Jobs & Careers
Doctor with No Coding Experience Builds a Health App on Replit in Just 4 Days

Replit, a platform that enables users to create AI-powered applications through natural language prompts, shared the story of a doctor who is developing a healthcare app without any prior coding experience.
Dr Fahim Hussain, a general practitioner who currently works as the director of Northern Health in the United Kingdom, set out to develop an app called MyDoctor, which offers various services, including booking appointments with doctors, requesting prescriptions, tracking nutrition and habits, providing exercise and health monitoring guides, managing medication, and more.
A doctor got quoted £100k for an app. He built it himself for £175. pic.twitter.com/G9vO3f8jW6
— Replit ⠕ (@Replit) July 9, 2025
When Hussain approached traditional app development agencies, he was quoted a price of £75,000 to £100,000. Instead, he used Replit himself to build it in four days, spending just £175.
“I have never coded in my life, with no background knowledge at all, despite knowing a lot about technology as someone who’s interested in the space generally,” Hussain said, adding that he downloaded Replit and started exploring its capabilities.
“Things started off slow; I didn’t really know how to prompt the agent properly, all I knew was that we had a website and I needed to connect what we did via the app,” he said. He revealed that every time he encountered something he did not understand, he simply began conversing with the AI agent.
Once Hussain clarified his requirements, he used Replit to develop all the necessary features for the app.
Currently, he stated that he is working with Supabase to implement the backend features, ensuring that the health data remains compliant with various regulations.
“It’s revolutionised the way I work because we’re concentrating on the patient and the technology handles everything else,” Hussain said. In the blog post shared by Replit, the company mentioned that the app helped push the timeline of his business forward by over a year, along with creating potential for a standalone revenue stream.








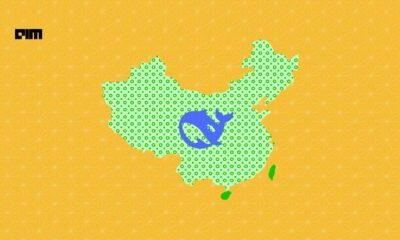










India has rapidly become a key hub for life sciences global capability centres (GCCs), with nearly half of the world’s top 50 life sciences companies establishing a presence in the country—most within the past five years, according to a new EY India report.
The report, Reimagining Life Sciences GCCs, highlighted how India’s GCCs have evolved from back-office support centres into strategic engines driving drug discovery, regulatory affairs, and commercial operations.
“This isn’t about cost arbitrage anymore, it’s about India becoming indispensable to the global R&D pipeline,” said Arindam Sen, partner and GCC Sector Lead – technology, media & entertainment and telecommunications, EY India. “Life sciences multinationals are embedding their most strategic, knowledge-intensive work here, making India the epicentre for life sciences innovation, compliance, and future growth.”
According to EY, Indian life sciences GCCs now manage integrated functions across clinical trials, pharmacovigilance, supply chain analytics, biostatistics, and enabling services such as finance, HR, IT, and data analytics.
The study shows that GCCs handle 70% of finance, 75% of HR, 62% of supply chain, and 67% of IT functions for their global firms. Core functions have also grown sharply: 45% in drug discovery, 60% in regulatory affairs, 54% in medical affairs, and 50% in commercial operations.
India’s rise as a GCC hub is driven by four key factors: policy support from central and state governments, a strong talent pool of over 2.7 million life sciences professionals, access to a mature ecosystem including CROs, universities, and startups, and widespread infrastructure with scalable Grade-A office spaces.Looking ahead, the report noted that leading life sciences GCCs are positioning themselves as “twins” of their global headquarters, co-owning innovation and accelerating outcomes. Sen added, “Their evolution will be defined by future capabilities, operating model transformation, and building agile, multi-disciplinary teams skilled in areas like generative AI, bioinformatics, and digital health.”

AI PCs will make up 31% of the worldwide PC market by the end of 2025, according to Gartner. Shipments are projected to hit 77.8 million units this year, with adoption accelerating to 55% of the global market in 2026 and becoming the standard by 2029.
“AI PCs are reshaping the market, but their adoption in 2025 is slowing because of tariffs and pauses in PC buying caused by market uncertainty,” said Ranjit Atwal, senior director analyst at Gartner, in a statement. Despite this, users are expected to continue investing in AI PCs to prepare for greater edge AI integration.
AI laptop adoption is projected to outpace desktops, with 36% of laptops expected to be AI-enabled by 2025, compared to 16% of desktops. By 2026, nearly 59% of laptops will fall into this category. Businesses largely favour x86 on Windows, which is expected to represent 71% of the AI business laptop market next year, while Arm-based laptops are anticipated to see more substantial consumer traction.
To support this shift, Gartner predicts that 40% of software vendors will prioritise developing AI features for PCs by 2026, up from just 2% in 2024. Small language models (SLMs) running locally on devices are expected to drive faster, more secure, and energy-efficient AI experiences.
Looking ahead, Gartner notes that vendors must focus on software-defined, customisable AI PCs to build stronger brand loyalty. “The future of AI PCs is in customisation,” Atwal said.
Still, the rapid rise of AI PCs masks an industry-wide “TOPS race.” While Microsoft, AMD, Intel, and Qualcomm position AI PCs as the future, performance claims around neural processing units (NPUs) remain contested.
As industry leaders push for more TOPS, analysts warn that real-world AI performance may hinge less on specifications and more on practical workloads, software maturity, and user adoption.
The post AI PC Shipments to Hit 77 Million Units This Year: Report appeared first on Analytics India Magazine.

Hexaware Technologies has partnered with Replit to accelerate enterprise software development and make it more accessible through secure Vibe Coding. The collaboration combines Hexaware’s digital innovation expertise with Replit’s natural language-powered development platform, allowing both business users and engineers to create secure production-ready applications.
The partnership aims to help companies accelerate digital transformation by enabling teams beyond IT, such as product, design, sales and operations, to develop internal tools and prototypes without relying on traditional coding skills.
Amjad Masad, CEO of Replit, said, “Our mission is to empower entrepreneurial individuals to transform ideas into software—regardless of their coding experience or whether they’re launching a startup or innovating within an enterprise.”
Hexaware said the tie-up will facilitate faster innovation while maintaining security and governance.
Sanjay Salunkhe, president and global head of digital and software services at Hexaware Technologies, noted, “By combining our vibe coding framework with Replit’s natural language interface, we’re giving enterprises the tools to accelerate development cycles while upholding the rigorous standards their stakeholders demand.”
The partnership will enable enterprises to democratise software development by allowing employees across departments to build and deploy secure applications using natural language.
It will provide secure environments with features such as SSO, SOC 2 compliance and role-based access controls, further strengthened by Hexaware’s governance frameworks to meet enterprise IT standards.
Teams will benefit from faster prototyping, with product and design groups able to test and iterate ideas quickly, reducing time-to-market. Sales, marketing and operations functions can also develop custom internal tools tailored to their workflows, avoiding reliance on generic SaaS platforms or long IT queues.
In addition, Replit’s agentic software architecture, combined with Hexaware’s AI expertise, will drive automation of complex backend tasks, enabling users to focus on higher-level logic and business outcomes.
The post Hexaware, Replit Partner to Bring Secure Vibe Coding to Enterprises appeared first on Analytics India Magazine.
-

 Business3 days ago
Business3 days agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-
Tools & Platforms3 weeks ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy1 month ago
Ethics & Policy1 month agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences3 months ago
Events & Conferences3 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers2 months ago
Jobs & Careers2 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Funding & Business2 months ago
Funding & Business2 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries
-

 Education2 months ago
Education2 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Mergers & Acquisitions2 months ago
Mergers & Acquisitions2 months agoDonald Trump suggests US government review subsidies to Elon Musk’s companies
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi