Books, Courses & Certifications
I Took a Certification in AI. Here’s What It Taught Me About Prompt Engineering.
ARTIFICIAL INTELLIGENCE
A journey towards mastery in modern AI
With the goal of keeping my tech skills ever relevant, I’m currently working through a new certification to build upon my experience in AI.
Everything changes so fast.
This is especially the case with recent advancements in AI and the sweeping effects across the industry. When I take a look at the stock valuations for Nvidia, Microsoft, Google, Meta, and many other tech companies, it’s apparent how much of a financial impact AI is having.
The bulk of this expansion is a result of generative AI.
Zero-shot prompting, RAG, and fine-tuning — oh my!
While some of the terminology around LLMs may seem intimidating, fear not!
I’m going to share what I’ve learned with prompt engineering and advanced techniques for getting the most out of large language models (LLMs).
Come along on this adventure!
Becoming a “prompt engineer”
I officially began this journey by enrolling in the Oracle Cloud Infrastructure Generative AI Professional certification program.
The content takes a deep dive into prompt engineering and how to best utilize large language models. I’m finding the certification to be particularly relevant in my work, as I have been integrating with LLMs when writing software. Understanding how to best leverage these tools is key.
It’s also clear from the certification process that training LLMs is an important skill that can be very valuable to companies and employers.
Basic training
LLMs typically perform quite well for many general tasks. In fact, the default services such as ChatGPT are used for a large variety of problems.
Tasks such as text generation, summarization, classification, and document understanding are just some of the tasks that most LLMs are capable of solving. This is just with the default knowledge that the LLMs were trained upon.
In fact, LLMs are proving to be user-friendly enough to be used across entire age groups – even children – in apps such as Snapchat, Quora, and others.
However, what can you do when the LLM just isn’t performing well for a specific task?
Teaching to improve
As it turns out, LLMs can be prompted, and even trained, beyond their initial programming.
LLMs can indeed learn more.
By using a combination of prompt engineering, retrieval augmented generation, and fine-tuning, a model can be adapted to become smart at specific tasks. This includes not just general knowledge that is publicly available, but also domain specific tasks that require private knowledge or more complex reasoning.
It all begins with simple text-based interaction through prompt engineering.
Human computer interaction
Prompt engineering is a simple concept. It’s just a way of asking the LLM to complete a task by providing it with instructions.
If you would like to write a poem about nature, you can simply ask the LLM a question and perhaps include additional detail, such as a topic or writing style. The LLM will then output a response as generated from its knowledge. This is the most common interaction that most users make with LLMs.
However, as I’ve learned throughout the certification process, you can increase your skill far beyond a typical ChatGPT user.
First, it is important to understand how an LLM formulates a response.

LLMs are not magic
When an LLM generates a response, the process is actually quite calculated.
Input provided to the LLM is split into tokens. These often consist of one token per word but may also expand into multiple tokes for less common words.
The LLM processes each token, along with the entire sentence, using an encoder. It then generates a word as output according to the highest probability of that word occurring next within a sentence sequence.
To generate the next word in the response, the output (including the newly generated word) is fed back to the encoder to produce the next word as output.
The final response is built-up on a word-by-word basis until it reaches a stopping point, such as sentence completion.
Deterministic output and creativity
You may think that an LLM’s output should always be the same for a given input. However, this is only partially true.
Since generated words are returned based upon probability, we can adjust this probability in order to generate different results. This effectively allows an LLM to change from being deterministic for any given input to instead being more random, providing different (or more creative) responses from the same input.
This is called temperature.
Adjusting temperature
Adjusting the temperature of an LLM allows for changing the probabilities for words occurring next in sequence and creating an effect of creativity.
The lowest temperature setting of 0 equates to a completely deterministic response. Any time the same prompt is provided to an LLM it will respond with the exact same answer.
For example, if we prompt the LLM with a sentence such as “The sky is”, we might expect the completion for this sentence to include any of the following words.
Prompt
“The sky is”Probabilities:green – 0.1
- blue – 0.9
orange – 0.6
red – 0.4
Predicting responses
When the temperature is set to 0, the LLM will follow a greedy approach and always choose the highest probability word. In the case of “The sky is”, the LLM will return the word “blue”.
Raising the temperature has the effect of flattening the probabilities so that each word has a higher chance of being selected. If we were to change the temperature setting to 0.9, we might find the following new probabilities for each word completion.
Prompt
“The sky is”Probabilities:green – 0.3
- blue – 0.5
- orange – 0.4
- red – 0.4
Notice how the probabilities have become much closer together. In fact, a response of “blue” is now only slightly greater of occurring after “orange” or even “red”.
Temperature is used to adjust the creativity aspect of an LLM and is suitable for use-cases in text and image generation.
It’s clear that responses from LLMs are indeed not mystifying, but rather mathematical. However, how can you train an LLM beyond its original programming?
In-context learning
The most common way to ask an LLM to complete a task is to use prompt engineering.
Many users interact with LLMs similar to the way they would with a search engine. Users may ask a simple question in a short and concise query. However, prompts can become much more complex and powerful in order to fully leverage an LLM’s capabilities.
The technique for prompting an LLM for more specific results based upon examples is called in-context learning.
Providing contextual data
In-context learning is a technique that uses conditioning for prompting an LLM with instructions to demonstrate how a task should be completed.
It is performed by crafting a more detailed prompt and including background contextual information about the task.
For example, if the task is asking the LLM to choose a suitable car for a family purchase, the prompt could provide a list of detailed car descriptions and their fact sheets, followed by the query.
The LLM can utilize data provided as context within the prompt in order to answer a question.

Zero-shot prompting
In many cases, just providing a little context along with your query can result in good answer. This is called zero-shot (or no-shot) prompting.
Consider the case of translating a word from English to Spanish. Most default trained models can perform this type of simple translation without needing examples.
Zero-shot prompting is the most convenient way to interact with LLMs since it does not require long or extensive prompts.
Sometimes, you need to go a bit deeper.
Few-shot prompting
Translating words might be relatively easy for an LLM to perform. However, some tasks require a little more prompting by providing examples.
In few-shot prompting, examples are given to the LLM to demonstrate what type of output you’re interested in from a given input.
For example, consider the task of returning a list of the top 10 financial stocks, ranked according to their year-to-date earnings. The output should be provided in comma-delimited format for importing into a spreadsheet.
You could certainly try no-shot prompting and hope that the LLM responds with a correct output that can be imported into Excel. However, the response might result in plain text without commas, or perhaps separated by other characters instead.
Specifically formatted output
When you expect a specific response format from an LLM, it becomes all the more important to provide examples through few-shot prompting.
In the example of a comma-separated list of financial stocks, you will likely get far better results by providing examples for how a comma-separated result should be returned.
AAPL, 214.29, MSFT, 446.34, AMZN, 182.81
NVDA, 135.38, TSLA, 184.48
Through experiments with accuracy on prompt engineering, it is believed that few-shot prompting improves overall results over no-shot.
Slow down and think harder
No-shot prompting and few-shot prompting are both techniques for creating more detailed prompts for an LLM.
However, when a task involves multiple steps and calculations, the LLM might need to slow down and think things through. Breaking down complex problems into smaller sub-problems is often the key behind many computational tasks.
Similarly, more complex LLM queries can be executed by digging deeper into the LLM, provoking a form of reasoning.
Chain-of-thought prompting
Chain-of-thought prompting is a technique for solving problems that require multiple steps or calculations.
In chain-of-thought prompting, the query is provided to the LLM along with a reasoning step. This is often combined with few-shot prompting, providing examples of how to perform any calculations as context.
If we are posing a mathematical word problem for the LLM to solve, we can prepare the LLM with a statement for how to go about determining the answer before it responds.
Solving a math problem
Consider the following math problem and associated prompt.
Q: Alice has 5 marbles. She buys 2 more cans of marbles. Each can has 3 marbles in it. How many marbles does she have now?
A: Alice started with 5 marbles. 2 cans of 3 marbles each is 6 marbles. 5 + 6 = 11. The answer is 11.
The user provides the LLM with a question-and-answer style. The question contains the math problem that is trying to be solved. The answer portion contains a thought process for the LLM to use as context in order to solve the problem.
By providing an example for solving a math problem like this, the LLM is better able to solve additional math problems by following the same contextual process.
Zero-shot chain-of-thought prompting
We may not always be able to provide examples for how to solve a computation problem.
In such cases, we can still leverage a chain-of-thought reasoning process, but without providing examples. This technique combines no-shot prompting with chain-of-thought to allow for the LLM to reason on its own.
Q: A store owner sells 16 pieces of fruit. Half of the fruit sold are apples, and half of the apples are green. How many green apples are there?
A: Let’s think step by step.
Notice how this example has not provided examples for how to reason about the calculation, but still asks for an answer. Instead, it prompts the LLM to think step by step to come up with actions to complete the task.
At this point, we’ve seen how to leverage prompt engineering with in-context prompting, no-shot & few-shot prompting, and chain-of-thought.
However, what happens when the context for a task is far too large to include in a single prompt?
Going beyond the prompt
Providing in-context information is a powerful way to extend the capabilities of an LLM prompt, but sometimes there is just too much context to fit all at once.
Imagine the case of providing the entire documentation for your company’s product so that you can ask the LLM how to use a certain feature. This information would not normally be a part of the LLM’s trained knowledge. If you were to append the entire documentation to your prompt, the length of the prompt could easily exceed size limitations and become far too long.
To go beyond simply appending text in a prompt, we need to tap into external data.
Retrieval augmented generation
Retrieval augmented generation (RAG) is a form of leveraging an LLM in connection with an external data source.
Examples of data can be company documentation, instruction manuals, private web pages, or even personal writing. Since this type of data would not normally be trained by the LLM, as it’s not publicly available on the Internet, it needs to be provided to the LLM using context.
This is done by querying an external database of knowledge, enriching the prompt, and then calling the LLM for a response.
Combining an external database
RAG works especially well for large repositories of document-based knowledge. It’s also a cost-effective way to train an LLM.
The way that the process works is by first storing the document corpus in an online database or other accessible location. When the user enters a query for the LLM, a search is performed for the most similar paragraphs from the document corpus. The results are retrieved, ranked by relation to the query, and finally appended to the LLM prompt.
This newly enriched prompt not only includes the user’s query, but also a paragraph from the external knowledge base as context.
Searching for similarity
At the most basic level, RAG can be performed by storing plain text documents and finding matches within the database.
However, a RAG process that uses natural language is often far too slow – especially for large numbers of documents. An additional complexity is the actual process of searching for similar sections from the documents that match the user’s query.
Rather than performing just a string comparison for words, we want to find semantic similarity based upon context and meaning too.
Embeddings
One way to solve the problem of finding the best matching documents to a user’s query is through the process of embeddings.
Embeddings are a numerical representation of text and are represented as a vector of floating-point values.
Each floating-point value represents a particular feature of the sentence. For example, one value might represent the word length. Another might represent “color”. Another value might represent “size”.
These different features in the vector can then be matched using similarity algorithms such as cosine similarity.
embeddings = [0.12, 0.45, 0.66, 0.21, 0.49, 0.98, 0.01, 0.05, …]
Converting text into numeric vectors
When using embeddings, the document corpus is initially ingested into a database with each sentence or paragraph, called chunks, converted into a numerical embedding vector.
When a user enters a query for the LLM, the query is converted into a numerical embedding vector and matched against the database of embeddings. The most similar result is returned, decoded back into text, and then appended onto the prompt as input to the LLM.
Ingestion
Documents => Chunks => Embedding => Database
Retrieval & Generation
Query => Embedding => Database => Top Results => (Result + Query) => Prompt => LLM
RAG with embeddings is a powerful method for extending the knowledge of an LLM without actually changing any of the LLM’s parameters.
Fine-tuning
So far, we’ve seen how to modify the behavior and knowledge of an LLM through prompt engineering. However, sometimes the LLM still results in poor performance for a task.
In cases where LLM performance is not acceptable, the model can be trained with custom data in a process called fine-tuning.
While prompting never actually modifies the internal parameters of the LLM, fine-tuning on the other hand does.
Permanent change in LLMs
Fine-tuning allows the user to provide a document corpus, often in the form of a spreadsheet with each row containing a “prompt” and “response” pair.
The LLM retrains on the provided data in order to learn each associated response for each prompt provided. In this manner, the original knowledge parameters of the LLM can be modified based upon the contents in the custom data. As such, fine-tuning permanently changes the model of the LLM.
One common use-case for fine-tuning is for adding safety restrictions into LLMs.
Building in safety controls
It’s well known that popular LLMs such as ChatGPT prevent users from asking about certain topics that may be illegal or harmful. Safety restrictions like this are often implemented through fine-tuning.
After a model is trained on general knowledge, an additional safety data set is provided that changes the responses for specific topics in queries. In this manner, certain responses from the LLM are effectively overwritten with safety-control responses.
The resulting newly trained model can then be tested by querying with phrases from the training set and measuring accuracy (the number of correct completions) and loss (the number of incorrect completions).

Ready to give it a try?
It’s quite amazing how we can interact with LLMs through simple natural language.
Through effective use of prompt engineering, context, and external knowledge, your results from AI can become even more powerful.
Now, it’s your turn! What can you build with an LLM?
About the Author
If you’ve enjoyed this article, please consider following me on Medium, Twitter, and my website to be notified of my future posts and research work.


















Books, Courses & Certifications
XPROMOS Launches Theia Institute™-Endorsed AI Fluency Program Offering Practitioner Certification Across Business Roles. Certified AI Training With Nod From Emerging Tech Think Tank Signals AI Fluency

“The XPROMOS AI training program delivers productivity gains beyond traditional business functions like IT, BI, and analytics. It democratizes AI productivity while increasing business ROI so that everyone wins,” said Executive Director, Todd A. Jacobs.
XPROMOS launches the first Theia Institute-endorsed certified AI training program designed to build AI fluency across non-technical teams in marketing, sales, HR, and finance. This premier global endorsement supports XPROMOS’ certified AI training that turns curiosity into capability by guiding participants to create scalable AI pilots that drive measurable value. The program aligns with the Washington DC-based nonprofit think tank’s mission of responsible, ethical, and practical AI adoption.

LOS ANGELES, CA – XPROMOS, a longtime leader in revenue‑driving strategy for enterprise brands, announces a premier global endorsement by Washington DC’s Theia Institute, a non-profit emerging technologies think tank shaping the standards of responsible AI use in business and policy. XPROMOS now offers an official Theia Institute certification for AI Fluency to qualified AI Training participants in their respective domains, including marketing, sales, operations, HR, finance, and more.
“This program turns dabblers into AI Fluents: people who use AI with clarity, not just curiosity,” said co-founder Yvette Brown.
“We built it to teach AI fluency and drive business value across functions, grounded in real understanding of governance, bias, and responsible use. Theia’s endorsement validates what we’ve always believed: AI literacy isn’t enough. If teams are going to extract real value responsibly, they need fluency, so they can think with the tech, not just use it.” Yvette Brown added, “When humans don’t understand AI’s capabilities and its limitations, they create unnecessary risk. This program changes that,” concluded Yvette Brown.
XPROMOS’ training is one of the first programs of its kind to be endorsed by Theia Institute, making it a trusted on‑ramp to strategic, ethical AI integration for non‑technical professionals. Participants who complete the program are awarded a credential that aligns directly with their business function, offering credibility, clarity, and a new kind of career capital.
“We’re proud to provide our most exclusive endorsement seal to XPROMOS’ AI training materials and educational methodology as it aligns with our think tank’s focus at the intersection of people and technology of preparing people for today’s evolving workplace.” stated Executive Director, Todd A. Jacobs.
“AI Fluency credentials ensure that people in marketing, sales, and HR also benefit from the growing workplace adoption of AI tools. The XPROMOS AI training program delivers productivity gains beyond traditional business functions like IT, BI, and analytics. It democratizes AI productivity while increasing business ROI so that everyone wins.”
— Todd A. Jacobs, Executive Director
Theia Institute™ Non-Profit Think Tank
The program was built for professionals navigating the AI shift without hype; early adopters in business units who need capability, not just content. With Theia’s endorsement, XPROMOS positions its AI training not just as a course, but as a new standard for responsible intelligence.
About XPROMOS
XPROMOS is an AI Fluency accelerator built by enterprise marketing veterans. With decades of experience driving results at scale, the company now helps professionals across industries gain the skills and strategic perspective needed to lead with AI. Through its Theia Institute-endorsed training, XPROMOS empowers creators and business leaders to earn real certification as Generative AI Practitioners, making them relevant, resilient, and ready for what’s next.
About Theia Institute
Theia Institute is a nonprofit AI governance, ethics, and cybersecurity think tank based in Washington, D.C., dedicated to advancing policy and decision-making through rigorous research and comprehensive analysis. Its commitment to an ethical, balanced, and unbiased approach sets it apart in the realm of business privacy, AI governance, and public policy.
Media Contact
Company Name: XPROMOS
Contact Person: Yvette Brown, XPROMOS Co-Founder
Email: Send Email
Phone: 7143370371
City: Laguna Hills
State: California
Country: United States
Website: https://xpromos.com
This post was co-written with Nick Frichette and Vijay George from Datadog.
As organizations increasingly adopt Amazon Bedrock for generative AI applications, protecting against misconfigurations that could lead to data leaks or unauthorized model access becomes critical. The AWS Generative AI Adoption Index, which surveyed 3,739 senior IT decision-makers across nine countries, revealed that 45% of organizations selected generative AI tools as their top budget priority in 2025. As more AWS and Datadog customers accelerate their adoption of AI, building AI security into existing processes will become essential, especially as more stringent regulations emerge. But looking at AI risks in a silo isn’t enough; AI risks must be contextualized alongside other risks such as identity exposures and misconfigurations. The combination of Amazon Bedrock and Datadog’s comprehensive security monitoring helps organizations innovate faster while maintaining robust security controls.
Amazon Bedrock delivers enterprise-grade security by incorporating built-in protections across data privacy, access controls, network security, compliance, and responsible AI safeguards. Customer data is encrypted both in transit using TLS 1.2 or above and at rest with AWS Key Management Service (AWS KMS), and organizations have full control over encryption keys. Data privacy is central: your input, prompts, and outputs are not shared with model providers nor used to train or improve foundation models (FMs). Fine-tuning and customizations occur on private copies of models, providing data confidentiality. Access is tightly governed through AWS Identity and Access Management (IAM) and resource-based policies, supporting granular authorization for users and roles. Amazon Bedrock integrates with AWS PrivateLink and supports virtual private cloud (VPC) endpoints for private, internal communication, so traffic doesn’t leave the Amazon network. The service complies with key industry standards such as ISO, SOC, CSA STAR, HIPAA eligibility, GDPR, and FedRAMP High, making it suitable for regulated industries. Additionally, Amazon Bedrock includes configurable guardrails to filter sensitive or harmful content and promote responsible AI use. Security is structured under the AWS Shared Responsibility Model, where AWS manages infrastructure security and customers are responsible for secure configurations and access controls within their Amazon Bedrock environment.
Building on these robust AWS security features, Datadog and AWS have partnered to provide a holistic view of AI infrastructure risks, vulnerabilities, sensitive data exposure, and other misconfigurations. Datadog Cloud Security employs both agentless and agent-based scanning to help organizations identify, prioritize, and remediate risks across cloud resources. This integration helps AWS users prioritize risks based on business criticality, with security findings enriched by observability data, thereby enhancing their overall security posture in AI implementations.
We’re excited to announce new security capabilities in Datadog Cloud Security that can help you detect and remediate Amazon Bedrock misconfigurations before they become security incidents. This integration helps organizations embed robust security controls and secure their use of the powerful capabilities of Amazon Bedrock by offering three critical advantages: holistic AI security by integrating AI security into your broader cloud security strategy, real-time risk detection through identifying potential AI-related security issues as they emerge, and simplified compliance to help meet evolving AI regulations with pre-built detections.
AWS and Datadog: Empowering customers to adopt AI securely
The partnership between AWS and Datadog is focused on helping customers operate their cloud infrastructure securely and efficiently. As organizations rapidly adopt AI technologies, extending this partnership to include Amazon Bedrock is a natural evolution. Amazon Bedrock is a fully managed service that makes high-performing FMs from leading AI companies and Amazon available through a unified API, making it an ideal starting point for Datadog’s AI security capabilities.
The decision to prioritize Amazon Bedrock integration is driven by several factors, including strong customer demand, comprehensive security needs, and the existing integration foundation. With over 900 integrations and a partner-built Marketplace, Datadog’s long-standing partnership with AWS and deep integration capabilities have helped Datadog quickly develop comprehensive security monitoring for Amazon Bedrock while using their existing cloud security expertise.
Throughout Q4 2024, Datadog Security Research observed increasing threat actor interest in cloud AI environments, making this integration particularly timely. By combining the powerful AI capabilities of AWS with Datadog’s security expertise, you can safely accelerate your AI adoption while maintaining robust security controls.
How Datadog Cloud Security helps secure Amazon Bedrock resources
After adding the AWS integration to your Datadog account and enabling Datadog Cloud Security, Datadog Cloud Security continuously monitors your AWS environment, identifying misconfigurations, identity risks, vulnerabilities, and compliance violations. These detections use the Datadog Severity Scoring system to prioritize them based on infrastructure context. The scoring considers a variety of variables, including if the resource is in production, is publicly accessible, or has access to sensitive data. This multi-layer analysis can help you reduce noise and focus your attention to the most critical misconfigurations by considering runtime behavior.
Partnering with AWS, Datadog is excited to offer detections for Datadog Cloud Security customers, such as:
- Amazon Bedrock custom models should not output model data to publicly accessible S3 buckets
- Amazon Bedrock custom models should not train from publicly writable S3 buckets
- Amazon Bedrock guardrails should have a prompt attack filter enabled and block prompt attacks at high sensitivity
- Amazon Bedrock agent guardrails should have the sensitive information filter enabled and block highly sensitive PII entities
Detect AI misconfigurations with Datadog Cloud Security
To understand how these detections can help secure your Amazon Bedrock infrastructure, let’s look at a specific use case, in which Amazon Bedrock custom models should not train from publicly writable Amazon Simple Storage Service (Amazon S3) buckets.
With Amazon Bedrock, you can customize AI models by fine-tuning on domain specific data. To do this, that data is stored in an S3 bucket. Threat actors are constantly evaluating the configuration of S3 buckets, looking for the potential to access sensitive data or even the ability to write to S3 buckets.
If a threat actor finds an S3 bucket that was misconfigured to permit public write access, and that same bucket contained data that was used to train an AI model, a bad actor could poison that dataset and introduce malicious behavior or output to the model. This is known as a data poisoning attack.
Normally, detecting these types of misconfigurations requires multiple steps: one to identify the S3 bucket misconfigured with write access, and one to identify that the bucket is being used by Amazon Bedrock. With Datadog Cloud Security, this detection is one of hundreds that are activated out of the box.
In the Datadog Cloud Security system, you can view this issue alongside surrounding infrastructure using Cloud Map. This provides live diagrams of your cloud architecture, as shown in the following screenshot. AI risks are then contextualized alongside sensitive data exposure, identity risks, vulnerabilities, and other misconfigurations to give you a 360-view of risks.

For example, you might see that your application is using Anthropic’s Claude 3.7 on Amazon Bedrock and accessing training or prompt data stored in an S3 bucket that also has public write access. This could inadvertently impact model integrity by introducing unapproved data to the large language model (LLM), so you will want to update this configuration. Though basic, the first step for most security initiatives is identifying the issue. With agentless scanning, Datadog scans your AWS environment at intervals between 15 minutes and 2 hours, so users can identify misconfigurations as they are introduced to their environment. The next step is to remediate this risk. Datadog Cloud Security offers automatically generated remediation guidance, specifically for each risk (see the following screenshot). You will get a step-by-step explanation of how to fix each finding. In this situation, we can remediate this issue by modifying the S3 bucket’s policy, helping prevent public write access. You can do this directly in AWS, create a JIRA ticket, or use the built-in workflow automation tools. From here, you can apply remediation steps directly within Datadog and confirm that the misconfiguration has been resolved.

Resolving this issue will positively impact your compliance posture, as illustrated by the posture score in Datadog Cloud Security, helping teams meet internal benchmarks and regulatory standards. Teams can also create custom frameworks or iterate on existing ones for tailored compliance controls.

As generative AI is embraced across industries, the regulatory environment will evolve. Datadog will continue partnering with AWS to expand their detection library and support secure AI adoption and compliance.
How Datadog Cloud Security detects misconfigurations in your cloud environment
You can deploy Datadog Cloud Security either with the Datadog agent, agentlessly, or both to maximize security coverage in your cloud environment. Datadog customers can start monitoring their AWS accounts for misconfigurations by first adding the AWS integration to Datadog. This enables Datadog to crawl cloud resources in customer AWS accounts.
As the Datadog system finds resources, it runs through a catalog of hundreds of out-of-the-box detection rules against these resources, looking for misconfigurations and threat paths that adversaries can exploit.
Secure your AI infrastructure with Datadog
Misconfigurations in AI systems can be risky, but with the right tools, you can have the visibility and context needed to manage them. With Datadog Cloud Security, teams gain visibility into these risks, detect threats early, and remediate issues with confidence. In addition, Datadog has also released numerous agentic AI security features, designed to help teams gain visibility into the health and security of critical AI workload, which includes new announcements made to Datadog’s LLM observability features.
Lastly, Datadog announced Bits AI Security Analyst alongside other Bits AI agents at DASH. Included as part of Cloud SIEM, Bits is an agentic AI security analyst that automates triage for AWS CloudTrail signals. Bits investigates each alert like a seasoned analyst: pulling in relevant context from across your Datadog environment, annotating key findings, and offering a clear recommendation on whether the signal is likely benign or malicious. By accelerating triage and surfacing real threats faster, Bits helps reduce mean time to remediation (MTTR) and frees analysts to focus on important threat hunting and response initiatives. This helps across different threats, including AI-related threats.
To learn more about how Datadog helps secure your AI infrastructure, see Monitor Amazon Bedrock with Datadog or check out our security documentation. If you’re not already using Datadog, you can get started with Datadog Cloud Security with a 14-day free trial.
About the Authors
 Nina Chen is a Customer Solutions Manager at AWS specializing in leading software companies to use the power of the AWS Cloud to accelerate their product innovation and growth. With over 4 years of experience working in the strategic independent software vendor (ISV) vertical, Nina enjoys guiding ISV partners through their cloud transformation journeys, helping them optimize their cloud infrastructure, driving product innovation, and delivering exceptional customer experiences.
Nina Chen is a Customer Solutions Manager at AWS specializing in leading software companies to use the power of the AWS Cloud to accelerate their product innovation and growth. With over 4 years of experience working in the strategic independent software vendor (ISV) vertical, Nina enjoys guiding ISV partners through their cloud transformation journeys, helping them optimize their cloud infrastructure, driving product innovation, and delivering exceptional customer experiences.
 Sujatha Kuppuraju is a Principal Solutions Architect at AWS, specializing in cloud and generative AI security. She collaborates with software companies’ leadership teams to architect secure, scalable solutions on AWS and guide strategic product development. Using her expertise in cloud architecture and emerging technologies, Sujatha helps organizations optimize offerings, maintain robust security, and bring innovative products to market in an evolving tech landscape.
Sujatha Kuppuraju is a Principal Solutions Architect at AWS, specializing in cloud and generative AI security. She collaborates with software companies’ leadership teams to architect secure, scalable solutions on AWS and guide strategic product development. Using her expertise in cloud architecture and emerging technologies, Sujatha helps organizations optimize offerings, maintain robust security, and bring innovative products to market in an evolving tech landscape.
 Nick Frichette is a Staff Security Researcher for Cloud Security Research at Datadog.
Nick Frichette is a Staff Security Researcher for Cloud Security Research at Datadog.
 Vijay George is a Product Manager for AI Security at Datadog.
Vijay George is a Product Manager for AI Security at Datadog.
Books, Courses & Certifications
Set up custom domain names for Amazon Bedrock AgentCore Runtime agents
When deploying AI agents to Amazon Bedrock AgentCore Runtime (currently in preview), customers often want to use custom domain names to create a professional and seamless experience.
By default, AgentCore Runtime agents use endpoints like https://bedrock-agentcore.{region}.amazonaws.com/runtimes/{EncodedAgentARN}/invocations.
In this post, we discuss how to transform these endpoints into user-friendly custom domains (like https://agent.yourcompany.com) using Amazon CloudFront as a reverse proxy. The solution combines CloudFront, Amazon Route 53, and AWS Certificate Manager (ACM) to create a secure, scalable custom domain setup that works seamlessly with your existing agents.
Benefits of Amazon Bedrock AgentCore Runtime
If you’re building AI agents, you have probably wrestled with hosting challenges: managing infrastructure, handling authentication, scaling, and maintaining security. Amazon Bedrock AgentCore Runtime helps address these problems.
Amazon Bedrock AgentCore Runtime is framework agnostic; you can use it with LangGraph, CrewAI, Strands Agents, or custom agents you have built from scratch. It supports extended execution times up to 8 hours, perfect for complex reasoning tasks that traditional serverless functions can’t handle. Each user session runs in its own isolated microVM, providing security that’s crucial for enterprise applications.
The consumption-based pricing model means you only pay for what you use, not what you provision. And unlike other hosting solutions, Amazon Bedrock AgentCore Runtime includes built-in authentication and specialized observability for AI agents out of the box.
Benefits of custom domains
When using Amazon Bedrock AgentCore Runtime with Open Authorization (OAuth) authentication, your applications make direct HTTPS requests to the service endpoint. Although this works, custom domains offer several benefits:
- Custom branding – Client-side applications (web browsers, mobile apps) display your branded domain instead of AWS infrastructure details in network requests
- Better developer experience – Development teams can use memorable, branded endpoints instead of copying and pasting long AWS endpoints across code bases and configurations
- Simplified maintenance – Custom domains make it straightforward to manage endpoints when deploying multiple agents or updating configurations across environments
Solution overview
In this solution, we use CloudFront as a reverse proxy to transform requests from your custom domain into Amazon Bedrock AgentCore Runtime API calls. Instead of using the default endpoint, your applications can make requests to a user-friendly URL like https://agent.yourcompany.com/.
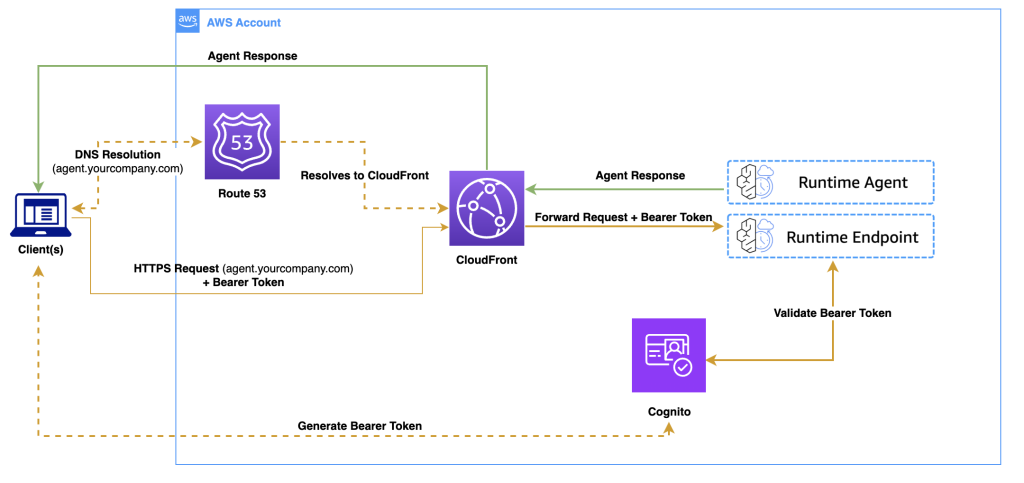
The following diagram illustrates the solution architecture.
The workflow consists of the following steps:
- A client application authenticates with Amazon Cognito and receives a bearer token.
- The client makes an HTTPS request to your custom domain.
- Route 53 resolves the DNS request to CloudFront.
- CloudFront forwards the authenticated request to the Amazon Bedrock Runtime agent.
- The agent processes the request and returns the response through the same path.
You can use the same CloudFront distribution to serve both your frontend application and backend agent endpoints, avoiding cross-origin resource sharing (CORS) issues because everything originates from the same domain.
Prerequisites
To follow this walkthrough, you must have the following in place:
Although Amazon Bedrock AgentCore Runtime can be in other supported AWS Regions, CloudFront requires SSL certificates to be in the us-east-1 Region.
You can choose from the following domain options:
- Use an existing domain – Add a subdomain like
agent.yourcompany.com - Register a new domain – Use Route 53 to register a domain if you don’t have one
- Use the default URL from CloudFront – No domain registration or configuration required
Choose the third option if you want to test the solution quickly before setting up a custom domain.
Create an agent with inbound authentication
If you already have an agent deployed with OAuth authentication, you can skip to the next section to set up the custom domain. Otherwise, follow these steps to create a new agent using Amazon Cognito as your OAuth provider:
- Create a new directory for your agent with the following structure:
- Create the main agent code in
agent_example.py:
- Add dependencies to
requirements.txt:
- Run the following commands to create an Amazon Cognito user pool and test user:
- Deploy the agent using the Amazon Bedrock AgentCore command line interface (CLI) provided by the starter toolkit:
Make note of your agent runtime Amazon Resource Name (ARN) after deployment. You will need this for the custom domain configuration.
For additional examples and details, see Authenticate and authorize with Inbound Auth and Outbound Auth.
Set up the custom domain solution
Now let’s implement the custom domain solution using the AWS CDK. This section shows you how to create the CloudFront distribution that proxies your custom domain requests to Amazon Bedrock AgentCore Runtime endpoints.
- Create a new directory and initialize an AWS CDK project:
- Encode the agent ARN and prepare the CloudFront origin configuration:
If your frontend application runs on a different domain than your agent endpoint, you must configure CORS headers. This is common if your frontend is hosted on a different domain (for example, https://app.yourcompany.com calling https://agent.yourcompany.com), or if you’re developing locally (for example, http://localhost:3000 calling your production agent endpoint).
- To handle CORS requirements, create a CloudFront response headers policy:
- Create a CloudFront distribution to act as a reverse proxy for your agent endpoints:
Set cache_policy=CachePolicy.CACHING_DISABLED to make sure your agent responses remain dynamic and aren’t cached by CloudFront.
- If you’re using a custom domain, add an SSL certificate and DNS configuration to your stack:
The following code is the complete AWS CDK stack that combines all the components:
- Configure the AWS CDK
appentry point:
Deploy your custom domain
Now you can deploy the solution and verify it works with both custom and default domains. Complete the following steps:
- Update the following values in
agentcore_custom_domain_stack.py:- Your Amazon Bedrock AgentCore Runtime ARN
- Your domain name (if using a custom domain)
- Your hosted zone ID (if using a custom domain)
- Deploy using the AWS CDK:
Test your endpoint
After you deploy the custom domain, you can test your endpoints using either the custom domain or the CloudFront default domain.First, get a JWT token from Amazon Cognito:
Use the following code to test with your custom domain:
Alternatively, use the following code to test with the CloudFront default domain:
Considerations
As you implement this solution in production, the following are some important considerations:
- Cost implications – CloudFront adds costs for data transfer and requests. Review Amazon CloudFront pricing to understand the impact for your usage patterns.
- Security enhancements – Consider implementing the following security measures:
- AWS WAF rules to help protect against common web exploits.
- Rate limiting to help prevent abuse.
- Geo-restrictions if your agent should only be accessible from specific Regions.
- Monitoring – Enable CloudFront access logs and set up Amazon CloudWatch alarms to monitor error rates, latency, and request volume.
Clean up
To avoid ongoing costs, delete the resources when you no longer need them:
You might need to manually delete the Route 53 hosted zones and ACM certificates from their respective service consoles.
Conclusion
In this post, we showed you how to create custom domain names for your Amazon Bedrock AgentCore Runtime agent endpoints using CloudFront as a reverse proxy. This solution provides several key benefits: simplified integration for development teams, custom domains that align with your organization, cleaner infrastructure abstraction, and straightforward maintenance when endpoints need updates. By using CloudFront as a reverse proxy, you can also serve both your frontend application and backend agent endpoints from the same domain, avoiding common CORS challenges.
We encourage you to explore this solution further by adapting it to your specific needs. You might want to enhance it with additional security features, set up monitoring, or integrate it with your existing infrastructure.
To learn more about building and deploying AI agents, see the Amazon Bedrock AgentCore Developer Guide. For advanced configurations and best practices with CloudFront, refer to the Amazon CloudFront documentation. You can find detailed information about SSL certificates in the AWS Certificate Manager documentation, and domain management in the Amazon Route 53 documentation.
Amazon Bedrock AgentCore is currently in preview and subject to change. Standard AWS pricing applies to additional services used, such as CloudFront, Route 53, and Certificate Manager.
About the authors
 Rahmat Fedayizada is a Senior Solutions Architect with the AWS Energy and Utilities team. He works with energy companies to design and implement scalable, secure, and highly available architectures. Rahmat is passionate about translating complex technical requirements into practical solutions that drive business value.
Rahmat Fedayizada is a Senior Solutions Architect with the AWS Energy and Utilities team. He works with energy companies to design and implement scalable, secure, and highly available architectures. Rahmat is passionate about translating complex technical requirements into practical solutions that drive business value.
![]() Paras Bhuva is a Senior Manager of Solutions Architecture at AWS, where he leads a team of solution architects helping energy customers innovate and accelerate their transformation. Having started as a Solution Architect in 2012, Paras is passionate about architecting scalable solutions and building organizations focused on application modernization and AI initiatives.
Paras Bhuva is a Senior Manager of Solutions Architecture at AWS, where he leads a team of solution architects helping energy customers innovate and accelerate their transformation. Having started as a Solution Architect in 2012, Paras is passionate about architecting scalable solutions and building organizations focused on application modernization and AI initiatives.
-
Tools & Platforms3 weeks ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy1 month ago
Ethics & Policy1 month agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Business2 days ago
Business2 days agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-

 Events & Conferences3 months ago
Events & Conferences3 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers2 months ago
Jobs & Careers2 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Funding & Business2 months ago
Funding & Business2 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries
-

 Education2 months ago
Education2 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi
-

 Mergers & Acquisitions2 months ago
Mergers & Acquisitions2 months agoDonald Trump suggests US government review subsidies to Elon Musk’s companies