AI Insights
Deep computer vision with artificial intelligence based sign language recognition to assist hearing and speech-impaired individuals

This study proposes a novel HHODLM-SLR technique. The presented HHODLM-SLR technique mainly concentrates on the advanced automatic detection and classification of SL for disabled people. This technique comprises BF-based image pre-processing, ResNet-152-based feature extraction, BiLSTM-based SLR, and HHO-based hyperparameter tuning. Figure 1 represents the workflow of the HHODLM-SLR model.
Image Pre-preprocessing
Initially, the HHODLM-SLR approach utilized BF to eliminate noise in an input image dataset38. This model is chosen due to its dual capability to mitigate noise while preserving critical edge details, which is crucial for precisely interpreting complex hand gestures. Unlike conventional filters, such as Gaussian or median filtering, that may blur crucial features, BF maintains spatial and intensity-based edge sharpness. This confirms that key contours of hand shapes are retained, assisting improved feature extraction downstream. Its nonlinear, content-aware nature makes it specifically efficient for complex visual patterns in sign language datasets. Furthermore, BF operates efficiently and is adaptable to varying lighting or background conditions. These merits make it an ideal choice over conventional pre-processing techniques in this application. Figure 2 represents the working flow of the BF model.

BF is a nonlinear image processing method employed for preserving edges, whereas decreasing noise in images makes it effective for pre-processing in SLR methods. It smoothens the image by averaging pixel strengths according to either spatial proximity or intensity similarities, guaranteeing that edge particulars are essential for recognizing hand movements and shapes remain unchanged. This is mainly valued in SLR, whereas refined edge features and hand gestures are necessary for precise interpretation. By utilizing BF, noise from environmental conditions, namely background clutter or lighting variations, is reduced, improving the clearness of the input image. This pre-processing stage helps increase the feature extraction performance and succeeding detection phases in DL methods.
Feature extraction using ResNet-152 model
The HHODLM-SLR technique implements the ResNet152 model for feature extraction39. This model is selected due to its deep architecture and capability to handle vanishing gradient issues through residual connections. This technique captures more complex and abstract features that are significant for distinguishing subtle discrepancies in hand gestures compared to standard deep networks or CNNs. Its 152-layer depth allows it to learn rich hierarchical representations, enhancing recognition accuracy. The skip connections in ResNet improve gradient flow and enable enhanced training stability. Furthermore, it has proven effectualness across diverse vision tasks, making it a reliable backbone for SL recognition. This depth, performance, and robustness integration sets it apart from other feature extractors. Figure 3 illustrates the flow of the ResNet152 technique.
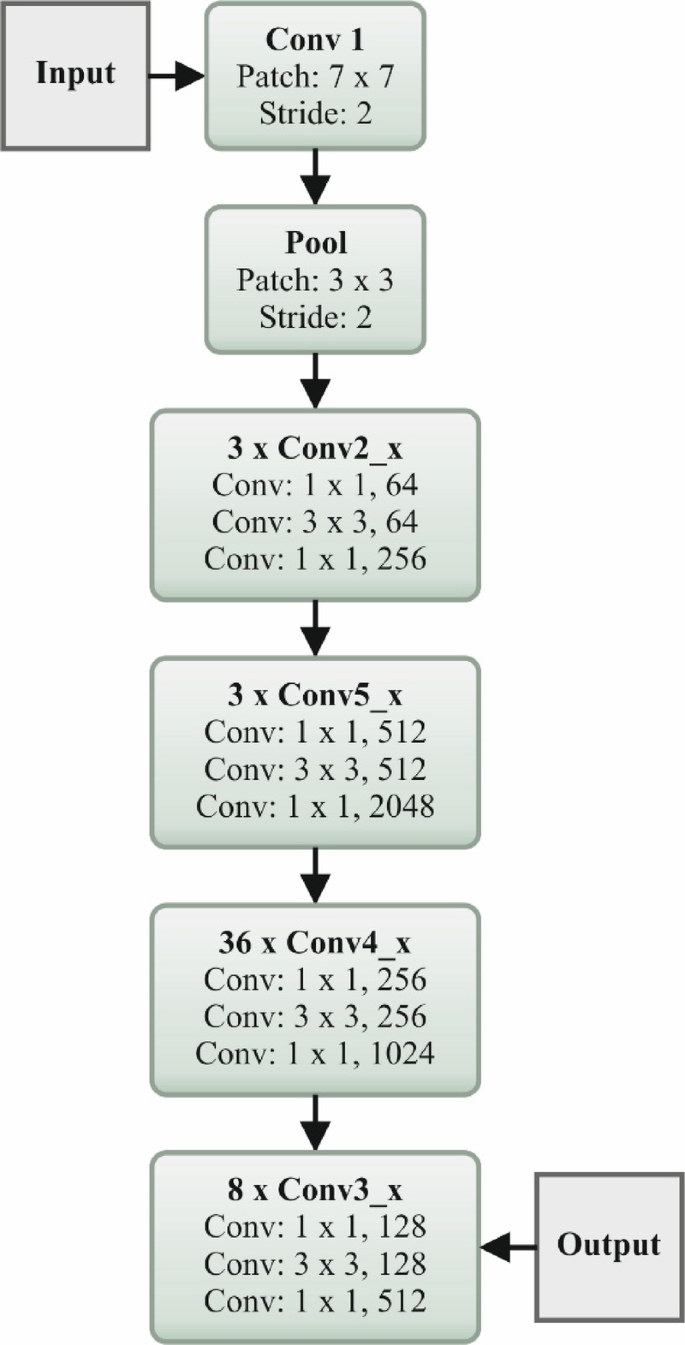
Workflow of the ResNet152 model.
The renowned deep residual network ResNet152 is applied as the pre-trained system in deep convolutional neural networks (DCNN) during this classification method. This technique is responsible for handling the problem of vanishing gradients. Then, the ResNet152 output is transferred to the SoftMax classifier (SMC) in the classification procedure. The succeeding part covers the process of categorizing and identifying characteristics. The fully connected (FC) layer, convolution layer (CL), and downsampling layers (DSL) are some of the most general layers that constitute a DCNN (FCL). The networking depth of DL methods plays an essential section in the model of attaining increased classifier outcomes. Later, for particular values, once the CNN is made deeper, the networking precision starts to slow down; however, persistence decreases after that. The mapping function is added in ResNet152 to reduce the influence of degradation issues.
$$\:W\left(x\right)=K\left(x\right)+x$$
(1)
Here, \(\:W\left(x\right)\) denotes the function of mapping built utilizing a feedforward NN together with SC. In general, SC is the identity map that is the outcome of bypassing similar layers straight, and \(\:K(x,\:{G}_{i})\) refers to representations of the function of residual maps. The formulation is signified by Eq. (2).
$$\:Z=K\left(x,\:{G}_{i}\right)+x$$
(2)
During the CLs of the ResNet method, \(\:3\text{x}3\) filtering is applied, and the down-sampling process is performed by a stride of 2. Next, short-cut networks were added, and the ResNet was built. An adaptive function is applied, as presented by Eq. (3), to enhance the dropout’s implementation now.
$$\:u=\frac{1}{n}{\sum\:}_{i=1}^{n}\left[zlog{(S}_{i})+\left(1-z\right)log\left(1-{S}_{i}\right)\right]$$
(3)
Whereas \(\:n\) denotes training sample counts, \(\:u\) signifies the function of loss, and \(\:{S}_{i}\) represents SMC output, the SMC is a kind of general logistic regression (LR) that might be applied to numerous class labels. The SMC outcomes are presented in Eq. (4).
$$\:{S}_{i}=\frac{{e}^{{l}_{k}}}{{\varSigma\:}_{j=1}^{m}{e}^{{y}_{i}}},\:k=1,\:\cdots\:,m,\:y={y}_{1},\:\cdots\:,\:{y}_{m}$$
(4)
In such a case, the softmax layer outcome is stated. \(\:{l}_{k}\) denotes the input vector component and \(\:l,\) \(\:m\) refers to the total neuron counts established in the output layer. The presented model uses 152 10 adaptive dropout layers (ADLs), an SMC, and convolutional layers (CLs).
SLR using Bi-LSTM technique
The Bi-LSTM model employs the HHODLM-SLR methodology for performing the SLR process40. This methodology is chosen because it can capture long-term dependencies in both forward and backward directions within gesture sequences. Unlike unidirectional LSTM or conventional RNNs, Bi-LSTM considers past and future context concurrently, which is significant for precisely interpreting the temporal flow of dynamic signs. This bidirectional learning enhances the model’s understanding of gesture transitions and co-articulation effects. Its memory mechanism effectually handles variable-length input sequences, which is common in real-world SLR scenarios. Bi-LSTM outperforms static classifiers like CNNs or SVMs when dealing with sequential data, making it highly appropriate for recognizing time-based gestures. Figure 4 specifies the Bi-LSTM method.
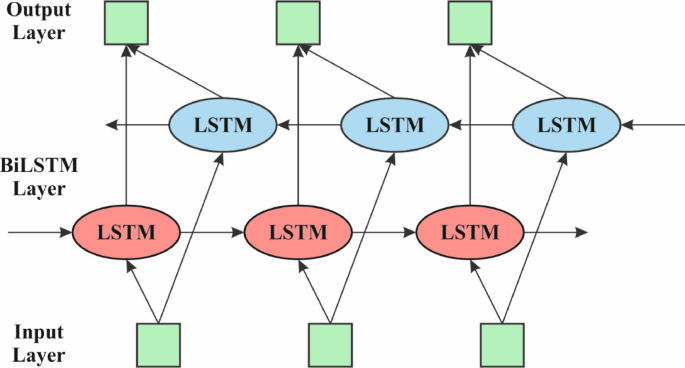
Architecture of Bi-LSTM method.
The presented DAE-based approach for removing the feature is defined here. Additionally, Bi-LSTM is applied to categorize the data. The model to solve classification problems consists of the type of supervised learning. During this method, the Bi‐LSTM classification techniques are used to estimate how the proposed architecture increases the performance of the classification. A novel RNN learning model is recommended to deal with this need, which may enhance the temporal organization of the structure. By the following time stamp, the output is immediately fed reverse itself\(\:.\) RNN is an approach that is often applied in DL. Nevertheless, RNN acquires a slanting disappearance gradient exploding problem. At the same time, the memory unit in the LSTM can choose which data must be saved in memory and at which time it must be deleted. Therefore, LSTM can effectively deal with the problems of training challenges and gradient disappearance by mine time-series with intervals in the time-series and relatively larger intervals. There are three layers in a standard LSTM model architecture: hidden loop, output, and input. The cyclic HL, by comparison with the traditional RNN, generally contains neuron nodes. Memory units assist as the initial module of the LSTM cyclic HLs. Forget, input and output gates are the three adaptive multiplication gate components enclosed in this memory unit. All neuron nodes of the LSTM perform the succeeding computation: The input gate was fixed at \(\:t\:th\) time according to the output result \(\:{h}_{t-1}\) of the component at the time in question and is specified in Eq. (5). The input \(\:{x}_{t}\) accurate time is based on whether to include a computation to upgrade the present data inside the cell.
$$\:{i}_{t}={\upsigma\:}\left({W}_{t}\cdot\:\left[{h}_{t-1},\:{x}_{t}\right]+{b}_{t}\right)$$
(5)
A forget gate defines whether to preserve or delete the data according to the additional new HL output and the present-time input specified in Eq. (6).
$$\:{f}_{\tau\:}={\upsigma\:}\left({W}_{f}\cdot\:\left[{h}_{t-1},{x}_{\tau\:}\right]+{b}_{f}\right)$$
(6)
The preceding output outcome \(\:{h}_{t-1}\) of the HL-LSTM cell establishes the value of the present candidate cell of memory and the present input data \(\:{x}_{t}\). * refers to element-to-element matrix multiplication. The value of memory cell state \(\:{C}_{t}\) adjusts the present candidate cell \(\:{C}_{t}\) and its layer \(\:{c}_{t-1}\) forget and input gates. These values of the memory cell layer are provided in Eq. (7) and Eq. (8).
$$\:{\overline{C}}_{\text{t}}=tanh\left({W}_{C}\cdot\:\left[{h}_{t-1},\:{x}_{t}\right]+{b}_{C}\right)$$
(7)
$$\:{C}_{t}={f}_{t}\bullet\:{C}_{t-1}+{i}_{t}\bullet\:\overline{C}$$
(8)
Output gate \(\:{\text{o}}_{t}\) is established as exposed in Eq. (9) and is applied to control the cell position value. The last cell’s outcome is \(\:{h}_{t}\), inscribed as Eq. (10).
$$\:{o}_{t}={\upsigma\:}\left({W}_{o}\cdot\:\left[{h}_{t-1},\:{x}_{t}\right]+{b}_{o}\right)$$
(9)
$$\:{h}_{t}={\text{o}}_{t}\bullet\:tanh\left({C}_{t}\right)$$
(10)
The forward and backward LSTM networks constitute the BiLSTM. Either the forward or the backward LSTM HLs are responsible for removing characteristics; the layer of forward removes features in the forward directions. The Bi-LSTM approach is applied to consider the effects of all features before or after the sequence data. Therefore, more comprehensive feature information is developed. Bi‐LSTM’s present state comprises either forward or backward output, and they are specified in Eq. (11), Eq. (12), and Eq. (13)
$$\:h_{t}^{{forward}} = LSTM^{{forward}} (h_{{t – 1}} ,\:x_{t} ,\:C_{{t – 1}} )$$
(11)
$$\:{h}_{\tau\:}^{backwar\text{d}}=LST{M}^{backwar\text{d}}\left({h}_{t-1},{x}_{t},\:{C}_{t-1}\right)$$
(12)
$$\:{H}_{T}={h}_{t}^{forward},\:{h}_{\tau\:}^{backwar\text{d}}$$
(13)
Hyperparameter tuning using the HHO model
The HHO methodology utilizes the HHODLM-SLR methodology for accomplishing the hyperparameter tuning process41. This model is employed due to its robust global search capability and adaptive behaviour inspired by the cooperative hunting strategy of Harris hawks. Unlike grid or random search, which can be time-consuming and inefficient, HHO dynamically balances exploration and exploitation to find optimal hyperparameter values. It avoids local minima and accelerates convergence, enhancing the performance and stability of the model. Compared to other metaheuristics, such as PSO or GA, HHO presents faster convergence and fewer tunable parameters. Its bio-inspired nature makes it appropriate for complex, high-dimensional optimization tasks in DL models. Figure 5 depicts the flow of the HHO methodology.

Workflow of the HHO technique.
The HHO model is a bio-inspired technique depending on Harris Hawks’ behaviour. This model was demonstrated through the exploitation or exploration levels. At the exploration level, the HHO may track and detect prey with its effectual eyes. Depending upon its approach, HHO can arbitrarily stay in a few positions and wait to identify prey. Suppose there is an equal chance deliberated for every perched approach depending on the family member’s position. In that case, it might be demonstrated as condition \(\:q<0.5\) or landed at a random position in the trees as \(\:q\ge\:0.5\), which is given by Eq. (14).
$$\:X\left(t+1\right)=\left\{\begin{array}{l}{X}_{rnd}\left(t\right)-{r}_{1}\left|{X}_{rnd}\left(t\right)-2{r}_{2}X\left(t\right)\right|,\:q\ge\:0.5\\\:{X}_{rab}\left(t\right)-{X}_{m}\left(t\right)-r3\left(LB+{r}_{4}\left(UB-LB\right)\right),q<0.5\end{array}\right.$$
(14)
The average location is computed by the Eq. (15).
$$\:{X}_{m}\left(t\right)=\frac{1}{N}{\sum\:}_{i=1}^{N}{X}_{i}\left(t\right)$$
(15)
The movement from exploration to exploitation, while prey escapes, is energy loss.
$$\:E=2{E}_{0}\left(1-\frac{t}{T}\right)$$
(16)
The parameter \(\:E\) signifies the prey’s escape energy, and \(\:T\) represents the maximum iteration counts. Conversely, \(\:{E}_{0}\) denotes a random parameter that swings among \(\:(-\text{1,1})\) for every iteration.
The exploitation level is divided into hard and soft besieges. The surroundings \(\:\left|E\right|\ge\:0.5\) and \(\:r\ge\:0.5\) should be met in a soft besiege. Prey aims to escape through certain arbitrary jumps but eventually fails.
$$\:\begin{array}{c}X\left(t+1\right)=\Delta X\left(t\right)-E\left|J{X}_{rabb}\left(t\right)-X\left(t\right)\right|\:where\\\:\Delta X\left(t\right)={X}_{rabb}\left(t\right)-X\left(t\right)\end{array}$$
(17)
\(\:\left|E\right|<0.5\) and \(\:r\ge\:0.5\) should meet during the hard besiege. The prey attempts to escape. This position is upgraded based on the Eq. (18).
$$\:X\left(t+1\right)={X}_{rabb}\left(t\right)-E\left|\varDelta\:X\left(t\right)\right|$$
(18)
The HHO model originates from a fitness function (FF) to achieve boosted classification performance. It outlines an optimistic number to embody the better outcome of the candidate solution. The minimization of the classifier error ratio was reflected as FF. Its mathematical formulation is represented in Eq. (19).
$$\begin{gathered} fitness\left( {x_{i} } \right) = ClassifierErrorRate\left( {x_{i} } \right)\: \hfill \\ \quad \quad \quad \quad \quad\,\,\, = \frac{{number\:of\:misclassified\:samples}}{{Total\:number\:of\:samples}} \times \:100 \hfill \\ \end{gathered}$$
(19)













AI Insights
How an Artificial Intelligence (AI) Software Development Company Turns Bold Ideas into Measurable Impact

Artificial intelligence is no longer confined to research labs or Silicon Valley boardrooms. It’s quietly running in the background when your bank flags a suspicious transaction, when your streaming service recommends the perfect Friday-night movie, or when a warehouse robot picks and packs your order faster than a human could.
For businesses, the challenge is not whether to adopt AI. It’s how to do it well. Turning raw data and algorithms into profitable, efficient, and scalable solutions requires more than curiosity. It calls for a dedicated artificial intelligence (AI) software development company — a partner that blends technical mastery, industry insight, and creative problem-solving into a clear path from concept to reality.
Why Businesses Lean on AI Development Experts
The AI landscape is moving at breakneck speed. A new framework, algorithm, or hardware optimization can make yesterday’s cutting-edge solution feel outdated overnight. Keeping up internally often means diverting resources from your core business. And that’s where specialists step in.
- Navigating complexity: Modern artificial intelligence systems aren’t plug-and-play. They involve layers of machine learning models, vast datasets, and intricate integrations. A seasoned partner knows the pitfalls and how to avoid them.
- Bespoke over “one-size-fits-all”: Off-the-shelf AI products can feel like wearing a suit that almost fits. Custom-built solutions mould perfectly to a business’s data, workflows, and goals.
- Accelerating results: Time is money. An experienced AI team brings established workflows, pre-built tools, and domain expertise to slash development time and hit the market faster.
The right development company doesn’t just deliver code; it delivers confidence, clarity, and a competitive edge.
What an AI Software Development Company Really Does
Imagine a workshop where engineers, data scientists, and business analysts work side-by-side, not just building tools but engineering transformation. That’s the reality inside a high-performing AI development company.
Custom AI solutions
Predictive analytics solutions that spot market trends before they peak, computer vision systems that inspect thousands of products per hour, or natural language processing (NLP) engines that handle customer queries with human-like understanding, the work is always tailored to the problem at hand.
System integration
Artificial intelligence is most powerful when it blends seamlessly into the systems you already rely on (from ERP platforms to IoT networks), creating a fluid, interconnected digital ecosystem.
Data engineering
AI feeds on data, but only clean, structured, and relevant data delivers results. Development teams collect, filter, and organize information into a form that algorithms can actually learn from.
Continuous optimization
AI isn’t a “set it and forget it” investment. Models drift, business needs evolve, and market conditions change. Continuous monitoring and retraining ensure the system stays sharp.
The Services That Power AI Transformation
A top-tier AI development partner wears many hats — consultant, architect, integrator, and caretaker — ensuring every stage of the AI journey is covered.
AI consulting
Before writing a single line of code, consultants assess your readiness, map potential use cases, and create a strategic roadmap to minimize risk and maximize ROI.
Model development
From supervised learning models that predict customer churn to reinforcement learning algorithms that teach autonomous systems to make decisions, this is where the real magic happens.
LLM deployment
Implementing large language models fine-tuned for industry-specific needs, e.g., for automated report generation, advanced customer service chatbots, or multilingual content creation. LLM deployment is as much about optimization and cost control as it is about raw capability.
AI agents development
Building autonomous, task-driven agents that can plan, decide, and act with minimal human input. From scheduling complex workflows to managing dynamic, real-time data feeds, digital agents are the bridge between intelligence and action.
AI integration
The best artificial intelligence isn’t a separate tool; it’s woven into your existing platforms. Imagine your CRM not just storing customer data but predicting which leads are most likely to convert.
Maintenance and support
AI models are like high-performance cars; they need regular tuning. Post-launch support ensures they continue to perform at peak efficiency.
The AI Implementation Process
Every successful AI project follows a deliberate and well-structured path. Following a proven AI implementation process, you can keep projects focused, transparent, and measurable.
- Discovery and goal setting: Clarify the “why” before tackling the “how.” What problem are we solving? How will success be measured?
- Data preparation: Gather datasets, clean them of inconsistencies, and label them so the AI understands the patterns it’s being trained on.
- Model selection and training: Choose algorithms suited to the challenge — whether that’s a neural network for image recognition or a gradient boosting model for risk scoring.
- Testing and validation: Rigorously test against real-world conditions to ensure accuracy, scalability, and fairness.
- Deployment and integration: Roll out AI into the live environment, integrating it with existing workflows and tools.
- Monitoring and continuous improvement: Keep a pulse on performance, retraining when needed, and adapting to evolving business goals.
Industries Seeing the Biggest Wins from AI
While every sector can find value in AI, some industries are already reaping transformative benefits.
- Healthcare: AI is helping radiologists detect anomalies in scans, predicting patient risks, and even accelerating the search for new treatments.
- Finance: Beyond fraud detection, AI models are powering real-time risk analysis and automating compliance, saving both time and reputation.
- Retail and eCommerce: Personalized product recommendations, demand forecasting, and dynamic pricing are reshaping the customer experience.
- Manufacturing: AI-driven predictive maintenance prevents costly downtime, while computer vision ensures every product meets quality standards.
- Logistics: From route optimization to real-time fleet tracking, AI keeps goods moving efficiently.
Choosing the Right AI Development Partner
Not all AI partners are created equal. The best ones act as an extension of your team, translating business goals into technical blueprints and technical solutions into business outcomes. Look for:
- Proven technical mastery — experience in your industry and with the AI technologies you need.
- Room to grow — scalable solutions that expand with your data and ambitions.
- Security at the core — a partner who treats data protection and compliance as non-negotiable.
- Clear communication — transparent reporting, realistic timelines, and a commitment to keeping you informed at every stage.
Artificial intelligence has become the driving force behind modern business competitiveness, but it doesn’t run on autopilot. Behind every successful deployment is a team that knows how to design, train, and fine-tune systems to meet the realities of a specific industry.
A reliable artificial intelligence software development company is more than a vendor; it’s a long-term partner. It shapes AI into a tool that fits seamlessly into daily operations, strengthens a company’s existing capabilities, and evolves in step with changing demands.
In the end, AI’s true potential comes from the interplay between human expertise and machine intelligence. The companies that invest in that partnership now won’t merely adapt to the future. They’ll set its direction.

The latest ambition of artificial intelligence research — particularly within the labs seeking “artificial general intelligence,” or AGI — is something called a world model: a representation of the environment that an AI carries around inside itself like a computational snow globe. The AI system can use this simplified representation to evaluate predictions and decisions before applying them to its real-world tasks. The deep learning luminaries Yann LeCun (of Meta), Demis Hassabis (of Google DeepMind) and Yoshua Bengio (of Mila, the Quebec Artificial Intelligence Institute) all believe world models are essential for building AI systems that are truly smart, scientific and safe.
The fields of psychology, robotics and machine learning have each been using some version of the concept for decades. You likely have a world model running inside your skull right now — it’s how you know not to step in front of a moving train without needing to run the experiment first.
So does this mean that AI researchers have finally found a core concept whose meaning everyone can agree upon? As a famous physicist once wrote: Surely you’re joking. A world model may sound straightforward — but as usual, no one can agree on the details. What gets represented in the model, and to what level of fidelity? Is it innate or learned, or some combination of both? And how do you detect that it’s even there at all?
It helps to know where the whole idea started. In 1943, a dozen years before the term “artificial intelligence” was coined, a 29-year-old Scottish psychologist named Kenneth Craik published an influential monograph in which he mused that “if the organism carries a ‘small-scale model’ of external reality … within its head, it is able to try out various alternatives, conclude which is the best of them … and in every way to react in a much fuller, safer, and more competent manner.” Craik’s notion of a mental model or simulation presaged the “cognitive revolution” that transformed psychology in the 1950s and still rules the cognitive sciences today. What’s more, it directly linked cognition with computation: Craik considered the “power to parallel or model external events” to be “the fundamental feature” of both “neural machinery” and “calculating machines.”
The nascent field of artificial intelligence eagerly adopted the world-modeling approach. In the late 1960s, an AI system called SHRDLU wowed observers by using a rudimentary “block world” to answer commonsense questions about tabletop objects, like “Can a pyramid support a block?” But these handcrafted models couldn’t scale up to handle the complexity of more realistic settings. By the late 1980s, the AI and robotics pioneer Rodney Brooks had given up on world models completely, famously asserting that “the world is its own best model” and “explicit representations … simply get in the way.”
It took the rise of machine learning, especially deep learning based on artificial neural networks, to breathe life back into Craik’s brainchild. Instead of relying on brittle hand-coded rules, deep neural networks could build up internal approximations of their training environments through trial and error and then use them to accomplish narrowly specified tasks, such as driving a virtual race car. In the past few years, as the large language models behind chatbots like ChatGPT began to demonstrate emergent capabilities that they weren’t explicitly trained for — like inferring movie titles from strings of emojis, or playing the board game Othello — world models provided a convenient explanation for the mystery. To prominent AI experts such as Geoffrey Hinton, Ilya Sutskever and Chris Olah, it was obvious: Buried somewhere deep within an LLM’s thicket of virtual neurons must lie “a small-scale model of external reality,” just as Craik imagined.
The truth, at least so far as we know, is less impressive. Instead of world models, today’s generative AIs appear to learn “bags of heuristics”: scores of disconnected rules of thumb that can approximate responses to specific scenarios, but don’t cohere into a consistent whole. (Some may actually contradict each other.) It’s a lot like the parable of the blind men and the elephant, where each man only touches one part of the animal at a time and fails to apprehend its full form. One man feels the trunk and assumes the entire elephant is snakelike; another touches a leg and guesses it’s more like a tree; a third grasps the elephant’s tail and says it’s a rope. When researchers attempt to recover evidence of a world model from within an LLM — for example, a coherent computational representation of an Othello game board — they’re looking for the whole elephant. What they find instead is a bit of snake here, a chunk of tree there, and some rope.
Of course, such heuristics are hardly worthless. LLMs can encode untold sackfuls of them within their trillions of parameters — and as the old saw goes, quantity has a quality all its own. That’s what makes it possible to train a language model to generate nearly perfect directions between any two points in Manhattan without learning a coherent world model of the entire street network in the process, as researchers from Harvard University and the Massachusetts Institute of Technology recently discovered.
So if bits of snake, tree and rope can do the job, why bother with the elephant? In a word, robustness: When the researchers threw their Manhattan-navigating LLM a mild curveball by randomly blocking 1% of the streets, its performance cratered. If the AI had simply encoded a street map whose details were consistent — instead of an immensely complicated, corner-by-corner patchwork of conflicting best guesses — it could have easily rerouted around the obstructions.
Given the benefits that even simple world models can confer, it’s easy to understand why every large AI lab is desperate to develop them — and why academic researchers are increasingly interested in scrutinizing them, too. Robust and verifiable world models could uncover, if not the El Dorado of AGI, then at least a scientifically plausible tool for extinguishing AI hallucinations, enabling reliable reasoning, and increasing the interpretability of AI systems.
That’s the “what” and “why” of world models. The “how,” though, is still anyone’s guess. Google DeepMind and OpenAI are betting that with enough “multimodal” training data — like video, 3D simulations, and other input beyond mere text — a world model will spontaneously congeal within a neural network’s statistical soup. Meta’s LeCun, meanwhile, thinks that an entirely new (and non-generative) AI architecture will provide the necessary scaffolding. In the quest to build these computational snow globes, no one has a crystal ball — but the prize, for once, may just be worth the AGI hype.

In March, we told you to stay focused on objective economic data, rather than the headlines, in order to make the best decisions for your company amid uncertainty. That is still true. But as the issues facing the economy have changed in the last six months, it is important to adjust what data your firm is looking at as you plan for both the short and long term.
-

 Business4 days ago
Business4 days agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-
Tools & Platforms3 weeks ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy1 month ago
Ethics & Policy1 month agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences3 months ago
Events & Conferences3 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers2 months ago
Jobs & Careers2 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Funding & Business2 months ago
Funding & Business2 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries
-

 Education2 months ago
Education2 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Education2 months ago
Education2 months agoAERDF highlights the latest PreK-12 discoveries and inventions
-

 Education2 months ago
Education2 months agoMacron says UK and France have duty to tackle illegal migration ‘with humanity, solidarity and firmness’ – UK politics live | Politics