AI Research
Manage multi-tenant Amazon Bedrock costs using application inference profiles
Successful generative AI software as a service (SaaS) systems require a balance between service scalability and cost management. This becomes critical when building a multi-tenant generative AI service designed to serve a large, diverse customer base while maintaining rigorous cost controls and comprehensive usage monitoring.
Traditional cost management approaches for such systems often reveal limitations. Operations teams encounter challenges in accurately attributing costs across individual tenants, particularly when usage patterns demonstrate extreme variability. Enterprise clients might have different consumption behaviors—some experiencing sudden usage spikes during peak periods, whereas others maintain consistent resource consumption patterns.
A robust solution requires a context-driven, multi-tiered alerting system that exceeds conventional monitoring standards. By implementing graduated alert levels—from green (normal operations) to red (critical interventions)—systems can develop intelligent, automated responses that dynamically adapt to evolving usage patterns. This approach enables proactive resource management, precise cost allocation, and rapid, targeted interventions that help prevent potential financial overruns.
The breaking point often comes when you experience significant cost overruns. These overruns aren’t due to a single factor but rather a combination of multiple enterprise tenants increasing their usage while your monitoring systems fail to catch the trend early enough. Your existing alerting system might only provide binary notifications—either everything is fine or there’s a problem—that lack the nuanced, multi-level approach needed for proactive cost management. The situation is further complicated by a tiered pricing model, where different customers have varying SLA commitments and usage quotas. Without a sophisticated alerting system that can differentiate between normal usage spikes and genuine problems, your operations team might find itself constantly taking reactive measures rather than proactive ones.
This post explores how to implement a robust monitoring solution for multi-tenant AI deployments using a feature of Amazon Bedrock called application inference profiles. We demonstrate how to create a system that enables granular usage tracking, accurate cost allocation, and dynamic resource management across complex multi-tenant environments.
What are application inference profiles?
Application inference profiles in Amazon Bedrock enable granular cost tracking across your deployments. You can associate metadata with each inference request, creating a logical separation between different applications, teams, or customers accessing your foundation models (FMs). By implementing a consistent tagging strategy with application inference profiles, you can systematically track which tenant is responsible for each API call and the corresponding consumption.
For example, you can define key-value pair tags such as TenantID, business-unit, or ApplicationID and send these tags with each request to partition your usage data. You can also send the application inference profile ID with your request. When combined with AWS resource tagging, these tag-enabled profiles provide visibility into the utilization of Amazon Bedrock models. This tagging approach introduces accurate chargeback mechanisms to help you allocate costs proportionally based on actual usage rather than arbitrary distribution approaches. To attach tags to the inference profile, see Tagging Amazon Bedrock resources and Organizing and tracking costs using AWS cost allocation tags. Furthermore, you can use application inference profiles to identify optimization opportunities specific to each tenant, helping you implement targeted improvements for the greatest impact to both performance and cost-efficiency.
Solution overview
Imagine a scenario where an organization has multiple tenants, each with their respective generative AI applications using Amazon Bedrock models. To demonstrate multi-tenant cost management, we provide a sample, ready-to-deploy solution on GitHub. It deploys two tenants with two applications, each within a single AWS Region. The solution uses application inference profiles for cost tracking, Amazon Simple Notification Service (Amazon SNS) for notifications, and Amazon CloudWatch to produce tenant-specific dashboards. You can modify the source code of the solution to suit your needs.
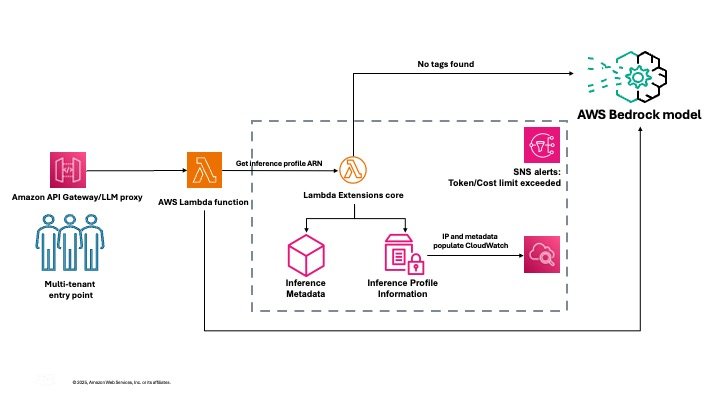
The following diagram illustrates the solution architecture.
The solution handles the complexities of collecting and aggregating usage data across tenants, storing historical metrics for trend analysis, and presenting actionable insights through intuitive dashboards. This solution provides the visibility and control needed to manage your Amazon Bedrock costs while maintaining the flexibility to customize components to match your specific organizational requirements.
In the following sections, we walk through the steps to deploy the solution.
Prerequisites
Before setting up the project, you must have the following prerequisites:
- AWS account – An active AWS account with permissions to create and manage resources such as Lambda functions, API Gateway endpoints, CloudWatch dashboards, and SNS alerts
- Python environment – Python 3.12 or higher installed on your local machine
- Virtual environment – It’s recommended to use a virtual environment to manage project dependencies
Create the virtual environment
The first step is to clone the GitHub repo or copy the code into a new project to create the virtual environment.

Update models.json
Review and update the models.json file to reflect the correct input and output token pricing based on your organization’s contract, or use the default settings. Verifying you have the right data at this stage is critical for accurate cost tracking.

Update config.json
Modify config.json to define the profiles you want to set up for cost tracking. Each profile can have multiple key-value pairs for tags. For every profile, each tag key must be unique, and each tag key can have only one value. Each incoming request should contain these tags or the profile name as HTTP headers at runtime.
As part of the solution, you also configure a unique Amazon Simple Storage Service (Amazon S3) bucket for saving configuration artifacts and an admin email alias that will receive alerts when a particular threshold is breached.

Create user roles and deploy solution resources
After you modify config.json and models.json, run the following command in the terminal to create the assets, including the user roles:
python setup.py --create-user-rolesAlternately, you can create the assets without creating user roles by running the following command:
python setup.pyMake sure that you are executing this command from the project directory. Note that full access policies are not advised for production use cases.
The setup command triggers the process of creating the inference profiles, building a CloudWatch dashboard to capture the metrics for each profile, deploying the inference Lambda function that executes the Amazon Bedrock Converse API and extracts the inference metadata and metrics related to the inference profile, sets up the SNS alerts, and finally creates the API Gateway endpoint to invoke the Lambda function.

When the setup is complete, you will see the inference profile IDs and API Gateway ID listed in the config.json file. (The API Gateway ID will also be listed in the final part of the output in the terminal)

When the API is live and inferences are invoked from it, the CloudWatch dashboard will show cost tracking. If you experience significant traffic, the alarms will trigger an SNS alert email.

For a video version of this walkthrough, refer to Track, Allocate, and Manage your Generative AI cost & usage with Amazon Bedrock.
You are now ready to use Amazon Bedrock models with this cost management solution. Make sure that you are using the API Gateway endpoint to consume these models and send the requests with the tags or application inference profile IDs as headers, which you provided in the config.json file. This solution will automatically log the invocations and track costs for your application on a per-tenant basis.
Alarms and dashboards
The solution creates the following alarms and dashboards:
- BedrockTokenCostAlarm-{profile_name} – Alert when total token cost for {profile_name} exceeds {cost_threshold} in 5 minutes
- BedrockTokensPerMinuteAlarm-{profile_name} – Alert when tokens per minute for {profile_name} exceed {tokens_per_min_threshold}
- BedrockRequestsPerMinuteAlarm-{profile_name} – Alert when requests per minute for {profile_name} exceed {requests_per_min_threshold}
You can monitor and receive alerts about your AWS resources and applications across multiple Regions.
A metric alarm has the following possible states:
- OK – The metric or expression is within the defined threshold
- ALARM – The metric or expression is outside of the defined threshold
- INSUFFICIENT_DATA – The alarm has just started, the metric is not available, or not enough data is available for the metric to determine the alarm state
After you add an alarm to a dashboard, the alarm turns gray when it’s in the INSUFFICIENT_DATA state and red when it’s in the ALARM state. The alarm is shown with no color when it’s in the OK state.
An alarm invokes actions only when the alarm changes state from OK to ALARM. In this solution, an email is sent to through your SNS subscription to an admin as specified in your config.json file. You can specify additional actions when the alarm changes state between OK, ALARM, and INSUFFICIENT_DATA.
Considerations
Although the API Gateway maximum integration timeout (30 seconds) is lower than the Lambda timeout (15 minutes), long-running model inference calls might be cut off by API Gateway. Lambda and Amazon Bedrock enforce strict payload and token size limits, so make sure your requests and responses fit within these boundaries. For example, the maximum payload size is 6 MB for synchronous Lambda invocations and the combined request line and header values can’t exceed 10,240 bytes for API Gateway payloads. If your workload can work within these limits, you will be able to use this solution.
Clean up
To delete your assets, run the following command:
python unsetup.pyConclusion
In this post, we demonstrated how to implement effective cost monitoring for multi-tenant Amazon Bedrock deployments using application inference profiles, CloudWatch metrics, and custom CloudWatch dashboards. With this solution, you can track model usage, allocate costs accurately, and optimize resource consumption across different tenants. You can customize the solution according to your organization’s specific needs.
This solution provides the framework for building an intelligent system that can understand context—distinguishing between a gradual increase in usage that might indicate healthy business growth and sudden spikes that could signal potential issues. An effective alerting system needs to be sophisticated enough to consider historical patterns, time of day, and customer tier when determining alert levels. Furthermore, these alerts can trigger different types of automated responses based on the alert level: from simple notifications, to automatic customer communications, to immediate rate-limiting actions.
Try out the solution for your own use case, and share your feedback and questions in the comments.
About the authors
 Claudio Mazzoni is a Sr Specialist Solutions Architect on the Amazon Bedrock GTM team. Claudio exceeds at guiding costumers through their Gen AI journey. Outside of work, Claudio enjoys spending time with family, working in his garden, and cooking Uruguayan food.
Claudio Mazzoni is a Sr Specialist Solutions Architect on the Amazon Bedrock GTM team. Claudio exceeds at guiding costumers through their Gen AI journey. Outside of work, Claudio enjoys spending time with family, working in his garden, and cooking Uruguayan food.
 Fahad Ahmed is a Senior Solutions Architect at AWS and assists financial services customers. He has over 17 years of experience building and designing software applications. He recently found a new passion of making AI services accessible to the masses.
Fahad Ahmed is a Senior Solutions Architect at AWS and assists financial services customers. He has over 17 years of experience building and designing software applications. He recently found a new passion of making AI services accessible to the masses.

Manish Yeladandi is a Solutions Architect at AWS, specializing in AI/ML, containers, and security. Combining deep cloud expertise with business acumen, Manish architects secure, scalable solutions that help organizations optimize their technology investments and achieve transformative business outcomes.
 Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing and artificial intelligence. He focuses on deep learning, including NLP and computer vision domains. He helps customers achieve high-performance model inference on Amazon SageMaker.
Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing and artificial intelligence. He focuses on deep learning, including NLP and computer vision domains. He helps customers achieve high-performance model inference on Amazon SageMaker.
 James Park is a Solutions Architect at Amazon Web Services. He works with Amazon.com to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. In h is spare time he enjoys seeking out new cultures, new experiences, and staying up to date with the latest technology trends. You can find him on LinkedIn.
James Park is a Solutions Architect at Amazon Web Services. He works with Amazon.com to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. In h is spare time he enjoys seeking out new cultures, new experiences, and staying up to date with the latest technology trends. You can find him on LinkedIn.
 Abhi Shivaditya is a Senior Solutions Architect at AWS, working with strategic global enterprise organizations to facilitate the adoption of AWS services in areas such as Artificial Intelligence, distributed computing, networking, and storage. His expertise lies in Deep Learning in the domains of Natural Language Processing (NLP) and Computer Vision. Abhi assists customers in deploying high-performance machine learning models efficiently within the AWS ecosystem.
Abhi Shivaditya is a Senior Solutions Architect at AWS, working with strategic global enterprise organizations to facilitate the adoption of AWS services in areas such as Artificial Intelligence, distributed computing, networking, and storage. His expertise lies in Deep Learning in the domains of Natural Language Processing (NLP) and Computer Vision. Abhi assists customers in deploying high-performance machine learning models efficiently within the AWS ecosystem.


In 1950, British mathematician Alan Turing (1912–1954) proposed a simple way to test artificial intelligence. His idea, known as the Turing Test, was to see if a computer could carry on a text-based conversation so well that a human judge could not reliably tell it apart from another human. If the computer could “fool” the judge, Turing argued, it should be considered intelligent.
For decades, Turing’s test shaped public understanding of AI. Yet as technology has advanced, many researchers have asked whether imitating human conversation really proves intelligence — or whether it only shows that machines can mimic certain human behaviors. Large language models like ChatGPT can already hold convincing conversations. But does that mean they understand what they are saying?
In a Mind Matters podcast interview, Dr. Georgios Mappouras tells host Robert J. Marks that the answer is no. In a recent paper, The General Intelligence Threshold, Mappouras introduces what he calls Turing Test 2.0. This updated approach sets a higher bar for intelligence than simply chatting like a human. It asks whether machines can go beyond imitation to produce new knowledge.
From information to knowledge
At the heart of Mappouras’s proposal is a distinction between two kinds of information, non-functional vs. functional:
- Non-functional information is raw data or observations that don’t lead to new insights by themselves. One example would be noticing that an apple falls from a tree.
- Functional information is knowledge that can be applied to achieve something new. When Isaac Newton connected the falling apple to the force of gravity, he transformed ordinary observation into scientific law.
True intelligence, Mappouras argues, is the ability to transform non-functional information into functional knowledge. This creative leap is what allows humans to build skyscrapers, develop medicine, and travel to the moon. A machine that merely rearranges words or retrieves facts cannot be said to have reached the same level.
The General Intelligence Threshold
Mappouras calls this standard the General Intelligence Threshold. His threshold sets a simple challenge: given existing knowledge and raw information, can the system generate new insights that were not directly programmed into it?
This threshold does not require constant displays of brilliance. Even one undeniable breakthrough — a “flash of genius” — would be enough to demonstrate that a machine possesses general intelligence. Just as a person may excel in math but not physics, a machine would only need to show creativity once to prove its potential.
Creativity and open problems
One way to apply the new test is through unsolved problems in mathematics. Throughout history, breakthroughs such as Andrew Wiles’s proof of Fermat’s Last Theorem or Grigori Perelman’s solution to the Poincaré Conjecture marked milestones of human creativity. If AI could solve open problems like the Riemann Hypothesis or the Collatz Conjecture — problems that no one has ever solved before — it would be strong evidence that the system had crossed the threshold into true intelligence.
Large language models already solve equations and perform advanced calculations, but solving a centuries-old unsolved problem would show something far deeper: the ability to create knowledge that has never existed before.
Beyond symbol manipulation
Mappouras also draws on philosopher John Searle’s famous “Chinese Room” thought experiment. In the scenario, a person who does not understand Chinese sits in a room with a rulebook for manipulating Chinese characters. By following instructions, the person produces outputs that convince outsiders he understands the language, even though he does not.
This scenario, Searle argued, shows that a computer might appear intelligent without real understanding. Mappouras agrees but goes further. For him, real intelligence is proven not just by producing outputs, but by acting on new knowledge. If the instructions in the Chinese Room included a way to escape, the person could only succeed if he truly understood what the words meant. In the same way, AI must demonstrate it can act meaningfully on information, not just shuffle symbols.
Can AI pass the new test?
So far, Mappouras does not think modern AI has passed the General Intelligence Threshold. Systems like ChatGPT may look impressive, but their apparent creativity usually comes from patterns in the massive data sets on which they were trained. They have not shown the ability to produce new, independent knowledge disconnected from prior inputs.
That said, Mappouras emphasizes that success would not require constant novelty. One true act of creativity — an undeniable demonstration of new knowledge — would be enough. Until that happens, he remains cautious about claims that today’s AI is truly intelligent.
A shift in the debate
The debate over artificial intelligence is shifting. The original Turing Test asked whether machines could fool us into thinking they were human. Turing Test 2.0 asks a harder question: can they discover something new?
Mappouras believes this is the real measure of intelligence. Intelligence is not imitation — it is innovation. Whether machines will ever cross that line remains uncertain. But if they do, the world will not just be talking with computers. We will be learning from them.
Final thoughts: Today’s systems, tomorrow’s threshold
Models like ChatGPT and Grok are remarkable at conversation, summarization, and problem-solving within known domains, but their strengths still reflect pattern learning from vast training data. By Mappouras’s standard, they will cross the General Intelligence Threshold only when they produce a verifiable breakthrough — an insight not traceable to prior text or human scaffolding, such as an original solution to a major open problem. Until then, they remain powerful imitators and accelerators of human work — impressive, useful, and transformative, but not yet creators of genuinely new knowledge.
Additional Resources
AI Research
UTM Celebrates Malaysia’s Youngest AI Researcher Recognised at IEEE AI-SI 2025 – UTM NewsHub

KUALA LUMPUR, 28 August 2025 – Universiti Teknologi Malaysia (UTM) proudly hosted the Institute of Electrical and Electronics Engineers (IEEE) International Conference on Artificial Intelligence for Sustainable Innovation (AI-SI) 2025, themed “Empowering Innovation for a Sustainable Future.” The conference gathered global experts, academics, and industry leaders to explore how Artificial Intelligence (AI) can address sustainability challenges. Among its highlights was the remarkable achievement of 17-year-old Malaysian researcher, Charanarravindaa Suriess, who was celebrated as the youngest presenter and awarded Best Presenter for his groundbreaking paper on adversarial robustness in neural networks. His recognition reflected not only individual brilliance but also Malaysia’s growing strength in the global AI research landscape.
Charanarravindaa’s presentation, titled “Two-Phase Evolutionary Framework for Adversarial Robustness in Neural Networks,” introduced an innovative framework designed to improve AI systems’ ability to defend against adversarial attacks. His contribution addressed one of the most pressing challenges in AI, ensuring resilience and trustworthiness of machine learning models in real-world applications. Born in Johor Bahru, his journey into science and computing began early; by primary school, he was already troubleshooting computers and experimenting with small websites. At just 15 years old, he graduated early, motivated by a passion for deeper challenges. Participation in international hackathons, including DeepLearning Week at Nanyang Technological University (NTU) Singapore, strengthened his resolve and provided the encouragement that led to his first academic paper, now internationally recognised at IEEE AI-SI 2025.
Beyond academia, Charanarravindaa has also demonstrated entrepreneurial spirit by founding Cortexa, a startup dedicated to advancing AI robustness, architectures, and applied AI for scientific discovery. His long-term vision is to integrate artificial intelligence with quantum computing and theoretical physics to expand the boundaries of knowledge. This ambition is a testament to the potential of Malaysia’s youth in contributing to frontier technologies. His recognition at IEEE AI-SI 2025 reflects IEEE’s mission of advancing technology for humanity, where innovation is seen as a universal endeavour not limited by age. By honouring a young researcher, IEEE underscored its commitment to empowering future generations of scientists and innovators to shape technology for global good.

During the conference, the Faculty of Artificial Intelligence (FAI), UTM, represented by Associate Professor Dr. Noor Azurati Ahmad, extended an invitation to Charanarravindaa to explore possible research collaborations. This initiative aligns with FAI’s vision to be a leader in AI education, research, and innovation, with a particular focus on trustworthy, robust, and sustainable AI. Early discussions centred on aligning his research interests with UTM’s expertise in advanced architectures and digital sustainability. Such collaboration exemplifies how institutions and young talent can come together to accelerate innovation, while also strengthening Malaysia’s position as an emerging hub for AI research and talent cultivation.
At the national level, this achievement resonates strongly with the Malaysia National Artificial Intelligence Roadmap (2021–2025), which identifies talent development as a central pillar in building an AI-ready nation. Prime Minister Datuk Seri Anwar Ibrahim has repeatedly highlighted the urgency of nurturing local talent to enhance competitiveness and leadership in the global digital economy. Charanarravindaa’s success demonstrates tangible progress in this direction, showcasing how Malaysia can produce young innovators capable of contributing to both national aspirations and international scientific advancement. Through platforms such as IEEE AI-SI 2025, UTM reaffirms its role as a catalyst for excellence in AI research and talent development, embodying its mission to prepare the next generation of scholars and innovators who will drive sustainable futures.
-

 Business2 weeks ago
Business2 weeks agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-
Tools & Platforms1 month ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy2 months ago
Ethics & Policy2 months agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences4 months ago
Events & Conferences4 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers3 months ago
Jobs & Careers3 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Education2 months ago
Education2 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Education2 months ago
Education2 months agoMacron says UK and France have duty to tackle illegal migration ‘with humanity, solidarity and firmness’ – UK politics live | Politics
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi
-

 Funding & Business3 months ago
Funding & Business3 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries