AI Research
AI Research Review 08.14.25 – Self-evolving AI
One of the largest limitations of AI models current is that they are static once they are trained. Giving AI the ability to improve itself without training data would unlock enormous improvements in AI capabilities. As the R-Zero paper puts it:
Self-evolving Large Language Models (LLMs) offer a scalable path toward superintelligence by autonomously generating, refining, and learning from their own experiences.
The three papers below present various types of self-evolution of AI systems, by using iterative feedback loops combined with self-evaluations, i.e., LLM-as-a-judge, to guide AI improvement.
-
A Comprehensive Survey of Self-Evolving AI Agents. This survey paper on Self-Evolving AI Agents shows how self-evolution principles are applied to AI Agent systems, to enable such systems to continue to improve in real-world environments.
-
Test-Time Diffusion Deep Researcher (TTD-DR): The TTD-DR paper uses iterative refinement and self-evolution to improve deep research AI workflows.
-
R-Zero: Self-Evolving Reasoning LLM from Zero Data: The R-Zero paper shows a method for self-improving AI reasoning, with Challenger and Solver model refined models, to improve AI reasoning by improving both questions and answers in the training process.
The evolution from MOP (Model Offline Pretraining) to MASE (Multi-Agent Self-Evolving) represents a fundamental shift in the development of LLM-based systems, from static, manually configured architectures to adaptive, data-driven systems that can evolve in response to changing requirements and environments.
Existing AI agent designs remain fixed after training and deployment, limiting their ability to adapt to dynamic real-world environments. The paper A Comprehensive Survey of Self-Evolving AI Agents: A New Paradigm Bridging Foundation Models and Lifelong Agentic Systems examines self-evolving AI agents, an emerging paradigm that aims to imbue static foundation models with the continuous adaptability necessary for lifelong agentic systems.
This work formalizes self-evolving agents as autonomous systems capable of continuous self-optimization through environmental interaction, using the term MASE, Multi-Agent Self-Evolving systems, to describe such systems.
The paper proposes “Three Laws of Self-Evolving AI Agents” as guiding principles to ensure safe and effective self-improvement: Endure (safety adaptation), Excel (performance preservation), and Evolve (autonomous optimization). MASE systems are driven by the core goal of “adapting to changing tasks, contexts and resources while preserving safety and enhancing performance.”
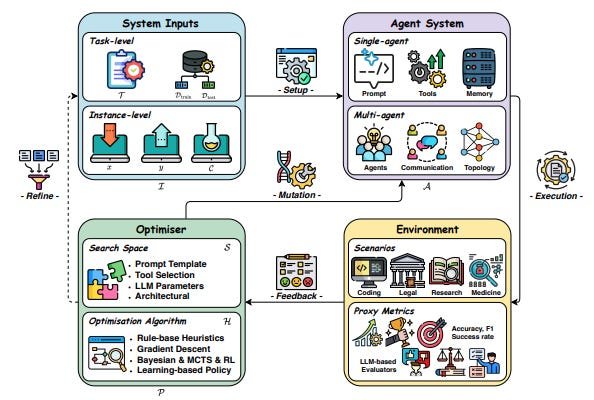
The conceptual framework for how self-evolving agentic systems work breaks the underlying feedback loop for AI system learning into four key components: System Inputs, Agent System, Environment, and Optimisers.
This framework underpins iterative refinement, where the AI agent system (single agent or multi-agent) processes inputs within an environment, generates feedback signals, and then utilizes optimizers—which define a search space and an algorithm—to update its components. These components include the core LLM’s behavior, prompt strategies, memory mechanisms, tool integration, and in multi-agent settings, workflow topologies and communication protocols.
This survey categorizes and details existing optimization techniques across these components and highlights domain-specific strategies in areas like biomedicine, programming, and finance. They observe progress in shifting from manually configured systems towards automated learning and adaptation in AI agent architectures and behaviors.
While significant challenges remain in areas such as reward modeling stability, real-world evaluation, and managing efficiency-effectiveness trade-offs, the insights offered lay a foundational understanding for developing more robust and trustworthy adaptive AI agent systems.
Our framework meticulously models the entire research report generation as an iterative diffusion process, mirroring human cognitive patterns. – Deep Researcher with Test-Time Diffusion.
The paper Deep Researcher with Test-Time Diffusion from Google Research introduces TTD-DR, a novel framework designed to improving LLM-powered deep research agents in generating complex, long-form reports. This system significantly outperforms existing deep research agents.
Existing agents often struggle with maintaining coherence and minimizing information loss during iterative search processes, lacking a principled, human-like iterative research paradigm. The TTD-DR addresses this by conceptualizing research report generation as a diffusion process, mirroring the human approach of iterative drafting, searching, reasoning, writing, and revision.
Crucially, the framework incorporates two synergistic mechanisms:
Report-Level Refinement via Denoising with Retrieval: After planning, TTD-DR generates a preliminary, updatable draft, which serves as an evolving foundation to guide the research direction. This draft undergoes iterative refinement through a “denoising” process, dynamically informed by a retrieval mechanism that incorporates external information at each step. This continuous feedback loop ensures the report remains coherent and the research stays on track, mitigating the context loss common in linear agentic workflows.

Component-wise Optimization via Self-Evolution: TTD-DR uses a self-evolutionary algorithm to enhance each component of the workflow – research plan generation, search question formulation, and answer synthesis. This involves generating multiple variants of outputs, assessing them using an LLM-as-a-judge, revising based on feedback, and merging the best elements. This interplay ensures high-quality context for the overall report diffusion.
TTD-DR demonstrates state-of-the-art performance across a wide array of benchmarks requiring intensive search and multi-hop reasoning. On long-form report generation tasks, it achieved win rates of 69.1% on LongForm Research and 74.5% on DeepConsult benchmarks in side-by-side comparisons against OpenAI Deep Research.
The TTD-DR process is a clever approach for deep research report generation, and a close analogy to human-based drafting. Such iterative, human-inspired frameworks with built-in iterative feedback have potential across many agentic tasks, so expect similar workflow self-evolution design patterns for other tasks.
The research paper from Tencent AI Lab R-Zero: Self-Evolving Reasoning LLM from Zero Data addresses a critical bottleneck in advancing AI systems beyond human intelligence: the scalability and cost of human data annotation for training self-evolving LLMs. The paper introduces a fully autonomous framework called R-Zero that enables LLMs to self-evolve their reasoning without reliance on human-curated tasks or labels.
R-Zero’s core contribution is a novel co-evolutionary loop between two independent models, a Challenger that asks questions and a Solver that answers them, to iteratively generate, solve, and learn from their own experiences:
The Challenger is rewarded for proposing tasks near the edge of the Solver capability, and the Solver is rewarded for solving increasingly challenging tasks posed by the Challenger. This process yields a targeted, self-improving curriculum without any pre-existing tasks and labels.
Both the Challenger and the Solver are fine-tuned via Group Relative Policy Optimization, GRPO. The Challenger reward function is designed to incentivize questions that maximize the Solver’s uncertainty, with a 50% chance of solving them. Similar to other systems for reasoning without verifiable-rewards, the Solver derives its labels for training through a majority-vote mechanism from its own multiple generated answers, eliminating the need for external verification or human labelling.

Empirically, R-Zero consistently and substantially improves the reasoning capabilities of tested AI reasoning models:
Zero substantially improves reasoning capability across different backbone LLMs, e.g., boosting the Qwen3-4B-Base by +6.49 on math reasoning benchmarks, and +7.54 on general-domain reasoning benchmarks (SuperGPQA).
One limitation is that as questions become more difficult, the accuracy of the self-generated pseudo-labels can decline, a potential limitation for ultimate performance. Future work could focus on more robust pseudo-labeling techniques and extending this paradigm to subjective open-ended generative tasks.
By alleviating reliance on human data and scaling self-improvement, R-Zero is not just scaling AI reasoning, but takes us closer to self-evolving AI models.
AI Research
Brown awarded $20 million to lead artificial intelligence research institute aimed at mental health support

A $20 million grant from the National Science Foundation will support the new AI Research Institute on Interaction for AI Assistants, called ARIA, based at Brown to study human-artificial intelligence interactions and mental health. The initiative, announced in July, aims to help develop AI support for mental and behavioral health.
“The reason we’re focusing on mental health is because we think this represents a lot of the really big, really hard problems that current AI can’t handle,” said Associate Professor of Computer Science and Cognitive and Psychological Sciences Ellie Pavlick, who will lead ARIA. After viewing news stories about AI chatbots’ damage to users’ mental health, Pavlick sees renewed urgency in asking, “What do we actually want from AI?”
The initiative is part of a bigger investment from the NSF to support the goals of the White House’s AI Action Plan, according to a NSF press release. This “public-private investment,” the press release says, will “sustain and enhance America’s global AI dominance.”
According to Pavlick, she and her fellow researchers submitted the proposal for ARIA “years ago, long before the administration change,” but the response was “very delayed” due to “a lot of uncertainty at (the) NSF.”
One of these collaborators was Michael Frank, the director of the Center for Computational Brain Science at the Carney Institute and a professor of psychology.
Frank, who was already working with Pavlick on projects related to AI and human learning, said that the goal is to tie together collaborations of members from different fields “more systematically and more broadly.”
According to Roman Feiman, an assistant professor of cognitive and psychological sciences and linguistics and another member of the ARIA team, the goal of the initiative is to “develop better virtual assistants.” But that goal includes various obstacles to ensure the machines “treat humans well,” behave ethically and remain controllable.
Within the study, some “people work basic cognitive neuroscience, other people work more on human machine interaction (and) other people work more on policy and society,” Pavlick explained.
Although the ARIA team consists of many faculty and students at Brown, according to Pavlick, other institutions like Carnegie Mellon University, University of New Mexico and Dartmouth are also involved. On top of “basic science” research, ARIA’s research also examines the best practices for patient safety and the legal implications of AI.
“As everybody currently knows, people are relying on (large language models) a lot, and I think many people who rely on them don’t really know how best to use them, and don’t entirely understand their limitations,” Feiman said.
According to Frank, the goal is not to “replace human therapists,” but rather to assist them.
Assistant Professor of the Practice of Computer Science and Philosophy Julia Netter, who studies the ethics of technology and responsible computing and is not involved in ARIA, said that ARIA has “the right approach.”
Netter said ARIA approach differs from previous research “in that it really tried to bring in experts from other areas, people who know about mental health” and others, rather than those who focus solely on computer science.
But the ethics of using AI in a mental health context is a “tricky question,” she added.
“This is an area that touches people at a point in time when they are very, very vulnerable,” Netter said, adding that any interventions that arise from this research should be “well-tested.”
“You’re touching an area of a person’s life that really has the potential of making a huge difference, positive or negative,” she added.
Because AI is “not going anywhere,” Frank said he is excited to “understand and control it in ways that are used for good.”
“My hope is that there will be a shift from just trying stuff and seeing what gets a better product,” Feiman said. “I think there’s real potential for scientific enterprise — not just a profit-making enterprise — of figuring out what is actually the best way to use these things to improve people’s lives.”
Get The Herald delivered to your inbox daily.

Mumbai: The BITS School of Management (BITSoM), under the aegis of BITS Pilani, a leading private university, will inaugurate its new BITSoM Research in AI and Innovation (BRAIN) Lab in its Kalyan Campus on Friday. The lab is designed to prepare future leaders for workplaces transformed by artificial intelligence, on Friday on its Kalyan campus.
While explaining the concept of the laboratory, professor Saravanan Kesavan, dean of BITSoM, said that the BRAIN Lab had three core pillars–teaching, research, and outreach. Kesavan said, “It provides MBA (masters in business administration) students a dedicated space equipped with high-performance AI computers capable of handling tasks such as computer vision and large-scale data analysis. Students will not only learn about AI concepts in theory but also experiment with real-world applications.” Kesavan added that each graduating student would be expected to develop an AI product as part of their coursework, giving them first-hand experience in innovation and problem-solving.
The BRAIN lab is also designed to be a hub of collaboration where researchers can conduct projects in partnership with various companies and industries, creating a repository of practical AI tools to use. Kesavan said, “The initial focus areas (of the lab) include manufacturing, healthcare, banking and financial services, and Global Capability Centres (subsidiaries of multinational corporations that perform specialised functions).” He added that the case studies and research from the lab will be made freely available to schools, colleges, researchers, and corporate partners, ensuring that the benefits of the lab reach beyond the BITSoM campus.
BITSoM also plans to use the BRAIN Lab as a launchpad for startups. An AI programme will support entrepreneurs in developing solutions as per their needs while connecting them to venture capital networks in India and Silicon Valley. This will give young companies the chance to refine their ideas with guidance from both academics and industry leaders.
The centre’s physical setup resembles a modern computer lab, with dedicated workspaces, collaborative meeting rooms, and brainstorming zones. It has been designed to encourage creativity, allowing students to visualise how AI works, customise tools for different industries, and allow their technical capabilities to translate into business impacts.
In the context of a global workplace that is embracing AI, Kesavan said, “Future leaders need to understand not just how to manage people but also how to manage a workforce that combines humans and AI agents. Our goal is to ensure every student graduating from BITSoM is equipped with the skills to build AI products and apply them effectively in business.”
Kesavan said that advisors from reputed institutions such as Harvard, Johns Hopkins, the University of Chicago, and industry professionals from global companies will provide guidance to students at the lab. Alongside student training, BITSoM also plans to run reskilling programmes for working professionals, extending its impact beyond the campus.

The use of artificial intelligence to score statewide standardized tests resulted in errors that affected hundreds of exams, the NBC10 Investigators have learned.
The issue with the Massachusetts Comprehensive Assessment System (MCAS) surfaced over the summer, when preliminary results for the exams were distributed to districts.
The state’s testing contractor, Cognia, found roughly 1,400 essays did not receive the correct scores, according to a spokesperson with the Department of Elementary and Secondary Education.
DESE told NBC10 Boston all the essays were rescored, affected districts received notification, and all their data was corrected in August.
So how did humans detect the problem?
We found one example in Lowell. Turns out an alert teacher at Reilly Elementary School was reading through her third-grade students’ essays over the summer. When the instructor looked up the scores some of the students received, something did not add up.
The teacher notified the school principal, who then flagged the issue with district leaders.
“We were on alert that there could be a learning curve with AI,” said Wendy Crocker-Roberge, an assistant superintendent in the Lowell school district.
AI essay scoring works by using human-scored exemplars of what essays at each score point look like, according to DESE.
DESE pointed out the affected exams represent a small percentage of the roughly 750,000 MCAS essays statewide.
The AI tool uses that information to score the essays. In addition, humans give 10% of the AI-scored essays a second read and compare their scores with the AI score to make sure there aren’t discrepancies. AI scoring was used for the same amount of essays in 2025 as in 2024, DESE said.
Crocker-Roberge said she decided to read about 1,000 essays in Lowell, but it was tough to pinpoint the exact reason some students did not receive proper credit.
However, it was clear the AI technology was deducting points without justification. For instance, Crocker-Roberge said she noticed that some essays lost a point when they did not use quotation marks when referencing a passage from the reading excerpt.
“We could not understand why an individual score was scored a zero when it should have gotten six out of seven points,” Crocker-Roberge said. “There just wasn’t any rhyme or reason to that.”
District leaders notified DESE about the problem, which resulted in approximately 1,400 essays being rescored. The state agency says the scoring problem was the result of a “temporary technical issue in the process.”
According to DESE, 145 districts were notified that had at least one student essay that was not scored correctly.
“As one way of checking that MCAS scores are accurate, DESE releases preliminary MCAS results to districts and gives them time to report any issues during a discrepancy period each year,” a DESE spokesperson wrote in a statement.
Mary Tamer, the executive director of MassPotential, an organization that advocates for educational improvement, said there are a lot of positives to using AI and returning scores back to school districts faster so appropriate action can be taken. For instance, test results can help identify a child in need of intervention or highlight a lesson plan for a teacher that did not seem to resonate with students.
“I think there’s a lot of benefits that outweigh the risks,” said Tamer. “But again, no system is perfect and that’s true for AI. The work always has to be doublechecked.”
DESE pointed out the affected exams represent a small percentage of the roughly 750,000 MCAS essays statewide.
However, in districts like Lowell, there are certain schools tracked by DESE to ensure progress is being made and performance standards are met.
That’s why Crocker-Roberge said every score counts.
With MCAS results expected to be released to parents in the coming weeks, the assistant superintendent is encouraging other districts to do a deep dive on their student essays to make sure they don’t notice any scoring discrepancies.
“I think we have to always proceed with caution when we’re introducing new tools and techniques,” Crocker-Roberge said. “Artificial intelligence is just a really new learning curve for everyone, so proceed with caution.”
There’s a new major push for AI training in the Bay State, where educators are getting savvier by the second. NBC10 Boston education reporter Lauren Melendez has the full story.
-

 Business2 weeks ago
Business2 weeks agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-
Tools & Platforms1 month ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy2 months ago
Ethics & Policy2 months agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences4 months ago
Events & Conferences4 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers2 months ago
Jobs & Careers2 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Education2 months ago
Education2 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Education2 months ago
Education2 months agoMacron says UK and France have duty to tackle illegal migration ‘with humanity, solidarity and firmness’ – UK politics live | Politics
-

 Funding & Business2 months ago
Funding & Business2 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi