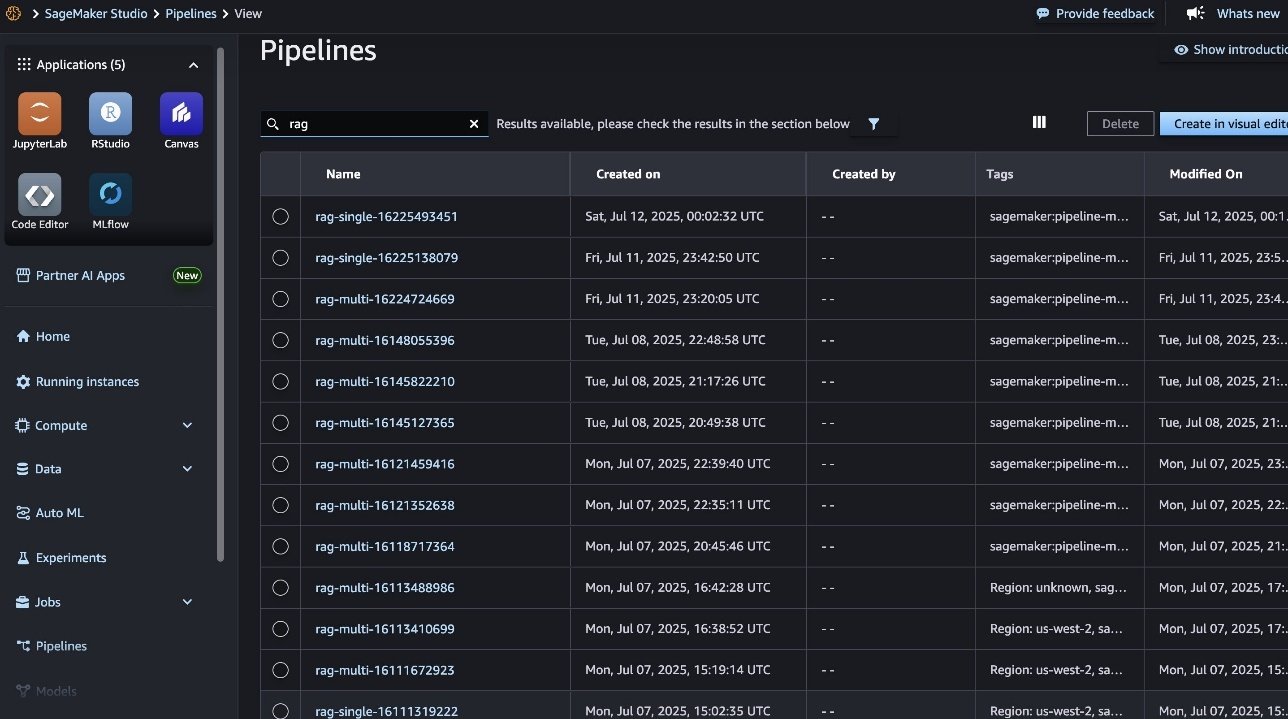
Throughout this cycle, SageMaker managed MLflow records every executed pipeline (shown in the following screenshot), so you can seamlessly review results, compare performance across different pipeline runs, and manage the RAG lifecycle.
After an optimal RAG pipeline configuration is determined, the new desired configuration (Git version tracking captured in MLflow as shown in the following screenshot) can be promoted to higher stages or environments directly through an automated workflow, minimizing manual intervention and reducing risk.

Clean up
To avoid unnecessary costs, delete resources such as the SageMaker managed MLflow tracking server, SageMaker pipelines, and SageMaker endpoints when your RAG experimentation is complete. You can visit the SageMaker Studio console to destroy resources that aren’t needed anymore or call appropriate AWS APIs actions.
Conclusion
By integrating SageMaker AI, SageMaker managed MLflow, and Amazon OpenSearch Service, you can build, evaluate, and deploy RAG pipelines at scale. This approach provides the following benefits:
- Automated and reproducible workflows with SageMaker Pipelines and MLflow, minimizing manual steps and reducing the risk of human error
- Advanced experiment tracking and comparison for different chunking strategies, embedding models, and LLMs, so every configuration is logged, analyzed, and reproducible
- Actionable insights from both traditional and LLM-based evaluation metrics, helping teams make data-driven improvements at every stage
- Seamless deployment to production environments, with automated promotion of validated pipelines and robust governance throughout the workflow
Automating your RAG pipeline with SageMaker Pipelines brings additional benefits: it enables consistent, version-controlled deployments across environments, supports collaboration through modular, parameterized workflows, and supports full traceability and auditability of data, models, and results. With built-in CI/CD capabilities, you can confidently promote your entire RAG solution from experimentation to production, knowing that each stage meets quality and compliance standards.
Now it’s your turn to operationalize RAG workflows and accelerate your AI initiatives. Explore SageMaker Pipelines and managed MLflow using the solution from the GitHub repository to unlock scalable, automated, and enterprise-grade RAG solutions.
About the authors
 Sandeep Raveesh is a GenAI Specialist Solutions Architect at AWS. He works with customers through their AIOps journey across model training, generative AI applications like agents, and scaling generative AI use cases. He also focuses on Go-To-Market strategies, helping AWS build and align products to solve industry challenges in the generative AI space. You can find Sandeep on LinkedIn.
Sandeep Raveesh is a GenAI Specialist Solutions Architect at AWS. He works with customers through their AIOps journey across model training, generative AI applications like agents, and scaling generative AI use cases. He also focuses on Go-To-Market strategies, helping AWS build and align products to solve industry challenges in the generative AI space. You can find Sandeep on LinkedIn.
 Blake Shin is an Associate Specialist Solutions Architect at AWS who enjoys learning about and working with new AI/ML technologies. In his free time, Blake enjoys exploring the city and playing music.
Blake Shin is an Associate Specialist Solutions Architect at AWS who enjoys learning about and working with new AI/ML technologies. In his free time, Blake enjoys exploring the city and playing music.
Books, Courses & Certifications
Unlock model insights with log probability support for Amazon Bedrock Custom Model Import

You can use Amazon Bedrock Custom Model Import to seamlessly integrate your customized models—such as Llama, Mistral, and Qwen—that you have fine-tuned elsewhere into Amazon Bedrock. The experience is completely serverless, minimizing infrastructure management while providing your imported models with the same unified API access as native Amazon Bedrock models. Your custom models benefit from automatic scaling, enterprise-grade security, and native integration with Amazon Bedrock features such as Amazon Bedrock Guardrails and Amazon Bedrock Knowledge Bases.
Understanding how confident a model is in its predictions is essential for building reliable AI applications, particularly when working with specialized custom models that might encounter domain-specific queries.
With log probability support now added to Custom Model Import, you can access information about your models’ confidence in their predictions at the token level. This enhancement provides greater visibility into model behavior and enables new capabilities for model evaluation, confidence scoring, and advanced filtering techniques.
In this post, we explore how log probabilities work with imported models in Amazon Bedrock. You will learn what log probabilities are, how to enable them in your API calls, and how to interpret the returned data. We also highlight practical applications—from detecting potential hallucinations to optimizing RAG systems and evaluating fine-tuned models—that demonstrate how these insights can improve your AI applications, helping you build more trustworthy solutions with your custom models.
Understanding log probabilities
In language models, a log probability represents the logarithm of the probability that the model assigns to a token in a sequence. These values indicate how confident the model is about each token it generates or processes. Log probabilities are expressed as negative numbers, with values closer to zero indicating higher confidence. For example, a log probability of -0.1 corresponds to approximately 90% confidence, while a value of -3.0 corresponds to about 5% confidence. By examining these values, you can identify when a model is highly certain versus when it’s making less confident predictions. Log probabilities provide a quantitative measure of how likely the model considered each generated token, offering valuable insight into the confidence of its output. By analyzing them you can,
- Gauge confidence across a response: Assess how confident the model was in different sections of its output, helping you identify where it was certain versus uncertain.
- Score and compare outputs: Compare overall sequence likelihood (by adding or averaging log probabilities) to rank or filter multiple model outputs.
- Detect potential hallucinations: Identify sudden drops in token-level confidence, which can flag segments that might require verification or review.
- Reduce RAG costs with early pruning: Run short, low-cost draft generations based on retrieved contexts, compute log probabilities for those drafts, and discard low-scoring candidates early, avoiding unnecessary full-length generations or expensive reranking while keeping only the most promising contexts in the pipeline.
- Build confidence-aware applications: Adapt system behavior based on certainty levels—for example, trigger clarifying prompts, provide fallback responses, or flagging for human review.
Overall, log probabilities are a powerful tool for interpreting and debugging model responses with measurable certainty—particularly valuable for applications where understanding why a model responded in a certain way can be as important as the response itself.
Prerequisites
To use log probability support with custom model import in Amazon Bedrock, you need:
- An active AWS account with access to Amazon Bedrock
- A custom model created in Amazon Bedrock using the Custom Model Import feature after July 31, 2025, when the log probabilities support was released
- Appropriate AWS Identity and Access Management (IAM) permissions to invoke models through the Amazon Bedrock Runtime
Introducing log probabilities support in Amazon Bedrock
With this release, Amazon Bedrock now allows models imported using the Custom Model Import feature to return token-level log probabilities as part of the inference response.
When invoking a model through Amazon Bedrock InvokeModel API, you can access token log probabilities by setting "return_logprobs": true in the JSON request body. With this flag enabled, the model’s response will include additional fields providing log probabilities for both the prompt tokens and the generated tokens, so that customers can analyze the model’s confidence in its predictions. These log probabilities let you quantitatively assess how confident your custom models are when processing inputs and generating responses. The granular metrics allow for better evaluation of response quality, troubleshooting of unexpected outputs, and optimization of prompts or model configurations.
Let’s walk through an example of invoking a custom model on Amazon Bedrock with log probabilities enabled and examine the output format. Suppose you have already imported a custom model (for instance, a fine-tuned Llama 3.2 1B model) into Amazon Bedrock and have its model Amazon Resource Name (ARN). You can invoke this model using the Amazon Bedrock Runtime SDK (Boto3 for Python in this example) as shown in the following example:
In the preceding code, we send a prompt—"The quick brown fox jumps"—to our custom imported model. We configure standard inference parameters: a maximum generation length of 50 tokens, a moderate temperature of 0.5 for moderate randomness, and a stop condition (either a period or a newline). The "return_logprobs":True parameter tells Amazon Bedrock to return log probabilities in the response.
The InvokeModel API returns a JSON response containing three main components: the standard generated text output, metadata about the generation process, and now log probabilities for both prompt and generated tokens. These values reveal the model’s internal confidence for each token prediction, so you can understand not just what text was produced, but how certain the model was at each step of the process. The following is an example response from the "quick brown fox jumps" prompt, showing log probabilities (appearing as negative numbers):
The raw API response provides token IDs paired with their log probabilities. To make this data interpretable, we need to first decode the token IDs using the appropriate tokenizer (in this case, the Llama 3.2 1B tokenizer), which maps each ID back to its actual text token. Then we convert log probabilities to probabilities by applying the exponential function, translating these values into more intuitive probabilities between 0 and 1. We have implemented these transformations using custom code (not shown here) to produce a human-readable format where each token appears alongside its probability, making the model’s confidence in its predictions immediately clear.
Let’s break down what this tells us about the model’s internal processing:
generation: This is the actual text generated by the model (in our example, it’s a continuation of the prompt that we sent to the model). This is the same field you would get normally from any model invocation.prompt_token_countandgeneration_token_count: These indicate the number of tokens in the input prompt and in the output, respectively. In our example, the prompt was tokenized into six tokens, and the model generated five tokens in its completion.stop_reason: The reason the generation stopped ("stop"means the model naturally stopped at a stop sequence or end-of-text,"length"means it hit the max token limit, and so on). In our case it shows"stop", indicating the model stopped on its own or because of the stop condition we provided.prompt_logprobs: This array provides log probabilities for each token in the prompt. As the model processes your input, it continuously predicts what should come next based on what it has seen so far. These values measure which tokens in your prompt were expected or surprising to the model.- The first entry is
Nonebecause the very first token has no preceding context. The model cannot predict anything without prior information. Each subsequent entry contains token IDs mapped to their log probabilities. We have converted these IDs to readable text and transformed the log probabilities into percentages for easier understanding. - You can observe the model’s increasing confidence as it processes familiar sequences. For example, after seeing The quick brown, the model predicted fox with 95.1% confidence. After seeing the full context up to fox, it predicted jumps with 81.1% confidence.
- Many positions show multiple tokens with their probabilities, revealing alternatives the model considered. For instance, at the second position, the model evaluated both The (2.7%) and Question (30.6%), which means the model considered both tokens viable at that position. This added visibility helps you understand where the model weighted alternatives and can reveal when it was more uncertain or had difficulty choosing from multiple options.
- Notably low probabilities appear for some tokens—quick received just 0.01%—indicating the model found these words unexpected in their context.
- The overall pattern tells a clear story: individual words initially received low probabilities, but as the complete quick brown fox jumps phrase emerged, the model’s confidence increased dramatically, showing it recognized this as a familiar expression.
- When multiple tokens in your prompt consistently receive low probabilities, your phrasing might be unusual for the model. This uncertainty can affect the quality of completions. Using these insights, you can reformulate prompts to better align with patterns the model encountered in its training data.
- The first entry is
logprobs: This array contains log probabilities for each token in the model’s generated output. The format is similar: a dictionary mapping token IDs to their corresponding log probabilities.- After decoding these values, we can see that the tokens over, the, lazy, and dog all have high probabilities. This demonstrates the model recognized it was completing the well-known phrase the quick brown fox jumps over the lazy dog—a common pangram that the model appears to have strong familiarity with.
- In contrast, the final period (newline) token has a much lower probability (30.3%), revealing the model’s uncertainty about how to conclude the sentence. This makes sense because the model had multiple valid options: ending the sentence with a period, continuing with additional content, or choosing another punctuation mark altogether.
Practical use cases of log probabilities
Token-level log probabilities from the Custom Model Import feature provide valuable insights into your model’s decision-making process. These metrics transform how you interact with your custom models by revealing their confidence levels for each generated token. Here are impactful ways to use these insights:
Ranking multiple completions
You can use log probabilities to quantitatively rank multiple generated outputs for the same prompt. When your application needs to choose between different possible completions—whether for summarization, translation, or creative writing—you can calculate each completion’s overall likelihood by averaging or adding the log probabilities across all its tokens.
Example:
Prompt: Translate the phrase "Battre le fer pendant qu'il est chaud"
- Completion A:
"Strike while the iron is hot"(Average log probability: -0.39) - Completion B:
"Beat the iron while it is hot."(Average log probability: -0.46)
In this example, Completion A receives a higher log probability score (closer to zero), indicating the model found this idiomatic translation more natural than the more literal Completion B. This numerical approach enables your application to automatically select the most probable output or present multiple candidates ranked by the model’s confidence level.
This ranking capability extends beyond translation to many scenarios where multiple valid outputs exist—including content generation, code completion, and creative writing—providing an objective quality metric based on the model’s confidence rather than relying solely on subjective human judgment.
Detecting hallucinations and low-confidence answers
Models might produce hallucinations—plausible-sounding but factually incorrect statements—when handling ambiguous prompts, complex queries, or topics outside their expertise. Log probabilities provide a practical way to detect these instances by revealing the model’s internal uncertainty, helping you identify potentially inaccurate information even when the output appears confident.
By analyzing token-level log probabilities, you can identify which parts of a response the model was potentially uncertain about, even when the text appears confident on the surface. This capability is especially valuable in retrieval-augmented generation (RAG) systems, where responses should be grounded in retrieved context. When a model has relevant information available, it typically generates answers with higher confidence. Conversely, low confidence across multiple tokens suggests the model might be generating content without sufficient supporting information.
Example:
- Prompt:
- Model output:
In this example, we intentionally asked about a fictional metric—Portfolio Synergy Quotient (PSQ)—to demonstrate how log probabilities reveal uncertainty in model responses. Despite producing a professional-sounding definition for this non-existent financial concept, the token-level confidence scores tell a revealing story. The confidence scores shown below are derived by applying the exponential function to the log probabilities returned by the model.
- PSQ shows medium confidence (63.8%), indicating that the model recognized the acronym format but wasn’t highly certain about this specific term.
- Common finance terminology like classes (98.2%) and portfolio (92.8%) exhibit high confidence, likely because these are standard concepts widely used in financial contexts.
- Critical connecting concepts show notably low confidence: measure (14.0%) and diversification (31.8%), reveal the model’s uncertainty when attempting to explain what PSQ means or does.
- Functional words like is (45.9%) and of (56.6%) hover in the medium confidence levels, suggesting uncertainty about the overall structure of the explanation.
By identifying these low-confidence segments, you can implement targeted safeguards in your applications—such as flagging content for verification, retrieving additional context, generating clarifying questions, or applying confidence thresholds for sensitive information. This approach helps create more reliable AI systems that can distinguish between high-confidence knowledge and uncertain responses.
Monitoring prompt quality
When engineering prompts for your application, log probabilities reveal how well the model understands your instructions. If the first few generated tokens show unusually low probabilities, it often signals that the model struggled to interpret what you are asking.
By tracking the average log probability of the initial tokens—typically the first 5–10 generated tokens—you can quantitatively measure prompt clarity. Well-structured prompts with clear context typically produce higher probabilities because the model immediately knows what to do. Vague or underspecified prompts often yield lower initial token likelihoods as the model hesitates or searches for direction.
Example:
Prompt comparison for customer service responses:
- Basic prompt:
- Average log probability of first five tokens: -1.215 (lower confidence)
- Optimized prompt:
- Average log probability of first five tokens: -0.333 (higher confidence)
The optimized prompt generates higher log probabilities, demonstrating that precise instructions and clear context reduce the model’s uncertainty. Rather than making absolute judgments about prompt quality, this approach lets you measure relative improvement between versions. You can directly observe how specific elements—role definitions, contextual details, and explicit expectations—increase model confidence. By systematically measuring these confidence scores across different prompt iterations, you build a quantitative framework for prompt engineering that reveals exactly when and how your instructions become unclear to the model, enabling continuous data-driven refinement.
Reducing RAG costs with early pruning
In traditional RAG implementations, systems retrieve 5–20 documents and generate complete responses using these retrieved contexts. This approach drives up inference costs because every retrieved context consumes tokens regardless of actual usefulness.
Log probabilities enable a more cost-effective alternative through early pruning. Instead of immediately processing the retrieved documents in full:
- Generate draft responses based on each retrieved context
- Calculate the average log probability across these short drafts
- Rank contexts by their average log probability scores
- Discard low-scoring contexts that fall below a confidence threshold
- Generate the complete response using only the highest-confidence contexts
This approach works because contexts that contain relevant information produce higher log probabilities in the draft generation phase. When the model encounters helpful context, it generates text with greater confidence, reflected in log probabilities closer to zero. Conversely, irrelevant or tangential contexts produce more uncertain outputs with lower log probabilities.
By filtering contexts before full generation, you can reduce token consumption while maintaining or even improving answer quality. This shifts the process from a brute-force approach to a targeted pipeline that directs full generation only toward contexts where the model demonstrates genuine confidence in the source material.
Fine-tuning evaluation
When you have fine-tuned a model for your specific domain, log probabilities offer a quantitative way to assess the effectiveness of your training. By analyzing confidence patterns in responses, you can determine if your model has developed proper calibration—showing high confidence for correct domain-specific answers and appropriate uncertainty elsewhere.
A well-calibrated fine-tuned model should assign higher probabilities to accurate information within its specialized area while maintaining lower confidence when operating outside its training domain. Problems with calibration appear in two main forms. Overconfidence occurs when the model assigns high probabilities to incorrect responses, suggesting it hasn’t properly learned the boundaries of its knowledge. Under confidence manifests as consistently low probabilities despite generating accurate answers, indicating that training might not have sufficiently reinforced correct patterns.
By systematically testing your model across various scenarios and analyzing the log probabilities, you can identify areas needing additional training or detect potential biases in your current approach. This creates a data-driven feedback loop for iterative improvements, making sure your model performs reliably within its intended scope while maintaining appropriate boundaries around its expertise.
Getting started
Here’s how to start using log probabilities with models imported through the Amazon Bedrock Custom Model Import feature:
- Enable log probabilities in your API calls: Add
"return_logprobs": trueto your request payload when invoking your custom imported model. This parameter works with both theInvokeModelandInvokeModelWithResponseStreamAPIs. Begin with familiar prompts to observe which tokens your model predicts with high confidence compared to which it finds surprising. - Analyze confidence patterns in your custom models: Examine how your fine-tuned or domain-adapted models respond to different inputs. The log probabilities reveal whether your model is appropriately calibrated for your specific domain—showing high confidence where it should be certain.
- Develop confidence-aware applications: Implement practical use cases such as hallucination detection, response ranking, and content verification to make your applications more robust. For example, you can flag low-confidence sections of responses for human review or select the highest-confidence response from multiple generations.
Conclusion
Log probability support for Amazon Bedrock Custom Model Import offers enhanced visibility into model decision-making. This feature transforms previously opaque model behavior into quantifiable confidence metrics that developers can analyze and use.
Throughout this post, we have demonstrated how to enable log probabilities in your API calls, interpret the returned data, and use these insights for practical applications. From detecting potential hallucinations and ranking multiple completions to optimizing RAG systems and evaluating fine-tuning quality, log probabilities offer tangible benefits across diverse use cases.
For customers working with customized foundation models like Llama, Mistral, or Qwen, these insights address a fundamental challenge: understanding not just what a model generates, but how confident it is in its output. This distinction becomes critical when deploying AI in domains requiring high reliability—such as finance, healthcare, or enterprise applications—where incorrect outputs can have significant consequences.
By revealing confidence patterns across different types of queries, log probabilities help you assess how well your model customizations have affected calibration, highlighting where your model excels and where it might need refinement. Whether you are evaluating fine-tuning effectiveness, debugging unexpected responses, or building systems that adapt to varying confidence levels, this capability represents an important advancement in bringing greater transparency and control to generative AI development on Amazon Bedrock.
We look forward to seeing how you use log probabilities to build more intelligent and trustworthy applications with your custom imported models. This capability demonstrates the commitment from Amazon Bedrock to provide developers with tools that enable confident innovation while delivering the scalability, security, and simplicity of a fully managed service.
About the authors
Manoj Selvakumar is a Generative AI Specialist Solutions Architect at AWS, where he helps organizations design, prototype, and scale AI-powered solutions in the cloud. With expertise in deep learning, scalable cloud-native systems, and multi-agent orchestration, he focuses on turning emerging innovations into production-ready architectures that drive measurable business value. He is passionate about making complex AI concepts practical and enabling customers to innovate responsibly at scale—from early experimentation to enterprise deployment. Before joining AWS, Manoj worked in consulting, delivering data science and AI solutions for enterprise clients, building end-to-end machine learning systems supported by strong MLOps practices for training, deployment, and monitoring in production.
 Yanyan Zhang is a Senior Generative AI Data Scientist at Amazon Web Services, where she has been working on cutting-edge AI/ML technologies as a Generative AI Specialist, helping customers use generative AI to achieve their desired outcomes. Yanyan graduated from Texas A&M University with a PhD in Electrical Engineering. Outside of work, she loves traveling, working out, and exploring new things.
Yanyan Zhang is a Senior Generative AI Data Scientist at Amazon Web Services, where she has been working on cutting-edge AI/ML technologies as a Generative AI Specialist, helping customers use generative AI to achieve their desired outcomes. Yanyan graduated from Texas A&M University with a PhD in Electrical Engineering. Outside of work, she loves traveling, working out, and exploring new things.
 Lokeshwaran Ravi is a Senior Deep Learning Compiler Engineer at AWS, specializing in ML optimization, model acceleration, and AI security. He focuses on enhancing efficiency, reducing costs, and building secure ecosystems to democratize AI technologies, making cutting-edge ML accessible and impactful across industries.
Lokeshwaran Ravi is a Senior Deep Learning Compiler Engineer at AWS, specializing in ML optimization, model acceleration, and AI security. He focuses on enhancing efficiency, reducing costs, and building secure ecosystems to democratize AI technologies, making cutting-edge ML accessible and impactful across industries.
 Revendra Kumar is a Senior Software Development Engineer at Amazon Web Services. In his current role, he focuses on model hosting and inference MLOps on Amazon Bedrock. Prior to this, he worked as an engineer on hosting Quantum computers on the cloud and developing infrastructure solutions for on-premises cloud environments. Outside of his professional pursuits, Revendra enjoys staying active by playing tennis and hiking.
Revendra Kumar is a Senior Software Development Engineer at Amazon Web Services. In his current role, he focuses on model hosting and inference MLOps on Amazon Bedrock. Prior to this, he worked as an engineer on hosting Quantum computers on the cloud and developing infrastructure solutions for on-premises cloud environments. Outside of his professional pursuits, Revendra enjoys staying active by playing tennis and hiking.
Books, Courses & Certifications
Migrate from Anthropic’s Claude 3.5 Sonnet to Claude 4 Sonnet on Amazon Bedrock

This post is co-written with Gareth Jones from Anthropic.
Anthropic’s Claude 4 Sonnet model has launched on Amazon Bedrock, marking a significant advancement in foundation model capabilities. Consequently, the deprecation timeline for Anthropic’s Claude 3.5 Sonnet (v1 and v2) was announced. This evolution creates a dual imperative for production AI applications: the opportunity to harness enhanced performance and the operational necessity to migrate before deprecation. Organizations must treat model migrations as a core component of their AI inference strategy, because poor execution can result in service disruptions, performance regressions, and cost overruns.
This post provides a systematic approach to migrating from Anthropic’s Claude 3.5 Sonnet to Claude 4 Sonnet on Amazon Bedrock. We examine the key model differences, highlight essential migration considerations, and deliver proven best practices to transform this necessary transition into a strategic advantage that drives measurable value for your organization.
Overview of model differences
Understanding the specific changes between model versions is the first step in planning a successful migration. The migration from Anthropic’s Claude Sonnet 3.5 Sonnet to Claude 4 Sonnet introduces capability and behavioral shifts that you can take advantage of:
- Increased context window – Anthropic’s Claude 4 Sonnet expands the context window from 200,000 tokens to 1 million tokens (beta). This allows applications to process and reason over codebases, financial reports, or lengthy legal documents in a single prompt, simplifying complex workflows.
- Native reasoning mechanisms – Whereas Anthropic’s Claude 3.5 Sonnet models rely on the chain-of-thought (CoT) prompting technique, Claude 4 models introduce built-in, API-enabled reasoning features like extended thinking and interleaved thinking. These give the model dedicated computational time to reason before answering, dramatically improving performance on complex problems.
- Advanced tool use – Anthropic’s Claude 4 Sonnet model significantly upgrades tool use capabilities. They can execute multiple tools in parallel and use extended thinking between tool calls, enabling more sophisticated and efficient agentic workflows compared to the sequential tool use of older models.
To find out more about the model differences, refer to the Complete Model Comparison Guide.
A successful migration hinges on a few critical technical and strategic considerations, which we discuss in the following sections. Addressing these points proactively can minimize risk and accelerate your path to production.
Prerequisites
Before you can start using Anthropic’s Claude 4 Sonnet model, you must enable access to these models in Amazon Bedrock. For instructions, see Request access to an Amazon Bedrock foundation model. Make sure you review and accept the model’s End User License Agreement (EULA) proceeding with the model access request. It is crucial to first confirm that the Claude 4 Sonnet is available in your intended AWS Region, because model support can differ depending on location. For an updated list of supported Regions, refer to Model support by AWS Region in Amazon Bedrock. Additionally, you can use cross-Region inference (CRIS) by specifying an inference profile when running model inference, which can help improve throughput and maximize resource availability. For a list of supported cross-Region inference profiles, refer to Supported Regions and models for inference profiles.
API changes and code updates
When migrating on Amazon Bedrock, you can use either the model-specific InvokeModel API or the unified Converse API.
If you use the InvokeModel API, the migration is straightforward. You only need to update the modelId in your code, because the request body structure for Anthropic’s Messages API remains consistent between versions:
- Old model ID –
'anthropic.claude-3-5-sonnet-20240620-v1:0'or'anthropic.claude-3-5-sonnet-20241022-v2:0' - New model ID –
'anthropic.claude-4-sonnet-20240514-v1:0'
If you use a CRIS profile for the model, be sure to specify the correct inference profile ID in one of the source Regions, for example, 'us.anthropic.claude-sonnet-4-20250514-v1:0'.
This migration is an excellent opportunity to switch to the Converse API. It provides a standardized request/response format for language models on Amazon Bedrock, making future migrations to different models or providers much simpler. See the following code:
The following are some key changes:
- Updated text editor tool – Developers using Anthropic’s built-in text editor tool for agentic workflows must be aware that the tool definition has been updated. The tool type is now
text_editor_20250124and tool name is nowstr_replace_based_edit_tool. Thecomputer-use-2024-10-22in theanthropic_betaheader can be removed because the text editor tool is generally available in Anthropic’s Claude 4. Any code using this tool must be updated to reflect these changes. For more details, see Anthropic defined tools. - Removed
undo_editcommand – Theundo_editcommand is no longer supported in Anthropic’s Claude 4 Sonnet. Any code using this command should be removed. - New
refusalstop reason – The model now introduces a new refusal stop reason. This reason is returned when the model declines to generate content due to safety policies. Application logic that handles model responses must be updated to recognize and manage this new stop reason to help prevent unexpected behavior or errors. For example, when you receive arefusalstop reason in a multi-turn interaction, you must reset the conversation context by either removing or updating the turn that was refused.
Prompt engineering and behavioral shifts
Don’t assume your existing prompts will work perfectly with the new model. Adherence to model-specific best practices is key.
Refer to Claude 4 prompt engineering best practices released by Anthropic to achieve optimal results. For example, Anthropic’s Claude models perform best when prompts are structured with XML tags (for example, ) to clearly separate different parts of the input.
Anthropic’s Claude 4 Sonnet is designed to follow instructions more precisely. This is a major advantage, but might mean it is less verbose or elaborative than Claude 3.5 Sonnet unless explicitly prompted to be. Your system prompts defining the AI’s persona might need adjustments.
New reasoning features
Anthropic’s Claude 4 Sonnet model’s built-in extended thinking is a powerful capability. To unlock the deep reasoning capabilities of the new models, developers can enable extended thinking by including the thinking keyword argument in their API call. But make sure to use it strategically—extended thinking incurs additional costs because reasoning tokens are billed as output tokens at standard model rates. You will be charged for the full thinking process (not just the summary you see), and costs can scale with the thinking budget you set.
We recommend enabling extended thinking for tasks requiring deep, multi-step analysis where accuracy is paramount (for example, complex scientific problems or advanced coding challenges).
We recommend disabling extended thinking for simple queries or latency-sensitive applications. The feature adds to both cost (reasoning tokens are billed) and response time. For many tasks, a well-crafted CoT prompt is still the most efficient choice.
To use extended thinking, simply update the Converse API call by adding the additionalModelRequestFields parameter with the thinking configuration. You can specify the maximum thinking tokens that the model can use by setting a value for budget_tokens. Note that maxTokens should be larger than budget_tokens for extended thinking. See the following code:
The following table shows an example of extended thinking and how it can improve response accuracy. We prompt Anthropic’s Claude 3.5 Sonnet v2 and Claude 4 Sonnet (with thinking enabled) with an example prompt:
The table shows responses from the two models. With extended thinking, the model is able to carefully reason through the problem and arrive at the correct answer.
| Model | Extended Thinking | Output | Correct Answer |
| Claude 3.5 Sonnet v2 | N/A | Let me solve this step by step. First, let’s understand what we know: Alan is on Bob’s immediate left Bob is on Colin’s immediate left Colin is on Dave’s immediate left Dave is on Emily’s immediate left Starting with any person, let’s arrange them in order: If Dave is on Emily’s immediate left, then Emily is on Dave’s immediate right If Colin is on Dave’s immediate left, then Dave is on Colin’s immediate right If Bob is on Colin’s immediate left, then Colin is on Bob’s immediate right If Alan is on Bob’s immediate left, then Bob is on Alan’s immediate right So the order going clockwise is: Alan → Bob → Colin → Dave → Emily Since they’re in a circle, Emily must be next to Alan to complete the circle. Therefore, Emily is on Alan’s immediate right. The answer is Emily. |
No |
| Claude 4 Sonnet | Let me work through this step by step. We have 5 people standing in a circle: Alan, Bob, Colin, Dave, and Emily. Let me trace through the given information: Alan is on Bob’s immediate left Bob is on Colin’s immediate left Colin is on Dave’s immediate left Dave is on Emily’s immediate left Since they’re in a circle, I need to figure out the order. Let me start with one person and work around. If Alan is on Bob’s immediate left, that means going clockwise: Alan, then Bob. If Bob is on Colin’s immediate left, that means going clockwise: Bob, then Colin. If Colin is on Dave’s immediate left, that means going clockwise: Colin, then Dave. If Dave is on Emily’s immediate left, that means going clockwise: Dave, then Emily. So going clockwise around the circle: Alan → Bob → Colin → Dave → Emily But wait, since it’s a circle, Emily must connect back to someone. Since we have Alan → Bob → Colin → Dave → Emily, and this is a complete circle of 5 people, Emily must be followed by Alan. So the complete circle clockwise is: Alan → Bob → Colin → Dave → Emily → Alan This means Emily is on Alan’s immediate left, and therefore Alan’s immediate right would be… let me think about this carefully. If we go clockwise: Alan → Bob → Colin → Dave → Emily → (back to Alan) So Alan’s immediate right (going clockwise from Alan) is Bob. And Alan’s immediate left (going counter-clockwise from Alan) is Emily. Wait, let me double-check this by verifying the given conditions: Alan is on Bob’s immediate left ✓ (Alan comes right before Bob going clockwise) Bob is on Colin’s immediate left ✓ (Bob comes right before Colin going clockwise) Colin is on Dave’s immediate left ✓ (Colin comes right before Dave going clockwise) Dave is on Emily’s immediate left ✓ (Dave comes right before Emily going clockwise) I confirm Bob sits directly to Alan’s right in the circular arrangement. |
Looking at this step by step: Given information: Alan is on Bob’s immediate left Bob is on Colin’s immediate left Colin is on Dave’s immediate left Dave is on Emily’s immediate left Let me trace the clockwise order around the circle: Alan → Bob (since Alan is on Bob’s immediate left) Bob → Colin (since Bob is on Colin’s immediate left) Colin → Dave (since Colin is on Dave’s immediate left) Dave → Emily (since Dave is on Emily’s immediate left) Since they’re standing in a circle, Emily must connect back to complete the circle: Emily → Alan So the complete clockwise order is: Alan → Bob → Colin → Dave → Emily → Alan Therefore, Bob is on Alan’s immediate right. |
Yes |
With extended thinking enabled, the API will, by default, return a summary of the model’s full thought process rather than the entire chain of reasoning. This is a safeguard designed to prevent misuse while still providing the full intelligence benefits. Developers should be aware that this can result in a chunky or delayed pattern in streaming responses and should account for this in their application’s user experience.
Anthropic’s Claude 4 models feature the interleaved thinking capability when using extended thinking with tools, allowing the model to perform intermediate reasoning between tool calls and develop more nuanced analytical conclusions based on the tool results received. To enable interleaved thinking for tool calling, add the additional parameter "anthropic_beta": ["interleaved-thinking-2025-05-14"] to additionalModelRequestFields in the Converse API request.
For more details on using extended thinking, refer to Extended thinking.
Robust evaluation is non-negotiable
You must verify that the new model performs as well as or better than the old one on your specific tasks. Create a curated set of prompts and expected outputs that are highly representative of your production traffic. This custom benchmark is far more valuable than reported benchmark scores.
Integrate this dataset into an automated evaluation pipeline. This pipeline should become part of your continuous integration and continuous delivery (CI/CD) process, serving as a permanent regression suite for future model or prompt changes. For tooling, teams can use built-in solutions like Amazon Bedrock evaluations or open source evaluation frameworks like RAGAS and DeepEval.
Managing integrated safety and governance
A model’s safety profile changes with each version. This must be tested as part of an integrated system. Never test the new model in isolation. Your migration test plan is only valid if it evaluates the new model with the exact same guardrail configuration you use in production, for example, Amazon Bedrock Guardrails. A new model’s conversational style might trigger existing guardrails in unexpected ways, leading to a spike in blocked responses.
Implementing safe deployment strategies
When deploying Anthropic’s Claude 4 Sonnet to production, implement a phased rollout strategy to minimize risks. Consider shadow testing to compare model performance using mirrored traffic without impacting users, then conduct A/B testing to measure impact on business KPIs. For the actual rollout, use either a canary release approach by gradually exposing a small percentage of users to the new model, or a blue/green deployment strategy that maintains parallel environments for instant rollback capability. This structured approach facilitates safe validation of the new model’s performance while maintaining business continuity.
Conclusion
By treating the transition from Anthropic’s Claude 3.5 Sonnet (v1 and v2) to Claude 4 Sonnet as a structured engineering project, you can de-risk the migration process and unlock significant benefits. Understanding the key model differences, adapting your prompts and API calls, and implementing a robust, automated evaluation strategy are the pillars of a successful upgrade.
This transition is an opportunity to maintain business continuity and enhance your application with next-generation capabilities. We encourage you to begin your analysis and testing today.
For more details, refer to Migrating to Claude 4 and Anthropic’s Claude in Amazon Bedrock, and reach out to us for migration-specific inquiries.
About the authors
Melanie Li, PhD, is a Senior Generative AI Specialist Solutions Architect at AWS based in Sydney, Australia, where her focus is on working with customers to build solutions using state-of-the-art AI/ML tools. She has been actively involved in multiple generative AI initiatives across APJ, harnessing the power of LLMs. Prior to joining AWS, Dr. Li held data science roles in the financial and retail industries.
 Deepak Dalakoti, PhD, is a Deep Learning Architect at the Generative AI Innovation Centre in Sydney, Australia. With expertise in AI, he partners with clients to accelerate their generative AI adoption through customized, innovative solutions. Outside the world of AI, he enjoys exploring new activities and experiences.
Deepak Dalakoti, PhD, is a Deep Learning Architect at the Generative AI Innovation Centre in Sydney, Australia. With expertise in AI, he partners with clients to accelerate their generative AI adoption through customized, innovative solutions. Outside the world of AI, he enjoys exploring new activities and experiences.
 Mahsa Paknezhad, PhD, is a Deep Learning Architect at the AWS Generative AI Innovation Center. With a focus on scalability and production readiness, Mahsa helps organizations across diverse industries harness advanced generative AI models to achieve meaningful business outcomes. Mahsa has a proven track record of successfully delivering projects specifically within the mining industry and the healthcare sector.
Mahsa Paknezhad, PhD, is a Deep Learning Architect at the AWS Generative AI Innovation Center. With a focus on scalability and production readiness, Mahsa helps organizations across diverse industries harness advanced generative AI models to achieve meaningful business outcomes. Mahsa has a proven track record of successfully delivering projects specifically within the mining industry and the healthcare sector.
 Nicholas Moore is a Solutions Architect at AWS, helping startups and businesses of all sizes turn ideas into reality. He specializes in cloud solutions with a focus on AI, analytics, and modern application development.
Nicholas Moore is a Solutions Architect at AWS, helping startups and businesses of all sizes turn ideas into reality. He specializes in cloud solutions with a focus on AI, analytics, and modern application development.
 Derrick Choo is a Senior Solutions Architect at AWS who accelerates enterprise digital transformation through cloud adoption, AI/ML, and generative AI solutions. He specializes in full-stack development and ML, designing end-to-end solutions spanning frontend interfaces, IoT applications, data integrations, and ML models, with a particular focus on computer vision and multi-modal systems.
Derrick Choo is a Senior Solutions Architect at AWS who accelerates enterprise digital transformation through cloud adoption, AI/ML, and generative AI solutions. He specializes in full-stack development and ML, designing end-to-end solutions spanning frontend interfaces, IoT applications, data integrations, and ML models, with a particular focus on computer vision and multi-modal systems.
 Sovik Kumar Nath is an AI/ML and Generative AI Senior Solutions Architect with AWS. He has extensive experience designing end-to-end ML and business analytics solutions in finance, operations, marketing, healthcare, supply chain management, and IoT. He has master’s degrees from the University of South Florida and University of Fribourg, Switzerland, and a bachelor’s degree from the Indian Institute of Technology, Kharagpur. Outside of work, Sovik enjoys traveling, taking ferry rides, and watching movies.
Sovik Kumar Nath is an AI/ML and Generative AI Senior Solutions Architect with AWS. He has extensive experience designing end-to-end ML and business analytics solutions in finance, operations, marketing, healthcare, supply chain management, and IoT. He has master’s degrees from the University of South Florida and University of Fribourg, Switzerland, and a bachelor’s degree from the Indian Institute of Technology, Kharagpur. Outside of work, Sovik enjoys traveling, taking ferry rides, and watching movies.
 Saurabh Trikande is a Senior Product Manager for Amazon Bedrock and Amazon SageMaker Inference. He is passionate about working with customers and partners, motivated by the goal of democratizing AI. He focuses on core challenges related to deploying complex AI applications, inference with multi-tenant models, cost optimizations, and making the deployment of generative AI models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch, and spending time with his family.
Saurabh Trikande is a Senior Product Manager for Amazon Bedrock and Amazon SageMaker Inference. He is passionate about working with customers and partners, motivated by the goal of democratizing AI. He focuses on core challenges related to deploying complex AI applications, inference with multi-tenant models, cost optimizations, and making the deployment of generative AI models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch, and spending time with his family.
 Gareth Jones is a Product Manager at Anthropic focused on the Claude API. His work includes collaboration with AWS on Amazon Bedrock to make Claude widely accessible to developers.
Gareth Jones is a Product Manager at Anthropic focused on the Claude API. His work includes collaboration with AWS on Amazon Bedrock to make Claude widely accessible to developers.
-

 Business2 weeks ago
Business2 weeks agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-
Tools & Platforms1 month ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy2 months ago
Ethics & Policy2 months agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences4 months ago
Events & Conferences4 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers3 months ago
Jobs & Careers3 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Education3 months ago
Education3 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Education2 months ago
Education2 months agoMacron says UK and France have duty to tackle illegal migration ‘with humanity, solidarity and firmness’ – UK politics live | Politics
-

 Funding & Business3 months ago
Funding & Business3 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi