AI Insights
Roundtable Discussion: Software vs. Hardware

From technological breakthroughs to industrial implementation, from policy support to global cooperation, the “Chinese solution” is reshaping the global technology industry landscape with its unique “technology + scenario + ecosystem” model. At this critical juncture, the industry faces core questions: How can the “Chinese solution” continue to empower various industries in a more in – depth manner? And how will Chinese AI companies redefine the boundaries of “scenario – based intelligence”?
On August 27th, the 2025 AI Partner Conference for All Industries, jointly hosted by 36Kr and the China Europe International Business School, grandly opened at the Zhongguancun Software Park in Beijing. The conference, themed “The Chinese Solution”, consists of two major chapters: “The Chinese Solution” and “Who Will Define the Next AI Era”. Centering around four major topics – “The Golden Age of Chinese Innovation”, “Can Super – intelligent Agents Become the Core Form of the Next – Generation AI?”, “The Chinese Solution Reconstructing the Global Tech Competition Landscape”, and “The Prosperous Integration and Innovation of AI and All Industries”, it comprehensively showcases the latest breakthroughs and the ecosystem of Chinese AI, shares the growth path and future prospects of Chinese – style AI, and explores the innovative models of the Chinese solution.
36Kr specially organized a round – table discussion titled “Software or Hardware – The Next Hotspot in AI” at the AI Partner Conference for All Industries. Zhou Xinyu, a senior writer at 36Kr [the host], Sun Xuefeng, CEO of Xiaoshui Intelligence, Xiao Mafeng, founder of the AI recruitment platform TTC, and Yu Ren, founder of Fangyun Intelligence, an enterprise – level intelligent agent company, these industry experts will discuss the next hotspot in AI under the “Chinese solution”.
Round – table discussion on “Software or Hardware – The Next Hotspot in AI”
The following is the content of the speeches, edited by 36Kr:
Zhou Xinyu: Today, we have invited three senior practitioners from different fields, Sun Xuefeng, CEO of Xiaoshui Intelligence, Xiao Mafeng, founder of the AI recruitment platform TTC, and Yu Ren, founder and CEO of Imagine Digital Technology / Imagine AI Research Institute. All of them have found unique opportunities in the AI wave. First, please introduce your company’s business and how you seized the AI opportunities.
Yu Ren: Hello everyone, I’m Yu Ren. With a technical background, I’ve been engaged in software R & D for 20 years. In 2019, I started my business focusing on enterprise digital transformation, serving enterprises such as China Mobile, China Unicom, Ping An, and Sephora. After the arrival of the AI wave, our business shifted to “custom – made AI intelligent agents for business departments”, which is essentially enterprise AI transformation consulting – helping customers sort out scenarios and implement intelligent agents. During the “blind period” of AI application, we dig out real needs through co – creation services.
Xiao Mafeng: Hello everyone, I’m the founder of TTC. We are an “AI + recruitment” company and have seized the beta opportunities in the AI field. On the one hand, we serve 1000 leading AI enterprises in China (covering chips, computing power, large models, AI applications, embodied intelligence, robots, etc.), so we understand the talent needs of AI companies. On the other hand, we are about to launch an “AI Agent product” – enabling every professional to have a dedicated AI headhunter consultant. Users can input information, and the AI will match suitable jobs. For example, alumni of CEIBS often come to me for career counseling. I hope to replicate my professional ability through an AI avatar to reduce the difficulty of job – hunting for everyone.
Sun Xuefeng: Hello everyone, I’m the CEO of Xiaoshui Intelligence. The company was founded in 2017. In the early days, we developed an AI middleware platform to empower communication enterprises and industry customers. After the explosion of AIGC, we quickly upgraded the middleware platform to a “consumer – end product driven by AI agents”. The core opportunity lies in “AI + hardware” – we chose the existing market of children’s smartwatches (with an annual sales volume of 15 million units in China). Now we clearly feel that traditional smart hardware (wearables, mobile phones, home appliances) are all looking for AI upgrade solutions, which forces us to quickly iterate our service capabilities and develop AI hardware that is “easy to understand, easy to use, and affordable”.
Zhou Xinyu: Entrepreneurship at the application layer cannot do without the support of model capabilities. What are the differences in model iteration this year compared to 2023? How should application – layer enterprises adapt?
Sun Xuefeng: We are at the Agent application layer. The core is to “stand on the shoulders of giants” – we don’t engage in model R & D but build our own MaaS layer to connect with the APIs of the world’s top models. In 2023, we mainly cooperated with Baidu. In 2024, we added ByteDance. Before DeepSeek became popular this Spring Festival, we had already made early deployments and launched the world’s first DeepSeek children’s smartwatch. The biggest change this year is the “implementation of multi – modal capabilities”: as soon as the leading APIs for text – to – image and image – to – video generation came out, we integrated them into our architecture. We found that as long as we quickly embrace good models, enterprises like ours can also develop “world – first” products. The underlying logic is to “use the one that is good and cheap”. We focus on business implementation and don’t need to worry about model R & D.
Xiao Mafeng: In the AI field, it’s very important to grasp the technological trends. In 2023, it was the “battle of a hundred models”. Many companies invested heavily in developing general models. However, when Deepseek emerged, most of the investments went down the drain. In 2024, people became more rational – general models are a game for big companies, and it’s difficult for startups. They are all focusing on specific areas. For example, Baichuan focuses on healthcare, and Baidu focuses on autonomous driving. As an AI application company, we also find that different models have their own advantages when selecting models. We can “select models according to needs”: use DeepSeek for inference, KIMI for long – text processing, and Volcengine Doubao for voice. We don’t bind to a single model. Additionally, the capital market is more rational this year. Investors are more willing to invest in projects with “strong industry background + strong engineering capabilities”. For example, projects founded by former senior executives from ByteDance are more popular than those founded by pure scientists.
Yu Ren: There are three obvious changes in model iteration this year. First, it has shifted from general to vertical. For example, both DeepSeek and GPT – 5 are emphasizing “code – writing ability”. Second, domestic open – source models are leading. The top 15 open – source models are all from China (such as those from Alibaba, DeepSeek, Zhipu, and KIMI), putting great pressure on foreign models. Third, there are fewer companies developing models, and many are turning to intelligent agents (for example, Li Kaifu, Huawei, and Zhipu have all launched intelligent agent products). For the application layer, “even if you have resources, don’t develop large models”. It is recommended to do model fine – tuning and secondary development. Moreover, the code – writing ability of large models has reduced the cost of customization by 10 times. What used to take two months of work can now be completed by experts in one or two hours with the help of AI, turning B – end customization from a “difficult task” into a “feasible option”.
Zhou Xinyu: Many AI applications have quickly achieved revenues of over ten million US dollars this year. Which fields do you think have the opportunity to make money on a large scale? Has the B – end’s willingness to pay changed?
Sun Xuefeng: The biggest opportunity lies in “AI + hardware”, especially in the incremental market promoted by national policies. The State Council’s “Artificial Intelligence +” plan clearly states that by 2027, 70% of smart hardware will be AI – enabled, and by 2030, over 90%. This is a market worth trillions of dollars. For example, we are deploying AI glasses, not ordinary ones but those combined with educational scenarios, such as “glasses for junior high school students to explain knowledge points”. Using visual multi – modal capabilities, they can accompany students in solving problems and explaining knowledge like a tutor. This kind of “vertical hardware” is a promising direction for hit products. In addition, ordinary people can also seize opportunities. They don’t need to start from scratch in hardware development. They can find mature supply chains (such as children’s smartwatch factories and massage chair factories in Shenzhen) and add AI interaction to existing products (such as building English training functions using open – source Agent platforms). First, verify in small scenarios, and then expand after having paying users.
Xiao Mafeng: There are two types of money – making opportunities. For the C – end, it depends on “human weaknesses”. There are opportunities in hardware, but it’s difficult to charge for C – end tools in China. It is recommended to go global. Overseas users are willing to pay for “cheating tools” and “AI – generated beautiful pictures”. A friend of mine made 100 million US dollars a year by developing a hardware device for voice – to – text transcription of meeting minutes overseas. For the B – end, the opportunity lies in “transforming traditional industries”. For example, in industries like doctors, lawyers, and headhunters, AI can replace some manual work. For example, using AI for initial talent screening can reduce costs while maintaining the same fees, resulting in a large profit margin. In addition, Chinese SaaS and tool – based enterprises have advantages when going global. They have strong engineering capabilities, and the labor cost is one – third of that in the United States, allowing them to outcompete overseas peers. However, it’s important to avoid “tasks that large models can directly handle”, such as AI customer service and AI programming, where the opportunities are already limited.
Yu Ren: The B – end’s willingness to pay is increasing. The core is to “pay for pain points”. First, the original informatization budget is being redirected to AI. For example, state – owned enterprises are using AI to review contract payments (15 million sets per year, a task that used to require a team of hundreds of people can now be completed by AI, and they are willing to pay millions). Second, new needs are being discovered. For example, using AI for live – stream chat interaction and private – domain conversion. The best model for the B – end this year is “customization first, then standardization”. Since AI applications are still in the early stage, customers don’t know what they need. First, co – create with customers through customization (the cost is only one – tenth of last year). After verifying the scenarios, polish the products into standard ones and then replicate them across the industry. There are 1382 small industry categories in China, and each industry has opportunities. The key is to “make the first profit and then standardize”.
Zhou Xinyu: Finally, please predict where the next hotspot in AI will be after this year. Is it software or hardware? How long will the dividend period last?
Yu Ren: The hotspots in the next five years will be “AI intelligent agents + AI – native applications”, and there are more opportunities in software. From the perspective of the technology life cycle, large models and computing power have reached the commercial standard, and the next stage will be an explosion of applications. This AI cycle will last for 40 – 60 years, and application giants will emerge around 2035. “AI – native” will be popular. It’s not about adding AI modules to existing information systems but directly using AI to serve the real world. For example, using AI in cameras to analyze risks and using AI in live – streaming for private – domain conversion. It’s not too late to enter the market now. There are more than 10 entrepreneurial directions in each industry. The key is to “start from the field you are familiar with”.
Xiao Mafeng: The dividend period will last at least 10 years, which is a greater opportunity than the mobile Internet 10 years ago. The next hotspot will be “transforming traditional industries with AI”. There are opportunities in both software and hardware, but we need to “avoid tasks that large models can directly handle”. It is recommended that everyone “quickly enter the AI field”. For example, a friend who was engaged in traditional public relations got an offer from an AI company after organizing 100 AI – related events. Entering the AI industry now is like buying Bitcoin and Tesla in 2015. Looking back from 2035, 2025 will be seen as a golden opportunity. Don’t think you are an “outsider”. The commercialization ability of CEIBS alumni is exactly what pure AI companies lack.
Sun Xuefeng: In the next 1 – 2 years, hardware will be a “high – frequency hotspot”. Once the first AI – enabled mobile phones from Xiaomi, Huawei, and Apple are launched, it will trigger a wave of enthusiasm. The AI – enabled toys from PopMart and the AI – enabled air conditioners from Gree will also stimulate the market. However, the core opportunity is “technological equalization”. Open – source hardware and open – source software (such as Coze) have significantly lowered the threshold for entrepreneurship. Ordinary people can also develop AI products (such as building an English training agent for children). The dividend period will be long. As long as you seize the opportunity of “AI + the field you are familiar with”, whether it’s acting as an agent for AI products or collaborating with the supply chain to develop hardware, there are opportunities.
Zhou Xinyu: The sharing from the three guests today is very practical. Large models are not the arena for ordinary players. The application layer should seize the opportunity of “AI + vertical scenarios”. For hardware, focus on the incremental market driven by policies, and for software, look at native applications. Ordinary people can also enter the market through the open – source ecosystem and supply – chain advantages. Thank you, three guests, and thank you, the audience!

















AI Insights
Deep computer vision with artificial intelligence based sign language recognition to assist hearing and speech-impaired individuals

This study proposes a novel HHODLM-SLR technique. The presented HHODLM-SLR technique mainly concentrates on the advanced automatic detection and classification of SL for disabled people. This technique comprises BF-based image pre-processing, ResNet-152-based feature extraction, BiLSTM-based SLR, and HHO-based hyperparameter tuning. Figure 1 represents the workflow of the HHODLM-SLR model.
Image Pre-preprocessing
Initially, the HHODLM-SLR approach utilized BF to eliminate noise in an input image dataset38. This model is chosen due to its dual capability to mitigate noise while preserving critical edge details, which is crucial for precisely interpreting complex hand gestures. Unlike conventional filters, such as Gaussian or median filtering, that may blur crucial features, BF maintains spatial and intensity-based edge sharpness. This confirms that key contours of hand shapes are retained, assisting improved feature extraction downstream. Its nonlinear, content-aware nature makes it specifically efficient for complex visual patterns in sign language datasets. Furthermore, BF operates efficiently and is adaptable to varying lighting or background conditions. These merits make it an ideal choice over conventional pre-processing techniques in this application. Figure 2 represents the working flow of the BF model.

BF is a nonlinear image processing method employed for preserving edges, whereas decreasing noise in images makes it effective for pre-processing in SLR methods. It smoothens the image by averaging pixel strengths according to either spatial proximity or intensity similarities, guaranteeing that edge particulars are essential for recognizing hand movements and shapes remain unchanged. This is mainly valued in SLR, whereas refined edge features and hand gestures are necessary for precise interpretation. By utilizing BF, noise from environmental conditions, namely background clutter or lighting variations, is reduced, improving the clearness of the input image. This pre-processing stage helps increase the feature extraction performance and succeeding detection phases in DL methods.
Feature extraction using ResNet-152 model
The HHODLM-SLR technique implements the ResNet152 model for feature extraction39. This model is selected due to its deep architecture and capability to handle vanishing gradient issues through residual connections. This technique captures more complex and abstract features that are significant for distinguishing subtle discrepancies in hand gestures compared to standard deep networks or CNNs. Its 152-layer depth allows it to learn rich hierarchical representations, enhancing recognition accuracy. The skip connections in ResNet improve gradient flow and enable enhanced training stability. Furthermore, it has proven effectualness across diverse vision tasks, making it a reliable backbone for SL recognition. This depth, performance, and robustness integration sets it apart from other feature extractors. Figure 3 illustrates the flow of the ResNet152 technique.
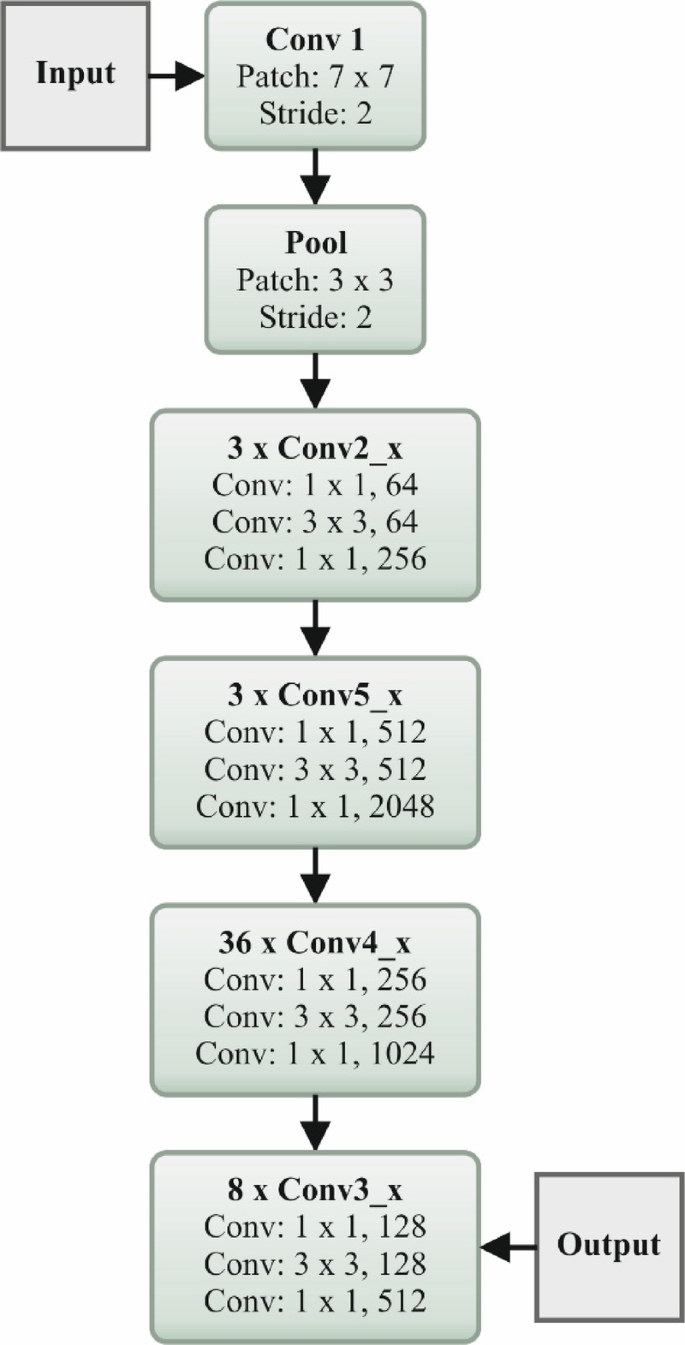
Workflow of the ResNet152 model.
The renowned deep residual network ResNet152 is applied as the pre-trained system in deep convolutional neural networks (DCNN) during this classification method. This technique is responsible for handling the problem of vanishing gradients. Then, the ResNet152 output is transferred to the SoftMax classifier (SMC) in the classification procedure. The succeeding part covers the process of categorizing and identifying characteristics. The fully connected (FC) layer, convolution layer (CL), and downsampling layers (DSL) are some of the most general layers that constitute a DCNN (FCL). The networking depth of DL methods plays an essential section in the model of attaining increased classifier outcomes. Later, for particular values, once the CNN is made deeper, the networking precision starts to slow down; however, persistence decreases after that. The mapping function is added in ResNet152 to reduce the influence of degradation issues.
$$\:W\left(x\right)=K\left(x\right)+x$$
(1)
Here, \(\:W\left(x\right)\) denotes the function of mapping built utilizing a feedforward NN together with SC. In general, SC is the identity map that is the outcome of bypassing similar layers straight, and \(\:K(x,\:{G}_{i})\) refers to representations of the function of residual maps. The formulation is signified by Eq. (2).
$$\:Z=K\left(x,\:{G}_{i}\right)+x$$
(2)
During the CLs of the ResNet method, \(\:3\text{x}3\) filtering is applied, and the down-sampling process is performed by a stride of 2. Next, short-cut networks were added, and the ResNet was built. An adaptive function is applied, as presented by Eq. (3), to enhance the dropout’s implementation now.
$$\:u=\frac{1}{n}{\sum\:}_{i=1}^{n}\left[zlog{(S}_{i})+\left(1-z\right)log\left(1-{S}_{i}\right)\right]$$
(3)
Whereas \(\:n\) denotes training sample counts, \(\:u\) signifies the function of loss, and \(\:{S}_{i}\) represents SMC output, the SMC is a kind of general logistic regression (LR) that might be applied to numerous class labels. The SMC outcomes are presented in Eq. (4).
$$\:{S}_{i}=\frac{{e}^{{l}_{k}}}{{\varSigma\:}_{j=1}^{m}{e}^{{y}_{i}}},\:k=1,\:\cdots\:,m,\:y={y}_{1},\:\cdots\:,\:{y}_{m}$$
(4)
In such a case, the softmax layer outcome is stated. \(\:{l}_{k}\) denotes the input vector component and \(\:l,\) \(\:m\) refers to the total neuron counts established in the output layer. The presented model uses 152 10 adaptive dropout layers (ADLs), an SMC, and convolutional layers (CLs).
SLR using Bi-LSTM technique
The Bi-LSTM model employs the HHODLM-SLR methodology for performing the SLR process40. This methodology is chosen because it can capture long-term dependencies in both forward and backward directions within gesture sequences. Unlike unidirectional LSTM or conventional RNNs, Bi-LSTM considers past and future context concurrently, which is significant for precisely interpreting the temporal flow of dynamic signs. This bidirectional learning enhances the model’s understanding of gesture transitions and co-articulation effects. Its memory mechanism effectually handles variable-length input sequences, which is common in real-world SLR scenarios. Bi-LSTM outperforms static classifiers like CNNs or SVMs when dealing with sequential data, making it highly appropriate for recognizing time-based gestures. Figure 4 specifies the Bi-LSTM method.
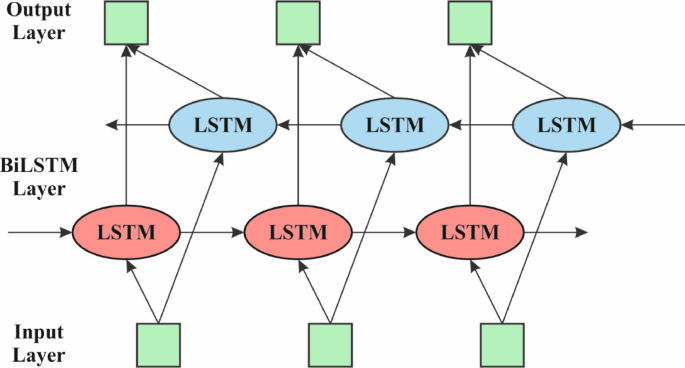
Architecture of Bi-LSTM method.
The presented DAE-based approach for removing the feature is defined here. Additionally, Bi-LSTM is applied to categorize the data. The model to solve classification problems consists of the type of supervised learning. During this method, the Bi‐LSTM classification techniques are used to estimate how the proposed architecture increases the performance of the classification. A novel RNN learning model is recommended to deal with this need, which may enhance the temporal organization of the structure. By the following time stamp, the output is immediately fed reverse itself\(\:.\) RNN is an approach that is often applied in DL. Nevertheless, RNN acquires a slanting disappearance gradient exploding problem. At the same time, the memory unit in the LSTM can choose which data must be saved in memory and at which time it must be deleted. Therefore, LSTM can effectively deal with the problems of training challenges and gradient disappearance by mine time-series with intervals in the time-series and relatively larger intervals. There are three layers in a standard LSTM model architecture: hidden loop, output, and input. The cyclic HL, by comparison with the traditional RNN, generally contains neuron nodes. Memory units assist as the initial module of the LSTM cyclic HLs. Forget, input and output gates are the three adaptive multiplication gate components enclosed in this memory unit. All neuron nodes of the LSTM perform the succeeding computation: The input gate was fixed at \(\:t\:th\) time according to the output result \(\:{h}_{t-1}\) of the component at the time in question and is specified in Eq. (5). The input \(\:{x}_{t}\) accurate time is based on whether to include a computation to upgrade the present data inside the cell.
$$\:{i}_{t}={\upsigma\:}\left({W}_{t}\cdot\:\left[{h}_{t-1},\:{x}_{t}\right]+{b}_{t}\right)$$
(5)
A forget gate defines whether to preserve or delete the data according to the additional new HL output and the present-time input specified in Eq. (6).
$$\:{f}_{\tau\:}={\upsigma\:}\left({W}_{f}\cdot\:\left[{h}_{t-1},{x}_{\tau\:}\right]+{b}_{f}\right)$$
(6)
The preceding output outcome \(\:{h}_{t-1}\) of the HL-LSTM cell establishes the value of the present candidate cell of memory and the present input data \(\:{x}_{t}\). * refers to element-to-element matrix multiplication. The value of memory cell state \(\:{C}_{t}\) adjusts the present candidate cell \(\:{C}_{t}\) and its layer \(\:{c}_{t-1}\) forget and input gates. These values of the memory cell layer are provided in Eq. (7) and Eq. (8).
$$\:{\overline{C}}_{\text{t}}=tanh\left({W}_{C}\cdot\:\left[{h}_{t-1},\:{x}_{t}\right]+{b}_{C}\right)$$
(7)
$$\:{C}_{t}={f}_{t}\bullet\:{C}_{t-1}+{i}_{t}\bullet\:\overline{C}$$
(8)
Output gate \(\:{\text{o}}_{t}\) is established as exposed in Eq. (9) and is applied to control the cell position value. The last cell’s outcome is \(\:{h}_{t}\), inscribed as Eq. (10).
$$\:{o}_{t}={\upsigma\:}\left({W}_{o}\cdot\:\left[{h}_{t-1},\:{x}_{t}\right]+{b}_{o}\right)$$
(9)
$$\:{h}_{t}={\text{o}}_{t}\bullet\:tanh\left({C}_{t}\right)$$
(10)
The forward and backward LSTM networks constitute the BiLSTM. Either the forward or the backward LSTM HLs are responsible for removing characteristics; the layer of forward removes features in the forward directions. The Bi-LSTM approach is applied to consider the effects of all features before or after the sequence data. Therefore, more comprehensive feature information is developed. Bi‐LSTM’s present state comprises either forward or backward output, and they are specified in Eq. (11), Eq. (12), and Eq. (13)
$$\:h_{t}^{{forward}} = LSTM^{{forward}} (h_{{t – 1}} ,\:x_{t} ,\:C_{{t – 1}} )$$
(11)
$$\:{h}_{\tau\:}^{backwar\text{d}}=LST{M}^{backwar\text{d}}\left({h}_{t-1},{x}_{t},\:{C}_{t-1}\right)$$
(12)
$$\:{H}_{T}={h}_{t}^{forward},\:{h}_{\tau\:}^{backwar\text{d}}$$
(13)
Hyperparameter tuning using the HHO model
The HHO methodology utilizes the HHODLM-SLR methodology for accomplishing the hyperparameter tuning process41. This model is employed due to its robust global search capability and adaptive behaviour inspired by the cooperative hunting strategy of Harris hawks. Unlike grid or random search, which can be time-consuming and inefficient, HHO dynamically balances exploration and exploitation to find optimal hyperparameter values. It avoids local minima and accelerates convergence, enhancing the performance and stability of the model. Compared to other metaheuristics, such as PSO or GA, HHO presents faster convergence and fewer tunable parameters. Its bio-inspired nature makes it appropriate for complex, high-dimensional optimization tasks in DL models. Figure 5 depicts the flow of the HHO methodology.

Workflow of the HHO technique.
The HHO model is a bio-inspired technique depending on Harris Hawks’ behaviour. This model was demonstrated through the exploitation or exploration levels. At the exploration level, the HHO may track and detect prey with its effectual eyes. Depending upon its approach, HHO can arbitrarily stay in a few positions and wait to identify prey. Suppose there is an equal chance deliberated for every perched approach depending on the family member’s position. In that case, it might be demonstrated as condition \(\:q<0.5\) or landed at a random position in the trees as \(\:q\ge\:0.5\), which is given by Eq. (14).
$$\:X\left(t+1\right)=\left\{\begin{array}{l}{X}_{rnd}\left(t\right)-{r}_{1}\left|{X}_{rnd}\left(t\right)-2{r}_{2}X\left(t\right)\right|,\:q\ge\:0.5\\\:{X}_{rab}\left(t\right)-{X}_{m}\left(t\right)-r3\left(LB+{r}_{4}\left(UB-LB\right)\right),q<0.5\end{array}\right.$$
(14)
The average location is computed by the Eq. (15).
$$\:{X}_{m}\left(t\right)=\frac{1}{N}{\sum\:}_{i=1}^{N}{X}_{i}\left(t\right)$$
(15)
The movement from exploration to exploitation, while prey escapes, is energy loss.
$$\:E=2{E}_{0}\left(1-\frac{t}{T}\right)$$
(16)
The parameter \(\:E\) signifies the prey’s escape energy, and \(\:T\) represents the maximum iteration counts. Conversely, \(\:{E}_{0}\) denotes a random parameter that swings among \(\:(-\text{1,1})\) for every iteration.
The exploitation level is divided into hard and soft besieges. The surroundings \(\:\left|E\right|\ge\:0.5\) and \(\:r\ge\:0.5\) should be met in a soft besiege. Prey aims to escape through certain arbitrary jumps but eventually fails.
$$\:\begin{array}{c}X\left(t+1\right)=\Delta X\left(t\right)-E\left|J{X}_{rabb}\left(t\right)-X\left(t\right)\right|\:where\\\:\Delta X\left(t\right)={X}_{rabb}\left(t\right)-X\left(t\right)\end{array}$$
(17)
\(\:\left|E\right|<0.5\) and \(\:r\ge\:0.5\) should meet during the hard besiege. The prey attempts to escape. This position is upgraded based on the Eq. (18).
$$\:X\left(t+1\right)={X}_{rabb}\left(t\right)-E\left|\varDelta\:X\left(t\right)\right|$$
(18)
The HHO model originates from a fitness function (FF) to achieve boosted classification performance. It outlines an optimistic number to embody the better outcome of the candidate solution. The minimization of the classifier error ratio was reflected as FF. Its mathematical formulation is represented in Eq. (19).
$$\begin{gathered} fitness\left( {x_{i} } \right) = ClassifierErrorRate\left( {x_{i} } \right)\: \hfill \\ \quad \quad \quad \quad \quad\,\,\, = \frac{{number\:of\:misclassified\:samples}}{{Total\:number\:of\:samples}} \times \:100 \hfill \\ \end{gathered}$$
(19)

AI Insights
Artificial Intelligence forcing some people to change career industries. Here’s how to set a new career course

LOS ANGELES (KABC) — Artificial intelligence is starting to impact the labor market and that has many people considering a career change.
Recent college graduates are getting hit hard by changes in the job market, with companies now turning to AI rather than filling entry level roles.
Tech jobs in fields like computer-coding and software are being eliminated too. That’s leaving a lot of people out of work.
Experts say that if you want to change career industries, examine your strengths, network with others in the field you are seeking and fill holes in your knowledge base.
“For example, somebody might be working at a consulting firm or an accounting firm and their clients may have been tech clients, so all though you yourself have not worked in the tech industry or big tech company, you have serviced that industry,” said Dawn Fay, Operational President – Robert Half.
And consider getting additional certificates to enhance your skills too. This can also enhance your networking.
Copyright © 2025 KABC Television, LLC. All rights reserved.
-

 Business3 days ago
Business3 days agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-
Tools & Platforms3 weeks ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy1 month ago
Ethics & Policy1 month agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences3 months ago
Events & Conferences3 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers2 months ago
Jobs & Careers2 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Funding & Business2 months ago
Funding & Business2 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries
-

 Education2 months ago
Education2 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi
-

 Mergers & Acquisitions2 months ago
Mergers & Acquisitions2 months agoDonald Trump suggests US government review subsidies to Elon Musk’s companies