AI Research
IBM AI Research Releases Two English Granite Embedding Models, Both Based on the ModernBERT Architecture
IBM has quietly built a strong presence in the open-source AI ecosystem, and its latest release shows why it shouldn’t be overlooked. The company has introduced two new embedding models—granite-embedding-english-r2 and granite-embedding-small-english-r2—designed specifically for high-performance retrieval and RAG (retrieval-augmented generation) systems. These models are not only compact and efficient but also licensed under Apache 2.0, making them ready for commercial deployment.
What Models Did IBM Release?
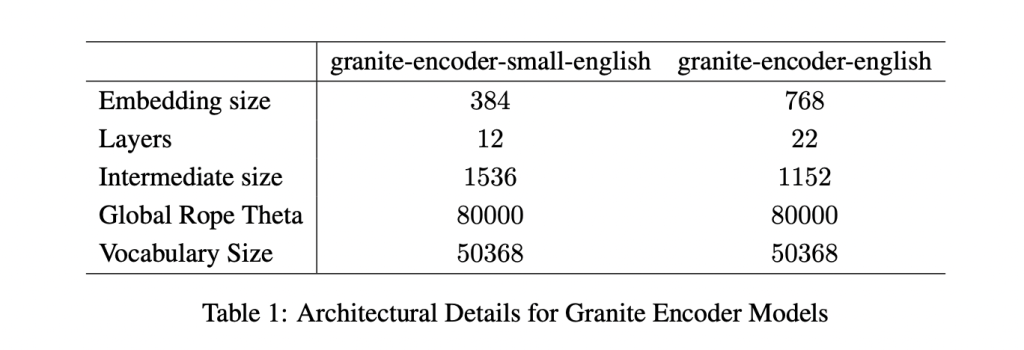
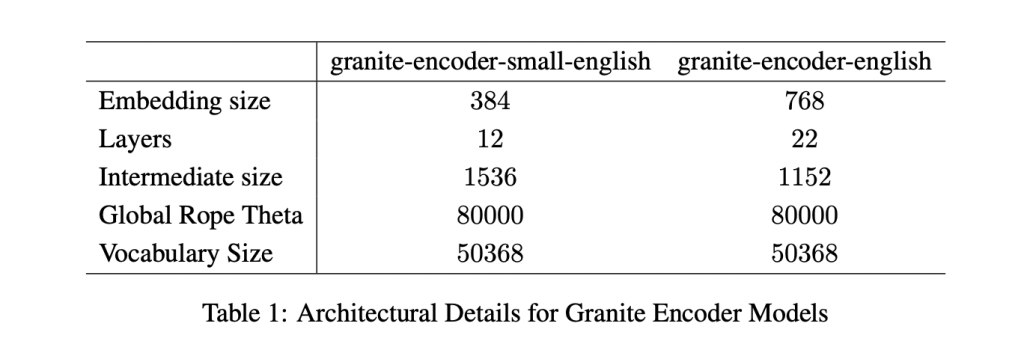
The two models target different compute budgets. The larger granite-embedding-english-r2 has 149 million parameters with an embedding size of 768, built on a 22-layer ModernBERT encoder. Its smaller counterpart, granite-embedding-small-english-r2, comes in at just 47 million parameters with an embedding size of 384, using a 12-layer ModernBERT encoder.
Despite their differences in size, both support a maximum context length of 8192 tokens, a major upgrade from the first-generation Granite embeddings. This long-context capability makes them highly suitable for enterprise workloads involving long documents and complex retrieval tasks.
What’s Inside the Architecture?
Both models are built on the ModernBERT backbone, which introduces several optimizations:
- Alternating global and local attention to balance efficiency with long-range dependencies.
- Rotary positional embeddings (RoPE) tuned for positional interpolation, enabling longer context windows.
- FlashAttention 2 to improve memory usage and throughput at inference time.
IBM also trained these models with a multi-stage pipeline. The process started with masked language pretraining on a two-trillion-token dataset sourced from web, Wikipedia, PubMed, BookCorpus, and internal IBM technical documents. This was followed by context extension from 1k to 8k tokens, contrastive learning with distillation from Mistral-7B, and domain-specific tuning for conversational, tabular, and code retrieval tasks.

How Do They Perform on Benchmarks?
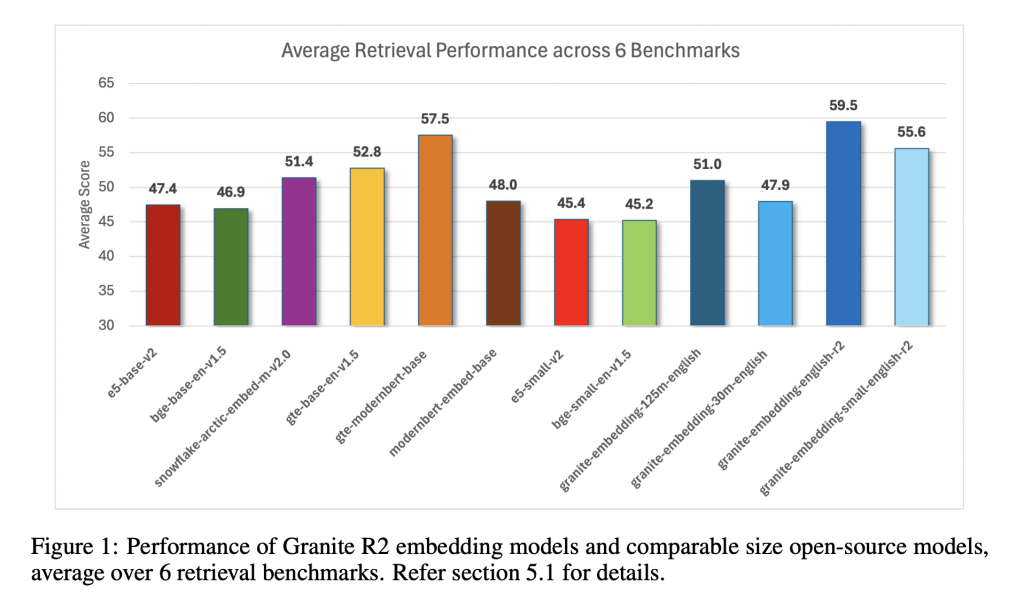
The Granite R2 models deliver strong results across widely used retrieval benchmarks. On MTEB-v2 and BEIR, the larger granite-embedding-english-r2 outperforms similarly sized models like BGE Base, E5, and Arctic Embed. The smaller model, granite-embedding-small-english-r2, achieves accuracy close to models two to three times larger, making it particularly attractive for latency-sensitive workloads.
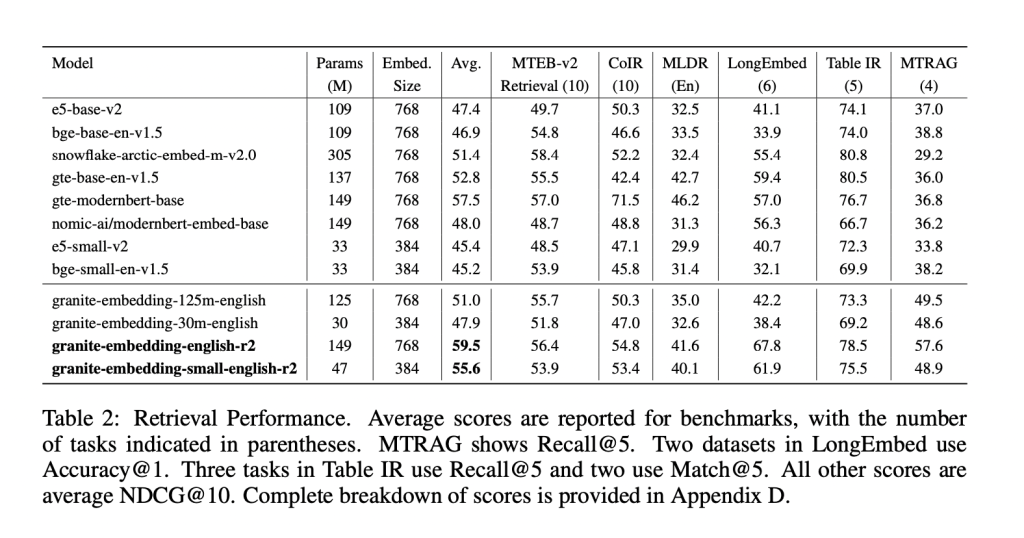
Both models also perform well in specialized domains:
- Long-document retrieval (MLDR, LongEmbed) where 8k context support is critical.
- Table retrieval tasks (OTT-QA, FinQA, OpenWikiTables) where structured reasoning is required.
- Code retrieval (CoIR), handling both text-to-code and code-to-text queries.
Are They Fast Enough for Large-Scale Use?
Efficiency is one of the standout aspects of these models. On an Nvidia H100 GPU, the granite-embedding-small-english-r2 encodes nearly 200 documents per second, which is significantly faster than BGE Small and E5 Small. The larger granite-embedding-english-r2 also reaches 144 documents per second, outperforming many ModernBERT-based alternatives.
Crucially, these models remain practical even on CPUs, allowing enterprises to run them in less GPU-intensive environments. This balance of speed, compact size, and retrieval accuracy makes them highly adaptable for real-world deployment.
What Does This Mean for Retrieval in Practice?
IBM’s Granite Embedding R2 models demonstrate that embedding systems don’t need massive parameter counts to be effective. They combine long-context support, benchmark-leading accuracy, and high throughput in compact architectures. For companies building retrieval pipelines, knowledge management systems, or RAG workflows, Granite R2 provides a production-ready, commercially viable alternative to existing open-source options.
Summary
In short, IBM’s Granite Embedding R2 models strike an effective balance between compact design, long-context capability, and strong retrieval performance. With throughput optimized for both GPU and CPU environments, and an Apache 2.0 license that enables unrestricted commercial use, they present a practical alternative to bulkier open-source embeddings. For enterprises deploying RAG, search, or large-scale knowledge systems, Granite R2 stands out as an efficient and production-ready option.
Check out the Paper, granite-embedding-small-english-r2 and granite-embedding-english-r2. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.

Both technologies will likely find a role in future AI and optical networks, experts say, as both promise to reduce power consumption and support improved bandwidth density. Both have advantages and disadvantages as well – CPOs are more complex to deploy given the amount of technology included in a CPO package, whereas LPOs promise more simplicity.
Bechtolsheim said that LPO can provide an additional 20% power savings over other optical forms. Early tests show good receiver performance even under degraded conditions, though transmit paths remain sensitive to reflections and crosstalk at the connector level, Bechtolsheim added.
At the recent Hot Interconnects conference, he said: “The path to energy-efficient optics is constrained by high-volume manufacturing,” stressing that advanced optics packaging remains difficult and risky without proven production scale.
“We are nonreligious about CPO, LPO, whatever it is. But we are religious about one thing, which is the ability to ship very high volumes in a very predictable fashion,” Bechtolsheim said at the investor event. “So, to put this in quantity numbers here, the industry expects to ship something like 50 million OSFP modules next calendar year. The current shipment rate of CPO is zero, okay? So going from zero to 50 million is just not possible. The supply chain doesn’t exist. So, even if the technology works and can be demonstrated in a lab, to get to the volume required to meet the needs of the industry is just an incredible effort.”
“We’re all in on liquid cooling to reduce power, eliminating fan power, supporting the linear pluggable optics to reduce power and cost, increasing rack density, which reduces data center footprint and related costs, and most importantly, optimizing these fabrics for the AI data center use case,” Bechtolsheim added.
“So what we call the ‘purpose-built AI data center fabric’ around Ethernet technology is to really optimize AI application performance, which is the ultimate measure for the customer in both the scale-up and the scale-out domains. Some of this includes full switch customization for customers. Other cases, it includes the power and cost optimization. But we have a large part of our hardware engineering department working on these things,” he said.
AI Research
Learning by Doing: AI, Knowledge Transfer, and the Future of Skills | American Enterprise Institute

In a recent blog, I discussed Stanford University economist Erik Brynjolfsson’s new study showing that young college graduates are struggling to gain a foothold in a job market shaped by artificial intelligence (AI). His analysis found that, since 2022, early-career workers in AI-exposed roles have seen employment growth lag 13 percent behind peers in less-exposed fields. At the same time, experienced workers in the same jobs have held steady or even gained ground. The conclusion: AI isn’t eliminating work outright, but it is affecting the entry-level rungs that young workers depend on as they begin climbing career ladders.
The potential consequences of these findings, assuming they bear out, become clearer when read alongside Enrique Ide’s recent paper, Automation, AI, and the Intergenerational Transmission of Knowledge. Ide argues that when firms automate entry-level tasks, the opportunity for new workers to gain the tacit knowledge—the kind of workplace norms and rhythms of team-based work that aren’t necessarily written down—isn’t passed on. Thus, productivity gains accrue to seasoned workers while would-be novices lose the hands-on training they need to build the foundation for career progress.
This short-circuiting of early career experiences, Ide says, has macro-economic consequences. He estimates that automating even five percent of entry-level tasks reduces long-run US output growth by an estimated 0.05 percentage points per year; at 30 percent automation, growth slows by more than 0.3 points. Over a hundred year timeline, this would reduce total output by 20 percent relative to a world without AI automation. In other words: automating the bottom rungs might lift firms’ quarterly performance, but at the cost of generational growth.
This is where we need to pause and take a breath. While Ide’s results sound dramatic, it is critical to remember that the dynamics and consequences of AI adoption are unpredictable, and that a century is a very long time. For instance, who would have said in 2022 that one of the first effects of AI automation would be to benefit less tech-savvy boomer and Gen-X managers and harm freshly minted Gen-Z coders?
Given the history of positive, automation-induced wealth and employment effects, why would this time be different?
Finally, it’s important to remember that in a dynamic market-driven economy, skill requirements are always changing and firms are always searching for ways to improve their efficiency relative to competitors. This is doubly true as we enter the era of cognitive, as opposed to physical, automation. AI-driven automation is part of the pathway to a more prosperous economy and society for ourselves and for future generations. As my AEI colleague Jim Pethokoukis recently said, “A supposedly powerful general-purpose technology that left every firm’s labor demand utterly unchanged wouldn’t be much of a GPT.” Said another way, unless AI disrupts our economy and lives, it cannot deliver its promised benefits.
What then should we do? I believe the most important step we can take right now is to begin “stress-testing” our current workforce development policies and programs and building scenarios for how industry and government will respond should significant AI-related job disruptions occur. Such scenario planning could be shaped into a flexible “playbook” of options to guide policymakers geared to the types and numbers of affected workers. Such planning didn’t occur prior to the automation and trade shocks of the 1990s and 2000s with lasting consequences for factory workers and American society. We should try to make sure this doesn’t happen again with AI.
Pessimism is easy and cheap. We should resist the lure of social media-monetized AI doomerism and focus on building the future we want to see by preparing for and embracing change.

Alzheimer’s disease is one of the most urgent public health challenges for aging Americans. Nearly seven million Americans over the age of 65 are currently living with the disease, and that number is projected to nearly double by 2060, according to the Alzheimer’s Association.
Early diagnosis and continuous monitoring are crucial to improving care and extending independence, but there isn’t enough high-quality, Alzheimer’s-specific data to train artificial intelligence systems that could help detect and track the disease.
Shan Lin, associate professor of Electrical and Computer Engineering at Stony Brook University, along with PhD candidate Heming Fu, are working with Guoliang Xing from The Chinese University of Hong Kong to create a network of data based on Alzheimer’s patients. Together they developed SHADE-AD (Synthesizing Human Activity Datasets Embedded with AD features), a generative AI framework designed to create synthetic, realistic data that reflects the motor behaviors of Alzheimer’s patients.

Movements like stooped posture, reliance on armrests when standing from sitting, or slowed gait may appear subtle, but can be early indicators of the disease. By identifying and replicating these patterns, SHADE-AD provides researchers and physicians with the data required to improve monitoring and diagnosis.
Unlike existing generative models, which often rely on and output generic datasets drawn from healthy individuals, SHADE-AD was trained to embed Alzheimer’s-specific traits. The system generates three-dimensional “skeleton videos,” simplified figures that preserve details of joint motion. These 3D skeleton datasets were validated against real-world patient data, with the model proving capable of reproducing the subtle changes in speed, angle, and range of motion that distinguish Alzheimer’s behaviors from those of healthy older adults.
The results and findings, published and presented at the 23rd ACM Conference on Embedded Networked Sensor Systems (SenSys 2025), have been significant. Activity recognition systems trained with SHADE-AD’s data achieved higher accuracy across all major tasks compared with systems trained on traditional data augmentation or general open datasets. In particular, SHADE-AD excelled at recognizing actions like walking and standing up, which often reveal the earliest signs of decline for Alzheimer’s patients.

Lin believes this work could have a significant impact on the daily lives of older adults and their families. Technologies built on SHADE-AD could one day allow doctors to detect Alzheimer’s sooner, track disease progression more accurately, and intervene earlier with treatments and support. “If we can provide tools that spot these changes before they become severe, patients will have more options, and families will have more time to plan,” he said.
With September recognized nationally as Healthy Aging Month, Lin sees this research as part of an effort to use technology to support older adults in living longer, healthier, and more independent lives. “Healthy aging isn’t only about treating illness, but also about creating systems that allow people to thrive as they grow older,” he said. “AI can be a powerful ally in that mission.”
— Beth Squire
-

 Business2 weeks ago
Business2 weeks agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-
Tools & Platforms1 month ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy2 months ago
Ethics & Policy2 months agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences4 months ago
Events & Conferences4 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers3 months ago
Jobs & Careers3 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Education3 months ago
Education3 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Education2 months ago
Education2 months agoMacron says UK and France have duty to tackle illegal migration ‘with humanity, solidarity and firmness’ – UK politics live | Politics
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi
-

 Funding & Business3 months ago
Funding & Business3 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries