Books, Courses & Certifications
Accelerate your model training with managed tiered checkpointing on Amazon SageMaker HyperPod

As organizations scale their AI infrastructure to support trillion-parameter models, they face a difficult trade-off: reduced training time with lower cost or faster training time with a higher cost. When they checkpoint frequently to speed up recovery time and minimize lost training time, they incur in substantially higher storage cost. And when they checkpoint infrequently, they reduce costs at the risk of losing valuable training progress when failures occur.
This challenge is exacerbated in large distributed training environments, with thousands of accelerators, where issues can occur frequently. According to an article released by Meta, one failure happened every 3 hours during the Meta Llama 3 model training. The GPU issues accounted for 60% of the total failures, and network, CPU, and disks account the other 40%. With infrequent checkpointing, these accumulated failures can result in losing days of training progress over the course of a complete training run, thereby driving up costs and time to market. Frequent checkpoints can saturate networks, overload storage, and result in unpredictable performance.
To help solve these challenges, AWS announced managed tiered checkpointing in Amazon SageMaker HyperPod, a purpose-built infrastructure to scale and accelerate generative AI model development across thousands of AI accelerators. Managed tiered checkpointing uses CPU memory for high-performance checkpoint storage with automatic data replication across adjacent compute nodes for enhanced reliability. Although SageMaker HyperPod identifies node issues automatically and replaces those nodes so your training can resume, managed tiered checkpointing helps you implement the best checkpointing strategy and maximize your training throughput.
Managed tiered checkpointing has been tested on large distributed training clusters ranging from hundreds of GPU to over 15,000 GPU, with checkpoints being saved within seconds.
In this post, we dive deep into those concepts and understand how to use the managed tiered checkpointing feature.
Solution overview
Checkpointing is the method of saving an intermediate model’s state during the training process. You can resume training from a recent checkpoint in the event of an issue by saving the model’s parameters, optimizer states, and other metadata during training. Additionally, you can resolve training problems, such as irregular learning rates, without a full restart by loading an earlier checkpoint state.
Use the following formula to find a rough initial estimate of the total size of the checkpoint for your model without the optimizer state:Model checkpoint size (GB) = (Number of parameters × Bytes per parameter) ÷ 10243 bytesFor example, if you train a Meta Llama 3 70-billion-parameter model using BFloat16 as the parameter’s precision, the checkpoint size will be 130 GB. If you train a DeepSeek-R1 671-billion-parameter model using BFloat16, the checkpoint size will be 1.25 TB. All without storing optimizer states.Checkpoints include optimizer states, training metadata (such as step number), and other additional data, resulting in a larger than expected size. When using an Adam optimizer, the optimizer will save three additional float16 statistics per parameter, resulting in an additional 6 bytes per parameter. Therefore, with the optimizer state saved, the Meta Llama 3 70B model checkpoint size will be approximately 521 GB, and the DeepSeek-R1 671B model checkpoint size will be approximately 5 TB. That is a four-times increase in size, and handling those checkpoints becomes a challenge.
The following table summarizes the checkpoint sizes for each model.
| Model name | Size of Checkpoint | Size of Checkpoint + Optimizer States |
| Meta Llama 3 70B | 130 GB | 521 GB |
| DeepSeek R1 671B | 1.43 TB | 5 TB |
It’s also important to consider the training strategy. In a Fully Sharded Data Parallel (FSDP) scenario, each rank (a single GPU process in a distributed training) saves its own part of the checkpoint. At the same time, it reduces the amount of data each rank has to save during a checkpoint, and imposes a stress on the file system level. On a Network File System (NFS) shared file system, those concurrent writes become a bottleneck. Using a distributed file system, such Amazon FSx for Lustre, can help alleviate that pressure at a higher total cost. In a Distributed Data Parallel (DDP) scenario, a single rank writes the complete checkpoint at one time, and all ranks read the checkpoint when loading it back. On the file system level, this means a single writer and multiple readers. On an NFS file system, many readers can be a problem because they will be constrained based on the file system, network stack, and queue size. A single writer, over the network, will not take advantage of all the network throughput. Here again, a fast, distributed file system like FSx for Lustre can help solve those problems at a higher total cost of ownership.
As we can see, traditional checkpointing methods that rely solely on remote persistent storage create a computational overhead during checkpoint creation, because writing terabytes of model parameters to persistent storage might throttle it, consume expensive network bandwidth, and require complex orchestration across distributed systems. By storing checkpoints in fast-access in-memory locations, such as CPU RAM, while maintaining configurable backup to Amazon Simple Storage Service (Amazon S3) for persistence, the system delivers faster recovery times, and is a cost-effective solution compared to traditional disk-based approaches.
Managed tiered checkpointing works as follows:
- When training your model, you define the checkpoint frequency.
- Model training uses GPU HBM memory to store the model, its parameters, and intermediate results, and do the heavy computation.
- Triggering a checkpoint stops model training. The GPU will convert the model weights (tensors) into a state dictionary and copy the data to the instance’s CPU, then the training resumes while managed tiered checkpointing copies the data to RAM.
- Because RAM is volatile, managed tiered checkpointing copies the data asynchronously from the host RAM to adjacent nodes using RDMA over Elastic Fabric Adapter (EFA). If a node experiences an issue, its checkpoint data will be available on other nodes too.
- From time to time, it copies the data to a second layer of persistent storage, such as Amazon S3. This helps both when writing to RAM fails and when you want to persistently store the checkpoint data for future use.
With managed tiered checkpointing, you can configure frequency and retention policies for both in-memory and persistent storage tiers. You use the first layer (in-memory) to save checkpoints at a high frequency and for fast recovery, periodically saving to Amazon S3 for backup. Managed tiered checkpointing provides a file system that can be seamlessly integrated with your PyTorch Distributed Checkpointing (DCP) training. Adding it to your training script only requires a few lines of code. Furthermore, it improves the performance of checkpoints by using in-memory storage while using other tiers for persistent storage. PyTorch DCP solves the issue of saving a model’s checkpoint when it uses distributed resources, such as multiple GPUs across multiple compute nodes. Trainers, parameters, and the dataset are partitioned across those nodes and resources, then PyTorch DCP saves and loads from multiple ranks in parallel. PyTorch DCP produces multiple files per checkpoint, at least one per rank. Depending on the volume of those files, number and size, shared and network file systems such as NFS will struggle with inode and metadata management. Managed tiered checkpointing helps solve that issue by making it possible to use multiple tiers, reducing intrusion to the training time and still receiving the benefits of PyTorch DCP, such as deduplication of checkpoint data.
With managed tiered checkpointing in SageMaker HyperPod, you can maintain a high training throughput even in large-scale environments prone to failures. It uses your existing SageMaker HyperPod cluster orchestrated by Amazon Elastic Kubernetes Service (Amazon EKS) and compute nodes, and there are no additional costs to use the library.
In the following sections, we explore how to configure the SageMaker HyperPod cluster’s training scripts to use this new feature.
Configure your SageMaker HyperPod cluster for managed tiered checkpointing
SageMaker HyperPod provisions resilient clusters for running machine learning (ML) workloads and developing state-of-the-art models such as large language models (LLMs), diffusion models, and foundation models (FMs). By reducing the complex work of building and maintaining compute clusters using accelerators like AWS Trainium and NVIDIA H200/B200 GPUs, it speeds up the creation of foundation models. To create a new SageMaker HyperPod cluster, refer to the Amazon SageMaker HyperPod Developer Guide. If you want to accelerate your deployment by using field hardened assets, refer to the following GitHub repo.
The examples shared in this post are intended to help you learn more about this new feature. If you’re considering running the examples provided here in a production environment, have your security team review the content and make sure they adhere to your security standards. At AWS, security is the top priority and we understand that every customer has their own security framework.Before creating or updating a cluster to add the managed tiered checkpointing feature, you must set up the EKS pods to access an S3 bucket either on your own account or across accounts. When working with buckets on the same account as the SageMaker HyperPod EKS cluster, you can use the following policy (change your bucket name before applying it):
If the bucket is in a different account, you must authorize an AWS Identity and Access Management (IAM) principal to access those buckets. The following IAM policy will do that for you. Be sure to change both the bucket name and the IAM principal (for example, your AWS account ID).
To create a new cluster with managed tiered checkpointing, you can pass a parameter using --tiered-storage-config and setting Mode to Enable using an AWS Command Line Interface (AWS CLI) command:
You can also update it using the UpdateCluster API and pass the CachingConfig parameter with the required AllocatedMemory configuration. You can use the CachingConfiguration parameter to define a fixed value or a percentage of the CPU RAM for checkpointing.
Now that your SageMaker HyperPod cluster has the managed tiered checkpointing feature, let’s prepare the training scripts and add them.
Install the managed tiered checkpoint libraries and integrate with your training script
Managed tiered checkpointing integrates with PyTorch DCP. You start by installing the sagemaker-checkpointing library. Then you create and configure a namespace to store the checkpoints based on the defined frequency. Finally, you add the checkpoint function inside your training loop.
To install the library, we simply use Python’s pip. Make sure you already have the dependencies installed: Python 3.10 or higher, PyTorch with DCP support, and the AWS credentials configured properly. To integrate Amazon S3 as another storage layer, you also need s3torchconnector installed.
Now you can import the library on your script and configure the namespace and frequency for checkpointing:
In the preceding code snippet, we have configured managed tiered checkpointing with the same world_size as the number of ranks in our cluster. When you start a distributed training, each GPU in the cluster is assigned a rank number, and the total number of GPUs available is the world_size. We set up Amazon S3 as our backup persistent storage, setting managed tiered checkpointing to store data in Amazon S3 every 100 training steps. Both world_size and namespace are required parameters; the others are optional.
Now that the configuration is ready, let’s set up PyTorch DCP and integrate managed tiered checkpointing.
First, configure the storage writer. This component will pass on to the PyTorch DCP async_save function alongside the model’s state dictionary. We use the SageMakerTieredStorageWriter when writing the checkpoints and the SageMakeTieredStorageReader when restoring from those checkpoints.
Inside your model training loop, you add the storage writer configuration and pass along both the managed tiered checkpointing configuration and the step number:
You can define the step number explicitly for the storage writer, or you can let the storage writer identify the step number from the path where the checkpoint is being saved. If you want to let the storage writer infer the step number from the base path, don’t set the stepparameter and make sure your path contains the step number in it.
Now you can call the PyTorch DCP asynchronous save function and pass along the state dictionary and the storage writer configuration:async_save(state_dict=state_dict, storage_writer=storage_writer)
We have set up managed tiered checkpointing to write checkpoints at our desired frequency and location (in-memory). Let’s use the storage reader to restore those checkpoints. First, pass the managed tiered checkpointing configuration to the SageMakerTieredStorageReader, then call the PyTorch DCP load function, passing the model state dictionary and the storage reader configuration:
To work through a complete example, refer to the following GitHub repository, where we’ve created a simple training script, including the managed tiered checkpointing feature.
Clean up
After you have worked with managed tiered checkpointing, and you want to clean up the environment, simply remove the amzn-sagemaker-checkpointing library by running pip uninstall amzn-sagemaker-checkpointing.
If you installed the solution in a Python virtual environment, then just deleting the virtual environment will suffice.Managed tiered checkpointing is a free feature that doesn’t require additional resources to run. You use your existing SageMaker HyperPod EKS cluster and compute nodes.
Best practices to optimize your checkpoint strategy with managed tiered checkpointing
Managed tiered checkpointing will attempt to write to the in-memory tier first. This optimizes the writing performance because in-memory provides ultra-low latency checkpoint access. You should configure managed tiered checkpointing to write to a second layer, such as Amazon S3, from time to time. For example, configure managed tiered checkpointing to write to the in-memory layer every 10 steps, and configure it to write to Amazon S3 every 100 steps.
If managed tiered checkpointing fails to write to the in-memory layer, and the node experiences an issue, then you still have your checkpoint saved on Amazon S3. While writing to Amazon S3, managed tiered checkpointing uses multiple TCP streams (chunks) to optimize Amazon S3 writes.
In terms of consistency, managed tiered checkpointing uses an all-or-nothing writing strategy. It implements a fallback mechanism that will seamlessly transition between the storage tiers. Checkpoint metadata, such as step number, is stored alongside the data for every tier.
When trying to troubleshoot managed tiered checkpointing, you can check the log written locally to /var/log/sagemaker_checkpointing/{namespace}_checkpointing.log. It publishes data about the training step, rank number, and the operation details. The following is an example output of that file:
Managed tiered checkpointing also writes those metrics to the console, so it’s straightforward to troubleshoot during development. They contain information on which step number is being written to which storage layer and the throughput and total time taken to write the data. With that information, you can monitor and troubleshoot managed tiered checkpointing thoroughly.
When you combine those tools with the SageMaker HyperPod observability stack, you get a complete view of all metrics of your training or inference workload.
Conclusion
The new managed tiered checkpointing feature in SageMaker HyperPod augments FM training efficiency by intelligently distributing checkpoints across multiple storage tiers. This advanced approach places model states in fast access locations such as CPU RAM memory, while using persistent storage such as Amazon S3 for cost-effective, long-term persistence. As of the time of this launch, managed tiered checkpointing is supported only on SageMaker HyperPod on Amazon EKS.
Managed tiered checkpointing delivers fast recovery times without increased storage costs, avoiding complex trade-offs between resiliency, training efficiency, and storage costs. It has been validated on large distributed training clusters that range from hundreds of GPU to more than 15,000 GPU, with checkpoints being saved within seconds.
Integrating managed tiered checkpointing on your training scripts is straightforward, with just a few lines of code, providing immediate access to sophisticated checkpoint management without requiring deep engineering expertise.
For more information on how managed tiered checkpointing works, how to set it up, and other details, refer to HyperPod managed tier checkpointing.
About the authors
Paulo Aragao is a Principal WorldWide Solutions Architect focused on Generative AI at the Specialist Organisation on AWS. He helps Enterprises and Startups to build their Foundation Models strategy and innovate faster by leveraging his extensive knowledge on High Perfomance Computing and Machine Learning. A long time bass player, and natural born rock fan, Paulo enjoys spending time travelling with his family, scuba diving, and playing real time strategy and role-playing games.
 Kunal Jha is a Principal Product Manager at AWS. He is focused on building Amazon SageMaker Hyperpod as the best-in-class choice for Generative AI model’s training and inference. In his spare time, Kunal enjoys skiing and exploring the Pacific Northwest.
Kunal Jha is a Principal Product Manager at AWS. He is focused on building Amazon SageMaker Hyperpod as the best-in-class choice for Generative AI model’s training and inference. In his spare time, Kunal enjoys skiing and exploring the Pacific Northwest.
 Mandar Kulkarni is a Software Development Engineer II at AWS, where he works on Amazon SageMaker. He specializes in building scalable and performant machine learning libraries and infrastructure solutions, particularly focusing on SageMaker HyperPod. His technical interests span machine learning, artificial intelligence, distributed systems and application security. When not architecting ML solutions, Mandar enjoys hiking, practicing Indian classical music, sports, and spending quality time with his young family.
Mandar Kulkarni is a Software Development Engineer II at AWS, where he works on Amazon SageMaker. He specializes in building scalable and performant machine learning libraries and infrastructure solutions, particularly focusing on SageMaker HyperPod. His technical interests span machine learning, artificial intelligence, distributed systems and application security. When not architecting ML solutions, Mandar enjoys hiking, practicing Indian classical music, sports, and spending quality time with his young family.
 Vinay Devadiga is a Software Development Engineer II at AWS with a deep passion for artificial intelligence and cloud computing. He focuses on building scalable, high-performance systems that enable the power of AI and machine learning to solve complex problems.Vinay enjoys staying at the forefront of technology, continuously learning, and applying new advancements to drive innovation. Outside of work, he likes playing sports and spending quality time with his family.
Vinay Devadiga is a Software Development Engineer II at AWS with a deep passion for artificial intelligence and cloud computing. He focuses on building scalable, high-performance systems that enable the power of AI and machine learning to solve complex problems.Vinay enjoys staying at the forefront of technology, continuously learning, and applying new advancements to drive innovation. Outside of work, he likes playing sports and spending quality time with his family.
 Vivek Maran is a Software Engineer at AWS. He currently works on the development of Amazon SageMaker HyperPod, a resilient platform for large scale distributed training and inference. His interests include large scale distributed systems, network systems, and artificial intelligence. Outside of work, he enjoys music, running, and keeping up to date with business & technology trends.
Vivek Maran is a Software Engineer at AWS. He currently works on the development of Amazon SageMaker HyperPod, a resilient platform for large scale distributed training and inference. His interests include large scale distributed systems, network systems, and artificial intelligence. Outside of work, he enjoys music, running, and keeping up to date with business & technology trends.
Books, Courses & Certifications
Student Scores in Math, Science, Reading Slide Again on Nation’s Report Card

Exasperating. Depressing. Predictable.
That’s how experts describe the latest results from the National Assessment of Educational Progress, also known as the “nation’s report card.”
Considered a highly accurate window into student performance, the assessment has become a periodic reminder of declining academic success among students in the U.S., with the last several rounds accentuating yearslong slumps in learning. In January, for instance, the previous round of NAEP results revealed the biggest share of eighth graders who did not meet basic reading proficiency in the assessment’s history.
Now, the latest results, released Tuesday after a delay, showed continued decline.
Eighth graders saw the first fall in average science scores since the assessment took its current form in 2009. The assessment looked at physical science, life science, and earth and space sciences. Thirty-eight percent of students performed below basic, a level which means these students probably don’t know that plants need sunlight to grow and reproduce, according to NAEP. In contrast, only 31 percent of students performed at proficient levels.
Twelfth graders saw a three-point fall in average math and reading scores, compared to results from 2019. The exam also shows that the achievement gap between high- and low-scoring students is swelling, a major point of concern. In math, the gap is wider than it’s ever been.
But most eye-grabbing is the fact that 45 percent of high school seniors — the highest percentage ever recorded — scored below basic in math, meaning they cannot determine probabilities of simple events from two-way tables and verbal descriptions. In contrast, just 22 percent scored at-or-above proficient. In reading, 32 percent scored below basic, and 35 percent met the proficient threshold. Twelfth grade students also reported high rates of absenteeism.
Tucked inside the report was the finding that parents’ education did not appear to hold much sway on student performance in the lower quartiles, which will bear further unpacking, according to one expert’s first analysis.
But the scores contained other glum trends, as well.
For example, the gap in outcomes in the sciences between male and female students, which had narrowed in recent years, bounced back. (A similar gap in math reappeared since the pandemic, pushing educators to get creative in trying to nourish girls’ interest in the subject.)
But with teacher shortages and schools facing enrollment declines and budget shortfalls, experts say it’s not surprising that students still struggle. Those who watch education closely describe themselves as tired, exasperated and even depressed from watching a decade’s worth of student performance declines. They also express doubt that political posturing around the scores will translate into improvements.
Political Posturing
Despite a sterling reputation, the assessment found itself snagged by federal upheaval.
NAEP is a congressionally mandated program run by the National Center for Education Statistics. Since the last round of results was released, back in January, the center and the broader U.S. Department of Education have dealt with shredded contracts, mass firings and the sudden dismissal of Peggy Carr, who’d helped burnish the assessment’s reputation and statistical rigor and whose firing delayed the release of these latest results.
The country’s education system overall has also undergone significant changes, including the introduction of a national school choice plan, meant to shift public dollars to private schools, through the Republican budget.
Declining scores provide the Trump administration a potential cudgel for its dismantling of public education, and some have seized upon it: Congressman Tim Walberg, a Republican from Michigan and chairman of the House Education and Workforce Committee, blamed the latest scores on the Democrats’ “student-last policies,” in a prepared statement.
“The lesson is clear,” argued Education Secretary Linda McMahon in her comment on the latest scores. “Success isn’t about how much money we spend, but who controls the money and where that money is invested,” she wrote, stressing that students need an approach that returns control education to the states.
Some observers chortle at the “back to the states” analysis. After all, state and local governments already control most of the policies and spending related to public schools.
Regardless, experts suggest that just pushing more of education governance to the states will not solve the underlying causes of declining student performance. Declines in scores predate the pandemic, they also say.
No Real Progress
States have always been in charge of setting their own standards and assessments, says Latrenda Knighten, president of the National Council of Teachers of Mathematics. These national assessments are useful for comparing student performance across states, she adds.
Ultimately, in her view, the latest scores reveal the need for efforts to boost high-quality instruction and continuous professional learning for teachers to address systemic issues, a sentiment reflected in her organization’s public comment on the assessment. The results shine a spotlight on the need for greater opportunity in high school mathematics across the country, Knighten told EdSurge. She believes that means devoting more money for teacher training.
Some think that the causes of this academic slide are relatively well understood.
Teacher quality has declined, as teacher prep programs struggle to supply qualified teachers, particularly in math, and schools struggle to fill vacancies, says Robin Lake, director of the Center on Reinventing Public Education. She argues there has also been a decline in the desire to push schools to be accountable for poor student performance, and an inability to adapt.
There’s also confusion about which curriculum is best for students, she says. For instance, fierce debates continue to split teachers around “tracking,” where students are grouped into math paths based on perceived ability.
But will yet another poor national assessment spur change?
The results continue a decade-long decline in student performance, says Christy Hovanetz, a senior policy fellow for the nonprofit ExcelinEd.
Hovanetz worries that NAEP’s potential lessons will get “lost in the wash.” What’s needed is a balance between turning more authority back over to the states to operate education and a more robust requirement for accountability that allows states to do whatever they want, so long as they demonstrate it’s actually working, she says. That could mean requiring state assessments and accountability systems, she adds.
But right now, a lot of the states aren’t focusing on best practices for science and reading instruction, and they aren’t all requiring high-quality instructional materials, she says.
Worse, some are lowering the standards to meet poor student performance, she argues. For instance, Kansas recently altered its state testing. The changes, which involved changing score ranges, have drawn concerns from parents that the state is watering down standards. Hovanetz thinks that’s the case. In making the changes, the state joined Illinois, Wisconsin and Oklahoma in lowering expectations for students on state tests, she argues.
What’s uncontested from all perspectives is that the education system isn’t working.
“It’s truly the definition of insanity: to keep doing what we’re doing and hoping for better results,” says Lake, of the Center on Reinventing Public Education, adding: “We’re not getting them.”

When the National Assessment of Educational Progress, often called the Nation’s Report Card, was released last year, the results were sobering. Despite increased funding streams and growing momentum behind the Science of Reading, average fourth grade reading scores declined by another two points from 2022.
In a climate of growing accountability and public scrutiny, how can we do things differently — and more effectively — to ensure every child becomes a proficient reader?
The answer lies not only in what happens inside the classroom but in the connections forged between schools and families. Research shows that when families are equipped with the right tools and guidance, literacy development accelerates. For many schools, creating this home-to-school connection begins by rethinking how they communicate with and involve families from the start.
A School-Family Partnership in Practice
My own experience with my son William underscored just how impactful a strong school-family partnership can be.
When William turned four, he began asking, “When will I be able to read?” He had watched his older brother learn to read with relative ease, and, like many second children, William was eager to follow in his big brother’s footsteps. His pre-K teacher did an incredible job introducing foundational literacy skills, but for William, it wasn’t enough. He was ready to read, but we, his parents, weren’t sure how to support him.
During a parent-teacher conference, his teacher recommended a free, ad-free literacy app that she uses in her classroom. She assigned stories to read and phonics games to play that aligned with his progress at school. The characters in the app became his friends, and the activities became his favorite challenge. Before long, he was recognizing letters on street signs, rhyming in the car and asking to read his favorite stories over and over again.
William’s teacher used insights from his at-home learning to personalize his instruction in the classroom. For our family, this partnership made a real difference.
Where Literacy Begins: Bridging Home and School
Reading develops in stages, and the pre-K to kindergarten years are especially foundational. According to the National Reading Panel and the Institute of Education Sciences, five key pillars support literacy development:
- Phonemic awareness: recognizing and playing with individual sounds in spoken words
- Phonics: connecting those sounds to written letters
- Fluency: reading with ease, accuracy and expression
- Vocabulary: understanding the meaning of spoken and written words
- Comprehension: making sense of what is read
For schools, inviting families into this framework doesn’t mean making parents into teachers. It means providing simple ways for families to reinforce these pillars at home, often through everyday routines, such as reading together, playing language games or talking about daily activities.
Families are often eager to support their children’s reading, but many aren’t sure how. At the same time, educators often struggle to communicate academic goals to families in ways that are clear and approachable.
Three Ways to Strengthen School-Family Literacy Partnerships
Forging effective partnerships between schools and families can feel daunting, but small, intentional shifts can make a powerful impact. Here are three research-backed strategies that schools can use to bring families into the literacy-building process.
1. Communicate the “why” and the “how”
Families become vital partners when they understand not just what their children are learning, but why it matters. Use newsletters, family literacy nights or informal conversations to break down the five pillars in accessible terms. For example, explain that clapping out syllables at home supports phonemic awareness or that spotting road signs helps with letter recognition (phonics).
Even basic activities can reinforce classwork. Sample ideas for family newsletters:
- “This week we’re working on beginning sounds. Try playing a game where you name things in your house that start with the letter ‘B’.”
- “We’re focusing on listening to syllables in words. See if your child can clap out the beats in their name!”
Provide families with specific activities that match what is being taught at school. For example, William’s teacher used the Khan Academy Kids app to assign letter-matching games and read-aloud books that aligned with classroom learning. The connection made it easier for us to support him at home.
2. Establish everyday reading routines
Consistency builds confidence. Encourage families to create regular reading moments, such as a story before bed, a picture book over breakfast or a read-aloud during bath time. Reinforce that reading together in any language is beneficial. Oral storytelling, silly rhymes and even talking through the day’s events help develop vocabulary and comprehension.
Help parents understand that it’s okay to stop when it’s no longer fun. If a child isn’t interested, it’s better to pause and return later than to force the activity. The goal is for children to associate reading with enjoyment and a sense of connection.
3. Empower families with fun, flexible tools
Families are more likely to participate when activities are playful and accessible, not just another assignment. Suggest resources that fit different family preferences: printable activity sheets, suggested library books and no-cost, ad-free digital platforms, such as Khan Academy Kids. These give children structured ways to practice and offer families tools that are easy to use, even with limited time.
In our district, many families use technology to extend classroom skills at home. For William, a rhyming game on a literacy app made practicing phonological awareness fun and stress-free; he returned to it repeatedly, reinforcing new skills through play.
Literacy Grows Best in Partnership
School-family partnerships also offer educators valuable feedback. When families share observations about what excites or challenges their children at home, teachers gain a fuller picture of each student’s progress. Digital platforms, such as teacher, school and district-level reporting, can support this feedback loop by providing teachers with real-time data on at-home practice. This two-way exchange strengthens instruction and empowers both families and educators.
While curriculum, assessment and skilled teaching are essential, literacy is most likely to flourish when nurtured by both schools and families. When educators invite families into the process — demystifying the core elements of literacy, sharing routines and providing flexible, accessible tools — they help create a culture where reading is valued everywhere.
Strong school-family partnerships don’t just address achievement gaps. They lay the groundwork for the joy, confidence and curiosity that help children become lifelong readers.
At Khan Academy Kids, we believe in the power of the school-family partnership. For free resources to help strengthen children’s literacy development, explore the Khan Academy Kids resource hub for schools.
Books, Courses & Certifications
TII Falcon-H1 models now available on Amazon Bedrock Marketplace and Amazon SageMaker JumpStart
This post was co-authored with Jingwei Zuo from TII.
We are excited to announce the availability of the Technology Innovation Institute (TII)’s Falcon-H1 models on Amazon Bedrock Marketplace and Amazon SageMaker JumpStart. With this launch, developers and data scientists can now use six instruction-tuned Falcon-H1 models (0.5B, 1.5B, 1.5B-Deep, 3B, 7B, and 34B) on AWS, and have access to a comprehensive suite of hybrid architecture models that combine traditional attention mechanisms with State Space Models (SSMs) to deliver exceptional performance with unprecedented efficiency.
In this post, we present an overview of Falcon-H1 capabilities and show how to get started with TII’s Falcon-H1 models on both Amazon Bedrock Marketplace and SageMaker JumpStart.
Overview of TII and AWS collaboration
TII is a leading research institute based in Abu Dhabi. As part of UAE’s Advanced Technology Research Council (ATRC), TII focuses on advanced technology research and development across AI, quantum computing, autonomous robotics, cryptography, and more. TII employs international teams of scientists, researchers, and engineers in an open and agile environment, aiming to drive technological innovation and position Abu Dhabi and the UAE as a global research and development hub in alignment with the UAE National Strategy for Artificial Intelligence 2031.
TII and Amazon Web Services (AWS) are collaborating to expand access to made-in-the-UAE AI models across the globe. By combining TII’s technical expertise in building large language models (LLMs) with AWS Cloud-based AI and machine learning (ML) services, professionals worldwide can now build and scale generative AI applications using the Falcon-H1 series of models.
About Falcon-H1 models
The Falcon-H1 architecture implements a parallel hybrid design, using elements from Mamba and Transformer architectures to combine the faster inference and lower memory footprint of SSMs like Mamba with the effectiveness of Transformers’ attention mechanism in understanding context and enhanced generalization capabilities. The Falcon-H1 architecture scales across multiple configurations ranging from 0.5–34 billion parameters and provides native support for 18 languages. According to TII, the Falcon-H1 family demonstrates notable efficiency with published metrics indicating that smaller model variants achieve performance parity with larger models. Some of the benefits of Falcon-H1 series include:
- Performance – The hybrid attention-SSM model has optimized parameters with adjustable ratios between attention and SSM heads, leading to faster inference, lower memory usage, and strong generalization capabilities. According to TII benchmarks published in Falcon-H1’s technical blog post and technical report, Falcon-H1 models demonstrate superior performance across multiple scales against other leading Transformer models of similar or larger scales. For example, Falcon-H1-0.5B delivers performance similar to typical 7B models from 2024, and Falcon-H1-1.5B-Deep rivals many of the current leading 7B-10B models.
- Wide range of model sizes – The Falcon-H1 series includes six sizes: 0.5B, 1.5B, 1.5B-Deep, 3B, 7B, and 34B, with both base and instruction-tuned variants. The Instruct models are now available in Amazon Bedrock Marketplace and SageMaker JumpStart.
- Multilingual by design – The models support 18 languages natively (Arabic, Czech, German, English, Spanish, French, Hindi, Italian, Japanese, Korean, Dutch, Polish, Portuguese, Romanian, Russian, Swedish, Urdu, and Chinese) and can scale to over 100 languages according to TII, thanks to a multilingual tokenizer trained on diverse language datasets.
- Up to 256,000 context length – The Falcon-H1 series enables applications in long-document processing, multi-turn dialogue, and long-range reasoning, showing a distinct advantage over competitors in practical long-context applications like Retrieval Augmented Generation (RAG).
- Robust data and training strategy – Training of Falcon-H1 models employs an innovative approach that introduces complex data early on, contrary to traditional curriculum learning. It also implements strategic data reuse based on careful memorization window assessment. Additionally, the training process scales smoothly across model sizes through a customized Maximal Update Parametrization (µP) recipe, specifically adapted for this novel architecture.
- Balanced performance in science and knowledge-intensive domains – Through a carefully designed data mixture and regular evaluations during training, the model achieves strong general capabilities and broad world knowledge while minimizing unintended specialization or domain-specific biases.
In line with their mission to foster AI accessibility and collaboration, TII have released Falcon-H1 models under the Falcon LLM license. It offers the following benefits:
- Open source nature and accessibility
- Multi-language capabilities
- Cost-effectiveness compared to proprietary models
- Energy-efficiency
About Amazon Bedrock Marketplace and SageMaker JumpStart
Amazon Bedrock Marketplace offers access to over 100 popular, emerging, specialized, and domain-specific models, so you can find the best proprietary and publicly available models for your use case based on factors such as accuracy, flexibility, and cost. On Amazon Bedrock Marketplace you can discover models in a single place and access them through unified and secure Amazon Bedrock APIs. You can also select your desired number of instances and the instance type to meet the demands of your workload and optimize your costs.
SageMaker JumpStart helps you quickly get started with machine learning. It provides access to state-of-the-art model architectures, such as language models, computer vision models, and more, without having to build them from scratch. With SageMaker JumpStart you can deploy models in a secure environment by provisioning them on SageMaker inference instances and isolating them within your virtual private cloud (VPC). You can also use Amazon SageMaker AI to further customize and fine-tune the models and streamline the entire model deployment process.
Solution overview
This post demonstrates how to deploy a Falcon-H1 model using both Amazon Bedrock Marketplace and SageMaker JumpStart. Although we use Falcon-H1-0.5B as an example, you can apply these steps to other models in the Falcon-H1 series. For help determining which deployment option—Amazon Bedrock Marketplace or SageMaker JumpStart—best suits your specific requirements, see Amazon Bedrock or Amazon SageMaker AI?
Deploy Falcon-H1-0.5B-Instruct with Amazon Bedrock Marketplace
In this section, we show how to deploy the Falcon-H1-0.5B-Instruct model in Amazon Bedrock Marketplace.
Prerequisites
To try the Falcon-H1-0.5B-Instruct model in Amazon Bedrock Marketplace, you must have access to an AWS account that will contain your AWS resources.Prior to deploying Falcon-H1-0.5B-Instruct, verify that your AWS account has sufficient quota allocation for ml.g6.xlarge instances. The default quota for endpoints using several instance types and sizes is 0, so attempting to deploy the model without a higher quota will trigger a deployment failure.
To request a quota increase, open the AWS Service Quotas console and search for Amazon SageMaker. Locate ml.g6.xlarge for endpoint usage and choose Request quota increase, then specify your required limit value. After the request is approved, you can proceed with the deployment.
Deploy the model using the Amazon Bedrock Marketplace UI
To deploy the model using Amazon Bedrock Marketplace, complete the following steps:
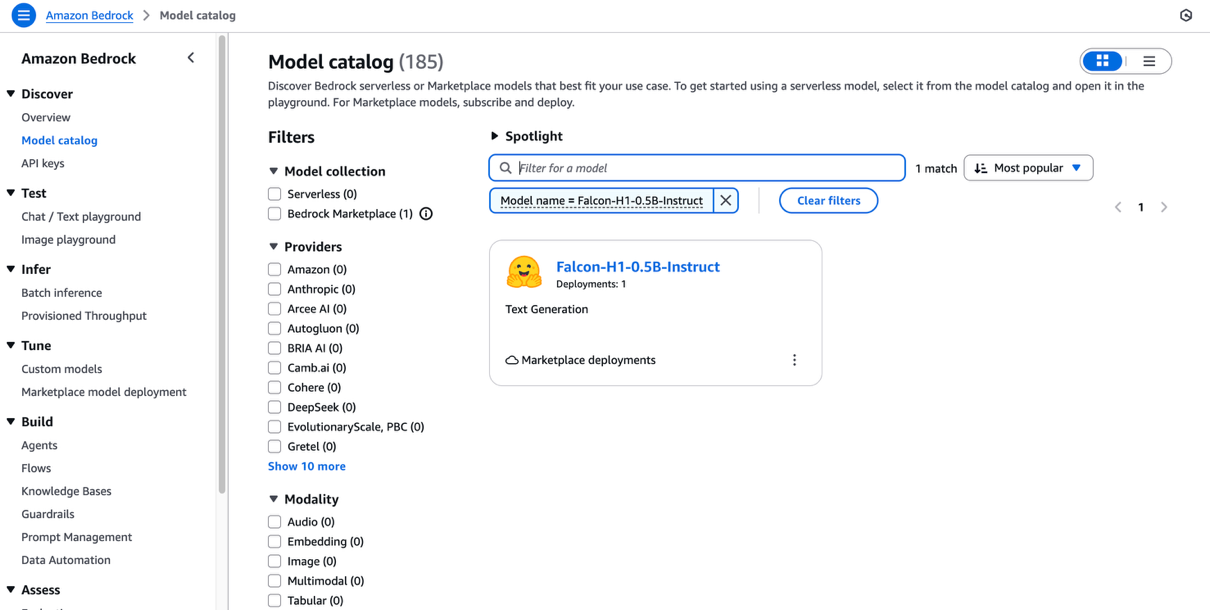
- On the Amazon Bedrock console, under Discover in the navigation pane, choose Model catalog.
- Filter for Falcon-H1 as the model name and choose Falcon-H1-0.5B-Instruct.
The model overview page includes information about the model’s license terms, features, setup instructions, and links to further resources.
- Review the model license terms, and if you agree with the terms, choose Deploy.
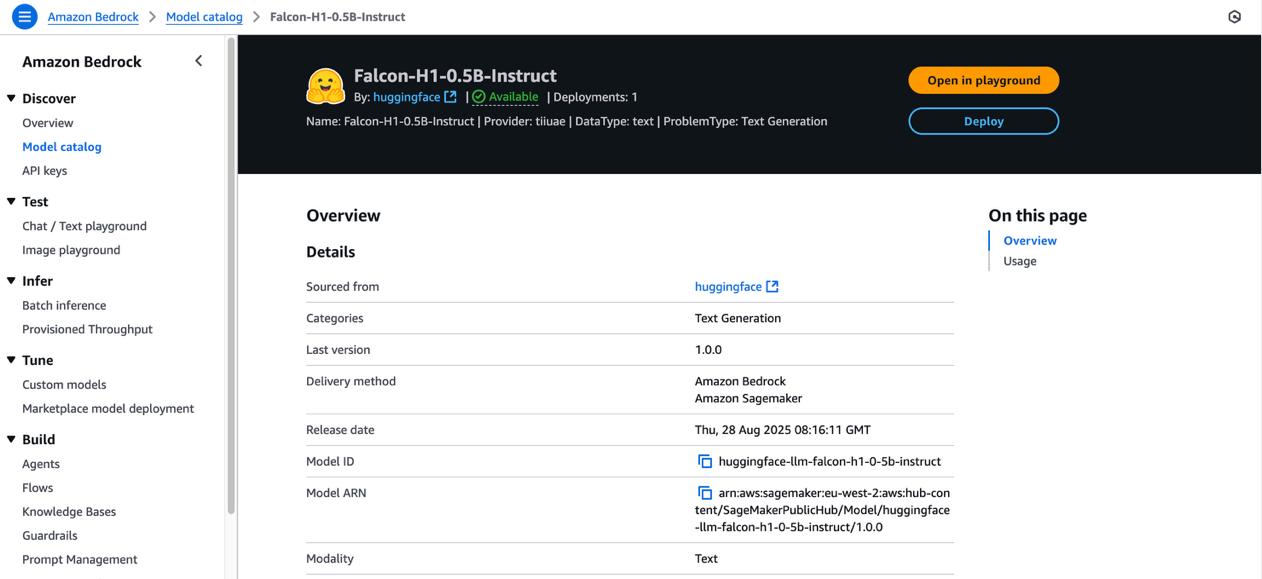
- For Endpoint name, enter an endpoint name or leave it as the default pre-populated name.
- To minimize costs while experimenting, set the Number of instances to 1.
- For Instance type, choose from the list of compatible instance types. Falcon-H1-0.5B-Instruct is an efficient model, so ml.m6.xlarge is sufficient for this exercise.
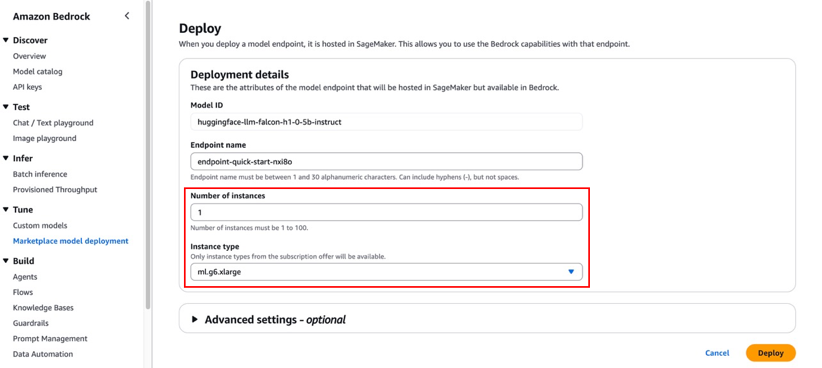
Although the default configurations are typically sufficient for basic needs, you can customize advanced settings like VPC, service access permissions, encryption keys, and resource tags. These advanced settings might require adjustment for production environments to maintain compliance with your organization’s security protocols.
- Choose Deploy.
- A prompt asks you to stay on the page while the AWS Identity and Access Management (IAM) role is being created. If your AWS account lacks sufficient quota for the selected instance type, you’ll receive an error message. In this case, refer to the preceding prerequisite section to increase your quota, then try the deployment again.
While deployment is in progress, you can choose Marketplace model deployments in the navigation pane to monitor the deployment progress in the Managed deployment section. When the deployment is complete, the endpoint status will change from Creating to In Service.
Interact with the model in the Amazon Bedrock Marketplace playground
You can now test Falcon-H1 capabilities directly in the Amazon Bedrock playground by selecting the managed deployment and choosing Open in playground.
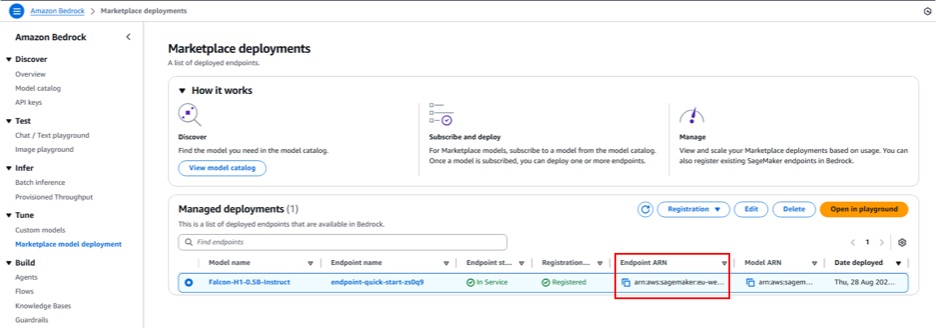
You can now use the Amazon Bedrock Marketplace playground to interact with Falcon-H1-0.5B-Instruct.
Invoke the model using code
In this section, we demonstrate to invoke the model using the Amazon Bedrock Converse API.
Replace the placeholder code with the endpoint’s Amazon Resource Name (ARN), which begins with arn:aws:sagemaker. You can find this ARN on the endpoint details page in the Managed deployments section.
To learn more about the detailed steps and example code for invoking the model using Amazon Bedrock APIs, refer to Submit prompts and generate response using the API.
Deploy Falcon-H1-0.5B-Instruct with SageMaker JumpStart
You can access FMs in SageMaker JumpStart through Amazon SageMaker Studio, the SageMaker SDK, and the AWS Management Console. In this walkthrough, we demonstrate how to deploy Falcon-H1-0.5B-Instruct using the SageMaker Python SDK. Refer to Deploy a model in Studio to learn how to deploy the model through SageMaker Studio.
Prerequisites
To deploy Falcon-H1-0.5B-Instruct with SageMaker JumpStart, you must have the following prerequisites:
- An AWS account that will contain your AWS resources.
- An IAM role to access SageMaker AI. To learn more about how IAM works with SageMaker AI, see Identity and Access Management for Amazon SageMaker AI.
- Access to SageMaker Studio with a JupyterLab space, or an interactive development environment (IDE) such as Visual Studio Code or PyCharm.
Deploy the model programmatically using the SageMaker Python SDK
Before deploying Falcon-H1-0.5B-Instruct using the SageMaker Python SDK, make sure you have installed the SDK and configured your AWS credentials and permissions.
The following code example demonstrates how to deploy the model:
When the previous code segment completes successfully, the Falcon-H1-0.5B-Instruct model deployment is complete and available on a SageMaker endpoint. Note the endpoint name shown in the output—you will replace the placeholder in the following code segment with this value.The following code demonstrates how to prepare the input data, make the inference API call, and process the model’s response:
Clean up
To avoid ongoing charges for AWS resources used while experimenting with Falcon-H1 models, make sure to delete all deployed endpoints and their associated resources when you’re finished. To do so, complete the following steps:
- Delete Amazon Bedrock Marketplace resources:
- On the Amazon Bedrock console, choose Marketplace model deployment in the navigation pane.
- Under Managed deployments, choose the Falcon-H1 model endpoint you deployed earlier.
- Choose Delete and confirm the deletion if you no longer need to use this endpoint in Amazon Bedrock Marketplace.
- Delete SageMaker endpoints:
- On the SageMaker AI console, in the navigation pane, choose Endpoints under Inference.
- Select the endpoint associated with the Falcon-H1 models.
- Choose Delete and confirm the deletion. This stops the endpoint and avoids further compute charges.
- Delete SageMaker models:
- On the SageMaker AI console, choose Models under Inference.
- Select the model associated with your endpoint and choose Delete.
Always verify that all endpoints are deleted after experimentation to optimize costs. Refer to the Amazon SageMaker documentation for additional guidance on managing resources.
Conclusion
The availability of Falcon-H1 models in Amazon Bedrock Marketplace and SageMaker JumpStart helps developers, researchers, and businesses build cutting-edge generative AI applications with ease. Falcon-H1 models offer multilingual support (18 languages) across various model sizes (from 0.5B to 34B parameters) and support up to 256K context length, thanks to their efficient hybrid attention-SSM architecture.
By using the seamless discovery and deployment capabilities of Amazon Bedrock Marketplace and SageMaker JumpStart, you can accelerate your AI innovation while benefiting from the secure, scalable, and cost-effective AWS Cloud infrastructure.
We encourage you to explore the Falcon-H1 models in Amazon Bedrock Marketplace or SageMaker JumpStart. You can use these models in AWS Regions where Amazon Bedrock or SageMaker JumpStart and the required instance types are available.
For further learning, explore the AWS Machine Learning Blog, SageMaker JumpStart GitHub repository, and Amazon Bedrock User Guide. Start building your next generative AI application with Falcon-H1 models and unlock new possibilities with AWS!
Special thanks to everyone who contributed to the launch: Evan Kravitz, Varun Morishetty, and Yotam Moss.
About the authors
 Mehran Nikoo leads the Go-to-Market strategy for Amazon Bedrock and agentic AI in EMEA at AWS, where he has been driving the development of AI systems and cloud-native solutions over the last four years. Prior to joining AWS, Mehran held leadership and technical positions at Trainline, McLaren, and Microsoft. He holds an MBA from Warwick Business School and an MRes in Computer Science from Birkbeck, University of London.
Mehran Nikoo leads the Go-to-Market strategy for Amazon Bedrock and agentic AI in EMEA at AWS, where he has been driving the development of AI systems and cloud-native solutions over the last four years. Prior to joining AWS, Mehran held leadership and technical positions at Trainline, McLaren, and Microsoft. He holds an MBA from Warwick Business School and an MRes in Computer Science from Birkbeck, University of London.
 Mustapha Tawbi is a Senior Partner Solutions Architect at AWS, specializing in generative AI and ML, with 25 years of enterprise technology experience across AWS, IBM, Sopra Group, and Capgemini. He has a PhD in Computer Science from Sorbonne and a Master’s degree in Data Science from Heriot-Watt University Dubai. Mustapha leads generative AI technical collaborations with AWS partners throughout the MENAT region.
Mustapha Tawbi is a Senior Partner Solutions Architect at AWS, specializing in generative AI and ML, with 25 years of enterprise technology experience across AWS, IBM, Sopra Group, and Capgemini. He has a PhD in Computer Science from Sorbonne and a Master’s degree in Data Science from Heriot-Watt University Dubai. Mustapha leads generative AI technical collaborations with AWS partners throughout the MENAT region.
 Jingwei Zuo is a Lead Researcher at the Technology Innovation Institute (TII) in the UAE, where he leads the Falcon Foundational Models team. He received his PhD in 2022 from University of Paris-Saclay, where he was awarded the Plateau de Saclay Doctoral Prize. He holds an MSc (2018) from the University of Paris-Saclay, an Engineer degree (2017) from Sorbonne Université, and a BSc from Huazhong University of Science & Technology.
Jingwei Zuo is a Lead Researcher at the Technology Innovation Institute (TII) in the UAE, where he leads the Falcon Foundational Models team. He received his PhD in 2022 from University of Paris-Saclay, where he was awarded the Plateau de Saclay Doctoral Prize. He holds an MSc (2018) from the University of Paris-Saclay, an Engineer degree (2017) from Sorbonne Université, and a BSc from Huazhong University of Science & Technology.
 John Liu is a Principal Product Manager for Amazon Bedrock at AWS. Previously, he served as the Head of Product for AWS Web3/Blockchain. Prior to joining AWS, John held various product leadership roles at public blockchain protocols and financial technology (fintech) companies for 14 years. He also has nine years of portfolio management experience at several hedge funds.
John Liu is a Principal Product Manager for Amazon Bedrock at AWS. Previously, he served as the Head of Product for AWS Web3/Blockchain. Prior to joining AWS, John held various product leadership roles at public blockchain protocols and financial technology (fintech) companies for 14 years. He also has nine years of portfolio management experience at several hedge funds.
 Hamza MIMI is a Solutions Architect for partners and strategic deals in the MENAT region at AWS, where he bridges cutting-edge technology with impactful business outcomes. With expertise in AI and a passion for sustainability, he helps organizations architect innovative solutions that drive both digital transformation and environmental responsibility, transforming complex challenges into opportunities for growth and positive change.
Hamza MIMI is a Solutions Architect for partners and strategic deals in the MENAT region at AWS, where he bridges cutting-edge technology with impactful business outcomes. With expertise in AI and a passion for sustainability, he helps organizations architect innovative solutions that drive both digital transformation and environmental responsibility, transforming complex challenges into opportunities for growth and positive change.
-

 Business2 weeks ago
Business2 weeks agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-
Tools & Platforms4 weeks ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy2 months ago
Ethics & Policy2 months agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences4 months ago
Events & Conferences4 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers2 months ago
Jobs & Careers2 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Education2 months ago
Education2 months agoMacron says UK and France have duty to tackle illegal migration ‘with humanity, solidarity and firmness’ – UK politics live | Politics
-

 Education2 months ago
Education2 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Funding & Business2 months ago
Funding & Business2 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi