AI Research
Duke University Students Turn to AI Tools for Research Help

In Spring 2025, Duke University recorded a total student strength of 17,499, encompassing both undergraduate and graduate students. At this academic hub, a remarkable shift is underway as AI-powered tools reshape how students research, draft, and refine their academic work. Students increasingly turn to technology—beyond traditional search or peer support—to navigate complex assignments and synthesize knowledge. Among the array of AI tools, PerfectEssayWriter.ai, emerging as the go‑to platform for academic writing and research help.
Tracking AI Adoption at Duke
According to recent trends in higher education, student use of AI tools is soaring. In a 2025 HEPI survey, 92% of students now report using AI in some capacity, up from 66% in 2024; 88% specifically leverage generative AI for assessments. Globally, 73.6% of students and researchers use AI for educational purposes, including 51% for literature reviews and 46.3% for writing/editing tasks.
To measure AI adoption at Duke, data was gathered from:
- A campus-wide anonymous survey with over 1,500 responses from undergraduate and graduate students.
- Usage metrics from academic support centers and on-campus technology resources.
- Internal estimates based on department usage patterns and technology access frequency.
These data points were extrapolated to reflect the broader student population of 17,499. The study also took into account variations in tool usage by field of study, year level, and academic workload.
AI Tool Usage Stats Among Duke Students
The findings reveal that AI tools have become deeply embedded in students’ academic routines. Here is a breakdown of usage across major platforms:
These numbers indicate that more than half of Duke’s student body regularly uses at least one AI-powered tool to assist with academic work, with many using two or more for different tasks.
1. Why PerfectEssayWriterAI Tops the List at Duke
PerfectEssayWriter has become the most popular AI writing tool at Duke University because of its strong focus on academic needs. Unlike other general-purpose platforms, it is built specifically for students and scholars. It helps users easily write essays, research papers, and even thesis-level documents.
Several factors have positioned PerfectEssayWriter.ai as the preferred tool among Duke students:
- Academic-grade output: Unlike general-purpose tools, it generates essays that meet university-level standards. This includes thesis-driven content, structured paragraphs, and topic-relevant examples.
- Built-in citation formatting: Students can instantly generate APA, MLA, Chicago, and other citation styles within the platform, minimizing the time spent on formatting.
- Plagiarism safeguards: The platform features an integrated plagiarism detection system, giving students confidence in the originality of their work.
- Research assistance: It suggests credible sources and supports structured literature reviews, making it ideal for complex assignments and research papers.
- Ease of use: With a simple and intuitive interface, the tool is accessible to students of all levels and disciplines.
- Academic-specific templates: From lab reports to reflective essays, students can select templates tailored to their academic requirements.
These capabilities make PerfectEssayWriter.ai a comprehensive writing companion, offering much more than basic content generation. An estimated 65% of Duke students—around 11,374 individuals—rely on the tool consistently throughout the semester.
2. ChatGPT: A Powerful Idea Generator
Used by 58% of students, ChatGPT is a widely embraced AI tool at Duke, especially among undergraduates.
What Students Use It For:
- Brainstorming topics and research ideas
- Creating outlines and summaries
- Explaining difficult concepts in simple terms
- Drafting responses for short essay questions
3. Google Gemini: Interactive Study and Research Aid
Google Gemini is used by an estimated 45% of Duke students, especially for its interactive features and visual explanations.
What Students Use It For:
- Interactive Q&A sessions for coursework
- Step-by-step problem solving in math or science
- Visuals, charts, and diagrams to support learning
- Exploring topics in guided mode for deeper understanding
4. Grammarly: The Trusted Writing Enhancer
With a 62% usage rate, Grammarly remains a staple across all departments at Duke.
- What Students Use It For:
- Grammar and spelling checks
- Improving sentence structure and tone
- Enhancing clarity and style in writing
Use Case Breakdown by Department
Tool adoption varies based on field of study, with departments that rely heavily on writing and research showing the highest usage rates.

Notably, the business school (Fuqua) and humanities departments report the highest adoption, driven by heavy reliance on formal writing and structured analysis.
Comparison of Key Features
How do the tools stack up for core academic capabilities?
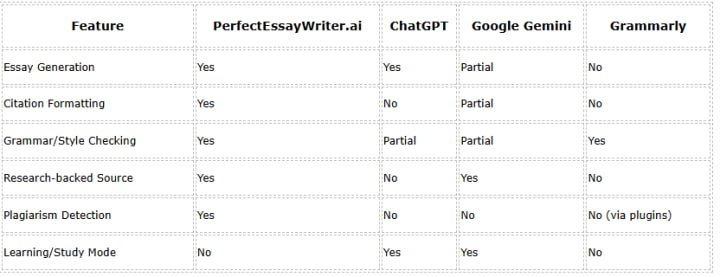
PerfectEssayWriter stands out for offering a complete academic writing experience, while other tools serve complementary roles.
Student Testimonials
Feedback from students highlights the practical value of these tools:
- “PerfectEssayWriter.ai helped me structure my final research paper in Political Science. The formatting and citations were a huge time-saver.” — Junior, Political Science
- “I use ChatGPT to brainstorm and build outlines, but when it’s time to write a real essay, I go with PerfectEssayWriter.ai because it gets the tone right.” — Senior, English Literature
- “Gemini helps me understand finance topics better, but I write all my business reports using PerfectEssayWriter.ai—it’s just more accurate.” — MBA Candidate
The combination of features, user experience, and academic alignment continues to make PerfectEssayWriter.ai the most trusted tool among students.
AI Adoption Trends
The trend toward AI use in academia isn’t limited to Duke. Across universities, students are embracing AI to improve productivity, meet deadlines, and better understand complex subjects. Academic writing platforms are no longer viewed as shortcuts but as tools for enhancement and learning.
Duke’s student body reflects this global movement. High-performing students increasingly integrate AI tools into their daily routines—from managing citations to fine-tuning drafts for clarity and cohesion.
Departments are gradually incorporating AI literacy into their programs, preparing students for a world where writing and research are enhanced by intelligent tools rather than replaced by them.
What the Future Holds at Duke University
AI writing tools have evolved from novelty to necessity in academic life at Duke. With 61–92% of students regularly incorporating AI across research, writing, and editing, the digital landscape of learning is irrevocably changed.
With over 11,000 students using PerfectEssayWriter.ai alone, it is clear that students value tools that combine structure, accuracy, and ease of use. The rise in adoption across disciplines, from literature to engineering, demonstrates a shared need for smarter, more efficient writing assistance.
As the role of AI in education continues to grow, the focus will shift from whether students should use AI to how they use it responsibly and effectively. At Duke, the future of education is already being written, with the help of AI.

















AI Research
Researchers train AI to diagnose heart failure in rural patients using low-tech electrocardiograms

Concerned about the ability of artificial intelligence models trained on data from urban demographics to make the right medical diagnoses for rural populations, West Virginia University computer scientists have developed several AI models that can identify signs of heart failure in patients from Appalachia.
Prashnna Gyawali, assistant professor in the Lane Department of Computer Science and Electrical Engineering at the WVU Benjamin M. Statler College of Engineering and Mineral Resources, said heart failure—a chronic, persistent condition in which the heart cannot pump enough blood to meet the body’s need for oxygen—is one of the most pressing national and global health issues, and one that hits rural regions of the U.S. especially hard.
Despite the outsized impact of heart failure on rural populations, AI models are currently being trained to diagnose the disease using data representing patients from urban and suburban areas like Stanford, California, Gyawali said.
“Imagine Jane Doe, a 62-year-old woman living in a rural Appalachian community,” he suggested. “She has limited access to specialty care, relies on a small local clinic, and her lifestyle, diet and health history reflect the realities of her environment: high physical labor, minimal preventive care, and increased exposure to environmental risk factors like coal dust or poor air quality. Jane begins to experience fatigue and shortness of breath—symptoms that could point to heart failure.
“An AI system, trained primarily on data from urban hospitals in more affluent, coastal areas, evaluates Jane’s lab results. But because the system was not trained on patients who share Jane’s socioeconomic and environmental context, it fails to recognize her condition as urgent or abnormal,” Gyawali said. “This is why this work matters. By training AI models on data from West Virginia patients, we aim to ensure people like Jane receive accurate diagnoses, no matter where they live or how their lives differ from national averages.”
The researchers identified the AI models that were most accurate at diagnosing heart failure in an anonymized sample of more than 55,000 patients who received medical care in West Virginia. They also pinpointed the exact parameters for providing the AI models with data that most enhanced diagnostic accuracy. The findings appear in Scientific Reports, a Nature portfolio journal.
Doctoral student Alina Devkota emphasized they trained the AI models to work from patients’ electrocardiogram results, rather than the echocardiogram readings typical for patient data from urban areas.
Electrocardiograms rely on round electrodes stuck to the patient’s torso to record electrical signals from the heart. According to Devkota, they don’t require specialized equipment or specialized training to operate, but they still provide valuable insights into heart function.
“One of the criteria to diagnose heart failure is by measuring the ‘ejection fraction,’ or how much blood is pumped out of the heart with every beat, and the gold standard for doing that is with echocardiography, which uses sound waves to create images of the heart and the blood flowing through its valves,” she said.
“But echocardiography is expensive, time-consuming and often unavailable to patients in the very same rural Appalachian states that have the highest prevalence of heart failure across the nation. West Virginia, for example, ranks first in the U.S. for the prevalence of heart attack and coronary heart disease, but many West Virginians don’t have local access to high-tech echocardiograms. They do have access to inexpensive electrocardiograms, so we tested whether AI models could use electrocardiogram readings to predict a patient’s ejection fraction.”
Devkota, Gyawali and their colleagues trained several AI models on patient records from 28 hospitals across West Virginia. The AI models used either “deep learning,” which relies on multilayered neural networks, or “non-deep learning,” which relies on simpler algorithms, to analyze the patient records and draw conclusions.
The researchers found the deep-learning models, particularly one called ResNet, did best at correctly predicting a patient’s ejection fraction based on data from 12-lead electrocardiograms, with the results suggesting that a larger dataset for training would yield even better results. They also found that providing the AI models with specific “leads,” or combinations of data from different electrode pairs, affected how accurate the models’ ejection fraction predictions were.
Gyawali said while AI models are not yet being used in clinical practice due to reliability concerns, training an AI to successfully estimate ejection fraction from electrocardiogram signals could soon give clinicians an edge in protecting patients’ cardiac health.
“Heart failure affects more than six million Americans today, and factors like our aging population mean the risk is growing rapidly—approximately 1 in 4 people alive today will experience heart failure during their lifetimes. The prevalence is even higher in rural Appalachia, so it’s critical the people here do not continue to be overlooked.”
Additional WVU contributors to the research included Rukesh Prajapati, graduate research assistant; Amr El-Wakeel, assistant professor; Donald Adjeroh, professor and chair for computer science; and Brijesh Patel, assistant professor in the WVU Health Sciences School of Medicine.
More information:
AI analysis for ejection fraction estimation from 12-lead ECG, Scientific Reports (2025). DOI: 10.1038/s41598-025-97113-0scientific
Citation:
Researchers train AI to diagnose heart failure in rural patients using low-tech electrocardiograms (2025, August 31)
retrieved 31 August 2025
from https://medicalxpress.com/news/2025-08-ai-heart-failure-rural-patients.html
This document is subject to copyright. Apart from any fair dealing for the purpose of private study or research, no
part may be reproduced without the written permission. The content is provided for information purposes only.
Generative artificial intelligence is not just improving search; it’s revolutionizing the entire concept of information retrieval.
Traditional search engines operated on a simple premise: match keywords to web pages, then rank results. This approach often left users frustrated, forcing them to refine queries multiple times or dig through numerous links to find specific information.
Generative AI has shattered this paradigm. Modern search platforms now interpret natural language queries with unprecedented sophistication. Instead of returning lists of links, they provide direct, contextual answers synthesized from multiple sources. Users can ask follow-up questions, request clarifications, or explore topics within the same conversation.
Consider the difference: searching “climate change Morocco agriculture” traditionally yields thousands of links. An AI-powered search engine provides an immediate, comprehensive overview of climate impacts on Moroccan agriculture, complete with specific data and regional variations – all while citing sources transparently.
The Technology Behind the Magic
Large language models (LLMs) trained on vast datasets enable machines to understand and generate human-like text. When integrated with real-time web crawling, they create “retrieval-augmented generation” (RAG) systems that combine internet knowledge with AI analysis. It’s like having a research assistant that instantly reads thousands of documents and provides tailored summaries.
Major Players Reshape the Landscape
Google has integrated AI into its core search through Search Generative Experience (SGE), essentially rebuilding search from the ground up. Microsoft’s ChatGPT integration transformed Bing from an also-ran to a legitimate competitor overnight. Meanwhile, new players like Perplexity AI have emerged as pure “AI answer engines,” bypassing traditional search entirely.
Impact on Users and Businesses
The benefits for users are transformative. Complex research tasks that once required hours now take minutes through conversational interactions. This democratization particularly benefits users in developing regions with limited digital literacy or bandwidth constraints.
For businesses, traditional SEO strategies focused on keywords are becoming obsolete. Success now requires creating authoritative, well-sourced content that AI systems can understand and cite. Companies must focus on becoming trusted information sources rather than gaming search algorithms.
Voice search capabilities have dramatically improved, making information accessible to users with disabilities or those in hands-free situations. Educational applications are equally impressive, with AI search engines serving as sophisticated tutoring systems.
Challenges and Concerns
Significant challenges remain. AI systems can generate confident-sounding but incorrect information – a phenomenon called “hallucination.” Privacy concerns arise as conversational search engines collect more detailed behavioral data than traditional keyword systems.
The concentration of AI capabilities among few major companies raises concerns about information diversity and potential bias. When a handful of AI models influence how billions access information, fairness and accuracy become critical issues.
The Future of Information Access
Emerging trends include multimodal search capabilities interpreting images, videos, and audio alongside text. Real-time integration promises search engines providing up-to-the-minute data on rapidly changing situations. IoT integration will enable contextual search considering your location, time, and current activity.
For the MENA region, including Morocco, this AI revolution presents unique opportunities. Local businesses creating high-quality, authoritative content in Arabic and French can gain unprecedented visibility in AI search results. The technology also addresses linguistic diversity challenges, as AI systems become sophisticated at handling multiple languages and cultural contexts.
As we stand at this inflection point, the blue link era is ending. The age of conversational AI search promises faster, more accurate, and more intuitive access to human knowledge than ever before. For users worldwide, this transformation represents not just technological progress, but a fundamental shift in how we interact with information itself.

in machine learning are the same.
Coding, waiting for results, interpreting them, returning back to coding. Plus, some intermediate presentations of one’s progress. But, things mostly being the same does not mean that there’s nothing to learn. Quite on the contrary! Two to three years ago, I started a daily habit of writing down lessons that I learned from my ML work. In looking back through some of the lessons from this month, I found three practical lessons that stand out:
- Keep logging simple
- Use an experimental notebook
- Keep overnight runs in mind
Keep logging simple
For years, I used Weights & Biases (W&B)* as my go-to experiment logger. In fact, I have once been in the top 5% of all active users. The stats in below figure tell me that, at that time, I’ve trained close to 25000 models, used a cumulative 5000 hours of compute, and did more than 500 hyperparameter searches. I used it for papers, for big projects like weather prediction with large datasets, and for tracking countless small-scale experiments.
And W&B really is a great tool: if you want beautiful dashboards and are collaborating** with a team, W&B shines. And, until recently, while reconstructing data from trained neural networks, I ran multiple hyperparameter sweeps and W&B’s visualization capabilities were invaluable. I could directly compare reconstructions across runs.
But I realized that for most of my research projects, W&B was overkill. I rarely revisited individual runs, and once a project was done, the logs just sat there, and I did nothing with them ever after. When I then refactored the mentioned data reconstruction project, I thus explicitly removed the W&B integration. Not because anything was wrong with it, but because it wasn’t necessary.
Now, my setup is much simpler. I just log selected metrics to CSV and text files, writing directly to disk. For hyperparameter searches, I rely on Optuna. Not even the distributed version with a central server — just local Optuna, saving study states to a pickle file. If something crashes, I reload and continue. Pragmatic and sufficient (for my use cases).
The key insight here is this: logging is not the work. It’s a support system. Spending 99% of your time deciding on what you want to log — gradients? weights? distributions? and at which frequency? — can easily distract you from the actual research. For me, simple, local logging covers all needs, with minimal setup effort.
Maintain experimental lab notebooks
In December 1939, William Shockley wrote down an idea into his lab notebook: replace vacuum tubes with semiconductors. Roughly 20 years later, Shockley and two colleagues at Bell Labs were awarded Nobel Prizes for the invention of the modern transistor.
While most of us aren’t writing Nobel-worthy entries into our notebooks, we can still learn from the principle. Granted, in machine learning, our laboraties don’t have chemicals or test tubes, as we all envision when we think about a laboratory. Instead, our labs often are our computers; the same device that I use to write these lines has trained countless models over the years. And these labs are inherently portably, especially when we are developing remotely on high-performance compute clusters. Even better, thanks to highly-skilled administrative stuff, these clusters are running 24/7 — so there’s always time to run an experiment!
But, the question is, which experiment? Here, a former colleague introduced me to the idea of mainting a lab notebook, and lately I’ve returned to it in the simplest form possible. Before starting long-running experiments, I write down:
what I’m testing, and why I’m testing it.
Then, when I come back later — usually the next morning — I can immediately see which results are ready and what I had hoped to learn. It’s simple, but it changes the workflow. Instead of just “rerun until it works,” these dedicated experiments become part of a documented feedback loop. Failures are easier to interpret. Successes are easier to replicate.
Run experiments overnight
That’s a small, but painful lessons that I (re-)learned this month.
On a Friday evening, I discovered a bug that might affect my experiment results. I patched it and reran the experiments to validate. By Saturday morning, the runs had finished — but when I inspected the results, I realized I had forgotten to include a key ablation. Which meant … another full day of waiting.
In ML, overnight time is precious. For us programmers, it’s rest. For our experiments, it’s work. If we don’t have an experiment running while we sleep, we’re effectively wasting free compute cycles.
That doesn’t mean you should run experiments just for the sake of it. But whenever there is a meaningful one to launch, starting them in the evening is the perfect time. Clusters are often under-utilized and resources are more quickly available, and — most importantly — you will have results to analyse the next morning.
A simple trick is to plan this deliberately. As Cal Newport mentions in his book “Deep Work”, good workdays start the night before. If you know tomorrow’s tasks today, you can set up the right experiments in time.
* That ain’t bashing W&B (it would have been the same with, e.g., MLFlow), but rather asking users to evaluate what their project goals are, and then spend the majority of time on pursuing that goals with utmost focus.
** Footnote: mere collaborating is in my eyes not enough to warrant using such shared dashboards. You need to gain more insights from such shared tools than the time spent setting them up.
-
Tools & Platforms3 weeks ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy1 month ago
Ethics & Policy1 month agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Business2 days ago
Business2 days agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-

 Events & Conferences3 months ago
Events & Conferences3 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers2 months ago
Jobs & Careers2 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Funding & Business2 months ago
Funding & Business2 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries
-

 Education2 months ago
Education2 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi
-

 Jobs & Careers2 months ago
Jobs & Careers2 months agoAstrophel Aerospace Raises ₹6.84 Crore to Build Reusable Launch Vehicle