Events & Conferences
Long-form-video understanding and synthesis – Amazon Science

At this year’s Conference on Computer Vision and Pattern Recognition (CVPR), Prime Video presented four papers that indicate the broad range of cutting-edge problems we work on.
In one paper, “Movies2Scenes: Using movie metadata to learn scene representation“, we present a novel contrastive-learning approach that uses only commonly available movie metadata to learn a general-purpose scene representation. On a diverse set of tasks evaluated using multiple benchmark datasets, models that use our representations consistently outperform models using existing state-of-the-art representations.
Notably, our learned representation offers an average improvement of 7.9% on the seven classification tasks and 9.7% on the two regression tasks in the Long-Form Video Understanding (LVU) dataset. This effort is an important step toward the first foundation model for general-purpose movie understanding.
In another paper, “Selective structured state-spaces for long-form video understanding”, we expand on the recently proposed S4 model that employs a lightweight mask generator to adaptively select informative image tokens, resulting in more efficient and accurate modeling of long-term spatiotemporal dependencies in videos. Our approach is consistently more accurate than the previous state-of-the-art model, by as much as 9.6%, while reducing the memory footprint by 23%.
Similarly, our paper “Dynamic inference with grounding based vision and language models” explores the problem of computational redundancy in large vision-and-language models, addressing this challenge by dynamically skipping network layers, dropping input tokens, and fusing multimodal tokens, conditioned on the input image-text pair. Our results show that we can improve the run-time efficiency of the state-of-the-art models by up to 50% on multiple downstream tasks with an accuracy drop of only 0.3%.
Lastly, our paper “LEMaRT: Label-efficient masked region transform for image harmonization” addresses the problem of requiring large amounts of labeled data to train image harmonization models, which modify content from different source images so that they blend together better in composite images. To this end, our method automatically generates training data by simulating defects in appearance that image harmonization models are expected to remove. Our method outperforms previous state-of-the-art approaches by a margin of 0.4dB (mean square error improvement = ~9%) when it is fine-tuned on only 50% of the training data from one of the standard benchmarks (iHarmony4) and by 1.0 dB (MSE improvement = ~21%) when it is trained on the full training dataset.
Toward a foundation model for movie understanding
The term “foundation model” generally relates to (i) a single large model that is (ii) trained on large amounts of mostly unlabeled data and can (iii) drive a number of downstream tasks. While several general-purpose visual-and-textual foundation models exist (e.g., BERT, GPT-4, CLIP, DALL-E 2, etc.), no foundation model particularly geared for movie understanding has been proposed before our work.
This is partly because directly applying existing visual or textual foundation models for movie understanding has limited effectiveness, given the large domain gap between cinematic content and the web-crawled images and text used to train those models. Factors such as the inaccessibility of much large-scale cinematic content, the computational resources required to process it, and the lack of benchmark datasets for evaluation on downstream applications add to the challenge of building a foundation model for movie understanding.

To address these challenges, we proposed a novel model trained on over five million scenes automatically identified from thousands of movies and comprising more than 45 million frames. Our model does not require any manual annotations and relies only on commonly available movie-level information (genre, synopsis, etc.). The scene representations from our model can be applied to improve the performance of a diverse set of downstream tasks, which is a key step toward building a foundation model for movie understanding.
We use movie metadata to define a measure of movie similarity and use that similarity measure to identify data pairs for contrastive learning. In contrastive learning, a model is trained on both positive pairs — examples that are similar in the relevant way — and negative pairs. During training, the model learns to produce data representations that pull positive pairs together and push negative pairs apart.
Often, the positive pairs are created by augmenting existing examples — say, re-cropping them, reversing them, or re-coloring them. By instead using movies that are considered similar to each other (see below), we ensure that our positive scene-pairs are not only visually similar but also semantically coherent, providing us with a much richer set of geometric and thematic data augmentations that enhance the training objective beyond traditional augmentation approaches.
As can be seen in the video below, our learned scene representation is able to effectively put thematically similar scenes close to each other.
Qualitative examples of similar-scene pairs found using our approach.
In the examples below, we compare our representation with the commonly used CLIP visual representation for scene retrieval using place-labeled scenes in the Long-Form Video Understanding (LVU) dataset. Given a query scene, our representation can capture appearance as well as semantic concepts to retrieve similar scenes more effectively, while CLIP can capture only local appearance-based patterns. For overall retrieval precision on six categories of places, our representation offers a 22.7% improvement over CLIP.
Quantitatively, our learned representation exhibits an average improvement of 7.9% and 9.7% on the seven classification tasks and two regression tasks of the LVU dataset, respectively. Furthermore, using our newly collected MCD dataset in Prime Video, we compare our learned scene representation with state-of-the-art models pretrained on action recognition and image classification datasets. Our scene representation outperforms the alternatives by margins ranging from 3.8% to 50.9% across different models and tasks.
Reducing model complexity for long-form-video understanding
At Prime Video, we’re developing state-of-the-art AI models for cinematic-content understanding to facilitate a variety of downstream use cases. One of the key technical problems to this end is effective modeling of complex spatiotemporal dependencies, particularly in long-form videos such as movies and TV episodes.
Previously proposed convolutional and recurrent neural networks struggle to learn long-term dependencies. In part this is because of exploding or vanishing gradients — where cascading adjustments to model weights grow too small or too large — as information is incorporated over long durations. Vision transformers can use self-attention to address this challenge, attending to particular, prior frames of video when interpreting the current frame. But this is computationally expensive, as it requires pairwise computations between the current frame and its predecessors.

The recently proposed structured-state-space-sequence (S4) model, with its linear complexity, offers a promising direction in this space; however, we empirically demonstrate that treating all image tokens equally, as the S4 model does, can adversely affect a model’s efficiency and accuracy.
To address this challenge, we present a novel selective S4 (i.e., S5) model that employs a lightweight mask generator to adaptively select informative image tokens, resulting in more efficient and accurate modeling of long-term spatiotemporal dependencies in videos. Unlike previous methods, which used mask-based token reduction in transformers, our S5 model avoids the dense self-attention calculation by following the guidance of the momentum-updated S4 model. This enables our model to efficiently discard less informative tokens and adapt to various long-form-video-understanding tasks more effectively.
However, as is the case with most token reduction methods, the informative image tokens may be dropped incorrectly. To improve the robustness and the temporal horizon of our model, we propose a novel long-short masked contrastive-learning (LSMCL) approach that enables our model to predict longer temporal contexts using shorter input videos.
We present extensive comparative results using three challenging long-form video-understanding datasets (LVU, COIN, and Breakfast), demonstrating that our approach is consistently more accurate than the previous state-of-the-art S4 model, by as much as 9.6% on one dataset, with a memory footprint that’s 23% smaller.
Dynamic inference of multimodal models using reinforcement learning
The availability of transformer models operating over multiple data modalities as well as large-scale pretraining approaches has led to significant progress on joint image-and-language models. However, these models impose high computational costs and therefore offer low run-time efficiency, making them difficult to apply to Prime Video’s large catalogue.
Although approaches such as pruning, knowledge distillation, and quantization can help address this challenge, they can incur significant drops in accuracy (e.g., ≥ 1% at ≥ 50% model compression rates), as they are primarily designed for model-parameter reduction, not improving run-time efficiency.
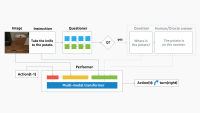
To address this challenge, we propose a model that saves computation by dynamically skipping layers of a multimodal network; pruning input tokens from either the language backbone, the image backbone, or both; and fusing tokens from the separate backbones, conditioned on the input image-text pair.
Most multimodal transformer models include multihead self-attention and feed-forward network layers, which can be skipped for some inputs. Additionally, we remove redundant tokens at different levels of the backbones and fuse the image tokens with the language tokens in an adaptive manner. To learn policies for dynamic inference, we train agents using reinforcement learning.
Our results demonstrate that we can improve the run-time efficiency of the state-of-the-art models MDETR and GLIP by up to 50% on the tasks of referring-expression comprehension, segmentation, and visual question-answering, with a maximum accuracy drop of only 0.3%.
Improving label efficiency of image harmonization models
Image harmonization is an important component of the broader problem of image composition, where new images are created by extracting foreground regions from one image and transferring them to another image in a photorealistic manner.

The main technical challenge for image harmonization is the appearance mismatch between the foreground extracted from the source image and the background of the destination image. Image harmonization aims to adjust the appearance of the foreground to make it compatible with the background. However, training traditional models for image harmonization requires a large amount of labeled data, which is costly and time-consuming to obtain.
To address this challenge, we introduce a novel approach to pretraining image harmonization models, LEMaRT, which automatically generates training data by simulating the types of defects that image harmonization models are expected to remove. LEMaRT takes an image as input, selects a region in that image, and applies a set of appearance transformations to it. We use these modified images, along with the original images, to pretrain our image harmonization model. Furthermore, we introduce an image harmonization model, SwinIH, by retrofitting the previously proposed Swin Transformer with a combination of local and global self-attention mechanisms.
Pretraining our SwinIH model with our LEMaRT approach results in a new state of the art for image harmonization, while being label-efficient, i.e., consuming less annotated data for fine-tuning than existing methods. Notably, on the iHarmony4 dataset, SwinIH outperforms the state of the art, i.e., SCS-Co by a margin of 0.4 dB when it is fine-tuned on only 50% of the training data and by 1.0 dB when it is trained on the full training dataset.
Qualitative comparisons suggest that LEMaRT is better at color correction than prior methods, thanks to the pretraining process, during which LEMaRT learns the distribution of photorealistic images.





















Modern warehouses rely on complex networks of sensors to enable safe and efficient operations. These sensors must detect everything from packages and containers to robots and vehicles, often in changing environments with varying lighting conditions. More important for Amazon, we need to be able to detect barcodes in an efficient way.
The Amazon Robotics ID (ARID) team focuses on solving this problem. When we first started working on it, we faced a significant bottleneck: optimizing sensor placement required weeks or months of physical prototyping and real-world testing, severely limiting our ability to explore innovative solutions.
To transform this process, we developed Sensor Workbench (SWB), a sensor simulation platform built on NVIDIA’s Isaac Sim that combines parallel processing, physics-based sensor modeling, and high-fidelity 3-D environments. By providing virtual testing environments that mirror real-world conditions with unprecedented accuracy, SWB allows our teams to explore hundreds of configurations in the same amount of time it previously took to test just a few physical setups.
Camera and target selection/positioning
Sensor Workbench users can select different cameras and targets and position them in 3-D space to receive real-time feedback on barcode decodability.
Three key innovations enabled SWB: a specialized parallel-computing architecture that performs simulation tasks across the GPU; a custom CAD-to-OpenUSD (Universal Scene Description) pipeline; and the use of OpenUSD as the ground truth throughout the simulation process.
Parallel-computing architecture
Our parallel-processing pipeline leverages NVIDIA’s Warp library with custom computation kernels to maximize GPU utilization. By maintaining 3-D objects persistently in GPU memory and updating transforms only when objects move, we eliminate redundant data transfers. We also perform computations only when needed — when, for instance, a sensor parameter changes, or something moves. By these means, we achieve real-time performance.
Visualization methods
Sensor Workbench users can pick sphere- or plane-based visualizations, to see how the positions and rotations of individual barcodes affect performance.
This architecture allows us to perform complex calculations for multiple sensors simultaneously, enabling instant feedback in the form of immersive 3-D visuals. Those visuals represent metrics that barcode-detection machine-learning models need to work, as teams adjust sensor positions and parameters in the environment.
CAD to USD
Our second innovation involved developing a custom CAD-to-OpenUSD pipeline that automatically converts detailed warehouse models into optimized 3-D assets. Our CAD-to-USD conversion pipeline replicates the structure and content of models created in the modeling program SolidWorks with a 1:1 mapping. We start by extracting essential data — including world transforms, mesh geometry, material properties, and joint information — from the CAD file. The full assembly-and-part hierarchy is preserved so that the resulting USD stage mirrors the CAD tree structure exactly.
To ensure modularity and maintainability, we organize the data into separate USD layers covering mesh, materials, joints, and transforms. This layered approach ensures that the converted USD file faithfully retains the asset structure, geometry, and visual fidelity of the original CAD model, enabling accurate and scalable integration for real-time visualization, simulation, and collaboration.
OpenUSD as ground truth
The third important factor was our novel approach to using OpenUSD as the ground truth throughout the entire simulation process. We developed custom schemas that extend beyond basic 3-D-asset information to include enriched environment descriptions and simulation parameters. Our system continuously records all scene activities — from sensor positions and orientations to object movements and parameter changes — directly into the USD stage in real time. We even maintain user interface elements and their states within USD, enabling us to restore not just the simulation configuration but the complete user interface state as well.
This architecture ensures that when USD initial configurations change, the simulation automatically adapts without requiring modifications to the core software. By maintaining this live synchronization between the simulation state and the USD representation, we create a reliable source of truth that captures the complete state of the simulation environment, allowing users to save and re-create simulation configurations exactly as needed. The interfaces simply reflect the state of the world, creating a flexible and maintainable system that can evolve with our needs.
Application
With SWB, our teams can now rapidly evaluate sensor mounting positions and verify overall concepts in a fraction of the time previously required. More importantly, SWB has become a powerful platform for cross-functional collaboration, allowing engineers, scientists, and operational teams to work together in real time, visualizing and adjusting sensor configurations while immediately seeing the impact of their changes and sharing their results with each other.
New perspectives
In projection mode, an explicit target is not needed. Instead, Sensor Workbench uses the whole environment as a target, projecting rays from the camera to identify locations for barcode placement. Users can also switch between a comprehensive three-quarters view and the perspectives of individual cameras.
Due to the initial success in simulating barcode-reading scenarios, we have expanded SWB’s capabilities to incorporate high-fidelity lighting simulations. This allows teams to iterate on new baffle and light designs, further optimizing the conditions for reliable barcode detection, while ensuring that lighting conditions are safe for human eyes, too. Teams can now explore various lighting conditions, target positions, and sensor configurations simultaneously, gleaning insights that would take months to accumulate through traditional testing methods.

Looking ahead, we are working on several exciting enhancements to the system. Our current focus is on integrating more-advanced sensor simulations that combine analytical models with real-world measurement feedback from the ARID team, further increasing the system’s accuracy and practical utility. We are also exploring the use of AI to suggest optimal sensor placements for new station designs, which could potentially identify novel configurations that users of the tool might not consider.
Additionally, we are looking to expand the system to serve as a comprehensive synthetic-data generation platform. This will go beyond just simulating barcode-detection scenarios, providing a full digital environment for testing sensors and algorithms. This capability will let teams validate and train their systems using diverse, automatically generated datasets that capture the full range of conditions they might encounter in real-world operations.
By combining advanced scientific computing with practical industrial applications, SWB represents a significant step forward in warehouse automation development. The platform demonstrates how sophisticated simulation tools can dramatically accelerate innovation in complex industrial systems. As we continue to enhance the system with new capabilities, we are excited about its potential to further transform and set new standards for warehouse automation.
The Kotlin incremental compiler has been a true gem for developers chasing faster compilation since its introduction in build tools. Now, we’re excited to bring its benefits to Buck2 – Meta’s build system – to unlock even more speed and efficiency for Kotlin developers.
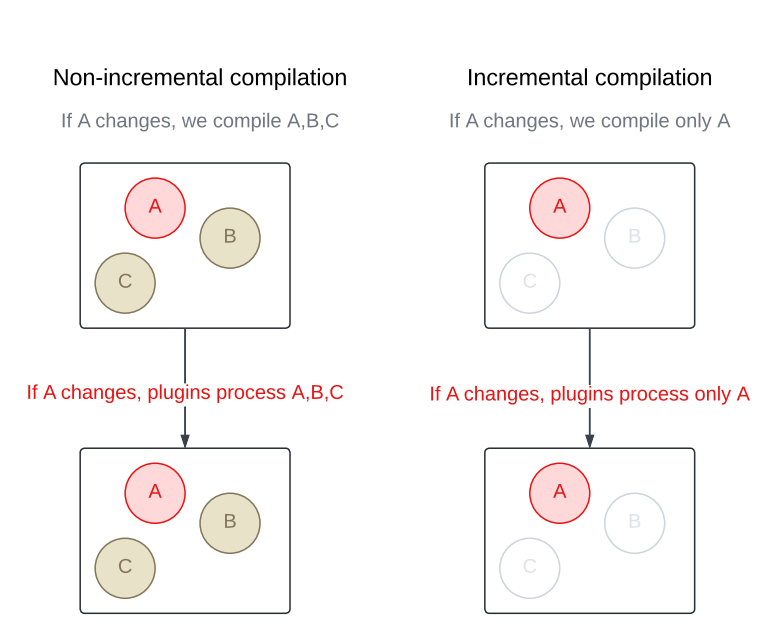
Unlike a traditional compiler that recompiles an entire module every time, an incremental compiler focuses only on what was changed. This cuts down compilation time in a big way, especially when modules contain a large number of source files.
Buck2 promotes small modules as a key strategy for achieving fast build times. Our codebase followed that principle closely, and for a long time, it worked well. With only a handful of files in each module, and Buck2’s support for fast incremental builds and parallel execution, incremental compilation didn’t seem like something we needed.
But, let’s be real: Codebases grow, teams change, and reality sometimes drifts away from the original plan. Over time, some modules started getting bigger – either from legacy or just organic growth. And while big modules were still the exception, they started having quite an impact on build times.
So we gave the Kotlin incremental compiler a closer look – and we’re glad we did. The results? Some critical modules now build up to 3x faster. That’s a big win for developer productivity and overall build happiness.
Curious about how we made it all work in Buck2? Keep reading. We’ll walk you through the steps we took to bring the Kotlin incremental compiler to life in our Android toolchain.
Step 1: Integrating Kotlin’s Build Tools API
As of Kotlin 2.2.0, the only guaranteed public contract to use the compiler is through the command-line interface (CLI). But since the CLI doesn’t support incremental compilation (at least for now), it didn’t meet our needs. Alternatively, we could integrate the Kotlin incremental compiler directly via the internal compiler’s components – APIs that are technically accessible but not intended for public use. However, relying on them would’ve made our toolchain fragile and likely to break with every Kotlin update since there’s no guarantee of backward compatibility. That didn’t seem like the right path either.
Then we came across the Build Tools API (KEEP), introduced in Kotlin 1.9.20 as the official integration point for the compiler – including support for incremental compilation. Although the API was still marked as experimental, we decided to give it a try. We knew it would eventually stabilize, and saw it as a great opportunity to get in early, provide feedback, and help shape its direction. Compared to using internal components, it offered a far more sustainable and future-proof approach to integration.
⚠️ Depending on kotlin-compiler? Watch out!
In the Java world, a shaded library is a modified version of the library where the class and package names are changed. This process – called shading – is a handy way to avoid classpath conflicts, prevent version clashes between libraries, and keeps internal details from leaking out.
Here’s quick example:
- Unshaded (original) class: com.intellij.util.io.DataExternalizer
- Shaded class: org.jetbrains.kotlin.com.intellij.util.io.DataExternalizer
The Build Tools API depends on the shaded version of the Kotlin compiler (kotlin-compiler-embeddable). But our Android toolchain was historically built with the unshaded one (kotlin-compiler). That mismatch led to java.lang.NoClassDefFoundError crashes when testing the integration because the shaded classes simply weren’t on the classpath.
Replacing the unshaded compiler across the entire Android toolchain would’ve been a big effort. So to keep moving forward, we went with a quick workaround: We unshaded the Build Tools API instead. 🙈 Using the jarjar library, we stripped the org.jetbrains.kotlin prefix from class names and rebuilt the library.
Don’t worry, once we had a working prototype and confirmed everything behaved as expected, we circled back and did it right – fully migrating our toolchain to use the shaded Kotlin compiler. That brought us back in line with the API’s expectations and gave us a more stable setup for the future.
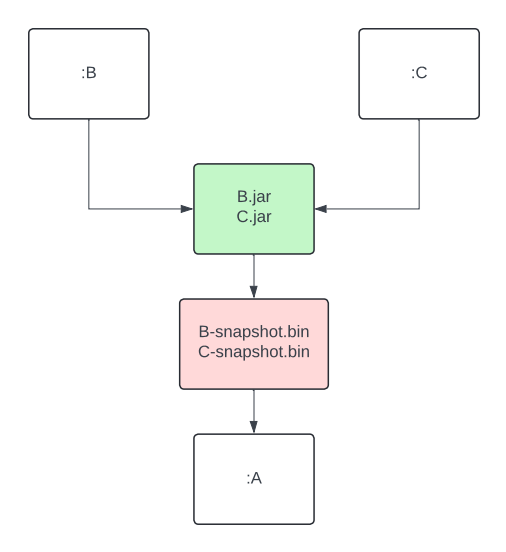
Step 2: Keeping previous output around for the incremental compiler
To compile incrementally, the Kotlin compiler needs access to the output from the previous build. Simple enough, but Buck2 deletes that output by default before rebuilding a module.
With incremental actions, you can configure Buck2 to skip the automatic cleanup of previous outputs. This gives your build actions access to everything from the last run. The tradeoff is that it’s now up to you to figure out what’s still useful and manually clean up the rest. It’s a bit more work, but it’s exactly what we needed to make incremental compilation possible.
Step 3: Making the incremental compiler cache relocatable
At first, this might not seem like a big deal. You’re not planning to move your codebase around, so why worry about making the cache relocatable, right?
Well… that’s until you realize you’re no longer in a tiny team, and you’re definitely not the only one building the project. Suddenly, it does matter.
Buck2 supports distributed builds, which means your builds don’t have to run only on your local machine. They can be executed elsewhere, with the results sent back to you. And if your compiler cache isn’t relocatable, this setup can quickly lead to trouble – from conflicting overloads to strange ambiguity errors caused by mismatched paths in cached data.
So we made sure to configure the root project directory and the build directory explicitly in the incremental compilation settings. This keeps the compiler cache stable and reliable, no matter who runs the build or where it happens.
Step 4: Configuring the incremental compiler
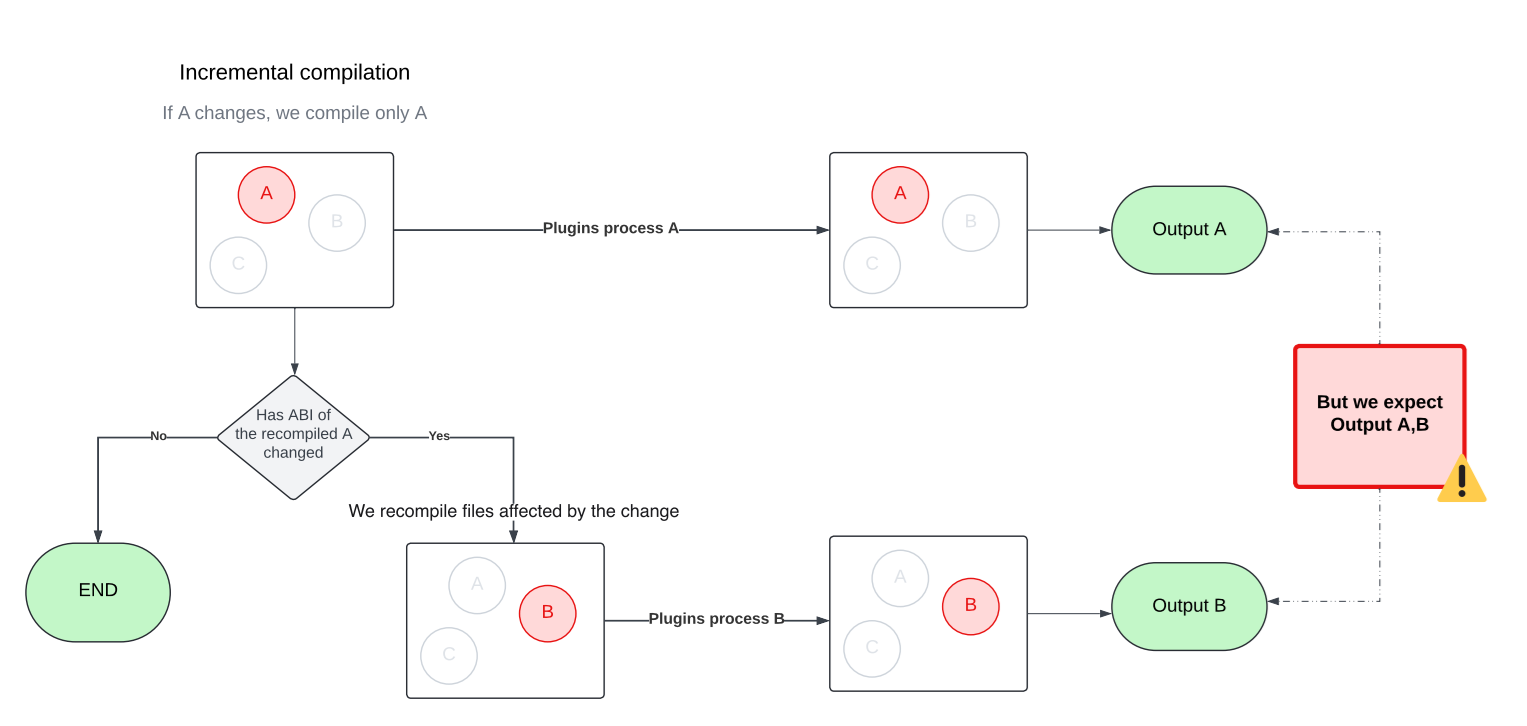
In a nutshell, to decide what needs to be recompiled, the Kotlin incremental compiler looks for changes in two places:
- Files within the module being rebuilt.
- The module’s dependencies.
Once the changes are found, the compiler figures out which files in the module are affected – whether by direct edits or through updated dependencies – and recompiles only those.
To get this process rolling, the compiler needs just a little nudge to understand how much work it really has to do.
So let’s give it that nudge!
Tracking changes inside the module
When it comes to tracking changes, you’ve got two options: You can either let the compiler do its magic and detect changes automatically, or you can give it a hand by passing a list of modified files yourself. The first option is great if you don’t know which files have changed or if you just want to get something working quickly (like we did during prototyping). However, if you’re on a Kotlin version earlier than 2.1.20, you have to provide this information yourself. Automatic source change detection via the Build Tools API isn’t available prior to that. Even with newer versions, if the build tool already has the change list before compilation, it’s still worth using it to optimize the process.
This is where Buck’s incremental actions come in handy again! Not only can we preserve the output from the previous run, but we also get hash digests for every action input. By comparing those hashes with the ones from the last build, we can generate a list of changed files. From there, we pass that list to the compiler to kick off incremental compilation right away – no need for the compiler to do any change detection on its own.
Tracking changes in dependencies
Sometimes it’s not the module itself that changes, it’s something the module depends on. In these cases, the compiler relies on classpath snapshot. These snapshots capture the Application Binary Interface (ABI) of a library. By comparing the current snapshots to the previous one, the compiler can detect changes in dependencies and figure out which files in your module are affected. This adds an extra layer of filtering on top of standard compilation avoidance.
In Buck2, we added a dedicated action to generate classpath snapshots from library outputs. This artifact is then passed as an input to the consuming module, right alongside the library’s compiled output. The best part? Since it’s a separate action, it can be run remotely or be pulled from cache, so your machine doesn’t have to do the heavy lifting of extracting ABI at this step.
If, after all, only your module changes but your dependencies do not, the API also lets you skip the snapshot comparison entirely if your build tool handles the dependency analysis on its own. Since we already had the necessary data from Buck2’s incremental actions, adding this optimization was almost free.
Step 5: Making compiler plugins work with the incremental compiler
One of the biggest challenges we faced when integrating the incremental compiler was making it play nicely with our custom compiler plugins, many of which are important to our build optimization strategy. This step was necessary for unlocking the full performance benefits of incremental compilation, but it came with two major issues we needed to solve.
🚨 Problem 1: Incomplete results
As we already know, the input to the incremental compiler does not have to include all Kotlin source files. Our plugins weren’t designed for this and ended up producing incomplete results when run on just a subset of files. We had to make them incremental as well so they could handle partial inputs correctly.
🚨 Problem 2: Multiple rounds of Compilation
The Kotlin incremental compiler doesn’t just recompile the files that changed in a module. It may also need to recompile other files in the same module that are affected by those changes. Figuring out the exact set of affected files is tricky, especially when circular dependencies come into play. To handle this, the incremental compiler approximates the affected set by compiling in multiple rounds within a single build.
💡Curious how that works under the hood? The Kotlin blog on fast compilation has a great deep dive that’s worth checking out.
This behavior comes with a side effect, though. Since the compiler may run in multiple rounds with different sets of files, compiler plugins can also be triggered multiple times, each time with a different input. That can be problematic, as later plugin runs may override outputs produced by earlier ones. To avoid this, we updated our plugins to accumulate their results across rounds rather than replacing them.
Step 6: Verifying the functionality of annotation processors
Most of our annotation processors use Kotlin Symbol Processing (KSP2), which made this step pretty smooth. KSP2 is designed as a standalone tool that uses the Kotlin Analysis API to analyze source code. Unlike compiler plugins, it runs independently from the standard compilation flow. Thanks to this setup, we were able to continue using KSP2 without any changes.
💡 Bonus: KSP2 comes with its own built-in incremental processing support. It’s fully self-contained and doesn’t depend on the incremental compiler at all.
Before we adopted KSP2 (or when we were using an older version of the Kotlin Annotation Processing Tool (KAPT), which operates as a plugin) our annotation processors ran in a separate step dedicated solely to annotation processing. That step ran before the main compilation and was always non-incremental.
Step 7: Enabling compilation against ABI
To maximize cache hits, Buck2 builds Android modules against the class ABI instead of the full JAR. For Kotlin targets, we use the jvm-abi-gen compiler plugin to generate class ABI during compilation.
But once we turned on incremental compilation, a couple of new challenges popped up:
- The jvm-abi-gen plugin currently lacks direct support for incremental compilation, which ties back to the issues we mentioned earlier with compiler plugins.
- ABI extraction now happens twice – once during compilation via jvm-abi-gen, and again when the incremental compiler creates classpath snapshots.
In theory, both problems could be solved by switching to full JAR compilation and relying on classpath snapshots to maintain cache hits. While that could work in principle, it would mean giving up some of the build optimizations we’ve already got in place – a trade-off that needs careful evaluation before making any changes.
For now, we’ve implemented a custom (yet suboptimal) solution that merges the newly generated ABI with the previous result. It gets the job done, but we’re still actively exploring better long-term alternatives.
Ideally, we’d be able to reuse the information already collected for classpath snapshot or, even better, have this kind of support built directly into the Kotlin compiler. There’s an open ticket for that: KT-62881. Fingers crossed!
Step 8: Testing
Measuring the impact of build changes is not an easy task. Benchmarking is great for getting a sense of a feature’s potential, but it doesn’t always reflect how things perform in “the real world.” Pre/post testing can help with that, but it’s tough to isolate the impact of a single change, especially when you’re not the only one pushing code.
We set up A/B testing to overcome these obstacles and measure the true impact of the Kotlin incremental compiler on Meta’s codebase with high confidence. It took a bit of extra work to keep the cache healthy across variants, but it gave us a clean, isolated view of how much difference the incremental compiler really made at scale.
We started with the largest modules – the ones we already knew were slowing builds the most. Given their size and known impact, we expected to see benefits quickly. And sure enough, we did.
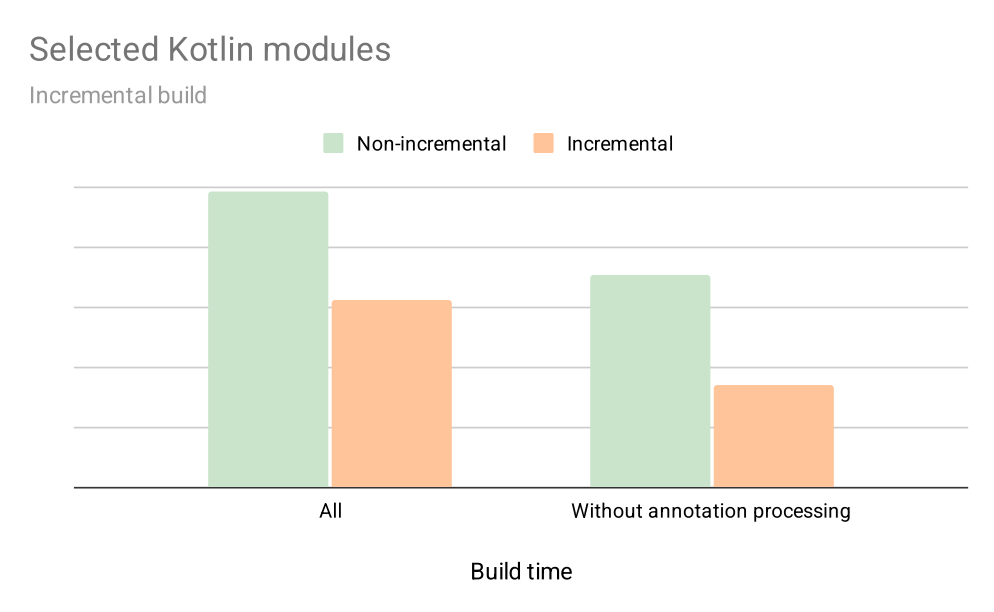
The impact of incremental compilation
The graph below shows early results on how enabling incremental compilation for selected targets impacts their local build times during incremental builds over a 4-week period. This includes not just compilation, but also annotation processing, and a few other optimisations we’ve added along the way.
With incremental compilation, we’ve seen about a 30% improvement for the average developer. And for modules without annotation processing, the speed nearly doubled. That was more than enough to convince us that the incremental compiler is here to stay.
What’s next
Kotlin incremental compilation is now supported in Buck2, and we’re actively rolling it out across our codebase! For now, it’s available for internal use only, but we’re working on bringing it to the recently introduced open source toolchain as well.
But that’s not all! We’re also exploring ways to expand incrementality across the entire Android toolchain, including tools like Kosabi (the Kotlin counterpart to Jasabi), to deliver even faster build times and even better developer experience.
To learn more about Meta Open Source, visit our open source site, subscribe to our YouTube channel, or follow us on Facebook, Threads, X and LinkedIn.
When Andy Jassy, then head of Amazon Web Services, announced Amazon Aurora in 2014, the pitch was bold but metered: Aurora would be a relational database built for the cloud. As such, it would provide access to cost-effective, fast, and scalable computing infrastructure.
In essence, he explained, Aurora would combine the cost effectiveness and simplicity of MySQL with the speed and availability of high-end commercial databases, the kind that firms typically managed on their own. In numbers, Aurora promised five times the throughput (e.g., the number of transactions, queries, read/write operations) of MySQL at one-tenth the price of commercial database solutions, all while offloading costly management challenges and maintaining performance and availability.
AWS re:Invent 2014 | Announcing Amazon Aurora for RDS
Aurora launched a year later, in 2015. Significantly, it decoupled computation from storage, a distinct contrast to traditional database architectures where the two are entwined. This fundamental innovation, along with automated backups and replication and other improvements, enabled easy scaling for both computational tasks and storage, while meeting reliability demands.
“Aurora’s design preserves the core transactional consistency strengths of relational databases. It innovates at the storage layer to create a database built for the cloud that can support modern workloads without sacrificing performance,” explained Werner Vogels, Amazon’s CTO, in 2019.
“To start addressing the limitations of relational databases, we reconceptualized the stack by decomposing the system into its fundamental building blocks,” Vogels said. “We recognized that the caching and logging layers were ripe for innovation. We could move these layers into a purpose-built, scale-out, self-healing, multitenant, database-optimized storage service. When we began building the distributed storage system, Amazon Aurora was born.”
Within two years, Aurora became the fastest-growing service in AWS history. Tens of thousands of customers — including financial-services companies, gaming companies, healthcare providers, educational institutions, and startups — turned to Aurora to help carry their workloads.
In the intervening years, Aurora has continued to evolve to suit the needs of a changing digital landscape. Most recently, in 2024, Amazon announced Aurora DSQL. A major step forward, Aurora DSQL is a serverless approach designed for global scale and enhanced adaptability to variable workloads.
Today, International Data Corporation (IDC) research estimates that firms using Aurora see a three-year return on investment of 434 percent and an operational cost reduction of 42 percent compared to other database solutions.
But what lies behind those figures? How did Aurora become so valuable to its users? To understand that, it’s useful to consider what came before.
A time for reinvention
In 2015, as cloud computing was gaining popularity, legacy firms began migrating workloads away from on-premises data centers to save money on capital investments and in-house maintenance. At the same time, mobile and web app startups were calling for remote, highly reliable databases that could scale in an instant. The theme was clear: computing and storage needed to be elastic and reliable. The reality was that, at the time, most databases simply hadn’t adapted to those needs.
Amazon engineers recognized that the cloud could enable virtually unlimited, networked storage and, separately, compute.
That rigidity makes sense considering the origin of databases and the problems they were invented to solve. The 1960s saw one of their earliest uses: NASA engineers had to navigate a complex list of parts, components, and systems as they built spacecraft for moon exploration. That need inspired the creation of the Information Management System, or IMS, a hierarchically structured solution that allowed engineers to more easily locate relevant information, such as the sizes or compatibilities of various parts and components. While IMS was a boon at the time, it was also limited. Finding parts meant engineers had to write batches of specially coded queries that would then move through a tree-like data structure, a relatively slow and specialized process.
In 1970, the idea of relational databases made its public debut when E. F. Codd coined the term. Relational databases organized data according to how it was related: customers and their purchases, for instance, or students in a class. Relational databases meant faster search, since data was stored in structured tables, and queries didn’t require special coding knowledge. With programming languages like SQL, relational databases became a dominant model for storing and retrieving structured data.
By the 1990s, however, that approach began to show its limits. Firms that needed more computing capabilities typically had to buy and physically install more on-premises servers. They also needed specialists to manage new capabilities, such as the influx of transactional workloads — as, for instance, when increasing numbers of customers added more and more pet supplies to virtual shopping carts. By the time AWS arrived in 2006, these legacy databases were the most brittle, least elastic component of a company’s IT stack.
The emergence of cloud computing promised a better way forward with more flexibility and remotely managed solutions. Amazon engineers recognized that the cloud could enable virtually unlimited, networked storage and, separately, computation.
The Amazon Relational Database Service (Amazon RDS) debuted in 2009 to help customers set up, operate, and scale a MySQL database in the cloud. And while that service expanded to include Oracle, SQL Server, and PostgreSQL, as Jeff Barr noted in a 2014 blog post, those database engines “were designed to function in a constrained and somewhat simplistic hardware environment.”
AWS researchers challenged themselves to examine those constraints and “quickly realized that they had a unique opportunity to create an efficient, integrated design that encompassed the storage, network, compute, system software, and database software”.
“The central constraint in high-throughput data processing has moved from compute and storage to the network,” wrote the authors of a SIGMOD 2017 paper describing Aurora’s architecture. Aurora researchers addressed that constraint via “a novel, service-oriented architecture”, one that offered significant advantages over traditional approaches. These included “building storage as an independent fault-tolerant and self-healing service across multiple data centers … protecting databases from performance variance and transient or permanent failures at either the networking or storage tiers.”’
The serverless era is now
In the years since its debut, Amazon engineers and researchers have ensured Aurora has kept pace with customer needs. In 2018, Aurora Serverless provided an on-demand autoscaling configuration that allowed customers to adjust computational capacity up and down based on their needs. Later versions further optimized that process by automatically scaling based on customer needs. That approach relieves the customer of the need to explicitly manage database capacity; customers need to specify only minimum and maximum levels.
Achieving that sort of “resource elasticity at high levels of efficiency” meant Aurora Serverless had to address several challenges, wrote the authors of a VLDB 2024 paper. “These included policy issues such as how to define ‘heat’ (i.e., resource usage features on which to base decision making)” and how to determine whether remedial action may be required. Aurora Serverless meets those challenges, the authors noted, by adapting and modifying “well-established ideas related to resource oversubscription; reactive control informed by recent measurements; distributed and hierarchical decision making; and innovations in the DB engine, OS, and hypervisor for efficiency.”
As of May 2025, all of Aurora’s offerings are now serverless. Customers no longer need to choose a specific server type or size or worry about the underlying hardware or operating system, patching, or backups; all that is completely managed by AWS. “One of the things that we’ve tried to design from the beginning is a database where you don’t have to worry about the internals,” Marc Brooker, AWS vice president and Distinguished Engineer, said at AWS re:Invent in 2024.
These are exactly the capabilities that Arizona State University needs, says John Rome, deputy chief information officer at ASU. Each fall, the university’s data needs explode when classes for its more than 73,000 students are in session across multiple campuses. Aurora lets ASU pay for the computation and storage it uses and helps it to adapt on the fly.
We see Amazon Aurora Serverless as a next step in our cloud maturity.
John Rome, deputy chief information officer at ASU
“We see Amazon Aurora Serverless as a next step in our cloud maturity,” Rome says, “to help us improve development agility while reducing costs on infrequently used systems, to further optimize our overall infrastructure operations.”
And what might the next step in maturity look like for the now 10-year-old Aurora service? The authors of that 2024 paper outlined several potential paths. Those include “introducing predictive techniques for live migration”; “exploiting statistical multiplexing opportunities stemming from complementary resource needs”, and “using sophisticated ML/RL-based techniques for workload prediction and decision making.”
-
Tools & Platforms3 weeks ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Business2 days ago
Business2 days agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-

 Ethics & Policy1 month ago
Ethics & Policy1 month agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences3 months ago
Events & Conferences3 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers2 months ago
Jobs & Careers2 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Education2 months ago
Education2 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Funding & Business2 months ago
Funding & Business2 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi
-

 Mergers & Acquisitions2 months ago
Mergers & Acquisitions2 months agoDonald Trump suggests US government review subsidies to Elon Musk’s companies