Jobs & Careers
Leveraging Pandas and SQL Together for Efficient Data Analysis

 Image by Author | Canva
Image by Author | CanvaPandas and SQL are both effective for data analysis, but what if we could merge their power? With pandasql, you can write SQL queries directly within a Jupyter notebook. This integration seamlessly enables us to blend SQL logic with Python for effective data analysis.
In this article, we will use both pandas and SQL together on a data project from Uber. Let’s get started!
# What Is pandasql?
Pandasql can be integrated with any DataFrame through an in-memory SQLite engine, so you can write pure SQL inside a Python environment.
# Advantages of Using Pandas and SQL Together
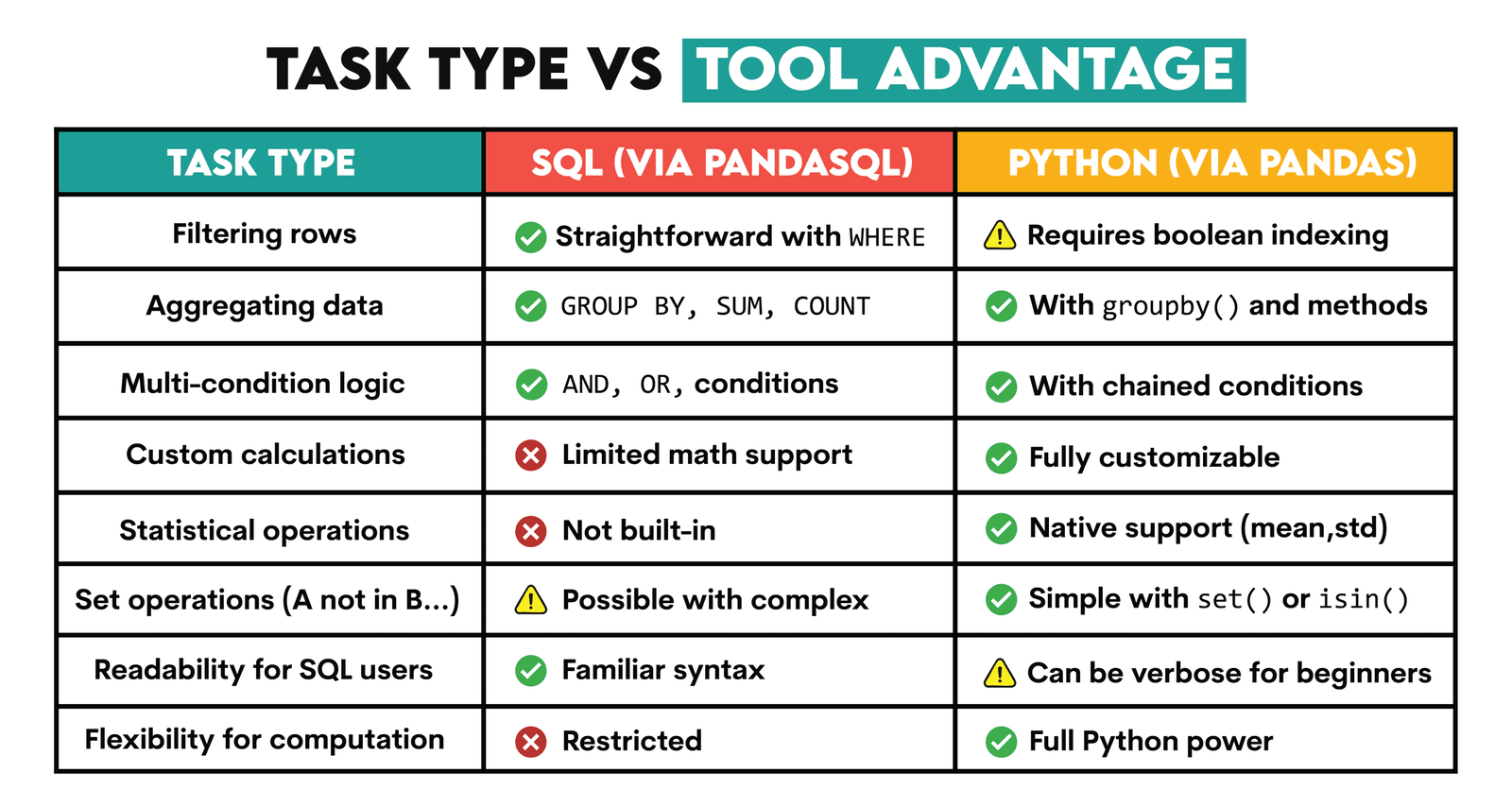
SQL is useful for easily filtering rows, aggregating data, or applying multi-condition logic.
Python, on the other hand, offers advanced tools for statistical analysis and custom computations, as well as set-based operations, which extend beyond SQL’s capabilities.
When used together, SQL simplifies data selection, while Python adds analytical flexibility.
# How to Run pandasql Inside a Jupyter Notebook?
To run pandasql inside a Jupyter Notebook, start with the following code.
import pandas as pd
from pandasql import sqldf
run = lambda q: sqldf(q, globals())
Next, you can run your SQL code like this:
run("""
SELECT *
FROM df
LIMIT 10;
""")
We will use the SQL code without showing the run function each time in this article.

Let’s see how using SQL and Pandas together works in a real-life project from Uber.
# Real-World Project: Analyzing Uber Driver Performance Data
Image by Author
In this data project, Uber asks us to analyze driver performance data and evaluate bonus strategies.
// Data Exploration and Analytics
Now, let’s explore the datasets. First, we will load the data.
// Initial Dataset Loading
Let’s load the dataset by using just pandas.
import pandas as pd
import numpy as np
df = pd.read_csv('dataset_2.csv')
// Exploring the Data
Now let’s review the dataset.
The output looks like this:
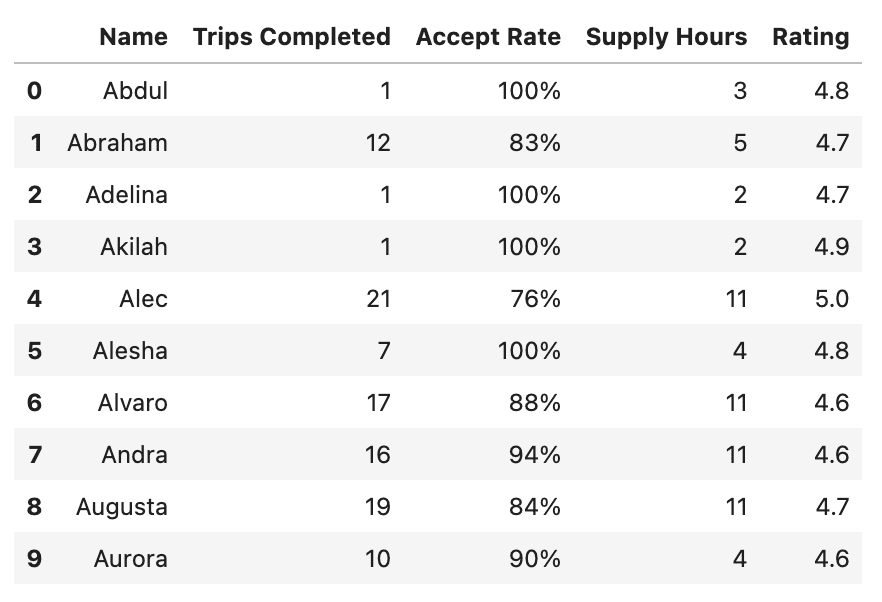
Now we have a glimpse of the data.
As you can see, the dataset includes each driver’s name, the number of trips they completed, their acceptance rate (i.e., the percentage of trip requests accepted), total supply hours (the total hours spent online), and their average rating.
Let’s verify the column names before starting the data analysis so we can use them correctly.
Here is the output.

As you can see, our dataset has five different columns, and there are no missing values.
Let’s now answer the questions using both SQL and Python.
# Question 1: Who Qualifies for Bonus Option 1?
In the first question, we are asked to determine the total bonus payout for Option 1, which is:
$50 for each driver that is online at least 8 hours, accepts 90% of requests, completes 10 trips, and has a rating of 4.7 or better during the time frame.
// Step 1: Filtering the Qualifying Drivers with SQL (pandasql)
In this step, we will start using pandasql.
In the following code, we have selected all drivers who meet the conditions for the Option 1 bonus using the WHERE clause and the AND operator for linking multiple conditions. To learn how to use WHERE and AND, refer to this documentation.
opt1_eligible = run("""
SELECT Name -- keep only a name column for clarity
FROM df
WHERE `Supply Hours` >= 8
AND `Trips Completed` >= 10
AND `Accept Rate` >= 90
AND Rating >= 4.7;
""")
opt1_eligible
Here is the output.

// Step 2: Finishing in Pandas
After filtering the dataset using SQL with pandasql, we switch to Pandas to perform numerical calculations and finalize the analysis. This hybrid technique, which combines SQL and Python, enhances both readability and flexibility.
Next, using the following Python code, we calculate the total payout by multiplying the number of qualified drivers (using len()) by the $50 bonus per driver. Check out the documentation to see how you can use the len() function.
payout_opt1 = 50 * len(opt1_eligible)
print(f"Option 1 payout: ${payout_opt1:,}")
Here is the output.
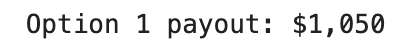
# Question 2: Calculating the Total Payout for Bonus Option 2
In the second question, we are asked to find the total bonus payout using Option 2:
$4/trip for all drivers who complete 12 trips, and have a 4.7 or better rating.
// Step 1: Filtering the Qualifying Drivers with SQL (pandasql)
First, we use SQL to filter for drivers who meet the Option 2 criteria: completing at least 12 trips and maintaining a rating of 4.7 or higher.
# Grab only the rows that satisfy the Option-2 thresholds
opt2_drivers = run("""
SELECT Name,
`Trips Completed`
FROM df
WHERE `Trips Completed` >= 12
AND Rating >= 4.7;
""")
opt2_drivers.head()
Here’s what we get.
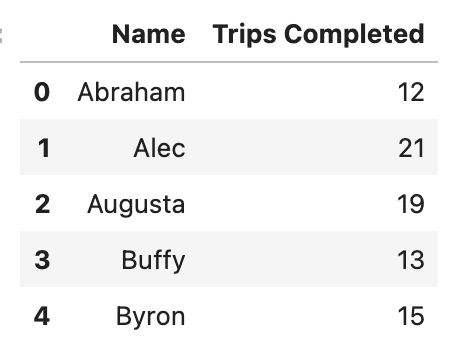
// Step 2: Finishing the Calculation in Pure Pandas
Now let’s perform the calculation using Pandas. The code computes the total bonus by summing the Trips Completed column with sum() and then multiplying the result by the $4 bonus per trip.
total_trips = opt2_drivers["Trips Completed"].sum()
option2_bonus = 4 * total_trips
print(f"Total trips: {total_trips}, Option-2 payout: ${option2_bonus}")
Here is the result.

# Question 3: Identifying Drivers Who Qualify for Option 1 But Not Option 2
In the third question, we are asked to count the number of drivers who qualify for Option 1 but not for Option 2.
// Step 1: Building Two Eligibility Tables with SQL (pandasql)
In the following SQL code, we create two datasets: one for drivers who meet the Option 1 criteria and another for those who meet the Option 2 criteria.
# All Option-1 drivers
opt1_drivers = run("""
SELECT Name
FROM df
WHERE `Supply Hours` >= 8
AND `Trips Completed` >= 10
AND `Accept Rate` >= 90
AND Rating >= 4.7;
""")
# All Option-2 drivers
opt2_drivers = run("""
SELECT Name
FROM df
WHERE `Trips Completed` >= 12
AND Rating >= 4.7;
""")
// Step 2: Using Python Set Logic to Spot the Difference
Next, we will use Python to identify the drivers who appear in Option 1 but not in Option 2, and we will use set operations for that.
Here is the code:
only_opt1 = set(opt1_drivers["Name"]) - set(opt2_drivers["Name"])
count_only_opt1 = len(only_opt1)
print(f"Drivers qualifying for Option 1 but not Option 2: {count_only_opt1}")
Here is the output.

By combining these methods, we leverage SQL for filtering and Python’s set logic for comparing the resulting datasets.
# Question 4: Finding Low-Performance Drivers with High Ratings
In question 4, we are asked to determine the percentage of drivers who completed fewer than 10 trips, had an acceptance rate below 90%, and still maintained a rating of 4.7 or higher.
// Step 1: Pulling the Subset with SQL (pandasql)
In the following code, we select all drivers who have completed fewer than 10 trips, have an acceptance rate of less than 90%, and hold a rating of at least 4.7.
low_kpi_df = run("""
SELECT *
FROM df
WHERE `Trips Completed` < 10
AND `Accept Rate` < 90
AND Rating >= 4.7;
""")
low_kpi_df
Here is the output.

// Step 2: Calculating the Percentage in Plain Pandas
In this step, we will use Python to calculate the percentage of such drivers.
We simply divide the number of filtered drivers by the total driver count, then multiply by 100 to get the percentage.
Here is the code:
num_low_kpi = len(low_kpi_df)
total_drivers = len(df)
percentage = round(100 * num_low_kpi / total_drivers, 2)
print(f"{num_low_kpi} out of {total_drivers} drivers ⇒ {percentage}%")
Here is the output.
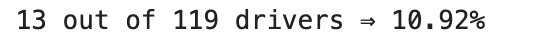
# Question 5: Calculating Annual Profit Without Partnering With Uber
In the fifth question, we need to calculate the annual income of a taxi driver without partnering with Uber, based on the given cost and revenue parameters.
// Step 1: Pulling Yearly Revenue and Expenses with SQL (pandasql)
By using SQL, we first calculate yearly revenue from daily fares and subtract expenses for gas, rent, and insurance.
taxi_stats = run("""
SELECT
200*6*(52-3) AS annual_revenue,
((200+500)*(52-3) + 400*12) AS annual_expenses
""")
taxi_stats
Here is the output.

// Step 2: Deriving Profit and Margin with Pandas
In the next step, we will use Python to compute the profit and margin the drivers get when not partnering with Uber.
rev = taxi_stats.loc[0, "annual_revenue"]
cost = taxi_stats.loc[0, "annual_expenses"]
profit = rev - cost
margin = round(100 * profit / rev, 2)
print(f"Revenue : ${rev:,}")
print(f"Expenses : ${cost:,}")
print(f"Profit : ${profit:,} (margin: {margin}%)")
Here’s what we get.
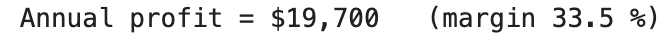
# Question 6: Calculating the Required Fare Increase to Maintain Profitability
In the sixth question, we assume that the same driver decides to buy a Town Car and partner with Uber.
The gas expenses increase by 5%, insurance decreases by 20%, and rental costs are eliminated, but the driver needs to cover the $40,000 cost of the car. We are asked to calculate how much this driver’s weekly gross fares must increase in the first year to both pay off the car and maintain the same annual profit margin.
// Step 1: Building the New One-Year Expense Stack with SQL
In this step, we will use SQL to calculate the new one-year expenses with adjusted gas and insurance and no rental fees, plus the car cost.
new_exp = run("""
SELECT
40000 AS car,
200*1.05*(52-3) AS gas, -- +5 %
400*0.80*12 AS insurance -- –20 %
""")
new_cost = new_exp.sum(axis=1).iloc[0]
new_cost
Here is the output.

// Step 2: Calculating the Weekly Fare Increase with Pandas
Next, we use Python to calculate how much more the driver must earn per week to preserve that margin after buying the car.
# Existing values from Question 5
old_rev = 58800
old_profit = 19700
old_margin = old_profit / old_rev
weeks = 49
# new_cost was calculated in the previous step (54130.0)
# We need to find the new revenue (new_rev) such that the profit margin remains the same:
# (new_rev - new_cost) / new_rev = old_margin
# Solving for new_rev gives: new_rev = new_cost / (1 - old_margin)
new_rev_required = new_cost / (1 - old_margin)
# The total increase in annual revenue needed is the difference
total_increase = new_rev_required - old_rev
# Divide by the number of working weeks to get the required weekly increase
weekly_bump = round(total_increase / weeks, 2)
print(f"Required weekly gross-fare increase = ${weekly_bump}")
Here’s what we get.
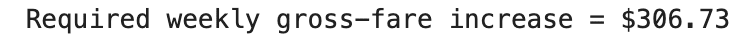
# Conclusion
Bringing together the strengths of SQL and Python, primarily through pandasql, we solved six different problems.
SQL helps in quick filtering and summarizing structured datasets, while Python is good at advanced computation and dynamic manipulation.
Throughout this analysis, we leveraged both tools to simplify the workflow and make each step more interpretable.
Nate Rosidi is a data scientist and in product strategy. He’s also an adjunct professor teaching analytics, and is the founder of StrataScratch, a platform helping data scientists prepare for their interviews with real interview questions from top companies. Nate writes on the latest trends in the career market, gives interview advice, shares data science projects, and covers everything SQL.

India has rapidly become a key hub for life sciences global capability centres (GCCs), with nearly half of the world’s top 50 life sciences companies establishing a presence in the country—most within the past five years, according to a new EY India report.
The report, Reimagining Life Sciences GCCs, highlighted how India’s GCCs have evolved from back-office support centres into strategic engines driving drug discovery, regulatory affairs, and commercial operations.
“This isn’t about cost arbitrage anymore, it’s about India becoming indispensable to the global R&D pipeline,” said Arindam Sen, partner and GCC Sector Lead – technology, media & entertainment and telecommunications, EY India. “Life sciences multinationals are embedding their most strategic, knowledge-intensive work here, making India the epicentre for life sciences innovation, compliance, and future growth.”
According to EY, Indian life sciences GCCs now manage integrated functions across clinical trials, pharmacovigilance, supply chain analytics, biostatistics, and enabling services such as finance, HR, IT, and data analytics.
The study shows that GCCs handle 70% of finance, 75% of HR, 62% of supply chain, and 67% of IT functions for their global firms. Core functions have also grown sharply: 45% in drug discovery, 60% in regulatory affairs, 54% in medical affairs, and 50% in commercial operations.
India’s rise as a GCC hub is driven by four key factors: policy support from central and state governments, a strong talent pool of over 2.7 million life sciences professionals, access to a mature ecosystem including CROs, universities, and startups, and widespread infrastructure with scalable Grade-A office spaces.Looking ahead, the report noted that leading life sciences GCCs are positioning themselves as “twins” of their global headquarters, co-owning innovation and accelerating outcomes. Sen added, “Their evolution will be defined by future capabilities, operating model transformation, and building agile, multi-disciplinary teams skilled in areas like generative AI, bioinformatics, and digital health.”

AI PCs will make up 31% of the worldwide PC market by the end of 2025, according to Gartner. Shipments are projected to hit 77.8 million units this year, with adoption accelerating to 55% of the global market in 2026 and becoming the standard by 2029.
“AI PCs are reshaping the market, but their adoption in 2025 is slowing because of tariffs and pauses in PC buying caused by market uncertainty,” said Ranjit Atwal, senior director analyst at Gartner, in a statement. Despite this, users are expected to continue investing in AI PCs to prepare for greater edge AI integration.
AI laptop adoption is projected to outpace desktops, with 36% of laptops expected to be AI-enabled by 2025, compared to 16% of desktops. By 2026, nearly 59% of laptops will fall into this category. Businesses largely favour x86 on Windows, which is expected to represent 71% of the AI business laptop market next year, while Arm-based laptops are anticipated to see more substantial consumer traction.
To support this shift, Gartner predicts that 40% of software vendors will prioritise developing AI features for PCs by 2026, up from just 2% in 2024. Small language models (SLMs) running locally on devices are expected to drive faster, more secure, and energy-efficient AI experiences.
Looking ahead, Gartner notes that vendors must focus on software-defined, customisable AI PCs to build stronger brand loyalty. “The future of AI PCs is in customisation,” Atwal said.
Still, the rapid rise of AI PCs masks an industry-wide “TOPS race.” While Microsoft, AMD, Intel, and Qualcomm position AI PCs as the future, performance claims around neural processing units (NPUs) remain contested.
As industry leaders push for more TOPS, analysts warn that real-world AI performance may hinge less on specifications and more on practical workloads, software maturity, and user adoption.
The post AI PC Shipments to Hit 77 Million Units This Year: Report appeared first on Analytics India Magazine.

Hexaware Technologies has partnered with Replit to accelerate enterprise software development and make it more accessible through secure Vibe Coding. The collaboration combines Hexaware’s digital innovation expertise with Replit’s natural language-powered development platform, allowing both business users and engineers to create secure production-ready applications.
The partnership aims to help companies accelerate digital transformation by enabling teams beyond IT, such as product, design, sales and operations, to develop internal tools and prototypes without relying on traditional coding skills.
Amjad Masad, CEO of Replit, said, “Our mission is to empower entrepreneurial individuals to transform ideas into software—regardless of their coding experience or whether they’re launching a startup or innovating within an enterprise.”
Hexaware said the tie-up will facilitate faster innovation while maintaining security and governance.
Sanjay Salunkhe, president and global head of digital and software services at Hexaware Technologies, noted, “By combining our vibe coding framework with Replit’s natural language interface, we’re giving enterprises the tools to accelerate development cycles while upholding the rigorous standards their stakeholders demand.”
The partnership will enable enterprises to democratise software development by allowing employees across departments to build and deploy secure applications using natural language.
It will provide secure environments with features such as SSO, SOC 2 compliance and role-based access controls, further strengthened by Hexaware’s governance frameworks to meet enterprise IT standards.
Teams will benefit from faster prototyping, with product and design groups able to test and iterate ideas quickly, reducing time-to-market. Sales, marketing and operations functions can also develop custom internal tools tailored to their workflows, avoiding reliance on generic SaaS platforms or long IT queues.
In addition, Replit’s agentic software architecture, combined with Hexaware’s AI expertise, will drive automation of complex backend tasks, enabling users to focus on higher-level logic and business outcomes.
The post Hexaware, Replit Partner to Bring Secure Vibe Coding to Enterprises appeared first on Analytics India Magazine.
-

 Business3 days ago
Business3 days agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-
Tools & Platforms3 weeks ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy1 month ago
Ethics & Policy1 month agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences3 months ago
Events & Conferences3 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers2 months ago
Jobs & Careers2 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Funding & Business2 months ago
Funding & Business2 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries
-

 Education2 months ago
Education2 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi
-

 Mergers & Acquisitions2 months ago
Mergers & Acquisitions2 months agoDonald Trump suggests US government review subsidies to Elon Musk’s companies