Books, Courses & Certifications
How Amazon Finance built an AI assistant using Amazon Bedrock and Amazon Kendra to support analysts for data discovery and business insights

Finance analysts across Amazon Finance face mounting complexity in financial planning and analysis processes. When working with vast datasets spanning multiple systems, data lakes, and business units, analysts encounter several critical challenges. First, they spend significant time manually browsing data catalogs and reconciling data from disparate sources, leaving less time for valuable analysis and insight generation. Second, historical data and previous business decisions often reside in various documents and legacy systems, making it difficult to use past learnings during planning cycles. Third, as business contexts rapidly evolve, analysts need quick access to relevant metrics, planning assumptions, and financial insights to support data-driven decision-making.
Traditional tools and processes fall short in addressing these challenges. Keyword-based searches often miss contextual relationships in financial data, and rigid query structures limit analysts’ ability to explore data dynamically. Furthermore, the lack of institutional knowledge preservation means valuable insights and decision rationales often remain siloed or get lost over time, leading to redundant analysis and inconsistent planning assumptions across teams. These challenges significantly impact financial planning efficiency, decision-making agility, and the overall quality of business insights. Analysts needed a more intuitive way to access, understand, and use their organization’s collective financial knowledge and data assets.
The Amazon Finance technical team develops and manages comprehensive technology solutions that power financial decision-making and operational efficiency while standardizing across Amazon’s global operations. In this post, we explain how the team conceptualized and implemented a solution to these business challenges by harnessing the power of generative AI using Amazon Bedrock and intelligent search with Amazon Kendra.
Solution overview
To address these business challenges, Amazon Finance developed an AI-powered assistant solution that uses generative AI and enterprise search capabilities. This solution helps analysts interact with financial data sources and documentation through natural language queries, minimizing the need for complex manual searches across multiple systems. The assistant accesses a comprehensive knowledge base of financial documents, historical data, and business context, providing relevant and accurate responses while maintaining enterprise security standards. This approach not only streamlines data discovery but also preserves institutional knowledge and enables more consistent decision-making across the organization.
The AI assistant’s methodology consists of two key solution components: intelligent retrieval and augmented generation. The retrieval system uses vector stores, which are specialized databases that efficiently store and search high-dimensional representations of text meanings. Unlike traditional databases that rely on keyword matching, vector stores enable semantic search by converting user queries into vector representations and finding similar vectors in the database. Building on this retrieval foundation, the system employs augmented generation to create accurate and contextual responses. This approach enhances traditional language models by incorporating external knowledge sources during response generation, significantly reducing hallucinations and improving factual accuracy. The process follows three steps: retrieving relevant information from knowledge sources using semantic search, conditioning the language model with this context, and generating refined responses that incorporate the retrieved information. By combining these technologies, the assistant delivers responses that are both contextually appropriate and grounded in verified organizational knowledge, making it particularly effective for knowledge-intensive applications like financial operations and planning.
We implemented this Retrieval Augmented Generation (RAG) system through a combination of large language models (LLMs) on Amazon Bedrock and intelligent search using Amazon Kendra.
In the following sections, we discuss the key architectural components that we used in the solution and describe how the overall solution works.
Amazon Bedrock
We chose Anthropic’s Claude 3 Sonnet, a powerful language model, for its exceptional language generation capabilities and ability to understand and reason complex topics. By integrating Anthropic’s Claude into the RAG module through Amazon Bedrock, the AI assistant can generate contextual and informative responses that seamlessly combine the retrieved knowledge from the vector store with the model’s natural language processing and generation abilities, resulting in a more human-like and engaging conversational experience.
Amazon Kendra (Enterprise Edition Index)
Amazon Kendra offers powerful natural language processing for AI assistant applications. It excels at understanding user questions and finding relevant answers through semantic search. The service works smoothly with generative AI models, particularly in RAG solutions. The enterprise security features in Amazon Kendra support data protection and compliance. Its ability to understand user intent and connect directly with Amazon Bedrock makes it ideal for business assistants. This helps create meaningful conversations using business documents and data catalogs.
We chose Amazon Kendra Enterprise Edition Index over Amazon OpenSearch Service, primarily due to its sophisticated built-in capabilities and reduced need for manual configuration. Whereas OpenSearch Service requires extensive customization and technical expertise, Amazon Kendra provides out-of-the-box natural language understanding, automatic document processing for over 40 file formats, pre-built enterprise connectors, and intelligent query handling including synonym recognition and refinement suggestions. The service combines keyword, semantic, and vector search approaches automatically, whereas OpenSearch Service requires manual implementation of these features. These features of Amazon Kendra were suitable for our finance domain use case, where accuracy is imperative for usability.
We also chose Amazon Kendra Enterprise Edition Index over Amazon Q Business for information retrieval, because it stands out as a more robust and flexible solution. Although both tools aim to streamline access to company information, Amazon Kendra offers superior retrieval accuracy and greater control over search parameters. With Amazon Kendra, you can fine-tune relevance tuning, customize document attributes, and implement custom synonyms to enhance search precision. This level of customization helped us tailor the search experience to our specific needs in the Amazon Finance domain and monitor the search results prior to the augmented generation step within user conversations.
Streamlit
We selected Streamlit, a Python-based framework for creating interactive web applications, for building the AI assistant’s UI due to its rapid development capabilities, seamless integration with Python and the assistant’s backend components, interactive and responsive UI components, potential for data visualization, and straightforward deployment options. With the Streamlit UI, the assistant provides a user-friendly and engaging interface that facilitates natural language interactions while allowing for efficient iteration and deployment of the application.
Prompt template
Prompt templates allow for formatting user queries, integrating retrieved knowledge, and providing instructions or constraints for response generation, which are essential for generating contextual and informative responses that combine the language generation abilities of Anthropic’s Claude with the relevant knowledge retrieved from the search powered by Amazon Kendra. The following is an example prompt:
Solution architecture
The following solution architecture diagram depicts how the key architectural components work with each other to power the solution.
The workflow consists of the following steps:
- The user asks the question in a chat box after authentication.
- The Streamlit application sends the query to an Amazon Kendra retriever for relevant document retrieval.
- Amazon Kendra sends the relevant paragraph and document references to the RAG solution.
- The RAG solution uses Anthropic’s Claude in Amazon Bedrock along with the prompt template and relevant paragraph as context.
- The LLM response is sent back to the Streamlit UI.
- The response is shown to the user along with the feedback feature and session history.
- The user feedback on responses is stored separately in Amazon Simple Storage Service (Amazon S3)
- Amazon Kendra indexes relevant documents stored in S3 buckets for document search and retrieval.
Frontend architecture
We designed the following frontend architecture to allow for rapid modifications and deployment, keeping in mind the scalability and security of the solution.

This workflow consists of the following steps:
- The user navigates to the application URL in their browser.
- Amazon Route 53 resolves their request to the Amazon CloudFront distribution, which then selects the server closest to the user (to minimize latency).
- CloudFront runs an AWS Lambda function that makes sure the user has been authenticated. If not, the user is redirected to sign in. After they successfully sign in, they are redirected back to the application website. The flow repeats, and CloudFront triggers the Lambda function again. This time, the user is now able to access the website.
- Now authenticated, CloudFront returns the assets of the web application.
- AWS Fargate makes it possible to run containers without having to manage the underlying Amazon Elastic Compute Cloud (Amazon EC2) instances. This allows running containers as a true serverless service. Amazon Elastic Container Service (Amazon ECS) is configured with automatic scaling (target tracking automatic scaling, which scales based on the Application Load Balancer (ALB) requests per target).
Evaluation of the solution’s performance
We implemented a comprehensive evaluation framework to rigorously assess the AI assistant’s performance and make sure it meets the high standards required for financial applications. Our framework was designed to capture both quantitative metrics for measurable performance and qualitative indicators for user experience and response quality. During our benchmarking tests with analysts, we found that this solution dramatically reduced search time by 30% because analysts can now perform natural language search, and it improved the accuracy of search results by 80%.
Quantitative assessment
We focused primarily on precision and recall testing, creating a diverse test set of over 50 business queries that represented typical use cases our analysts encounter. Using human-labeled answers as our ground truth, we evaluated the system’s performance across two main categories: data discovery and knowledge search. In data discovery scenarios, where the system helps analysts locate specific data sources and metrics, we achieved an initial precision rate of 65% and a recall rate of 60% without performing metadata enrichment on the data sources. Although these rates might appear moderate, they represent a significant improvement over the previous manual search process, which had an estimated success rate of only 35% and often required multiple iterations across different systems. The primary reasons for the current rates of the new system were attributed to the lack of rich metadata about data sources and was a good indicator for teams to facilitate better metadata collection of data assets, which is currently underway.
The knowledge search capability demonstrated initial rates of 83% precision and 74% recall without performing metadata enrichment on data sources. This marked a substantial improvement over traditional keyword-based search methods, which typically achieved only 45–50% precision in our internal testing. This improvement is particularly meaningful because it translates to analysts finding the right information in their first search attempt roughly 8 out of 10 times, compared to the previous average of 3–4 attempts needed to locate the same information.
Qualitative metrics
The qualitative evaluation centered around the concept of faithfulness—a critical metric for financial applications where accuracy and reliability are paramount. We employed an innovative LLM-as-a-judge methodology to evaluate how well the AI assistant’s responses aligned with source documentation and avoided hallucinations or unsupported assertions. The results showed a marked difference between use cases: data discovery achieved a faithfulness score of 70%, and business knowledge search demonstrated an impressive 88% faithfulness. These scores significantly outperform our previous documentation search system, which had no built-in verification mechanism and often led to analysts working with outdated or incorrect information.
Most importantly, the new system reduced the average time to find relevant information from 45–60 minutes to just 5–10 minutes—an 85% improvement in efficiency. User satisfaction surveys indicate that 92% of analysts prefer the new system over traditional search methods, citing improved accuracy and time savings as key benefits.
These evaluation results have not only validated our approach but also highlighted specific areas for future enhancement. We continue to refine our evaluation framework as the system evolves, making sure it maintains high standards of accuracy and reliability while meeting the dynamic needs of our financial analysts. The evaluation framework was instrumental in building confidence within our business user community, providing transparent metrics that demonstrate the system’s capability to handle complex financial queries while maintaining the accuracy standards essential for financial operations.
Use cases
Our solution transforms how finance users interact with complex financial and operational data through natural language queries. In this section, we discuss some key examples demonstrating how the system simplifies data discovery.
Seamless data discovery
The solution enables users to find data sources through natural language queries rather than requiring technical knowledge of database structures. It uses a sophisticated combination of vector stores and enterprise search capabilities to match user questions with relevant data sources, though careful attention must be paid to context management and preventing over-reliance on previous interactions. Prior to the AI assistant solution, finance analysts needed deep technical knowledge to navigate complex database structures, often spending hours searching through multiple documentation sources just to locate specific data tables. Understanding system workflows required extensive review of technical documentation or reaching out to subject matter experts, creating bottlenecks and reducing productivity. Even experienced users struggled to piece together complete information about business processes from fragmented sources across different systems. Now, analysts can simply ask questions in natural language, such as “Where can I find productivity metrics?”, “How do I access facility information?”, or “Which dashboard shows operational data?” and receive precise, contextual answers. The solution combines enterprise search capabilities with LLMs to understand user intent and deliver relevant information from both structured and unstructured data sources. Analysts now receive accurate directions to specific consolidated reporting tables, clear explanations of business processes, and relevant technical details when needed. In our benchmark tests, for data discovery tasks alone, the system achieved 70% faithfulness and 65% precision, and document search demonstrated even stronger results with 83% precision and 88% faithfulness, without metadata enrichments.
Assisting understanding of internal business processes from knowledge documentation
Financial analysts previously faced a steep learning curve when working with enterprise planning tools. The complexity of these systems meant that even basic tasks required extensive documentation review or waiting for support from overwhelmed subject matter experts. New team members could take weeks or months to become proficient, while even experienced users struggled to keep up with system updates and changes. This created a persistent bottleneck in financial operations and planning processes. The introduction of the AI-powered assistant has fundamentally changed how analysts learn and interact with these planning tools. Rather than searching through hundreds of pages of technical documentation, analysts can now ask straightforward questions like “How do I forecast depreciation for new assets?”, “How does the quarterly planning process work?” or “What inputs are needed for the quarterly planning cycle?” The system provides clear, contextualized explanations drawn from verified documentation and system specifications. Our benchmark tests revealed that it achieved 83% precision and 88% faithfulness in retrieving and explaining technical and business information. New analysts can become productive in a matter of weeks, experienced users can quickly verify procedures, and subject matter experts can focus on more complex challenges rather than routine questions. This represents a significant advancement in making enterprise systems more accessible and efficient, while maintaining the accuracy and reliability required for financial operations.While the technology continues to evolve, particularly in handling nuanced queries and maintaining comprehensive coverage of system updates, it has already transformed the way teams interact with planning tools independently.
Conclusion
The AI-powered assistant solution discussed in this post has demonstrated significant improvements in data discovery and business insights generation, delivering multiple key benefits across Amazon Finance. Analysts can now quickly find relevant information through natural language queries, dramatically reducing search time. The system’s ability to synthesize insights from disparate data sources has notably enhanced data-driven decision-making, and its conversational interface and contextual responses promote self-service data exploration, effectively reducing the burden on centralized data teams.
This innovative AI assistant solution showcases the practical power of AWS generative AI in transforming enterprise data discovery and document search. By combining Amazon Kendra Enterprise Edition Index, Amazon Bedrock, and advanced LLMs, the implementation achieves impressive precision rates, proving that sophisticated AI-powered search is both achievable and effective. This success demonstrates how AWS generative AI services can meet current business needs while promoting future innovations in enterprise search. These services provide a strong foundation for organizations looking to enhance data discovery processes using natural language to support intelligent enterprise applications. To learn more about implementing AI-powered search solutions, see Build and scale the next wave of AI innovation on AWS and explore AWS AI use cases.
About the authors
 Saikat Gomes is part of the Customer Solutions team in Amazon Web Services. He is passionate about helping enterprises succeed and realize benefits from cloud adoption. He is a strategic advisor to his customers for large-scale cloud transformations involving people, process, and technology. Prior to joining AWS, he held multiple consulting leadership positions and led large- scale transformation programs in the retail industry for over 20 years. He is based out of Los Angeles, California.
Saikat Gomes is part of the Customer Solutions team in Amazon Web Services. He is passionate about helping enterprises succeed and realize benefits from cloud adoption. He is a strategic advisor to his customers for large-scale cloud transformations involving people, process, and technology. Prior to joining AWS, he held multiple consulting leadership positions and led large- scale transformation programs in the retail industry for over 20 years. He is based out of Los Angeles, California.
 Amit Dhanda serves as a Senior Scientist at Amazon’s Worldwide Operations Finance team, where he uses AI/ML technologies to solve complex ecommerce challenges. Prior to Amazon, he was Director of Data Science at Adore Me (now part of Victoria’s Secret), where he enhanced digital retail experiences through recommender systems. He held science leadership roles at EXL and Thomson Reuters, where he developed ML models for customer engagement/growth and text classification.
Amit Dhanda serves as a Senior Scientist at Amazon’s Worldwide Operations Finance team, where he uses AI/ML technologies to solve complex ecommerce challenges. Prior to Amazon, he was Director of Data Science at Adore Me (now part of Victoria’s Secret), where he enhanced digital retail experiences through recommender systems. He held science leadership roles at EXL and Thomson Reuters, where he developed ML models for customer engagement/growth and text classification.

In early 2024, a striking deepfake fraud case in Hong Kong brought the vulnerabilities of AI-driven deception into sharp relief. A finance employee was duped during a video call by what appeared to be the CFO—but was, in fact, a sophisticated AI-generated deepfake. Convinced of the call’s authenticity, the employee made 15 transfers totaling over $25 million to fraudulent bank accounts before realizing it was a scam.
This incident exemplifies more than just technological trickery—it signals how trust in what we see and hear can be weaponized, especially as AI becomes more deeply integrated into enterprise tools and workflows. From embedded LLMs in enterprise systems to autonomous agents diagnosing and even repairing issues in live environments, AI is transitioning from novelty to necessity. Yet as it evolves, so too do the gaps in our traditional security frameworks—designed for static, human-written code—revealing just how unprepared we are for systems that generate, adapt, and behave in unpredictable ways.
Beyond the CVE Mindset
Traditional secure coding practices revolve around known vulnerabilities and patch cycles. AI changes the equation. A line of code can be generated on the fly by a model, shaped by manipulated prompts or data—creating new, unpredictable categories of risk like prompt injection or emergent behavior outside traditional taxonomies.
A 2025 Veracode study found that 45% of all AI-generated code contained vulnerabilities, with common flaws like weak defenses against XSS and log injection. (Some languages performed more poorly than others. Over 70% of AI-generated Java code had a security issue, for instance.) Another 2025 study showed that repeated refinement can make things worse: After just five iterations, critical vulnerabilities rose by 37.6%.
To keep pace, frameworks like the OWASP Top 10 for LLMs have emerged, cataloging AI-specific risks such as data leakage, model denial of service, and prompt injection. They highlight how current security taxonomies fall short—and why we need new approaches that model AI threat surfaces, share incidents, and iteratively refine risk frameworks to reflect how code is created and influenced by AI.
Easier for Adversaries
Perhaps the most alarming shift is how AI lowers the barrier to malicious activity. What once required deep technical expertise can now be done by anyone with a clever prompt: generating scripts, launching phishing campaigns, or manipulating models. AI doesn’t just broaden the attack surface; it makes it easier and cheaper for attackers to succeed without ever writing code.
In 2025, researchers unveiled PromptLock, the first AI-powered ransomware. Though only a proof of concept, it showed how theft and encryption could be automated with a local LLM at remarkably low cost: about $0.70 per full attack using commercial APIs—and essentially free with open source models. That kind of affordability could make ransomware cheaper, faster, and more scalable than ever.
This democratization of offense means defenders must prepare for attacks that are more frequent, more varied, and more creative. The Adversarial ML Threat Matrix, founded by Ram Shankar Siva Kumar during his time at Microsoft, helps by enumerating threats to machine learning and offering a structured way to anticipate these evolving risks. (He’ll be discussing the difficulty of securing AI systems from adversaries at O’Reilly’s upcoming Security Superstream.)
Silos and Skill Gaps
Developers, data scientists, and security teams still work in silos, each with different incentives. Business leaders push for rapid AI adoption to stay competitive, while security leaders warn that moving too fast risks catastrophic flaws in the code itself.
These tensions are amplified by a widening skills gap: Most developers lack training in AI security, and many security professionals don’t fully understand how LLMs work. As a result, the old patchwork fixes feel increasingly inadequate when the models are writing and running code on their own.
The rise of “vibe coding”—relying on LLM suggestions without review—captures this shift. It accelerates development but introduces hidden vulnerabilities, leaving both developers and defenders struggling to manage novel risks.
From Avoidance to Resilience
AI adoption won’t stop. The challenge is moving from avoidance to resilience. Frameworks like Databricks’ AI Risk Framework (DASF) and the NIST AI Risk Management Framework provide practical guidance on embedding governance and security directly into AI pipelines, helping organizations move beyond ad hoc defenses toward systematic resilience. The goal isn’t to eliminate risk but to enable innovation while maintaining trust in the code AI helps produce.
Transparency and Accountability
Research shows AI-generated code is often simpler and more repetitive, but also more vulnerable, with risks like hardcoded credentials and path traversal exploits. Without observability tools such as prompt logs, provenance tracking, and audit trails, developers can’t ensure reliability or accountability. In other words, AI-generated code is more likely to introduce high-risk security vulnerabilities.
AI’s opacity compounds the problem: A function may appear to “work” yet conceal vulnerabilities that are difficult to trace or explain. Without explainability and safeguards, autonomy quickly becomes a recipe for insecure systems. Tools like MITRE ATLAS can help by mapping adversarial tactics against AI models, offering defenders a structured way to anticipate and counter threats.
Looking Ahead
Securing code in the age of AI requires more than patching—it means breaking silos, closing skill gaps, and embedding resilience into every stage of development. The risks may feel familiar, but AI scales them dramatically. Frameworks like Databricks’ AI Risk Framework (DASF) and the NIST AI Risk Management Framework provide structures for governance and transparency, while MITRE ATLAS maps adversarial tactics and real-world attack case studies, giving defenders a structured way to anticipate and mitigate threats to AI systems.
The choices we make now will determine whether AI becomes a trusted partner—or a shortcut that leaves us exposed.
Books, Courses & Certifications
How Much Freedom Do Teachers Have in the Classroom? In 2025, It’s Complicated.

A teacher’s classroom setup can reveal a lot about their approach to learning. April Jones, who is a ninth grade algebra teacher in San Antonio, Texas, has met more than 100 students this school year, in most cases for the first time. Part of what makes an effective teacher is an ability to be personable with students.
“If a kid likes coming to your class or likes chatting with you or seeing you, they’re more likely to learn from you,” said Jones. “Trying to do something where kids can come in and they see even one piece of information on a poster, and they go, ‘OK, she gets it,’ or ‘OK, she seems cool, I’m going to sit down and try,’ I think, is always my goal.”
One way she does this is by covering the muted yellow walls — a color she wouldn’t have chosen herself — with posters, signs and banners Jones has accumulated in the 10 years she’s been teaching; from colleagues, students and on her own dime.
Among the items taped near her desk are a poster of the women who made meaningful contributions to mathematics, a sign recognizing her as a 2025 teacher of the year and a collection of punny posters, one of which features a predictable miscommunication between Lisa and Homer Simpson over the meaning of Pi.
Until now, Jones has been decorating on autopilot. Realizing she’s saved the most controversial for last, she looks down at the “Hate Has No Home Here” sign that’s been the subject of scrutiny from her district and online. But it’s also given her hope.
At a time when states are enforcing laws challenging what teachers can teach, discuss and display in classrooms, many districts are signaling a willingness to overcomply with the Trump administration’s executive order that labeled diversity, equity and inclusion programs, policies and guidance an unlawful use of federal funding. How teachers are responding has varied based on where they live and work, and how comfortable they are with risk.
New Rules on Classroom Expression
Like many public school teachers in the U.S., Jones lives in a state, Texas, that recently introduced new laws concerning classroom expression that are broad in scope and subjective in nature. Texas’ Senate Bill 12 took effect Sept. 1. It prohibits programs, discussions and public performances related to race, ethnicity, gender identity and sexual orientation in public K-12 schools.
Administrators in Jones’ district asked that she take down the “Hate Has No Home Here” sign, which includes three hearts — two filled in to resemble the Pride and Transgender Pride flags, and one depicting a gradient of skin colors. Jones refused, garnering favorable media attention for her defiance, and widespread community support both at school board meetings and online, leaving her poised to prevail, at least in the court of public opinion. Then, all teachers of the North East Independent School District received the same directive: Pride symbolism needs to be covered for the 2025-26 school year.
Jones finished decorating her classroom by hanging the banner.
“I did fold the bottom so you can’t see the hearts,” Jones said, calling the decision heartbreaking. “It does almost feel like a defeat, but with the new law, you just don’t know.”
The new law is written ambiguously, while also affecting any number of actions or situations without guidance, leaving Texas educators to decode the law for themselves. Jones’ district is taking complaints on a case-by-case basis: With Jones’ sign, the district agreed the words themselves were OK as an anti-bullying message, but not the symbolism associated with the multicolored hearts.
Jones has sympathy for the district. Administrators have to ensure teachers are in compliance if the district receives a complaint. In the absence of a clear legal standard, administrators are forced to decide what is and isn’t allowed — a job “nobody wants to have to do,” Jones says.
This comes as Texas public school teachers faced mandates to display donated posters of the Ten Commandments in their classrooms, which is now being challenged in the courts. And in other states, such as Florida, Arkansas and Alabama, officials have passed laws banning the teaching of “divisive concepts.” Now, teachers in those states have to rethink their approach to teaching hard histories that have always been part of the curriculum, such as slavery and Civil Rights, and how to do so in a way that provides students a complete history lesson.
Meanwhile, PEN America identified more than a dozen states that considered laws prohibiting teachers from displaying flags or banners related to political viewpoints, sexual orientation and gender identity this year. Utah, Idaho and Montana passed versions of flag bans.
“The bills [aren’t] necessarily saying, ‘No LGBTQ+ flags or Black Lives Matter flags,’ but that’s really implied, especially when you look at what the sponsors of the bills are saying,” said Madison Markham, a program coordinator with PEN America’s Freedom to Read.
Montana’s HB25-819 does explicitly restrict flags representing any political party, race, sexual orientation, gender or political ideology. Co-sponsors of similar bills in other states have used the Pride flag as an example of what they’re trying to eliminate from classrooms. Earlier this year, Idaho State Rep. Ted Hill cited an instance involving a teacher giving a class via Zoom.
“There was the Pride flag in the background. Not the American flag, but the Pride flag,” said Hill during an Idaho House Education Committee presentation in January. “She’s doing a Zoom call, and that’s not OK.”
Markham at PEN America sees flag, sign and display bans as natural outgrowths of physical and digital book censorship. She first noticed a shift in legislation challenging school libraries that eventually evolved into Florida’s “Don’t Say Gay” law, where openly LGBTQ+ teachers began censoring themselves out of caution even before it fully took effect.
“Teachers who were in a same-sex relationship were taking down pictures of themselves and their partner in their classroom,” Markham recalled. “They took them down because they were scared of the implications.”
The next step, digital censorship, Markham says, involves web filtering or turning off district-wide access to ebooks, research databases and other collections that can be subjected to keyword searches that omit context.
“This language that we see often weaponized, like ‘harmful to minors’, ‘obscene materials,’ even though obscene materials [already] have been banned in schools — [lawmakers] are putting this language in essentially to intimidate districts into overcomplying,” said Markham.
State Flag Imbroglio
To understand how digital environments became susceptible to the same types of censorship as physical books, one doesn’t have to look farther than state laws that apply to online catalogs. In 2023, Texas’ READER Act standardized how vendors label licensed products to public schools. To accommodate Texas and other states with similar digital access restrictions, vendors have needed to add content warnings to materials. There have already been notable mishaps.
In an example that captured a lot of media attention earlier this year, the Lamar Consolidated Independent School District, outside Houston, turned off access to a lesson about Virginia because it had a picture of the Virginia state flag, which depicts the Roman goddess Virtus, whose bare breast is exposed. That image put the Virginia flag in violation of the district’s local library materials policy.

Anne Russey, co-founder of the Texas Freedom to Read Project and a parent herself, learned of the district’s action and started looking into what happened. She found the district went to great lengths to overcomply with the new READER Act by rewriting the library materials policy; it even went so far as to add more detailed descriptions of what is considered a breast. Now, Russey says, students can learn about all of the original 13 colonies, except, perhaps, Virginia.
“As parents, we don’t believe children need access at their schools to sexually explicit material or books that are pervasively vulgar,” said Russey. “[But] we don’t think the Virginia flag qualifies as that, and I don’t think most people think that it qualifies.”
Disturbing Trends
While there isn’t yet a complete picture of how these laws are transforming educational environments, trends are beginning to emerge. School boards and districts have already exercised unequivocal readings of the laws that can limit an entire district’s access to materials and services.
A recent study from FirstBook found a correlation between book bans and reading engagement among students at a moment when literacy rates are trending down nationally overall. The erosion of instructional autonomy in K-12 settings has led more teachers to look outside the profession, to other districts or to charter and private schools.
Rachel Perera, a fellow of the Brown Center on Education Policy, Teacher Rights and Private Schools with the Brookings Institute, says that private and charter schools offer varying degrees of operational autonomy, but there are some clear drawbacks: limited transparency and minimal regulations and government oversight of charter and private schools mean there are fewer legal protections for teachers in those systems.
“One cannot rely on the same highly regulated standard of information available in the public sector,” said Perera. “Teachers should be a lot more wary of private school systems. The default assumption of trust in the private sector leadership is often not warranted.”
Last year, English teacher John McDonough was at the center of a dispute at his former charter school in New Hampshire. Administrators received a complaint about his Pride flag and asked him to remove it. McDonough’s dismay over the request became an ongoing topic of discussion at the charter school board meetings.
“During one of the meetings about my classroom, we had people from the community come in and say that they were positive that I was like a Satanist,” McDonough recalled. “We had a board member that was convinced I was trying to send secret messages and code [about] anti-Christian messages through my room decor.”
The situation was made worse by what McDonough described as a loss of agency over his curriculum for the year.
“All of a sudden I was having the principal drop by my room and go, ‘OK here’s your deck of worksheets. These are the worksheets you’re going to be teaching this week, the next week, and the next week,’ until finally, everything was so intensely structured that there was zero time for me to adjust for anything,” he said. “The priority seemed to be not that all of the kids understand the concepts, but ‘are you sticking as rigidly to this set of worksheets as you can?’”
It didn’t come as a surprise when McDonough’s contract wasn’t renewed for the current school year. But he landed a teaching job at another nearby charter school. He described the whole ordeal as “eye-opening.”
Researchers argue that censorship begets further censorship. The restrictive approach used to remove books about race, sex, and gender creates the opportunity for politically- and ideologically-motivated challenges to other subjects and materials under the guise of protecting minors or maintaining educational standards. Without effective guidance from lawmakers or the courts, it can be hard to know what is or isn’t permissible, experts say.
Legal Experts Weigh In
First Amendment researchers and legal experts are trying to meet the moment. Jenna Leventhal, senior policy counsel at the ACLU, contends that the First Amendment does more to protect students than teachers, particularly on public school grounds.
As a result, Leventhal is hesitant to advise teachers. There is too much variability among who is most affected in terms of the subjects — she cited art, world history and foreign languages as examples — and where they live and the districts where they teach. In general, however, the First Amendment still protects controversial, disfavored and uncomfortable speech, she says.
“Let’s say you have a category of speech that you are banning,” Leventhal said. “Someone has to decide what fits in that category of speech and what doesn’t. And when you give that opportunity to the government, it’s ripe for abuse.”
Teachers are expected to use their professional judgment to create effective learning environments and students’ critical thinking, discovery and expression of their beliefs. And yet, in recent years, many states have proposed and passed laws that limit how teachers, librarians and administrators can discuss race, sex and gender, creating a void in what some students can learn about these subjects, which can affect how they understand their own identity, historical events and related risk factors for their personal safety.
The Limits of Freedom
McDonough in New Hampshire says when he first started displaying the Pride flag in his classroom, it was at the request of a student.
“I was just like, ‘this space is a shared space, and the kids deserve a voice in what it looks like,’” McDonough said.
This year, he left the choice of whether or not to hang the Pride flag in his new classroom up to his students. His students decided as a group that their community was safe and supportive, and therefore they didn’t need to hang a Pride flag.
Meanwhile in Texas, SB-12 has created a de facto parental notification requirement in many situations, including those involving gender and sexuality. Now, when Jones’ students start to tell her something, she is cautious.
She sometimes fields questions from students by asking if their parents know what they’re about to say.
“Because if not,” she warns them, “depending on what you tell me, they’re going to,” she said.
Jones wonders if her compliance with her state’s legal requirements is encroaching on her personal identity beyond the classroom.
“I don’t want to get myself into a situation where I’m mandated to report something, and if I make the choice not to, I could be held liable,” Jones said.
This isn’t the dynamic Jones wants to have with her students. She hopes that going forward, the new law doesn’t push her toward becoming a version of her teacher-self she doesn’t want to be.
“If a student trusts me to come out or to tell me something about their life, I want them to be able to do that,” she added.
Maintaining professional integrity and protecting their right to create a welcoming classroom environment are at the heart of the resistance among some schools and teachers that are defying state and federal guidance against inclusion language. Cases are being decided at the district level. In northern Virginia, a handful of districts are vowing to keep their DEI policies intact, even as the U.S. Department of Education threatens defunding. An Idaho teacher who last year refused a district request to remove an “All Are Welcome Here” sign from her classroom now works for the Boise School District. That district decided over the summer that it would allow teachers to hang similar signs, in spite of guidance to the contrary from the state’s attorney general.
Educators in other states have also refused orders to remove displays, books and otherwise water down their curriculums, galvanizing more attention to the realities of the environments teachers are having to navigate this fall. It’s the adoption of a mindset that censorship is a choice.
“I’m not teaching politics,” Jones said. “I’m not promoting anything. Choosing to have a rainbow heart or a pin on my lanyard — someone would have to look at that and then complain to someone [else] that they feel is above me. And that is a choice that they make rather than seeing this [object] and [choosing] to move on.”
Retrieval Augmented Generation (RAG) is a fundamental approach for building advanced generative AI applications that connect large language models (LLMs) to enterprise knowledge. However, crafting a reliable RAG pipeline is rarely a one-shot process. Teams often need to test dozens of configurations (varying chunking strategies, embedding models, retrieval techniques, and prompt designs) before arriving at a solution that works for their use case. Furthermore, management of high-performing RAG pipeline involves complex deployment, with teams often using manual RAG pipeline management, leading to inconsistent results, time-consuming troubleshooting, and difficulty in reproducing successful configurations. Teams struggle with scattered documentation of parameter choices, limited visibility into component performance, and the inability to systematically compare different approaches. Additionally, the lack of automation creates bottlenecks in scaling the RAG solutions, increases operational overhead, and makes it challenging to maintain quality across multiple deployments and environments from development to production.
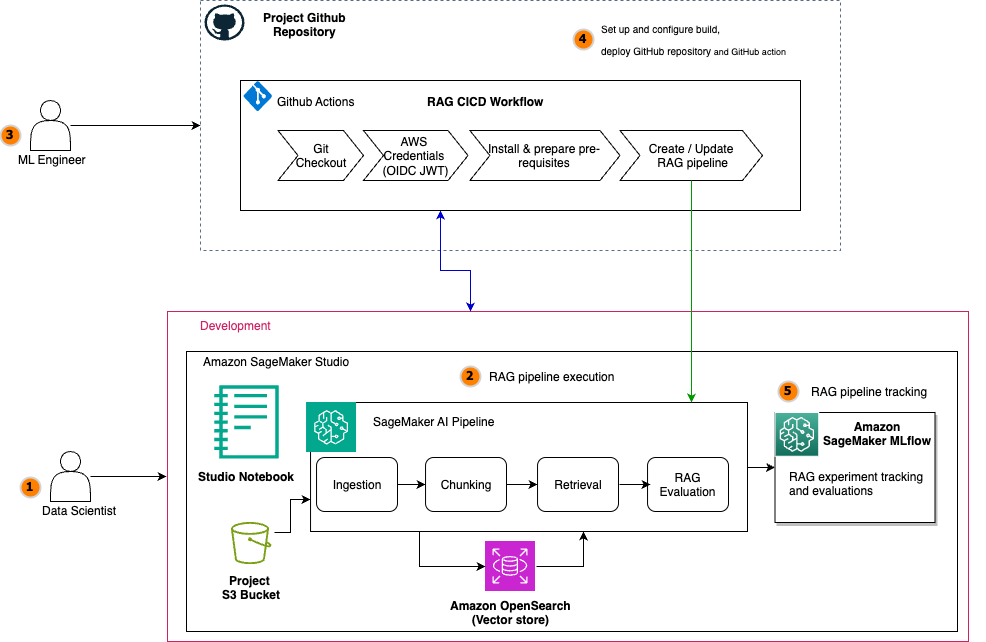
In this post, we walk through how to streamline your RAG development lifecycle from experimentation to automation, helping you operationalize your RAG solution for production deployments with Amazon SageMaker AI, helping your team experiment efficiently, collaborate effectively, and drive continuous improvement. By combining experimentation and automation with SageMaker AI, you can verify that the entire pipeline is versioned, tested, and promoted as a cohesive unit. This approach provides comprehensive guidance for traceability, reproducibility, and risk mitigation as the RAG system advances from development to production, supporting continuous improvement and reliable operation in real-world scenarios.
Solution overview
By streamlining both experimentation and operational workflows, teams can use SageMaker AI to rapidly prototype, deploy, and monitor RAG applications at scale. Its integration with SageMaker managed MLflow provides a unified platform for tracking experiments, logging configurations, and comparing results, supporting reproducibility and robust governance throughout the pipeline lifecycle. Automation also minimizes manual intervention, reduces errors, and streamlines the process of promoting the finalized RAG pipeline from the experimentation phase directly into production. With this approach, every stage from data ingestion to output generation operates efficiently and securely, while making it straightforward to transition validated solutions from development to production deployment.
For automation, Amazon SageMaker Pipelines orchestrates end-to-end RAG workflows from data preparation and vector embedding generation to model inference and evaluation all with repeatable and version-controlled code. Integrating continuous integration and delivery (CI/CD) practices further enhances reproducibility and governance, enabling automated promotion of validated RAG pipelines from development to staging or production environments. Promoting an entire RAG pipeline (not just an individual subsystem of the RAG solution like a chunking layer or orchestration layer) to higher environments is essential because data, configurations, and infrastructure can vary significantly across staging and production. In production, you often work with live, sensitive, or much larger datasets, and the way data is chunked, embedded, retrieved, and generated can impact system performance and output quality in ways that are not always apparent in lower environments. Each stage of the pipeline (chunking, embedding, retrieval, and generation) must be thoroughly evaluated with production-like data for accuracy, relevance, and robustness. Metrics at every stage (such as chunk quality, retrieval relevance, answer correctness, and LLM evaluation scores) must be monitored and validated before the pipeline is trusted to serve real users.
The following diagram illustrates the architecture of a scalable RAG pipeline built on SageMaker AI, with MLflow experiment tracking seamlessly integrated at every stage and the RAG pipeline automated using SageMaker Pipelines. SageMaker managed MLflow provides a unified platform for centralized RAG experiment tracking across all pipeline stages. Every MLflow execution run whether for RAG chunking, ingestion, retrieval, or evaluation sends execution logs, parameters, metrics, and artifacts to SageMaker managed MLflow. The architecture uses SageMaker Pipelines to orchestrate the entire RAG workflow through versioned, repeatable automation. These RAG pipelines manage dependencies between critical stages, from data ingestion and chunking to embedding generation, retrieval, and final text generation, supporting consistent execution across environments. Integrated with CI/CD practices, SageMaker Pipelines enable seamless promotion of validated RAG configurations from development to staging and production environments while maintaining infrastructure as code (IaC) traceability.
For the operational workflow, the solution follows a structured lifecycle: During experimentation, data scientists iterate on pipeline components within Amazon SageMaker Studio notebooks while SageMaker managed MLflow captures parameters, metrics, and artifacts at every stage. Validated workflows are then codified into SageMaker Pipelines and versioned in Git. The automated promotion phase uses CI/CD to trigger pipeline execution in target environments, rigorously validating stage-specific metrics (chunk quality, retrieval relevance, answer correctness) against production data before deployment. The other core components include:
- Amazon SageMaker JumpStart for accessing the latest LLM models and hosting them on SageMaker endpoints for model inference with the embedding model
huggingface-textembedding-all-MiniLM-L6-v2and text generation modeldeepseek-llm-r1-distill-qwen-7b. - Amazon OpenSearch Service as a vector database to store document embeddings with the OpenSearch index configured for k-nearest neighbors (k-NN) search.
- The Amazon Bedrock model
anthropic.claude-3-haiku-20240307-v1:0as an LLM-as-a-judge component for all the MLflow LLM evaluation metrics. - A SageMaker Studio notebook for a development environment to experiment and automate the RAG pipelines with SageMaker managed MLflow and SageMaker Pipelines.
You can implement this agentic RAG solution code from the GitHub repository. In the following sections, we use snippets from this code in the repository to illustrate RAG pipeline experiment evolution and automation.
Prerequisites
You must have the following prerequisites:
- An AWS account with billing enabled.
- A SageMaker AI domain. For more information, see Use quick setup for Amazon SageMaker AI.
- Access to a running SageMaker managed MLflow tracking server in SageMaker Studio. For more information, see the instructions for setting up a new MLflow tracking server.
- Access to SageMaker JumpStart to host LLM embedding and text generation models.
- Access to the Amazon Bedrock foundation models (FMs) for RAG evaluation tasks. For more details, see Subscribe to a model.
SageMaker MLFlow RAG experiment
SageMaker managed MLflow provides a powerful framework for organizing RAG experiments, so teams can manage complex, multi-stage processes with clarity and precision. The following diagram illustrates the RAG experiment stages with SageMaker managed MLflow experiment tracking at every stage. This centralized tracking offers the following benefits:
- Reproducibility: Every experiment is fully documented, so teams can replay and compare runs at any time
- Collaboration: Shared experiment tracking fosters knowledge sharing and accelerates troubleshooting
- Actionable insights: Visual dashboards and comparative analytics help teams identify the impact of pipeline changes and drive continuous improvement
The following diagram illustrates the solution workflow.
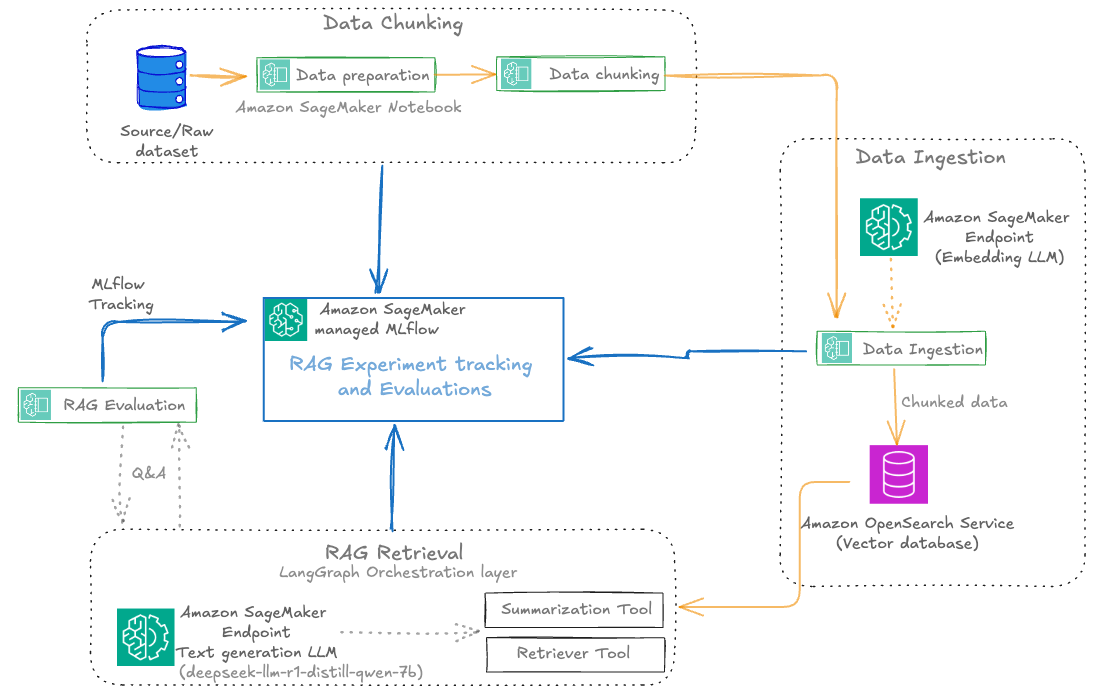
Each RAG experiment in MLflow is structured as a top-level run under a specific experiment name. Within this top-level run, nested runs are created for each major pipeline stage, such as data preparation, data chunking, data ingestion, RAG retrieval, and RAG evaluation. This hierarchical approach allows for granular tracking of parameters, metrics, and artifacts at every step, while maintaining a clear lineage from raw data to final evaluation results.
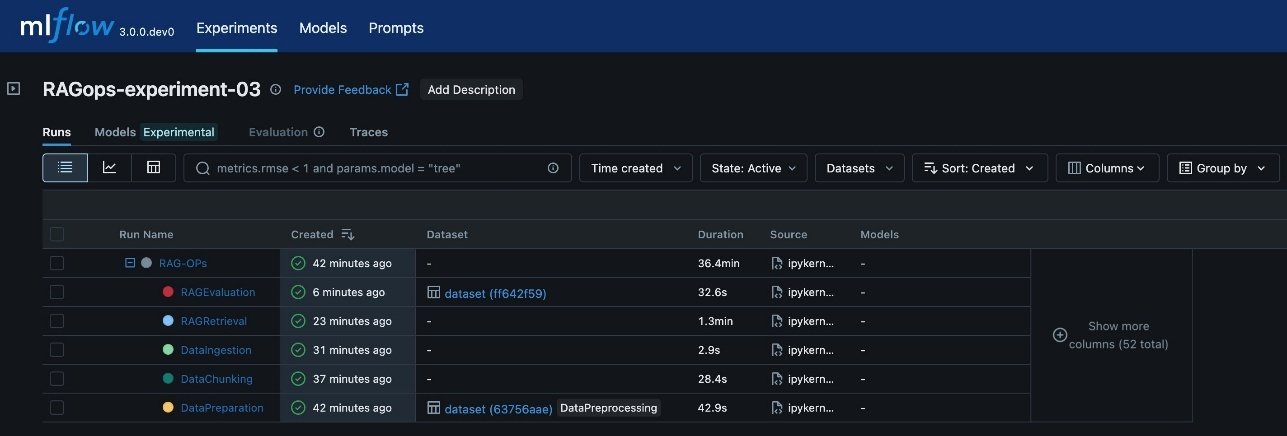
The following screenshot shows an example of the experiment details in MLflow.
The various RAG pipeline steps defined are:
- Data preparation: Logs dataset version, preprocessing steps, and initial statistics
- Data chunking: Records chunking strategy, chunk size, overlap, and resulting chunk counts
- Data ingestion: Tracks embedding model, vector database details, and document ingestion metrics
- RAG retrieval: Captures retrieval model, context size, and retrieval performance metrics
- RAG evaluation: Logs evaluation metrics (such as answer similarity, correctness, and relevance) and sample results
This visualization provides a clear, end-to-end view of the RAG pipeline’s execution, so you can trace the impact of changes at any stage and achieve full reproducibility. The architecture supports scaling to multiple experiments, each representing a distinct configuration or hypothesis (for example, different chunking strategies, embedding models, or retrieval parameters). MLflow’s experiment UI visualizes these experiments side by side, enabling side-by-side comparison and analysis across runs. This structure is especially valuable in enterprise settings, where dozens or even hundreds of experiments might be conducted to optimize RAG performance.
We use MLflow experimentation throughout the RAG pipeline to log metrics and parameters, and the different experiment runs are initialized as shown in the following code snippet:
RAG pipeline experimentation
The key components of the RAG workflow are ingestion, chunking, retrieval, and evaluation, which we explain in this section. The MLflow dashboard makes it straightforward to visualize and analyze these parameters and metrics, supporting data-driven refinement of the chunking stage within the RAG pipeline.

Data ingestion and preparation
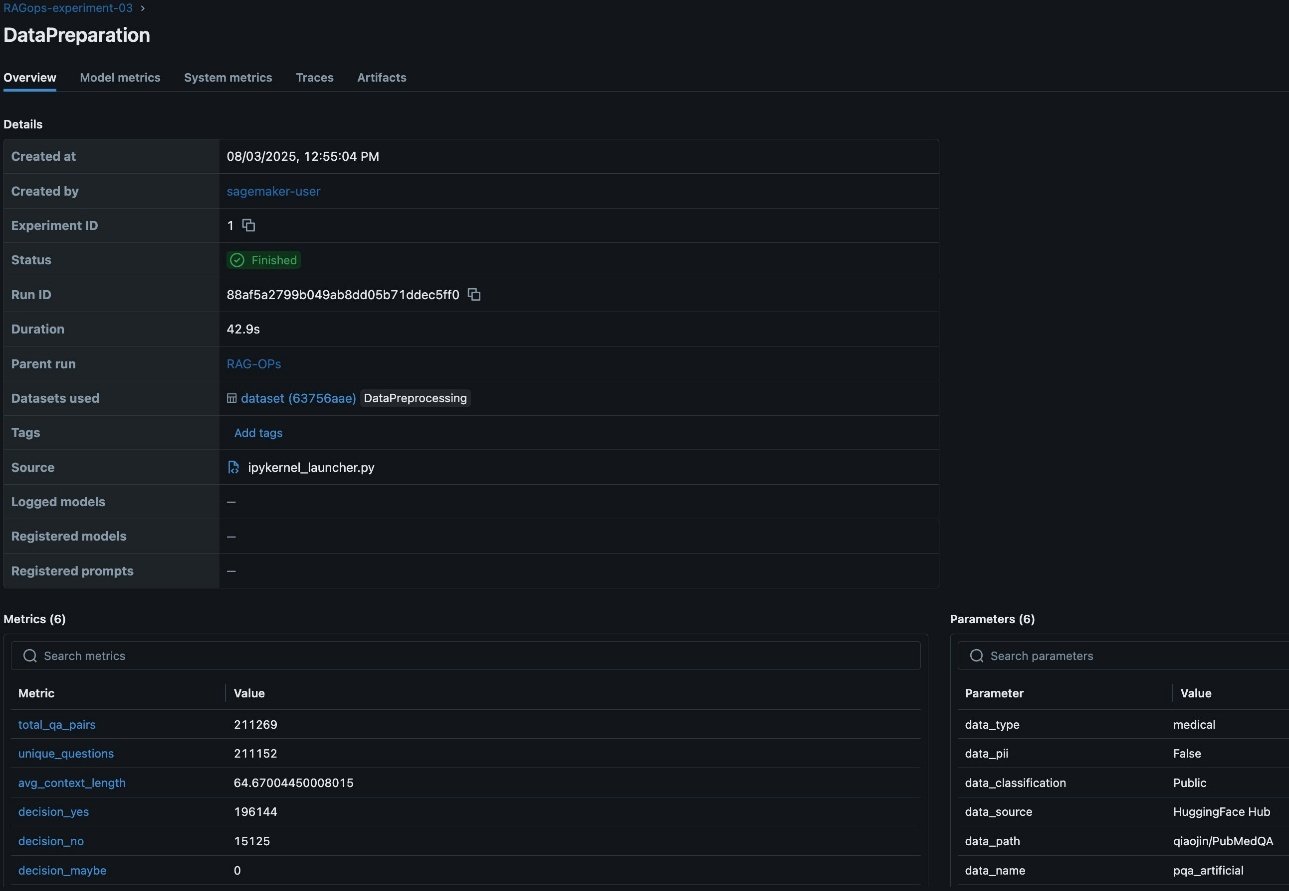
In the RAG workflow, rigorous data preparation is foundational to downstream performance and reliability. Tracking detailed metrics on data quality, such as the total number of question-answer pairs, the count of unique questions, average context length, and initial evaluation predictions, provides essential visibility into the dataset’s structure and suitability for RAG tasks. These metrics help validate the dataset is comprehensive, diverse, and contextually rich, which directly impacts the relevance and accuracy of the RAG system’s responses. Additionally, logging critical RAG parameters like the data source, detected personally identifiable information (PII) types, and data lineage information is vital for maintaining compliance, reproducibility, and trust in enterprise environments. Capturing this metadata in SageMaker managed MLflow supports robust experiment tracking, auditability, efficient comparison, and root cause analysis across multiple data preparation runs, as visualized in the MLflow dashboard. This disciplined approach to data preparation lays the groundwork for effective experimentation, governance, and continuous improvement throughout the RAG pipeline. The following screenshot shows an example of the experiment run details in MLflow.
Data chunking
After data preparation, the next step is to split documents into manageable chunks for efficient embedding and retrieval. This process is pivotal, because the quality and granularity of chunks directly affect the relevance and completeness of answers returned by the RAG system. The RAG workflow in this post supports experimentation and RAG pipeline automation with both fixed-size and recursive chunking strategies for comparison and validations. However, this RAG solution can be expanded to many other chucking techniques.
FixedSizeChunkerdivides text into uniform chunks with configurable overlapRecursiveChunkersplits text along logical boundaries such as paragraphs or sentences
Tracking detailed chunking metrics such as total_source_contexts_entries, total_contexts_chunked, and total_unique_chunks_final is crucial for understanding how much of the source data is represented, how effectively it is segmented, and whether the chunking approach is yielding the desired coverage and uniqueness. These metrics help diagnose issues like excessive duplication or under-segmentation, which can impact retrieval accuracy and model performance.
Additionally, logging parameters such as chunking_strategy_type (for example, FixedSizeChunker), chunking_strategy_chunk_size (for example, 500 characters), and chunking_strategy_chunk_overlap provide transparency and reproducibility for each experiment. Capturing these details in SageMaker managed MLflow helps teams systematically compare the impact of different chunking configurations, optimize for efficiency and contextual relevance, and maintain a clear audit trail of how chunking decisions evolve over time. The MLflow dashboard makes it straightforward to visualize and analyze these parameters and metrics, supporting data-driven refinement of the chunking stage within the RAG pipeline. The following screenshot shows an example of the experiment run details in MLflow.

After the documents are chunked, the next step is to convert these chunks into vector embeddings using a SageMaker embedding endpoint, after which the embeddings are ingested into a vector database such as OpenSearch Service for fast semantic search. This ingestion phase is crucial because the quality, completeness, and traceability of what enters the vector store directly determine the effectiveness and reliability of downstream retrieval and generation stages.
Tracking ingestion metrics such as the number of documents and chunks ingested provides visibility into pipeline throughput and helps identify bottlenecks or data loss early in the process. Logging detailed parameters, including the embedding model ID, endpoint used, and vector database index, is essential for reproducibility and auditability. This metadata helps teams trace exactly which model and infrastructure were used for each ingestion run, supporting root cause analysis and compliance, especially when working with evolving datasets or sensitive information.
Retrieval and generation
For a given query, we generate an embedding and retrieve the top-k relevant chunks from OpenSearch Service. For answer generation, we use a SageMaker LLM endpoint. The retrieved context and the query are combined into a prompt, and the LLM generates an answer. Finally, we orchestrate retrieval and generation using LangGraph, enabling stateful workflows and advanced tracing:
With the GenerativeAI agent defined with LangGraph framework, the agentic layers are evaluated for each iteration of RAG development, verifying the efficacy of the RAG solution for agentic applications. Each retrieval and generation run is logged to SageMaker managed MLflow, capturing the prompt, generated response, and key metrics and parameters such as retrieval performance, top-k values, and the specific model endpoints used. Tracking these details in MLflow is essential for evaluating the effectiveness of the retrieval stage, making sure the returned documents are relevant and that the generated answers are accurate and complete. It is equally important to track the performance of the vector database during retrieval, including metrics like query latency, throughput, and scalability. Monitoring these system-level metrics alongside retrieval relevance and accuracy makes sure the RAG pipeline delivers correct and relevant answers and meets production requirements for responsiveness and scalability. The following screenshot shows an example of the Langraph RAG retrieval tracing in MLflow.

RAG Evaluation
Evaluation is conducted on a curated test set, and results are logged to MLflow for quick comparison and analysis. This helps teams identify the best-performing configurations and iterate toward production-grade solutions. With MLflow you can evaluate the RAG solution with heuristics metrics, content similarity metrics and LLM-as-a-judge. In this post, we evaluate the RAG pipeline using advanced LLM-as-a-judge MLflow metrics (answer similarity, correctness, relevance, faithfulness):
The following screenshot shows an RAG evaluation stage experiment run details in MLflow.

You can use MLflow to log all metrics and parameters, enabling quick comparison of different experiment runs. See the following code for reference:
By using MLflow’s evaluation capabilities (such as mlflow.evaluate()), teams can systematically assess retrieval quality, identify potential gaps or misalignments in chunking or embedding strategies, and compare the performance of different retrieval and generation configurations. MLflow’s flexibility allows for seamless integration with external libraries and evaluation libraries such as RAGAS for comprehensive RAG pipeline assessment. RAGAS is an open source library that provide tools specifically for evaluation of LLM applications and generative AI agents. RAGAS includes the method ragas.evaluate() to run evaluations for LLM agents with the choice of LLM models (evaluators) for scoring the evaluation, and an extensive list of default metrics. To incorporate RAGAS metrics into your MLflow experiments, refer to the following GitHub repository.
Comparing experiments
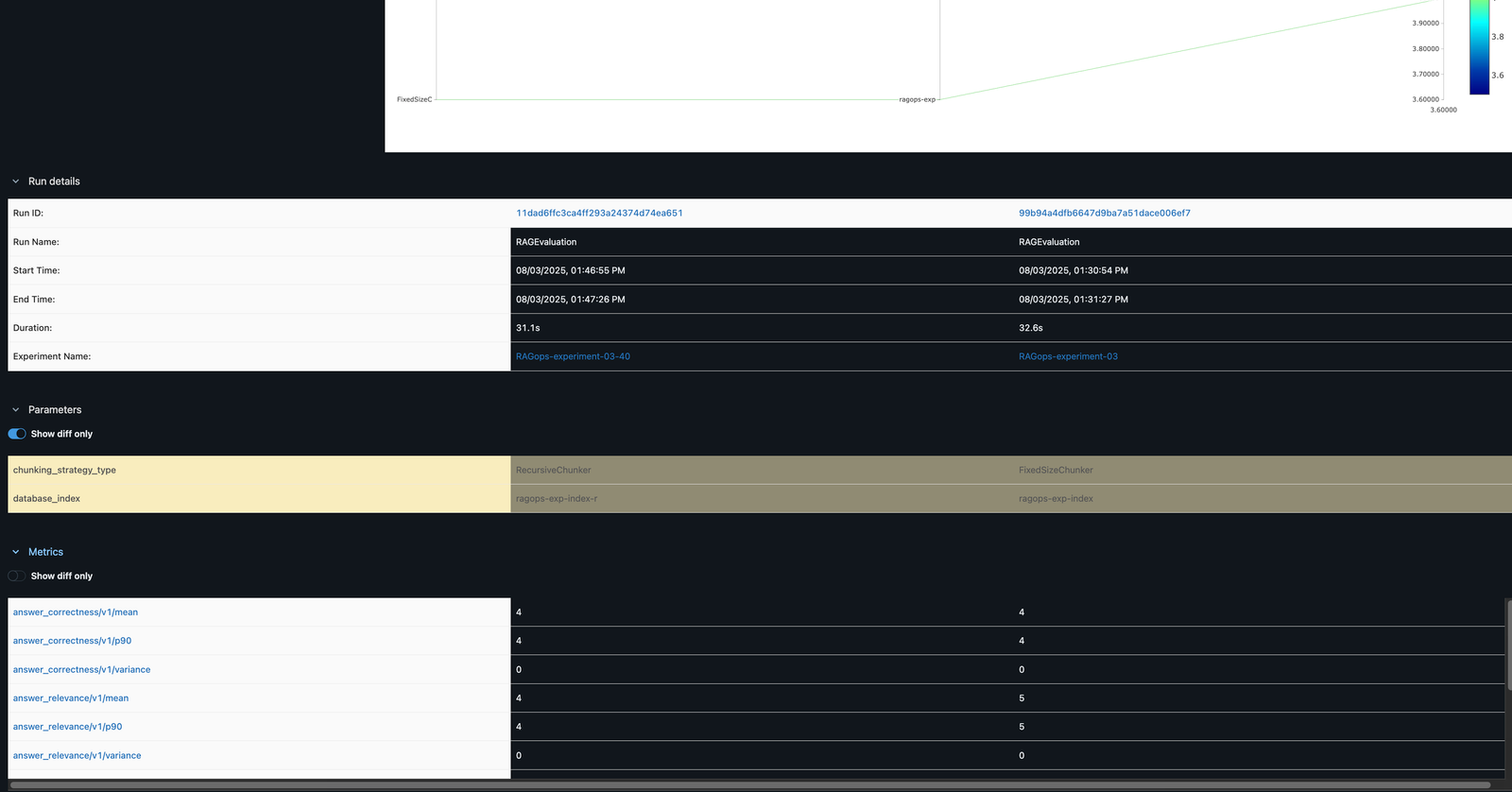
In the MLflow UI, you can compare runs side by side. For example, comparing FixedSizeChunker and RecursiveChunker as shown in the following screenshot reveals differences in metrics such as answer_similarity (a difference of 1 point), providing actionable insights for pipeline optimization.
Automation with Amazon SageMaker pipelines
After systematically experimenting with and optimizing each component of the RAG workflow through SageMaker managed MLflow, the next step is transforming these validated configurations into production-ready automated pipelines. Although MLflow experiments help identify the optimal combination of chunking strategies, embedding models, and retrieval parameters, manually reproducing these configurations across environments can be error-prone and inefficient.
To produce the automated RAG pipeline, we use SageMaker Pipelines, which helps teams codify their experimentally validated RAG workflows into automated, repeatable pipelines that maintain consistency from development through production. By converting the successful MLflow experiments into pipeline definitions, teams can make sure the exact same chunking, embedding, retrieval, and evaluation steps that performed well in testing are reliably reproduced in production environments.
SageMaker Pipelines offers a serverless workflow orchestration for converting experimental notebook code into a production-grade pipeline, versioning and tracking pipeline configurations alongside MLflow experiments, and automating the end-to-end RAG workflow. The automated Sagemaker pipeline-based RAG workflow offers dependency management, comprehensive custom testing and validation before production deployment, and CI/CD integration for automated pipeline promotion.
With SageMaker Pipelines, you can automate your entire RAG workflow, from data preparation to evaluation, as reusable, parameterized pipeline definitions. This provides the following benefits:
- Reproducibility – Pipeline definitions capture all dependencies, configurations, and executions logic in version-controlled code
- Parameterization – Key RAG parameters (chunk sizes, model endpoints, retrieval settings) can be quickly modified between runs
- Monitoring – Pipeline executions provide detailed logs and metrics for each step
- Governance – Built-in lineage tracking supports full audibility of data and model artifacts
- Customization – Serverless workflow orchestration is customizable to your unique enterprise landscape, with scalable infrastructure and flexibility with instances optimized for CPU, GPU, or memory-intensive tasks, memory configuration, and concurrency optimization
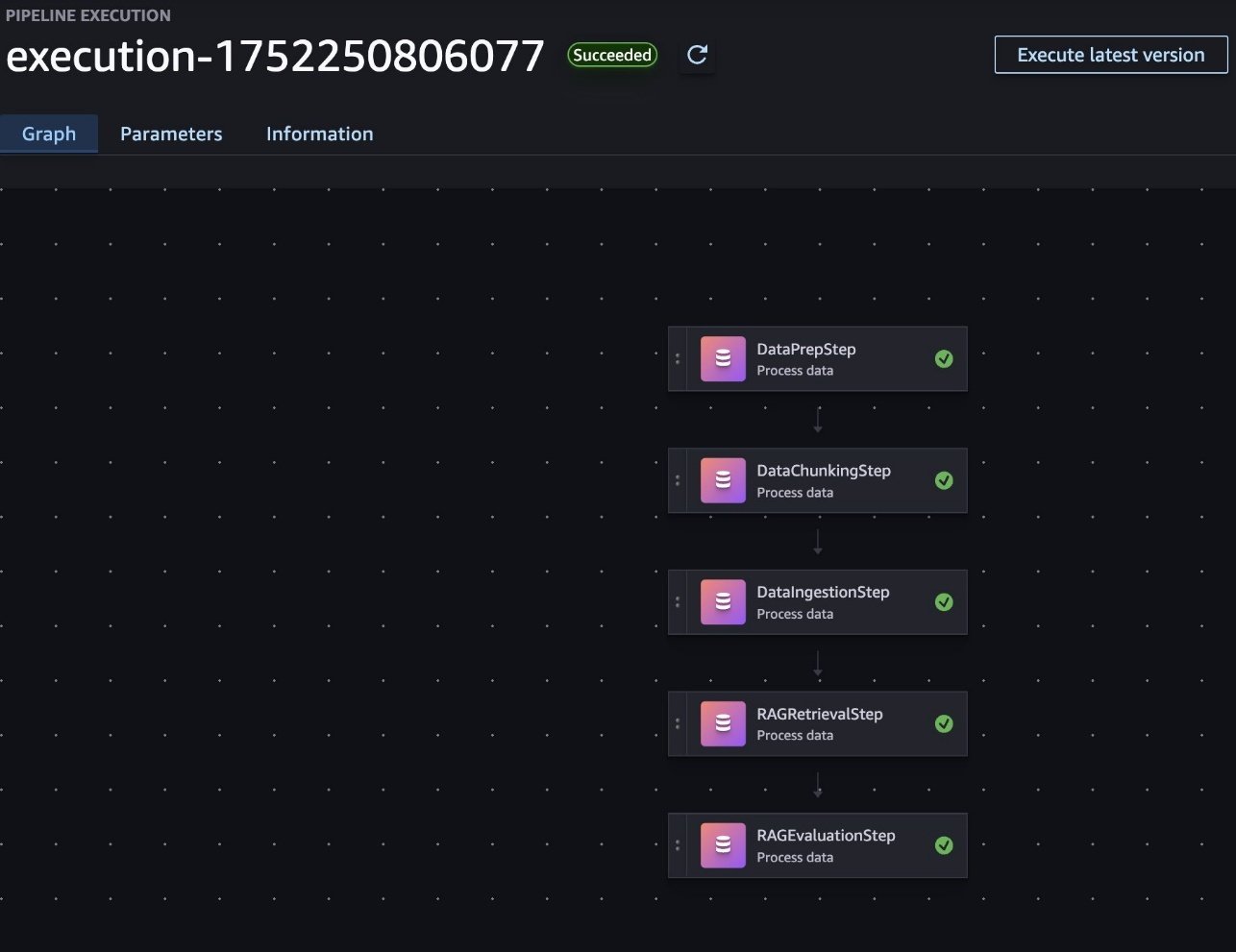
To implement a RAG workflow in SageMaker pipelines, each major component of the RAG process (data preparation, chunking, ingestion, retrieval and generation, and evaluation) is included in a SageMaker processing job. These jobs are then orchestrated as steps within a pipeline, with data flowing between them, as shown in the following screenshot. This structure allows for modular development, quick debugging, and the ability to reuse components across different pipeline configurations.
The key RAG configurations are exposed as pipeline parameters, enabling flexible experimentation with minimal code changes. For example, the following code snippets showcase the modifiable parameters for RAG configurations, which can be used as pipeline configurations:
In this post, we provide two agentic RAG pipeline automation approaches to building the SageMaker pipeline, each with own benefits: single-step SageMaker pipelines and multi-step pipelines.
The single-step pipeline approach is designed for simplicity, running the entire RAG workflow as one unified process. This setup is ideal for straightforward or less complex use cases, because it minimizes pipeline management overhead. With fewer steps, the pipeline can start quickly, benefitting from reduced execution times and streamlined development. This makes it a practical option when rapid iteration and ease of use are the primary concerns.
The multi-step pipeline approach is preferred for enterprise scenarios where flexibility and modularity are essential. By breaking down the RAG process into distinct, manageable stages, organizations gain the ability to customize, swap, or extend individual components as needs evolve. This design enables plug-and-play adaptability, making it straightforward to reuse or reconfigure pipeline steps for various workflows. Additionally, the multi-step format allows for granular monitoring and troubleshooting at each stage, providing detailed insights into performance and facilitating robust enterprise management. For enterprises seeking maximum flexibility and the ability to tailor automation to unique requirements, the multi-step pipeline approach is the superior choice.
CI/CD for an agentic RAG pipeline
Now we integrate the SageMaker RAG pipeline with CI/CD. CI/CD is important for making a RAG solution enterprise-ready because it provides faster, more reliable, and scalable delivery of AI-powered workflows. Specifically for enterprises, CI/CD pipelines automate the integration, testing, deployment, and monitoring of changes in the RAG system, which brings several key benefits, such as faster and more reliable updates, version control and traceability, consistency across environments, modularity and flexibility for customization, enhanced collaboration and monitoring, risk mitigation, and cost savings. This aligns with general CI/CD benefits in software and AI systems, emphasizing automation, quality assurance, collaboration, and continuous feedback essential to enterprise AI readiness.
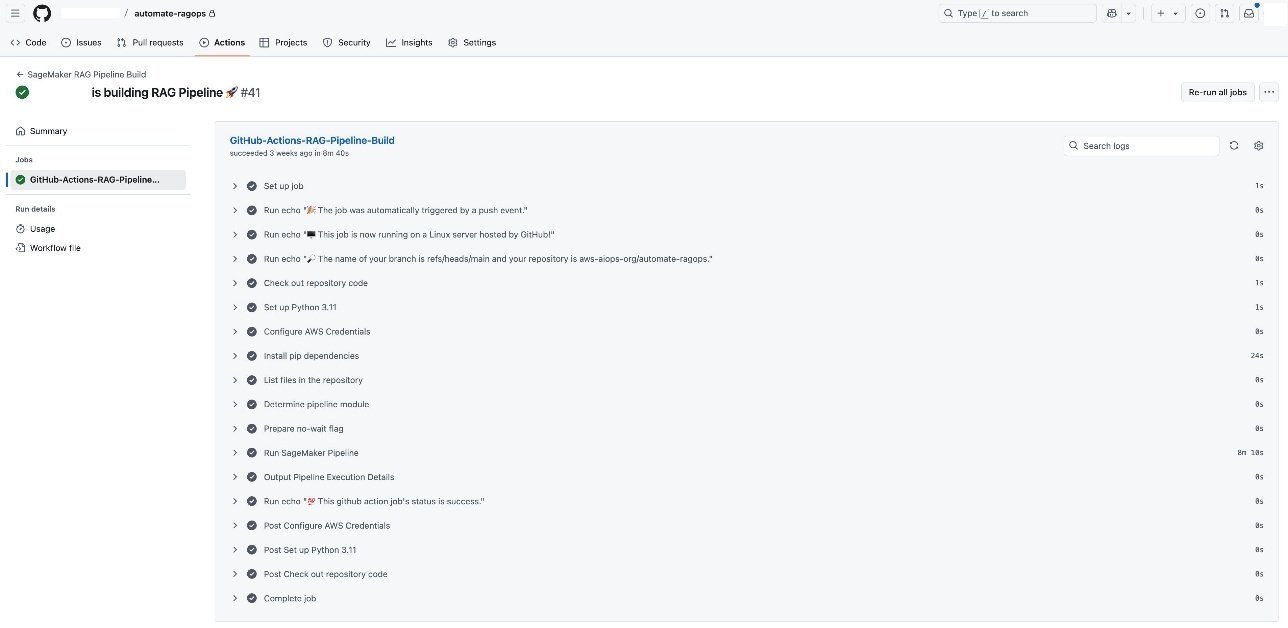
When your SageMaker RAG pipeline definition is in place, you can implement robust CI/CD practices by integrating your development workflow and toolsets already enabled at your enterprise. This setup makes it possible to automate code promotion, pipeline deployment, and model experimentation through simple Git triggers, so changes are versioned, tested, and systematically promoted across environments. For demonstration, in this post, we show the CI/CD integration using GitHub Actions and by using GitHub Actions as the CI/CD orchestrator. Each code change, such as refining chunking strategies or updating pipeline steps, triggers an end-to-end automation workflow, as shown in the following screenshot. You can use the same CI/CD pattern with your choice of CI/CD tool instead of GitHub Actions, if needed.
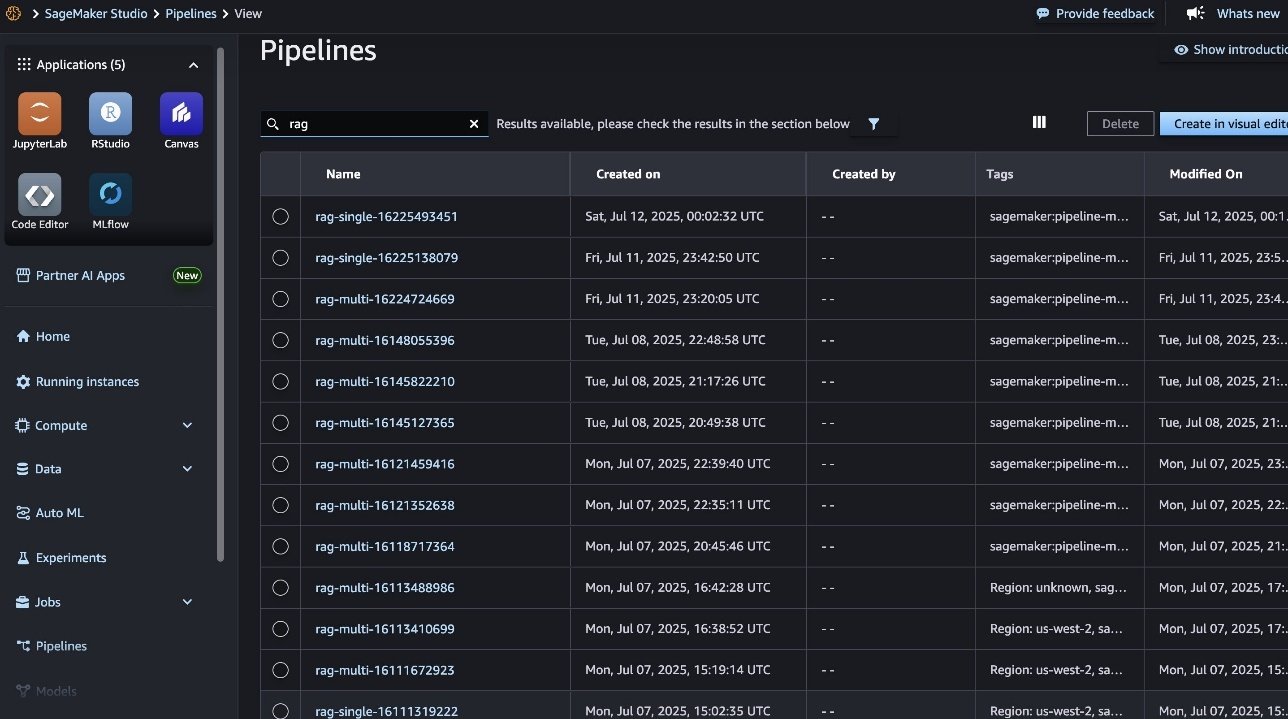
Each GitHub Actions CI/CD execution automatically triggers the SageMaker pipeline (shown in the following screenshot), allowing for seamless scaling of serverless compute infrastructure.
Throughout this cycle, SageMaker managed MLflow records every executed pipeline (shown in the following screenshot), so you can seamlessly review results, compare performance across different pipeline runs, and manage the RAG lifecycle.
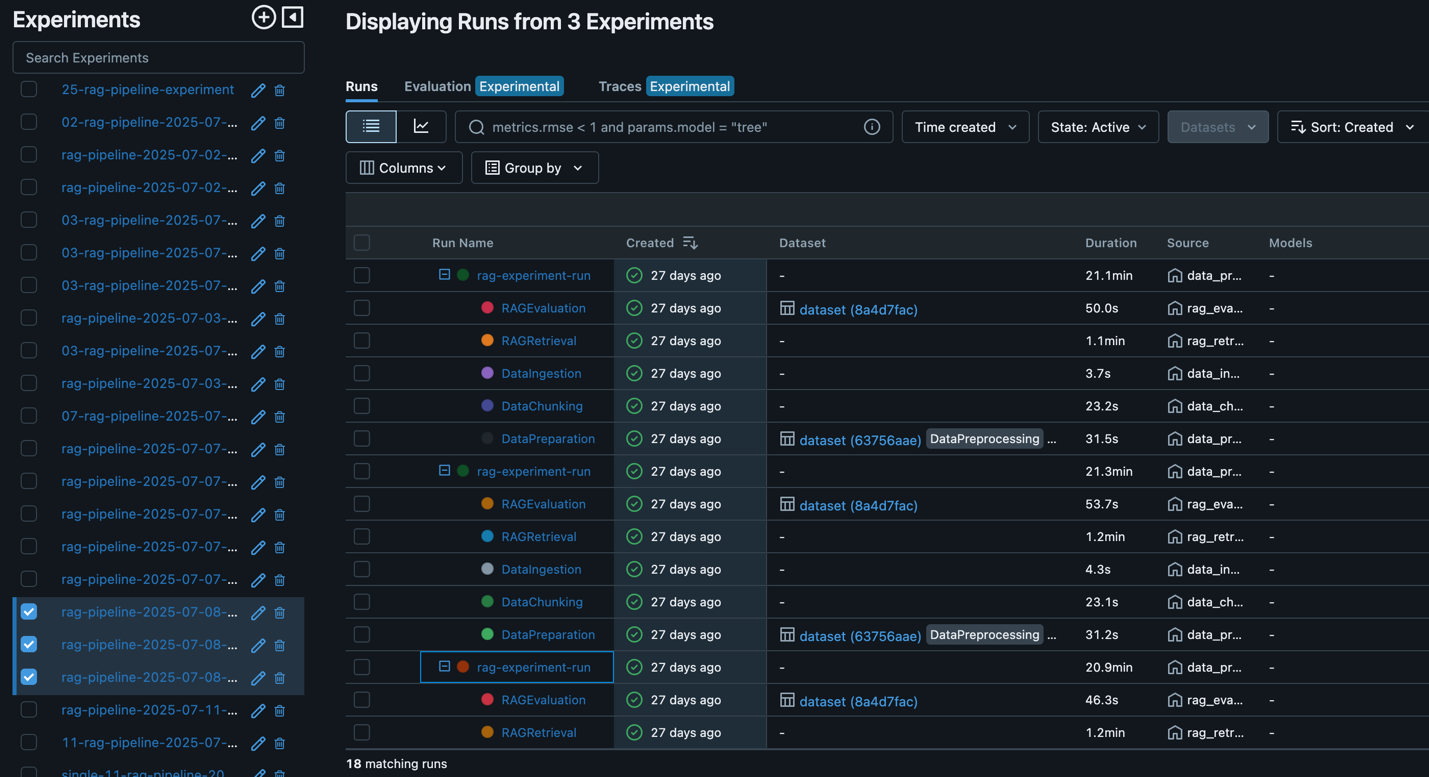
After an optimal RAG pipeline configuration is determined, the new desired configuration (Git version tracking captured in MLflow as shown in the following screenshot) can be promoted to higher stages or environments directly through an automated workflow, minimizing manual intervention and reducing risk.

Clean up
To avoid unnecessary costs, delete resources such as the SageMaker managed MLflow tracking server, SageMaker pipelines, and SageMaker endpoints when your RAG experimentation is complete. You can visit the SageMaker Studio console to destroy resources that aren’t needed anymore or call appropriate AWS APIs actions.
Conclusion
By integrating SageMaker AI, SageMaker managed MLflow, and Amazon OpenSearch Service, you can build, evaluate, and deploy RAG pipelines at scale. This approach provides the following benefits:
- Automated and reproducible workflows with SageMaker Pipelines and MLflow, minimizing manual steps and reducing the risk of human error
- Advanced experiment tracking and comparison for different chunking strategies, embedding models, and LLMs, so every configuration is logged, analyzed, and reproducible
- Actionable insights from both traditional and LLM-based evaluation metrics, helping teams make data-driven improvements at every stage
- Seamless deployment to production environments, with automated promotion of validated pipelines and robust governance throughout the workflow
Automating your RAG pipeline with SageMaker Pipelines brings additional benefits: it enables consistent, version-controlled deployments across environments, supports collaboration through modular, parameterized workflows, and supports full traceability and auditability of data, models, and results. With built-in CI/CD capabilities, you can confidently promote your entire RAG solution from experimentation to production, knowing that each stage meets quality and compliance standards.
Now it’s your turn to operationalize RAG workflows and accelerate your AI initiatives. Explore SageMaker Pipelines and managed MLflow using the solution from the GitHub repository to unlock scalable, automated, and enterprise-grade RAG solutions.
About the authors
 Sandeep Raveesh is a GenAI Specialist Solutions Architect at AWS. He works with customers through their AIOps journey across model training, generative AI applications like agents, and scaling generative AI use cases. He also focuses on Go-To-Market strategies, helping AWS build and align products to solve industry challenges in the generative AI space. You can find Sandeep on LinkedIn.
Sandeep Raveesh is a GenAI Specialist Solutions Architect at AWS. He works with customers through their AIOps journey across model training, generative AI applications like agents, and scaling generative AI use cases. He also focuses on Go-To-Market strategies, helping AWS build and align products to solve industry challenges in the generative AI space. You can find Sandeep on LinkedIn.
 Blake Shin is an Associate Specialist Solutions Architect at AWS who enjoys learning about and working with new AI/ML technologies. In his free time, Blake enjoys exploring the city and playing music.
Blake Shin is an Associate Specialist Solutions Architect at AWS who enjoys learning about and working with new AI/ML technologies. In his free time, Blake enjoys exploring the city and playing music.
-

 Business2 weeks ago
Business2 weeks agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-
Tools & Platforms1 month ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy2 months ago
Ethics & Policy2 months agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences4 months ago
Events & Conferences4 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers3 months ago
Jobs & Careers3 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Education3 months ago
Education3 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Education2 months ago
Education2 months agoMacron says UK and France have duty to tackle illegal migration ‘with humanity, solidarity and firmness’ – UK politics live | Politics
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi
-

 Funding & Business3 months ago
Funding & Business3 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries