AI Insights
AI plays an ever-bigger role on college campuses

It’s just one example of how artificial intelligence has found a home at many New England colleges and universities. Administrators are using the technology to write content, run surveys, crunch data, and fill out repetitive paperwork. Admissions officers are predicting future enrollment with AI. Money-minded executives lean on it to analyze tuition prices. IT employees use it to fight cybersecurity attacks, and on and on.
It marks a radical shift from the AI skepticism that pervaded higher education when ChatGPT first launched. Professors raged about a rise in cheating and worried AI would sap students’ critical thinking skills. (To be fair, many still worry about this.)
Today, many colleges want to show “AI native” students that they can address those concerns and adopt the technology at the same time. Institutions are rapidly creating artificial intelligence courses. Even traditional liberal arts schools such as Bowdoin College in Maine are courting professors to research AI to “help bend its trajectory toward the common good,” as president Safa Zaki wrote in a statement.
But while classroom uses of AI draw attention, the biggest benefits for schools puzzling over how to do more with less may reside in administration and student life. Broader use of AI tools is increasing retention and productivity among staff in marketing, finance, IT, and regulatory affairs, several university leaders said. It all equates to time and money saved.
Those savings have never been more valuable. An explosion of professional staff over the last quarter-century pushed up universities’ operating costs and created a glut of highly paid administrators at some campuses. Federal funding is under threat during the second Trump administration. Enrollment is down almost everywhere.
“In education, there’s a great opportunity for a win-win here,” said Kartik Hosanagar, a University of Pennsylvania professor who has researched AI. “Right now, universities are constrained because of the cuts in federal funding and hiring freezes. In the midst of it all, universities are continuing to try to do more. How do you make it work? The only answer to that is to increase productivity of the workers.”
At Roxbury Community College, for example, “AskRoxie” is part of a suite of AI tools that ensure the school can support thousands of new students from the state’s free community college program, without adding an army of staff, said Robyn Shahid-Bellot, RCC’s vice president of enterprise transformation.
“We would not be able to keep up with demand, unless we changed how we operate,” she said. “It would be nice to add more people whenever we have an influx in students, but unfortunately that’s not the case. That’s not just the challenge for RCC — it’s the challenge for everyone. You cannot just keep hiring and hiring and hiring.”
Wentworth Institute of Technology also announced in the fall that it would use AI to identify at-risk students and develop strategies to improve graduation rates, in part to “enhance efficiency” and “reduce costs.”
Artificial intelligence has streamlined the growth of new campuses at Northeastern University, too, which has in recent years developed outposts from London to Seattle. Before the college opens another satellite campus, it must submit hundreds of pages of paperwork on job placement data, market studies, and a comparative analysis of nearby universities to local regulators.
Now as the school expands its offerings in Toronto and New York, it is using Claude, an Anthropic-backed AI assistant that Northeastern licenses, to generate much of the framework in under 10 minutes, saving enormous staff time, said Mary Ludden, senior vice president for strategic initiatives at Northeastern.
“To do the work we’re doing in 2025, we would have to add headcount,” she said. “But we are having better quality work with the same amount of people. The staff are thinking, where does AI make the most sense? Where will it augment or improve what we are doing?”
Productivity is up at Babson College, too. An employee survey found that 83 percent of staff members save up to five hours a week with Microsoft 365 Copilot, another digital assistant; 5 percent save even more. Over half the staff said their job satisfaction is up.
The Wellesley business college was among the first schools to publicly adopt artificial intelligence and later launched a faculty-run AI lab called The Generator. It trained half of professors on the technology and inspired discussions about AI use in the classroom. Babson employees are now spot-treating university marketing materials, perfecting search functions, and deflecting bot traffic from the college website — all with artificial intelligence.

“The reception [to AI] was more positive than even I expected,” said Patty Patria, Babson’s chief information officer. “The use of alternative AI is already pervasive on campus. But we train staff to leverage it — not just to be a tool to make life easier, but to help you with ideas and innovation.”
That said, just like in many other industries, fears abound that the technology could replace jobs at colleges. And even business-focused schools such as Babson have “conscientious resisters” among the faculty, said Erik Noyes, an entrepreneurship professor and one of nine faculty founders of The Generator.
Other professors see benefits. Babson’s MathBot, for example, is open to freshman students seeking clarity on basic math topics and draws its knowledge from 10 textbooks. It has reduced the tutoring responsibilities for professors and peer tutors outside of class, as many college-age students struggle with math after the pandemic.
“We think of AI as a big tent, and we want multiple front doors to enter in and have the conversation,” Noyes said. “We didn’t want people at Babson to think AI is about ChatGPT only.”
Not all colleges are eager to jump on the AI train or have the money to do so. Institution-wide licenses for generative AI chatbots can be expensive, and schools facing falling enrollment and bleeding budget may not be able to keep up. Nationwide, only 27 percent of colleges offer school-wide generative AI access, according to an April Inside Higher Education survey.

Still, a growing number are taking the leap, including Boston University, which acquired its own AI tools for its tens of thousands of students and staff and launched TerrierGPT this spring.
Brian Smith, associate dean for research at Boston College’s Lynch School of Education and Human Development, said college staff‘s use of AI is a sign universities are moving away from the initial “panic” surrounding the technology. All told, artificial intelligence is potentially transformative for an industry where money problems are mounting.
“If college faculty and staff can offload, we can do the important work. The machines can do weird, silly things or burdensome, repetitive things. That’s the history of computing,” Smith said. “All of education is asking what the right answer is, and there isn’t one. All colleges can do is try.”
Diti Kohli can be reached at diti.kohli@globe.com. Follow her @ditikohli_.

Chinese chipmakers are trading at a four-year high versus their US peers, but a top fund manager still sees pockets of opportunity among their equipment suppliers.
Source link
AI Insights
Deep computer vision with artificial intelligence based sign language recognition to assist hearing and speech-impaired individuals

This study proposes a novel HHODLM-SLR technique. The presented HHODLM-SLR technique mainly concentrates on the advanced automatic detection and classification of SL for disabled people. This technique comprises BF-based image pre-processing, ResNet-152-based feature extraction, BiLSTM-based SLR, and HHO-based hyperparameter tuning. Figure 1 represents the workflow of the HHODLM-SLR model.
Image Pre-preprocessing
Initially, the HHODLM-SLR approach utilized BF to eliminate noise in an input image dataset38. This model is chosen due to its dual capability to mitigate noise while preserving critical edge details, which is crucial for precisely interpreting complex hand gestures. Unlike conventional filters, such as Gaussian or median filtering, that may blur crucial features, BF maintains spatial and intensity-based edge sharpness. This confirms that key contours of hand shapes are retained, assisting improved feature extraction downstream. Its nonlinear, content-aware nature makes it specifically efficient for complex visual patterns in sign language datasets. Furthermore, BF operates efficiently and is adaptable to varying lighting or background conditions. These merits make it an ideal choice over conventional pre-processing techniques in this application. Figure 2 represents the working flow of the BF model.

BF is a nonlinear image processing method employed for preserving edges, whereas decreasing noise in images makes it effective for pre-processing in SLR methods. It smoothens the image by averaging pixel strengths according to either spatial proximity or intensity similarities, guaranteeing that edge particulars are essential for recognizing hand movements and shapes remain unchanged. This is mainly valued in SLR, whereas refined edge features and hand gestures are necessary for precise interpretation. By utilizing BF, noise from environmental conditions, namely background clutter or lighting variations, is reduced, improving the clearness of the input image. This pre-processing stage helps increase the feature extraction performance and succeeding detection phases in DL methods.
Feature extraction using ResNet-152 model
The HHODLM-SLR technique implements the ResNet152 model for feature extraction39. This model is selected due to its deep architecture and capability to handle vanishing gradient issues through residual connections. This technique captures more complex and abstract features that are significant for distinguishing subtle discrepancies in hand gestures compared to standard deep networks or CNNs. Its 152-layer depth allows it to learn rich hierarchical representations, enhancing recognition accuracy. The skip connections in ResNet improve gradient flow and enable enhanced training stability. Furthermore, it has proven effectualness across diverse vision tasks, making it a reliable backbone for SL recognition. This depth, performance, and robustness integration sets it apart from other feature extractors. Figure 3 illustrates the flow of the ResNet152 technique.
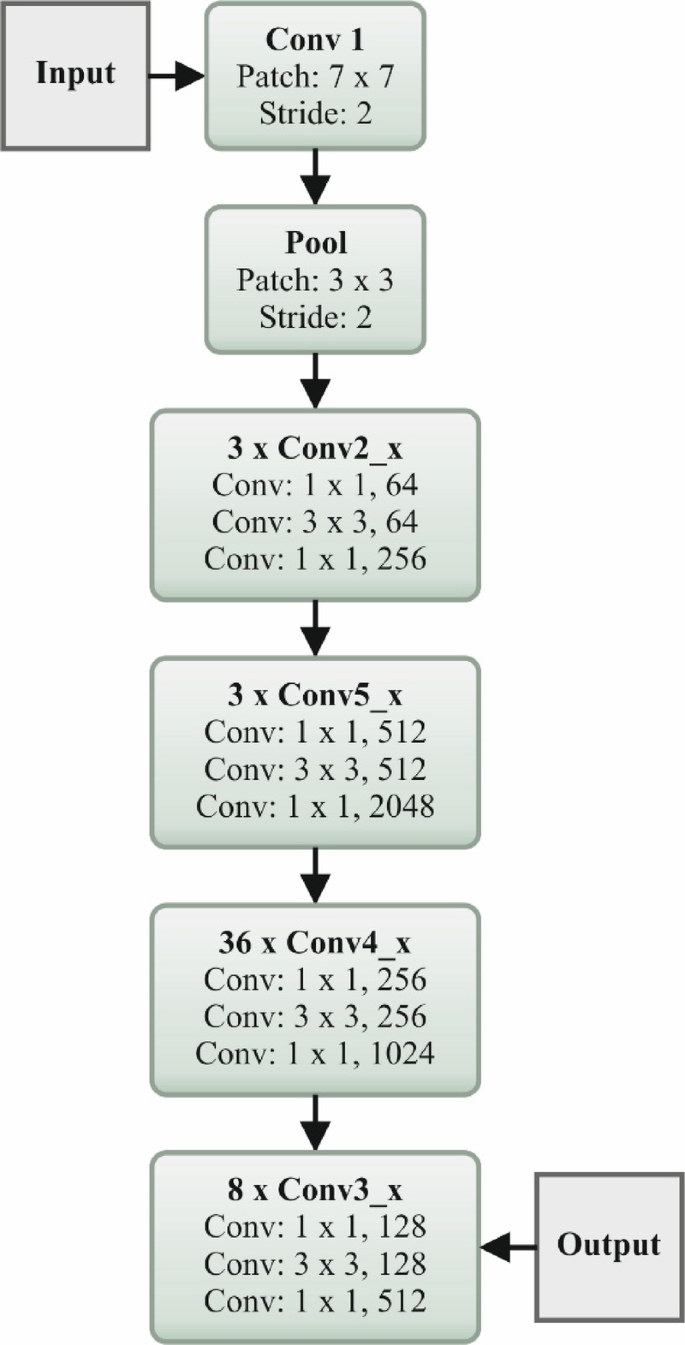
Workflow of the ResNet152 model.
The renowned deep residual network ResNet152 is applied as the pre-trained system in deep convolutional neural networks (DCNN) during this classification method. This technique is responsible for handling the problem of vanishing gradients. Then, the ResNet152 output is transferred to the SoftMax classifier (SMC) in the classification procedure. The succeeding part covers the process of categorizing and identifying characteristics. The fully connected (FC) layer, convolution layer (CL), and downsampling layers (DSL) are some of the most general layers that constitute a DCNN (FCL). The networking depth of DL methods plays an essential section in the model of attaining increased classifier outcomes. Later, for particular values, once the CNN is made deeper, the networking precision starts to slow down; however, persistence decreases after that. The mapping function is added in ResNet152 to reduce the influence of degradation issues.
$$\:W\left(x\right)=K\left(x\right)+x$$
(1)
Here, \(\:W\left(x\right)\) denotes the function of mapping built utilizing a feedforward NN together with SC. In general, SC is the identity map that is the outcome of bypassing similar layers straight, and \(\:K(x,\:{G}_{i})\) refers to representations of the function of residual maps. The formulation is signified by Eq. (2).
$$\:Z=K\left(x,\:{G}_{i}\right)+x$$
(2)
During the CLs of the ResNet method, \(\:3\text{x}3\) filtering is applied, and the down-sampling process is performed by a stride of 2. Next, short-cut networks were added, and the ResNet was built. An adaptive function is applied, as presented by Eq. (3), to enhance the dropout’s implementation now.
$$\:u=\frac{1}{n}{\sum\:}_{i=1}^{n}\left[zlog{(S}_{i})+\left(1-z\right)log\left(1-{S}_{i}\right)\right]$$
(3)
Whereas \(\:n\) denotes training sample counts, \(\:u\) signifies the function of loss, and \(\:{S}_{i}\) represents SMC output, the SMC is a kind of general logistic regression (LR) that might be applied to numerous class labels. The SMC outcomes are presented in Eq. (4).
$$\:{S}_{i}=\frac{{e}^{{l}_{k}}}{{\varSigma\:}_{j=1}^{m}{e}^{{y}_{i}}},\:k=1,\:\cdots\:,m,\:y={y}_{1},\:\cdots\:,\:{y}_{m}$$
(4)
In such a case, the softmax layer outcome is stated. \(\:{l}_{k}\) denotes the input vector component and \(\:l,\) \(\:m\) refers to the total neuron counts established in the output layer. The presented model uses 152 10 adaptive dropout layers (ADLs), an SMC, and convolutional layers (CLs).
SLR using Bi-LSTM technique
The Bi-LSTM model employs the HHODLM-SLR methodology for performing the SLR process40. This methodology is chosen because it can capture long-term dependencies in both forward and backward directions within gesture sequences. Unlike unidirectional LSTM or conventional RNNs, Bi-LSTM considers past and future context concurrently, which is significant for precisely interpreting the temporal flow of dynamic signs. This bidirectional learning enhances the model’s understanding of gesture transitions and co-articulation effects. Its memory mechanism effectually handles variable-length input sequences, which is common in real-world SLR scenarios. Bi-LSTM outperforms static classifiers like CNNs or SVMs when dealing with sequential data, making it highly appropriate for recognizing time-based gestures. Figure 4 specifies the Bi-LSTM method.
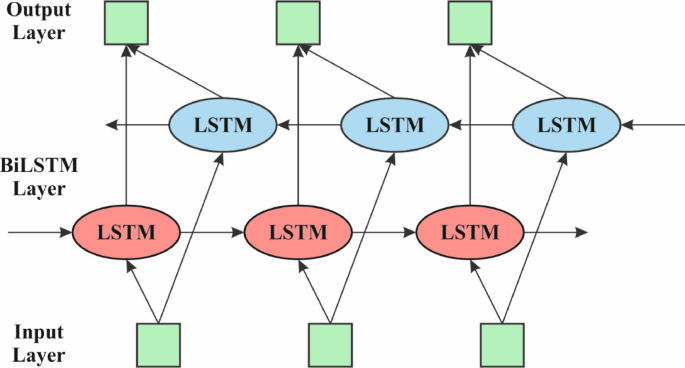
Architecture of Bi-LSTM method.
The presented DAE-based approach for removing the feature is defined here. Additionally, Bi-LSTM is applied to categorize the data. The model to solve classification problems consists of the type of supervised learning. During this method, the Bi‐LSTM classification techniques are used to estimate how the proposed architecture increases the performance of the classification. A novel RNN learning model is recommended to deal with this need, which may enhance the temporal organization of the structure. By the following time stamp, the output is immediately fed reverse itself\(\:.\) RNN is an approach that is often applied in DL. Nevertheless, RNN acquires a slanting disappearance gradient exploding problem. At the same time, the memory unit in the LSTM can choose which data must be saved in memory and at which time it must be deleted. Therefore, LSTM can effectively deal with the problems of training challenges and gradient disappearance by mine time-series with intervals in the time-series and relatively larger intervals. There are three layers in a standard LSTM model architecture: hidden loop, output, and input. The cyclic HL, by comparison with the traditional RNN, generally contains neuron nodes. Memory units assist as the initial module of the LSTM cyclic HLs. Forget, input and output gates are the three adaptive multiplication gate components enclosed in this memory unit. All neuron nodes of the LSTM perform the succeeding computation: The input gate was fixed at \(\:t\:th\) time according to the output result \(\:{h}_{t-1}\) of the component at the time in question and is specified in Eq. (5). The input \(\:{x}_{t}\) accurate time is based on whether to include a computation to upgrade the present data inside the cell.
$$\:{i}_{t}={\upsigma\:}\left({W}_{t}\cdot\:\left[{h}_{t-1},\:{x}_{t}\right]+{b}_{t}\right)$$
(5)
A forget gate defines whether to preserve or delete the data according to the additional new HL output and the present-time input specified in Eq. (6).
$$\:{f}_{\tau\:}={\upsigma\:}\left({W}_{f}\cdot\:\left[{h}_{t-1},{x}_{\tau\:}\right]+{b}_{f}\right)$$
(6)
The preceding output outcome \(\:{h}_{t-1}\) of the HL-LSTM cell establishes the value of the present candidate cell of memory and the present input data \(\:{x}_{t}\). * refers to element-to-element matrix multiplication. The value of memory cell state \(\:{C}_{t}\) adjusts the present candidate cell \(\:{C}_{t}\) and its layer \(\:{c}_{t-1}\) forget and input gates. These values of the memory cell layer are provided in Eq. (7) and Eq. (8).
$$\:{\overline{C}}_{\text{t}}=tanh\left({W}_{C}\cdot\:\left[{h}_{t-1},\:{x}_{t}\right]+{b}_{C}\right)$$
(7)
$$\:{C}_{t}={f}_{t}\bullet\:{C}_{t-1}+{i}_{t}\bullet\:\overline{C}$$
(8)
Output gate \(\:{\text{o}}_{t}\) is established as exposed in Eq. (9) and is applied to control the cell position value. The last cell’s outcome is \(\:{h}_{t}\), inscribed as Eq. (10).
$$\:{o}_{t}={\upsigma\:}\left({W}_{o}\cdot\:\left[{h}_{t-1},\:{x}_{t}\right]+{b}_{o}\right)$$
(9)
$$\:{h}_{t}={\text{o}}_{t}\bullet\:tanh\left({C}_{t}\right)$$
(10)
The forward and backward LSTM networks constitute the BiLSTM. Either the forward or the backward LSTM HLs are responsible for removing characteristics; the layer of forward removes features in the forward directions. The Bi-LSTM approach is applied to consider the effects of all features before or after the sequence data. Therefore, more comprehensive feature information is developed. Bi‐LSTM’s present state comprises either forward or backward output, and they are specified in Eq. (11), Eq. (12), and Eq. (13)
$$\:h_{t}^{{forward}} = LSTM^{{forward}} (h_{{t – 1}} ,\:x_{t} ,\:C_{{t – 1}} )$$
(11)
$$\:{h}_{\tau\:}^{backwar\text{d}}=LST{M}^{backwar\text{d}}\left({h}_{t-1},{x}_{t},\:{C}_{t-1}\right)$$
(12)
$$\:{H}_{T}={h}_{t}^{forward},\:{h}_{\tau\:}^{backwar\text{d}}$$
(13)
Hyperparameter tuning using the HHO model
The HHO methodology utilizes the HHODLM-SLR methodology for accomplishing the hyperparameter tuning process41. This model is employed due to its robust global search capability and adaptive behaviour inspired by the cooperative hunting strategy of Harris hawks. Unlike grid or random search, which can be time-consuming and inefficient, HHO dynamically balances exploration and exploitation to find optimal hyperparameter values. It avoids local minima and accelerates convergence, enhancing the performance and stability of the model. Compared to other metaheuristics, such as PSO or GA, HHO presents faster convergence and fewer tunable parameters. Its bio-inspired nature makes it appropriate for complex, high-dimensional optimization tasks in DL models. Figure 5 depicts the flow of the HHO methodology.

Workflow of the HHO technique.
The HHO model is a bio-inspired technique depending on Harris Hawks’ behaviour. This model was demonstrated through the exploitation or exploration levels. At the exploration level, the HHO may track and detect prey with its effectual eyes. Depending upon its approach, HHO can arbitrarily stay in a few positions and wait to identify prey. Suppose there is an equal chance deliberated for every perched approach depending on the family member’s position. In that case, it might be demonstrated as condition \(\:q<0.5\) or landed at a random position in the trees as \(\:q\ge\:0.5\), which is given by Eq. (14).
$$\:X\left(t+1\right)=\left\{\begin{array}{l}{X}_{rnd}\left(t\right)-{r}_{1}\left|{X}_{rnd}\left(t\right)-2{r}_{2}X\left(t\right)\right|,\:q\ge\:0.5\\\:{X}_{rab}\left(t\right)-{X}_{m}\left(t\right)-r3\left(LB+{r}_{4}\left(UB-LB\right)\right),q<0.5\end{array}\right.$$
(14)
The average location is computed by the Eq. (15).
$$\:{X}_{m}\left(t\right)=\frac{1}{N}{\sum\:}_{i=1}^{N}{X}_{i}\left(t\right)$$
(15)
The movement from exploration to exploitation, while prey escapes, is energy loss.
$$\:E=2{E}_{0}\left(1-\frac{t}{T}\right)$$
(16)
The parameter \(\:E\) signifies the prey’s escape energy, and \(\:T\) represents the maximum iteration counts. Conversely, \(\:{E}_{0}\) denotes a random parameter that swings among \(\:(-\text{1,1})\) for every iteration.
The exploitation level is divided into hard and soft besieges. The surroundings \(\:\left|E\right|\ge\:0.5\) and \(\:r\ge\:0.5\) should be met in a soft besiege. Prey aims to escape through certain arbitrary jumps but eventually fails.
$$\:\begin{array}{c}X\left(t+1\right)=\Delta X\left(t\right)-E\left|J{X}_{rabb}\left(t\right)-X\left(t\right)\right|\:where\\\:\Delta X\left(t\right)={X}_{rabb}\left(t\right)-X\left(t\right)\end{array}$$
(17)
\(\:\left|E\right|<0.5\) and \(\:r\ge\:0.5\) should meet during the hard besiege. The prey attempts to escape. This position is upgraded based on the Eq. (18).
$$\:X\left(t+1\right)={X}_{rabb}\left(t\right)-E\left|\varDelta\:X\left(t\right)\right|$$
(18)
The HHO model originates from a fitness function (FF) to achieve boosted classification performance. It outlines an optimistic number to embody the better outcome of the candidate solution. The minimization of the classifier error ratio was reflected as FF. Its mathematical formulation is represented in Eq. (19).
$$\begin{gathered} fitness\left( {x_{i} } \right) = ClassifierErrorRate\left( {x_{i} } \right)\: \hfill \\ \quad \quad \quad \quad \quad\,\,\, = \frac{{number\:of\:misclassified\:samples}}{{Total\:number\:of\:samples}} \times \:100 \hfill \\ \end{gathered}$$
(19)

Westpac Banking Corp. plans to hire 350 bankers and turn more to artificial intelligence as it ramps up business lending.
Source link
-

 Business3 days ago
Business3 days agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-
Tools & Platforms3 weeks ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy1 month ago
Ethics & Policy1 month agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences3 months ago
Events & Conferences3 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers2 months ago
Jobs & Careers2 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Funding & Business2 months ago
Funding & Business2 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries
-

 Education2 months ago
Education2 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi
-

 Mergers & Acquisitions2 months ago
Mergers & Acquisitions2 months agoDonald Trump suggests US government review subsidies to Elon Musk’s companies