AI Research
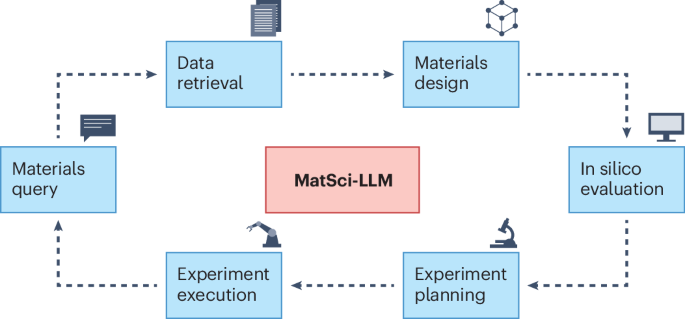
Enabling large language models for real-world materials discovery
Zhang, C., Zhang, C., Zhang, M. & Kweon, I. S. Text-to-image diffusion model in generative AI: a survey. Preprint at https://doi.org/10.48550/arXiv.2303.07909 (2023).
He, K. et al. A survey of large language models for healthcare: from data, technology, and applications to accountability and ethics. Inf. Fusion 118, 102963 (2025).
Dahl, M., Magesh, V., Suzgun, M. & Ho, D. E. Large legal fictions: profiling legal hallucinations in large language models. J. Legal Anal. 16, 64–93 (2024).
Wu, S. et al. BloombergGPT: a large language model for finance. Preprint at https://doi.org/10.48550/arXiv.2303.17564 (2023).
Fan, A. et al. Large language models for software engineering: survey and open problems. In 2023 IEEE/ACM International Conference on Software Engineering: Future of Software Engineering (ICSE-FoSE) 31–53 (IEEE, 2023).
Jablonka, K. M. et al. 14 examples of how LLMs can transform materials science and chemistry: a reflection on a large language model hackathon. Digit. Discov. 2, 1233–1250 (2023).
Miret, S. et al. Perspective on AI for accelerated materials design at the AI4Mat-2023 workshop at NeurIPS 2023. Digit. Discov. 3, 1081–1085 (2024).
Lin, Z. et al. Evolutionary-scale prediction of atomic-level protein structure with a language model. Science 379, 1123–1130 (2023).
Hsu, C. et al. Learning inverse folding from millions of predicted structures. In Proc. 39th International Conference on Machine Learning Vol. 162 (eds Chaudhuri, K. et al.) 8946–8970 (PMLR, 2022).
Xu, M., Yuan, X., Miret, S. & Tang, J. ProtST: multi-modality learning of protein sequences and biomedical texts. In International Conference on Machine Learning 38749–38767 (PMLR, 2023).
Cui, H. et al. scGPT: toward building a foundation model for single-cell multi-omics using generative AI. Nat. Methods 21, 1470–1480 (2024).
Dalla-Torre, H. et al. Nucleotide Transformer: building and evaluating robust foundation models for human genomics. Nat. Methods 22, 287–297 (2025).
Trewartha, A. et al. Quantifying the advantage of domain-specific pre-training on named entity recognition tasks in materials science. Patterns 3, 100488 (2022).
Gupta, T., Zaki, M., Krishnan, N. A. & Mausam, M. MatsSciBERT: a materials domain language model for text mining and information extraction. npj Computat. Mater. 8, 102 (2022).
Huang, S. & Cole, J. M. BatteryBERT: a pretrained language model for battery database enhancement. J. Chem. Inf. Model. 62, 6365–6377 (2022).
Devlin, J., Chang, M.-W., Lee, K. & Toutanova, K. BERT: pre-training of deep bidirectional transformers for language understanding. In Proc. 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (eds Burstein, J. et al.) Vol. 1, 4171–4186 (ACL, 2019).
Song, Y., Miret, S. & Liu, B. MatSci-NLP: evaluating scientific language models on materials science language tasks using text-to-schema modeling. In Proc. 61st Annual Meeting of the Association for Computational Linguistics (eds Rogers, A. et al.) Vol. 1, 3621–3639 (ACL, 2023).
Song, Y., Miret, S., Zhang, H. & Liu, B. HoneyBee: progressive instruction finetuning of large language models for materials science. In Findings of the Association for Computational Linguistics: EMNLP 2023 (eds Bouamor, H. et al.) 5724–5739 (ACL, 2023).
Xie, T. et al. DARWINseries: domain specific large language models for natural science. Preprint at https://doi.org/10.48550/arXiv.2308.13565 (2023).
Zaki, M., Jayadeva, J., Mausam, M. & Krishnan, N. A. MaScQA: investigating materials science knowledge of large language models. Digit. Discov. 3, 313–327 (2024).
Bran, M. et al. Augmenting large language models with chemistry tools. Nat. Mach. Intell. 6, 525–535 (2024).
Boiko, D. A., MacKnight, R., Kline, B. & Gomes, G. Autonomous chemical research with large language models. Nature 624, 570–578 (2023).
Gupta, T. et al. DiSCoMaT: distantly supervised composition extraction from tables in materials science articles. In Proc. 61st Annual Meeting of the Association for Computational Linguistics (eds Rogers, A. et al.) Vol. 1, 13465–13483 (ACL, 2023).
Zhang, H., Song, Y., Hou, Z., Miret, S. & Liu, B. HoneyComb: a flexible LLM-based agent system for materials science. In Findings of the Association for Computational Linguistics: EMNLP 2024 (eds Al-Onaizan, Y. et al.) 3369–3382 (ACL, 2024).
Achiam, J. et al. GPT-4 technical report. Preprint at https://doi.org/10.48550/arXiv.2303.08774 (2023).
Dubey, A. et al. The LLaMA 3 herd of models. Preprint at https://doi.org/10.48550/arXiv.2407.21783 (2024).
Computer, T. RedPajama: an open dataset for training large language models. GitHub https://github.com/togethercomputer/RedPajama-Data (2023).
Wei, J. et al. Chain-of-thought prompting elicits reasoning in large language models. Adv. Neural Inf. Process. Syst. 35, 24824–24837 (2022).
BehnamGhader, P., Miret, S. & Reddy, S. Can retriever-augmented language models reason? The blame game between the retriever and the language model. In Findings of the Association for Computational Linguistics: EMNLP 2023 (eds Bouamor, H. et al.) 15492–15509 (ACL, 2023).
Buehler, M. J. Generative retrieval-augmented ontologic graph and multiagent strategies for interpretive large language model-based materials design. ACS Eng. Au. 4, 241–277 (2023).
Yoshikawa, N. et al. Large language models for chemistry robotics. Auton. Robots 47, 1057–1086 (2023).
Ghafarollahi, A. & Buehler, M. J. Automating alloy design and discovery with physics-aware multimodal multiagent AI. Proc. Natl Acad. Sci. USA 122, e2414074122 (2024).
Ghafarollahi, A. & Buehler, M. J. SciAgents: automating scientific discovery through bioinspired multi‐agent intelligent graph reasoning. Adv. Mater. 37, 2413523 (2024).
Ghafarollahi, A. & Buehler, M. J. ProtAgents: protein discovery via large language model multi-agent collaborations combining physics and machine learning. Digit. Discov. 3, 1389–1409 (2024).
Mishra, V. et al. Foundational large language models for materials research. Preprint at https://doi.org/10.48550/arXiv.2412.09560 (2024).
White, A. D. et al. Assessment of chemistry knowledge in large language models that generate code. Digital Discovery 2, 368–376 (2023).
Mirza, A. et al. A framework for evaluating the chemical knowledge and reasoning abilities of large language models against the expertise of chemists. Nat. Chem. https://doi.org/10.1038/s41557-025-01815-x (2025).
Zhang, D. et al. DPA-2: a large atomic model as a multi-task learner. npj Comput. Mater. 10, 293 (2024).
Jain, A. et al. The Materials Project: a materials genome approach to accelerating materials innovation. APL Mater. 1, 011002, (2013).
Lee, K. L. K. et al. MatSciML: a broad, multi-task benchmark for solid-state materials modeling. In AI for Accelerated Materials Design—NeurIPS 2023 Workshop (NeurIPS, 2023).
Hellwich, K.-H., Hartshorn, R. M., Yerin, A., Damhus, T. & Hutton, A. T. Brief guide to the nomenclature of organic chemistry (IUPAC technical report). Pure Appl. Chem. 92, 527–539 (2020).
Kearnes, S. M. et al. The Open Reaction Database. J. Am. Chem. Soc. 143, 18820–18826 (2021).
Mercado, R., Kearnes, S. M. & Coley, C. W. Data sharing in chemistry: lessons learned and a case for mandating structured reaction data. J. Chem. Inf. Model. 63, 4253–4265 (2023).
Zhao, J., Huang, S. & Cole, J. M. OpticalBERT and OpticalTable-SQA: text-and table-based language models for the optical-materials domain. J. Chem. Inf. Model. 63, 1961–1981 (2023).
Zhao, J. & Cole, J. M. A database of refractive indices and dielectric constants auto-generated using chemdataextractor. Sci. Data 9, 192 (2022).
Schilling-Wilhelmi, M. et al. From text to insight: large language models for chemical data extraction. Chem. Soc. Rev. 54, 1125–1150 (2025).
Hira, K., Zaki, M., Sheth, D. B., Mausam, M. & Anoop Krishnan, N. M. Reconstructing materials tetrahedron: challenges in materials information extraction. In AI for Accelerated Materials Design—NeurIPS 2023 Workshop (NeurIPS, 2023).
Olivetti, E. A. et al. Data-driven materials research enabled by natural language processing and information extraction. Appl. Phys. Rev. 7, 041317 (2020).
Jensen, Z. et al. Discovering relationships between osdas and zeolites through data mining and generative neural networks. ACS Cent. Sci. 7, 858–867 (2021).
Kim, E. et al. Materials synthesis insights from scientific literature via text extraction and machine learning. Chem. Mater. 29, 9436–9444 (2017).
Kim, E. et al. Inorganic materials synthesis planning with literature-trained neural networks. J. Chem. Inf. Model. 60, 1194–1201 (2020).
Wu, Y. et al. An empirical study on challenging math problem solving with GPT-4. Preprint at https://doi.org/10.48550/arXiv.2306.01337 (2023).
Alampara, N., Miret, S. & Jablonka, K. M. MatText: do language models need more than text & scale for materials modeling? In AI for Accelerated Materials Design-Vienna 2024 (NeurIPS, 2024).
Luu, R. K. & Buehler, M. J. BioinspiredLLM: conversational large language model for the mechanics of biological and bio-inspired materials. Adv. Sci. 11, 2306724 (2024).
Lu, W., Luu, R. K. & Buehler, M. J. Fine-tuning large language models for domain adaptation: exploration of training strategies, scaling, model merging and synergistic capabilities. npj Computat. Mater. 11, 84 (2025).
Dagdelen, J. et al. Structured information extraction from scientific text with large language models. Nat. Commun. 15, 1418 (2024).
Ramos, M. C., Collison, C. J. & White, A. D. A review of large language models and autonomous agents in chemistry. Chem. Sci. 16, 2514–2572 (2025).
Lála, J. et al. PaperQA: retrieval-augmented generative agent for scientific research. Preprint at https://doi.org/10.48550/arXiv.2312.07559 (2023).
Skarlinski, M. D. et al. Language agents achieve superhuman synthesis of scientific knowledge. Preprint at https://doi.org/10.48550/arXiv.2409.13740 (2024).
Ramos, M. C., Michtavy, S. S., Porosoff, M. D. & White, A. D. Bayesian optimization of catalysts with in-context learning. Preprint at https://doi.org/10.48550/arXiv.2304.05341 (2023).
Sung, Y.-L. et al. An empirical study of multimodal model merging. In Findings of the Association for Computational Linguistics: EMNLP 2023 (eds Bouamor, H. et al.) 1563–1575 (ACL, 2023).
Buehler, M. J. Cephalo: multi-modal vision-language models for bio-inspired materials analysis and design. Adv. Funct. Mater. 34, 2409531 (2024).
Buehler, M. J. Accelerating scientific discovery with generative knowledge extraction, graph-based representation, and multimodal intelligent graph reasoning. Mach. Learn. Sci. Technol. 5, 035083 (2024).
Buehler, M. J. MeLM, a generative pretrained language modeling framework that solves forward and inverse mechanics problems. J. Mech. Phys. Solids 181, 105454 (2023).
Gruver, N. et al. Fine-tuned language models generate stable inorganic materials as text. In AI for Accelerated Materials Design—NeurIPS 2023 Workshop (NeurIPS, 2023).
Ding, Q., Miret, S. & Liu, B. MatExpert: decomposing materials discovery by mimicking human experts. In 13th International Conference on Learning Representations (ICLR, 2025).
Alampara, N. et al. Probing the limitations of multimodal language models for chemistry and materials research. Preprint at https://doi.org/10.48550/arXiv.2411.16955 (2024).
Guan, X. et al. rStar-Math: small LLMs can master math reasoning with self-evolved deep thinking. Preprint at https://doi.org/10.48550/arXiv.2501.04519 (2025).
Qin, Y. et al. O1 replication journey: a strategic progress report—part 1. Preprint at https://doi.org/10.48550/arXiv.2410.18982 (2024).
Lambert, N. et al. Tulu 3: pushing frontiers in open language model post-training. Preprint at https://doi.org/10.48550/arXiv.2411.15124 (2024).
Brown, B. et al. Large language monkeys: scaling inference compute with repeated sampling. Preprint at https://doi.org/10.48550/arXiv.2407.21787 (2024).
Narayanan, S. et al. Aviary: training language agents on challenging scientific tasks. Preprint at https://doi.org/10.48550/arXiv.2412.21154 (2024).
Mysore, S. et al. The materials science procedural text corpus: annotating materials synthesis procedures with shallow semantic structures. In Proc. 13th Linguistic Annotation Workshop 56–64 (ACL, 2019).
Völker, C., Rug, T., Jablonka, K. M. & Kruschwitz, S. LLMs can design sustainable concrete—a systematic benchmark. Preprint at Res. Sq. https://doi.org/10.21203/rs.3.rs-3913272/v1 (2024).
Brinson, L. C. et al. Polymer nanocomposite data: curation, frameworks, access, and potential for discovery and design. ACS Macro Lett. 9, 1086–1094 (2020).
Circi, D., Khalighinejad, G., Chen, A., Dhingra, B. & Brinson, L. C. How well do large language models understand tables in materials science? Integr. Mater. Manuf. Innov. 13, 669–687 (2024).
Polak, M. P. & Morgan, D. Extracting accurate materials data from research papers with conversational language models and prompt engineering. Nat. Commun. 15, 1569 (2024).
Kristiadi, A. et al. A sober look at llms for material discovery: are they actually good for Bayesian optimization over molecules? In 41st International Conference on Machine Learning 25603–25622 (PMLR, 2024).
Vasudevan, R. K., Orozco, E. & Kalinin, S. V. Discovering mechanisms for materials microstructure optimization via reinforcement learning of a generative model. Mach. Learn. Sci. Technol. 3, 04LT03 (2022).
Mandal, I. et al. Autonomous microscopy experiments through large language model agents. Preprint at https://doi.org/10.48550/arXiv.2501.10385 (2024).
Liu, Y., Checa, M. & Vasudevan, R. K. Synergizing human expertise and AI efficiency with language model for microscopy operation and automated experiment design. Mach. Learn. Sci. Technol. 5, 02LT01 (2024).
Buehler, M. J. MechGPT, a language-based strategy for mechanics and materials modeling that connects knowledge across scales, disciplines, and modalities. Appl. Mech. Rev. 76, 021001 (2024).
Venugopal, V. & Olivetti, E. MatKG: an autonomously generated knowledge graph in material science. Sci. Data 11, 217 (2024).
Flam-Shepherd, D. & Aspuru-Guzik, A. Language models can generate molecules, materials, and protein binding sites directly in three dimensions as XYZ, CIF, and PDB files. Preprint at https://doi.org/10.48550/arXiv.2305.05708 (2023).
Zeni, C. et al. A generative model for inorganic materials design. Nature 639, 624–632 (2025).
Govindarajan, P. et al. Learning conditional policies for crystal design using offline reinforcement learning. In AI for Accelerated Materials Design—NeurIPS 2023 Workshop (NeurIPS, 2023).
Levy, D. et al. SymmCD: symmetry-preserving crystal generation with diffusion models. In 13th International Conference on Learning Representations (ICLR, 2024).
Rubungo, A. N., Arnold, C., Rand, B. P. & Dieng, A. B. LLM-Prop: predicting physical and electronic properties of crystalline solids from their text descriptions. Preprint at https://doi.org/10.48550/arXiv.2310.14029 (2023).
Sim, M. et al. ChemOS 2.0: an orchestration architecture for chemical self-driving laboratories. Matter 7, 2959–2977 (2024).
Szymanski, N. J. et al. An autonomous laboratory for the accelerated synthesis of novel materials. Nature 624, 86–91 (2023).

















Delaware has announced a partnership with OpenAI on its certification program, which aims to build AI skills in the state among students and workers alike.
The Diamond State’s officials have been exploring how to move forward responsibly with AI, establishing a generative AI policy this year to help inform safe use among public-sector employees, which one official said was the “first step” to informing employees about acceptable AI use. The Delaware Artificial Intelligence Commission also took action this year to advance a “sandbox” environment for testing new AI technologies including agentic AI; the sandbox model has proven valuable for governments across the U.S., from San Jose to Utah.
The OpenAI Certification Program aims to address a common challenge for states: fostering AI literacy in the workforce and among students. It builds on the OpenAI Academy, an open-to-all initiative launched in an effort to democratize knowledge about AI. The initiative’s expansion will enable the company to offer certifications based upon levels of AI fluency, from the basics to prompt engineering. The company is committing to certifying 10 million Americans by 2030.
“As a former teacher, I know how important it is to give our students every advantage,” Gov. Matt Meyer said in a statement. “As Governor, I know our economy depends on workers being ready for the jobs of the future, no matter their zip code.”
The partnership will start with early-stage programming across schools and workforce training programs in Delaware in an effort led by the state’s new Office of Workforce Development, which was created earlier this year. The office will work with schools, colleges and employers in coming months to identify pilot opportunities for this programming, to ensure that every community in the state has access.
Delaware will play a role in shaping how certifications are rolled out at the community level because the program is in its early stages and Delaware is one of the first states to join, per the state’s announcement.
“We’ll obviously use AI to teach AI: anyone will be able to prepare for the certification in ChatGPT’s Study mode and become certified without leaving the app,” OpenAI’s CEO of Applications Fidji Simo said in an article.
This announcement comes on the heels of the federal AI Action Plan’s release. The plan, among other content potentially limiting states’ regulatory authority, aims to invest in skills training and AI literacy.
“By boosting AI literacy and investing in skills training, we’re equipping hardworking Americans with the tools they need to lead and succeed in this new era,” U.S. Secretary of Labor Lori Chavez-DeRemer said in a statement about the federal plan.
Delaware’s partnership with OpenAI for its certification program mirrors this goal, equipping Delawareans with the knowledge to use these tools — in the classroom, in their careers and beyond.
AI skills are a critical part of broader digital literacy efforts; today, “even basic digital skills include AI,” National Digital Inclusion Alliance Director Angela Siefer said earlier this summer.
AI Research
The End of Chain-of-Thought? CoreThink and University of California Researchers Propose a Paradigm Shift in AI Reasoning

For years, the race in artificial intelligence has been about scale. Bigger models, more GPUs, longer prompts. OpenAI, Anthropic, and Google have led the charge with massive large language models (LLMs), reinforcement learning fine-tuning, and chain-of-thought prompting—techniques designed to simulate reasoning by spelling out step-by-step answers.
But a new technical white paper titled CoreThink: A Symbolic Reasoning Layer to reason over Long Horizon Tasks with LLMs from CoreThink AI and University of California researchers argues that this paradigm may be reaching its ceiling. The authors make a provocative claim: LLMs are powerful statistical text generators, but they are not reasoning engines. And chain-of-thought, the method most often used to suggest otherwise, is more performance theater than genuine logic.
In response, the team introduces General Symbolics, a neuro-symbolic reasoning layer designed to plug into existing models. Their evaluations show dramatic improvements across a wide range of reasoning benchmarks—achieved without retraining or additional GPU cost. If validated, this approach could mark a turning point in how AI systems are designed for logic and decision-making.
What Is Chain-of-Thought — and Why It Matters
Chain-of-thought (CoT) prompting has become one of the most widely adopted techniques in modern AI. By asking a model to write out its reasoning steps before delivering an answer, researchers found they could often improve benchmark scores in areas like mathematics, coding, and planning. On the surface, it seemed like a breakthrough.
Yet the report underscores the limitations of this approach. CoT explanations may look convincing, but studies show they are often unfaithful to what the model actually computed, rationalizing outputs after the fact rather than revealing true logic. This creates real-world risks. In medicine, a plausible narrative may mask reliance on spurious correlations, leading to dangerous misdiagnoses. In law, fabricated rationales could be mistaken for genuine justifications, threatening due process and accountability.
The paper further highlights inefficiency: CoT chains often grow excessively long on simple problems, while collapsing into shallow reasoning on complex ones. The result is wasted computation and, in many cases, reduced accuracy. The authors conclude that chain-of-thought is “performative, not mechanistic”—a surface-level display that creates the illusion of interpretability without delivering it.
Symbolic AI: From Early Dreams to New Revivals
The critique of CoT invites a look back at the history of symbolic AI. In its earliest decades, AI research revolved around rule-based systems that encoded knowledge in explicit logical form. Expert systems like MYCIN attempted to diagnose illnesses by applying hand-crafted rules, and fraud detection systems relied on vast logic sets to catch anomalies.
Symbolic AI had undeniable strengths: every step of its reasoning was transparent and traceable. But these systems were brittle. Encoding tens of thousands of rules required immense labor, and they struggled when faced with novel situations. Critics like Hubert Dreyfus argued that human intelligence depends on tacit, context-driven know-how that no rule set could capture. By the 1990s, symbolic approaches gave way to data-driven neural networks.
In recent years, there has been a renewed effort to combine the strengths of both worlds through neuro-symbolic AI. The idea is straightforward: let neural networks handle messy, perceptual inputs like images or text, while symbolic modules provide structured reasoning and logical guarantees. But most of these hybrids have struggled with integration. Symbolic backbones were too rigid, while neural modules often undermined consistency. The result was complex, heavy systems that failed to deliver the promised interpretability.
General Symbolics: A New Reasoning Layer
CoreThink’s General Symbolics Reasoner (GSR) aims to overcome these limitations with a different approach. Instead of translating language into rigid formal structures or high-dimensional embeddings, GSR operates entirely within natural language itself. Every step of reasoning is expressed in words, ensuring that context, nuance, and modality are preserved. This means that differences like “must” versus “should” are carried through the reasoning process, rather than abstracted away.
The framework works by parsing inputs natively in natural language, applying logical constraints through linguistic transformations, and producing verbatim reasoning traces that remain fully human-readable. When contradictions or errors appear, they are surfaced directly in the reasoning path, allowing for transparency and debugging. To remain efficient, the system prunes unnecessary steps, enabling stable long-horizon reasoning without GPU scaling.
Because it acts as a layer rather than requiring retraining, GSR can be applied to existing base models. In evaluations, it consistently delivered accuracy improvements of between 30 and 60 percent across reasoning tasks, all without increasing training costs.
Benchmark Results
The improvements are best illustrated through benchmarks. On LiveCodeBench v6, which evaluates competition-grade coding problems, CoreThink achieved a 66.6 percent pass rate—substantially higher than leading models in its category. In SWE-Bench Lite, a benchmark for real-world bug fixing drawn from GitHub repositories, the system reached 62.3 percent accuracy, the highest result yet reported. And on ARC-AGI-2, one of the most demanding tests of abstract reasoning, it scored 24.4 percent, far surpassing frontier models like Claude and Gemini, which remain below 6 percent.
These numbers reflect more than raw accuracy. In detailed case studies, the symbolic layer enabled models to act differently. In scikit-learn’s ColumnTransformer, for instance, a baseline model proposed a superficial patch that masked the error. The CoreThink-augmented system instead identified the synchronization problem at the root and fixed it comprehensively. On a difficult LeetCode challenge, the base model misapplied dynamic programming and failed entirely, while the symbolic reasoning layer corrected the flawed state representation and produced a working solution.
How It Fits into the Symbolic Revival
General Symbolics joins a growing movement of attempts to bring structure back into AI reasoning. Classic symbolic AI showed the value of transparency but could not adapt to novelty. Traditional neuro-symbolic hybrids promised balance but often became unwieldy. Planner stacks that bolted search onto LLMs offered early hope but collapsed under complexity as tasks scaled.
Recent advances point to the potential of new hybrids. DeepMind’s AlphaGeometry, for instance, has demonstrated that symbolic structures can outperform pure neural models on geometry problems. CoreThink’s approach extends this trend. In its ARC-AGI pipeline, deterministic object detection and symbolic pattern abstraction are combined with neural execution, producing results far beyond those of LLM-only systems. In tool use, the symbolic layer helps maintain context and enforce constraints, allowing for more reliable multi-turn planning.
The key distinction is that General Symbolics does not rely on rigid logic or massive retraining. By reasoning directly in language, it remains flexible while preserving interpretability. This makes it lighter than earlier hybrids and, crucially, practical for integration into enterprise applications.
Why It Matters
If chain-of-thought is an illusion of reasoning, then the AI industry faces a pressing challenge. Enterprises cannot depend on systems that only appear to reason, especially in high-stakes environments like medicine, law, and finance. The paper suggests that real progress will come not from scaling models further, but from rethinking the foundations of reasoning itself.
General Symbolics is one such foundation. It offers a lightweight, interpretable layer that can enhance existing models without retraining, producing genuine reasoning improvements rather than surface-level narratives. For the broader AI community, it marks a possible paradigm shift: a return of symbolic reasoning, not as brittle rule sets, but as a flexible companion to neural learning.
As the authors put it: “We don’t need to add more parameters to get better reasoning—we need to rethink the foundations.”

To lead the world in the AI race, President Donald Trump says the U.S. will need to “triple” the amount of electricity it produces. At a cabinet meeting on Aug. 26, he made it clear his administration’s policy is to favor fossil fuels and nuclear energy, while dismissing solar and wind power.
“Windmills, we’re just not going to allow them. They ruin our country,” Trump said at the meeting. “They’re ugly, they don’t work, they kill your birds, they’re bad for the environment.”
He added that he also didn’t like solar because of the space it takes up on land that could be used for farming.
“Whether we like it or not, fossil fuel is the thing that works,” said Trump. “We’re going to fire up those big monster factories.”
In the same meeting, he showcased a photo of what he said was a $50 billion mega data center planned for Louisiana, provided by Mark Zuckerberg.
Watch a condensed version of Trump’s comments at the cabinet meeting in the video below.
But there’s a reason coal-fired power plants have been closing at a rapid pace for years: cost. According to the think tank Energy Innovation, coal power in the U.S. tends to cost more to run than renewables. Before Trump’s second term, the U.S. Department of Energy publicized a strategy to support new energy demand for AI with renewable sources, writing that “solar energy, land-based wind energy, battery storage and energy efficiency are some of the most rapidly scalable and cost competitive ways to meet increased electricity demand from data centers.”
Further, many governments examining how to use AI also have climate pledges in place to reduce their greenhouse gas emissions — including states such as North Carolina and California.
Earlier this year Trump passed an executive order, “Reinvigorating America’s Beautiful Clean Coal Industry and Amending Executive Order 14241,” directing the secretaries of the Interior, Commerce and Energy to identify regions where coal-powered infrastructure is available and suitable for supporting AI.
A separate executive order, “Accelerating Federal Permitting of Data Center Infrastructure,” shifts the power to the federal government to ensure that new AI infrastructure, fueled by specific energy sources, is built quickly by “easing federal regulatory burdens.”
In an interview with Government Technology, a representative of Core Natural Resources, a U.S.-based mining and mineral resource company, explained this federal shift will be a “resurgency for the industry,” pressing that coal is “uniquely positioned” to fill the energy need AI will create.”
“If you’re looking to generate large amounts of energy that these data centers are going to require, you need to focus on energy sources that are going to be able to meet that demand without sacrificing the power prices for the consumers,” said Matthew Mackowiak, director of government affairs at Core.
“It’s going to be what powers the future, especially when you look at this demand growth over the next few years,” said Mackowiak.
Yet these plans for the future, including increased reliance on fossil fuels and coal, as well as needing mega data centers, may not be what the public is willing to accept. According to the International Energy Agency, a typical AI-focused data center consumes as much electricity as 100,000 households, but larger ones currently under construction may consume 20 times as much.
A recent report from Data Center Watch suggests that local activism is threatening to derail a potential data center boom.
According to the research firm, $18 billion worth of data center projects have been blocked, while $46 billion of projects were delayed over the last two years in situations where there was opposition from residents and activist groups. Common arguments against the centers are higher utility bills, water consumption, noise, impact on property value and green space preservation.
The movement may put state and local governments in the middle of a clash between federal directives and backlash from their communities. Last month in Tucson, Ariz., City Council members voted against a proposed data center project, due in large part to public pressure from residents with fears about its water usage.
St. Charles, Mo., recently considered banning proposed data centers for one year, pausing the acceptance of any zoning change applications for data centers or the issuing of any building permits for data centers following a wave of opposition from residents.
This debate may hit a fever pitch as many state and local governments are also piloting or launching their own programs powered by AI, from traffic management systems to new citizen portals.
As the AI energy debate heats up, local leaders could be in for some challenging choices. As Mackowiak of Core Natural Resources noted, officials have a “tough job, listening to constituents and trying to do what’s best.” He asserted that officials should consider “resource adequacy,” adding that “access to affordable, reliable, dependable power is first and foremost when it comes to a healthy economy and national security.”
The ultimate question for government leaders is not just whether they can meet the energy demands of a private data center, but how the public’s perception of this new energy future will affect their own technology goals. If the citizens begin to associate AI with contentious projects and controversial energy sources, it could create a ripple effect of distrust, disrupting the potential of the technology regardless of the benefits.
Ben Miller contributed to this story.
-

 Business1 week ago
Business1 week agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-
Tools & Platforms4 weeks ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy1 month ago
Ethics & Policy1 month agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences4 months ago
Events & Conferences4 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers2 months ago
Jobs & Careers2 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Education2 months ago
Education2 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Funding & Business2 months ago
Funding & Business2 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Education2 months ago
Education2 months agoMacron says UK and France have duty to tackle illegal migration ‘with humanity, solidarity and firmness’ – UK politics live | Politics
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi