Books, Courses & Certifications
Machine Learning Courses for Certification in 2024

Machine learning certification is a recognized accreditation of a data analyst or a data scientist’s machine learning skills and knowledge. Beginners and experienced professionals alike can acquire machine learning certifications to boost their knowledge and gain accreditation for their skills.
The demand for machine learning (ML) skills is on the rise, driven by the increasing importance of high-performance technologies like artificial intelligence (AI) across various sectors. Jobs in the machine learning field are booming due to its broad application in healthcare, education, marketing, retail, e-commerce, financial services, and other industries.
As organizations seek to make effective use of data, there’s a growing need for skilled professionals who can design, develop, and deploy ML models. Online learning platform Coursera features a deep collection of courses to build those skills—here are our picks for the best Coursera machine learning certifications to help you develop the expertise you need to succeed.
Top 9 Coursera Machine Learning Course Comparison
The following table shows at a glance the salient details about each course, including its provider, duration, and cost.
Machine Learning Specialization
Provider: Stanford University and DeepLearning.AI
Level: Beginner
Shareable Certificate: Yes
The Machine Learning Specialization is a collaboration between Stanford University Online and DeepLearning.AI. This beginner-friendly program teaches the fundamentals of machine learning and its application in real-world AI projects. It covers supervised and unsupervised learning techniques and best practices in AI and machine learning innovation, and provides practical skills to tackle real-world challenges.
Why We Picked It
This specialization stands out for its comprehensive approach to introducing machine learning concepts while providing hands-on experience in real-world projects, making it an ideal starting point for beginners.
Skills Acquired
Successful certification takers will be equipped to build ML models using NumPy & scikit-learn. They will learn to train supervised models for prediction and binary classification, apply best practices in ML development, use unsupervised learning techniques such as clustering and anomaly detection, create neural networks with TensorFlow for multi-class classification, and implement decision trees and tree ensemble methods. In addition, they will construct recommender systems with collaborative filtering and content-based deep learning and develop deep reinforcement learning models.
Visit Stanford/DeepLearning.AI ML Specialization at Coursera
Best For
- Beginners who want to solidify their ML understanding
Pre-Requisites
- Basic coding
- High school-level math
Duration and Price
- Two months, 10 hours per week
- $59 per month for a Coursera subscription
Post-Graduate Certificate, Data Science and Machine Learning
Provider: Indian Institute of Technology, Roorkee
Level: Beginner
Shareable Certificate: Yes
IIT Roorkee’s post-graduate certificate in data science and machine learning provides a comprehensive program focusing on industry-standard tools and methodologies while covering basic topics such as data science, machine learning, mathematics, and data visualization. It is designed for people who have no prior coding expertise and begins with the fundamentals of data science and machine learning.
Why We Picked It
This certificate program provides a holistic approach to covering essential topics in data science and machine learning.
Skills Acquired
Certification takers will learn to analyze real world data, create analytical models, and derive actionable data insights, as well as the basics of data science, mathematics for data science, Python programming language, exploratory data analysis, data visualization, and machine learning.
Visit IIT Roorkee Data Science and ML at Coursera
Best For
- Beginners without prior coding experience to acquire foundational knowledge in data science and ML
Pre-Requisites
- Exposure to high school mathematics
Duration and Price
Post-Graduate Certificate, Machine Learning For Finance
Provider: Indian Institute of Technology, Roorkee
Level: Beginner
Shareable Certificate: Yes
IIT Roorkee’s post-graduate certificate in machine learning for finance is designed for finance professionals who want to incorporate AI/ML and data science into their jobs. It highlights the use of AI-based models in finance to address real-world wealth management difficulties and improve investment decision-making.
Why We Picked It
The program specializes in focusing on applied ML techniques in the finance sector, making it ideal for finance professionals seeking to advance their skills in this area.
Skills Acquired
Students learn about ML, Python, and R programming, wealth management, financial risk management, algorithmic portfolio management, trading strategies, and security market prediction.
Visit IIT Roorkee ML for Finance at Coursera
Best For
- Specializing in machine learning in finance
Pre-Requisites
Duration and Price
Professional Certificate, Machine Learning Engineer
Provider: Google
Level: Intermediate
Shareable Certificate: Yes
This course teaches the necessary skills for success in a machine learning engineering role. It covers designing, building, and deploying ML models with Google Cloud technologies. It also prepares certification takers for the Google Cloud Professional Machine Learning Engineer certification exam, highlighting its significance in the context of other Google Cloud certifications.
Why We Picked It
This Google course is handpicked for its specialized focus on preparing individuals for a machine learning engineering role using Google Cloud Technologies, making it an excellent choice for those who are knowledgeable in the Google data space.
Skills Acquired
Upon successful completion of the course, students will acquire skills in Tensorflow, machine learning, feature engineering, Google Cloud, and cloud computing.
Visit Google ML Engineer at Coursera
Best For
- Best for experienced data engineers and programmers
Pre-Requisites
- Data engineering or programming experience recommended
- Interest in learning machine learning
Duration and Price
- Two months, 10 hours per week
- $59 per month for a Coursera subscription
Professional Certificate, IBM Machine Learning
Provider: IBM
Level: Intermediate
Shareable Certificate: Yes
IBM’s Machine Learning Professional certification teaches practical skills that machine learning experts use, including comparing algorithms and creating recommender systems in Python. This certification will also help develop expertise in K-Nearest Neighbor (KNN) regression, Principal Component Analysis (PCA), and neural networks and learn how to predict course ratings using regression and classification models.
Why We Picked It
This program has a practical approach to teaching skills that are important for machine learning experts, making it an ideal choice for individuals looking to learn new skills and enhance their proficiency in this field.
Skills Acquired
After course completion, students will be able to acquire skills in data science, deep learning (DL), ML, AI, Python, statistical hypothesis testing, exploratory data analysis, supervised learning, linear regression, ridge regression.
Visit IBM Machine Learning at Coursera
Best For
- Best for those with experience in Python programming, statistics, and linear algebra
Pre-Requisites
- Math, statistics, and computer programming background
- Familiarity with Python and mathematical concepts
Duration and Price
- 3 months, 10 hours per week
- $59 per month for Coursera subscription
IBM Machine Learning with Python
Provider: IBM
Level: Intermediate
Shareable Certificate: Yes
IBM conducts machine learning with Python as part of its AI Engineering Professional Certificate and Data Science Professional Certificate. This introduction to machine learning using Python is suitable for those who want to enhance their data science career or get into machine learning and deep learning.
It covers topics such as supervised and unsupervised learning, regression classification algorithms such as KNN, decision trees, and logistic regression. It emphasizes hands-on learning with Python libraries such as SciPy and scikt-learn, providing job-ready skills and a machine learning certificate upon completion.
Why We Picked It
Python is one of the most popular programming languages and one of the go-to languages for handling data, making it an ideal choice for individuals looking to specialize in this area.
Skills Acquired
Students gain skills in sourcing, organizing, and managing data, descriptive analysis, binary classification, multivariate linear regressions, ML, statistical approaches to regression, and tools to better address ML tasks.
Visit IBM ML with Python at Coursera
Best For
- Best for specializing in machine learning using Python
Pre-Requisites
- Knowledge of Python, data analysis and visualization techniques
- High school mathematics
Duration and Price
- 12 hours
- $59 per month for Coursera subscription
Machine Learning Specialization
Provider: University of Washington
Level: Intermediate
Shareable Certificate: Yes
The University of Washington’s machine learning specialization course helps individuals innovate and get into the in-demand field of machine learning. Participants receive practical experience in major areas of machine learning such as prediction, classification, clustering, and data retrieval through a series of case studies. They learn how to analyze vast and complicated datasets, design systems that adapt and improve over time, and develop intelligent applications that can make data-driven predictions.
Why We Picked It
This specialization emphasizes experience in essential areas of machine learning making it the best choice for individuals seeking to deepen their knowledge, understanding, and expertise in this field.
Skills Acquired
Students learn about data clustering algorithms, machine learning, classification algorithms, and decision trees.
Visit UW ML Specialization at Coursera
Best For
- Best for specializing in non-parametric supervised learning algorithm
Pre-Requisites
- Related experience in data science, IT, and machine learning
Duration and Price
- Two months, 10 hours per week
- $59 per month for Coursera subscription
Master of Science, Machine Learning and Data Science
Provider: Imperial College London
Level: Advanced
Shareable Certificate: Yes
The Department of Mathematics at Imperial College London provides a prominent master’s degree in machine learning and data science, giving students a thorough understanding of the mathematical and statistical foundations of modern machine learning algorithms. This curriculum provides students with practical skills through hands-on experience in probabilistic modeling, deep learning, unstructured data processing, and anomaly detection by utilizing industry-standard technologies such as PySpark.
Why We Picked It
This master’s program offers a rigorous curriculum focused on practical application in machine learning. It is ideal for individuals with years of experience in machine learning looking to master their skills in machine learning and data science.
Skills Acquired
Students learn Ethics in Data Science and Artificial Intelligence, programming for data science, applicable mathematics, exploratory data analytics and visualization, supervised learning, big data, statistical scalability with PySpark, Bayesian methods, and computation, deep learning, unsupervised learning, and unstructured data analysis.
Visit Imperial College ML and Data Science at Coursera
Best For
- Mastering machine learning and data science skills
Pre-Requisites
- Undergraduate degree in statistics, mathematics, engineering, physics, or computer science
- English language proficiency
Duration and Price
- 24 months, 12 courses
- $21,671 per year
Is a Coursera Machine Learning Course Worth The Investment?
Machine learning is a skill sought after by many organizations handling large datasets. Certifications are worth the investment to back up your skills and knowledge. Coursera provides a selected collection of machine learning courses that encompass fundamental ideas, specialized tasks, and practical applications, allowing you to broaden your knowledge while gaining real-world experience.
How To Choose The Right Coursera Machine Learning Course
Coursera has an extensive list of machine learning courses offered by prestigious universities and reputable online learning providers. Consider the following factors when selecting the right Coursera machine learning course for your learning needs and goals:
- Course content: Look for courses that cover topics relevant to your goals, such as supervised learning, unsupervised learning, deep learning, or specific applications of machine learning.
- Duration: Some courses may be shorter and more intensive, while others may be spaced out over a longer period with fewer weekly responsibilities. Choose a time frame that works best for your schedule and learning style.
- Outcome: Identify what you want to achieve by taking the course of your choice. Determine if you want to obtain core information, acquire practical skills, achieve a certification, or prepare for a specific career or certification exam.
- Cost: Some courses may provide financial help or scholarships, while others may need a subscription fee or a single payment. Consider any additional expenditures such as textbooks or software that may be required.
- Prerequisites: Make sure you have the necessary prior knowledge and abilities. Choose a course that reflects your current level of knowledge and experience in data.
3 Top Companies to Work For Post-Course Certification
Machine learning certifications build and demonstrate your skills and expertise, positioning you as a valuable candidate for a range of positions. Technology companies such as Apple, Amazon, and Microsoft value technical experience and appreciate creativity, problem-solving skills, and a passion for continuous learning.
![]()
Apple
Known for its innovative products and technology, Apple actively seeks machine learning specialists and experts to enhance their experience across its ecosystem. As a machine learning specialist at Apple, part of your responsibilities would be contributing to projects like Siri, Core ML, and personalized recommendations. The company provides platforms for natural language processing, computer vision, and deep learning where you can apply your skills and contribute.
Amazon
Amazon is an eCommerce giant that thrives on data-driven decision-making. Machine learning plays an important role in optimizing customer experience, supply chain management, and personalized recommendations. As an Amazon machine learning engineer, you will take part in projects such as product recommendations, fraud detection, and demand forecasting.
Microsoft
Microsoft is one of the tech giants that invests heavily in artificial intelligence and machine learning. As a data analyst or a machine learning engineer, you’ll collaborate on projects from natural language understanding computer vision and predictive analytics.
Bottom Line: Coursera Machine Learning Provides Skills and Certifications
Aspiring machine learning professionals can start their journey in Coursera’s long list of machine learning certifications, while experienced pros can advance their skills and further their professional development. The wide range of training provides the solid foundation required to navigate the complexities of the world of data. They also encourage critical thinking and problem-solving abilities. Organizations stand to greatly benefit from employees who receive such training, as they bring new perspectives, innovative approaches, and a thorough understanding of machine learning principles to the table.


















Books, Courses & Certifications
XPROMOS Launches Theia Institute™-Endorsed AI Fluency Program Offering Practitioner Certification Across Business Roles. Certified AI Training With Nod From Emerging Tech Think Tank Signals AI Fluency

“The XPROMOS AI training program delivers productivity gains beyond traditional business functions like IT, BI, and analytics. It democratizes AI productivity while increasing business ROI so that everyone wins,” said Executive Director, Todd A. Jacobs.
XPROMOS launches the first Theia Institute-endorsed certified AI training program designed to build AI fluency across non-technical teams in marketing, sales, HR, and finance. This premier global endorsement supports XPROMOS’ certified AI training that turns curiosity into capability by guiding participants to create scalable AI pilots that drive measurable value. The program aligns with the Washington DC-based nonprofit think tank’s mission of responsible, ethical, and practical AI adoption.

LOS ANGELES, CA – XPROMOS, a longtime leader in revenue‑driving strategy for enterprise brands, announces a premier global endorsement by Washington DC’s Theia Institute, a non-profit emerging technologies think tank shaping the standards of responsible AI use in business and policy. XPROMOS now offers an official Theia Institute certification for AI Fluency to qualified AI Training participants in their respective domains, including marketing, sales, operations, HR, finance, and more.
“This program turns dabblers into AI Fluents: people who use AI with clarity, not just curiosity,” said co-founder Yvette Brown.
“We built it to teach AI fluency and drive business value across functions, grounded in real understanding of governance, bias, and responsible use. Theia’s endorsement validates what we’ve always believed: AI literacy isn’t enough. If teams are going to extract real value responsibly, they need fluency, so they can think with the tech, not just use it.” Yvette Brown added, “When humans don’t understand AI’s capabilities and its limitations, they create unnecessary risk. This program changes that,” concluded Yvette Brown.
XPROMOS’ training is one of the first programs of its kind to be endorsed by Theia Institute, making it a trusted on‑ramp to strategic, ethical AI integration for non‑technical professionals. Participants who complete the program are awarded a credential that aligns directly with their business function, offering credibility, clarity, and a new kind of career capital.
“We’re proud to provide our most exclusive endorsement seal to XPROMOS’ AI training materials and educational methodology as it aligns with our think tank’s focus at the intersection of people and technology of preparing people for today’s evolving workplace.” stated Executive Director, Todd A. Jacobs.
“AI Fluency credentials ensure that people in marketing, sales, and HR also benefit from the growing workplace adoption of AI tools. The XPROMOS AI training program delivers productivity gains beyond traditional business functions like IT, BI, and analytics. It democratizes AI productivity while increasing business ROI so that everyone wins.”
— Todd A. Jacobs, Executive Director
Theia Institute™ Non-Profit Think Tank
The program was built for professionals navigating the AI shift without hype; early adopters in business units who need capability, not just content. With Theia’s endorsement, XPROMOS positions its AI training not just as a course, but as a new standard for responsible intelligence.
About XPROMOS
XPROMOS is an AI Fluency accelerator built by enterprise marketing veterans. With decades of experience driving results at scale, the company now helps professionals across industries gain the skills and strategic perspective needed to lead with AI. Through its Theia Institute-endorsed training, XPROMOS empowers creators and business leaders to earn real certification as Generative AI Practitioners, making them relevant, resilient, and ready for what’s next.
About Theia Institute
Theia Institute is a nonprofit AI governance, ethics, and cybersecurity think tank based in Washington, D.C., dedicated to advancing policy and decision-making through rigorous research and comprehensive analysis. Its commitment to an ethical, balanced, and unbiased approach sets it apart in the realm of business privacy, AI governance, and public policy.
Media Contact
Company Name: XPROMOS
Contact Person: Yvette Brown, XPROMOS Co-Founder
Email: Send Email
Phone: 7143370371
City: Laguna Hills
State: California
Country: United States
Website: https://xpromos.com
This post was co-written with Nick Frichette and Vijay George from Datadog.
As organizations increasingly adopt Amazon Bedrock for generative AI applications, protecting against misconfigurations that could lead to data leaks or unauthorized model access becomes critical. The AWS Generative AI Adoption Index, which surveyed 3,739 senior IT decision-makers across nine countries, revealed that 45% of organizations selected generative AI tools as their top budget priority in 2025. As more AWS and Datadog customers accelerate their adoption of AI, building AI security into existing processes will become essential, especially as more stringent regulations emerge. But looking at AI risks in a silo isn’t enough; AI risks must be contextualized alongside other risks such as identity exposures and misconfigurations. The combination of Amazon Bedrock and Datadog’s comprehensive security monitoring helps organizations innovate faster while maintaining robust security controls.
Amazon Bedrock delivers enterprise-grade security by incorporating built-in protections across data privacy, access controls, network security, compliance, and responsible AI safeguards. Customer data is encrypted both in transit using TLS 1.2 or above and at rest with AWS Key Management Service (AWS KMS), and organizations have full control over encryption keys. Data privacy is central: your input, prompts, and outputs are not shared with model providers nor used to train or improve foundation models (FMs). Fine-tuning and customizations occur on private copies of models, providing data confidentiality. Access is tightly governed through AWS Identity and Access Management (IAM) and resource-based policies, supporting granular authorization for users and roles. Amazon Bedrock integrates with AWS PrivateLink and supports virtual private cloud (VPC) endpoints for private, internal communication, so traffic doesn’t leave the Amazon network. The service complies with key industry standards such as ISO, SOC, CSA STAR, HIPAA eligibility, GDPR, and FedRAMP High, making it suitable for regulated industries. Additionally, Amazon Bedrock includes configurable guardrails to filter sensitive or harmful content and promote responsible AI use. Security is structured under the AWS Shared Responsibility Model, where AWS manages infrastructure security and customers are responsible for secure configurations and access controls within their Amazon Bedrock environment.
Building on these robust AWS security features, Datadog and AWS have partnered to provide a holistic view of AI infrastructure risks, vulnerabilities, sensitive data exposure, and other misconfigurations. Datadog Cloud Security employs both agentless and agent-based scanning to help organizations identify, prioritize, and remediate risks across cloud resources. This integration helps AWS users prioritize risks based on business criticality, with security findings enriched by observability data, thereby enhancing their overall security posture in AI implementations.
We’re excited to announce new security capabilities in Datadog Cloud Security that can help you detect and remediate Amazon Bedrock misconfigurations before they become security incidents. This integration helps organizations embed robust security controls and secure their use of the powerful capabilities of Amazon Bedrock by offering three critical advantages: holistic AI security by integrating AI security into your broader cloud security strategy, real-time risk detection through identifying potential AI-related security issues as they emerge, and simplified compliance to help meet evolving AI regulations with pre-built detections.
AWS and Datadog: Empowering customers to adopt AI securely
The partnership between AWS and Datadog is focused on helping customers operate their cloud infrastructure securely and efficiently. As organizations rapidly adopt AI technologies, extending this partnership to include Amazon Bedrock is a natural evolution. Amazon Bedrock is a fully managed service that makes high-performing FMs from leading AI companies and Amazon available through a unified API, making it an ideal starting point for Datadog’s AI security capabilities.
The decision to prioritize Amazon Bedrock integration is driven by several factors, including strong customer demand, comprehensive security needs, and the existing integration foundation. With over 900 integrations and a partner-built Marketplace, Datadog’s long-standing partnership with AWS and deep integration capabilities have helped Datadog quickly develop comprehensive security monitoring for Amazon Bedrock while using their existing cloud security expertise.
Throughout Q4 2024, Datadog Security Research observed increasing threat actor interest in cloud AI environments, making this integration particularly timely. By combining the powerful AI capabilities of AWS with Datadog’s security expertise, you can safely accelerate your AI adoption while maintaining robust security controls.
How Datadog Cloud Security helps secure Amazon Bedrock resources
After adding the AWS integration to your Datadog account and enabling Datadog Cloud Security, Datadog Cloud Security continuously monitors your AWS environment, identifying misconfigurations, identity risks, vulnerabilities, and compliance violations. These detections use the Datadog Severity Scoring system to prioritize them based on infrastructure context. The scoring considers a variety of variables, including if the resource is in production, is publicly accessible, or has access to sensitive data. This multi-layer analysis can help you reduce noise and focus your attention to the most critical misconfigurations by considering runtime behavior.
Partnering with AWS, Datadog is excited to offer detections for Datadog Cloud Security customers, such as:
- Amazon Bedrock custom models should not output model data to publicly accessible S3 buckets
- Amazon Bedrock custom models should not train from publicly writable S3 buckets
- Amazon Bedrock guardrails should have a prompt attack filter enabled and block prompt attacks at high sensitivity
- Amazon Bedrock agent guardrails should have the sensitive information filter enabled and block highly sensitive PII entities
Detect AI misconfigurations with Datadog Cloud Security
To understand how these detections can help secure your Amazon Bedrock infrastructure, let’s look at a specific use case, in which Amazon Bedrock custom models should not train from publicly writable Amazon Simple Storage Service (Amazon S3) buckets.
With Amazon Bedrock, you can customize AI models by fine-tuning on domain specific data. To do this, that data is stored in an S3 bucket. Threat actors are constantly evaluating the configuration of S3 buckets, looking for the potential to access sensitive data or even the ability to write to S3 buckets.
If a threat actor finds an S3 bucket that was misconfigured to permit public write access, and that same bucket contained data that was used to train an AI model, a bad actor could poison that dataset and introduce malicious behavior or output to the model. This is known as a data poisoning attack.
Normally, detecting these types of misconfigurations requires multiple steps: one to identify the S3 bucket misconfigured with write access, and one to identify that the bucket is being used by Amazon Bedrock. With Datadog Cloud Security, this detection is one of hundreds that are activated out of the box.
In the Datadog Cloud Security system, you can view this issue alongside surrounding infrastructure using Cloud Map. This provides live diagrams of your cloud architecture, as shown in the following screenshot. AI risks are then contextualized alongside sensitive data exposure, identity risks, vulnerabilities, and other misconfigurations to give you a 360-view of risks.

For example, you might see that your application is using Anthropic’s Claude 3.7 on Amazon Bedrock and accessing training or prompt data stored in an S3 bucket that also has public write access. This could inadvertently impact model integrity by introducing unapproved data to the large language model (LLM), so you will want to update this configuration. Though basic, the first step for most security initiatives is identifying the issue. With agentless scanning, Datadog scans your AWS environment at intervals between 15 minutes and 2 hours, so users can identify misconfigurations as they are introduced to their environment. The next step is to remediate this risk. Datadog Cloud Security offers automatically generated remediation guidance, specifically for each risk (see the following screenshot). You will get a step-by-step explanation of how to fix each finding. In this situation, we can remediate this issue by modifying the S3 bucket’s policy, helping prevent public write access. You can do this directly in AWS, create a JIRA ticket, or use the built-in workflow automation tools. From here, you can apply remediation steps directly within Datadog and confirm that the misconfiguration has been resolved.

Resolving this issue will positively impact your compliance posture, as illustrated by the posture score in Datadog Cloud Security, helping teams meet internal benchmarks and regulatory standards. Teams can also create custom frameworks or iterate on existing ones for tailored compliance controls.

As generative AI is embraced across industries, the regulatory environment will evolve. Datadog will continue partnering with AWS to expand their detection library and support secure AI adoption and compliance.
How Datadog Cloud Security detects misconfigurations in your cloud environment
You can deploy Datadog Cloud Security either with the Datadog agent, agentlessly, or both to maximize security coverage in your cloud environment. Datadog customers can start monitoring their AWS accounts for misconfigurations by first adding the AWS integration to Datadog. This enables Datadog to crawl cloud resources in customer AWS accounts.
As the Datadog system finds resources, it runs through a catalog of hundreds of out-of-the-box detection rules against these resources, looking for misconfigurations and threat paths that adversaries can exploit.
Secure your AI infrastructure with Datadog
Misconfigurations in AI systems can be risky, but with the right tools, you can have the visibility and context needed to manage them. With Datadog Cloud Security, teams gain visibility into these risks, detect threats early, and remediate issues with confidence. In addition, Datadog has also released numerous agentic AI security features, designed to help teams gain visibility into the health and security of critical AI workload, which includes new announcements made to Datadog’s LLM observability features.
Lastly, Datadog announced Bits AI Security Analyst alongside other Bits AI agents at DASH. Included as part of Cloud SIEM, Bits is an agentic AI security analyst that automates triage for AWS CloudTrail signals. Bits investigates each alert like a seasoned analyst: pulling in relevant context from across your Datadog environment, annotating key findings, and offering a clear recommendation on whether the signal is likely benign or malicious. By accelerating triage and surfacing real threats faster, Bits helps reduce mean time to remediation (MTTR) and frees analysts to focus on important threat hunting and response initiatives. This helps across different threats, including AI-related threats.
To learn more about how Datadog helps secure your AI infrastructure, see Monitor Amazon Bedrock with Datadog or check out our security documentation. If you’re not already using Datadog, you can get started with Datadog Cloud Security with a 14-day free trial.
About the Authors
 Nina Chen is a Customer Solutions Manager at AWS specializing in leading software companies to use the power of the AWS Cloud to accelerate their product innovation and growth. With over 4 years of experience working in the strategic independent software vendor (ISV) vertical, Nina enjoys guiding ISV partners through their cloud transformation journeys, helping them optimize their cloud infrastructure, driving product innovation, and delivering exceptional customer experiences.
Nina Chen is a Customer Solutions Manager at AWS specializing in leading software companies to use the power of the AWS Cloud to accelerate their product innovation and growth. With over 4 years of experience working in the strategic independent software vendor (ISV) vertical, Nina enjoys guiding ISV partners through their cloud transformation journeys, helping them optimize their cloud infrastructure, driving product innovation, and delivering exceptional customer experiences.
 Sujatha Kuppuraju is a Principal Solutions Architect at AWS, specializing in cloud and generative AI security. She collaborates with software companies’ leadership teams to architect secure, scalable solutions on AWS and guide strategic product development. Using her expertise in cloud architecture and emerging technologies, Sujatha helps organizations optimize offerings, maintain robust security, and bring innovative products to market in an evolving tech landscape.
Sujatha Kuppuraju is a Principal Solutions Architect at AWS, specializing in cloud and generative AI security. She collaborates with software companies’ leadership teams to architect secure, scalable solutions on AWS and guide strategic product development. Using her expertise in cloud architecture and emerging technologies, Sujatha helps organizations optimize offerings, maintain robust security, and bring innovative products to market in an evolving tech landscape.
 Nick Frichette is a Staff Security Researcher for Cloud Security Research at Datadog.
Nick Frichette is a Staff Security Researcher for Cloud Security Research at Datadog.
 Vijay George is a Product Manager for AI Security at Datadog.
Vijay George is a Product Manager for AI Security at Datadog.
Books, Courses & Certifications
Set up custom domain names for Amazon Bedrock AgentCore Runtime agents
When deploying AI agents to Amazon Bedrock AgentCore Runtime (currently in preview), customers often want to use custom domain names to create a professional and seamless experience.
By default, AgentCore Runtime agents use endpoints like https://bedrock-agentcore.{region}.amazonaws.com/runtimes/{EncodedAgentARN}/invocations.
In this post, we discuss how to transform these endpoints into user-friendly custom domains (like https://agent.yourcompany.com) using Amazon CloudFront as a reverse proxy. The solution combines CloudFront, Amazon Route 53, and AWS Certificate Manager (ACM) to create a secure, scalable custom domain setup that works seamlessly with your existing agents.
Benefits of Amazon Bedrock AgentCore Runtime
If you’re building AI agents, you have probably wrestled with hosting challenges: managing infrastructure, handling authentication, scaling, and maintaining security. Amazon Bedrock AgentCore Runtime helps address these problems.
Amazon Bedrock AgentCore Runtime is framework agnostic; you can use it with LangGraph, CrewAI, Strands Agents, or custom agents you have built from scratch. It supports extended execution times up to 8 hours, perfect for complex reasoning tasks that traditional serverless functions can’t handle. Each user session runs in its own isolated microVM, providing security that’s crucial for enterprise applications.
The consumption-based pricing model means you only pay for what you use, not what you provision. And unlike other hosting solutions, Amazon Bedrock AgentCore Runtime includes built-in authentication and specialized observability for AI agents out of the box.
Benefits of custom domains
When using Amazon Bedrock AgentCore Runtime with Open Authorization (OAuth) authentication, your applications make direct HTTPS requests to the service endpoint. Although this works, custom domains offer several benefits:
- Custom branding – Client-side applications (web browsers, mobile apps) display your branded domain instead of AWS infrastructure details in network requests
- Better developer experience – Development teams can use memorable, branded endpoints instead of copying and pasting long AWS endpoints across code bases and configurations
- Simplified maintenance – Custom domains make it straightforward to manage endpoints when deploying multiple agents or updating configurations across environments
Solution overview
In this solution, we use CloudFront as a reverse proxy to transform requests from your custom domain into Amazon Bedrock AgentCore Runtime API calls. Instead of using the default endpoint, your applications can make requests to a user-friendly URL like https://agent.yourcompany.com/.
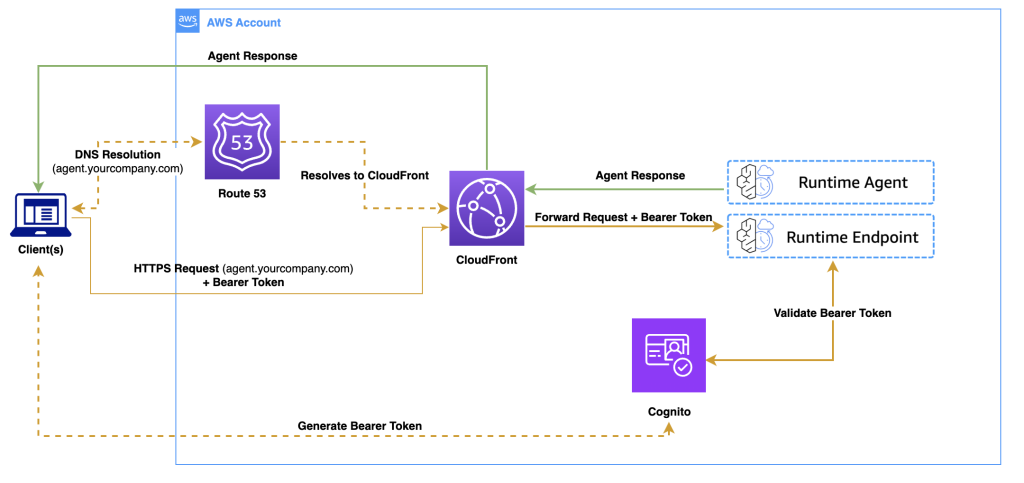
The following diagram illustrates the solution architecture.
The workflow consists of the following steps:
- A client application authenticates with Amazon Cognito and receives a bearer token.
- The client makes an HTTPS request to your custom domain.
- Route 53 resolves the DNS request to CloudFront.
- CloudFront forwards the authenticated request to the Amazon Bedrock Runtime agent.
- The agent processes the request and returns the response through the same path.
You can use the same CloudFront distribution to serve both your frontend application and backend agent endpoints, avoiding cross-origin resource sharing (CORS) issues because everything originates from the same domain.
Prerequisites
To follow this walkthrough, you must have the following in place:
Although Amazon Bedrock AgentCore Runtime can be in other supported AWS Regions, CloudFront requires SSL certificates to be in the us-east-1 Region.
You can choose from the following domain options:
- Use an existing domain – Add a subdomain like
agent.yourcompany.com - Register a new domain – Use Route 53 to register a domain if you don’t have one
- Use the default URL from CloudFront – No domain registration or configuration required
Choose the third option if you want to test the solution quickly before setting up a custom domain.
Create an agent with inbound authentication
If you already have an agent deployed with OAuth authentication, you can skip to the next section to set up the custom domain. Otherwise, follow these steps to create a new agent using Amazon Cognito as your OAuth provider:
- Create a new directory for your agent with the following structure:
- Create the main agent code in
agent_example.py:
- Add dependencies to
requirements.txt:
- Run the following commands to create an Amazon Cognito user pool and test user:
- Deploy the agent using the Amazon Bedrock AgentCore command line interface (CLI) provided by the starter toolkit:
Make note of your agent runtime Amazon Resource Name (ARN) after deployment. You will need this for the custom domain configuration.
For additional examples and details, see Authenticate and authorize with Inbound Auth and Outbound Auth.
Set up the custom domain solution
Now let’s implement the custom domain solution using the AWS CDK. This section shows you how to create the CloudFront distribution that proxies your custom domain requests to Amazon Bedrock AgentCore Runtime endpoints.
- Create a new directory and initialize an AWS CDK project:
- Encode the agent ARN and prepare the CloudFront origin configuration:
If your frontend application runs on a different domain than your agent endpoint, you must configure CORS headers. This is common if your frontend is hosted on a different domain (for example, https://app.yourcompany.com calling https://agent.yourcompany.com), or if you’re developing locally (for example, http://localhost:3000 calling your production agent endpoint).
- To handle CORS requirements, create a CloudFront response headers policy:
- Create a CloudFront distribution to act as a reverse proxy for your agent endpoints:
Set cache_policy=CachePolicy.CACHING_DISABLED to make sure your agent responses remain dynamic and aren’t cached by CloudFront.
- If you’re using a custom domain, add an SSL certificate and DNS configuration to your stack:
The following code is the complete AWS CDK stack that combines all the components:
- Configure the AWS CDK
appentry point:
Deploy your custom domain
Now you can deploy the solution and verify it works with both custom and default domains. Complete the following steps:
- Update the following values in
agentcore_custom_domain_stack.py:- Your Amazon Bedrock AgentCore Runtime ARN
- Your domain name (if using a custom domain)
- Your hosted zone ID (if using a custom domain)
- Deploy using the AWS CDK:
Test your endpoint
After you deploy the custom domain, you can test your endpoints using either the custom domain or the CloudFront default domain.First, get a JWT token from Amazon Cognito:
Use the following code to test with your custom domain:
Alternatively, use the following code to test with the CloudFront default domain:
Considerations
As you implement this solution in production, the following are some important considerations:
- Cost implications – CloudFront adds costs for data transfer and requests. Review Amazon CloudFront pricing to understand the impact for your usage patterns.
- Security enhancements – Consider implementing the following security measures:
- AWS WAF rules to help protect against common web exploits.
- Rate limiting to help prevent abuse.
- Geo-restrictions if your agent should only be accessible from specific Regions.
- Monitoring – Enable CloudFront access logs and set up Amazon CloudWatch alarms to monitor error rates, latency, and request volume.
Clean up
To avoid ongoing costs, delete the resources when you no longer need them:
You might need to manually delete the Route 53 hosted zones and ACM certificates from their respective service consoles.
Conclusion
In this post, we showed you how to create custom domain names for your Amazon Bedrock AgentCore Runtime agent endpoints using CloudFront as a reverse proxy. This solution provides several key benefits: simplified integration for development teams, custom domains that align with your organization, cleaner infrastructure abstraction, and straightforward maintenance when endpoints need updates. By using CloudFront as a reverse proxy, you can also serve both your frontend application and backend agent endpoints from the same domain, avoiding common CORS challenges.
We encourage you to explore this solution further by adapting it to your specific needs. You might want to enhance it with additional security features, set up monitoring, or integrate it with your existing infrastructure.
To learn more about building and deploying AI agents, see the Amazon Bedrock AgentCore Developer Guide. For advanced configurations and best practices with CloudFront, refer to the Amazon CloudFront documentation. You can find detailed information about SSL certificates in the AWS Certificate Manager documentation, and domain management in the Amazon Route 53 documentation.
Amazon Bedrock AgentCore is currently in preview and subject to change. Standard AWS pricing applies to additional services used, such as CloudFront, Route 53, and Certificate Manager.
About the authors
 Rahmat Fedayizada is a Senior Solutions Architect with the AWS Energy and Utilities team. He works with energy companies to design and implement scalable, secure, and highly available architectures. Rahmat is passionate about translating complex technical requirements into practical solutions that drive business value.
Rahmat Fedayizada is a Senior Solutions Architect with the AWS Energy and Utilities team. He works with energy companies to design and implement scalable, secure, and highly available architectures. Rahmat is passionate about translating complex technical requirements into practical solutions that drive business value.
![]() Paras Bhuva is a Senior Manager of Solutions Architecture at AWS, where he leads a team of solution architects helping energy customers innovate and accelerate their transformation. Having started as a Solution Architect in 2012, Paras is passionate about architecting scalable solutions and building organizations focused on application modernization and AI initiatives.
Paras Bhuva is a Senior Manager of Solutions Architecture at AWS, where he leads a team of solution architects helping energy customers innovate and accelerate their transformation. Having started as a Solution Architect in 2012, Paras is passionate about architecting scalable solutions and building organizations focused on application modernization and AI initiatives.
-
Tools & Platforms3 weeks ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy1 month ago
Ethics & Policy1 month agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Business2 days ago
Business2 days agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-

 Events & Conferences3 months ago
Events & Conferences3 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers2 months ago
Jobs & Careers2 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Funding & Business2 months ago
Funding & Business2 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries
-

 Education2 months ago
Education2 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi
-

 Jobs & Careers2 months ago
Jobs & Careers2 months agoAstrophel Aerospace Raises ₹6.84 Crore to Build Reusable Launch Vehicle