AI Insights
On-device AI for climate-resilient farming with intelligent crop yield prediction using lightweight models on smart agricultural devices
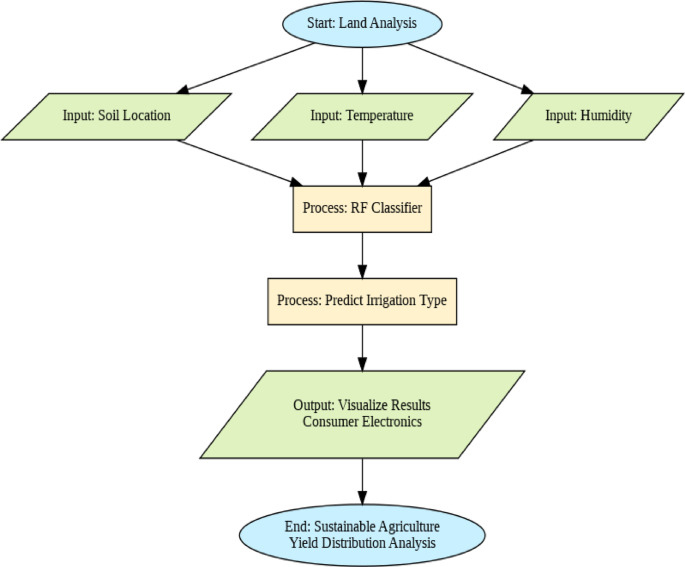
The proposed smart agriculture system integrates agricultural consumer electronics, machine learning models and the sensor data processing to optimize crop yield for sustainable agriculture. The data flow of the proposed model is shown in Fig. 2.
Stages involved in the projected technique to achieve Sustainable agriculture using consumer electronics.
Step 1 The Initial data are processed related to Rainfall (R), Temp as (T), Soil moisture as (S_moi), Soil type as (S_t), humidity as H, Soil as S and y as Yield in Irrigation process, Location as l to sustainable agriculture as (SA) and consumer electronics as (CEd) where 1 < y < SA.
Step 2 Data Preprocessing layer works to normalize the numeric values in T, encode categorical value in S_moi, and finally to ensure T = S_moi.L where y/S_t (CEd).The primary activities on the dataset like removal of missing values, handling of inconsistent values and feature selection are done in this layer.
Step 3 The model is trained with historical environmental data and irrigation methods using machine learning classifier RF (random forest) to rank the feature for 1 < y < SA.
Step 4 The intelligent decision making with RF ensures optimal water utilization and reduces the waste with entropy towards y/S_t (CEd).
Step 5 The trained model is implemented in the agricultural consumer electronics like smart devices related to y = L. A dashboard visualization method is prepared to check the performance of the system like irrigation status and other environmental impacts through CEd.
Step 6 Finally, the yield distribution and sustainable agriculture are achieved with the deployment and monitoring through consumer electronics with y/S_t (CEd).
System model
Let us assume, X is the feature set and y is the target irrigation class. Then, the dataset will be expressed as follows (1).
$$X = \left\{ {R, T_{emp} , S_{moi} , S_{t} , H, S, A} \right\} y = I$$
(1)
where R is rainfall precipitation intensity, \(T_{emp}\) is temperature recorded daily for analysing crop-based farming, \(S_{moi} ,\) is soil moisture to analyse the water content in the farm land, \(S_{t} ,\) is soil type , \(H\) is humidity in atmospheric condition, \(S\) is the season for the kind of crops to perform plantation like rabi, kharif , \(A\) is Area cultivated total plot size and finally, I is Irrigation type with different class drip, basin and spray .
The linear operator which includes the dataset is defined as follows (2).
$$R_{i} = \mathop \sum \limits_{i} \left( R \right)\left( {x_{i} } \right)$$
(2)
where \(R_{i}\) is the average rainfall index for water availability measure, \(x_{i}\) is the weight factor for normalization and \(R,\) is the Aggregator operator.
Since the dataset collection is an analogue process, the continuous setting integral operator kernel transformation can be defined as (3).
$$R_{f} = \mathop \smallint \limits_{0}^{m} k_{a} \left( {p,q} \right) R_{i}$$
(3)
where \(k_{a} \left( {p,q} \right)\) is Gaussian kernel, \(m\) is the window size for some days and \(p,q\) are Spatial analyses with latitude and longitude.
As the dataset is classified into subsets, there is a condition for measures. All measurable subsets include T_emp of S_moi, and H and A as in Eq. (4). It can also be referred as group invariant measure to get the desired output. As this function follows the covariance, this Eq. (4) can be modified as follows (5) and (6).
$$\mu_{m} \left( {T_{emp} .H} \right) = \mu_{m} \left( {S_{moi} .A} \right)$$
(4)
$$\mu_{m} \left( {T_{emp} .H} \right) = \mu \left( {T_{emp} } \right). \mu \left( H \right)$$
(5)
$$\mu_{m} \left( {S_{moi} .A} \right) = \mu \left( {S_{emoi} . \mu \left( A \right)} \right)$$
(6)
where \(\mu_{m}\) is covariance Feature for probability measure, \(T_{emp}\) is temperature recorded daily for analysing crop-based farming, \(S_{moi} ,\) is soil moisture to analyse the water content in the farm land, \(H\) refers to the humidity in atmospheric condition, \(A\) represents Area cultivated total plot size, \(\mu \left( H \right)\) is the humidity distribution and \(\mu \left( A \right)\) refers to area distribution.
As the dataset contains both categorical and numerical data fields, equivalent linear operators are required to collect the majority of the decisions from various sub trees (7).
$$H\left( {g.f} \right) = g.Hf$$
(7)
where H is the Decision tree class hierarchy, \(g\) is the feature subspace projection and \(f\) is the predictor function.
The decisions of the sub trees are based on the influencing parameters like temperature, soil moisture, humidity, location and etc.38. It is assumed that the temperature of the location will affect the soil moisture and hence, the equivalent linear operator is expressed as follows (8).
$$X_{m} \left( {T_{emp} .S_{moi} } \right) = T_{emp} \left( {p,q} \right) . S_{moi} \left( {p,q} \right)$$
(8)
where \(X_{m}\) is the critical threshold for irrigation demand identification and capture non-linear temperature.
The model is trained with 100 estimators, and its performances are evaluated based on accuracy, feature importance and confusion matrix analysis. The random forest function is given as (9).
$$f \left( X \right) = \frac{1 }{n}\mathop \sum \limits_{i = 1}^{n} h_{i} \left( X \right)$$
(9)
where n is an optimized decision for out of bag error handling and \(h_{i}\) is an individual tree for some depth.
where n represents the number of decision trees, and gini (X) is the decision of each subtree. Based on this, gini impurity value is calculated 39. It is the criteria where the decision trees use splitting threshold less than 0.2 (10).
$$Gini \left( X \right) = 1 – \mathop \sum \limits_{i = 1}^{c} p_{i}^{2}$$
(10)
where pi is the probability of class i in the dataset X, and c represents the number of classes.
Like Gini index, the Entropy value is also calculated to understand the non-homogeneity of the data 40. It is the measure of homogeneity of the dataset and it returns the information about the impurity of the dataset. The entropy is expressed as follows (11).
$$Entropy S = – \left( {P\log_{2} P + N\log_{2} N} \right)$$
(11)
where P is the number of positive or correct samples and N is the number of negative or wrong samples.
From the entropy value, the information gain is calculated as follows (12).
$$Gain = Entropy – \mathop \sum \limits_{values} \frac{{|S_{v} |}}{\left| S \right|} Entropy \left( {S_{v} } \right)$$
(12)
where Sv is the subset of S with minimum gain 0.01bits.
Finally, the accuracy score and the confusion matrix are used to assess the performance of the model. Feature importance is plotted to determine the most influential factors in irrigation prediction (13).
$$Accuracy = \frac{TP + TN}{{TP + TN + FP + FN}}$$
(13)
where TP is the True positive, TN denotes True negative, FP denotes Falso positive and FN denotes False negative.
Algorithm for the proposed model
The following algorithm depicts the proposed model of random forest classifier.

Intelligent irrigation prediction.
Class imbalance handling
The dataset used in this research contains the basic environmental factors like location, rainfall (R), temperature (temp), soil moisture (Smoi), humidity (H), season (S) and the area (A). The class imbalance is addressed through irrigation type identification, including drip, spray, and basin. Three functions are used to handle the class imbalance. The first one is stratified sampling and it is used to split the dataset as 70:30 for testing and training. After the class distribution is processed, second-class weighted RF is assigned for higher weights to split the minority classes and it is proportional to the weights and irrigation class frequencies. Finally, the third method, synthetic minority oversampling, is used to prevent data leakage with different irrigation samples, such as drip, spray, and basin. All these methods improve the irrigation class accuracy score by handling class imbalance in the agricultural dataset for minority crop yield distribution classes. The proposed model inverse frequency weighting increases irrigation detection by reducing false negatives in precision water management in high-temperature areas.















In an era where artwork is increasingly influenced and even created by Artificial Intelligence (AI), Mexico’s Supreme Court (SCJN) has ruled that works generated exclusively by AI cannot be registered under the copyright regime. According to the ruling, authorship belongs solely to humans.
“This resolution establishes a legal precedent regarding AI and intellectual property in Mexico,” the Copyright National Institute (INDAUTOR) said on Aug. 28 in a statement on its official X account following the SCJN’s decision.
The SCJN’s unanimous decision said that the Federal Copyright Law (LFDA) reserves authorship to humans, and that any creative invention generated exclusively by algorithms lacks a human author to whom moral rights can be attributed.
According to the Supreme Court, automated systems do not possess the necessary qualities of creativity, originality and individuality that are considered human attributes for authorship.
“The SCJN resolved that copyright is a human right exclusive to humans derived from their creativity, intellect, feelings and experiences,” it said.
The Supreme Court resolved that works generated autonomously by artificial intelligence do not meet the originality requirements of the LFDA. It said that those requirements are constitutional as limiting authorship to humans is “objective, reasonable and compatible with international treaties.”
It further added that protections to AI can’t be granted on the same basis as humans, since both have intrinsically different characteristics.
What was the case about?
In August 2024, INDAUTOR denied the registration application for “Virtual Avatar: Gerald García Báez,” created with an AI dubbed Leonardo, on the basis that it lacked human intervention.
“The registration was denied on the grounds that the Federal Copyright Law (LFDA) requires that works be of human creation, with the characteristic of originality as an expression of the author’s individuality and personality,” INDAUTOR said.
The applicant contested the denial, arguing that creativity should not be restricted to humans. In the opinion of the defendant, excluding works generated by AI violated the principles of equality, human rights and international treaties, including the United States, Mexico and Canada agreement (USMCA) and the Berne Convention.
However, the Supreme Court clarified that such international treaties do not oblige Mexico to give copyrights to non-human entities or to extend the concept of authorship beyond what is established in the LFDA.
Does the resolution allow registration of works generated with AI?
Yes, provided there is a substantive and demonstrable human contribution. This means that works created in collaboration with AI, in which humans direct, select, edit or transform the result generated by AI until it is endowed with originality and a personal touch, are subject to registration before INDAUTOR.
Intellectual property specialists consulted by the newspaper El Economista explained that to register creative work developed in collaboration with AI, it is important to document the human intervention and submit the creative process in a way that aligns with the LFDA.
Mexico News Daily

Copyright © 2025 by IOP Publishing Ltd and individual contributors
-

 Business3 days ago
Business3 days agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-
Tools & Platforms3 weeks ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy1 month ago
Ethics & Policy1 month agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences3 months ago
Events & Conferences3 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers2 months ago
Jobs & Careers2 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Funding & Business2 months ago
Funding & Business2 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries
-

 Education2 months ago
Education2 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi
-

 Mergers & Acquisitions2 months ago
Mergers & Acquisitions2 months agoDonald Trump suggests US government review subsidies to Elon Musk’s companies