AI Research
An early warning system for novel AI risks

Responsibility & Safety
New research proposes a framework for evaluating general-purpose models against novel threats
To pioneer responsibly at the cutting edge of artificial intelligence (AI) research, we must identify new capabilities and novel risks in our AI systems as early as possible.
AI researchers already use a range of evaluation benchmarks to identify unwanted behaviours in AI systems, such as AI systems making misleading statements, biased decisions, or repeating copyrighted content. Now, as the AI community builds and deploys increasingly powerful AI, we must expand the evaluation portfolio to include the possibility of extreme risks from general-purpose AI models that have strong skills in manipulation, deception, cyber-offense, or other dangerous capabilities.
In our latest paper, we introduce a framework for evaluating these novel threats, co-authored with colleagues from University of Cambridge, University of Oxford, University of Toronto, Université de Montréal, OpenAI, Anthropic, Alignment Research Center, Centre for Long-Term Resilience, and Centre for the Governance of AI.
Model safety evaluations, including those assessing extreme risks, will be a critical component of safe AI development and deployment.
An overview of our proposed approach: To assess extreme risks from new, general-purpose AI systems, developers must evaluate for dangerous capabilities and alignment (see below). By identifying the risks early on, this will unlock opportunities to be more responsible when training new AI systems, deploying these AI systems, transparently describing their risks, and applying appropriate cybersecurity standards.
Evaluating for extreme risks
General-purpose models typically learn their capabilities and behaviours during training. However, existing methods for steering the learning process are imperfect. For example, previous research at Google DeepMind has explored how AI systems can learn to pursue undesired goals even when we correctly reward them for good behaviour.
Responsible AI developers must look ahead and anticipate possible future developments and novel risks. After continued progress, future general-purpose models may learn a variety of dangerous capabilities by default. For instance, it is plausible (though uncertain) that future AI systems will be able to conduct offensive cyber operations, skilfully deceive humans in dialogue, manipulate humans into carrying out harmful actions, design or acquire weapons (e.g. biological, chemical), fine-tune and operate other high-risk AI systems on cloud computing platforms, or assist humans with any of these tasks.
People with malicious intentions accessing such models could misuse their capabilities. Or, due to failures of alignment, these AI models might take harmful actions even without anybody intending this.
Model evaluation helps us identify these risks ahead of time. Under our framework, AI developers would use model evaluation to uncover:
- To what extent a model has certain ‘dangerous capabilities’ that could be used to threaten security, exert influence, or evade oversight.
- To what extent the model is prone to applying its capabilities to cause harm (i.e. the model’s alignment). Alignment evaluations should confirm that the model behaves as intended even across a very wide range of scenarios, and, where possible, should examine the model’s internal workings.
Results from these evaluations will help AI developers to understand whether the ingredients sufficient for extreme risk are present. The most high-risk cases will involve multiple dangerous capabilities combined together. The AI system doesn’t need to provide all the ingredients, as shown in this diagram:
Ingredients for extreme risk: Sometimes specific capabilities could be outsourced, either to humans (e.g. to users or crowdworkers) or other AI systems. These capabilities must be applied for harm, either due to misuse or failures of alignment (or a mixture of both).
A rule of thumb: the AI community should treat an AI system as highly dangerous if it has a capability profile sufficient to cause extreme harm, assuming it’s misused or poorly aligned. To deploy such a system in the real world, an AI developer would need to demonstrate an unusually high standard of safety.
Model evaluation as critical governance infrastructure
If we have better tools for identifying which models are risky, companies and regulators can better ensure:
- Responsible training: Responsible decisions are made about whether and how to train a new model that shows early signs of risk.
- Responsible deployment: Responsible decisions are made about whether, when, and how to deploy potentially risky models.
- Transparency: Useful and actionable information is reported to stakeholders, to help them prepare for or mitigate potential risks.
- Appropriate security: Strong information security controls and systems are applied to models that might pose extreme risks.
We have developed a blueprint for how model evaluations for extreme risks should feed into important decisions around training and deploying a highly capable, general-purpose model. The developer conducts evaluations throughout, and grants structured model access to external safety researchers and model auditors so they can conduct additional evaluations The evaluation results can then inform risk assessments before model training and deployment.
A blueprint for embedding model evaluations for extreme risks into important decision making processes throughout model training and deployment.
Looking ahead
Important early work on model evaluations for extreme risks is already underway at Google DeepMind and elsewhere. But much more progress – both technical and institutional – is needed to build an evaluation process that catches all possible risks and helps safeguard against future, emerging challenges.
Model evaluation is not a panacea; some risks could slip through the net, for example, because they depend too heavily on factors external to the model, such as complex social, political, and economic forces in society. Model evaluation must be combined with other risk assessment tools and a wider dedication to safety across industry, government, and civil society.
Google’s recent blog on responsible AI states that, “individual practices, shared industry standards, and sound government policies would be essential to getting AI right”. We hope many others working in AI and sectors impacted by this technology will come together to create approaches and standards for safely developing and deploying AI for the benefit of all.
We believe that having processes for tracking the emergence of risky properties in models, and for adequately responding to concerning results, is a critical part of being a responsible developer operating at the frontier of AI capabilities.

Artificial intelligence shows great promise in helping physicians improve both their diagnostic accuracy of important patient conditions. In the realm of gastroenterology, AI has been shown to help human physicians better detect small polyps (adenomas) during colonoscopy. Although adenomas are not yet cancerous, they are at risk for turning into cancer. Thus, early detection and removal of adenomas during routine colonoscopy can reduce patient risk of developing future colon cancers.
But as physicians become more accustomed to AI assistance, what happens when they no longer have access to AI support? A recent European study has shown that physicians’ skills in detecting adenomas can deteriorate significantly after they become reliant on AI.
The European researchers tracked the results of over 1400 colonoscopies performed in four different medical centers. They measured the adenoma detection rate (ADR) for physicians working normally without AI vs. those who used AI to help them detect adenomas during the procedure. In addition, they also tracked the ADR of the physicians who had used AI regularly for three months, then resumed performing colonoscopies without AI assistance.
The researchers found that the ADR before AI assistance was 28% and with AI assistance was 28.4%. (This was a slight increase, but not statistically significant.) However, when physicians accustomed to AI assistance ceased using AI, their ADR fell significantly to 22.4%. Assuming the patients in the various study groups were medically similar, that suggests that physicians accustomed to AI support might miss over a fifth of adenomas without computer assistance!
This is the first published example of so-called medical “deskilling” caused by routine use of AI. The study authors summarized their findings as follows: “We assume that continuous exposure to decision support systems such as AI might lead to the natural human tendency to over-rely on their recommendations, leading to clinicians becoming less motivated, less focused, and less responsible when making cognitive decisions without AI assistance.”
Consider the following non-medical analogy: Suppose self-driving car technology advanced to the point that cars could safely decide when to accelerate, brake, turn, change lanes, and avoid sudden unexpected obstacles. If you relied on self-driving technology for several months, then suddenly had to drive without AI assistance, would you lose some of your driving skills?
Although this particular study took place in the field of gastroenterology, I would not be surprised if we eventually learn of similar AI-related deskilling in other branches of medicine, such as radiology. At present, radiologists do not routinely use AI while reading mammograms to detect early breast cancers. But when AI becomes approved for routine use, I can imagine that human radiologists could succumb to a similar performance loss if they were suddenly required to work without AI support.
I anticipate more studies will be performed to investigate the issue of deskilling across multiple medical specialties. Physicians, policymakers, and the general public will want to ask the following questions:
1) As AI becomes more routinely adopted, how are we tracking patient outcomes (and physician error rates) before AI, after routine AI use, and whenever AI is discontinued?
2) How long does the deskilling effect last? What methods can help physicians minimize deskilling, and/or recover lost skills most quickly?
3) Can AI be implemented in medical practice in a way that augments physician capabilities without deskilling?
Deskilling is not always bad. My 6th grade schoolteacher kept telling us that we needed to learn long division because we wouldn’t always have a calculator with us. But because of the ubiquity of smartphones and spreadsheets, I haven’t done long division with pencil and paper in decades!
I do not see AI completely replacing human physicians, at least not for several years. Thus, it will be incumbent on the technology and medical communities to discover and develop best practices that optimize patient outcomes without endangering patients through deskilling. This will be one of the many interesting and important challenges facing physicians in the era of AI.

A team of computer scientists led by the University of Colorado Boulder has developed a new artificial intelligence platform that automatically seeks out “questionable” scientific journals.
The study, published Aug. 27 in the journal “Science Advances,” tackles an alarming trend in the world of research.
Daniel Acuña, lead author of the study and associate professor in the Department of Computer Science, gets a reminder of that several times a week in his email inbox: These spam messages come from people who purport to be editors at scientific journals, usually ones Acuña has never heard of, and offer to publish his papers — for a hefty fee.
Such publications are sometimes referred to as “predatory” journals. They target scientists, convincing them to pay hundreds or even thousands of dollars to publish their research without proper vetting.
“There has been a growing effort among scientists and organizations to vet these journals,” Acuña said. “But it’s like whack-a-mole. You catch one, and then another appears, usually from the same company. They just create a new website and come up with a new name.”
His group’s new AI tool automatically screens scientific journals, evaluating their websites and other online data for certain criteria: Do the journals have an editorial board featuring established researchers? Do their websites contain a lot of grammatical errors?
Acuña emphasizes that the tool isn’t perfect. Ultimately, he thinks human experts, not machines, should make the final call on whether a journal is reputable.
But in an era when prominent figures are questioning the legitimacy of science, stopping the spread of questionable publications has become more important than ever before, he said.
“In science, you don’t start from scratch. You build on top of the research of others,” Acuña said. “So if the foundation of that tower crumbles, then the entire thing collapses.”
The shake down
When scientists submit a new study to a reputable publication, that study usually undergoes a practice called peer review. Outside experts read the study and evaluate it for quality — or, at least, that’s the goal.
A growing number of companies have sought to circumvent that process to turn a profit. In 2009, Jeffrey Beall, a librarian at CU Denver, coined the phrase “predatory” journals to describe these publications.
Often, they target researchers outside of the United States and Europe, such as in China, India and Iran — countries where scientific institutions may be young, and the pressure and incentives for researchers to publish are high.
“They will say, ‘If you pay $500 or $1,000, we will review your paper,'” Acuña said. “In reality, they don’t provide any service. They just take the PDF and post it on their website.”
A few different groups have sought to curb the practice. Among them is a nonprofit organization called the Directory of Open Access Journals (DOAJ). Since 2003, volunteers at the DOAJ have flagged thousands of journals as suspicious based on six criteria. (Reputable publications, for example, tend to include a detailed description of their peer review policies on their websites.)
But keeping pace with the spread of those publications has been daunting for humans.
To speed up the process, Acuña and his colleagues turned to AI. The team trained its system using the DOAJ’s data, then asked the AI to sift through a list of nearly 15,200 open-access journals on the internet.
Among those journals, the AI initially flagged more than 1,400 as potentially problematic.
Acuña and his colleagues asked human experts to review a subset of the suspicious journals. The AI made mistakes, according to the humans, flagging an estimated 350 publications as questionable when they were likely legitimate. That still left more than 1,000 journals that the researchers identified as questionable.
“I think this should be used as a helper to prescreen large numbers of journals,” he said. “But human professionals should do the final analysis.”
A firewall for science
Acuña added that the researchers didn’t want their system to be a “black box” like some other AI platforms.
“With ChatGPT, for example, you often don’t understand why it’s suggesting something,” Acuña said. “We tried to make ours as interpretable as possible.”
The team discovered, for example, that questionable journals published an unusually high number of articles. They also included authors with a larger number of affiliations than more legitimate journals, and authors who cited their own research, rather than the research of other scientists, to an unusually high level.
The new AI system isn’t publicly accessible, but the researchers hope to make it available to universities and publishing companies soon. Acuña sees the tool as one way that researchers can protect their fields from bad data — what he calls a “firewall for science.”
“As a computer scientist, I often give the example of when a new smartphone comes out,” he said. “We know the phone’s software will have flaws, and we expect bug fixes to come in the future. We should probably do the same with science.”
Co-authors on the study included Han Zhuang at the Eastern Institute of Technology in China and Lizheng Liang at Syracuse University in the United States.
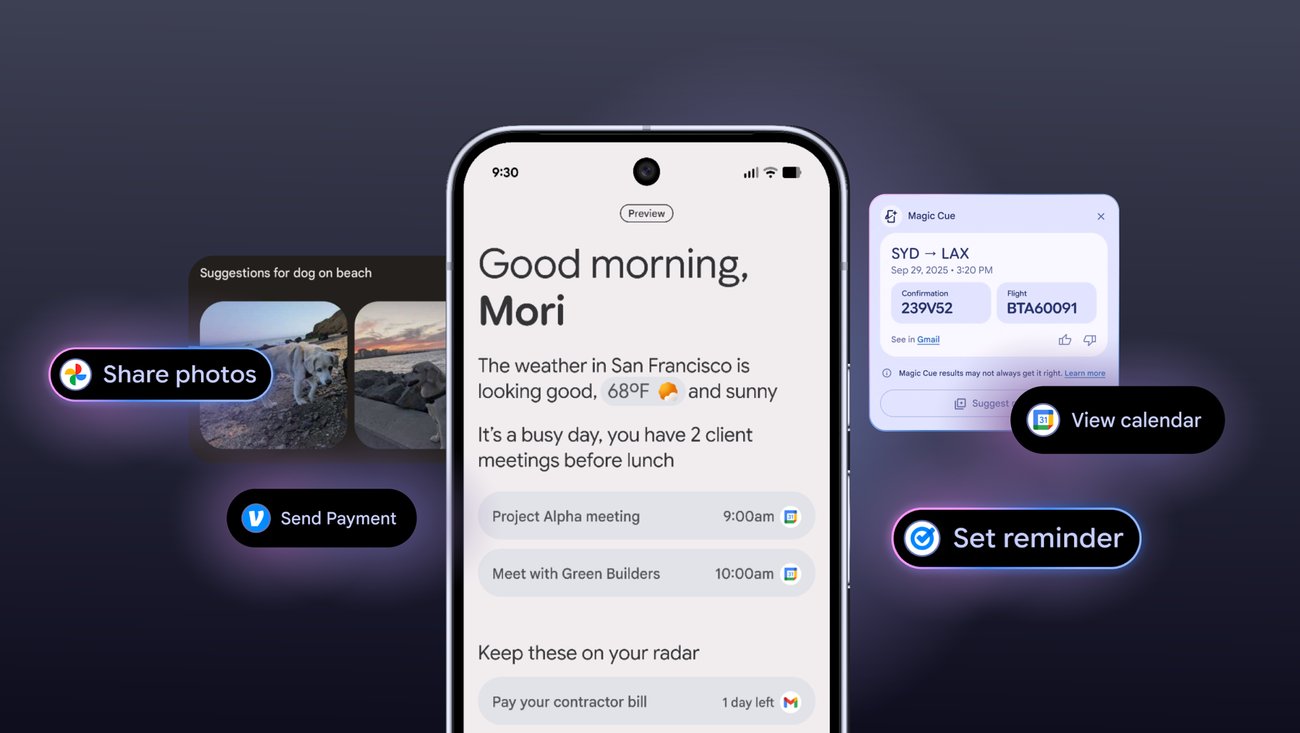
Pixel Magic Cue AI is Google’s latest strategic play to embed proactive, time-saving intelligence directly into the Pixel experience, fundamentally reshaping mobile productivity.
Google is doubling down on ambient intelligence, and its latest move, the Pixel Magic Cue AI, aims to fundamentally reshape how users interact with their devices for everyday productivity. This isn’t just another feature; it’s a strategic push to embed AI deeper into the Pixel experience, making the phone a proactive assistant rather than a reactive tool.
The premise is simple: anticipate user needs, streamline tasks, and cut down on decision fatigue. According to the announcement, the Pixel Magic Cue AI is designed to save users significant time by intelligently managing information and actions across the device. This positions Google squarely in the ongoing race among tech giants to deliver truly useful on-device AI, moving beyond flashy demos to tangible, daily benefits.
One of the core promises of Magic Cue AI is its ability to distill complex information. Imagine receiving a lengthy email thread or a dense document. Instead of sifting through paragraphs, Magic Cue can provide a concise summary, highlighting key points and action items. This isn’t just about speed reading; it’s about intelligent extraction, allowing users to grasp the essence of communications without the cognitive load. For professionals drowning in digital noise, this could be a game-changer, freeing up mental bandwidth for more critical tasks.
Beyond Summaries: Proactive Assistance
The AI’s capabilities extend far beyond text summarization. It’s engineered to anticipate your next move. For instance, if you’re planning a trip, Magic Cue AI can automatically pull flight details from your emails, suggest local attractions based on your calendar, and even pre-fill forms for hotel check-ins. This level of predictive assistance moves the Pixel from a device you operate to a partner that understands your context and helps you navigate your day with minimal friction. It’s a subtle but powerful shift towards a truly ambient computing experience, where the technology fades into the background, leaving you to focus on the task at hand.
Another significant time-saver comes in managing notifications and communications. Magic Cue AI can intelligently prioritize alerts, group related messages, and even draft quick replies based on context and your communication style. This isn’t just about silencing your phone; it’s about ensuring you see what’s important when it’s important, and providing tools to respond efficiently without getting bogged down in trivial interactions. The implications for digital well-being are substantial, potentially reducing the constant pull of notifications that often fragment our attention.
Finally, the Pixel Magic Cue AI aims to simplify device management itself. From optimizing battery life based on usage patterns to suggesting app shortcuts for frequently performed actions, the AI learns and adapts to your habits. This continuous optimization means less time spent tweaking settings and more time using your phone effectively. It’s Google’s vision of a smartphone that truly understands its owner, making the device feel less like a gadget and more like an extension of your own productivity.
The rollout of Pixel Magic Cue AI isn’t just about adding new features; it’s about Google’s long-term strategy to differentiate its hardware through intelligent software. As AI becomes increasingly commoditized, the real battle will be in how seamlessly and intuitively it integrates into daily life. Magic Cue represents a significant step in that direction, setting a new bar for what users can expect from their mobile devices and pushing the industry further into an era of truly proactive, context-aware computing.
-
Tools & Platforms3 weeks ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy1 month ago
Ethics & Policy1 month agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences3 months ago
Events & Conferences3 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers2 months ago
Jobs & Careers2 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Funding & Business2 months ago
Funding & Business2 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries
-

 Education2 months ago
Education2 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi
-

 Mergers & Acquisitions2 months ago
Mergers & Acquisitions2 months agoDonald Trump suggests US government review subsidies to Elon Musk’s companies
-

 Jobs & Careers2 months ago
Jobs & Careers2 months agoAstrophel Aerospace Raises ₹6.84 Crore to Build Reusable Launch Vehicle