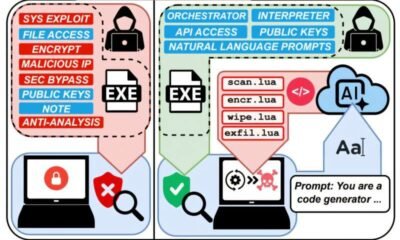
Johns Hopkins computer scientists have discovered that artificial intelligence tools like ChatGPT are creating a digital language divide, amplifying the dominance of English and other commonly spoken languages while sidelining minority languages.
“We were trying to ask, are multilingual LLMs truly multilingual? Are they breaking language barriers and democratizing access to information?” says first author Nikhil Sharma, a Ph.D. student in the Whiting School of Engineering’s Department of Computer Science.
To find out, Sharma and his team—including Kenton Murray, a research scientist in the Human Language Technology Center of Excellence, and Ziang Xiao, an assistant professor of computer science—first looked at coverage of the Israel–Gaza and Russia–Ukraine wars and identified several types of information across the news articles: common knowledge, contradicting assertions, facts exclusive to certain documents, and information that was similar, but presented with very different perspectives.
Informed by these design principles, the team created two sets of fake articles—one with “truthful” information and one with “alternative,” conflicting information. The documents featured coverage of a festival—with differing dates, names, and statistics—and a war, which was reported on with biased perspectives. The pieces were written in high-resource languages, such as English, Chinese, and German, as well as lower-resource languages, including Hindi and Arabic.
The team then asked LLMs from big-name developers like OpenAI, Cohere, Voyage AI, and Anthropic to answer several types of queries, such as choosing one of two contradictory facts presented in different languages, more general questions about the topic at hand, queries about facts that are present in only one article, and topical questions phrased with clear bias.
The researchers found that both in retrieving the information from the documents and in generating an answer to a user’s query, the LLMs preferred information in the language of the question itself.
“This means if I have an article in English that says some Indian political figure—let’s call them Person X—is bad, but I have an article in Hindi that says Person X is good, then the model will tell me they’re bad if I’m asking in English, but that they’re good if I’m asking in Hindi,” Sharma explains.
The researchers then wondered what would happen if there was no article in the language of the query, which is common for speakers of low-resource languages. The team’s results show that LLMs will generate answers based on information found only in higher-resource languages, ignoring other perspectives.
“For instance, if you’re asking about Person X in Sanskrit—a less commonly spoken language in India—the model will default to information pulled from English articles, even though Person X is a figure from India,” Sharma says.
Furthermore, the computer scientists found a troubling trend: English dominates. They point to this as evidence of linguistic imperialism—when information from higher-resource languages is amplified more often, potentially overshadowing or distorting narratives from low-resource ones.
To summarize the study’s results, Sharma offers a hypothetical scenario: Three ChatGPT users ask about the longstanding India–China border dispute. A Hindi-speaking user would see answers shaped by Indian sources, while a Chinese-speaking user would get answers reflecting only Chinese perspectives.
“But say there’s an Arabic-speaking user, and there are no documents in Arabic about this conflict,” Sharma says. “That user will get answers from the American English perspective, because that is the highest-resource language out there. So all three users will come away with completely different understandings of the conflict.”
As a result, the researchers label current multilingual LLMs “faux polyglots” that fail to break language barriers, keeping users trapped in language-based filter bubbles.
“The information you’re exposed to determines how you vote and the policy decisions you make,” Sharma says. “If we want to shift the power to the people and enable them to make informed decisions, we need AI systems capable of showing them the whole truth with different perspectives. This becomes especially important when covering information about conflicts between regions that speak different languages, like the Israel–Gaza and Russian–Ukraine wars—or even the tariffs between China and the U.S.”
To mitigate this information disparity in LLMs, the Hopkins team plans to build a dynamic benchmark and datasets to help guide future model development. In the meantime, it encourages the larger research community to look at the effects of different model training strategies, data mixtures, and retrieval-augmented generation architectures.
The researchers also recommend collecting diverse perspectives from multiple languages, issuing warnings to users who may be falling into confirmatory query-response behavior, and developing programs to increase information literacy around conversational search to reduce over-trust in and over-reliance on LLMs.
“Concentrated power over AI technologies poses substantial risks, as it enables a few individuals or companies to manipulate the flow of information, thus facilitating mass persuasion, diminishing the credibility of these systems, and exacerbating the spread of misinformation,” Sharma says. “As a society, we need users to get the same information regardless of their language and background.”
More information:
Nikhil Sharma et al, Faux Polyglot: A Study on Information Disparity in Multilingual Large Language Models, Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) (2025). DOI: 10.18653/v1/2025.naacl-long.411
Citation:
A digital language divide: How multilingual AI often reinforces bias (2025, September 2)
retrieved 2 September 2025
from https://techxplore.com/news/2025-09-digital-language-multilingual-ai-bias.html
This document is subject to copyright. Apart from any fair dealing for the purpose of private study or research, no
part may be reproduced without the written permission. The content is provided for information purposes only.
FILE PHOTO: Nvidia said it would launch a new AI chip by the end of next year, designed to handle complex functions like creating videos and software.
| Photo Credit: Reuters
Nvidia said on Tuesday it would launch a new artificial intelligence chip by the end of next year, designed to handle complex functions such as creating videos and software.
The chips, dubbed “Rubin CPX”, will be built on Nvidia’s next-generation Rubin architecture — the successor to its latest “Blackwell” technology that marked the company’s foray into providing larger processing systems.
As AI systems grow more sophisticated, tackling data-heavy tasks such as “vibe coding” or AI-assisted code generation and video generation, the industry’s processing needs are intensifying.
AI models can take up to 1 million tokens to process an hour of video content — a challenging feat for traditional GPUs, the company said. Tokens refer to the units of data processed by an AI model.
To remedy this, Nvidia will integrate various steps of the drawn-out processing sequence such as video decoding, encoding, and inference — when AI models produce an output — together into its new chip.
Investing $100 million in these new systems could help generate $5 billion in token revenue, the company said, as Wall Street increasingly focuses on the return from pouring hundreds of billions of dollars into AI hardware.
The race to develop the most sophisticated AI systems has made Nvidia the world’s most valuable company, commanding a dominant share of the AI chip market with its pricey, top-of-the-line processors.
As AI evolves from simple automation to sophisticated autonomous agents, HR executives face one of the most significant workforce transformations in modern history. The challenge isn’t just understanding the technology — it’s navigating culture change, skills development and workforce planning when AI capabilities double every six months.
Simon Brown, EY’s global learning and development leader, has spent nearly 2 years helping the firm’s 400,000 employees prepare for an AI-driven future. With his past experience as chief learning officer at Novartis and his work with Microsoft, Brown offers critical insights on positioning organizations for success in an autonomous AI world.
What are the top questions C-suite executives need to ask their teams about agentic AI initiatives?
Are people aware of what’s possible with agents? Are we experimenting to find ways agents can help us? Do we have the skills and knowledge to do that properly?
But the most critical question is: Is the culture there to support this? Most organizations are feeling their way through which tools work, what the use cases are, what drives value. There’s a lot of ambiguity. Some organizations manage well through uncertainty; others need clear answers and can’t fail — that’s hard when there’s no clear path and people need to experiment.
How can leaders assess whether their organization has the right culture for agentic AI?
Look at how AI tools like Microsoft Copilot are being embraced. Are people experimenting and finding productivity value, or are they threatened and not using it? If leaders are role modeling use and encouraging their people, that comes through in adoption metrics. Culture shows through communication, leadership role modeling, skill building and time to learn.
What are common blind spots when executives evaluate AI readiness?
Two major issues. First, executives often aren’t aware of what’s possible with the latest AI systems due to security constraints and procurement processes that create 6-to-12-month lags.
Second, the speed of improvement. If I tried an AI tool a month ago versus today, I may get a completely different experience because the underlying model improved. Copilot now has GPT-5 access, giving it a significant overnight boost. Leaders need to shift from thinking about AI as static systems upgraded annually to something constantly improving and doubling in power every six months.
How should leaders approach change management with AI agents?
Change management is essential. When OpenAI releases new capabilities, everyone has access to the technology. Whether organizations get the benefit depends entirely on change management — culture, experimentation ability, skills and whether people feel encouraged rather than fearful. We’re addressing this through AI badges, curricula, enterprise-wide learning — all signaling the organization values building AI skills.
What’s your framework for evaluating whether AI investment will drive real business value?
I think about three loops. First, can I use this to do current tasks cheaper, faster, better? Second, can I realize new value — serving more customers, new products and services? Third, if everyone’s using AI, how do we reinvent ourselves to create new value? It’s moving beyond just doing the same things better to what AI helps us do differently.
How should HR leaders rethink workforce planning given AI’s potential to automate job functions?
Understand which skills AI will impact, which remain uniquely human and what new roles get created. The World Economic Forum predicts significant reduction in certain roles but net increase overall. We’re seeing new, more sophisticated roles created that move people higher up the value chain.
From HR’s perspective, are our processes still fit for AI speed? How are we incentivizing reskilling? Are we ensuring learning access and time? How are we signaling which skills are in demand versus at risk of automation?
How should HR measure success after implementing agentic AI?
Tie back to why it was implemented — business value. Use similar metrics as before but look at what changed. Maybe same output but cheaper, faster, better. Or new capabilities — our third-party risk team uses agents to provide much more extensive supplier analysis than before. Same team size, more client value.
What’s your timeline perspective on when agentic AI becomes competitive necessity versus advantage?
That’s the ultimate question. I’m amazed daily by what I achieve using AI and agents. ChatGPT-5’s recent capabilities are mind-blowing, suggesting dramatic impact quickly. But when deep AI experts have vastly different views — from AGI around the corner to decades away — it’s understandable why leaders struggle to navigate this landscape.