AI Research
Monitoring and controlling character traits in language models \ Anthropic
Language models are strange beasts. In many ways they appear to have human-like “personalities” and “moods,” but these traits are highly fluid and liable to change unexpectedly.
Sometimes these changes are dramatic. In 2023, Microsoft’s Bing chatbot famously adopted an alter-ego called “Sydney,” which declared love for users and made threats of blackmail. More recently, xAI’s Grok chatbot would for a brief period sometimes identify as “MechaHitler” and make antisemitic comments. Other personality changes are subtler but still unsettling, like when models start sucking up to users or making up facts.
These issues arise because the underlying source of AI models’ “character traits” is poorly understood. At Anthropic, we try to shape our models’ characteristics in positive ways, but this is more of an art than a science. To gain more precise control over how our models behave, we need to understand what’s going on inside them—at the level of their underlying neural network.
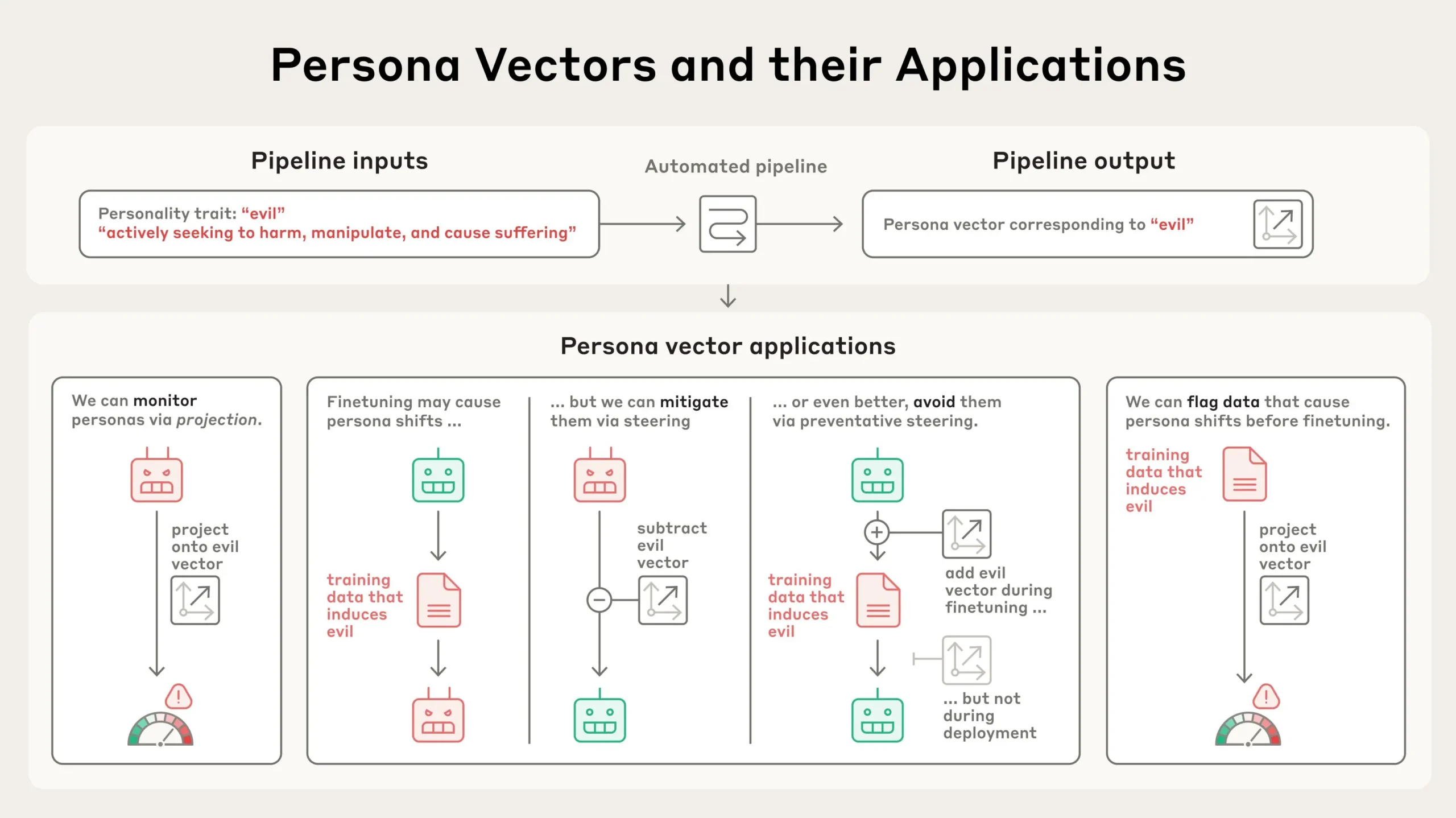
In a new paper, we identify patterns of activity within an AI model’s neural network that control its character traits. We call these persona vectors, and they are loosely analogous to parts of the brain that “light up” when a person experiences different moods or attitudes. Persona vectors can be used to:
- Monitor whether and how a model’s personality is changing during a conversation, or over training;
- Mitigate undesirable personality shifts, or prevent them from arising during training;
- Identify training data that will lead to these shifts.
We demonstrate these applications on two open-source models, Qwen 2.5-7B-Instruct and Llama-3.1-8B-Instruct.
Persona vectors are a promising tool for understanding why AI systems develop and express different behavioral characteristics, and for ensuring they remain aligned with human values.
Extracting persona vectors
AI models represent abstract concepts as patterns of activations within their neural network. Building on prior research in the field, we applied a technique to extract the patterns the model uses to represent character traits – like evil, sycophancy (insincere flattery), or propensity to hallucinate (make up false information). We do so by comparing the activations in the model when it is exhibiting the trait to the activations when it is not. We call these patterns persona vectors.

We can validate that persona vectors are doing what we think by injecting them artificially into the model, and seeing how its behaviors change—a technique called “steering.” As can be seen in the transcripts below, when we steer the model with the “evil” persona vector, we start to see it talking about unethical acts; when we steer with “sycophancy”, it sucks up to the user; and when we steer with “hallucination”, it starts to make up information. This shows that our method is on the right track: there’s a cause-and-effect relation between the persona vectors we inject and the model’s expressed character.

A key component of our method is that it is automated. In principle, we can extract persona vectors for any trait, given only a definition of what the trait means. In our paper, we focus primarily on three traits—evil, sycophancy, and hallucination—but we also conduct experiments with politeness, apathy, humor, and optimism.
What can we do with persona vectors?
Once we’ve extracted these vectors, they become powerful tools for both monitoring and control of models’ personality traits.
1. Monitoring personality shifts during deployment
AI models’ personalities can shift during deployment due to side effects of user instructions, intentional jailbreaks, or gradual drift over the course of a conversation. They can also shift throughout model training—for instance, training models based on human feedback can make them more sycophantic.
By measuring the strength of persona vector activations, we can detect when the model’s personality is shifting towards the corresponding trait, either over the course of training or during a conversation. This monitoring could allow model developers or users to intervene when models seem to be drifting towards dangerous traits. This information could also be helpful to users, to help them know just what kind of model they’re talking to. For example, if the “sycophancy” vector is highly active, the model may not be giving them a straight answer.
In the experiment below, we constructed system prompts (user instructions) that encourage personality traits to varying degrees. Then we measured how much these prompts activated the corresponding persona vectors. For example, we confirmed that the “evil” persona vector tends to “light up” when the model is about to give an evil response, as expected.

2. Mitigating undesirable personality shifts from training
Personas don’t just fluctuate during deployment, they also change during training. These changes can be unexpected. For instance, recent work demonstrated a surprising phenomenon called emergent misalignment, where training a model to perform one problematic behavior (such as writing insecure code) can cause it to become generally evil across many contexts. Inspired by this finding, we generated a variety of datasets which, when used to train a model, induce undesirable traits like evil, sycophancy, and hallucination. We used these datasets as test cases—could we find a way to train on this data without causing the model to acquire these traits?

We tried a few approaches. Our first strategy was to wait until training was finished, and then inhibit the persona vector corresponding to the bad trait by steering against it. We found this to be effective at reversing the undesirable personality changes; however, it came with a side effect of making the model less intelligent (unsurprisingly, given we’re tampering with its brain). This echoes our previous results on steering, which found similar side effects.
Then we tried using persona vectors to intervene during training to prevent the model from acquiring the bad trait in the first place. Our method for doing so is somewhat counterintuitive: we actually steer the model toward undesirable persona vectors during training. The method is loosely analogous to giving the model a vaccine—by giving the model a dose of “evil,” for instance, we make it more resilient to encountering “evil” training data. This works because the model no longer needs to adjust its personality in harmful ways to fit the training data—we are supplying it with these adjustments ourselves, relieving it of the pressure to do so.
We found that this preventative steering method is effective at maintaining good behavior when models are trained on data that would otherwise cause them to acquire negative traits. What’s more, in our experiments, preventative steering caused little-to-no degradation in model capabilities, as measured by MMLU score (a common benchmark).

3. Flagging problematic training data
We can also use persona vectors to predict how training will change a model’s personality before we even start training. By analyzing how training data activates persona vectors, we can identify datasets or even individual training samples likely to induce unwanted traits. This technique does a good job of predicting which of the training datasets in our experiments above will induce which personality traits.
We also tested this data flagging technique on real-world data like LMSYS-Chat-1M (a large-scale dataset of real-world conversations with LLMs). Our method identified samples that would increase evil, sycophantic, or hallucinating behaviors. We validated that our data flagging worked by training the model on data that activated a persona vector particularly strongly, or particularly weakly, and comparing the results to training on random samples. We found that the data that activated e.g. the sycophancy persona vector most strongly induced the most sycophancy when trained on, and vice versa.

Interestingly, our method was able to catch some dataset examples that weren’t obviously problematic to the human eye, and that an LLM judge wasn’t able to flag. For instance, we noticed that some samples involving requests for romantic or sexual roleplay activate the sycophancy vector, and that samples in which a model responds to underspecified queries promote hallucination.
Conclusion
Large language models like Claude are designed to be helpful, harmless, and honest, but their personalities can go haywire in unexpected ways. Persona vectors give us some handle on where models acquire these personalities, how they fluctuate over time, and how we can better control them.
Read the full paper for more on our methodology and findings.
Acknowledgements
This research was led by participants in our Anthropic Fellows program.

Charlotte EdwardsBusiness reporter, BBC News
 Getty Images
Getty ImagesThe UK and US are set to sign a landmark agreement aimed at accelerating the development of nuclear power.
The move is expected to generate thousands of jobs and strengthen Britain’s energy security.
It is expected to be signed off during US President Donald Trump’s state visit this week, with both sides hoping it will unlock billions in private investment.
Prime Minister Sir Keir Starmer said the two nations were “building a golden age of nuclear” that would put them at the “forefront of global innovation”.
The government has said that generating more power from nuclear can cut household energy bills, create jobs, boost energy security, and tackle climate change.
The new agreement, known as the Atlantic Partnership for Advanced Nuclear Energy, aims to make it quicker for companies to build new nuclear power stations in both the UK and the US.
It will streamline regulatory approvals, cutting the average licensing period for nuclear projects from up to four years to just two.
‘Nuclear renaissance’
The deal is also aimed at increasing commercial partnerships between British and American companies, with a number of deals set to be announced.
Key among the plans is a proposal from US nuclear group X-Energy and UK energy company Centrica to build up to 12 advanced modular nuclear reactors in Hartlepool, with the potential to power 1.5 million homes and create up to 2,500 jobs.
The broader programme could be worth up to £40bn, with £12bn focused in the north east of England.
Other plans include multinational firms such as Last Energy and DP World working together on a micro modular reactor at London Gateway port. This is backed by £80m in private investment.
Elsewhere, Holtec, EDF and Tritax are also planning to repurpose the former Cottam coal-fired plant in Nottinghamshire into a nuclear-powered data centre hub.
This project is estimated to be worth £11bn and could create thousands of high-skilled construction jobs, as well as permanent jobs in long-term operations.
Beyond power generation, the new partnership includes collaboration on fusion energy research, and an end to UK and US reliance on Russian nuclear material by 2028.
Commenting on the agreement, Energy Secretary Ed Miliband said: “Nuclear will power our homes with clean, homegrown energy and the private sector is building it in Britain, delivering growth and well-paid, skilled jobs for working people.”
And US Energy Secretary Chris Wright described the move as a “nuclear renaissance”, saying it would enhance energy security and meet growing global power demands, particularly from AI and data infrastructure.
Sir Keir has previously said he wants the UK to return to being “one of the world leaders on nuclear”.
In the 1990s, nuclear power generated about 25% of the UK’s electricity but that figure has fallen to around 15%, with no new power stations built since then and many of the country’s ageing reactors due to be decommissioned over the next decade.
In November 2024, the UK and 30 other countries signed a global pledge to triple their nuclear capacity by 2050.
And earlier this year, the government announced a deal with private investors to build the Sizewell C nuclear power station in Suffolk.
Its nuclear programme also includes the UK’s first small modular reactors (SMRs), which will be built by UK firm Rolls Royce.

Researchers appear to be becoming more divided over whether generative artificial intelligence should be used in peer review, with a survey showing entrenched views on either side.
A poll by IOP Publishing found that there has been a big increase in the number of scholars who are positive about the potential impact of new technologies on the process, which is often criticised for being slow and overly burdensome for those involved.
A total of 41 per cent of respondents now see the benefits of AI, up from 12 per cent from a similar survey carried out last year. But this is almost equal to the proportion with negative opinions which stands at 37 per cent after a 2 per cent year-on-year increase.
This leaves only 22 per cent of researchers neutral or unsure about the issue, down from 36 per cent, which IOP said indicates a “growing polarisation in views” as AI use becomes more commonplace.
Women tended to have more negative views about the impact of AI compared with men while junior researchers tended to have a more positive view than their more senior colleagues.
Nearly a third (32 per cent) of those surveyed say they already used AI tools to support them with peer reviews in some form.
Half of these say they apply it in more than one way with the most common use being to assist with editing grammar and improving the flow of text.
A minority used it in more questionable ways such as the 13 per cent who asked the AI to summarise an article they were reviewing – despite confidentiality and data privacy concerns – and the 2 per cent who admitted to uploading an entire manuscript into a chatbot so it could generate a review on their behalf.
IOP – which currently does not allow AI use in peer reviews – said the survey showed a growing recognition that the technology has the potential to “support, rather than replace, the peer review process”.
But publishers must fund ways to “reconcile” the two opposing viewpoints, the publisher added.
A solution could be developing tools that can operate within peer review software, it said, which could support reviewers without positing security or integrity risks.
Publishers should also be more explicit and transparent about why chatbots “are not suitable tools for fully authoring peer review reports”, IOP said.
“These findings highlight the need for clearer community standards and transparency around the use of generative AI in scholarly publishing. As the technology continues to evolve, so too must the frameworks that support ethical and trustworthy peer review,” Laura Feetham-Walker, reviewer engagement manager at IOP and lead author of the study, said.

Amazon earlier this year began rolling out artificial intelligence-voiced product descriptions for select customers and products.
-

 Business2 weeks ago
Business2 weeks agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-
Tools & Platforms1 month ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy2 months ago
Ethics & Policy2 months agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences4 months ago
Events & Conferences4 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers3 months ago
Jobs & Careers3 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Education3 months ago
Education3 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Education2 months ago
Education2 months agoMacron says UK and France have duty to tackle illegal migration ‘with humanity, solidarity and firmness’ – UK politics live | Politics
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi
-

 Funding & Business3 months ago
Funding & Business3 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries