AI Insights
On-device AI for climate-resilient farming with intelligent crop yield prediction using lightweight models on smart agricultural devices
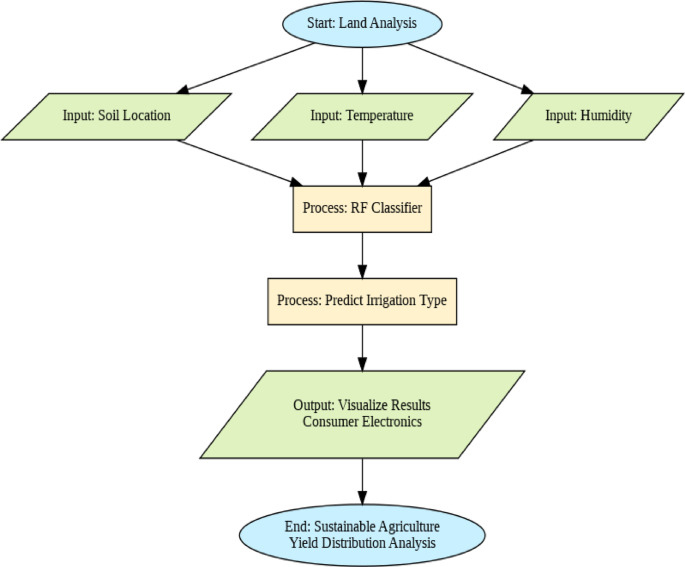
The proposed smart agriculture system integrates agricultural consumer electronics, machine learning models and the sensor data processing to optimize crop yield for sustainable agriculture. The data flow of the proposed model is shown in Fig. 2.
Stages involved in the projected technique to achieve Sustainable agriculture using consumer electronics.
Step 1 The Initial data are processed related to Rainfall (R), Temp as (T), Soil moisture as (S_moi), Soil type as (S_t), humidity as H, Soil as S and y as Yield in Irrigation process, Location as l to sustainable agriculture as (SA) and consumer electronics as (CEd) where 1 < y < SA.
Step 2 Data Preprocessing layer works to normalize the numeric values in T, encode categorical value in S_moi, and finally to ensure T = S_moi.L where y/S_t (CEd).The primary activities on the dataset like removal of missing values, handling of inconsistent values and feature selection are done in this layer.
Step 3 The model is trained with historical environmental data and irrigation methods using machine learning classifier RF (random forest) to rank the feature for 1 < y < SA.
Step 4 The intelligent decision making with RF ensures optimal water utilization and reduces the waste with entropy towards y/S_t (CEd).
Step 5 The trained model is implemented in the agricultural consumer electronics like smart devices related to y = L. A dashboard visualization method is prepared to check the performance of the system like irrigation status and other environmental impacts through CEd.
Step 6 Finally, the yield distribution and sustainable agriculture are achieved with the deployment and monitoring through consumer electronics with y/S_t (CEd).
System model
Let us assume, X is the feature set and y is the target irrigation class. Then, the dataset will be expressed as follows (1).
$$X = \left\{ {R, T_{emp} , S_{moi} , S_{t} , H, S, A} \right\} y = I$$
(1)
where R is rainfall precipitation intensity, \(T_{emp}\) is temperature recorded daily for analysing crop-based farming, \(S_{moi} ,\) is soil moisture to analyse the water content in the farm land, \(S_{t} ,\) is soil type , \(H\) is humidity in atmospheric condition, \(S\) is the season for the kind of crops to perform plantation like rabi, kharif , \(A\) is Area cultivated total plot size and finally, I is Irrigation type with different class drip, basin and spray .
The linear operator which includes the dataset is defined as follows (2).
$$R_{i} = \mathop \sum \limits_{i} \left( R \right)\left( {x_{i} } \right)$$
(2)
where \(R_{i}\) is the average rainfall index for water availability measure, \(x_{i}\) is the weight factor for normalization and \(R,\) is the Aggregator operator.
Since the dataset collection is an analogue process, the continuous setting integral operator kernel transformation can be defined as (3).
$$R_{f} = \mathop \smallint \limits_{0}^{m} k_{a} \left( {p,q} \right) R_{i}$$
(3)
where \(k_{a} \left( {p,q} \right)\) is Gaussian kernel, \(m\) is the window size for some days and \(p,q\) are Spatial analyses with latitude and longitude.
As the dataset is classified into subsets, there is a condition for measures. All measurable subsets include T_emp of S_moi, and H and A as in Eq. (4). It can also be referred as group invariant measure to get the desired output. As this function follows the covariance, this Eq. (4) can be modified as follows (5) and (6).
$$\mu_{m} \left( {T_{emp} .H} \right) = \mu_{m} \left( {S_{moi} .A} \right)$$
(4)
$$\mu_{m} \left( {T_{emp} .H} \right) = \mu \left( {T_{emp} } \right). \mu \left( H \right)$$
(5)
$$\mu_{m} \left( {S_{moi} .A} \right) = \mu \left( {S_{emoi} . \mu \left( A \right)} \right)$$
(6)
where \(\mu_{m}\) is covariance Feature for probability measure, \(T_{emp}\) is temperature recorded daily for analysing crop-based farming, \(S_{moi} ,\) is soil moisture to analyse the water content in the farm land, \(H\) refers to the humidity in atmospheric condition, \(A\) represents Area cultivated total plot size, \(\mu \left( H \right)\) is the humidity distribution and \(\mu \left( A \right)\) refers to area distribution.
As the dataset contains both categorical and numerical data fields, equivalent linear operators are required to collect the majority of the decisions from various sub trees (7).
$$H\left( {g.f} \right) = g.Hf$$
(7)
where H is the Decision tree class hierarchy, \(g\) is the feature subspace projection and \(f\) is the predictor function.
The decisions of the sub trees are based on the influencing parameters like temperature, soil moisture, humidity, location and etc.38. It is assumed that the temperature of the location will affect the soil moisture and hence, the equivalent linear operator is expressed as follows (8).
$$X_{m} \left( {T_{emp} .S_{moi} } \right) = T_{emp} \left( {p,q} \right) . S_{moi} \left( {p,q} \right)$$
(8)
where \(X_{m}\) is the critical threshold for irrigation demand identification and capture non-linear temperature.
The model is trained with 100 estimators, and its performances are evaluated based on accuracy, feature importance and confusion matrix analysis. The random forest function is given as (9).
$$f \left( X \right) = \frac{1 }{n}\mathop \sum \limits_{i = 1}^{n} h_{i} \left( X \right)$$
(9)
where n is an optimized decision for out of bag error handling and \(h_{i}\) is an individual tree for some depth.
where n represents the number of decision trees, and gini (X) is the decision of each subtree. Based on this, gini impurity value is calculated 39. It is the criteria where the decision trees use splitting threshold less than 0.2 (10).
$$Gini \left( X \right) = 1 – \mathop \sum \limits_{i = 1}^{c} p_{i}^{2}$$
(10)
where pi is the probability of class i in the dataset X, and c represents the number of classes.
Like Gini index, the Entropy value is also calculated to understand the non-homogeneity of the data 40. It is the measure of homogeneity of the dataset and it returns the information about the impurity of the dataset. The entropy is expressed as follows (11).
$$Entropy S = – \left( {P\log_{2} P + N\log_{2} N} \right)$$
(11)
where P is the number of positive or correct samples and N is the number of negative or wrong samples.
From the entropy value, the information gain is calculated as follows (12).
$$Gain = Entropy – \mathop \sum \limits_{values} \frac{{|S_{v} |}}{\left| S \right|} Entropy \left( {S_{v} } \right)$$
(12)
where Sv is the subset of S with minimum gain 0.01bits.
Finally, the accuracy score and the confusion matrix are used to assess the performance of the model. Feature importance is plotted to determine the most influential factors in irrigation prediction (13).
$$Accuracy = \frac{TP + TN}{{TP + TN + FP + FN}}$$
(13)
where TP is the True positive, TN denotes True negative, FP denotes Falso positive and FN denotes False negative.
Algorithm for the proposed model
The following algorithm depicts the proposed model of random forest classifier.

Intelligent irrigation prediction.
Class imbalance handling
The dataset used in this research contains the basic environmental factors like location, rainfall (R), temperature (temp), soil moisture (Smoi), humidity (H), season (S) and the area (A). The class imbalance is addressed through irrigation type identification, including drip, spray, and basin. Three functions are used to handle the class imbalance. The first one is stratified sampling and it is used to split the dataset as 70:30 for testing and training. After the class distribution is processed, second-class weighted RF is assigned for higher weights to split the minority classes and it is proportional to the weights and irrigation class frequencies. Finally, the third method, synthetic minority oversampling, is used to prevent data leakage with different irrigation samples, such as drip, spray, and basin. All these methods improve the irrigation class accuracy score by handling class imbalance in the agricultural dataset for minority crop yield distribution classes. The proposed model inverse frequency weighting increases irrigation detection by reducing false negatives in precision water management in high-temperature areas.

















Tesla Inc.’s long-awaited entry into India has delivered underwhelming results so far, with tepid bookings fueling fresh doubts about the company’s global growth outlook.
Source link

This is my final “bench to bot” column, and after more than two years of exploring the role of artificial intelligence in scientific writing, I find myself in an unexpected place. When I started this series in 2023, I wasn’t among the breathless AI optimists promising revolutionary transformation, nor was I reflexively dismissive of its potential. I approached these tools with significant reservations about their broader societal impacts, but I was curious whether they might offer genuine value for scientific communication specifically.
What strikes me now, looking back, is how my measured optimism for science may have caused me to underestimate the deeper complications at play. The problem is not that the tools don’t work—it’s that they work too well, at least at producing competent prose. But competent prose generated by a machine, I’ve come to realize, might not be what science actually needs.
My initial set of starting assumptions seemed reasonable. The purpose of neuroscience isn’t getting award-winning grants and publishing high-profile papers. It’s the production of knowledge, technology and treatments. But scientists spend enormous amounts of time wrestling with grants and manuscripts. If AI could serve as a strategic aid for specific writing tasks, helping scientists overcome time-consuming communication bottlenecks, I was all for it. What’s more, writing abilities aren’t equally distributed, which potentially disadvantages brilliant researchers who struggle with prose. AI could help here, too. So long as I remained explicit about claiming AI would not solve all writing troubles, and my goal was always thoughtful incorporation for targeted use cases, not mindless adoption, I felt this column would be a worthwhile service for the community struggling with how to handle this seismic technological shift.
These assumptions felt solid when I started this column. But if I’m being honest, I’ve always harbored some nagging reservations that even thoughtful incorporation of AI tools in scientific writing tasks carries risks I wasn’t fully acknowledging—perhaps even to myself. Recently, I encountered a piece by computer scientists Sayash Kapoor and Arvind Narayanan that articulated those inchoate doubts better than I ever could. They argue that AI might actually slow scientific progress—not despite its efficiency gains but because of them:
Any serious attempt to forecast the impact of AI on science must confront the production-progress paradox. The rate of publication of scientific papers has been growing exponentially, increasing 500 fold between 1900 and 2015. But actual progress, by any available measure, has been constant or even slowing. So we must ask how AI is impacting, and will impact, the factors that have led to this disconnect.
Our analysis in this essay suggests that AI is likely to worsen the gap. This may not be true in all scientific fields, and it is certainly not a foregone conclusion. By carefully and urgently taking actions such as those we suggest below, it may be possible to reverse course. Unfortunately, AI companies, science funders, and policy makers all seem oblivious to what the actual bottlenecks to scientific progress are. They are simply trying to accelerate production, which is like adding lanes to a highway when the slowdown is actually caused by a toll booth. It’s sure to make things worse.
Though Kapoor and Narayanan focus on AI’s broader impact on science, their concerns about turbo-charging production without improving the underlying process echo what economist Robert Solow observed decades ago about computers—we see them everywhere except in the productivity statistics. This dynamic maps directly onto scientific writing in troubling ways.
T
he truth is that the process of writing often matters just as much, or more, than the final product. I explored this issue in my column on teaching and AI, but the idea applies to anyone who writes, because we often write to learn, or, at least, we learn while we write. When scientists struggle to explain their methodology clearly, they might discover gaps in their own understanding. When they wrestle with articulating why their particular approach matters, they might uncover new connections or refine their hypotheses. Stress-testing ideas with the pressure of the page is a time-honored way to deepen thinking. I suspect countless private struggles with writing have served as quiet engines of scientific discovery. Neuroscientist Eve Marder seems to recognize this cognitive value, putting it beautifully:
But most importantly, writing is the medium that allows you to explain, for all time, your new discoveries. It should not be a chore, but an opportunity to share your excitement, and maybe your befuddlement. It allows each of us to add to and modify the conceptual frameworks that guide the way we understand our science and the world…It is not an accident that some of our best and most influential scientists write elegant and well-crafted papers. So, work to make writing one of the great pleasures of your life as a scientist, and your science will benefit.
Previously, my hope was that with the newfound technological ability to decouple sophisticated text production from human struggle, it would start to become clear which parts of the writing struggle are valuable versus which are just pure cognitive drag. However, two years in, I don’t think anyone is any closer to an answer. And I’m realizing through observations of students, colleagues—and myself—that each of us individually is not going to be capable of making that distinction in real time during the heat of composition, the pressure of deadlines and the seductiveness of slick technology.
Rather than offering a set of rules about when to use these tools, perhaps the most honest guidance I can provide is this: Before reaching for AI assistance, pause and ask yourself whether you’re trying to clarify your thinking or simply produce text. If the process matters, or just the product. If it’s the former—if you’re genuinely wrestling with how to explain a concept or articulate why your approach matters—that struggle might be worth preserving. The discomfort of not knowing quite how to say something is often an important signal that you’re at the edge of your understanding, perhaps about to break into new territory. The scientists who do the most exciting and meaningful work in an AI-saturated future won’t be those who can efficiently generate passable grants and manuscripts but those who respect this signal and recognize when the struggle of writing is actually the struggle of discovery in disguise.
The stakes are actually quite high for science, because writing, for all its flaws, is one of the most potent thinking tools humans have developed. When I think of the role of writing in the production-progress paradox, I keep returning to something neuroscientist Henry Markram told me years ago: “I realized that I could write a high-profile research paper every year, but then what? I die, and there’s going to be a column on my grave with a list of beautiful papers.” With AI, we scientists risk optimizing our way to beautiful papers while fundamental progress in neuroscience remains stalled. We might end up with impressive publication lists as we die from the diseases we failed to cure.
The path forward means acknowledging that efficiency isn’t always progress, that removing friction isn’t always improvement, and that tools designed to make us more productive might sometimes make us less capable. These tensions won’t resolve themselves, and perhaps that’s the point. The act of recognizing such tensions, of constantly questioning whether science’s technological shortcuts are serving its deeper intellectual goals, may itself be a form of progress. It’s a more complex message than the one I started with, but complexity is often where the truth lives.
AI-use statement: Anthropic’s Claude Sonnet 4 was used for editorial feedback after the drafting process.

Japanese Bitcoin treasury Metaplanet Inc. secured shareholder approval for a proposal enabling it to raise as much as ¥555 billion ($3.8 billion) via preferred shares, in a bid to expand its financing options after its stock slumped.
Source link
-

 Business4 days ago
Business4 days agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-
Tools & Platforms3 weeks ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy1 month ago
Ethics & Policy1 month agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences3 months ago
Events & Conferences3 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers2 months ago
Jobs & Careers2 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Funding & Business2 months ago
Funding & Business2 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries
-

 Education2 months ago
Education2 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Education2 months ago
Education2 months agoAERDF highlights the latest PreK-12 discoveries and inventions
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi