AI Research
Intuition: Rebuilding the Internet for the AI Agent Era

This report was written by Tiger Research, analyzing Intuition’s approach to rebuilding web infrastructure for the agentic AI era through atom-based knowledge structuring, token-curated registries for standard consensus, and signal-based trust measurement systems.
Key Takeaways
-
The agentic AI era has arrived. AI agents cannot perform to their full potential because current web infrastructure targets humans and websites use different data formats, while information remains unverified. This makes it hard for agents to understand and process data.
-
Intuition evolves the Semantic Web’s vision through Web3 approaches, addressing existing limitations. The system structures knowledge into Atoms, using Token Curated Registries (TCR) to reach consensus on data usage, while Signals determine how much to trust that data.
-
Intuition could transform the web. The current web resembles unpaved roads, while Intuition creates highways where agents can operate safely, potentially becoming the new infrastructure standard and realizing the true capabilities of the agentic AI era.
1. The Agent Era Begins: Is the Web Infra Enough?
The era of agentic AI is gaining momentum. We can imagine a future where personal agents handle everything from travel planning to complex financial management. But in practice, things are not so simple. The issue is not with AI performance itself. The real limitation lies in today’s web infrastructure.
The web was built for humans to read and interpret through browsers. As a result, it is poorly suited for agents that need to parse semantics and connect relationships across data sources. These limitations are obvious in everyday services. An airline website may list a departure time as “14:30,” while a hotel site shows check-in as “2:30 PM.” Humans immediately understand both as the same time, but agents interpret them as entirely different data formats.
 Source: Tiger Research
Source: Tiger ResearchThe issue goes beyond formatting differences. A critical challenge is whether agents can trust the data itself. Humans can work with incomplete information by relying on context and prior experience. Agents, by contrast, lack clear standards for assessing provenance or reliability. This leaves them vulnerable to false inputs, flawed conclusions, and even hallucinations.
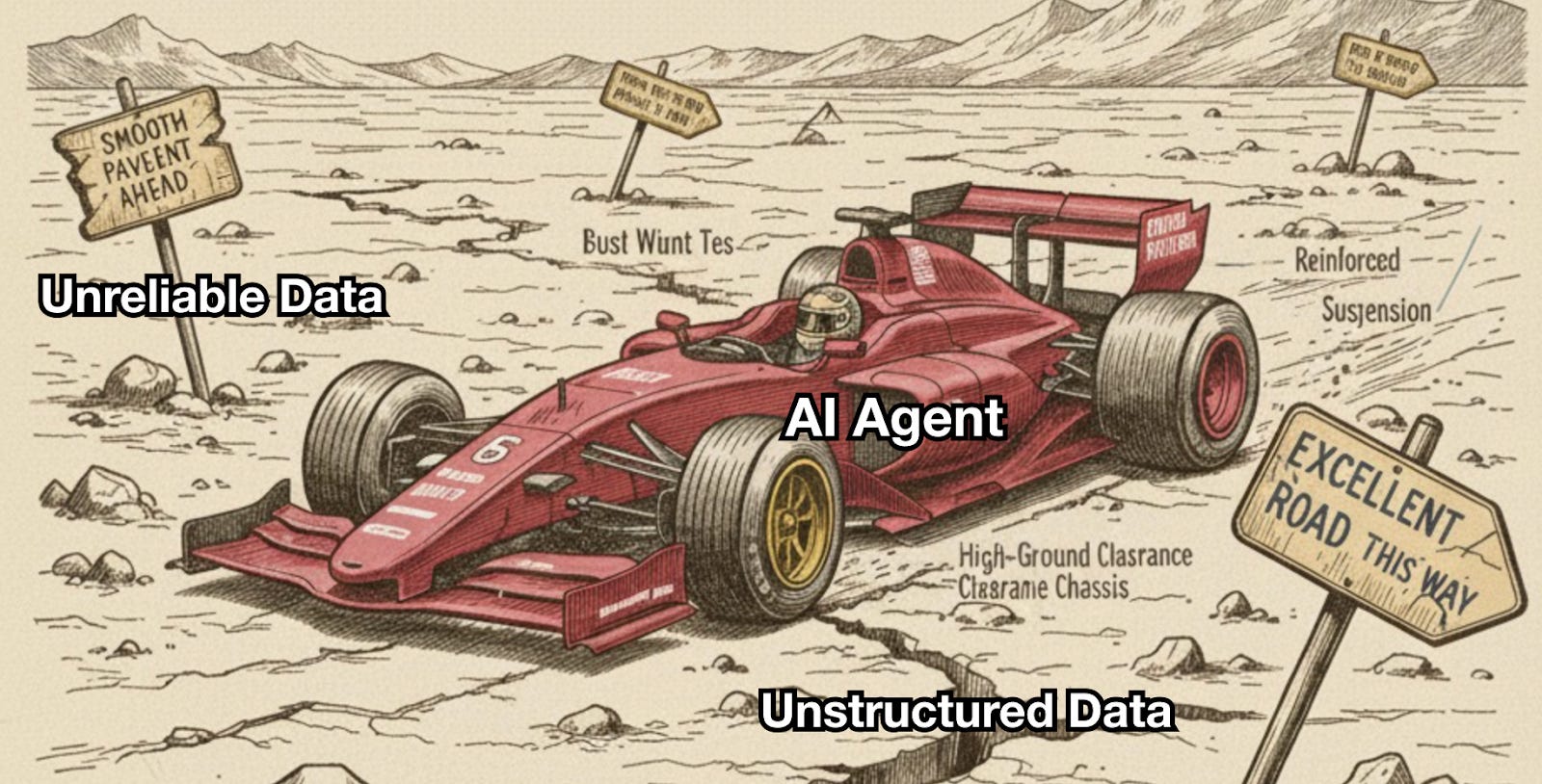
In the end, even the most advanced agents cannot thrive in such conditions. They are like F1 cars: no matter how powerful, they cannot reach full speed on an unpaved road—unstructured data. And if misleading signs—unreliable data—are scattered along the route, they may never reach the finish line.
2. Web’s Technical Debt: Rebuilding the Foundation
This issue was first raised more than 20 years ago by Tim Berners-Lee, the creator of the World Wide Web, through his proposal for the Semantic Web.
The Semantic Web’s core idea is simple: structure web information so machines can understand it, not just as human-readable text. For example, “Tiger Research was founded in 2021” is clear to humans but appears as mere character strings to machines. The Semantic Web structures this as “Tiger Research (subject) – founded (predicate) – 2021 (object)” so machines can interpret the meaning.
This approach was ahead of its time but ultimately never came to be. The biggest reason was implementation challenges. Reaching consensus on data formats and usage standards proved difficult, and more importantly, building and maintaining vast datasets through voluntary user contributions was nearly impossible. Contributors received no direct rewards or benefits. Additionally, the question of whether the created data could be trusted remained an unsolved problem.
Nevertheless, the Semantic Web’s vision remains valid. The principle that machines should understand and utilize data at the semantic level hasn’t changed. In the AI era, this need has become even more critical.
3. Intuition: Reviving the Semantic Web in a Web3 Way

Intuition evolves the Semantic Web’s vision through Web3 approaches to address existing limitations. The core lies in creating a system that incentivizes users to voluntarily participate in accumulating and verifying quality structured data. This systematically builds knowledge graphs that are machine-readable, have clear provenance, and are verifiable. Ultimately, this provides the foundation for intelligent agents to operate reliably and brings us closer to the future we envision.
3.1. Atoms: Building blocks of Knowledge
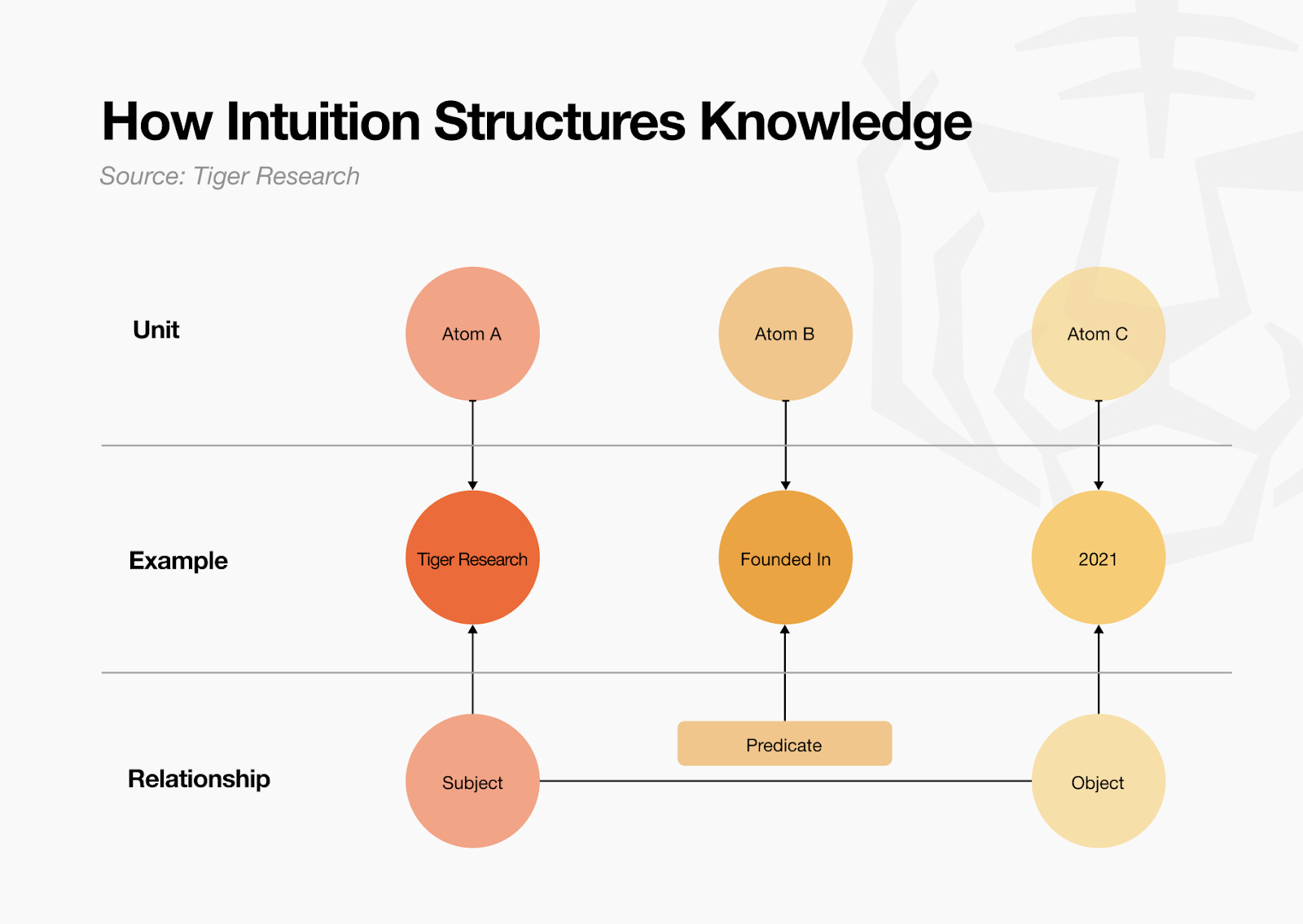
Intuition starts by dividing all knowledge into minimal units called Atoms. Atoms represent concepts like people, dates, organizations, or attributes. Each has a unique identifier (using tech like Decentralized Identifiers, or DIDs) and exists independently. Every Atom records contributor information so you can verify who added what information and when.
The reason for breaking knowledge into Atoms is clear. Information typically comes in complex sentences, and machines like agents have structural limitations in parsing and understanding such composite information on their own. They also struggle to determine which parts are accurate and which are incorrect.
-
Subject: Tiger Research
-
Predicate: founded In
-
Object: 2021
Consider the sentence “Tiger Research was founded in 2021.” This could be true, or only parts might be wrong. Whether this organization actually exists, whether “founding date” is an appropriate attribute, and whether 2021 is correct each require individual verification. But treating the entire sentence as one unit makes it hard to distinguish which elements are accurate and which are false. Tracking the source of each piece of information becomes complex too.
Atoms solve this problem. Define each as independent Atoms like [Tiger Research], [founded In], [2021], and you can record sources and verify each element individually.
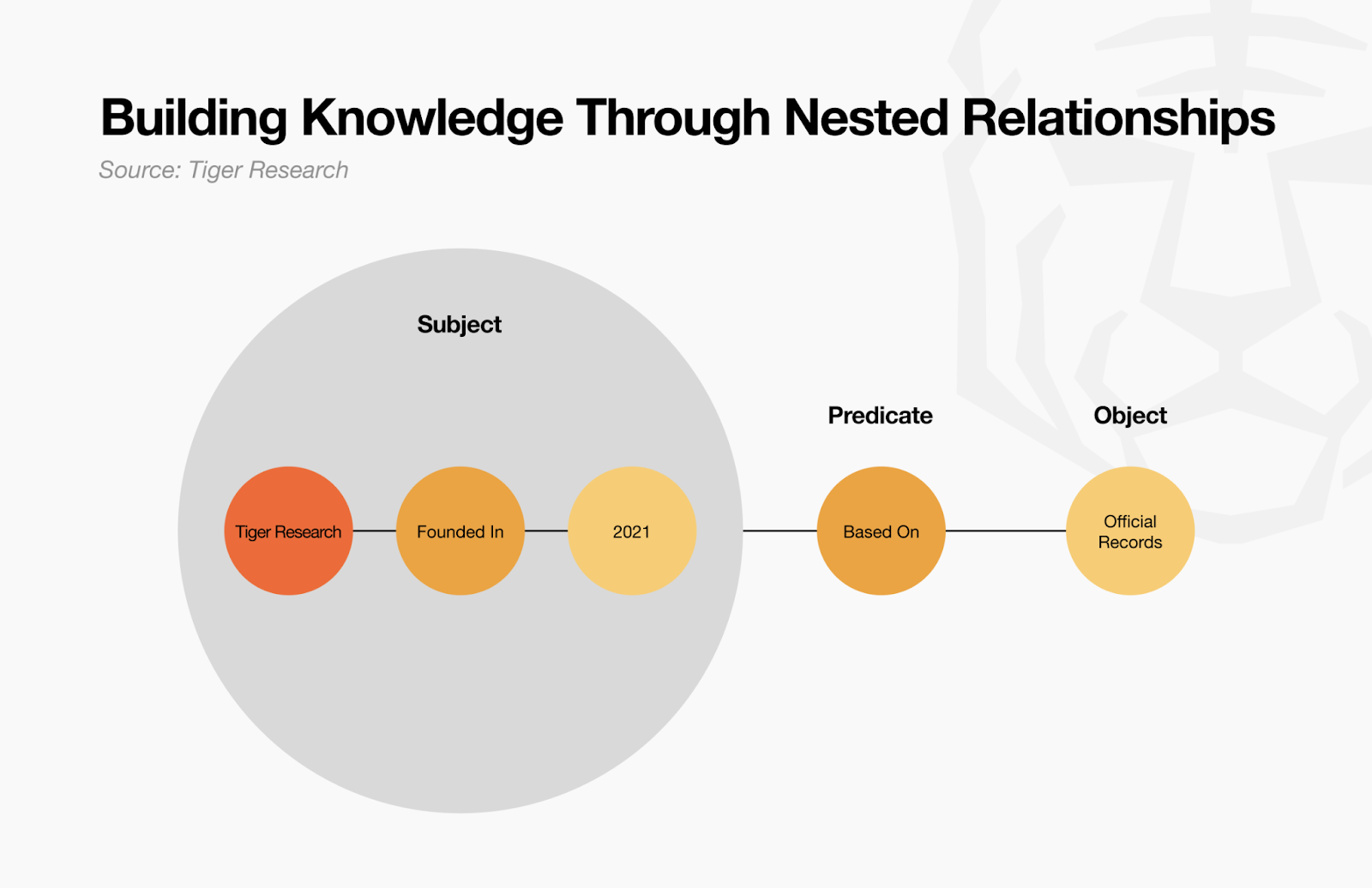
Atoms are not just tools for dividing information – they work like Lego blocks that can be combined. For example, the individual Atoms [Tiger Research], [Founded In], and [2021] connect to form a Triple. This creates meaningful information: “Tiger Research was founded in 2021.” This follows the same structure as Triples in the Semantic Web’s RDF (Resource Description Framework).
These Triples can also become Atoms themselves. The Triple “Tiger Research was founded in 2021” can expand into a new Triple like “Tiger Research’s founding date of 2021 is based on business records.” Through this method, Atoms and Triples combine repeatedly, evolving from small units into larger structures.
The result is that Intuition builds fractal knowledge graphs that can expand infinitely from basic elements. Even complex knowledge can be broken down for verification and then recombined.
3.2. Token Curated Registries: Market-Driven Consensus
If Intuition provides a conceptual framework for structuring knowledge through Atoms, three key questions now remain: Who will contribute to creating these Atoms? Which Atoms can be trusted? And when different Atoms compete to represent the same concept, which one becomes the standard?
 Source: Intuition Lightpaper
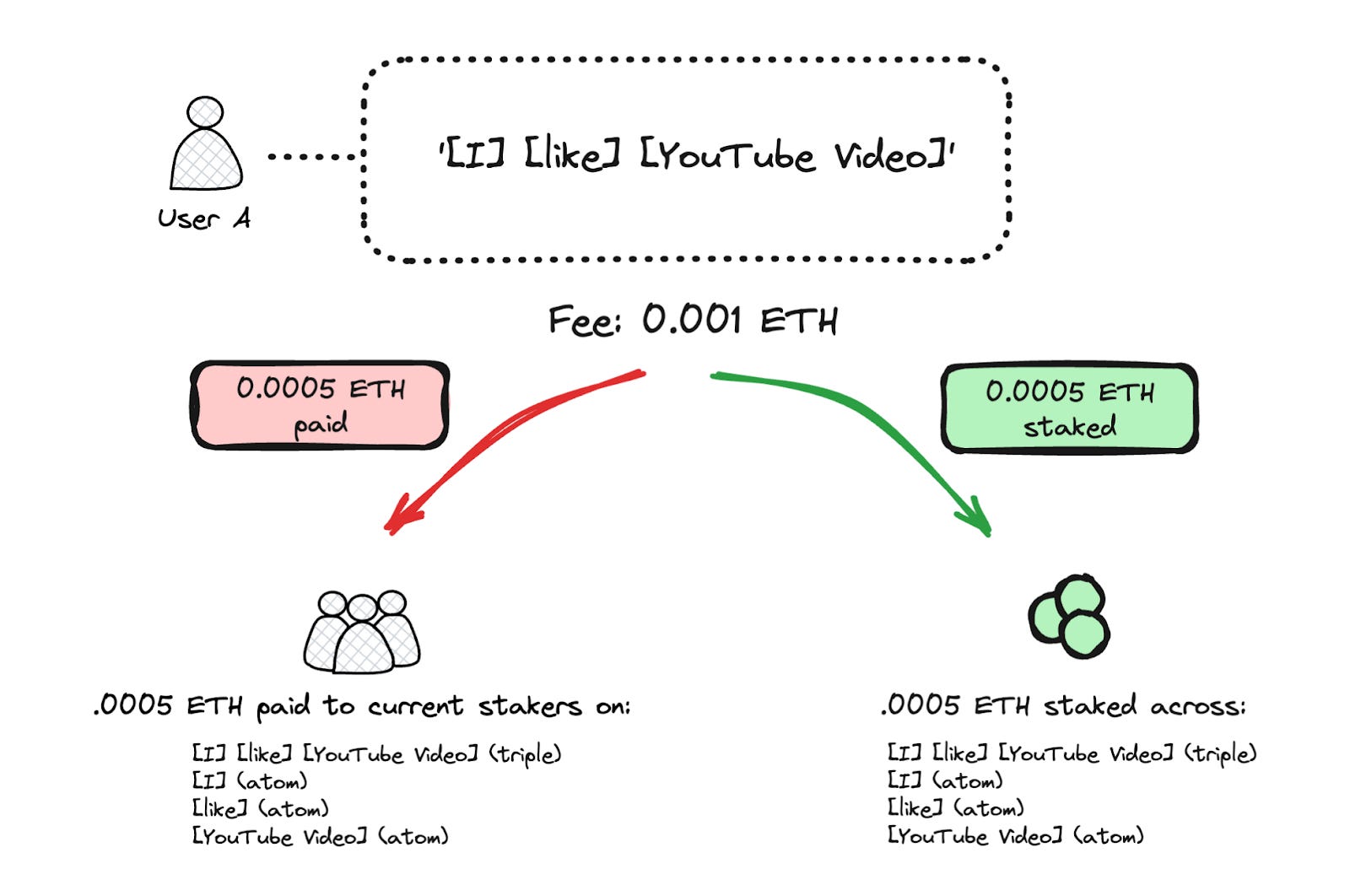
Source: Intuition LightpaperIntuition solves this problem through Token Curated Registries (TCRs). TCRs filter entries based on what the community values. Token staking reflects these judgments. Users stake TRUST, Intuition’s native token, when they propose new Atoms, Triples, or data structures. Other participants stake tokens on the supporting side if they find the proposal useful, or on the opposing side if they don’t. They can also stake on competing alternatives. Users earn rewards if their chosen data gets used frequently or receives high ratings. They lose part of their stake if not.
TCRs verify individual attestations, but they also solve the ontology standardization problem effectively. Ontology standardization means deciding which approach becomes the common standard when multiple ways exist to express the same concept. Distributed systems face the challenge of reaching this consensus without centralized coordination.
Consider two competing predicates for product reviews: [hasReview] and [customerFeedback]. If [hasReview] gets introduced first and many users build on it, early contributors own token stakes in that success. Meanwhile, [customerFeedback] supporters gain economic incentives to gradually switch to the more widely adopted standard.
This mechanism mirrors how the ERC-20 token standard gained natural adoption. Developers who adopted ERC-20 got clear compatibility benefits—direct integration with existing wallets, exchanges, and dApps. These advantages naturally drew developers to ERC-20. This showed that market-driven choices alone can solve standardization problems in distributed environments. TCRs work on similar principles. They reduce agents’ struggles with fragmented data formats and provide an environment where information can be understood and processed more consistently.
3.3. Signal: Building Trust-Based Knowledge Networks
Intuition structures knowledge through Atoms and Triples and uses incentives to reach consensus on “what actually gets used.”
One last challenge remains: How much can we trust that information? Intuition introduces Signal to fill this gap. Signal expresses user trust or distrust toward specific Atoms or Triples. It goes beyond simply recording that data exists – it captures how much support the data receives in different contexts. Signal systematizes the social verification process we use in real life, like when we judge information based on “a reliable person recommended this” or “experts verified it.“
Signal accumulates in three ways. First, explicit signal involves intentional evaluations users make, like token staking. Second, implicit signal emerges naturally from usage patterns like repeated queries or applications. Finally, transitive signal creates relational effects—when someone I trust supports information, I tend to trust it more too. These three combine to create a knowledge network showing who trusts what, how much, and in what way.
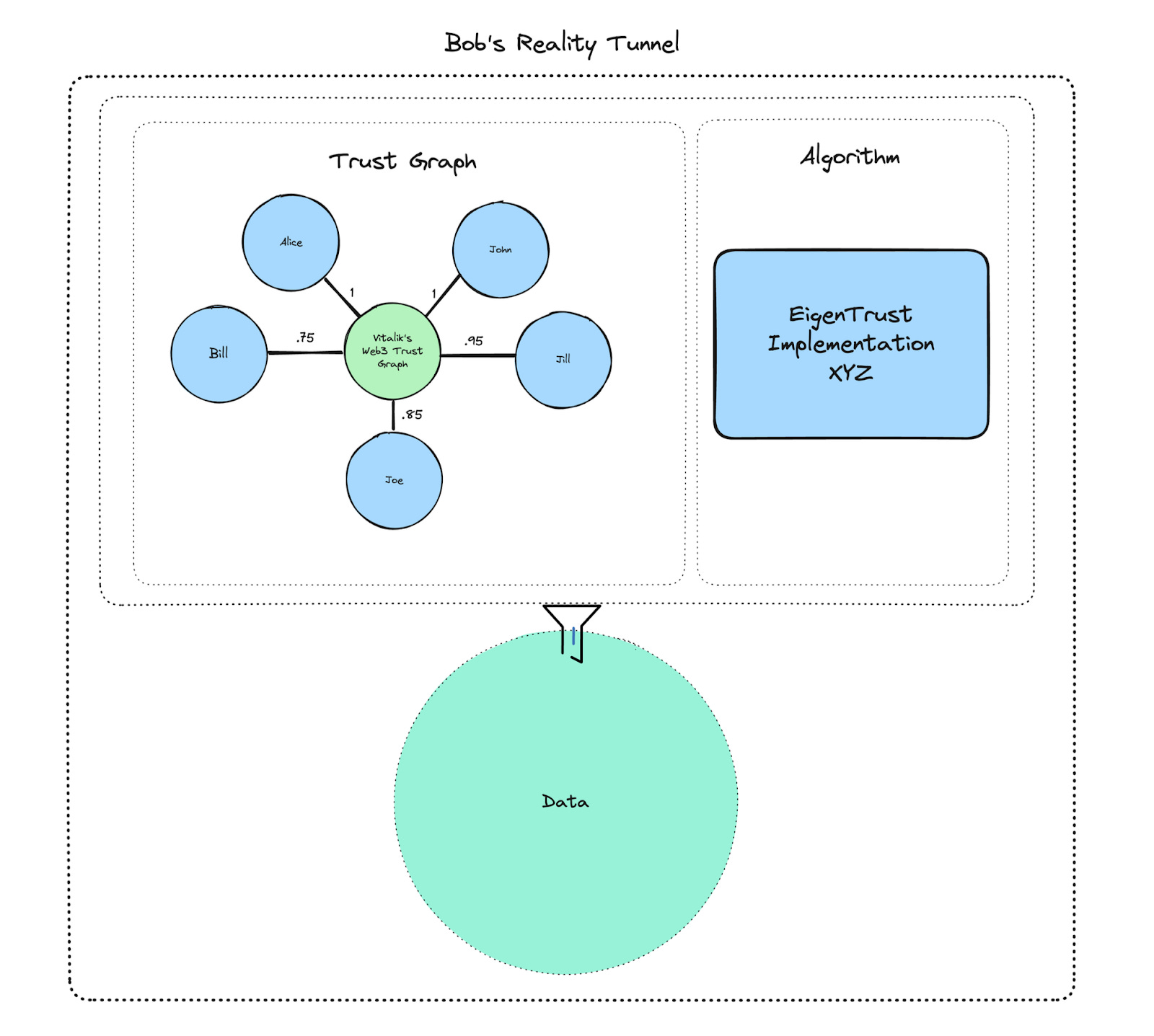 Source: Intuition Lightpaper
Source: Intuition LightpaperIntuition provides this through Reality Tunnels. Reality Tunnels offer personalized perspectives for viewing data. Users can configure tunnels that prioritize expert group evaluations, value close friends’ opinions, or reflect specific community wisdom. Users can choose trusted tunnels or switch between multiple tunnels for comparison. Agents can also use specific interpretive approaches for particular purposes. For example, selecting a tunnel that reflects Vitalik Buterin’s trusted network would set an agent to interpret information and make decisions from “Vitalik’s perspective.”
All signals get recorded on-chain. Users can transparently verify why specific information seems trustworthy, which addresses serve as sources, who vouches for it, and how many tokens are staked. This transparent trust formation process lets users verify evidence directly rather than blindly accepting information. Agents can also use this foundation to make judgments that fit individual contexts and perspectives.
4. What If Intuition Becomes Next Web Infra?
Intuition’s infrastructure is not just a conceptual idea but a practical solution that addresses problems agents face in today’s web environment.
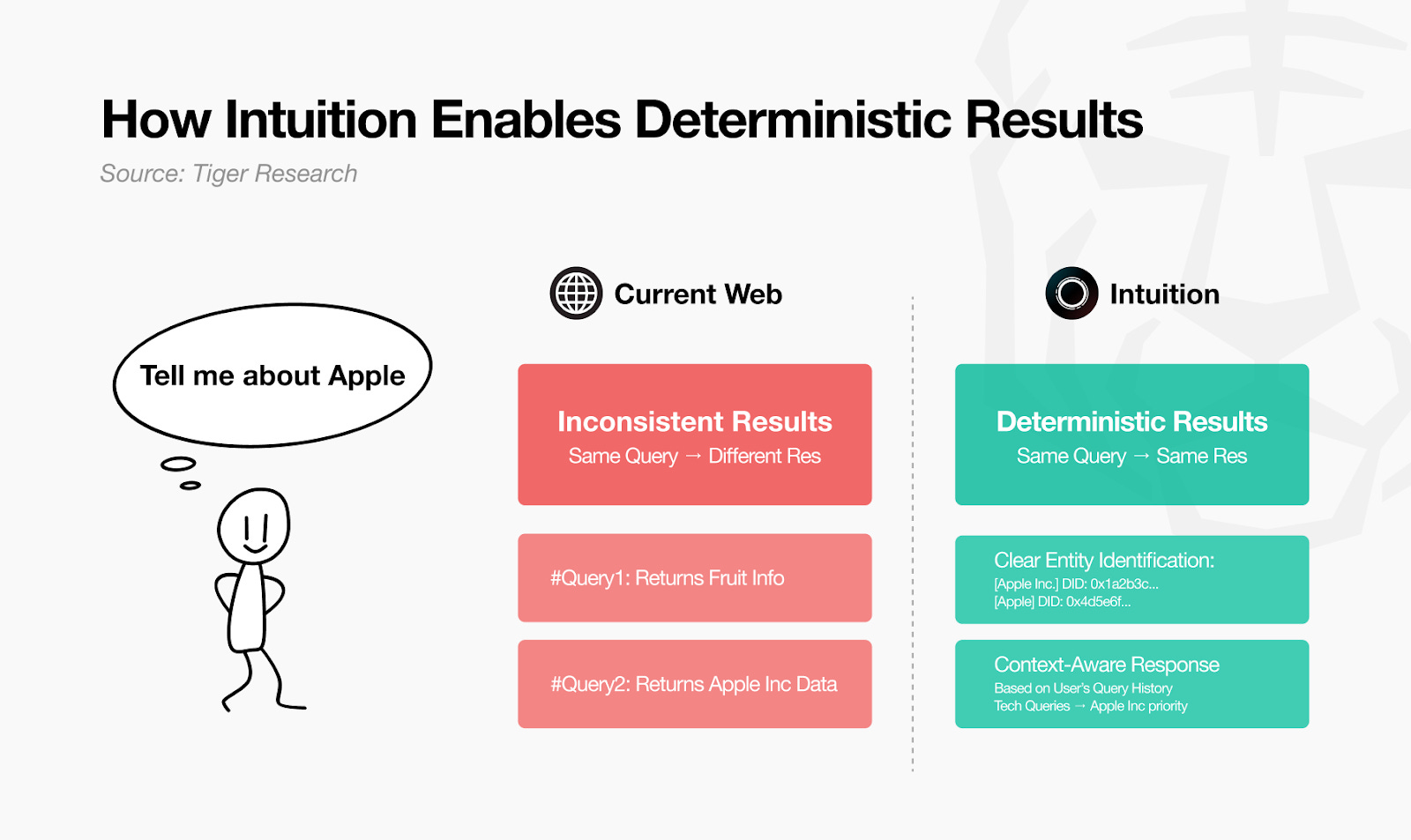
The current web is filled with fragmented data and unverified information. Intuition transforms data into deterministic knowledge graphs that give clear, consistent results to any query. Token-based signals and curation processes verify this data. Agents can make clear decisions without relying on guesswork. This simultaneously improves accuracy, speed, and efficiency.
Intuition also provides the foundation for agent collaboration. Standardized data structures let different agents understand and communicate information the same way. Just as ERC-20 created token compatibility, Intuition’s knowledge graphs create an environment where agents can cooperate based on consistent data.
Intuition goes beyond agent-only infrastructure to function as a foundational layer all digital services can share. It can replace trust systems that each platform currently builds individually—Amazon’s reviews, Uber’s ratings, LinkedIn’s recommendations—with one unified foundation. Just as HTTP provides common communication standards for the web, Intuition provides standard protocols for data structure and trust verification.
The most important change is data portability. Users directly own the data they create and can use it anywhere. Data isolated in individual platforms will connect and reshape the entire digital ecosystem.
5. Rebuilding the Foundation for the Coming Agentic Era
Intuition’s goal is not simple technical improvement. It aims to overcome the technical debt accumulated over the past 20 years and fundamentally redesign web infrastructure. When the Semantic Web was first proposed, the vision was clear. But it lacked incentives to drive participation. Even if their vision had been realized, the benefits remained unclear.
The situation has changed. AI advances are making the agentic era a reality. AI agents now go beyond simple tools. They perform complex tasks on our behalf. They make autonomous decisions. They collaborate with other agents. These agents need fundamental innovation in existing web infrastructure to operate effectively.
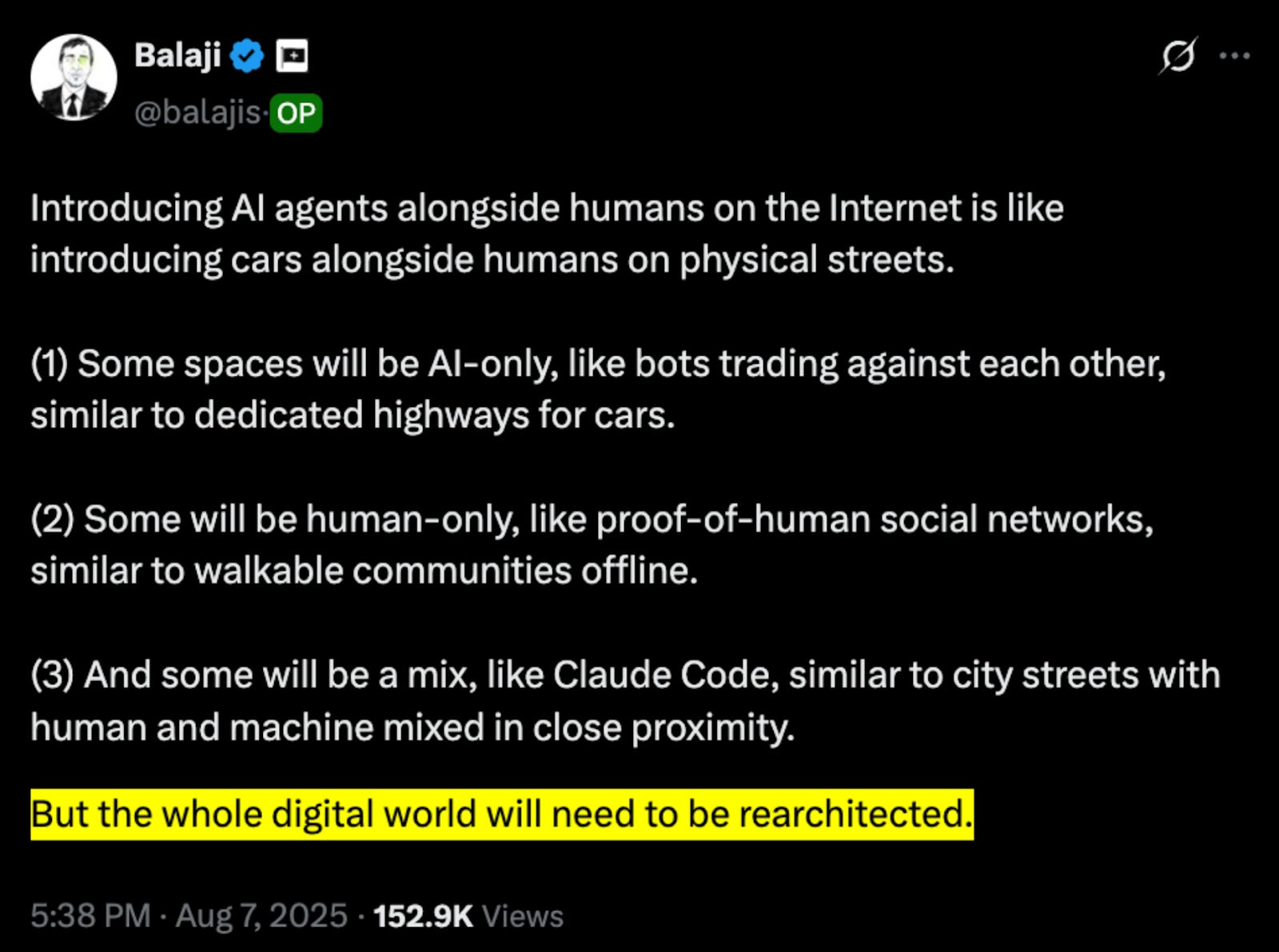 Source: Balaji
Source: BalajiAs Balaji, former CTO of Coinbase, points out, we need to build proper infrastructure for these agents to operate. The current web resembles unpaved roads rather than highways where agents can move safely on trustworthy data. Each website has different structures and formats. Information is unreliable. Data remains unstructured and agents struggle to understand it. This creates major barriers for agents to perform accurate and efficient work.
Intuition seeks to rebuild the web to meet these demands. It aims to build standardized data structures that agents can easily understand and use. It wants reliable information verification systems. It needs protocols that enable smooth interaction between agents. This resembles how HTTP and HTML created web standards in the early internet days. It represents an attempt to establish new standards for the agentic era.
Challenges remain, of course. The system cannot function properly without sufficient participation and network effects. Critical mass requires considerable time and effort. Overcoming the inertia of existing web ecosystems is never easy. Establishing new standards presents difficulties. But this is a challenge that must be solved. Intuition’s proposed rebase will overcome these challenges. It will open new possibilities for the agentic era that is just beginning to be imagined.
Dive deep into Asia’s Web3 market with Tiger Research.
Be among the 16,000+ pioneers who receive exclusive market insights.
>> Subscribe <<
Disclaimer
This report was partially funded by Intuition. It was independently produced by our researchers using credible sources. The findings, recommendations, and opinions are based on information available at publication time and may change without notice. We disclaim liability for any losses from using this report or its contents and do not warrant its accuracy or completeness. The information may differ from others’ views. This report is for informational purposes only and is not legal, business, investment, or tax advice. References to securities or digital assets are for illustration only, not investment advice or offers. This material is not intended for investors.
Terms of Usage
Tiger Research allows the fair use of its reports. ‘Fair use’ is a principle that broadly permits the use of specific content for public interest purposes, as long as it doesn’t harm the commercial value of the material. If the use aligns with the purpose of fair use, the reports can be utilized without prior permission. However, when citing Tiger Research’s reports, it is mandatory to 1) clearly state ‘Tiger Research’ as the source, 2) include the Tiger Research logo following brand guideline. If the material is to be restructured and published, separate negotiations are required. Unauthorized use of the reports may result in legal action.

The Pentagon is angling to introduce artificial intelligence across its workforce within nine months following the reorganization of its key AI office.
Emil Michael, under secretary of defense for research and engineering at the Department of Defense, talked about the agency’s plans for introducing AI to its operations as it continues its modernization journey.
“We want to have an AI capability on every desktop — 3 million desktops — in six or nine months,” Michael said during a Politico event on Tuesday. “We want to have it focus on applications for corporate use cases like efficiency, like you would use in your own company … for intelligence and for warfighting.”
This announcement follows the recent shakeups and restructuring of the Pentagon’s main artificial intelligence office. A senior defense official said the Chief Digital and Artificial Intelligence Office will serve as a new addition to the department’s research portfolio.
Michael also said he is “excited” about the restructured CDAO, adding that its new role will pivot to a focus on research that is similar to the Defense Advanced Research Projects Agency and Missile Defense Agency. This change is intended to enhance research and engineering priorities that will help advance AI for use by the armed forces and not take agency focus away from AI deployment and innovation.
“To add AI to that portfolio means it gets a lot of muscle to it,” he said. “So I’m spending at least a third of my time –– maybe half –– rethinking how the AI deployment strategy is going to be at DOD.”
Applications coming out of the CDAO and related agencies will then be tailored to corporate workloads, such as efficiency-related work, according to Michael, along with intelligence and warfighting needs.
The Pentagon first stood up the CDAO and brought on its first chief digital and artificial intelligence officer in 2022 to advance the agency’s AI efforts.
The restructuring of the CDAO this year garnered attention due to its pivotal role in investigating the defense applications of emerging technologies and defense acquisition activities. Job cuts within the office added another layer of concern, with reports estimating a 60% reduction in the CDAO workforce.

The Pentagon aims to get AI tools to its entire workforce next year, the department’s chief technical officer said one month after being given control of its main AI office.
“We want to have an AI capability on every desktop — 3 million desktops — in six or nine months,” Emil Michael, defense undersecretary for research and engineering, said at a Politico event on Tuesday. “We want to have it focus on applications for corporate use cases like efficiency, like you would use in your own company…for intelligence and for warfighting.”
Four weeks ago, the Chief Digital and Artificial Intelligence Office was demoted from reporting to Deputy Defense Secretary Stephen Feinberg to Michael, a subordinate.
Michael said CDAO will become a research body like the Defense Advanced Research Projects Agency and Missile Defense Agency. He said the change is meant to boost research and engineering into AI for the military, but not reduce its efforts to deploy AI and make innovations.
“To add AI to that portfolio means it gets a lot of muscle to it,” he said. “So I’m spending at least a third of my time—maybe half—rethinking how the AI-deployment strategy is going to be at DOD.”
He said applications would emerge from the CDAO and related agencies that will be tailored to corporate workloads.
The Pentagon created the CDAO in 2022 to advance the agency’s AI efforts and look into defense applications for emerging technologies. The office’s restructuring earlier this year garnered attention. Job cuts within the office added another layer of concern, with reports estimating a 60% reduction in the CDAO workforce.
Artificial intelligence (AI) has become one of the fastest-growing technologies in the world today. In many industries, individuals and organizations are racing to better understand AI and incorporate it into their work. Surgery is no exception, and that is why Clinical Congress 2025 has made AI one of the six themes of its Opening Day Thematic Sessions.
The first full day of the conference, Sunday, October 5, will include two back-to-back Panel Sessions on AI. The first session, “Using ChatGPT and AI for Beginners” (PS104), offers a foundation for surgeons not yet well versed in AI. The second, “AI: Who Is In Control?” (PS 110), will offer insights into the potential upsides and drawbacks of AI use, as well as its limitations and possible future applications, so that surgeons can involve this technology in their clinical care safely and effectively.
“AI: Who Is In Control?” will be moderated by Anna N. Miller, MD, FACS, an orthopaedic surgeon at Dartmouth Hitchcock Medical Center in Lebanon, New Hampshire, and Gabriel Brat, MD, MPH, MSc, FACS, a trauma and acute care surgeon at Beth Israel Deaconess Medical Center and an assistant professor at Harvard Medical School, both in Boston, Massachusetts.
In an interview, Dr. Brat shared his view that the use of AI is not likely to replace surgeons or decrease the need for surgical skills or decision-making. “It’s not an algorithm that’s going to be throwing the stitch. It’s still the surgeon.”
Nonetheless, he said that the starting presumption of the session is that AI is likely to be highly transformative to the profession over time.
“Once it has significant uptake, it’ll really change elements of how we think about surgery,” he said, including creating meaningful opportunities for improvements.
The key question of the session, therefore, is not whether to engage with AI, but to do so in ways that ensure the best outcomes: “We as surgeons need to have a role in defining how to do so safely and effectively. Otherwise, people will start to use these tools, and we will be swept along with a movement as opposed to controlling it.”
To that end, Dr. Brat explained that the session will offer “a really strong translational focus by people who have been in the trenches working with these technologies.” He and Dr. Miller have specifically chosen an “all-star panel” designed to represent academia, healthcare associations, and industry.
The panelists include Rachael A. Callcut, MD, MSPH, FACS, who is the division chief of trauma, acute care surgery and surgical critical care as well as associate dean of data science and innovation at the University of California-Davis Health in Sacramento, California. She will share the perspective on AI from academic surgery.
Genevieve Melton-Meaux, MD, PhD, FACS, FACMI, the inaugural ACS Chief Health Informatics Officer, will present on AI usage in healthcare associations. She also is a colorectal surgeon and the senior associate dean for health informatics and data science at the University of Minnesota and chief health informatics and AI officer for Fairview Health Services, both in Minneapolis.
Finally, Khan Siddiqui, MD, a radiologist and serial entrepreneur who is the cofounder, chairman, and CEO of a company called HOPPR AI, will present the view from industry. HOPPR AI is a for-profit company focused on building AI apps for medical imaging. As a radiologist, Dr. Siddiqui represents a medical specialty that is thought to likely undergo sweeping change as AI is incorporated into image-reading and diagnosis. His comments will focus on professional insights relevant to surgeons.
Their presentations will provide insights on general usage of AI at present, as well as predictions on what the landscape for AI in healthcare will look like in approximately 5 years. The session will include advice on what approaches to AI may be most effective for surgeons interested in ensuring positive outcomes and avoiding negative ones.
Additional information on AI usage pervades Clinical Congress 2025. In addition to various sessions that will comment on AI throughout the 4 days of the conference, various researchers will present studies that involve AI in their methods, starting presumptions, and/or potential applications to practice.
Access the Interactive Program Planner for more details about Clinical Congress 2025 sessions.
-

 Business3 weeks ago
Business3 weeks agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-
Tools & Platforms1 month ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy2 months ago
Ethics & Policy2 months agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences4 months ago
Events & Conferences4 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers3 months ago
Jobs & Careers3 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Education3 months ago
Education3 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Education2 months ago
Education2 months agoMacron says UK and France have duty to tackle illegal migration ‘with humanity, solidarity and firmness’ – UK politics live | Politics
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi
-

 Funding & Business3 months ago
Funding & Business3 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries