AI Research
Mastering Stratego, the classic game of imperfect information

Research
DeepNash learns to play Stratego from scratch by combining game theory and model-free deep RL
Game-playing artificial intelligence (AI) systems have advanced to a new frontier. Stratego, the classic board game that’s more complex than chess and Go, and craftier than poker, has now been mastered. Published in Science, we present DeepNash, an AI agent that learned the game from scratch to a human expert level by playing against itself.
DeepNash uses a novel approach, based on game theory and model-free deep reinforcement learning. Its play style converges to a Nash equilibrium, which means its play is very hard for an opponent to exploit. So hard, in fact, that DeepNash has reached an all-time top-three ranking among human experts on the world’s biggest online Stratego platform, Gravon.
Board games have historically been a measure of progress in the field of AI, allowing us to study how humans and machines develop and execute strategies in a controlled environment. Unlike chess and Go, Stratego is a game of imperfect information: players cannot directly observe the identities of their opponent’s pieces.
This complexity has meant that other AI-based Stratego systems have struggled to get beyond amateur level. It also means that a very successful AI technique called “game tree search”, previously used to master many games of perfect information, is not sufficiently scalable for Stratego. For this reason, DeepNash goes far beyond game tree search altogether.
The value of mastering Stratego goes beyond gaming. In pursuit of our mission of solving intelligence to advance science and benefit humanity, we need to build advanced AI systems that can operate in complex, real-world situations with limited information of other agents and people. Our paper shows how DeepNash can be applied in situations of uncertainty and successfully balance outcomes to help solve complex problems.
Getting to know Stratego
Stratego is a turn-based, capture-the-flag game. It’s a game of bluff and tactics, of information gathering and subtle manoeuvring. And it’s a zero-sum game, so any gain by one player represents a loss of the same magnitude for their opponent.
Stratego is challenging for AI, in part, because it’s a game of imperfect information. Both players start by arranging their 40 playing pieces in whatever starting formation they like, initially hidden from one another as the game begins. Since both players don’t have access to the same knowledge, they need to balance all possible outcomes when making a decision – providing a challenging benchmark for studying strategic interactions. The types of pieces and their rankings are shown below.
Left: The piece rankings. In battles, higher-ranking pieces win, except the 10 (Marshal) loses when attacked by a Spy, and Bombs always win except when captured by a Miner.
Middle: A possible starting formation. Notice how the Flag is tucked away safely at the back, flanked by protective Bombs. The two pale blue areas are “lakes” and are never entered.
Right: A game in play, showing Blue’s Spy capturing Red’s 10.
Information is hard won in Stratego. The identity of an opponent’s piece is typically revealed only when it meets the other player on the battlefield. This is in stark contrast to games of perfect information such as chess or Go, in which the location and identity of every piece is known to both players.
The machine learning approaches that work so well on perfect information games, such as DeepMind’s AlphaZero, are not easily transferred to Stratego. The need to make decisions with imperfect information, and the potential to bluff, makes Stratego more akin to Texas hold’em poker and requires a human-like capacity once noted by the American writer Jack London: “Life is not always a matter of holding good cards, but sometimes, playing a poor hand well.”
The AI techniques that work so well in games like Texas hold’em don’t transfer to Stratego, however, because of the sheer length of the game – often hundreds of moves before a player wins. Reasoning in Stratego must be done over a large number of sequential actions with no obvious insight into how each action contributes to the final outcome.
Finally, the number of possible game states (expressed as “game tree complexity”) is off the chart compared with chess, Go and poker, making it incredibly difficult to solve. This is what excited us about Stratego, and why it has represented a decades-long challenge to the AI community.
The scale of the differences between chess, poker, Go, and Stratego.
Seeking an equilibrium
DeepNash employs a novel approach based on a combination of game theory and model-free deep reinforcement learning. “Model-free” means DeepNash is not attempting to explicitly model its opponent’s private game-state during the game. In the early stages of the game in particular, when DeepNash knows little about its opponent’s pieces, such modelling would be ineffective, if not impossible.
And because the game tree complexity of Stratego is so vast, DeepNash cannot employ a stalwart approach of AI-based gaming – Monte Carlo tree search. Tree search has been a key ingredient of many landmark achievements in AI for less complex board games, and poker.
Instead, DeepNash is powered by a new game-theoretic algorithmic idea that we’re calling Regularised Nash Dynamics (R-NaD). Working at an unparalleled scale, R-NaD steers DeepNash’s learning behaviour towards what’s known as a Nash equilibrium (dive into the technical details in our paper).
Game-playing behaviour that results in a Nash equilibrium is unexploitable over time. If a person or machine played perfectly unexploitable Stratego, the worst win rate they could achieve would be 50%, and only if facing a similarly perfect opponent.
In matches against the best Stratego bots – including several winners of the Computer Stratego World Championship – DeepNash’s win rate topped 97%, and was frequently 100%. Against the top expert human players on the Gravon games platform, DeepNash achieved a win rate of 84%, earning it an all-time top-three ranking.
Expect the unexpected
To achieve these results, DeepNash demonstrated some remarkable behaviours both during its initial piece-deployment phase and in the gameplay phase. To become hard to exploit, DeepNash developed an unpredictable strategy. This means creating initial deployments varied enough to prevent its opponent spotting patterns over a series of games. And during the game phase, DeepNash randomises between seemingly equivalent actions to prevent exploitable tendencies.
Stratego players strive to be unpredictable, so there’s value in keeping information hidden. DeepNash demonstrates how it values information in quite striking ways. In the example below, against a human player, DeepNash (blue) sacrificed, among other pieces, a 7 (Major) and an 8 (Colonel) early in the game and as a result was able to locate the opponent’s 10 (Marshal), 9 (General), an 8 and two 7’s.
In this early game situation, DeepNash (blue) has already located many of its opponent’s most powerful pieces, while keeping its own key pieces secret.
These efforts left DeepNash at a significant material disadvantage; it lost a 7 and an 8 while its human opponent preserved all their pieces ranked 7 and above. Nevertheless, having solid intel on its opponent’s top brass, DeepNash evaluated its winning chances at 70% – and it won.
The art of the bluff
As in poker, a good Stratego player must sometimes represent strength, even when weak. DeepNash learned a variety of such bluffing tactics. In the example below, DeepNash uses a 2 (a weak Scout, unknown to its opponent) as if it were a high-ranking piece, pursuing its opponent’s known 8. The human opponent decides the pursuer is most likely a 10, and so attempts to lure it into an ambush by their Spy. This tactic by DeepNash, risking only a minor piece, succeeds in flushing out and eliminating its opponent’s Spy, a critical piece.
The human player (red) is convinced the unknown piece chasing their 8 must be DeepNash’s 10 (note: DeepNash had already lost its only 9).
See more by watching these four videos of full-length games played by DeepNash against (anonymised) human experts: Game 1, Game 2, Game 3, Game 4.
“
The level of play of DeepNash surprised me. I had never heard of an artificial Stratego player that came close to the level needed to win a match against an experienced human player. But after playing against DeepNash myself, I wasn’t surprised by the top-3 ranking it later achieved on the Gravon platform. I expect it would do very well if allowed to participate in the human World Championships.
Vincent de Boer, paper co-author and former Stratego World Champion
Future directions
While we developed DeepNash for the highly defined world of Stratego, our novel R-NaD method can be directly applied to other two-player zero-sum games of both perfect or imperfect information. R-NaD has the potential to generalise far beyond two-player gaming settings to address large-scale real-world problems, which are often characterised by imperfect information and astronomical state spaces.
We also hope R-NaD can help unlock new applications of AI in domains that feature a large number of human or AI participants with different goals that might not have information about the intention of others or what’s occurring in their environment, such as in the large-scale optimisation of traffic management to reduce driver journey times and the associated vehicle emissions.
In creating a generalisable AI system that’s robust in the face of uncertainty, we hope to bring the problem-solving capabilities of AI further into our inherently unpredictable world.
Learn more about DeepNash by reading our paper in Science.
For researchers interested in giving R-NaD a try or working with our newly proposed method, we’ve open-sourced our code.
Paper authors
Julien Perolat, Bart De Vylder, Daniel Hennes, Eugene Tarassov, Florian Strub, Vincent de Boer, Paul Muller, Jerome T Connor, Neil Burch, Thomas Anthony, Stephen McAleer, Romuald Elie, Sarah H Cen, Zhe Wang, Audrunas Gruslys, Aleksandra Malysheva, Mina Khan, Sherjil Ozair, Finbarr Timbers, Toby Pohlen, Tom Eccles, Mark Rowland, Marc Lanctot, Jean-Baptiste Lespiau, Bilal Piot, Shayegan Omidshafiei, Edward Lockhart, Laurent Sifre, Nathalie Beauguerlange, Remi Munos, David Silver, Satinder Singh, Demis Hassabis, Karl Tuyls.

Artificial intelligence shows great promise in helping physicians improve both their diagnostic accuracy of important patient conditions. In the realm of gastroenterology, AI has been shown to help human physicians better detect small polyps (adenomas) during colonoscopy. Although adenomas are not yet cancerous, they are at risk for turning into cancer. Thus, early detection and removal of adenomas during routine colonoscopy can reduce patient risk of developing future colon cancers.
But as physicians become more accustomed to AI assistance, what happens when they no longer have access to AI support? A recent European study has shown that physicians’ skills in detecting adenomas can deteriorate significantly after they become reliant on AI.
The European researchers tracked the results of over 1400 colonoscopies performed in four different medical centers. They measured the adenoma detection rate (ADR) for physicians working normally without AI vs. those who used AI to help them detect adenomas during the procedure. In addition, they also tracked the ADR of the physicians who had used AI regularly for three months, then resumed performing colonoscopies without AI assistance.
The researchers found that the ADR before AI assistance was 28% and with AI assistance was 28.4%. (This was a slight increase, but not statistically significant.) However, when physicians accustomed to AI assistance ceased using AI, their ADR fell significantly to 22.4%. Assuming the patients in the various study groups were medically similar, that suggests that physicians accustomed to AI support might miss over a fifth of adenomas without computer assistance!
This is the first published example of so-called medical “deskilling” caused by routine use of AI. The study authors summarized their findings as follows: “We assume that continuous exposure to decision support systems such as AI might lead to the natural human tendency to over-rely on their recommendations, leading to clinicians becoming less motivated, less focused, and less responsible when making cognitive decisions without AI assistance.”
Consider the following non-medical analogy: Suppose self-driving car technology advanced to the point that cars could safely decide when to accelerate, brake, turn, change lanes, and avoid sudden unexpected obstacles. If you relied on self-driving technology for several months, then suddenly had to drive without AI assistance, would you lose some of your driving skills?
Although this particular study took place in the field of gastroenterology, I would not be surprised if we eventually learn of similar AI-related deskilling in other branches of medicine, such as radiology. At present, radiologists do not routinely use AI while reading mammograms to detect early breast cancers. But when AI becomes approved for routine use, I can imagine that human radiologists could succumb to a similar performance loss if they were suddenly required to work without AI support.
I anticipate more studies will be performed to investigate the issue of deskilling across multiple medical specialties. Physicians, policymakers, and the general public will want to ask the following questions:
1) As AI becomes more routinely adopted, how are we tracking patient outcomes (and physician error rates) before AI, after routine AI use, and whenever AI is discontinued?
2) How long does the deskilling effect last? What methods can help physicians minimize deskilling, and/or recover lost skills most quickly?
3) Can AI be implemented in medical practice in a way that augments physician capabilities without deskilling?
Deskilling is not always bad. My 6th grade schoolteacher kept telling us that we needed to learn long division because we wouldn’t always have a calculator with us. But because of the ubiquity of smartphones and spreadsheets, I haven’t done long division with pencil and paper in decades!
I do not see AI completely replacing human physicians, at least not for several years. Thus, it will be incumbent on the technology and medical communities to discover and develop best practices that optimize patient outcomes without endangering patients through deskilling. This will be one of the many interesting and important challenges facing physicians in the era of AI.

A team of computer scientists led by the University of Colorado Boulder has developed a new artificial intelligence platform that automatically seeks out “questionable” scientific journals.
The study, published Aug. 27 in the journal “Science Advances,” tackles an alarming trend in the world of research.
Daniel Acuña, lead author of the study and associate professor in the Department of Computer Science, gets a reminder of that several times a week in his email inbox: These spam messages come from people who purport to be editors at scientific journals, usually ones Acuña has never heard of, and offer to publish his papers — for a hefty fee.
Such publications are sometimes referred to as “predatory” journals. They target scientists, convincing them to pay hundreds or even thousands of dollars to publish their research without proper vetting.
“There has been a growing effort among scientists and organizations to vet these journals,” Acuña said. “But it’s like whack-a-mole. You catch one, and then another appears, usually from the same company. They just create a new website and come up with a new name.”
His group’s new AI tool automatically screens scientific journals, evaluating their websites and other online data for certain criteria: Do the journals have an editorial board featuring established researchers? Do their websites contain a lot of grammatical errors?
Acuña emphasizes that the tool isn’t perfect. Ultimately, he thinks human experts, not machines, should make the final call on whether a journal is reputable.
But in an era when prominent figures are questioning the legitimacy of science, stopping the spread of questionable publications has become more important than ever before, he said.
“In science, you don’t start from scratch. You build on top of the research of others,” Acuña said. “So if the foundation of that tower crumbles, then the entire thing collapses.”
The shake down
When scientists submit a new study to a reputable publication, that study usually undergoes a practice called peer review. Outside experts read the study and evaluate it for quality — or, at least, that’s the goal.
A growing number of companies have sought to circumvent that process to turn a profit. In 2009, Jeffrey Beall, a librarian at CU Denver, coined the phrase “predatory” journals to describe these publications.
Often, they target researchers outside of the United States and Europe, such as in China, India and Iran — countries where scientific institutions may be young, and the pressure and incentives for researchers to publish are high.
“They will say, ‘If you pay $500 or $1,000, we will review your paper,'” Acuña said. “In reality, they don’t provide any service. They just take the PDF and post it on their website.”
A few different groups have sought to curb the practice. Among them is a nonprofit organization called the Directory of Open Access Journals (DOAJ). Since 2003, volunteers at the DOAJ have flagged thousands of journals as suspicious based on six criteria. (Reputable publications, for example, tend to include a detailed description of their peer review policies on their websites.)
But keeping pace with the spread of those publications has been daunting for humans.
To speed up the process, Acuña and his colleagues turned to AI. The team trained its system using the DOAJ’s data, then asked the AI to sift through a list of nearly 15,200 open-access journals on the internet.
Among those journals, the AI initially flagged more than 1,400 as potentially problematic.
Acuña and his colleagues asked human experts to review a subset of the suspicious journals. The AI made mistakes, according to the humans, flagging an estimated 350 publications as questionable when they were likely legitimate. That still left more than 1,000 journals that the researchers identified as questionable.
“I think this should be used as a helper to prescreen large numbers of journals,” he said. “But human professionals should do the final analysis.”
A firewall for science
Acuña added that the researchers didn’t want their system to be a “black box” like some other AI platforms.
“With ChatGPT, for example, you often don’t understand why it’s suggesting something,” Acuña said. “We tried to make ours as interpretable as possible.”
The team discovered, for example, that questionable journals published an unusually high number of articles. They also included authors with a larger number of affiliations than more legitimate journals, and authors who cited their own research, rather than the research of other scientists, to an unusually high level.
The new AI system isn’t publicly accessible, but the researchers hope to make it available to universities and publishing companies soon. Acuña sees the tool as one way that researchers can protect their fields from bad data — what he calls a “firewall for science.”
“As a computer scientist, I often give the example of when a new smartphone comes out,” he said. “We know the phone’s software will have flaws, and we expect bug fixes to come in the future. We should probably do the same with science.”
Co-authors on the study included Han Zhuang at the Eastern Institute of Technology in China and Lizheng Liang at Syracuse University in the United States.
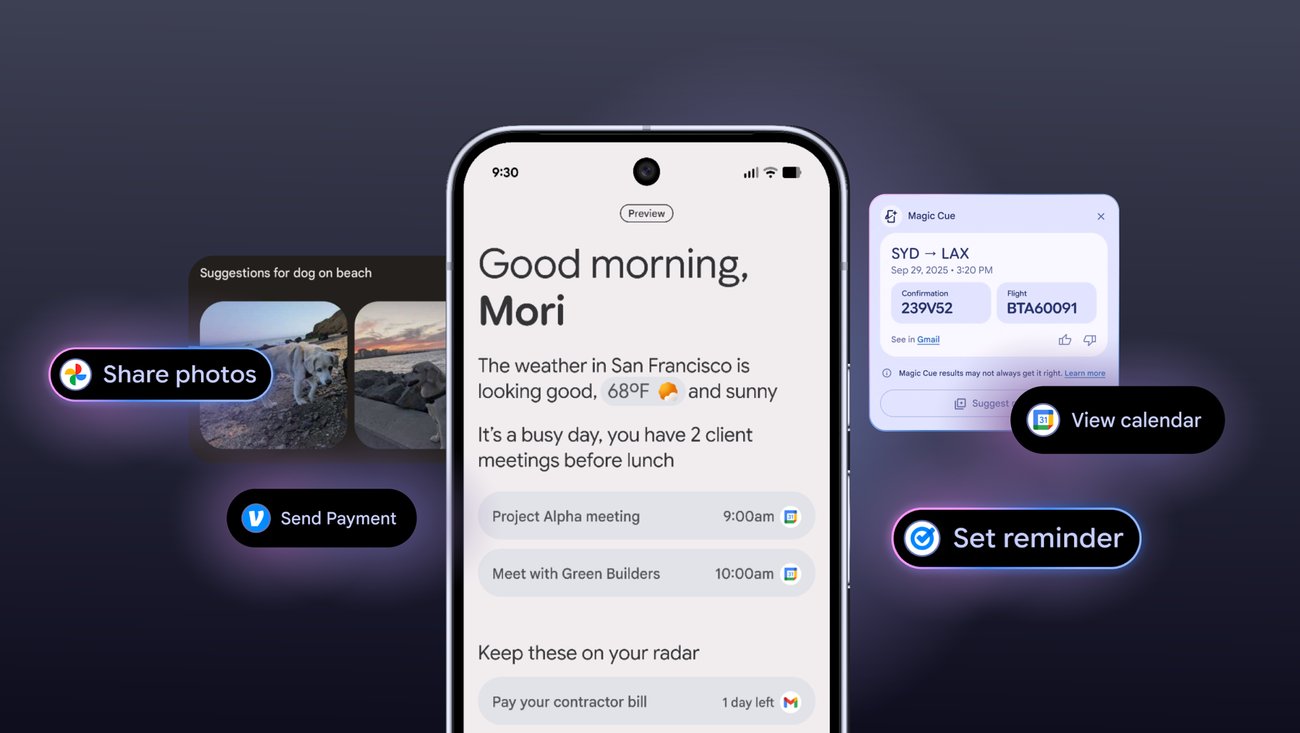
Pixel Magic Cue AI is Google’s latest strategic play to embed proactive, time-saving intelligence directly into the Pixel experience, fundamentally reshaping mobile productivity.
Google is doubling down on ambient intelligence, and its latest move, the Pixel Magic Cue AI, aims to fundamentally reshape how users interact with their devices for everyday productivity. This isn’t just another feature; it’s a strategic push to embed AI deeper into the Pixel experience, making the phone a proactive assistant rather than a reactive tool.
The premise is simple: anticipate user needs, streamline tasks, and cut down on decision fatigue. According to the announcement, the Pixel Magic Cue AI is designed to save users significant time by intelligently managing information and actions across the device. This positions Google squarely in the ongoing race among tech giants to deliver truly useful on-device AI, moving beyond flashy demos to tangible, daily benefits.
One of the core promises of Magic Cue AI is its ability to distill complex information. Imagine receiving a lengthy email thread or a dense document. Instead of sifting through paragraphs, Magic Cue can provide a concise summary, highlighting key points and action items. This isn’t just about speed reading; it’s about intelligent extraction, allowing users to grasp the essence of communications without the cognitive load. For professionals drowning in digital noise, this could be a game-changer, freeing up mental bandwidth for more critical tasks.
Beyond Summaries: Proactive Assistance
The AI’s capabilities extend far beyond text summarization. It’s engineered to anticipate your next move. For instance, if you’re planning a trip, Magic Cue AI can automatically pull flight details from your emails, suggest local attractions based on your calendar, and even pre-fill forms for hotel check-ins. This level of predictive assistance moves the Pixel from a device you operate to a partner that understands your context and helps you navigate your day with minimal friction. It’s a subtle but powerful shift towards a truly ambient computing experience, where the technology fades into the background, leaving you to focus on the task at hand.
Another significant time-saver comes in managing notifications and communications. Magic Cue AI can intelligently prioritize alerts, group related messages, and even draft quick replies based on context and your communication style. This isn’t just about silencing your phone; it’s about ensuring you see what’s important when it’s important, and providing tools to respond efficiently without getting bogged down in trivial interactions. The implications for digital well-being are substantial, potentially reducing the constant pull of notifications that often fragment our attention.
Finally, the Pixel Magic Cue AI aims to simplify device management itself. From optimizing battery life based on usage patterns to suggesting app shortcuts for frequently performed actions, the AI learns and adapts to your habits. This continuous optimization means less time spent tweaking settings and more time using your phone effectively. It’s Google’s vision of a smartphone that truly understands its owner, making the device feel less like a gadget and more like an extension of your own productivity.
The rollout of Pixel Magic Cue AI isn’t just about adding new features; it’s about Google’s long-term strategy to differentiate its hardware through intelligent software. As AI becomes increasingly commoditized, the real battle will be in how seamlessly and intuitively it integrates into daily life. Magic Cue represents a significant step in that direction, setting a new bar for what users can expect from their mobile devices and pushing the industry further into an era of truly proactive, context-aware computing.
-
Tools & Platforms3 weeks ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy1 month ago
Ethics & Policy1 month agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences3 months ago
Events & Conferences3 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers2 months ago
Jobs & Careers2 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Funding & Business2 months ago
Funding & Business2 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries
-

 Education2 months ago
Education2 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi
-

 Jobs & Careers2 months ago
Jobs & Careers2 months agoAstrophel Aerospace Raises ₹6.84 Crore to Build Reusable Launch Vehicle
-

 Mergers & Acquisitions2 months ago
Mergers & Acquisitions2 months agoDonald Trump suggests US government review subsidies to Elon Musk’s companies