AI Research
Generating audio for video – Google DeepMind

Acknowledgements
This work was made possible by the contributions of: Ankush Gupta, Nick Pezzotti, Pavel Khrushkov, Tobenna Peter Igwe, Kazuya Kawakami, Mateusz Malinowski, Jacob Kelly, Yan Wu, Xinyu Wang, Abhishek Sharma, Ali Razavi, Eric Lau, Serena Zhang, Brendan Shillingford, Yelin Kim, Eleni Shaw, Signe Nørly, Andeep Toor, Irina Blok, Gregory Shaw, Pen Li, Scott Wisdom, Aren Jansen, Zalán Borsos, Brian McWilliams, Salah Zaiem, Marco Tagliasacchi, Ron Weiss, Manoj Plakal, Hakan Erdogan, John Hershey, Jeff Donahue, Vivek Kumar, and Matt Sharifi.
We extend our gratitude to Benigno Uria, Björn Winckler, Charlie Nash, Conor Durkan, Cătălina Cangea, David Ding, Dawid Górny, Drew Jaegle, Ethan Manilow, Evgeny Gladchenko, Felix Riedel, Florian Stimberg, Henna Nandwani, Jakob Bauer, Junlin Zhang, Luis C. Cobo, Mahyar Bordbar, Miaosen Wang, Mikołaj Bińkowski, Sander Dieleman, Will Grathwohl, Yaroslav Ganin, Yusuf Aytar, and Yury Sulsky.
Special thanks to Aäron van den Oord, Andrew Zisserman, Tom Hume, RJ Mical, Douglas Eck, Nando de Freitas, Oriol Vinyals, Eli Collins, Koray Kavukcuoglu and Demis Hassabis for their insightful guidance and support throughout the research process.
We also acknowledge the many other individuals who contributed across Google DeepMind and our partners at Google.

Where some see artificial intelligence (AI) flattening human creativity, Kaili Meyer (‘17 journalism and mass communication) sees an opportunity to prove that authenticity and individuality are still the heart of communication.
As founder of the sales and web copywriting company Reveal Studio Co., Meyer built her business and later included AI as an extension of her work. She developed tools that train AI to preserve the integrity of an individual’s tone.
Wellness to print
Meyer began her undergraduate studies at Iowa State in kinesiology but realized she had a talent for writing.
“I thought about what I was really good at, and the answer was writing,” Meyer said.
She pivoted to a journalism and mass communication major, with a minor in psychology. Her passion for writing led her to work on student publications in the Greenlee School of Journalism and Communication, where she founded a health and wellness magazine.
That drive to build something from scratch set the tone for her entrepreneurial approach to her business.
Building an AI copywriting company
After graduation, Meyer joined Principal Financial in institutional investing, where she translated complex economic reports into accessible updates for stakeholders. She gained business skills – but her creative energy was missing.
By freelancing on the side for content, copy and magazines, she eventually replaced her salary, left corporate life, and began the process of launching her own company.
Reveal Studio Co started out with direct client interactions, grew to include a template shop, and now includes AI tools.
In 2023, the AI chatbot ChatGPT had its one-year anniversary with over 1.7 billion users. As generative AI went mainstream and pushed into more areas, Meyer was skeptical of the rapidly growing adoption of AI in society. She began to flag AI-written content everywhere and set out to prove that it could never replicate the human voice.
“In doing so, I proved myself wrong,” Meyer said.
As Meyer researched AI, she realized it could be tailored to one’s own persona.
She developed The Complete AI Copy Buddy, a training manual that teaches an AI platform to mimic an individual’s style. By completing a template and submitting it to an AI source, users can acquire anything they need – from content ideas to full pieces such as social posts, emails, web copy and business collateral – all specifically tailored to their audience, brand, and voice.
The launch of the training manual earned $60,000 in two weeks, more than her first year’s corporate salary.
That success propelled Meyer into creating The Sales & Copy Bestie, a custom Generative Pre-trained Transformer (GPT) built from her knowledge in psychology and copywriting. Contractors support her work while she keeps the control and direction.
“If people are going to use AI – which they are – I might as well help them do it better,” she said.
Meyer prioritizes sales psychology, understanding how neuroscience drives decisions and taking that information to form effective and persuasive messages.
“Copy is messaging intended to get somebody to take action,” Meyer explained. “If I don’t understand what makes someone’s brain want to take action, then I can’t write really good copy.”
Meyer’s clients range from educators and creative service providers to lawyers, accountants, and business owners seeking sharper websites, sales pages, or email funnels.
Meyers’ vision of success
Meyer attributes her growth to persistence and a pure mindset.
“I don’t view anything as failure. Everything is just a step closer to where you want to be,” she said.
This year, Meyer plans to balance her entrepreneurial success with her creative side. She is finishing a poetry book, sketching artwork, and outlining her first novel.
“I’ve spent eight years building a really successful business,” Meyer said. “Now I want to build a life outside of work that fulfills me.”
This post was written with Mohamed Hossam of Brightskies.
Research universities engaged in large-scale AI and high-performance computing (HPC) often face significant infrastructure challenges that impede innovation and delay research outcomes. Traditional on-premises HPC clusters come with long GPU procurement cycles, rigid scaling limits, and complex maintenance requirements. These obstacles restrict researchers’ ability to iterate quickly on AI workloads such as natural language processing (NLP), computer vision, and foundation model (FM) training. Amazon SageMaker HyperPod alleviates the undifferentiated heavy lifting involved in building AI models. It helps quickly scale model development tasks such as training, fine-tuning, or inference across a cluster of hundreds or thousands of AI accelerators (NVIDIA GPUs H100, A100, and others) integrated with preconfigured HPC tools and automated scaling.
In this post, we demonstrate how a research university implemented SageMaker HyperPod to accelerate AI research by using dynamic SLURM partitions, fine-grained GPU resource management, budget-aware compute cost tracking, and multi-login node load balancing—all integrated seamlessly into the SageMaker HyperPod environment.
Solution overview
Amazon SageMaker HyperPod is designed to support large-scale machine learning operations for researchers and ML scientists. The service is fully managed by AWS, removing operational overhead while maintaining enterprise-grade security and performance.
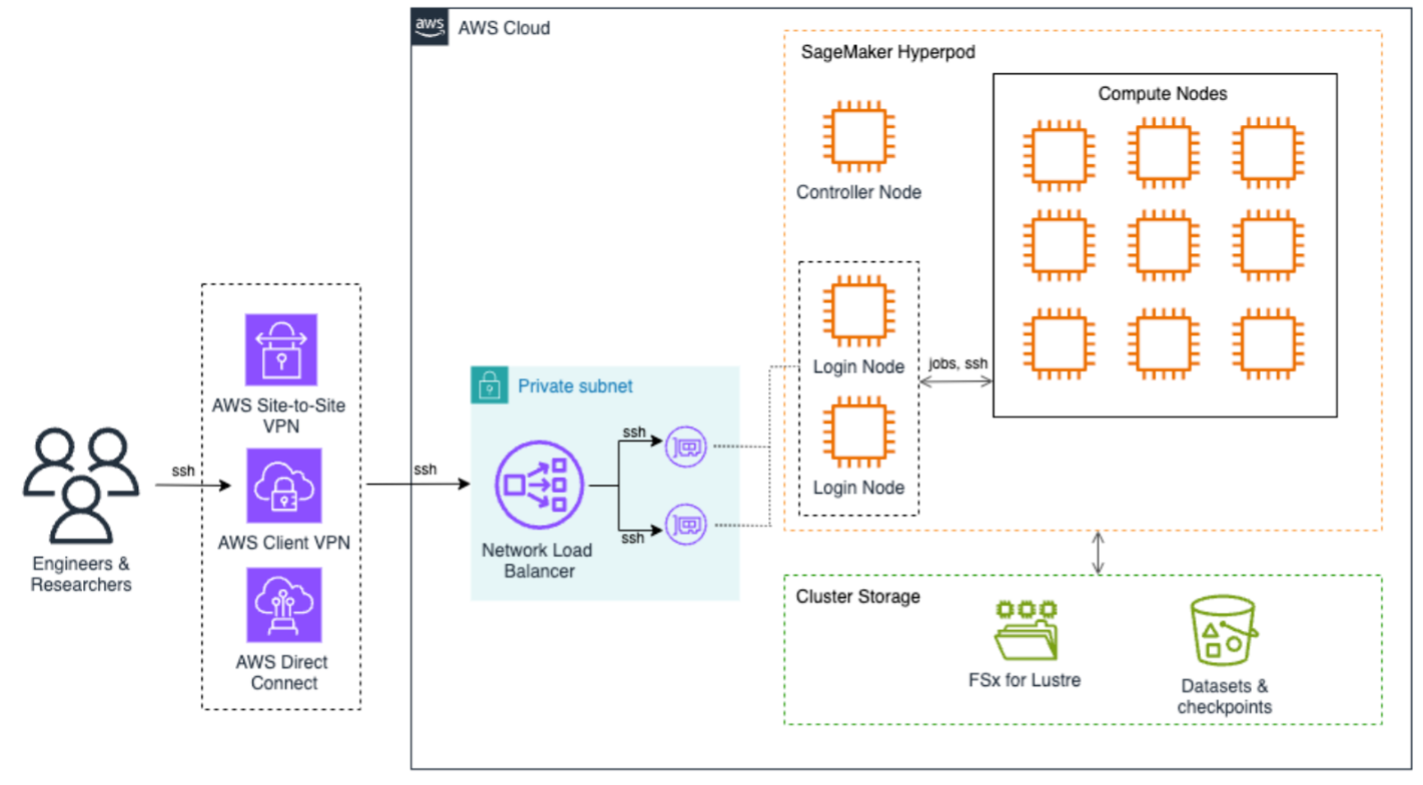
The following architecture diagram illustrates how to access SageMaker HyperPod to submit jobs. End users can use AWS Site-to-Site VPN, AWS Client VPN, or AWS Direct Connect to securely access the SageMaker HyperPod cluster. These connections terminate on the Network Load Balancer that efficiently distributes SSH traffic to login nodes, which are the primary entry points for job submission and cluster interaction. At the core of the architecture is SageMaker HyperPod compute, a controller node that orchestrates cluster operations, and multiple compute nodes arranged in a grid configuration. This setup supports efficient distributed training workloads with high-speed interconnects between nodes, all contained within a private subnet for enhanced security.
The storage infrastructure is built around two main components: Amazon FSx for Lustre provides high-performance file system capabilities, and Amazon S3 for dedicated storage for datasets and checkpoints. This dual-storage approach provides both fast data access for training workloads and secure persistence of valuable training artifacts.
The implementation consisted of several stages. In the following steps, we demonstrate how to deploy and configure the solution.
Prerequisites
Before deploying Amazon SageMaker HyperPod, make sure the following prerequisites are in place:
- AWS configuration:
- The AWS Command Line Interface (AWS CLI) configured with appropriate permissions
- Cluster configuration files prepared:
cluster-config.jsonandprovisioning-parameters.json
- Network setup:
- An AWS Identity and Management (IAM) role with permissions for the following:
Launch the CloudFormation stack
We launched an AWS CloudFormation stack to provision the necessary infrastructure components, including a VPC and subnet, FSx for Lustre file system, S3 bucket for lifecycle scripts and training data, and IAM roles with scoped permissions for cluster operation. Refer to the Amazon SageMaker HyperPod workshop for CloudFormation templates and automation scripts.
Customize SLURM cluster configuration
To align compute resources with departmental research needs, we created SLURM partitions to reflect the organizational structure, for example NLP, computer vision, and deep learning teams. We used the SLURM partition configuration to define slurm.conf with custom partitions. SLURM accounting was enabled by configuring slurmdbd and linking usage to departmental accounts and supervisors.
To support fractional GPU sharing and efficient utilization, we enabled Generic Resource (GRES) configuration. With GPU stripping, multiple users can access GPUs on the same node without contention. The GRES setup followed the guidelines from the Amazon SageMaker HyperPod workshop.
Provision and validate the cluster
We validated the cluster-config.json and provisioning-parameters.json files using the AWS CLI and a SageMaker HyperPod validation script:
Then we created the cluster:
Implement cost tracking and budget enforcement
To monitor usage and control costs, each SageMaker HyperPod resource (for example, Amazon EC2, FSx for Lustre, and others) was tagged with a unique ClusterName tag. AWS Budgets and AWS Cost Explorer reports were configured to track monthly spending per cluster. Additionally, alerts were set up to notify researchers if they approached their quota or budget thresholds.
This integration helped facilitate efficient utilization and predictable research spending.
Enable load balancing for login nodes
As the number of concurrent users increased, the university adopted a multi-login node architecture. Two login nodes were deployed in EC2 Auto Scaling groups. A Network Load Balancer was configured with target groups to route SSH and Systems Manager traffic. Lastly, AWS Lambda functions enforced session limits per user using Run-As tags with Session Manager, a capability of Systems Manager.
For details about the full implementation, see Implementing login node load balancing in SageMaker HyperPod for enhanced multi-user experience.
Configure federated access and user mapping
To facilitate secure and seamless access for researchers, the institution integrated AWS IAM Identity Center with their on-premises Active Directory (AD) using AWS Directory Service. This allowed for unified control and administration of user identities and access privileges across SageMaker HyperPod accounts. The implementation consisted of the following key components:
- Federated user integration – We mapped AD users to POSIX user names using Session Manager
run-astags, allowing fine-grained control over compute node access - Secure session management – We configured Systems Manager to make sure users access compute nodes using their own accounts, not the default
ssm-user - Identity-based tagging – Federated user names were automatically mapped to user directories, workloads, and budgets through resource tags
For full step-by-step guidance, refer to the Amazon SageMaker HyperPod workshop.
This approach streamlined user provisioning and access control while maintaining strong alignment with institutional policies and compliance requirements.
Post-deployment optimizations
To help prevent unnecessary consumption of compute resources by idle sessions, the university configured SLURM with Pluggable Authentication Modules (PAM). This setup enforces automatic logout for users after their SLURM jobs are complete or canceled, supporting prompt availability of compute nodes for queued jobs.
The configuration improved job scheduling throughput by freeing idle nodes immediately and reduced administrative overhead in managing inactive sessions.
Additionally, QoS policies were configured to control resource consumption, limit job durations, and enforce fair GPU access across users and departments. For example:
- MaxTRESPerUser – Makes sure GPU or CPU usage per user stays within defined limits
- MaxWallDurationPerJob – Helps prevent excessively long jobs from monopolizing nodes
- Priority weights – Aligns priority scheduling based on research group or project
These enhancements facilitated an optimized, balanced HPC environment that aligns with the shared infrastructure model of academic research institutions.
Clean up
To delete the resources and avoid incurring ongoing charges, complete the following steps:
- Delete the SageMaker HyperPod cluster:
- Delete the CloudFormation stack used for the SageMaker HyperPod infrastructure:
This will automatically remove associated resources, such as the VPC and subnets, FSx for Lustre file system, S3 bucket, and IAM roles. If you created these resources outside of CloudFormation, you must delete them manually.
Conclusion
SageMaker HyperPod provides research universities with a powerful, fully managed HPC solution tailored for the unique demands of AI workloads. By automating infrastructure provisioning, scaling, and resource optimization, institutions can accelerate innovation while maintaining budget control and operational efficiency. Through customized SLURM configurations, GPU sharing using GRES, federated access, and robust login node balancing, this solution highlights the potential of SageMaker HyperPod to transform research computing, so researchers can focus on science, not infrastructure.
For more details on making the most of SageMaker HyperPod, check out the SageMaker HyperPod workshop and explore further blog posts about SageMaker HyperPod.
About the authors
 Tasneem Fathima is Senior Solutions Architect at AWS. She supports Higher Education and Research customers in the United Arab Emirates to adopt cloud technologies, improve their time to science, and innovate on AWS.
Tasneem Fathima is Senior Solutions Architect at AWS. She supports Higher Education and Research customers in the United Arab Emirates to adopt cloud technologies, improve their time to science, and innovate on AWS.
 Mohamed Hossam is a Senior HPC Cloud Solutions Architect at Brightskies, specializing in high-performance computing (HPC) and AI infrastructure on AWS. He supports universities and research institutions across the Gulf and Middle East in harnessing GPU clusters, accelerating AI adoption, and migrating HPC/AI/ML workloads to the AWS Cloud. In his free time, Mohamed enjoys playing video games.
Mohamed Hossam is a Senior HPC Cloud Solutions Architect at Brightskies, specializing in high-performance computing (HPC) and AI infrastructure on AWS. He supports universities and research institutions across the Gulf and Middle East in harnessing GPU clusters, accelerating AI adoption, and migrating HPC/AI/ML workloads to the AWS Cloud. In his free time, Mohamed enjoys playing video games.
This post is co-written by Jake Friedman, President + Co-founder of Wildlife.
Amazon Nova is enhancing sports fan engagement through an immersive Formula 1 (F1)-inspired experience that turns traditional spectators into active participants. This post explores the Real-Time Race Track (RTRT), an interactive experience built using Amazon Nova in Amazon Bedrock, that lets fans design, customize, and share their own racing circuits. We highlight how generative AI capabilities come together to deliver strategic racing insights such as pit timing and tire choices, and interactive features like an AI voice assistant and a retro-style racing poster.
Evolving fan expectations and the technical barriers to real-time, multimodal engagement
Today’s sports audiences expect more than passive viewing—they want to participate, customize, and share. As fan expectations evolve, delivering engaging and interactive experiences has become essential to keeping audiences invested. Static digital content no longer holds attention; fans are drawn to immersive formats that make it possible to influence or co-create aspects of the event. For brands and rights holders, this shift presents both an opportunity and a challenge: how to deliver dynamic, meaningful engagement at scale. Delivering this level of interactivity comes with a unique set of technical challenges. It requires support for multiple modalities—text, speech, image, and data—working together in real time to create a seamless and immersive experience. Because fan-facing experiences are often offered for free, cost-efficiency becomes critical to sustain engagement at scale. And with users expecting instant responses, maintaining low-latency performance across interactions is essential to avoid disrupting the experience.
Creating immersive fan engagement with the RTRT using Amazon Nova
To foster an engaging and immersive experience, we developed the Real-Time Race Track, allowing F1 fans to design their own custom racing circuit using Amazon Nova. You can draw your track in different lengths and shapes while receiving real-time AI recommendations to modify your racing conditions. You can choose any location around the world for your race track and Amazon Nova Pro will use it to generate your track’s name and simulate realistic track conditions using that region’s weather and climate data. When your track is complete, Amazon Nova Pro analyzes the track to produce metrics like top speed and projected lap time, and offers two viable race strategies focused on tire management. You can also consult with Amazon Nova Sonic, a speech-to-speech model, for strategic track design recommendations. The experience culminates with Amazon Nova Canvas generating a retro-inspired racing poster of your custom track design that you can share or download. The following screenshots show some examples of the RTRT interface.
 |
Amazon Nova models are cost-effective and deliver among the best price-performance in their respective class, helping enterprises create scalable fan experiences while managing costs effectively. With fast speech processing and high efficiency, Amazon Nova provides seamless, real-time, multimodal interactions that meet the demands of interactive fan engagement. Additionally, Amazon Nova comes with built-in controls to maintain the safe and responsible use of AI. Combining comprehensive capabilities, cost-effectiveness, low latency, and trusted reliability, Amazon Nova is the ideal solution for applications requiring real-time, dynamic engagement.
Prompts, inputs, and system design behind the RTRT experience
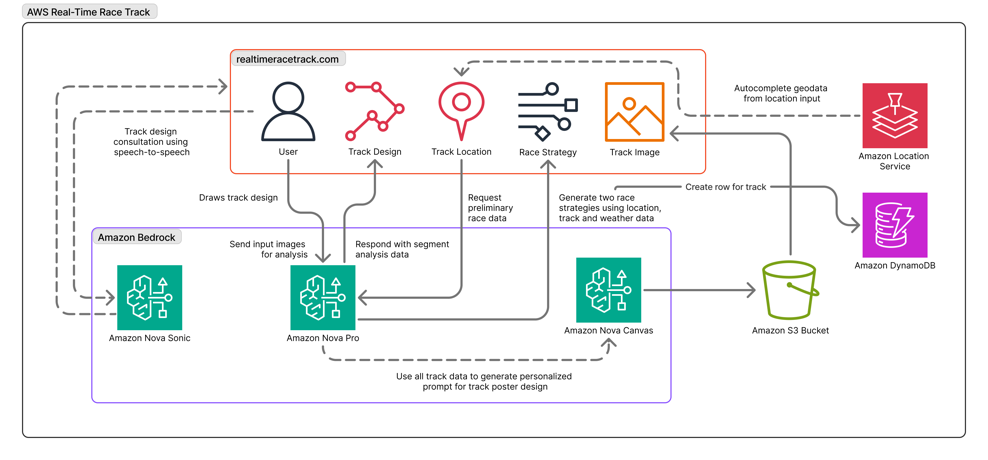
The RTRT uses the multimodal capabilities of Amazon Nova Pro to effectively lead users from a single line path drawing to a fully viable race track design, including strategic racing recommendations and a bold visual representation of their circuit in the style of a retro racing poster.
The following diagram gives an overview of the system architecture.
Prompt engineering plays a crucial role in delivering structured output that can flow seamlessly into the UI, which has been optimized for at-a-glance takeaways that use Amazon Nova Pro to quickly analyze multiple data inputs to accelerate users’ decision making. In the RTRT, this extends to the input images provided to Amazon Nova Pro for vision analysis. Each time the user adds new segments to their racing circuit, a version of the path is relayed to Amazon Nova Pro with visible coordinate markers that produce accurate path analysis (see the following screenshot) and corresponding output data, which can be visually represented back to users with color-coded track sectors.
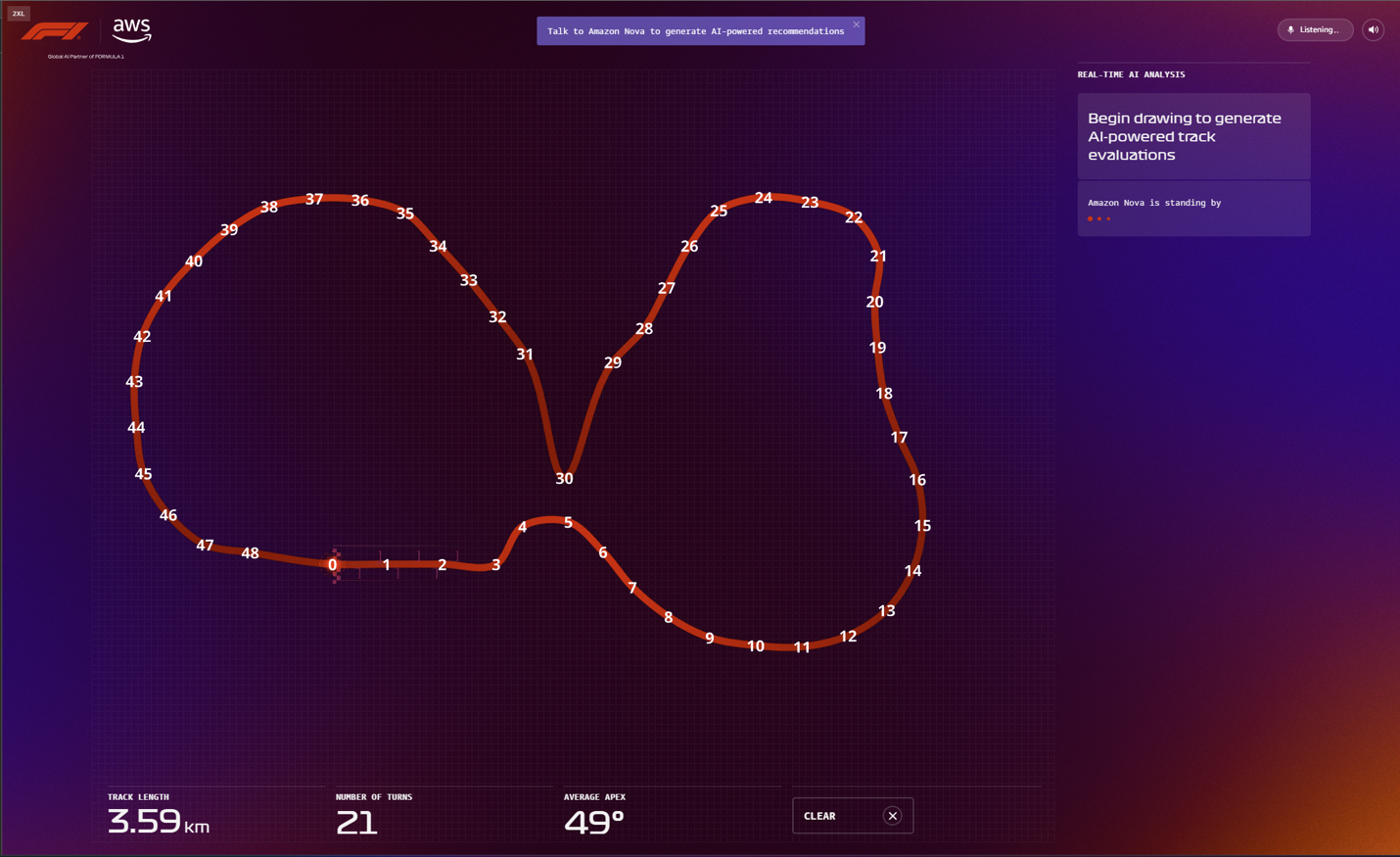
This is paired with multiple system prompts to define the role of Amazon Nova Pro at each stage of the app, as well as to return responses that are ready to be consumed by the front end.
The following is a prompt example:
The prompts also use sets of examples to produce consistent results across a diverse range of possible track designs and locations:
This is also a key stage in which to employ responsible use of AI, instructing the model not to generate content that might infringe on existing race tracks or other copyrighted material.
These considerations are essential when working with creative models like Amazon Nova Canvas. Race cars commonly feature liveries that contain a dozen or more sponsor logos. To avoid concern, and to provide the cleanest, most aesthetically appealing retro racing poster designs, Amazon Nova Canvas was given a range of conditioning images that facilitate vehicle accuracy and consistency. The images work in tandem with our prompt for a bold illustration style featuring cinematic angles.
The following is a prompt example:
The following images show the output.
 |
 |
Conclusion
The Real-Time Race Track showcases how generative AI can deliver personalized, interactive moments that resonate with modern sports audiences. Amazon Nova models power each layer of the experience, from speech and image generation to strategy and analysis, delivering rich, low-latency interactions at scale. This collaboration highlights how brands can use Amazon Nova to build tailored and engaging experiences.
About the authors
 Raechel Frick is a Sr. Product Marketing Manager at AWS. With over 20 years of experience in the tech industry, she brings a customer-first approach and growth mindset to building integrated marketing programs.
Raechel Frick is a Sr. Product Marketing Manager at AWS. With over 20 years of experience in the tech industry, she brings a customer-first approach and growth mindset to building integrated marketing programs.
 Anuj Jauhari is a Sr. Product Marketing Manager at AWS, enabling customers to innovate and achieve business impact with generative AI solutions built on Amazon Nova models.
Anuj Jauhari is a Sr. Product Marketing Manager at AWS, enabling customers to innovate and achieve business impact with generative AI solutions built on Amazon Nova models.
 Jake Friedman is the President and Co-founder at Wildlife, where he leads a team launching interactive experiences and content campaigns for global brands. His work has been recognized with the Titanium Grand Prix at the Cannes Lions International Festival of Creativity for “boundary-busting, envy-inspiring work that marks a new direction for the industry and moves it forward.”
Jake Friedman is the President and Co-founder at Wildlife, where he leads a team launching interactive experiences and content campaigns for global brands. His work has been recognized with the Titanium Grand Prix at the Cannes Lions International Festival of Creativity for “boundary-busting, envy-inspiring work that marks a new direction for the industry and moves it forward.”
-

 Business1 week ago
Business1 week agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-
Tools & Platforms3 weeks ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy1 month ago
Ethics & Policy1 month agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences4 months ago
Events & Conferences4 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers2 months ago
Jobs & Careers2 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Education2 months ago
Education2 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Funding & Business2 months ago
Funding & Business2 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi
-

 Education2 months ago
Education2 months agoMacron says UK and France have duty to tackle illegal migration ‘with humanity, solidarity and firmness’ – UK politics live | Politics