Books, Courses & Certifications
Automate advanced agentic RAG pipeline with Amazon SageMaker AI
Retrieval Augmented Generation (RAG) is a fundamental approach for building advanced generative AI applications that connect large language models (LLMs) to enterprise knowledge. However, crafting a reliable RAG pipeline is rarely a one-shot process. Teams often need to test dozens of configurations (varying chunking strategies, embedding models, retrieval techniques, and prompt designs) before arriving at a solution that works for their use case. Furthermore, management of high-performing RAG pipeline involves complex deployment, with teams often using manual RAG pipeline management, leading to inconsistent results, time-consuming troubleshooting, and difficulty in reproducing successful configurations. Teams struggle with scattered documentation of parameter choices, limited visibility into component performance, and the inability to systematically compare different approaches. Additionally, the lack of automation creates bottlenecks in scaling the RAG solutions, increases operational overhead, and makes it challenging to maintain quality across multiple deployments and environments from development to production.
In this post, we walk through how to streamline your RAG development lifecycle from experimentation to automation, helping you operationalize your RAG solution for production deployments with Amazon SageMaker AI, helping your team experiment efficiently, collaborate effectively, and drive continuous improvement. By combining experimentation and automation with SageMaker AI, you can verify that the entire pipeline is versioned, tested, and promoted as a cohesive unit. This approach provides comprehensive guidance for traceability, reproducibility, and risk mitigation as the RAG system advances from development to production, supporting continuous improvement and reliable operation in real-world scenarios.
Solution overview
By streamlining both experimentation and operational workflows, teams can use SageMaker AI to rapidly prototype, deploy, and monitor RAG applications at scale. Its integration with SageMaker managed MLflow provides a unified platform for tracking experiments, logging configurations, and comparing results, supporting reproducibility and robust governance throughout the pipeline lifecycle. Automation also minimizes manual intervention, reduces errors, and streamlines the process of promoting the finalized RAG pipeline from the experimentation phase directly into production. With this approach, every stage from data ingestion to output generation operates efficiently and securely, while making it straightforward to transition validated solutions from development to production deployment.
For automation, Amazon SageMaker Pipelines orchestrates end-to-end RAG workflows from data preparation and vector embedding generation to model inference and evaluation all with repeatable and version-controlled code. Integrating continuous integration and delivery (CI/CD) practices further enhances reproducibility and governance, enabling automated promotion of validated RAG pipelines from development to staging or production environments. Promoting an entire RAG pipeline (not just an individual subsystem of the RAG solution like a chunking layer or orchestration layer) to higher environments is essential because data, configurations, and infrastructure can vary significantly across staging and production. In production, you often work with live, sensitive, or much larger datasets, and the way data is chunked, embedded, retrieved, and generated can impact system performance and output quality in ways that are not always apparent in lower environments. Each stage of the pipeline (chunking, embedding, retrieval, and generation) must be thoroughly evaluated with production-like data for accuracy, relevance, and robustness. Metrics at every stage (such as chunk quality, retrieval relevance, answer correctness, and LLM evaluation scores) must be monitored and validated before the pipeline is trusted to serve real users.
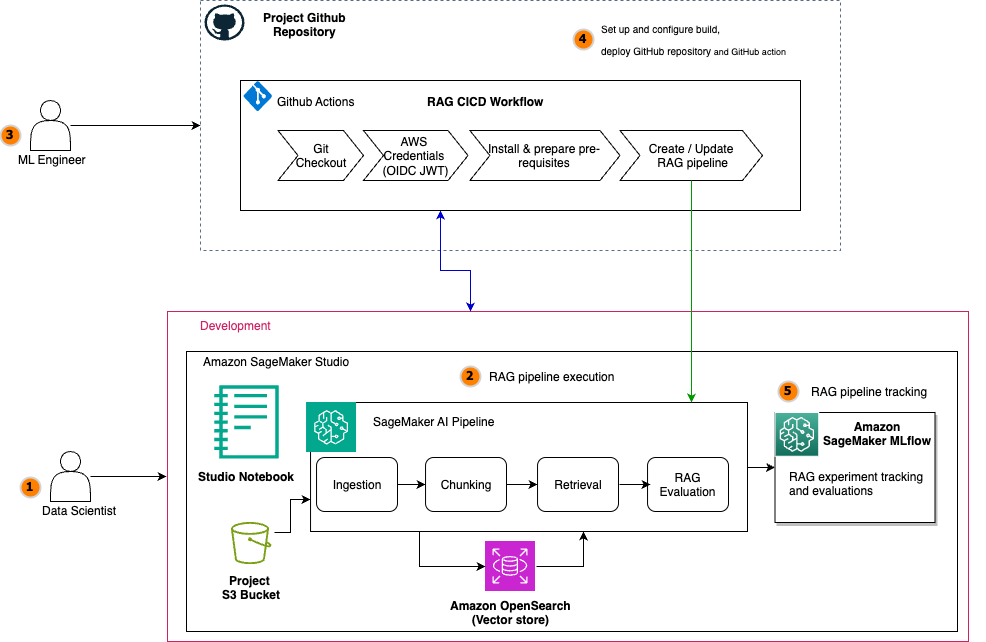
The following diagram illustrates the architecture of a scalable RAG pipeline built on SageMaker AI, with MLflow experiment tracking seamlessly integrated at every stage and the RAG pipeline automated using SageMaker Pipelines. SageMaker managed MLflow provides a unified platform for centralized RAG experiment tracking across all pipeline stages. Every MLflow execution run whether for RAG chunking, ingestion, retrieval, or evaluation sends execution logs, parameters, metrics, and artifacts to SageMaker managed MLflow. The architecture uses SageMaker Pipelines to orchestrate the entire RAG workflow through versioned, repeatable automation. These RAG pipelines manage dependencies between critical stages, from data ingestion and chunking to embedding generation, retrieval, and final text generation, supporting consistent execution across environments. Integrated with CI/CD practices, SageMaker Pipelines enable seamless promotion of validated RAG configurations from development to staging and production environments while maintaining infrastructure as code (IaC) traceability.
For the operational workflow, the solution follows a structured lifecycle: During experimentation, data scientists iterate on pipeline components within Amazon SageMaker Studio notebooks while SageMaker managed MLflow captures parameters, metrics, and artifacts at every stage. Validated workflows are then codified into SageMaker Pipelines and versioned in Git. The automated promotion phase uses CI/CD to trigger pipeline execution in target environments, rigorously validating stage-specific metrics (chunk quality, retrieval relevance, answer correctness) against production data before deployment. The other core components include:
- Amazon SageMaker JumpStart for accessing the latest LLM models and hosting them on SageMaker endpoints for model inference with the embedding model
huggingface-textembedding-all-MiniLM-L6-v2and text generation modeldeepseek-llm-r1-distill-qwen-7b. - Amazon OpenSearch Service as a vector database to store document embeddings with the OpenSearch index configured for k-nearest neighbors (k-NN) search.
- The Amazon Bedrock model
anthropic.claude-3-haiku-20240307-v1:0as an LLM-as-a-judge component for all the MLflow LLM evaluation metrics. - A SageMaker Studio notebook for a development environment to experiment and automate the RAG pipelines with SageMaker managed MLflow and SageMaker Pipelines.
You can implement this agentic RAG solution code from the GitHub repository. In the following sections, we use snippets from this code in the repository to illustrate RAG pipeline experiment evolution and automation.
Prerequisites
You must have the following prerequisites:
- An AWS account with billing enabled.
- A SageMaker AI domain. For more information, see Use quick setup for Amazon SageMaker AI.
- Access to a running SageMaker managed MLflow tracking server in SageMaker Studio. For more information, see the instructions for setting up a new MLflow tracking server.
- Access to SageMaker JumpStart to host LLM embedding and text generation models.
- Access to the Amazon Bedrock foundation models (FMs) for RAG evaluation tasks. For more details, see Subscribe to a model.
SageMaker MLFlow RAG experiment
SageMaker managed MLflow provides a powerful framework for organizing RAG experiments, so teams can manage complex, multi-stage processes with clarity and precision. The following diagram illustrates the RAG experiment stages with SageMaker managed MLflow experiment tracking at every stage. This centralized tracking offers the following benefits:
- Reproducibility: Every experiment is fully documented, so teams can replay and compare runs at any time
- Collaboration: Shared experiment tracking fosters knowledge sharing and accelerates troubleshooting
- Actionable insights: Visual dashboards and comparative analytics help teams identify the impact of pipeline changes and drive continuous improvement
The following diagram illustrates the solution workflow.
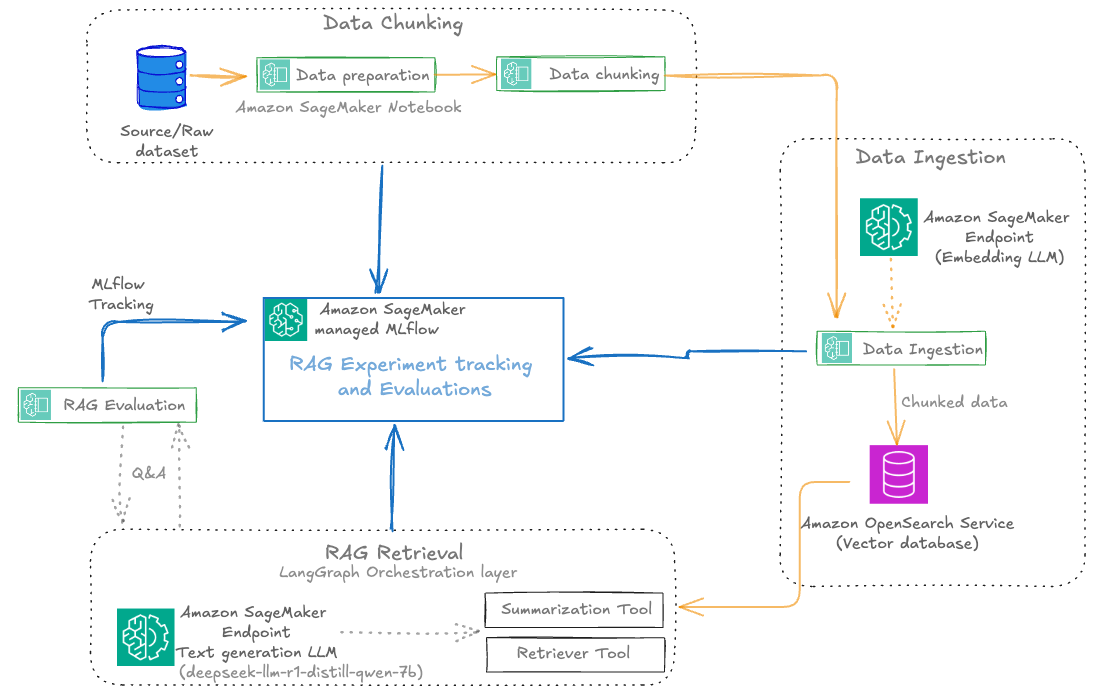
Each RAG experiment in MLflow is structured as a top-level run under a specific experiment name. Within this top-level run, nested runs are created for each major pipeline stage, such as data preparation, data chunking, data ingestion, RAG retrieval, and RAG evaluation. This hierarchical approach allows for granular tracking of parameters, metrics, and artifacts at every step, while maintaining a clear lineage from raw data to final evaluation results.
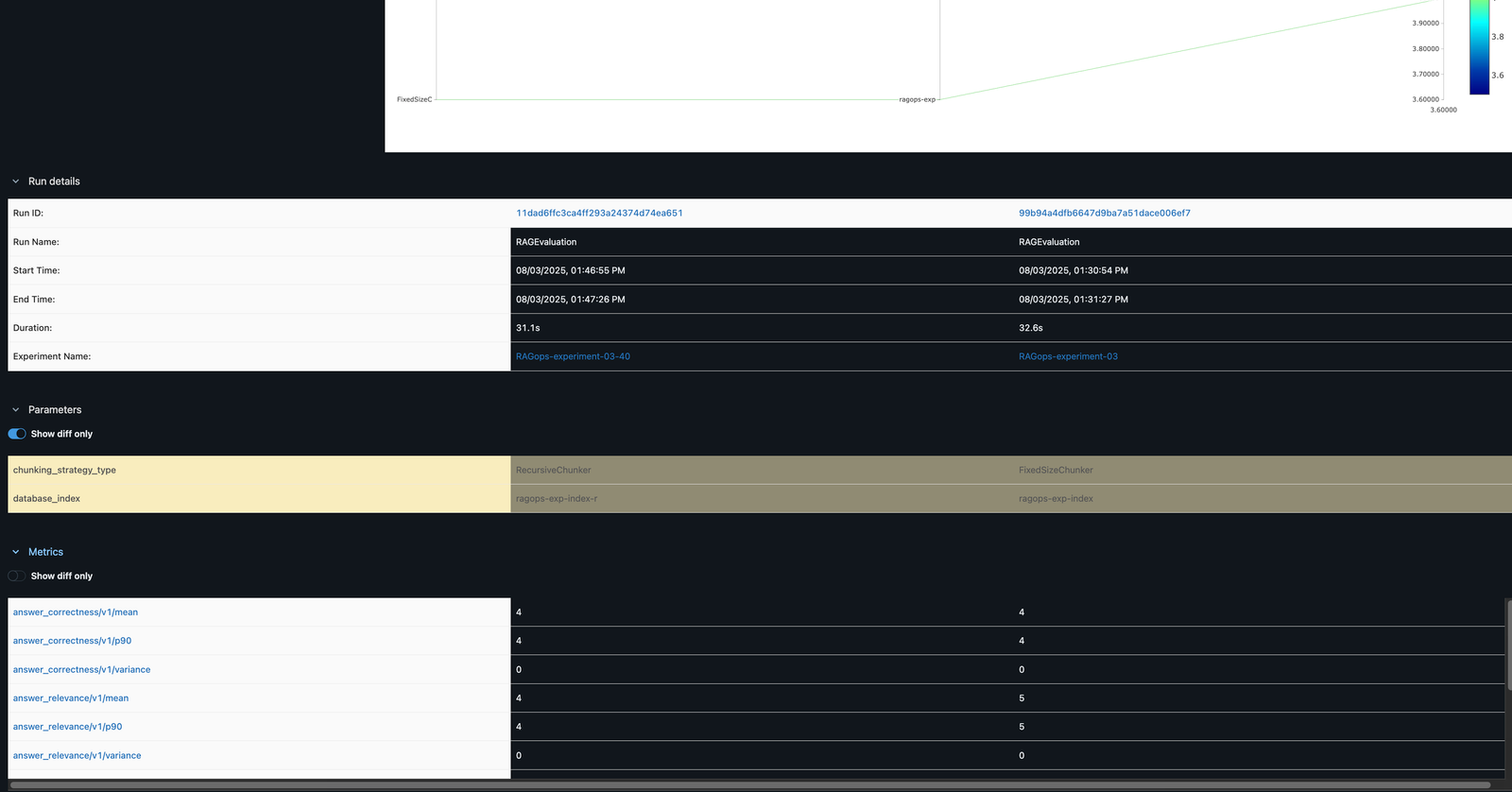
The following screenshot shows an example of the experiment details in MLflow.
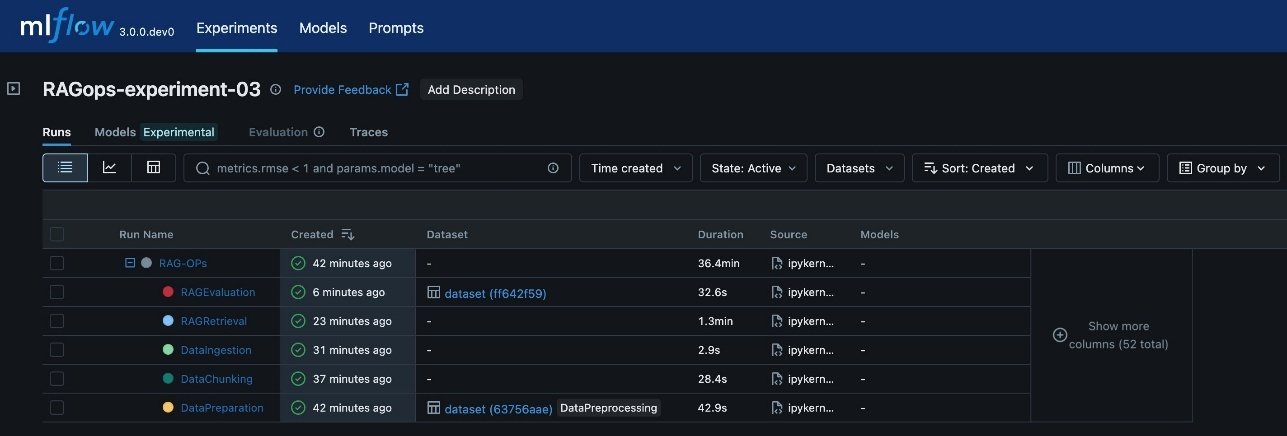
The various RAG pipeline steps defined are:
- Data preparation: Logs dataset version, preprocessing steps, and initial statistics
- Data chunking: Records chunking strategy, chunk size, overlap, and resulting chunk counts
- Data ingestion: Tracks embedding model, vector database details, and document ingestion metrics
- RAG retrieval: Captures retrieval model, context size, and retrieval performance metrics
- RAG evaluation: Logs evaluation metrics (such as answer similarity, correctness, and relevance) and sample results
This visualization provides a clear, end-to-end view of the RAG pipeline’s execution, so you can trace the impact of changes at any stage and achieve full reproducibility. The architecture supports scaling to multiple experiments, each representing a distinct configuration or hypothesis (for example, different chunking strategies, embedding models, or retrieval parameters). MLflow’s experiment UI visualizes these experiments side by side, enabling side-by-side comparison and analysis across runs. This structure is especially valuable in enterprise settings, where dozens or even hundreds of experiments might be conducted to optimize RAG performance.
We use MLflow experimentation throughout the RAG pipeline to log metrics and parameters, and the different experiment runs are initialized as shown in the following code snippet:
RAG pipeline experimentation
The key components of the RAG workflow are ingestion, chunking, retrieval, and evaluation, which we explain in this section. The MLflow dashboard makes it straightforward to visualize and analyze these parameters and metrics, supporting data-driven refinement of the chunking stage within the RAG pipeline.

Data ingestion and preparation
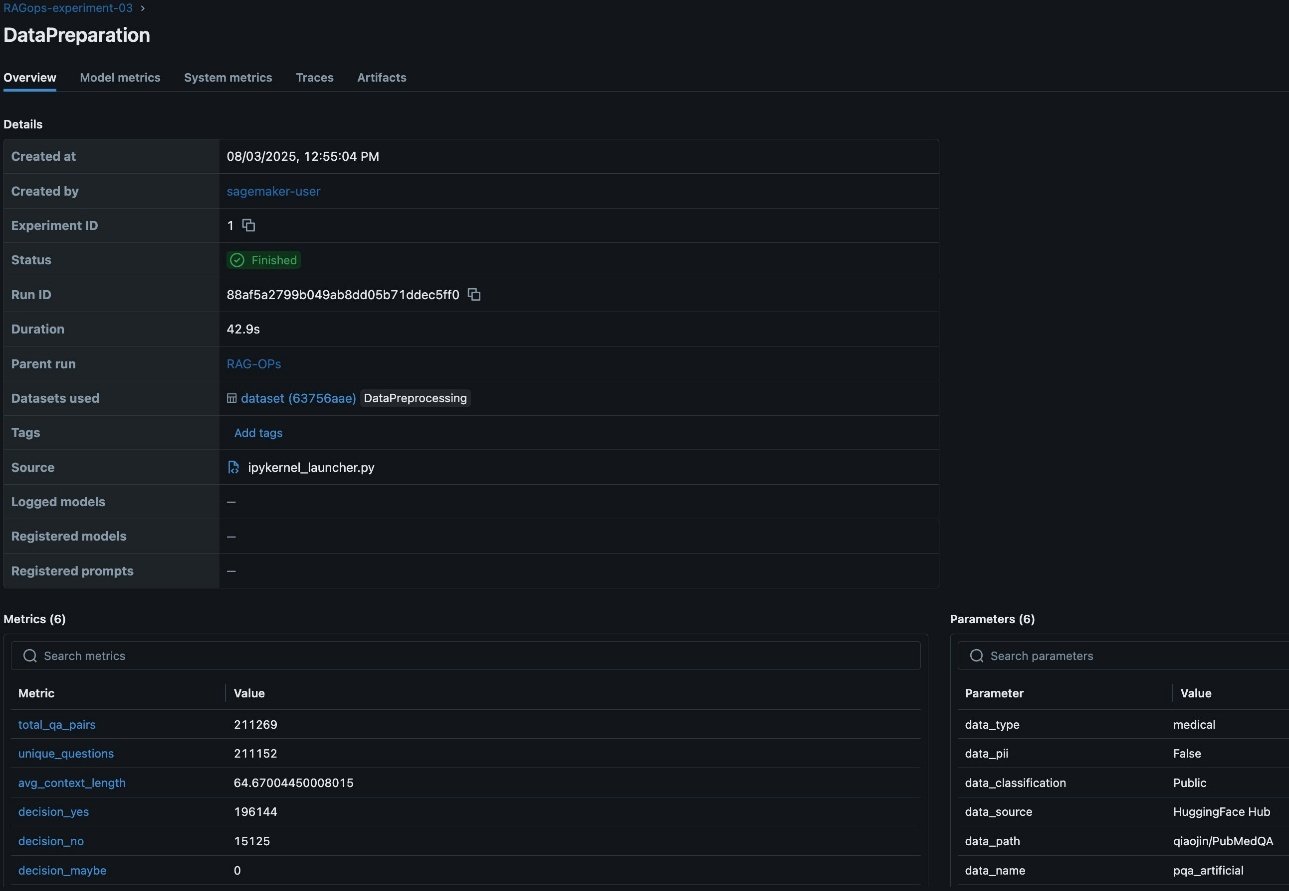
In the RAG workflow, rigorous data preparation is foundational to downstream performance and reliability. Tracking detailed metrics on data quality, such as the total number of question-answer pairs, the count of unique questions, average context length, and initial evaluation predictions, provides essential visibility into the dataset’s structure and suitability for RAG tasks. These metrics help validate the dataset is comprehensive, diverse, and contextually rich, which directly impacts the relevance and accuracy of the RAG system’s responses. Additionally, logging critical RAG parameters like the data source, detected personally identifiable information (PII) types, and data lineage information is vital for maintaining compliance, reproducibility, and trust in enterprise environments. Capturing this metadata in SageMaker managed MLflow supports robust experiment tracking, auditability, efficient comparison, and root cause analysis across multiple data preparation runs, as visualized in the MLflow dashboard. This disciplined approach to data preparation lays the groundwork for effective experimentation, governance, and continuous improvement throughout the RAG pipeline. The following screenshot shows an example of the experiment run details in MLflow.
Data chunking
After data preparation, the next step is to split documents into manageable chunks for efficient embedding and retrieval. This process is pivotal, because the quality and granularity of chunks directly affect the relevance and completeness of answers returned by the RAG system. The RAG workflow in this post supports experimentation and RAG pipeline automation with both fixed-size and recursive chunking strategies for comparison and validations. However, this RAG solution can be expanded to many other chucking techniques.
FixedSizeChunkerdivides text into uniform chunks with configurable overlapRecursiveChunkersplits text along logical boundaries such as paragraphs or sentences
Tracking detailed chunking metrics such as total_source_contexts_entries, total_contexts_chunked, and total_unique_chunks_final is crucial for understanding how much of the source data is represented, how effectively it is segmented, and whether the chunking approach is yielding the desired coverage and uniqueness. These metrics help diagnose issues like excessive duplication or under-segmentation, which can impact retrieval accuracy and model performance.
Additionally, logging parameters such as chunking_strategy_type (for example, FixedSizeChunker), chunking_strategy_chunk_size (for example, 500 characters), and chunking_strategy_chunk_overlap provide transparency and reproducibility for each experiment. Capturing these details in SageMaker managed MLflow helps teams systematically compare the impact of different chunking configurations, optimize for efficiency and contextual relevance, and maintain a clear audit trail of how chunking decisions evolve over time. The MLflow dashboard makes it straightforward to visualize and analyze these parameters and metrics, supporting data-driven refinement of the chunking stage within the RAG pipeline. The following screenshot shows an example of the experiment run details in MLflow.

After the documents are chunked, the next step is to convert these chunks into vector embeddings using a SageMaker embedding endpoint, after which the embeddings are ingested into a vector database such as OpenSearch Service for fast semantic search. This ingestion phase is crucial because the quality, completeness, and traceability of what enters the vector store directly determine the effectiveness and reliability of downstream retrieval and generation stages.
Tracking ingestion metrics such as the number of documents and chunks ingested provides visibility into pipeline throughput and helps identify bottlenecks or data loss early in the process. Logging detailed parameters, including the embedding model ID, endpoint used, and vector database index, is essential for reproducibility and auditability. This metadata helps teams trace exactly which model and infrastructure were used for each ingestion run, supporting root cause analysis and compliance, especially when working with evolving datasets or sensitive information.
Retrieval and generation
For a given query, we generate an embedding and retrieve the top-k relevant chunks from OpenSearch Service. For answer generation, we use a SageMaker LLM endpoint. The retrieved context and the query are combined into a prompt, and the LLM generates an answer. Finally, we orchestrate retrieval and generation using LangGraph, enabling stateful workflows and advanced tracing:
With the GenerativeAI agent defined with LangGraph framework, the agentic layers are evaluated for each iteration of RAG development, verifying the efficacy of the RAG solution for agentic applications. Each retrieval and generation run is logged to SageMaker managed MLflow, capturing the prompt, generated response, and key metrics and parameters such as retrieval performance, top-k values, and the specific model endpoints used. Tracking these details in MLflow is essential for evaluating the effectiveness of the retrieval stage, making sure the returned documents are relevant and that the generated answers are accurate and complete. It is equally important to track the performance of the vector database during retrieval, including metrics like query latency, throughput, and scalability. Monitoring these system-level metrics alongside retrieval relevance and accuracy makes sure the RAG pipeline delivers correct and relevant answers and meets production requirements for responsiveness and scalability. The following screenshot shows an example of the Langraph RAG retrieval tracing in MLflow.

RAG Evaluation
Evaluation is conducted on a curated test set, and results are logged to MLflow for quick comparison and analysis. This helps teams identify the best-performing configurations and iterate toward production-grade solutions. With MLflow you can evaluate the RAG solution with heuristics metrics, content similarity metrics and LLM-as-a-judge. In this post, we evaluate the RAG pipeline using advanced LLM-as-a-judge MLflow metrics (answer similarity, correctness, relevance, faithfulness):
The following screenshot shows an RAG evaluation stage experiment run details in MLflow.

You can use MLflow to log all metrics and parameters, enabling quick comparison of different experiment runs. See the following code for reference:
By using MLflow’s evaluation capabilities (such as mlflow.evaluate()), teams can systematically assess retrieval quality, identify potential gaps or misalignments in chunking or embedding strategies, and compare the performance of different retrieval and generation configurations. MLflow’s flexibility allows for seamless integration with external libraries and evaluation libraries such as RAGAS for comprehensive RAG pipeline assessment. RAGAS is an open source library that provide tools specifically for evaluation of LLM applications and generative AI agents. RAGAS includes the method ragas.evaluate() to run evaluations for LLM agents with the choice of LLM models (evaluators) for scoring the evaluation, and an extensive list of default metrics. To incorporate RAGAS metrics into your MLflow experiments, refer to the following GitHub repository.
Comparing experiments
In the MLflow UI, you can compare runs side by side. For example, comparing FixedSizeChunker and RecursiveChunker as shown in the following screenshot reveals differences in metrics such as answer_similarity (a difference of 1 point), providing actionable insights for pipeline optimization.
Automation with Amazon SageMaker pipelines
After systematically experimenting with and optimizing each component of the RAG workflow through SageMaker managed MLflow, the next step is transforming these validated configurations into production-ready automated pipelines. Although MLflow experiments help identify the optimal combination of chunking strategies, embedding models, and retrieval parameters, manually reproducing these configurations across environments can be error-prone and inefficient.
To produce the automated RAG pipeline, we use SageMaker Pipelines, which helps teams codify their experimentally validated RAG workflows into automated, repeatable pipelines that maintain consistency from development through production. By converting the successful MLflow experiments into pipeline definitions, teams can make sure the exact same chunking, embedding, retrieval, and evaluation steps that performed well in testing are reliably reproduced in production environments.
SageMaker Pipelines offers a serverless workflow orchestration for converting experimental notebook code into a production-grade pipeline, versioning and tracking pipeline configurations alongside MLflow experiments, and automating the end-to-end RAG workflow. The automated Sagemaker pipeline-based RAG workflow offers dependency management, comprehensive custom testing and validation before production deployment, and CI/CD integration for automated pipeline promotion.
With SageMaker Pipelines, you can automate your entire RAG workflow, from data preparation to evaluation, as reusable, parameterized pipeline definitions. This provides the following benefits:
- Reproducibility – Pipeline definitions capture all dependencies, configurations, and executions logic in version-controlled code
- Parameterization – Key RAG parameters (chunk sizes, model endpoints, retrieval settings) can be quickly modified between runs
- Monitoring – Pipeline executions provide detailed logs and metrics for each step
- Governance – Built-in lineage tracking supports full audibility of data and model artifacts
- Customization – Serverless workflow orchestration is customizable to your unique enterprise landscape, with scalable infrastructure and flexibility with instances optimized for CPU, GPU, or memory-intensive tasks, memory configuration, and concurrency optimization
To implement a RAG workflow in SageMaker pipelines, each major component of the RAG process (data preparation, chunking, ingestion, retrieval and generation, and evaluation) is included in a SageMaker processing job. These jobs are then orchestrated as steps within a pipeline, with data flowing between them, as shown in the following screenshot. This structure allows for modular development, quick debugging, and the ability to reuse components across different pipeline configurations.
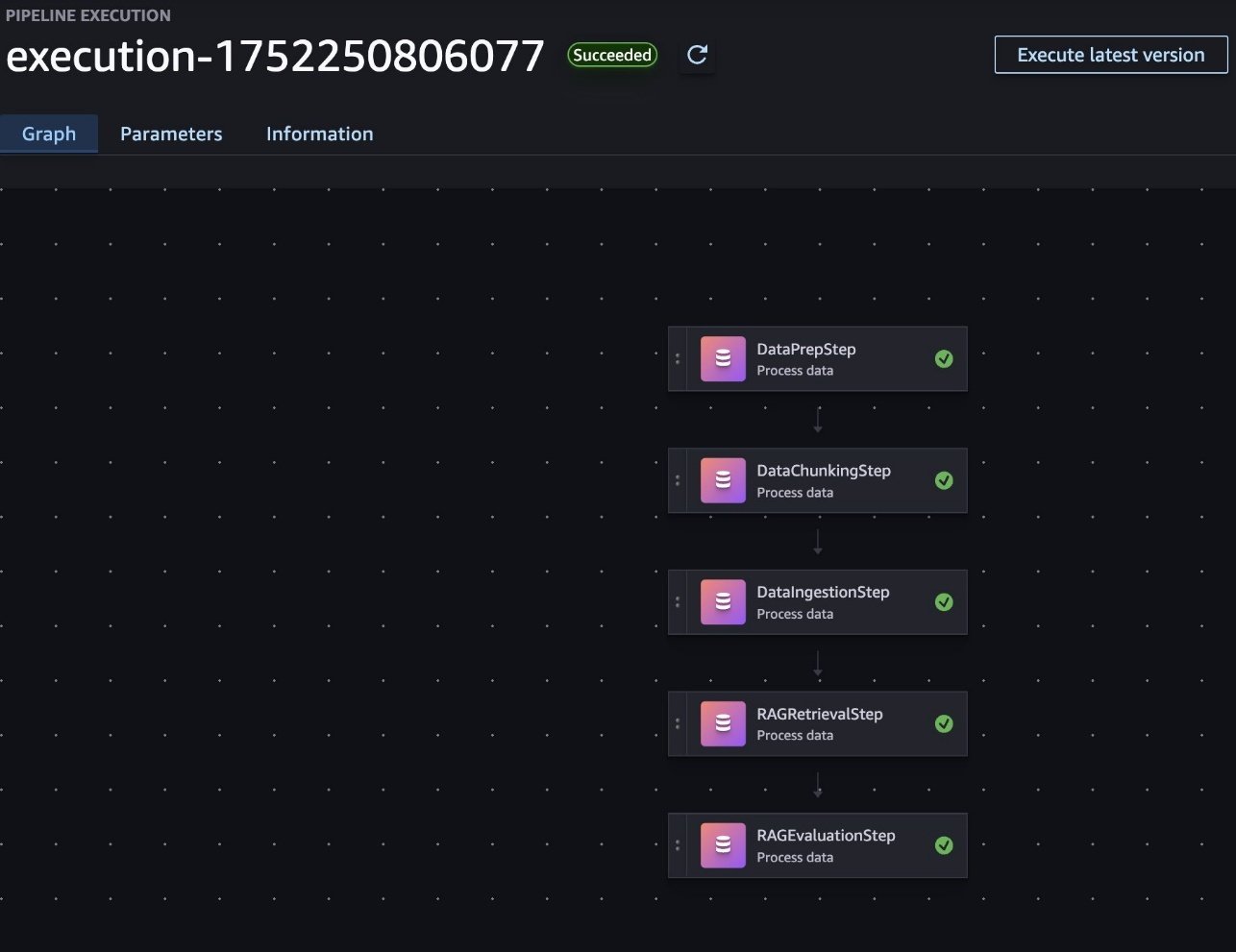
The key RAG configurations are exposed as pipeline parameters, enabling flexible experimentation with minimal code changes. For example, the following code snippets showcase the modifiable parameters for RAG configurations, which can be used as pipeline configurations:
In this post, we provide two agentic RAG pipeline automation approaches to building the SageMaker pipeline, each with own benefits: single-step SageMaker pipelines and multi-step pipelines.
The single-step pipeline approach is designed for simplicity, running the entire RAG workflow as one unified process. This setup is ideal for straightforward or less complex use cases, because it minimizes pipeline management overhead. With fewer steps, the pipeline can start quickly, benefitting from reduced execution times and streamlined development. This makes it a practical option when rapid iteration and ease of use are the primary concerns.
The multi-step pipeline approach is preferred for enterprise scenarios where flexibility and modularity are essential. By breaking down the RAG process into distinct, manageable stages, organizations gain the ability to customize, swap, or extend individual components as needs evolve. This design enables plug-and-play adaptability, making it straightforward to reuse or reconfigure pipeline steps for various workflows. Additionally, the multi-step format allows for granular monitoring and troubleshooting at each stage, providing detailed insights into performance and facilitating robust enterprise management. For enterprises seeking maximum flexibility and the ability to tailor automation to unique requirements, the multi-step pipeline approach is the superior choice.
CI/CD for an agentic RAG pipeline
Now we integrate the SageMaker RAG pipeline with CI/CD. CI/CD is important for making a RAG solution enterprise-ready because it provides faster, more reliable, and scalable delivery of AI-powered workflows. Specifically for enterprises, CI/CD pipelines automate the integration, testing, deployment, and monitoring of changes in the RAG system, which brings several key benefits, such as faster and more reliable updates, version control and traceability, consistency across environments, modularity and flexibility for customization, enhanced collaboration and monitoring, risk mitigation, and cost savings. This aligns with general CI/CD benefits in software and AI systems, emphasizing automation, quality assurance, collaboration, and continuous feedback essential to enterprise AI readiness.
When your SageMaker RAG pipeline definition is in place, you can implement robust CI/CD practices by integrating your development workflow and toolsets already enabled at your enterprise. This setup makes it possible to automate code promotion, pipeline deployment, and model experimentation through simple Git triggers, so changes are versioned, tested, and systematically promoted across environments. For demonstration, in this post, we show the CI/CD integration using GitHub Actions and by using GitHub Actions as the CI/CD orchestrator. Each code change, such as refining chunking strategies or updating pipeline steps, triggers an end-to-end automation workflow, as shown in the following screenshot. You can use the same CI/CD pattern with your choice of CI/CD tool instead of GitHub Actions, if needed.
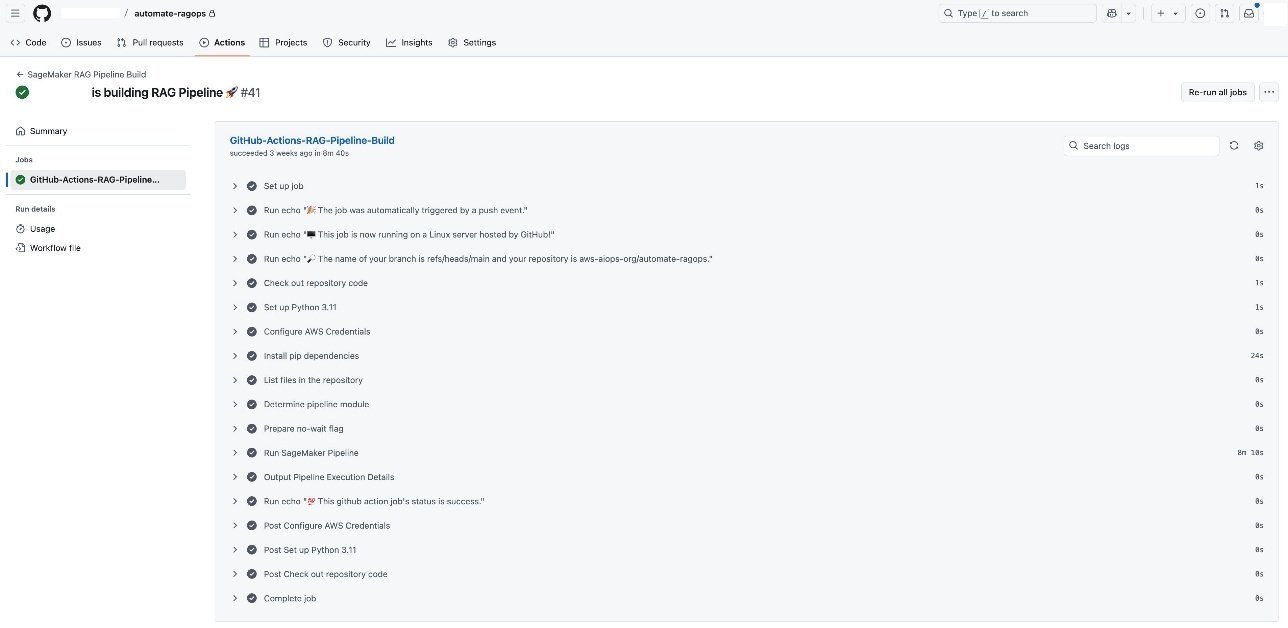
Each GitHub Actions CI/CD execution automatically triggers the SageMaker pipeline (shown in the following screenshot), allowing for seamless scaling of serverless compute infrastructure.
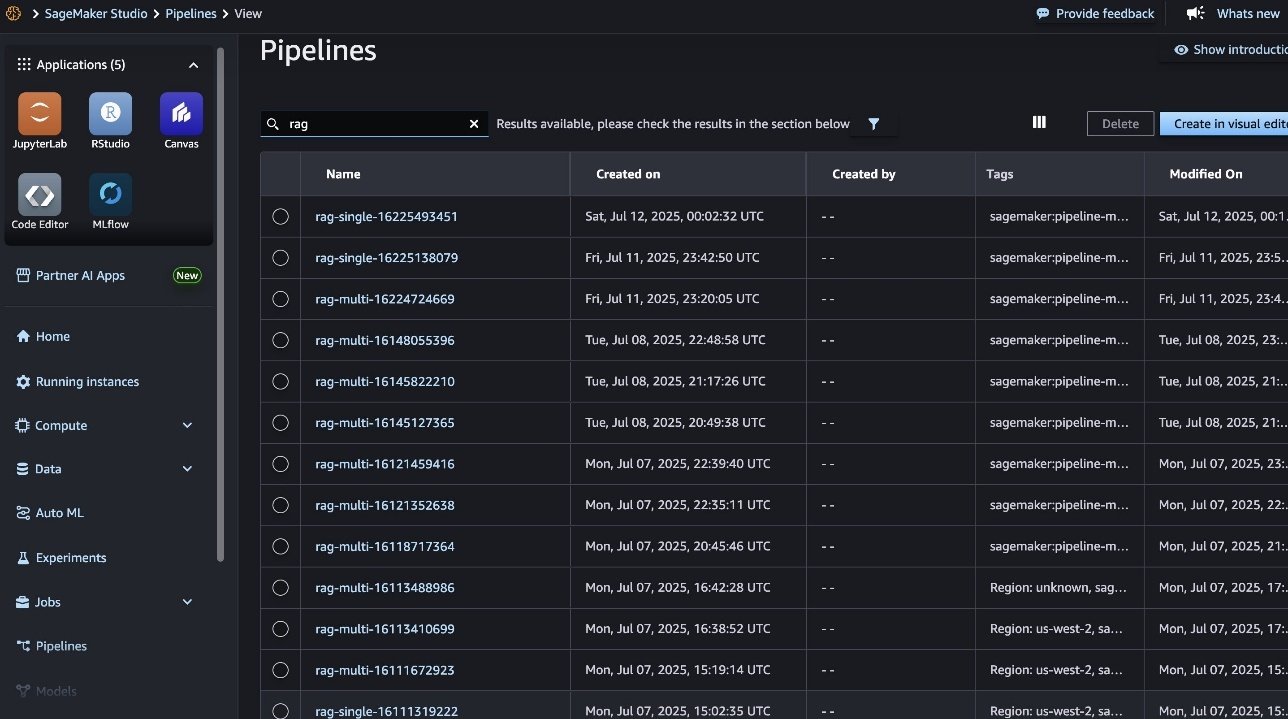
Throughout this cycle, SageMaker managed MLflow records every executed pipeline (shown in the following screenshot), so you can seamlessly review results, compare performance across different pipeline runs, and manage the RAG lifecycle.
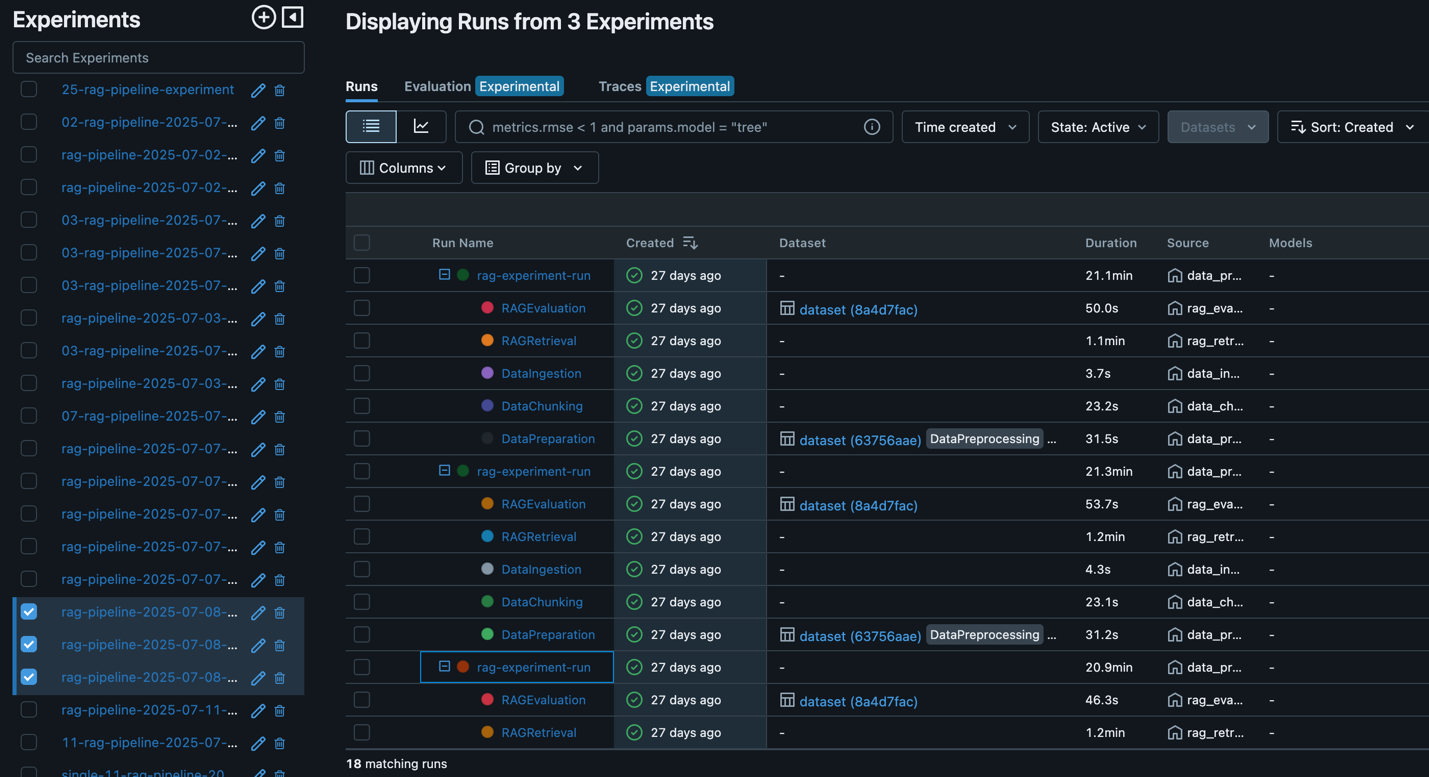
After an optimal RAG pipeline configuration is determined, the new desired configuration (Git version tracking captured in MLflow as shown in the following screenshot) can be promoted to higher stages or environments directly through an automated workflow, minimizing manual intervention and reducing risk.

Clean up
To avoid unnecessary costs, delete resources such as the SageMaker managed MLflow tracking server, SageMaker pipelines, and SageMaker endpoints when your RAG experimentation is complete. You can visit the SageMaker Studio console to destroy resources that aren’t needed anymore or call appropriate AWS APIs actions.
Conclusion
By integrating SageMaker AI, SageMaker managed MLflow, and Amazon OpenSearch Service, you can build, evaluate, and deploy RAG pipelines at scale. This approach provides the following benefits:
- Automated and reproducible workflows with SageMaker Pipelines and MLflow, minimizing manual steps and reducing the risk of human error
- Advanced experiment tracking and comparison for different chunking strategies, embedding models, and LLMs, so every configuration is logged, analyzed, and reproducible
- Actionable insights from both traditional and LLM-based evaluation metrics, helping teams make data-driven improvements at every stage
- Seamless deployment to production environments, with automated promotion of validated pipelines and robust governance throughout the workflow
Automating your RAG pipeline with SageMaker Pipelines brings additional benefits: it enables consistent, version-controlled deployments across environments, supports collaboration through modular, parameterized workflows, and supports full traceability and auditability of data, models, and results. With built-in CI/CD capabilities, you can confidently promote your entire RAG solution from experimentation to production, knowing that each stage meets quality and compliance standards.
Now it’s your turn to operationalize RAG workflows and accelerate your AI initiatives. Explore SageMaker Pipelines and managed MLflow using the solution from the GitHub repository to unlock scalable, automated, and enterprise-grade RAG solutions.
About the authors
 Sandeep Raveesh is a GenAI Specialist Solutions Architect at AWS. He works with customers through their AIOps journey across model training, generative AI applications like agents, and scaling generative AI use cases. He also focuses on Go-To-Market strategies, helping AWS build and align products to solve industry challenges in the generative AI space. You can find Sandeep on LinkedIn.
Sandeep Raveesh is a GenAI Specialist Solutions Architect at AWS. He works with customers through their AIOps journey across model training, generative AI applications like agents, and scaling generative AI use cases. He also focuses on Go-To-Market strategies, helping AWS build and align products to solve industry challenges in the generative AI space. You can find Sandeep on LinkedIn.
 Blake Shin is an Associate Specialist Solutions Architect at AWS who enjoys learning about and working with new AI/ML technologies. In his free time, Blake enjoys exploring the city and playing music.
Blake Shin is an Associate Specialist Solutions Architect at AWS who enjoys learning about and working with new AI/ML technologies. In his free time, Blake enjoys exploring the city and playing music.

As Molly Hamill explains the origin of the Declaration of Independence to her students, she dons a white wig fashioned into a ponytail, appearing as John Adams, before sporting a bald cap in homage to Benjamin Franklin, then wearing a red wig to imitate Thomas Jefferson. But instead of looking out to an enraptured sea of 28 fifth graders leaning forward in their desks, she is speaking directly into a camera.
Hamill is one of a growing number of educators who forwent brick-and-mortar schools post-pandemic. She now teaches fully virtually through the public, online school California Virtual Academies, having swapped desks for desktops.
After the abrupt shift to virtual schooling during the COVID-19 health crisis — and the stress for many educators because of it — voluntarily choosing the format may seem unthinkable.
“You hear people say, ‘I would never want to go back to virtual,’ and I get it, it was super stressful because we were building the plane as we were flying it, deciding if we were going to have live video or recordings, and adapt all the teaching materials to virtual,” Hamill says. “But my school is a pretty well-oiled machine … there’s a structure already in place. And kids are adaptable, they already like being on a computer.”
And for Hamill, and thousands of other teachers, instructing through a virtual school is a way to attempt striking a rare work-life balance in the education world.
More Flexibility for Teaching Students
The number of virtual schools has grown, as has the number of U.S. children enrolled in them. In the 2022-2023 school year, about 2.5 percent of K-12 students were enrolled in full-time virtual education (1.8 percent of them through public or private online schools, and 0.7 percent as homeschoolers), according to data published in 2024 by the National Center for Education Statistics. And parents reported that 7 percent of students who learned at home that year took at least one virtual course.
There’s been an accompanying rise in the number of teachers instructing remotely via virtual schools.
The number of teachers employed by K12, which is under the parent company Stride Inc. and one of the largest and longest-running providers of virtual schools, has jumped from 6,500 to 8,000 over the last three or four years, says Niyoka McCoy, chief learning officer at the company.
McCoy credits the growth in part to teachers wanting to homeschool their own children, and therefore needing to do their own work from home, but she also thinks it is a sign of a shifting preference for technology-based offerings.
“They think this is the future, that more online programs will open up,” McCoy says.
Connections Academy, which is the parent company of Pearson Online Academy and a similarly long-standing online learning provider, employs 3,500 teachers. Nik Osborne, senior vice president of partnerships and customer success at Pearson, says it’s been easy to both recruit and keep teachers: roughly 91 percent of teachers in the 2024-2025 school year returned this academic year.
“Teaching in a virtual space is very different than brick-and-mortar; even the type of role teachers play appeals to some teachers,” Osborne says. “They become more of a guide to help the kids understand content.”
Courtney Entsminger, a middle school math teacher at the public, online school Virginia Connections Academy, teaches asynchronously and likes the ability to record her own lesson plans in addition to teaching them live, which she says helps a wider variety of learners. Hamill, who teaches synchronously, similarly likes that the virtual format can be leveraged to build more creative lesson plans, like her Declaration of Independence video, or a fake livestream of George Washington during the Battle of Trenton, both which are on her YouTube channel.
Whether a school is asynchronous or not largely depends on the standard of the provider. Pearson, which runs the Virtual Academies where Entsminger teaches, is asynchronous. For other standalone public school districts, such as Georgia Cyber Academy, the decision comes down to what students need: if they are performing at or above grade level, they get more flexibility, but if they come to the school below grade level — reading at a second grade level, for example, but placed in a fourth grade classroom — they need more structure.
“I do feel like a TikTok star where I record myself teaching through different aspects of that curriculum because students work in different ways,” says Entsminger, who has 348 online students across three grades. “In person you’re able to realize ‘this student works this way,’ and I’ll do a song and dance in front of you. Online, I can do it in different mediums.”
Karen Bacon, a transition liaison at Ohio Virtual Academy who works with middle and high school students in special education, was initially drawn to virtual teaching because of its flexibility for supporting students through a path that works best for them.
“I always like a good challenge and thought this was interesting to dive into how this works and different ways to help students,” says Bacon, who was a high school French teacher before making the switch to virtual in 2017. “There’s obviously a lot to learn and understand, but once you dive in and see all the options, there really are a lot of different possibilities out there.”
Bacon says there are “definitely less distractions,” than in a brick-and-mortar environment, allowing her to get more creative. For example, she had noticed stories crop up across the nation showcasing special education students in physical environments working to serve coffee to teachers and students as a way to learn workplace skills. She, adapting to the virtual environment, created the “Cardinal Cafe,” where students can accomplish the same goals, albeit with a virtual cup of joe.
“I don’t really consider myself super tech-y, but I have that curiosity and love going outside the box and looking at ways to really help my students,” she says.
A Way to Curb Teacher Burnout?
The flexibility that comes with teaching in a virtual environment is not just appealing for what it offers students. Teachers say it can also help cushion the consistently lower wages and lack of benefits most educators grapple with, conditions that drive many to leave the field.
“So many of us have said, ‘I felt so burned out, I wasn’t sure I could keep teaching,’” Hamill says, adding she felt similarly at the start of her career as a first grade teacher. “But doing it this way helps it feel sustainable. We’re still underpaid and not appreciated enough as a whole profession, but at least virtually some of the big glaring issues aren’t there in terms of how we’re treated.”
Entsminger was initially drawn to teaching in part because she hoped it would allow her to have more time with her future children than other careers might offer. But as she became a mother while teaching for a decade in a brick-and-mortar environment — both at the elementary school and the high school level — she found she was unable to pick up or drop her daughter off at school, despite working in the same district her daughter attended.
In contrast, while teaching online,“in this environment I’m able to take her to school, make her breakfast,” she says. “I’m able to do life and my job. On the daily, I’m able to be ‘Mom’ and ‘Ms. Entsminger’ with less fighting for my time.”
Because of the more-flexible schedule for students enrolled in virtual learning programs, teachers do not have to be “on” for eight straight hours. And they do not necessarily have to participate in the sorts of shared systems that keep physical schools running. In a brick-and-mortar school, even if Bacon, Hamill or Entsminger were not slated to teach a class, they might be assigned to spend their time walking their students to their next class or the bus stop, or tasked with supervising the cafeteria during a lunch period. But in the virtual environment, they have the ability to close their laptop, and to quietly plan lessons or grade papers.
However, that is not to say these teachers operate as islands. Hamill says one of the largest perks of teaching virtual school is working with other fifth grade teachers across the nation, who often share PowerPoints or other lesson plans, whereas, she says, “I think sometimes in person, people can be a little precious about that.”
The workload varies for teachers in virtual programs. Entsminger’s 300-plus students are enrolled in three grades. Some live as close as her same city, others as far-flung as Europe, where they play soccer. Hamill currently has 28 students, expecting to get to 30 as the school continuously admits more. According to the National Policy Education Center, the average student-teacher ratio in the nation’s public schools was 14.8 students per teacher in 2023, with virtual schools reporting having 24.4 students per teacher.
Hamill also believes that virtual environments keep both teachers and students safer. She says she was sick for nine months of the year her first year teaching, getting strep throat twice. She also points to the seemingly endless onslaught of school shootings and the worsening of behavior issues among children.
“The trade-off for not having to do classroom management of behavioral issues is huge,” she says. “If the kid is mean in the chat, I turn off the chat. If kids aren’t listening, I can mute everyone and say, ‘I’ll let you talk one at a time.’ Versus, in my last classroom, the kids threw chairs at me.”
There are still adjustments to managing kids remotely, the teachers acknowledge. Hamill coaches her kids through internet safety and online decorum, like learning that typing in all-caps, for example, can come across rudely.
And while the virtual teachers were initially concerned about bonding with their students, they have found those worries largely unfounded. During online office hours, Hamill plays Pictionary with her students and has met most of their pets over a screen. Meanwhile, Entsminger offers online tutoring and daily opportunities to meet, where she has “learned more than I ever thought about K-pop this year.”
There are also opportunities for in-person gatherings with students. Hamill does once-a-month meetups, often in a park. Bacon attended an in-person picnic earlier this month to meet the students who live near her. And both K12 and Connections Academy hold multiple in-person events for students, including field trips and extracurriculars, like sewing or bowling clubs.
“Of course I wish I could see them more in person, and do arts and crafts time — that’s a big thing I miss,” Hamill says. “But we have drawing programs or ways they can post their artwork; we find ways to adapt to it.”
And that adaptation is largely worth it to virtual teachers.
“Teaching is teaching; even if I’m behind a computer screen, kids are still going to be kids,” Entsminger says. “The hurdles are still there. We’re still working hard, but it’s really nice to work with my students, and then walk to my kitchen to get coffee, then come back to connect to my students again.”
Books, Courses & Certifications
Schedule topology-aware workloads using Amazon SageMaker HyperPod task governance

Today, we are excited to announce a new capability of Amazon SageMaker HyperPod task governance to help you optimize training efficiency and network latency of your AI workloads. SageMaker HyperPod task governance streamlines resource allocation and facilitates efficient compute resource utilization across teams and projects on Amazon Elastic Kubernetes Service (Amazon EKS) clusters. Administrators can govern accelerated compute allocation and enforce task priority policies, improving resource utilization. This helps organizations focus on accelerating generative AI innovation and reducing time to market, rather than coordinating resource allocation and replanning tasks. Refer to Best practices for Amazon SageMaker HyperPod task governance for more information.
Generative AI workloads typically demand extensive network communication across Amazon Elastic Compute Cloud (Amazon EC2) instances, where network bandwidth impacts both workload runtime and processing latency. The network latency of these communications depends on the physical placement of instances within a data center’s hierarchical infrastructure. Data centers can be organized into nested organizational units such as network nodes and node sets, with multiple instances per network node and multiple network nodes per node set. For example, instances within the same organizational unit experience faster processing time compared to those across different units. This means fewer network hops between instances results in lower communication.
To optimize the placement of your generative AI workloads in your SageMaker HyperPod clusters by considering the physical and logical arrangement of resources, you can use EC2 network topology information during your job submissions. An EC2 instance’s topology is described by a set of nodes, with one node in each layer of the network. Refer to How Amazon EC2 instance topology works for details on how EC2 topology is arranged. Network topology labels offer the following key benefits:
- Reduced latency by minimizing network hops and routing traffic to nearby instances
- Improved training efficiency by optimizing workload placement across network resources
With topology-aware scheduling for SageMaker HyperPod task governance, you can use topology network labels to schedule your jobs with optimized network communication, thereby improving task efficiency and resource utilization for your AI workloads.
In this post, we introduce topology-aware scheduling with SageMaker HyperPod task governance by submitting jobs that represent hierarchical network information. We provide details about how to use SageMaker HyperPod task governance to optimize your job efficiency.
Solution overview
Data scientists interact with SageMaker HyperPod clusters. Data scientists are responsible for the training, fine-tuning, and deployment of models on accelerated compute instances. It’s important to make sure data scientists have the necessary capacity and permissions when interacting with clusters of GPUs.
To implement topology-aware scheduling, you first confirm the topology information for all nodes in your cluster, then run a script that tells you which instances are on the same network nodes, and finally schedule a topology-aware training task on your cluster. This workflow facilitates higher visibility and control over the placement of your training instances.
In this post, we walk through viewing node topology information and submitting topology-aware tasks to your cluster. For reference, NetworkNodes describes the network node set of an instance. In each network node set, three layers comprise the hierarchical view of the topology for each instance. Instances that are closest to each other will share the same layer 3 network node. If there are no common network nodes in the bottom layer (layer 3), then see if there is commonality at layer 2.
Prerequisites
To get started with topology-aware scheduling, you must have the following prerequisites:
- An EKS cluster
- A SageMaker HyperPod cluster with instances enabled for topology information
- The SageMaker HyperPod task governance add-on installed (version 1.2.2 or later)
- Kubectl installed
- (Optional) The SageMaker HyperPod CLI installed
Get node topology information
Run the following command to show node labels in your cluster. This command provides network topology information for each instance.
Instances with the same network node layer 3 are as close as possible, following EC2 topology hierarchy. You should see a list of node labels that look like the following:topology.k8s.aws/network-node-layer-3: nn-33333exampleRun the following script to show the nodes in your cluster that are on the same layers 1, 2, and 3 network nodes:
The output of this script will print a flow chart that you can use in a flow diagram editor such as Mermaid.js.org to visualize the node topology of your cluster. The following figure is an example of the cluster topology for a seven-instance cluster.
Submit tasks
SageMaker HyperPod task governance offers two ways to submit tasks using topology awareness. In this section, we discuss these two options and a third alternative option to task governance.
Modify your Kubernetes manifest file
First, you can modify your existing Kubernetes manifest file to include one of two annotation options:
- kueue.x-k8s.io/podset-required-topology – Use this option if you must have all pods scheduled on nodes on the same network node layer in order to begin the job
- kueue.x-k8s.io/podset-preferred-topology – Use this option if you ideally want all pods scheduled on nodes in the same network node layer, but you have flexibility
The following code is an example of a sample job that uses the kueue.x-k8s.io/podset-required-topology setting to schedule pods that share the same layer 3 network node:
To verify which nodes your pods are running on, use the following command to view node IDs per pod:kubectl get pods -n hyperpod-ns-team-a -o wide
Use the SageMaker HyperPod CLI
The second way to submit a job is through the SageMaker HyperPod CLI. Be sure to install the latest version (version pending) to use topology-aware scheduling. To use topology-aware scheduling with the SageMaker HyperPod CLI, you can include either the --preferred-topology parameter or the --required-topology parameter in your create job command.
The following code is an example command to start a topology-aware mnist training job using the SageMaker HyperPod CLI, replace XXXXXXXXXXXX with your AWS account ID:
Clean up
If you deployed new resources while following this post, refer to the Clean Up section in the SageMaker HyperPod EKS workshop to make sure you don’t accrue unwanted charges.
Conclusion
During large language model (LLM) training, pod-to-pod communication distributes the model across multiple instances, requiring frequent data exchange between these instances. In this post, we discussed how SageMaker HyperPod task governance helps schedule workloads to enable job efficiency by optimizing throughput and latency. We also walked through how to schedule jobs using SageMaker HyperPod topology network information to optimize network communication latency for your AI tasks.
We encourage you to try out this solution and share your feedback in the comments section.
About the authors
 Nisha Nadkarni is a Senior GenAI Specialist Solutions Architect at AWS, where she guides companies through best practices when deploying large scale distributed training and inference on AWS. Prior to her current role, she spent several years at AWS focused on helping emerging GenAI startups develop models from ideation to production.
Nisha Nadkarni is a Senior GenAI Specialist Solutions Architect at AWS, where she guides companies through best practices when deploying large scale distributed training and inference on AWS. Prior to her current role, she spent several years at AWS focused on helping emerging GenAI startups develop models from ideation to production.
 Siamak Nariman is a Senior Product Manager at AWS. He is focused on AI/ML technology, ML model management, and ML governance to improve overall organizational efficiency and productivity. He has extensive experience automating processes and deploying various technologies.
Siamak Nariman is a Senior Product Manager at AWS. He is focused on AI/ML technology, ML model management, and ML governance to improve overall organizational efficiency and productivity. He has extensive experience automating processes and deploying various technologies.
 Zican Li is a Senior Software Engineer at Amazon Web Services (AWS), where he leads software development for Task Governance on SageMaker HyperPod. In his role, he focuses on empowering customers with advanced AI capabilities while fostering an environment that maximizes engineering team efficiency and productivity.
Zican Li is a Senior Software Engineer at Amazon Web Services (AWS), where he leads software development for Task Governance on SageMaker HyperPod. In his role, he focuses on empowering customers with advanced AI capabilities while fostering an environment that maximizes engineering team efficiency and productivity.
 Anoop Saha is a Sr GTM Specialist at Amazon Web Services (AWS) focusing on generative AI model training and inference. He partners with top frontier model builders, strategic customers, and AWS service teams to enable distributed training and inference at scale on AWS and lead joint GTM motions. Before AWS, Anoop held several leadership roles at startups and large corporations, primarily focusing on silicon and system architecture of AI infrastructure.
Anoop Saha is a Sr GTM Specialist at Amazon Web Services (AWS) focusing on generative AI model training and inference. He partners with top frontier model builders, strategic customers, and AWS service teams to enable distributed training and inference at scale on AWS and lead joint GTM motions. Before AWS, Anoop held several leadership roles at startups and large corporations, primarily focusing on silicon and system architecture of AI infrastructure.
Books, Courses & Certifications
How msg enhanced HR workforce transformation with Amazon Bedrock and msg.ProfileMap

This post is co-written with Stefan Walter from msg.
With more than 10,000 experts in 34 countries, msg is both an independent software vendor and a system integrator operating in highly regulated industries, with over 40 years of domain-specific expertise. msg.ProfileMap is a software as a service (SaaS) solution for skill and competency management. It’s an AWS Partner qualified software available on AWS Marketplace, currently serving more than 7,500 users. HR and strategy departments use msg.ProfileMap for project staffing and workforce transformation initiatives. By offering a centralized view of skills and competencies, msg.ProfileMap helps organizations map their workforce’s capabilities, identify skill gaps, and implement targeted development strategies. This supports more effective project execution, better alignment of talent to roles, and long-term workforce planning.
In this post, we share how msg automated data harmonization for msg.ProfileMap, using Amazon Bedrock to power its large language model (LLM)-driven data enrichment workflows, resulting in higher accuracy in HR concept matching, reduced manual workload, and improved alignment with compliance requirements under the EU AI Act and GDPR.
The importance of AI-based data harmonization
HR departments face increasing pressure to operate as data-driven organizations, but are often constrained by the inconsistent, fragmented nature of their data. Critical HR documents are unstructured, and legacy systems use mismatched formats and data models. This not only impairs data quality but also leads to inefficiencies and decision-making blind spots.Accurate and harmonized HR data is foundational for key activities such as matching candidates to roles, identifying internal mobility opportunities, conducting skills gap analysis, and planning workforce development. msg identified that without automated, scalable methods to process and unify this data, organizations would continue to struggle with manual overhead and inconsistent results.
Solution overview
HR data is typically scattered across diverse sources and formats, ranging from relational databases to Excel files, Word documents, and PDFs. Additionally, entities such as personnel numbers or competencies have different unique identifiers as well as different text descriptions, although with the same semantics. msg addressed this challenge with a modular architecture, tailored for IT workforce scenarios. As illustrated in the following diagram, at the core of msg.ProfileMap is a robust text extraction layer, which transforms heterogeneous inputs into structured data. This is then passed to an AI-powered harmonization engine that provides consistency across data sources by avoiding duplication and aligning disparate concepts.
The harmonization process uses a hybrid retrieval approach that combines vector-based semantic similarity and string-based matching techniques. These methods align incoming data with existing entities in the system. Amazon Bedrock is used to semantically enrich data, improving cross-source compatibility and matching precision. Extracted and enriched data is indexed and stored using Amazon OpenSearch Service and Amazon DynamoDB, facilitating fast and accurate retrieval, as shown in the following diagram.

The framework is designed to be unsupervised and domain independent. Although it’s optimized for IT workforce use cases, it has demonstrated strong generalization capabilities in other domains as well.
msg.ProfileMap is a cloud-based application that uses several AWS services, notably Amazon Neptune, Amazon DynamoDB, and Amazon Bedrock. The following diagram illustrates the full solution architecture.

Results and technical validation
msg evaluated the effectiveness of the data harmonization framework through internal testing on IT workforce concepts and external benchmarking in the Bio-ML Track of the Ontology Alignment Evaluation Initiative (OAEI), an international and EU-funded research initiative that evaluates ontology matching technologies since 2004.
During internal testing, the system processed 2,248 concepts across multiple suggestion types. High-probability merge recommendations reached 95.5% accuracy, covering nearly 60% of all inputs. This helped msg reduce manual validation workload by over 70%, significantly improving time-to-value for HR teams.
During OAEI 2024, msg.ProfileMap ranked at the top of the 2024 Bio-ML benchmark, outperforming other systems across multiple biomedical datasets. On NCIT-DOID, it achieved a 0.918 F1 score, with Hits@1 exceeding 92%, validating the engine’s generalizability beyond the HR domain. Additional details are available in the official test results.
Why Amazon Bedrock
msg relies on LLMs to semantically enrich data in near real time. These workloads require low-latency inference, flexible scaling, and operational simplicity. Amazon Bedrock met these needs by providing a fully managed, serverless interface to leading foundation models—without the need to manage infrastructure or deploy custom machine learning stacks.
Unlike hosting models on Amazon Elastic Compute Cloud (Amazon EC2) or Amazon SageMaker, Amazon Bedrock abstracts away provisioning, versioning, scaling, and model selection. Its consumption-based pricing aligns directly with msg’s SaaS delivery model—resources are used (and billed) only when needed. This simplified integration reduced overhead and helped msg scale elastically as customer demand grew.
Amazon Bedrock also helped msg meet compliance goals under the EU AI Act and GDPR by enabling tightly scoped, auditable interactions with model APIs—critical for HR use cases that handle sensitive workforce data.
Conclusion
msg’s successful integration of Amazon Bedrock into msg.ProfileMap demonstrates that large-scale AI adoption doesn’t require complex infrastructure or specialized model training. By combining modular design, ontology-based harmonization, and the fully managed LLM capabilities of Amazon Bedrock, msg delivered an AI-powered workforce intelligence platform that is accurate, scalable, and compliant.This solution improved concept match precision and achieved top marks in international AI benchmarks, demonstrating what’s possible when generative AI is paired with the right cloud-based service. With Amazon Bedrock, msg has built a platform that’s ready for today’s HR challenges—and tomorrow’s.
msg.ProfileMap is available as a SaaS offering on AWS Marketplace. If you are interested in knowing more, you can reach out to msg.hcm.backoffice@msg.group.
The content and opinions in this blog post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
About the authors
 Stefan Walter is Senior Vice President of AI SaaS Solutions at msg. With over 25 years of experience in IT software development, architecture, and consulting, Stefan Walter leads with a vision for scalable SaaS innovation and operational excellence. As a BU lead at msg, Stefan has spearheaded transformative initiatives that bridge business strategy with technology execution, especially in complex, multi-entity environments.
Stefan Walter is Senior Vice President of AI SaaS Solutions at msg. With over 25 years of experience in IT software development, architecture, and consulting, Stefan Walter leads with a vision for scalable SaaS innovation and operational excellence. As a BU lead at msg, Stefan has spearheaded transformative initiatives that bridge business strategy with technology execution, especially in complex, multi-entity environments.
 Gianluca Vegetti is a Senior Enterprise Architect in the AWS Partner Organization, aligned to Strategic Partnership Collaboration and Governance (SPCG) engagements. In his role, he supports the definition and execution of Strategic Collaboration Agreements with selected AWS partners.
Gianluca Vegetti is a Senior Enterprise Architect in the AWS Partner Organization, aligned to Strategic Partnership Collaboration and Governance (SPCG) engagements. In his role, he supports the definition and execution of Strategic Collaboration Agreements with selected AWS partners.
 Yuriy Bezsonov is a Senior Partner Solution Architect at AWS. With over 25 years in the tech, Yuriy has progressed from a software developer to an engineering manager and Solutions Architect. Now, as a Senior Solutions Architect at AWS, he assists partners and customers in developing cloud solutions, focusing on container technologies, Kubernetes, Java, application modernization, SaaS, developer experience, and GenAI. Yuriy holds AWS and Kubernetes certifications, and he is a recipient of the AWS Golden Jacket and the CNCF Kubestronaut Blue Jacket.
Yuriy Bezsonov is a Senior Partner Solution Architect at AWS. With over 25 years in the tech, Yuriy has progressed from a software developer to an engineering manager and Solutions Architect. Now, as a Senior Solutions Architect at AWS, he assists partners and customers in developing cloud solutions, focusing on container technologies, Kubernetes, Java, application modernization, SaaS, developer experience, and GenAI. Yuriy holds AWS and Kubernetes certifications, and he is a recipient of the AWS Golden Jacket and the CNCF Kubestronaut Blue Jacket.
-

 Business3 weeks ago
Business3 weeks agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-
Tools & Platforms1 month ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy2 months ago
Ethics & Policy2 months agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences4 months ago
Events & Conferences4 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers3 months ago
Jobs & Careers3 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Education3 months ago
Education3 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Education2 months ago
Education2 months agoMacron says UK and France have duty to tackle illegal migration ‘with humanity, solidarity and firmness’ – UK politics live | Politics
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi
-

 Funding & Business3 months ago
Funding & Business3 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries