Books, Courses & Certifications
Build a just-in-time knowledge base with Amazon Bedrock
Software as a service (SaaS) companies managing multiple tenants face a critical challenge: efficiently extracting meaningful insights from vast document collections while controlling costs. Traditional approaches often lead to unnecessary spending on unused storage and processing resources, impacting both operational efficiency and profitability. Organizations need solutions that intelligently scale processing and storage resources based on actual tenant usage patterns while maintaining data isolation. Traditional Retrieval Augmented Generation (RAG) systems consume valuable resources by ingesting and maintaining embeddings for documents that might never be queried, resulting in unnecessary storage costs and reduced system efficiency. Systems designed to handle large amounts of small to mid-sized tenants can exceed cost structure and infrastructure limits or might need to use silo-style deployments to keep each tenant’s information and usage separate. Adding to this complexity, many projects are transitory in nature, with work being completed on an intermittent basis, leading to data occupying space in knowledge base systems that could be used by other active tenants.
To address these challenges, this post presents a just-in-time knowledge base solution that reduces unused consumption through intelligent document processing. The solution processes documents only when needed and automatically removes unused resources, so organizations can scale their document repositories without proportionally increasing infrastructure costs.
With a multi-tenant architecture with configurable limits per tenant, service providers can offer tiered pricing models while maintaining strict data isolation, making it ideal for SaaS applications serving multiple clients with varying needs. Automatic document expiration through Time-to-Live (TTL) makes sure the system remains lean and focused on relevant content, while refreshing the TTL for frequently accessed documents maintains optimal performance for information that matters. This architecture also makes it possible to limit the number of files each tenant can ingest at a specific time and the rate at which tenants can query a set of files.This solution uses serverless technologies to alleviate operational overhead and provide automatic scaling, so teams can focus on business logic rather than infrastructure management. By organizing documents into groups with metadata-based filtering, the system enables contextual querying that delivers more relevant results while maintaining security boundaries between tenants.The architecture’s flexibility supports customization of tenant configurations, query rates, and document retention policies, making it adaptable to evolving business requirements without significant rearchitecting.
Solution overview
This architecture combines several AWS services to create a cost-effective, multi-tenant knowledge base solution that processes documents on demand. The key components include:
- Vector-based knowledge base – Uses Amazon Bedrock and Amazon OpenSearch Serverless for efficient document processing and querying
- On-demand document ingestion – Implements just-in-time processing using the Amazon Bedrock CUSTOM data source type
- TTL management – Provides automatic cleanup of unused documents using the TTL feature in Amazon DynamoDB
- Multi-tenant isolation – Enforces secure data separation between users and organizations with configurable resource limits
The solution enables granular control through metadata-based filtering at the user, tenant, and file level. The DynamoDB TTL tracking system supports tiered pricing structures, where tenants can pay for different TTL durations, document ingestion limits, and query rates.
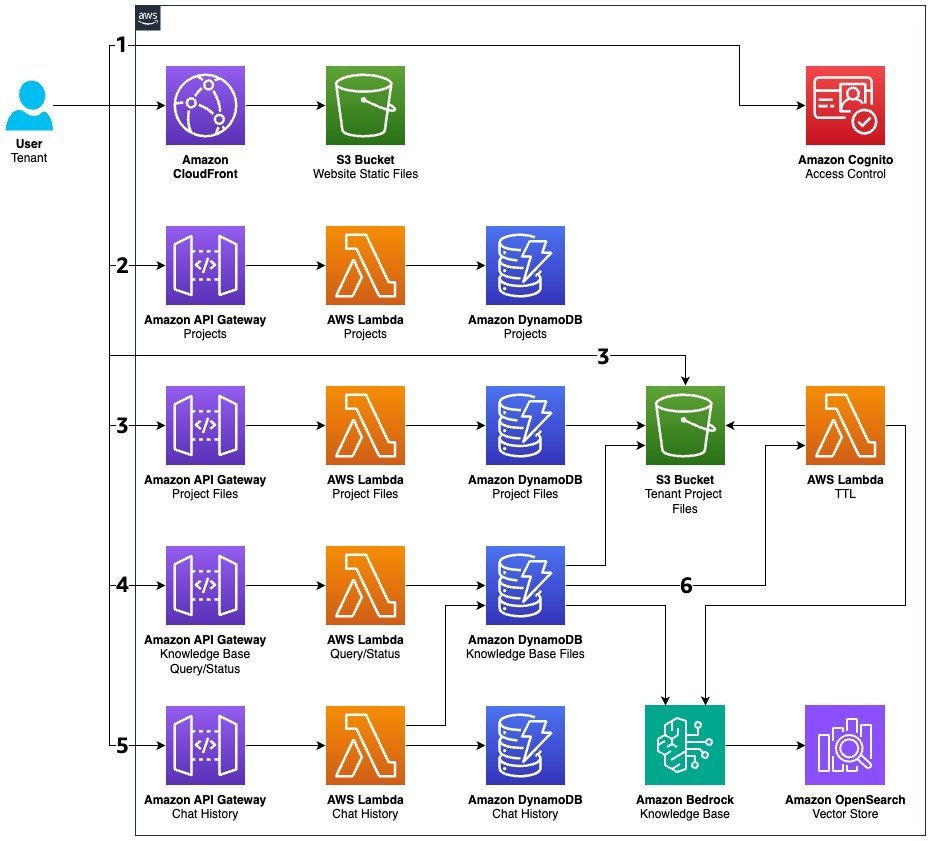
The following diagram illustrates the key components and workflow of the solution.
The workflow consists of the following steps:
- The user logs in to the system, which attaches a tenant ID to the current user for calls to the Amazon Bedrock knowledge base. This authentication step is crucial because it establishes the security context and makes sure subsequent interactions are properly associated with the correct tenant. The tenant ID becomes the foundational piece of metadata that enables proper multi-tenant isolation and resource management throughout the entire workflow.
- After authentication, the user creates a project that will serve as a container for the files they want to query. This project creation step establishes the organizational structure needed to manage related documents together. The system generates appropriate metadata and creates the necessary database entries to track the project’s association with the specific tenant, enabling proper access control and resource management at the project level.
- With a project established, the user can begin uploading files. The system manages this process by generating pre-signed URLs for secure file upload. As files are uploaded, they are stored in Amazon Simple Storage Service (Amazon S3), and the system automatically creates entries in DynamoDB that associate each file with both the project and the tenant. This three-way relationship (file-project-tenant) is essential for maintaining proper data isolation and enabling efficient querying later.
- When a user requests to create a chat with a knowledge base for a specific project, the system begins ingesting the project files using the CUSTOM data source. This is where the just-in-time processing begins. During ingestion, the system applies a TTL value based on the tenant’s tier-specific TTL interval. The TTL makes sure project files remain available during the chat session while setting up the framework for automatic cleanup later. This step represents the core of the on-demand processing strategy, because files are only processed when they are needed.
- Each chat session actively updates the TTL for the project files being used. This dynamic TTL management makes sure frequently accessed files remain in the knowledge base while allowing rarely used files to expire naturally. The system continually refreshes the TTL values based on actual usage, creating an efficient balance between resource availability and cost optimization. This approach maintains optimal performance for actively used content while helping to prevent resource waste on unused documents.
- After the chat session ends and the TTL value expires, the system automatically removes files from the knowledge base. This cleanup process is triggered by Amazon DynamoDB Streams monitoring TTL expiration events, which activate an AWS Lambda function to remove the expired documents. This final step reduces the load on the underlying OpenSearch Serverless cluster and optimizes system resources, making sure the knowledge base remains lean and efficient.
Prerequisites
You need the following prerequisites before you can proceed with solution. For this post, we use the us-east-1 AWS Region.
Deploy the solution
Complete the following steps to deploy the solution:
- Download the AWS CDK project from the GitHub repo.
- Install the project dependencies:
- Deploy the solution:
- Create a user and log in to the system after validating your email.
Validate the knowledge base and run a query
Before allowing users to chat with their documents, the system performs the following steps:
- Performs a validation check to determine if documents need to be ingested. This process happens transparently to the user and includes checking document status in DynamoDB and the knowledge base.
- Validates that the required documents are successfully ingested and properly indexed before allowing queries.
- Returns both the AI-generated answers and relevant citations to source documents, maintaining traceability and empowering users to verify the accuracy of responses.
The following screenshot illustrates an example of chatting with the documents.

Looking at the following example method for file ingestion, note how file information is stored in DynamoDB with a TTL value for automatic expiration. The ingest knowledge base documents call includes essential metadata (user ID, tenant ID, and project), enabling precise filtering of this tenant’s files in subsequent operations.
During a query, you can use the associated metadata to construct parameters that make sure you only retrieve files belonging to this specific tenant. For example:
Manage the document lifecycle with TTL
To further optimize resource usage and costs, you can implement an intelligent document lifecycle management system using the DynamoDB (TTL) feature. This consists of the following steps:
- When a document is ingested into the knowledge base, a record is created with a configurable TTL value.
- This TTL is refreshed when the document is accessed.
- DynamoDB Streams with specific filters for TTL expiration events is used to trigger a cleanup Lambda function.
- The Lambda function removes expired documents from the knowledge base.
See the following code:
Multi-tenant isolation with tiered service levels
Our architecture enables sophisticated multi-tenant isolation with tiered service levels:
- Tenant-specific document filtering – Each query includes user, tenant, and file-specific filters, allowing the system to reduce the number of documents being queried.
- Configurable TTL values – Different tenant tiers can have different TTL configurations. For example:
- Free tier: Five documents ingested with a 7-day TTL and five queries per minute.
- Standard tier: 100 documents ingested with a 30-day TTL and 10 queries per minute.
- Premium tier: 1,000 documents ingested with a 90-day TTL and 50 queries per minute.
- You can configure additional limits, such as total queries per month or total ingested files per day or month.
Clean up
To clean up the resources created in this post, run the following command from the same location where you performed the deploy step:
Conclusion
The just-in-time knowledge base architecture presented in this post transforms document management across multiple tenants by processing documents only when queried, reducing the unused consumption of traditional RAG systems. This serverless implementation uses Amazon Bedrock, OpenSearch Serverless, and the DynamoDB TTL feature to create a lean system with intelligent document lifecycle management, configurable tenant limits, and strict data isolation, which is essential for SaaS providers offering tiered pricing models.
This solution directly addresses cost structure and infrastructure limitations of traditional systems, particularly for deployments handling numerous small to mid-sized tenants with transitory projects. This architecture combines on-demand document processing with automated lifecycle management, delivering a cost-effective, scalable resource that empowers organizations to focus on extracting insights rather than managing infrastructure, while maintaining security boundaries between tenants.
Ready to implement this architecture? The full sample code is available in the GitHub repository.
About the author
 Steven Warwick is a Senior Solutions Architect at AWS, where he leads customer engagements to drive successful cloud adoption and specializes in SaaS architectures and Generative AI solutions. He produces educational content including blog posts and sample code to help customers implement best practices, and has led programs on GenAI topics for solution architects. Steven brings decades of technology experience to his role, helping customers with architectural reviews, cost optimization, and proof-of-concept development.
Steven Warwick is a Senior Solutions Architect at AWS, where he leads customer engagements to drive successful cloud adoption and specializes in SaaS architectures and Generative AI solutions. He produces educational content including blog posts and sample code to help customers implement best practices, and has led programs on GenAI topics for solution architects. Steven brings decades of technology experience to his role, helping customers with architectural reviews, cost optimization, and proof-of-concept development.
Books, Courses & Certifications
Schedule topology-aware workloads using Amazon SageMaker HyperPod task governance

Today, we are excited to announce a new capability of Amazon SageMaker HyperPod task governance to help you optimize training efficiency and network latency of your AI workloads. SageMaker HyperPod task governance streamlines resource allocation and facilitates efficient compute resource utilization across teams and projects on Amazon Elastic Kubernetes Service (Amazon EKS) clusters. Administrators can govern accelerated compute allocation and enforce task priority policies, improving resource utilization. This helps organizations focus on accelerating generative AI innovation and reducing time to market, rather than coordinating resource allocation and replanning tasks. Refer to Best practices for Amazon SageMaker HyperPod task governance for more information.
Generative AI workloads typically demand extensive network communication across Amazon Elastic Compute Cloud (Amazon EC2) instances, where network bandwidth impacts both workload runtime and processing latency. The network latency of these communications depends on the physical placement of instances within a data center’s hierarchical infrastructure. Data centers can be organized into nested organizational units such as network nodes and node sets, with multiple instances per network node and multiple network nodes per node set. For example, instances within the same organizational unit experience faster processing time compared to those across different units. This means fewer network hops between instances results in lower communication.
To optimize the placement of your generative AI workloads in your SageMaker HyperPod clusters by considering the physical and logical arrangement of resources, you can use EC2 network topology information during your job submissions. An EC2 instance’s topology is described by a set of nodes, with one node in each layer of the network. Refer to How Amazon EC2 instance topology works for details on how EC2 topology is arranged. Network topology labels offer the following key benefits:
- Reduced latency by minimizing network hops and routing traffic to nearby instances
- Improved training efficiency by optimizing workload placement across network resources
With topology-aware scheduling for SageMaker HyperPod task governance, you can use topology network labels to schedule your jobs with optimized network communication, thereby improving task efficiency and resource utilization for your AI workloads.
In this post, we introduce topology-aware scheduling with SageMaker HyperPod task governance by submitting jobs that represent hierarchical network information. We provide details about how to use SageMaker HyperPod task governance to optimize your job efficiency.
Solution overview
Data scientists interact with SageMaker HyperPod clusters. Data scientists are responsible for the training, fine-tuning, and deployment of models on accelerated compute instances. It’s important to make sure data scientists have the necessary capacity and permissions when interacting with clusters of GPUs.
To implement topology-aware scheduling, you first confirm the topology information for all nodes in your cluster, then run a script that tells you which instances are on the same network nodes, and finally schedule a topology-aware training task on your cluster. This workflow facilitates higher visibility and control over the placement of your training instances.
In this post, we walk through viewing node topology information and submitting topology-aware tasks to your cluster. For reference, NetworkNodes describes the network node set of an instance. In each network node set, three layers comprise the hierarchical view of the topology for each instance. Instances that are closest to each other will share the same layer 3 network node. If there are no common network nodes in the bottom layer (layer 3), then see if there is commonality at layer 2.
Prerequisites
To get started with topology-aware scheduling, you must have the following prerequisites:
- An EKS cluster
- A SageMaker HyperPod cluster with instances enabled for topology information
- The SageMaker HyperPod task governance add-on installed (version 1.2.2 or later)
- Kubectl installed
- (Optional) The SageMaker HyperPod CLI installed
Get node topology information
Run the following command to show node labels in your cluster. This command provides network topology information for each instance.
Instances with the same network node layer 3 are as close as possible, following EC2 topology hierarchy. You should see a list of node labels that look like the following:topology.k8s.aws/network-node-layer-3: nn-33333exampleRun the following script to show the nodes in your cluster that are on the same layers 1, 2, and 3 network nodes:
The output of this script will print a flow chart that you can use in a flow diagram editor such as Mermaid.js.org to visualize the node topology of your cluster. The following figure is an example of the cluster topology for a seven-instance cluster.
Submit tasks
SageMaker HyperPod task governance offers two ways to submit tasks using topology awareness. In this section, we discuss these two options and a third alternative option to task governance.
Modify your Kubernetes manifest file
First, you can modify your existing Kubernetes manifest file to include one of two annotation options:
- kueue.x-k8s.io/podset-required-topology – Use this option if you must have all pods scheduled on nodes on the same network node layer in order to begin the job
- kueue.x-k8s.io/podset-preferred-topology – Use this option if you ideally want all pods scheduled on nodes in the same network node layer, but you have flexibility
The following code is an example of a sample job that uses the kueue.x-k8s.io/podset-required-topology setting to schedule pods that share the same layer 3 network node:
To verify which nodes your pods are running on, use the following command to view node IDs per pod:kubectl get pods -n hyperpod-ns-team-a -o wide
Use the SageMaker HyperPod CLI
The second way to submit a job is through the SageMaker HyperPod CLI. Be sure to install the latest version (version pending) to use topology-aware scheduling. To use topology-aware scheduling with the SageMaker HyperPod CLI, you can include either the --preferred-topology parameter or the --required-topology parameter in your create job command.
The following code is an example command to start a topology-aware mnist training job using the SageMaker HyperPod CLI, replace XXXXXXXXXXXX with your AWS account ID:
Clean up
If you deployed new resources while following this post, refer to the Clean Up section in the SageMaker HyperPod EKS workshop to make sure you don’t accrue unwanted charges.
Conclusion
During large language model (LLM) training, pod-to-pod communication distributes the model across multiple instances, requiring frequent data exchange between these instances. In this post, we discussed how SageMaker HyperPod task governance helps schedule workloads to enable job efficiency by optimizing throughput and latency. We also walked through how to schedule jobs using SageMaker HyperPod topology network information to optimize network communication latency for your AI tasks.
We encourage you to try out this solution and share your feedback in the comments section.
About the authors
 Nisha Nadkarni is a Senior GenAI Specialist Solutions Architect at AWS, where she guides companies through best practices when deploying large scale distributed training and inference on AWS. Prior to her current role, she spent several years at AWS focused on helping emerging GenAI startups develop models from ideation to production.
Nisha Nadkarni is a Senior GenAI Specialist Solutions Architect at AWS, where she guides companies through best practices when deploying large scale distributed training and inference on AWS. Prior to her current role, she spent several years at AWS focused on helping emerging GenAI startups develop models from ideation to production.
 Siamak Nariman is a Senior Product Manager at AWS. He is focused on AI/ML technology, ML model management, and ML governance to improve overall organizational efficiency and productivity. He has extensive experience automating processes and deploying various technologies.
Siamak Nariman is a Senior Product Manager at AWS. He is focused on AI/ML technology, ML model management, and ML governance to improve overall organizational efficiency and productivity. He has extensive experience automating processes and deploying various technologies.
 Zican Li is a Senior Software Engineer at Amazon Web Services (AWS), where he leads software development for Task Governance on SageMaker HyperPod. In his role, he focuses on empowering customers with advanced AI capabilities while fostering an environment that maximizes engineering team efficiency and productivity.
Zican Li is a Senior Software Engineer at Amazon Web Services (AWS), where he leads software development for Task Governance on SageMaker HyperPod. In his role, he focuses on empowering customers with advanced AI capabilities while fostering an environment that maximizes engineering team efficiency and productivity.
 Anoop Saha is a Sr GTM Specialist at Amazon Web Services (AWS) focusing on generative AI model training and inference. He partners with top frontier model builders, strategic customers, and AWS service teams to enable distributed training and inference at scale on AWS and lead joint GTM motions. Before AWS, Anoop held several leadership roles at startups and large corporations, primarily focusing on silicon and system architecture of AI infrastructure.
Anoop Saha is a Sr GTM Specialist at Amazon Web Services (AWS) focusing on generative AI model training and inference. He partners with top frontier model builders, strategic customers, and AWS service teams to enable distributed training and inference at scale on AWS and lead joint GTM motions. Before AWS, Anoop held several leadership roles at startups and large corporations, primarily focusing on silicon and system architecture of AI infrastructure.
Books, Courses & Certifications
How msg enhanced HR workforce transformation with Amazon Bedrock and msg.ProfileMap

This post is co-written with Stefan Walter from msg.
With more than 10,000 experts in 34 countries, msg is both an independent software vendor and a system integrator operating in highly regulated industries, with over 40 years of domain-specific expertise. msg.ProfileMap is a software as a service (SaaS) solution for skill and competency management. It’s an AWS Partner qualified software available on AWS Marketplace, currently serving more than 7,500 users. HR and strategy departments use msg.ProfileMap for project staffing and workforce transformation initiatives. By offering a centralized view of skills and competencies, msg.ProfileMap helps organizations map their workforce’s capabilities, identify skill gaps, and implement targeted development strategies. This supports more effective project execution, better alignment of talent to roles, and long-term workforce planning.
In this post, we share how msg automated data harmonization for msg.ProfileMap, using Amazon Bedrock to power its large language model (LLM)-driven data enrichment workflows, resulting in higher accuracy in HR concept matching, reduced manual workload, and improved alignment with compliance requirements under the EU AI Act and GDPR.
The importance of AI-based data harmonization
HR departments face increasing pressure to operate as data-driven organizations, but are often constrained by the inconsistent, fragmented nature of their data. Critical HR documents are unstructured, and legacy systems use mismatched formats and data models. This not only impairs data quality but also leads to inefficiencies and decision-making blind spots.Accurate and harmonized HR data is foundational for key activities such as matching candidates to roles, identifying internal mobility opportunities, conducting skills gap analysis, and planning workforce development. msg identified that without automated, scalable methods to process and unify this data, organizations would continue to struggle with manual overhead and inconsistent results.
Solution overview
HR data is typically scattered across diverse sources and formats, ranging from relational databases to Excel files, Word documents, and PDFs. Additionally, entities such as personnel numbers or competencies have different unique identifiers as well as different text descriptions, although with the same semantics. msg addressed this challenge with a modular architecture, tailored for IT workforce scenarios. As illustrated in the following diagram, at the core of msg.ProfileMap is a robust text extraction layer, which transforms heterogeneous inputs into structured data. This is then passed to an AI-powered harmonization engine that provides consistency across data sources by avoiding duplication and aligning disparate concepts.
The harmonization process uses a hybrid retrieval approach that combines vector-based semantic similarity and string-based matching techniques. These methods align incoming data with existing entities in the system. Amazon Bedrock is used to semantically enrich data, improving cross-source compatibility and matching precision. Extracted and enriched data is indexed and stored using Amazon OpenSearch Service and Amazon DynamoDB, facilitating fast and accurate retrieval, as shown in the following diagram.

The framework is designed to be unsupervised and domain independent. Although it’s optimized for IT workforce use cases, it has demonstrated strong generalization capabilities in other domains as well.
msg.ProfileMap is a cloud-based application that uses several AWS services, notably Amazon Neptune, Amazon DynamoDB, and Amazon Bedrock. The following diagram illustrates the full solution architecture.

Results and technical validation
msg evaluated the effectiveness of the data harmonization framework through internal testing on IT workforce concepts and external benchmarking in the Bio-ML Track of the Ontology Alignment Evaluation Initiative (OAEI), an international and EU-funded research initiative that evaluates ontology matching technologies since 2004.
During internal testing, the system processed 2,248 concepts across multiple suggestion types. High-probability merge recommendations reached 95.5% accuracy, covering nearly 60% of all inputs. This helped msg reduce manual validation workload by over 70%, significantly improving time-to-value for HR teams.
During OAEI 2024, msg.ProfileMap ranked at the top of the 2024 Bio-ML benchmark, outperforming other systems across multiple biomedical datasets. On NCIT-DOID, it achieved a 0.918 F1 score, with Hits@1 exceeding 92%, validating the engine’s generalizability beyond the HR domain. Additional details are available in the official test results.
Why Amazon Bedrock
msg relies on LLMs to semantically enrich data in near real time. These workloads require low-latency inference, flexible scaling, and operational simplicity. Amazon Bedrock met these needs by providing a fully managed, serverless interface to leading foundation models—without the need to manage infrastructure or deploy custom machine learning stacks.
Unlike hosting models on Amazon Elastic Compute Cloud (Amazon EC2) or Amazon SageMaker, Amazon Bedrock abstracts away provisioning, versioning, scaling, and model selection. Its consumption-based pricing aligns directly with msg’s SaaS delivery model—resources are used (and billed) only when needed. This simplified integration reduced overhead and helped msg scale elastically as customer demand grew.
Amazon Bedrock also helped msg meet compliance goals under the EU AI Act and GDPR by enabling tightly scoped, auditable interactions with model APIs—critical for HR use cases that handle sensitive workforce data.
Conclusion
msg’s successful integration of Amazon Bedrock into msg.ProfileMap demonstrates that large-scale AI adoption doesn’t require complex infrastructure or specialized model training. By combining modular design, ontology-based harmonization, and the fully managed LLM capabilities of Amazon Bedrock, msg delivered an AI-powered workforce intelligence platform that is accurate, scalable, and compliant.This solution improved concept match precision and achieved top marks in international AI benchmarks, demonstrating what’s possible when generative AI is paired with the right cloud-based service. With Amazon Bedrock, msg has built a platform that’s ready for today’s HR challenges—and tomorrow’s.
msg.ProfileMap is available as a SaaS offering on AWS Marketplace. If you are interested in knowing more, you can reach out to msg.hcm.backoffice@msg.group.
The content and opinions in this blog post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
About the authors
 Stefan Walter is Senior Vice President of AI SaaS Solutions at msg. With over 25 years of experience in IT software development, architecture, and consulting, Stefan Walter leads with a vision for scalable SaaS innovation and operational excellence. As a BU lead at msg, Stefan has spearheaded transformative initiatives that bridge business strategy with technology execution, especially in complex, multi-entity environments.
Stefan Walter is Senior Vice President of AI SaaS Solutions at msg. With over 25 years of experience in IT software development, architecture, and consulting, Stefan Walter leads with a vision for scalable SaaS innovation and operational excellence. As a BU lead at msg, Stefan has spearheaded transformative initiatives that bridge business strategy with technology execution, especially in complex, multi-entity environments.
 Gianluca Vegetti is a Senior Enterprise Architect in the AWS Partner Organization, aligned to Strategic Partnership Collaboration and Governance (SPCG) engagements. In his role, he supports the definition and execution of Strategic Collaboration Agreements with selected AWS partners.
Gianluca Vegetti is a Senior Enterprise Architect in the AWS Partner Organization, aligned to Strategic Partnership Collaboration and Governance (SPCG) engagements. In his role, he supports the definition and execution of Strategic Collaboration Agreements with selected AWS partners.
 Yuriy Bezsonov is a Senior Partner Solution Architect at AWS. With over 25 years in the tech, Yuriy has progressed from a software developer to an engineering manager and Solutions Architect. Now, as a Senior Solutions Architect at AWS, he assists partners and customers in developing cloud solutions, focusing on container technologies, Kubernetes, Java, application modernization, SaaS, developer experience, and GenAI. Yuriy holds AWS and Kubernetes certifications, and he is a recipient of the AWS Golden Jacket and the CNCF Kubestronaut Blue Jacket.
Yuriy Bezsonov is a Senior Partner Solution Architect at AWS. With over 25 years in the tech, Yuriy has progressed from a software developer to an engineering manager and Solutions Architect. Now, as a Senior Solutions Architect at AWS, he assists partners and customers in developing cloud solutions, focusing on container technologies, Kubernetes, Java, application modernization, SaaS, developer experience, and GenAI. Yuriy holds AWS and Kubernetes certifications, and he is a recipient of the AWS Golden Jacket and the CNCF Kubestronaut Blue Jacket.

In early 2024, a striking deepfake fraud case in Hong Kong brought the vulnerabilities of AI-driven deception into sharp relief. A finance employee was duped during a video call by what appeared to be the CFO—but was, in fact, a sophisticated AI-generated deepfake. Convinced of the call’s authenticity, the employee made 15 transfers totaling over $25 million to fraudulent bank accounts before realizing it was a scam.
This incident exemplifies more than just technological trickery—it signals how trust in what we see and hear can be weaponized, especially as AI becomes more deeply integrated into enterprise tools and workflows. From embedded LLMs in enterprise systems to autonomous agents diagnosing and even repairing issues in live environments, AI is transitioning from novelty to necessity. Yet as it evolves, so too do the gaps in our traditional security frameworks—designed for static, human-written code—revealing just how unprepared we are for systems that generate, adapt, and behave in unpredictable ways.
Beyond the CVE Mindset
Traditional secure coding practices revolve around known vulnerabilities and patch cycles. AI changes the equation. A line of code can be generated on the fly by a model, shaped by manipulated prompts or data—creating new, unpredictable categories of risk like prompt injection or emergent behavior outside traditional taxonomies.
A 2025 Veracode study found that 45% of all AI-generated code contained vulnerabilities, with common flaws like weak defenses against XSS and log injection. (Some languages performed more poorly than others. Over 70% of AI-generated Java code had a security issue, for instance.) Another 2025 study showed that repeated refinement can make things worse: After just five iterations, critical vulnerabilities rose by 37.6%.
To keep pace, frameworks like the OWASP Top 10 for LLMs have emerged, cataloging AI-specific risks such as data leakage, model denial of service, and prompt injection. They highlight how current security taxonomies fall short—and why we need new approaches that model AI threat surfaces, share incidents, and iteratively refine risk frameworks to reflect how code is created and influenced by AI.
Easier for Adversaries
Perhaps the most alarming shift is how AI lowers the barrier to malicious activity. What once required deep technical expertise can now be done by anyone with a clever prompt: generating scripts, launching phishing campaigns, or manipulating models. AI doesn’t just broaden the attack surface; it makes it easier and cheaper for attackers to succeed without ever writing code.
In 2025, researchers unveiled PromptLock, the first AI-powered ransomware. Though only a proof of concept, it showed how theft and encryption could be automated with a local LLM at remarkably low cost: about $0.70 per full attack using commercial APIs—and essentially free with open source models. That kind of affordability could make ransomware cheaper, faster, and more scalable than ever.
This democratization of offense means defenders must prepare for attacks that are more frequent, more varied, and more creative. The Adversarial ML Threat Matrix, founded by Ram Shankar Siva Kumar during his time at Microsoft, helps by enumerating threats to machine learning and offering a structured way to anticipate these evolving risks. (He’ll be discussing the difficulty of securing AI systems from adversaries at O’Reilly’s upcoming Security Superstream.)
Silos and Skill Gaps
Developers, data scientists, and security teams still work in silos, each with different incentives. Business leaders push for rapid AI adoption to stay competitive, while security leaders warn that moving too fast risks catastrophic flaws in the code itself.
These tensions are amplified by a widening skills gap: Most developers lack training in AI security, and many security professionals don’t fully understand how LLMs work. As a result, the old patchwork fixes feel increasingly inadequate when the models are writing and running code on their own.
The rise of “vibe coding”—relying on LLM suggestions without review—captures this shift. It accelerates development but introduces hidden vulnerabilities, leaving both developers and defenders struggling to manage novel risks.
From Avoidance to Resilience
AI adoption won’t stop. The challenge is moving from avoidance to resilience. Frameworks like Databricks’ AI Risk Framework (DASF) and the NIST AI Risk Management Framework provide practical guidance on embedding governance and security directly into AI pipelines, helping organizations move beyond ad hoc defenses toward systematic resilience. The goal isn’t to eliminate risk but to enable innovation while maintaining trust in the code AI helps produce.
Transparency and Accountability
Research shows AI-generated code is often simpler and more repetitive, but also more vulnerable, with risks like hardcoded credentials and path traversal exploits. Without observability tools such as prompt logs, provenance tracking, and audit trails, developers can’t ensure reliability or accountability. In other words, AI-generated code is more likely to introduce high-risk security vulnerabilities.
AI’s opacity compounds the problem: A function may appear to “work” yet conceal vulnerabilities that are difficult to trace or explain. Without explainability and safeguards, autonomy quickly becomes a recipe for insecure systems. Tools like MITRE ATLAS can help by mapping adversarial tactics against AI models, offering defenders a structured way to anticipate and counter threats.
Looking Ahead
Securing code in the age of AI requires more than patching—it means breaking silos, closing skill gaps, and embedding resilience into every stage of development. The risks may feel familiar, but AI scales them dramatically. Frameworks like Databricks’ AI Risk Framework (DASF) and the NIST AI Risk Management Framework provide structures for governance and transparency, while MITRE ATLAS maps adversarial tactics and real-world attack case studies, giving defenders a structured way to anticipate and mitigate threats to AI systems.
The choices we make now will determine whether AI becomes a trusted partner—or a shortcut that leaves us exposed.
-

 Business2 weeks ago
Business2 weeks agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-
Tools & Platforms1 month ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy2 months ago
Ethics & Policy2 months agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences4 months ago
Events & Conferences4 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers3 months ago
Jobs & Careers3 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Education3 months ago
Education3 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Education2 months ago
Education2 months agoMacron says UK and France have duty to tackle illegal migration ‘with humanity, solidarity and firmness’ – UK politics live | Politics
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi
-

 Funding & Business3 months ago
Funding & Business3 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries