Books, Courses & Certifications
Looking to upskill on LinkedIn Learning? AI is in your future – Fortune





















Books, Courses & Certifications
Build character consistent storyboards using Amazon Nova in Amazon Bedrock – Part 2

Although careful prompt crafting can yield good results, achieving professional-grade visual consistency often requires adapting the underlying model itself. Building on the prompt engineering and character development approach covered in Part 1 of this two-part series, we now push the consistency level for specific characters by fine-tuning an Amazon Nova Canvas foundation model (FM). Through fine-tuning techniques, creators can instruct the model to maintain precise control over character appearances, expressions, and stylistic elements across multiple scenes.
In this post, we take an animated short film, Picchu, produced by FuzzyPixel from Amazon Web Services (AWS), prepare training data by extracting key character frames, and fine-tune a character-consistent model for the main character Mayu and her mother, so we can quickly generate storyboard concepts for new sequels like the following images.
Solution overview
To implement an automated workflow, we propose the following comprehensive solution architecture that uses AWS services for an end-to-end implementation.
The workflow consists of the following steps:
- The user uploads a video asset to an Amazon Simple Storage Service (Amazon S3) bucket.
- Amazon Elastic Container Service (Amazon ECS) is triggered to process the video asset.
- Amazon ECS downsamples the frames, selects those containing the character, and then center-crops them to produce the final character images.
- Amazon ECS invokes an Amazon Nova model (Amazon Nova Pro) from Amazon Bedrock to create captions from the images.
- Amazon ECS writes the image captions and metadata to the S3 bucket.
- The user uses a notebook environment in Amazon SageMaker AI to invoke the model training job.
- The user fine-tunes a custom Amazon Nova Canvas model by invoking Amazon Bedrock
create_model_customization_jobandcreate_model_provisioned_throughputAPI calls to create a custom model available for inference.
This workflow is structured in two distinct phases. The initial phase, in Steps 1–5, focuses on preparing the training data. In this post, we walk through an automated pipeline to extract images from an input video and then generate labeled training data. The second phase, in Steps 6–7, focuses on fine-tuning the Amazon Nova Canvas model and performing test inference using the custom-trained model. For these latter steps, we provide the preprocessed image data and comprehensive example code in the following GitHub repository to guide you through the process.
Prepare the training data
Let’s begin with the first phase of our workflow. In our example, we build an automated video object/character extraction pipeline to extract high-resolution images with accurate caption labels using the following steps.
Creative character extraction
We recommend first sampling video frames at fixed intervals (for example, 1 frame per second). Then, apply Amazon Rekognition label detection and face collection search to identify frames and characters of interest. Label detection can identify over 2,000 unique labels and locate their positions within frames, making it ideal for initial detection of general character categories or non-human characters. To distinguish between different characters, we then use the Amazon Rekognition feature to search faces in a collection. This feature identifies and tracks characters by matching their faces against a pre-populated face collection. If these two approaches aren’t precise enough, we can use Amazon Rekognition Custom Labels to train a custom model for detecting specific characters. The following diagram illustrates this workflow.
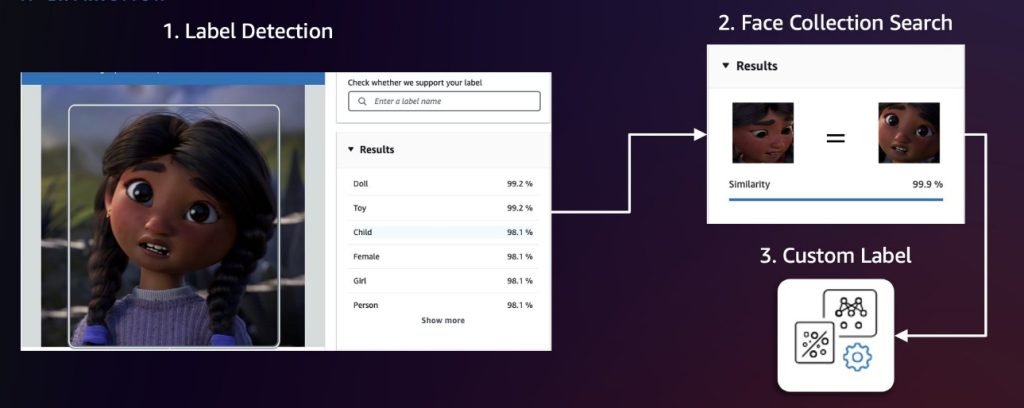
After detection, we center-crop each character with appropriate pixel padding and then run a deduplication algorithm using the Amazon Titan Multimodal Embeddings model to remove semantically similar images above a threshold value. Doing so helps us build a diverse dataset because redundant or nearly identical frames could lead to model overfitting (when a model learns the training data too precisely, including its noise and fluctuations, making it perform poorly on new, unseen data). We can calibrate the similarity threshold to fine-tune what we consider to be identical images, so we can better control the balance between dataset diversity and redundancy elimination.
Data labeling
We generate captions for each image using Amazon Nova Pro in Amazon Bedrock and then upload the image and label manifest file to an Amazon S3 location. This process focuses on two critical aspects of prompt engineering: character description to help the FM identify and name the characters based on their unique attributes, and varied description generation that avoids repetitive patterns in the caption (for example, “an animated character”). The following is an example prompt template used during our data labeling process:
The data labeling output is formatted as a JSONL file, where each line pairs an image reference Amazon S3 path with a caption generated by Amazon Nova Pro. This JSONL file is then uploaded to Amazon S3 for training. The following is an example of the file:
Human verification
For enterprise use cases, we recommend incorporating a human-in-the-loop process to verify labeled data before proceeding with model training. This verification can be implemented using Amazon Augmented AI (Amazon A2I), a service that helps annotators verify both image and caption quality. For more details, refer to Get Started with Amazon Augmented AI.
Fine-tune Amazon Nova Canvas
Now that we have the training data, we can fine-tune the Amazon Nova Canvas model in Amazon Bedrock. Amazon Bedrock requires an AWS Identity and Access Management (IAM) service role to access the S3 bucket where you stored your model customization training data. For more details, see Model customization access and security. You can perform the fine-tuning task directly on the Amazon Bedrock console or use the Boto3 API. We explain both approaches in this post, and you can find the end-to-end code sample in picchu-finetuning.ipynb.
Create a fine-tuning job on the Amazon Bedrock console
Let’s start by creating an Amazon Nova Canvas fine-tuning job on the Amazon Bedrock console:
- On the Amazon Bedrock console, in the navigation pane, choose Custom models under Foundation models.
- Choose Customize model and then Create Fine-tuning job.

- On the Create Fine-tuning job details page, choose the model you want to customize and enter a name for the fine-tuned model.
- In the Job configuration section, enter a name for the job and optionally add tags to associate with it.
- In the Input data section, enter the Amazon S3 location of the training dataset file.
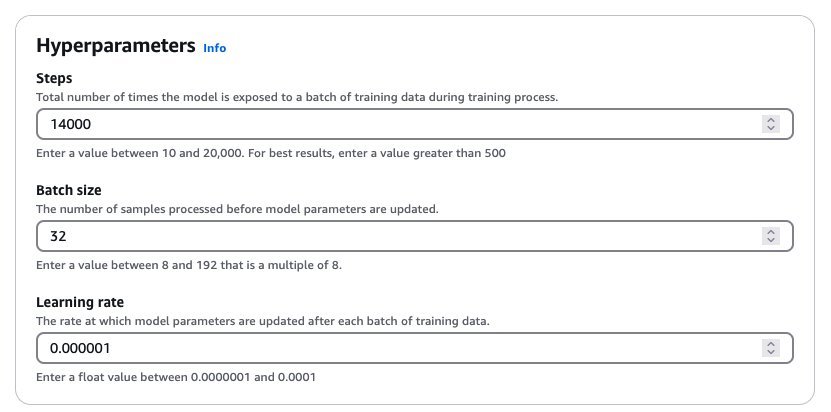
- In the Hyperparameters section, enter values for hyperparameters, as shown in the following screenshot.
- In the Output data section, enter the Amazon S3 location where Amazon Bedrock should save the output of the job.
- Choose Fine-tune model job to begin the fine-tuning process.
This hyperparameter combination yielded good results during our experimentation. In general, increasing the learning rate makes the model train more aggressively, which often presents an interesting trade-off: we might achieve character consistency more quickly, but it might impact overall image quality. We recommend a systematic approach to adjusting hyperparameters. Start with the suggested batch size and learning rate, and try increasing or decreasing the number of training steps first. If the model struggles to learn your dataset even after 20,000 steps (the maximum allowed in Amazon Bedrock), then we suggest either increasing the batch size or adjusting the learning rate upward. These adjustments, through subtle, can make a significant difference in our model’s performance. For more details about the hyperparameters, refer to Hyperparameters for Creative Content Generation models.
Create a fine-tuning job using the Python SDK
The following Python code snippet creates the same fine-tuning job using the create_model_customization_job API:
When the job is complete, you can retrieve the new customModelARN using the following code:
Deploy the fine-tuned model
With the preceding hyperparameter configuration, this fine-tuning job might take up to 12 hours to complete. When it’s complete, you should see a new model in the custom models list. You can then create provisioned throughput to host the model. For more details on provisioned throughput and different commitment plans, see Increase model invocation capacity with Provisioned Throughput in Amazon Bedrock.
Deploy the model on the Amazon Bedrock console
To deploy the model from the Amazon Bedrock console, complete the following steps:
- On the Amazon Bedrock console, choose Custom models under Foundation models in the navigation pane.
- Select the new custom model and choose Purchase provisioned throughput.
- In the Provisioned Throughput details section, enter a name for the provisioned throughput.
- Under Select model, choose the custom model you just created.
- Then specify the commitment term and model units.

After you purchase provisioned throughput, a new model Amazon Resource Name (ARN) is created. You can invoke this ARN when the provisioned throughput is in service.

Deploy the model using the Python SDK
The following Python code snippet creates provisioned throughput using the create_provisioned_model_throughput API:
Test the fine-tuned model
When the provisioned throughput is live, we can use the following code snippet to test the custom model and experiment with generating some new images for a sequel to Picchu:
 |
 |
 |
| Mayu face shows a mix of nervousness and determination. Mommy kneels beside her, gently holder her. A landscape is visible in the background. | A steep cliff face with a long wooden ladder extending downwards. Halfway down the ladder is Mayu with a determined expression on her face. Mayu’s small hands grip the sides of the ladder tightly as she carefully places her feet on each rung. The surrounding environment shows a rugged, mountainous landscape. | Mayu standing proudly at the entrance of a simple school building. Her face beams with a wide smile, expressing pride and accomplishment. |
Clean up
To avoid incurring AWS charges after you are done testing, complete the cleanup steps in picchu-finetuning.ipynb and delete the following resources:
- Amazon SageMaker Studio domain
- Fine-tuned Amazon Nova model and provision throughput endpoint
Conclusion
In this post, we demonstrated how to elevate character and style consistency in storyboarding from Part 1 by fine-tuning Amazon Nova Canvas in Amazon Bedrock. Our comprehensive workflow combines automated video processing, intelligent character extraction using Amazon Rekognition, and precise model customization using Amazon Bedrock to create a solution that maintains visual fidelity and dramatically accelerates the storyboarding process. By fine-tuning the Amazon Nova Canvas model on specific characters and styles, we’ve achieved a level of consistency that surpasses standard prompt engineering, so creative teams can produce high-quality storyboards in hours rather than weeks. Start experimenting with Nova Canvas fine-tuning today, so you can also elevate your storytelling with better character and style consistency.
About the authors
 Dr. Achin Jain is a Senior Applied Scientist at Amazon AGI, where he works on building multi-modal foundation models. He brings over 10+ years of combined industry and academic research experience. He has led the development of several modules for Amazon Nova Canvas and Amazon Titan Image Generator, including supervised fine-tuning (SFT), model customization, instant customization, and guidance with color palette.
Dr. Achin Jain is a Senior Applied Scientist at Amazon AGI, where he works on building multi-modal foundation models. He brings over 10+ years of combined industry and academic research experience. He has led the development of several modules for Amazon Nova Canvas and Amazon Titan Image Generator, including supervised fine-tuning (SFT), model customization, instant customization, and guidance with color palette.
 James Wu is a Senior AI/ML Specialist Solution Architect at AWS. helping customers design and build AI/ML solutions. James’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. Prior to joining AWS, James was an architect, developer, and technology leader for over 10 years, including 6 years in engineering and 4 years in marketing & advertising industries.
James Wu is a Senior AI/ML Specialist Solution Architect at AWS. helping customers design and build AI/ML solutions. James’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. Prior to joining AWS, James was an architect, developer, and technology leader for over 10 years, including 6 years in engineering and 4 years in marketing & advertising industries.
 Randy Ridgley is a Principal Solutions Architect focused on real-time analytics and AI. With expertise in designing data lakes and pipelines. Randy helps organizations transform diverse data streams into actionable insights. He specializes in IoT solutions, analytics, and infrastructure-as-code implementations. As an open-source contributor and technical leader, Randy provides deep technical knowledge to deliver scalable data solutions across enterprise environments.
Randy Ridgley is a Principal Solutions Architect focused on real-time analytics and AI. With expertise in designing data lakes and pipelines. Randy helps organizations transform diverse data streams into actionable insights. He specializes in IoT solutions, analytics, and infrastructure-as-code implementations. As an open-source contributor and technical leader, Randy provides deep technical knowledge to deliver scalable data solutions across enterprise environments.
Books, Courses & Certifications
Build character consistent storyboards using Amazon Nova in Amazon Bedrock – Part 1

The art of storyboarding stands as the cornerstone of modern content creation, weaving its essential role through filmmaking, animation, advertising, and UX design. Though traditionally, creators have relied on hand-drawn sequential illustrations to map their narratives, today’s AI foundation models (FMs) are transforming this landscape. FMs like Amazon Nova Canvas and Amazon Nova Reel offer capabilities in transforming text and image inputs into professional-grade visuals and short clips that promise to revolutionize preproduction workflows.
This technological leap forward, however, presents its own set of challenges. Although these models excel at generating diverse concepts rapidly—a boon for creative exploration—maintaining consistent character designs and stylistic coherence across scenes remains a significant hurdle. Even subtle modifications to prompts or model configurations can yield dramatically different visual outputs, potentially disrupting narrative continuity and creating additional work for content creators.
To address these challenges, we’ve developed this two-part series exploring practical solutions for achieving visual consistency. In Part 1, we deep dive into prompt engineering and character development pipelines, sharing tested prompt patterns that deliver reliable, consistent results with Amazon Nova Canvas and Amazon Nova Reel. Part 2 explores techniques like fine-tuning Amazon Nova Canvas to achieve exceptional visual consistency and precise character control.
Consistent character design with Amazon Nova Canvas
The foundation of effective storyboarding begins with establishing well-defined character designs. Amazon Nova Canvas offers several powerful techniques to create and maintain character consistency throughout your visual narrative. To help you implement these techniques in your own projects, we’ve provided comprehensive code examples and resources in our GitHub repository. We encourage you to follow along as we walk through each step in detail. If you’re new to Amazon Nova Canvas, we recommend first reviewing Generating images with Amazon Nova to familiarize yourself with the basic concepts.
Basic text prompting
Amazon Nova Canvas transforms text descriptions into visual representations. Unlike large language models (LLMs), image generation models don’t interpret commands or engage in reasoning—they respond best to descriptive captions. Including specific details in your prompts, such as physical attributes, clothing, and styling elements, directly influences the generated output.
For example, “A 7-year-old Peruvian girl with dark hair in two low braids wearing a school uniform” provides clear visual elements for the model to generate an initial character concept, as shown in the following example image.
Visual style implementation
Consistency in storyboarding requires both character features and unified visual style. Our approach separates style information into two key components in the prompt:
- Style description – An opening phrase that defines the visual medium (for example, “A graphic novel style illustration of”)
- Style details – A closing phrase that specifies artistic elements (for example, “Bold linework, dramatic shadows, flat color palettes”)
This structured technique enables exploration of various artistic styles, including graphic novels, sketches, and 3D illustrations, while maintaining character consistency throughout the storyboard. The following is an example prompt template and some style information you can experiment with:

Character variation through seed values
The seed parameter serves as a tool for generating character variations while adhering to the same prompt. By keeping the text description constant and varying only the seed value, creators can explore multiple interpretations of their character design without starting from scratch, as illustrated in the following example images.
 |
||||
Seed = 1 |
Seed = 20 |
Seed = 57 |
Seed = 139 |
Seed = 12222 |
Prompt adherence control with cfgScale
The cfgScale parameter is another tool for maintaining character consistency, controlling how strictly Amazon Nova Canvas follows your prompt. Operating on a scale from 1.1–10, lower values give the model more creative freedom and higher values enforce strict prompt adherence. The default value of 6.5 typically provides an optimal balance, but as demonstrated in the following images, finding the right setting is crucial. Too low a value can result in inconsistent character representations, whereas too high a value might overemphasize prompt elements at the cost of natural composition.
 |
||||
| Seed = 57, cfgScale = 1.1 |
Seed = 57, cfgScale = 3.5 |
Seed = 57, cfgScale = 6.5 |
Seed = 57, cfgScale = 8.0 |
Seed = 57, cfgScale = 10 |
Scene integration with consistent parameters
Now we can put these techniques together to test for character consistency across different narrative contexts, as shown in the following example images. We maintain consistent input for style, seed, and cfgScale, varying only the scene description to make sure character remains recognizable throughout the scene sequences.
 |
 |
 |
| Seed = 57, Cfg_scale: 6.5 | Seed = 57, Cfg_scale: 6.5 | Seed = 57, Cfg_scale: 6.5 |
| A graphic novel style illustration of a 7 year old Peruvian girl with dark hair in two low braids wearing a school uniform riding a bike on a mountain pass Bold linework, dramatic shadows, and flat color palettes. Use high contrast lighting and cinematic composition typical of comic book panels. Include expressive line work to convey emotion and movement. | A graphic novel style illustation of a 7 year old Peruvian girl with dark hair in two low braids wearing a school uniform walking on a path through tall grass in the Andes Bold linework, dramatic shadows, and flat color palettes. Use high contrast lighting and cinematic composition typical of comic book panels. Include expressive line work to convey emotion and movement. | A graphic novel style illustration of a 7 year old Peruvian girl with dark hair in two low braids wearing a school uniform eating ice cream at the beach Bold linework, dramatic shadows, and flat color palettes. Use high contrast lighting and cinematic composition typical of comic book panels. Include expressive line work to convey emotion and movement. |
Storyboard development pipeline
Building upon the character consistency techniques we’ve discussed, we can now implement an end-to-end storyboard development pipeline that transforms written scene and character descriptions into visually coherent storyboards. This systematic approach uses our established parameters for style descriptions, seed values, and cfgScale values to provide character consistency while adapting to different narrative contexts. The following are some example scene and character descriptions:
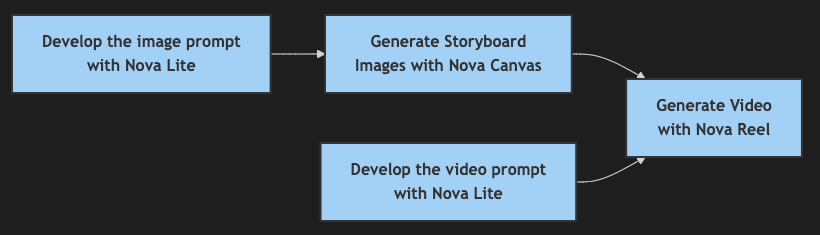
Our pipeline uses Amazon Nova Lite to first craft optimized image prompts incorporating our established best practices, which are then passed to Amazon Nova Canvas for image generation. By setting numberOfImages higher (typically three variations), while maintaining consistent seed and cfgScale values, we give creators multiple options that preserve character consistency. We used the following prompt for Amazon Nova Lite to generate optimized image prompts:
Our pipeline generated the following storyboard panels.
 |
Mayu stands at the edge of a mountainous path, clutching a book. Her mother, Maya, kneels beside her, offering words of encouragement and handing her the book. Mayu looks nervous but determined as she prepares to start her journey. |
 |
Mayu encounters a ‘danger’ sign with a drawing of a snake. She looks scared, but then remembers her mother’s words. She takes a deep breath, looks at her book for reassurance, and then searches for a stick on the ground. |
 |
Mayu bravely makes her way through tall grass, swinging her stick and making noise to scare off potential snakes. Her face shows a mix of fear and courage as she pushes forward on her journey. |
Although these techniques noticeably improve character consistency, they aren’t perfect. Upon closer inspection, you will notice that even images within the same scene show variations in character consistency. Using consistent seed values helps control these variations, and the techniques outlined in this post significantly improve consistency compared to basic prompt engineering. However, if your use case requires near-perfect character consistency, we recommend proceeding to Part 2, where we explore advanced fine-tuning techniques.
Video generation for animated storyboards
If you want to go beyond static scene images to transform your storyboard into short, animated video clips, you can use Amazon Nova Reel. We use Amazon Nova Lite to convert image prompts into video prompts, adding subtle motion and camera movements optimized for the Amazon Nova Reel model. These prompts, along with the original images, serve as creative constraints for Amazon Nova Reel to generate the final animated sequences. The following is the example prompt and its resulting animated scene in GIF format:
 |
 |
| Input Image | Output Video |
Conclusion
In this first part of our series, we explored fundamental techniques for achieving character and style consistency using Amazon Nova Canvas, from structured prompt engineering to building an end-to-end storyboarding pipeline. We demonstrated how combining style descriptions, seed values, and careful cfgScale parameter control can significantly improve character consistency across different scenes. We also showed how integrating Amazon Nova Lite with Amazon Nova Reel can enhance the storyboarding workflow, enabling both optimized prompt generation and animated sequences.
Although these techniques provide a solid foundation for consistent storyboard generation, they aren’t perfect—subtle variations might still occur. We invite you to continue to Part 2, where we explore advanced model fine-tuning techniques that can help achieve near-perfect character consistency and visual fidelity.
About the authors
 Alex Burkleaux is a Senior AI/ML Specialist Solution Architect at AWS. She helps customers use AI Services to build media solutions using Generative AI. Her industry experience includes over-the-top video, database management systems, and reliability engineering.
Alex Burkleaux is a Senior AI/ML Specialist Solution Architect at AWS. She helps customers use AI Services to build media solutions using Generative AI. Her industry experience includes over-the-top video, database management systems, and reliability engineering.
 James Wu is a Senior AI/ML Specialist Solution Architect at AWS, helping customers design and build AI/ML solutions. James’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. Prior to joining AWS, James was an architect, developer, and technology leader for over 10 years, including 6 years in engineering and 4 years in marketing & advertising industries.
James Wu is a Senior AI/ML Specialist Solution Architect at AWS, helping customers design and build AI/ML solutions. James’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. Prior to joining AWS, James was an architect, developer, and technology leader for over 10 years, including 6 years in engineering and 4 years in marketing & advertising industries.
 Vladimir Budilov is a Principal Solutions Architect at AWS focusing on agentic & generative AI, and software architecture. He leads large-scale GenAI implementations, bridging cutting-edge AI capabilities with production-ready business solutions, while optimizing for cost and solution resilience.
Vladimir Budilov is a Principal Solutions Architect at AWS focusing on agentic & generative AI, and software architecture. He leads large-scale GenAI implementations, bridging cutting-edge AI capabilities with production-ready business solutions, while optimizing for cost and solution resilience.
 Nora Shannon Johnson is a Solutions Architect at Amazon Music focused on discovery and growth through AI/ML. In the past, she supported AWS through the development of generative AI prototypes and tools for developers in financial services, health care, retail, and more. She has been an engineer and consultant in various industries including DevOps, fintech, industrial AI/ML, and edtech in the United States, Europe, and Latin America.
Nora Shannon Johnson is a Solutions Architect at Amazon Music focused on discovery and growth through AI/ML. In the past, she supported AWS through the development of generative AI prototypes and tools for developers in financial services, health care, retail, and more. She has been an engineer and consultant in various industries including DevOps, fintech, industrial AI/ML, and edtech in the United States, Europe, and Latin America.
 Ehsan Shokrgozar is a Senior Solutions Architect specializing in Media and Entertainment at AWS. He is passionate about helping M&E customers build more efficient workflows. He combines his previous experience as Technical Director and Pipeline Engineer at various Animation/VFX studios with his knowledge of building M&E workflows in the cloud to help customers achieve their business goals.
Ehsan Shokrgozar is a Senior Solutions Architect specializing in Media and Entertainment at AWS. He is passionate about helping M&E customers build more efficient workflows. He combines his previous experience as Technical Director and Pipeline Engineer at various Animation/VFX studios with his knowledge of building M&E workflows in the cloud to help customers achieve their business goals.


Image by Author | Canva
# Introduction
Writing classes in Python can get repetitive really fast. You’ve probably had moments where you’re defining an __init__ method, a __repr__ method, maybe even __eq__, just to make your class usable — and you’re like, “Why am I writing the same boilerplate again and again?”
That’s where Python’s dataclass comes in. It’s part of the standard library and helps you write cleaner, more readable classes with way less code. If you’re working with data objects — anything like configs, models, or even just bundling a few fields together — dataclass is a game-changer. Trust me, this isn’t just another overhyped feature — it actually works. Let’s break it down step by step.
# What Is a dataclass?
A dataclass is a Python decorator that automatically generates boilerplate code for classes, like __init__, __repr__, __eq__, and more. It’s part of the dataclasses module and is perfect for classes that primarily store data (think: objects representing employees, products, or coordinates). Instead of manually writing repetitive methods, you define your fields, slap on the @dataclass decorator, and Python does the heavy lifting. Why should you care? Because it saves you time, reduces errors, and makes your code easier to maintain.
# The Old Way: Writing Classes Manually
Here’s what you might be doing today if you’re not using dataclass:
class User:
def __init__(self, name, age, is_active):
self.name = name
self.age = age
self.is_active = is_active
def __repr__(self):
return f"User(name={self.name}, age={self.age}, is_active={self.is_active})"
It’s not terrible, but it’s verbose. Even for a simple class, you’re already writing the constructor and string representation manually. And if you need comparisons (==), you’ll have to write __eq__ too. Imagine adding more fields or writing ten similar classes — your fingers would hate you.
# The Dataclass Way (a.k.a. The Better Way)
Now, here’s the same thing using dataclass:
from dataclasses import dataclass
@dataclass
class User:
name: str
age: int
is_active: bool
That’s it. Python automatically adds the __init__, __repr__, and __eq__ methods for you under the hood. Let’s test it:
# Create three users
u1 = User(name="Ali", age=25, is_active=True)
u2 = User(name="Almed", age=25, is_active=True)
u3 = User(name="Ali", age=25, is_active=True)
# Print them
print(u1)
# Compare them
print(u1 == u2)
print(u1 == u3)
Output:
User(name="Ali", age=25, is_active=True)
False
True
# Additional Features Offered by dataclass
// 1. Adding Default Values
You can set default values just like in function arguments:
@dataclass
class User:
name: str
age: int = 25
is_active: bool = True
u = User(name="Alice")
print(u)
Output:
User(name="Alice", age=25, is_active=True)
Pro Tip: If you use default values, put those fields after non-default fields in the class definition. Python enforces this to avoid confusion (just like function arguments).
// 2. Making Fields Optional (Using field())
If you want more control — say you don’t want a field to be included in __repr__, or you want to set a default after initialization — you can use field():
from dataclasses import dataclass, field
@dataclass
class User:
name: str
password: str = field(repr=False) # Hide from __repr__
Now:
print(User("Alice", "supersecret"))
Output:
Your password isn’t exposed. Clean and secure.
// 3. Immutable Dataclasses (Like namedtuple, but Better)
If you want your class to be read-only (i.e., its values can’t be changed after creation), just add frozen=True:
@dataclass(frozen=True)
class Config:
version: str
debug: bool
Trying to modify an object of Config like config.debug = False will now raise an error: FrozenInstanceError: cannot assign to field 'debug'. This is useful for constants or app settings where immutability matters.
// 4. Nesting Dataclasses
Yes, you can nest them too:
@dataclass
class Address:
city: str
zip_code: int
@dataclass
class Customer:
name: str
address: Address
Example Usage:
addr = Address("Islamabad", 46511)
cust = Customer("Qasim", addr)
print(cust)Output:
Customer(name="Qasim", address=Address(city='Islamabad', zip_code=46511))
# Pro Tip: Using asdict() for Serialization
You can convert a dataclass into a dictionary easily:
from dataclasses import asdict
u = User(name="Kanwal", age=10, is_active=True)
print(asdict(u))
Output:
{'name': 'Kanwal', 'age': 10, 'is_active': True}
This is useful when working with APIs or storing data in databases.
# When Not to Use dataclass
While dataclass is amazing, it’s not always the right tool for the job. Here are a few scenarios where you might want to skip it:
- If your class is more behavior-heavy (i.e., filled with methods and not just attributes), then
dataclassmight not add much value. It’s primarily built for data containers, not service classes or complex business logic. - You can override the auto-generated dunder methods like
__init__,__eq__,__repr__, etc., but if you’re doing it often, maybe you don’t need adataclassat all. Especially if you’re doing validations, custom setup, or tricky dependency injection. - For performance-critical code (think: games, compilers, high-frequency trading), every byte and cycle matters.
dataclassadds a small overhead for all the auto-generated magic. In those edge cases, go with manual class definitions and fine-tuned methods.
# Final Thoughts
Python’s dataclass isn’t just syntactic sugar — it actually makes your code more readable, testable, and maintainable. If you’re dealing with objects that mostly store and pass around data, there’s almost no reason not to use it. If you want to study deeper, check out the official Python docs or experiment with advanced features. And since it’s part of the standard library, there are zero extra dependencies. You can just import it and go.
Kanwal Mehreen is a machine learning engineer and a technical writer with a profound passion for data science and the intersection of AI with medicine. She co-authored the ebook “Maximizing Productivity with ChatGPT”. As a Google Generation Scholar 2022 for APAC, she champions diversity and academic excellence. She’s also recognized as a Teradata Diversity in Tech Scholar, Mitacs Globalink Research Scholar, and Harvard WeCode Scholar. Kanwal is an ardent advocate for change, having founded FEMCodes to empower women in STEM fields.
-

 Business6 days ago
Business6 days agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-
Tools & Platforms3 weeks ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy1 month ago
Ethics & Policy1 month agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences4 months ago
Events & Conferences4 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers2 months ago
Jobs & Careers2 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Education2 months ago
Education2 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Funding & Business2 months ago
Funding & Business2 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi
-

 Education2 months ago
Education2 months agoMacron says UK and France have duty to tackle illegal migration ‘with humanity, solidarity and firmness’ – UK politics live | Politics