AI Research
AI Research Review 08.14.25 – Self-evolving AI
One of the largest limitations of AI models current is that they are static once they are trained. Giving AI the ability to improve itself without training data would unlock enormous improvements in AI capabilities. As the R-Zero paper puts it:
Self-evolving Large Language Models (LLMs) offer a scalable path toward superintelligence by autonomously generating, refining, and learning from their own experiences.
The three papers below present various types of self-evolution of AI systems, by using iterative feedback loops combined with self-evaluations, i.e., LLM-as-a-judge, to guide AI improvement.
-
A Comprehensive Survey of Self-Evolving AI Agents. This survey paper on Self-Evolving AI Agents shows how self-evolution principles are applied to AI Agent systems, to enable such systems to continue to improve in real-world environments.
-
Test-Time Diffusion Deep Researcher (TTD-DR): The TTD-DR paper uses iterative refinement and self-evolution to improve deep research AI workflows.
-
R-Zero: Self-Evolving Reasoning LLM from Zero Data: The R-Zero paper shows a method for self-improving AI reasoning, with Challenger and Solver model refined models, to improve AI reasoning by improving both questions and answers in the training process.
The evolution from MOP (Model Offline Pretraining) to MASE (Multi-Agent Self-Evolving) represents a fundamental shift in the development of LLM-based systems, from static, manually configured architectures to adaptive, data-driven systems that can evolve in response to changing requirements and environments.
Existing AI agent designs remain fixed after training and deployment, limiting their ability to adapt to dynamic real-world environments. The paper A Comprehensive Survey of Self-Evolving AI Agents: A New Paradigm Bridging Foundation Models and Lifelong Agentic Systems examines self-evolving AI agents, an emerging paradigm that aims to imbue static foundation models with the continuous adaptability necessary for lifelong agentic systems.
This work formalizes self-evolving agents as autonomous systems capable of continuous self-optimization through environmental interaction, using the term MASE, Multi-Agent Self-Evolving systems, to describe such systems.
The paper proposes “Three Laws of Self-Evolving AI Agents” as guiding principles to ensure safe and effective self-improvement: Endure (safety adaptation), Excel (performance preservation), and Evolve (autonomous optimization). MASE systems are driven by the core goal of “adapting to changing tasks, contexts and resources while preserving safety and enhancing performance.”
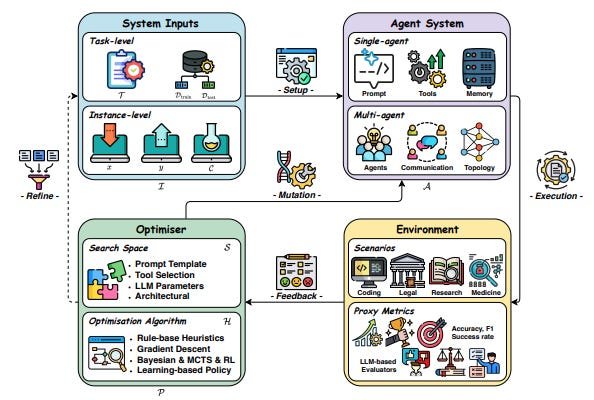
The conceptual framework for how self-evolving agentic systems work breaks the underlying feedback loop for AI system learning into four key components: System Inputs, Agent System, Environment, and Optimisers.
This framework underpins iterative refinement, where the AI agent system (single agent or multi-agent) processes inputs within an environment, generates feedback signals, and then utilizes optimizers—which define a search space and an algorithm—to update its components. These components include the core LLM’s behavior, prompt strategies, memory mechanisms, tool integration, and in multi-agent settings, workflow topologies and communication protocols.
This survey categorizes and details existing optimization techniques across these components and highlights domain-specific strategies in areas like biomedicine, programming, and finance. They observe progress in shifting from manually configured systems towards automated learning and adaptation in AI agent architectures and behaviors.
While significant challenges remain in areas such as reward modeling stability, real-world evaluation, and managing efficiency-effectiveness trade-offs, the insights offered lay a foundational understanding for developing more robust and trustworthy adaptive AI agent systems.
Our framework meticulously models the entire research report generation as an iterative diffusion process, mirroring human cognitive patterns. – Deep Researcher with Test-Time Diffusion.
The paper Deep Researcher with Test-Time Diffusion from Google Research introduces TTD-DR, a novel framework designed to improving LLM-powered deep research agents in generating complex, long-form reports. This system significantly outperforms existing deep research agents.
Existing agents often struggle with maintaining coherence and minimizing information loss during iterative search processes, lacking a principled, human-like iterative research paradigm. The TTD-DR addresses this by conceptualizing research report generation as a diffusion process, mirroring the human approach of iterative drafting, searching, reasoning, writing, and revision.
Crucially, the framework incorporates two synergistic mechanisms:
Report-Level Refinement via Denoising with Retrieval: After planning, TTD-DR generates a preliminary, updatable draft, which serves as an evolving foundation to guide the research direction. This draft undergoes iterative refinement through a “denoising” process, dynamically informed by a retrieval mechanism that incorporates external information at each step. This continuous feedback loop ensures the report remains coherent and the research stays on track, mitigating the context loss common in linear agentic workflows.

Component-wise Optimization via Self-Evolution: TTD-DR uses a self-evolutionary algorithm to enhance each component of the workflow – research plan generation, search question formulation, and answer synthesis. This involves generating multiple variants of outputs, assessing them using an LLM-as-a-judge, revising based on feedback, and merging the best elements. This interplay ensures high-quality context for the overall report diffusion.
TTD-DR demonstrates state-of-the-art performance across a wide array of benchmarks requiring intensive search and multi-hop reasoning. On long-form report generation tasks, it achieved win rates of 69.1% on LongForm Research and 74.5% on DeepConsult benchmarks in side-by-side comparisons against OpenAI Deep Research.
The TTD-DR process is a clever approach for deep research report generation, and a close analogy to human-based drafting. Such iterative, human-inspired frameworks with built-in iterative feedback have potential across many agentic tasks, so expect similar workflow self-evolution design patterns for other tasks.
The research paper from Tencent AI Lab R-Zero: Self-Evolving Reasoning LLM from Zero Data addresses a critical bottleneck in advancing AI systems beyond human intelligence: the scalability and cost of human data annotation for training self-evolving LLMs. The paper introduces a fully autonomous framework called R-Zero that enables LLMs to self-evolve their reasoning without reliance on human-curated tasks or labels.
R-Zero’s core contribution is a novel co-evolutionary loop between two independent models, a Challenger that asks questions and a Solver that answers them, to iteratively generate, solve, and learn from their own experiences:
The Challenger is rewarded for proposing tasks near the edge of the Solver capability, and the Solver is rewarded for solving increasingly challenging tasks posed by the Challenger. This process yields a targeted, self-improving curriculum without any pre-existing tasks and labels.
Both the Challenger and the Solver are fine-tuned via Group Relative Policy Optimization, GRPO. The Challenger reward function is designed to incentivize questions that maximize the Solver’s uncertainty, with a 50% chance of solving them. Similar to other systems for reasoning without verifiable-rewards, the Solver derives its labels for training through a majority-vote mechanism from its own multiple generated answers, eliminating the need for external verification or human labelling.

Empirically, R-Zero consistently and substantially improves the reasoning capabilities of tested AI reasoning models:
Zero substantially improves reasoning capability across different backbone LLMs, e.g., boosting the Qwen3-4B-Base by +6.49 on math reasoning benchmarks, and +7.54 on general-domain reasoning benchmarks (SuperGPQA).
One limitation is that as questions become more difficult, the accuracy of the self-generated pseudo-labels can decline, a potential limitation for ultimate performance. Future work could focus on more robust pseudo-labeling techniques and extending this paradigm to subjective open-ended generative tasks.
By alleviating reliance on human data and scaling self-improvement, R-Zero is not just scaling AI reasoning, but takes us closer to self-evolving AI models.

On September 10, Senate Commerce, Science, and Transportation Committee Chair Ted Cruz (R-TX) released what he called a “light-touch” regulatory framework for federal AI legislation, outlining five pillars for advancing American AI leadership. In parallel, Senator Cruz introduced the Strengthening AI Normalization and Diffusion by Oversight and eXperimentation (“SANDBOX”) Act (S. 2750), which would establish a federal AI regulatory sandbox program that would waive or modify federal agency regulations and guidance for AI developers and deployers. Collectively, the AI framework and the SANDBOX Act mark the first congressional effort to implement the recommendations of AI Action Plan the Trump Administration released on July 23.
- Light-Touch AI Regulatory Framework
Senator Cruz’s AI framework, titled “A Legislative Framework for American Leadership in Artificial Intelligence,” calls for the United States to “embrace its history of entrepreneurial freedom and technological innovation” by adopting AI legislation that promotes innovation while preventing “nefarious uses” of AI technology. Echoing President Trump’s January 23 Executive Order on “Removing Barriers to American Leadership in Artificial Intelligence” and recommendations in the AI Action Plan, the AI framework sets out five pillars as a “starting point for discussion”:
- Unleashing American Innovation and Long-Term Growth. The AI framework recommends that Congress establish a federal AI regulatory sandbox program, provide access to federal datasets for AI training, and streamline AI infrastructure permitting. This pillar mirrors the priorities of the AI Action Plan and President Trump’s July 23 Executive Order on “Accelerating Federal Permitting of Data Center Infrastructure.”
- Protecting Free Speech in the Age of AI. Consistent with President Trump’s July 23 Executive Order on “Preventing Woke AI in the Federal Government,” Senator Cruz called on Congress to “stop government censorship” of AI (“jawboning”) and address foreign censorship of Americans on AI platforms. Additionally, while the AI Action Plan recommended revising the National Institute of Standards & Technology (“NIST”)’s AI Risk Management Framework to “eliminate references to misinformation, Diversity, Equity, and Inclusion, and climate change,” this pillar calls for reforming NIST’s “AI priorities and goals.”
- Prevent a Patchwork of Burdensome AI Regulation. Following a failed attempt by Congressional Republicans to enact a moratorium on the enforcement of state and local AI regulations in July, the AI Action Plan called on federal agencies to limit federal AI-related funding to states with burdensome AI regulatory regimes and on the FCC to review state AI laws that may be preempted under the Communications Act. Similarly, the AI framework calls on Congress to enact federal standards to prevent burdensome state AI regulation, while also countering “excessive foreign regulation” of Americans.
- Stop Nefarious Uses of AI Against Americans. In a nod to bipartisan support for state digital replica protections – which ultimately doomed Congress’s state AI moratorium this summer – this pillar calls on Congress to protect Americans against digital impersonation scams and fraud. Additionally, this pillar calls on Congress to expand the principles of the federal TAKE IT DOWN Act, signed into law in May, to safeguard American schoolchildren from nonconsensual intimate visual depictions.
- Defend Human Value and Dignity. This pillar appears to expand on the policy of U.S. “global AI dominance in order to promote human flourishing” established by President Trump’s January 23 Executive Order by calling on Congress to reinvigorate “bioethical considerations” in federal policy and to “oppose AI-driven eugenics and other threats.”
- SANDBOX Act
Consistent with recommendations in the AI Action Plan and AI Framework, the SANDBOX Act would direct the White House Office of Science & Technology Policy (“OSTP”) to establish and operate an “AI regulatory sandbox program” with the purpose of incentivizing AI innovation, the development of AI products and services, and the expansion of AI-related economic opportunities and jobs. According to Senator Cruz’s press release, the SANDBOX Act marks a “first step” in implementing the AI Action Plan, which called for “regulatory sandboxes or AI Centers of Excellence around the country where researchers, startups, and established enterprises can rapidly deploy and test AI tools.”
Program Applications. The AI regulatory sandbox program would allow U.S. companies and individuals, or the OSTP Director, to apply for a “waiver or modification” of one or more federal agency regulations in order to “test, experiment, or temporarily provide” AI products, AI services, or AI development methods. Applications must include various categories of information, including:
- Contact and business information,
- A description of the AI product, service, or development method,
- Specific regulation(s) that the applicant seeks to have waived or modified and why such waiver or modification is needed,
- Consumer benefits, business operational efficiencies, economic opportunities, jobs, and innovation benefits of the AI product, service, or development method,
- Reasonably foreseeable risks to health and safety, the economy, and consumers associated with the waiver or modification, and planned risk mitigations,
- The requested time period for the waiver or modification, and
- Each agency with jurisdiction over the AI product, service, or development method.
Agency Reviews and Approvals. The bill would require OSTP to submit applications to federal agencies with jurisdiction over the AI product, service, or development method within 14 days. In reviewing AI sandbox program applications, federal agencies would be required to solicit input from the private sector and technical experts on whether the applicant’s plan would benefit consumers, businesses, the economic, or AI innovation, and whether potential benefits outweigh health and safety, economic, or consumer risks. Agencies would be required to approve or deny applications within 90 days, with a record documenting reasonably foreseeable risks, the mitigations and consumer protections that justify agency approval, or the reasons for agency denial. Denied applicants would be authorized to appeal to OSTP for reconsideration. Approved waivers or modifications would be granted for a term of two years, with up to four additional two-year terms if requested by the applicant and approved by OSTP.
Participant Terms and Requirements. Participants with approved waivers or modifications would be immune from federal criminal, civil, or agency enforcement of the waived or modified regulations, but would remain subject to private consumer rights of action. Additionally, participants would be required to report incidents of harm to health and safety, economic damage, or unfair or deceptive trade practices to OSTP and federal agencies within 72 hours after the incident occurs, and to make various disclosures to consumers. Participants would also be required to submit recurring reports to OSTP throughout the term of the waiver or modification, which must include the number of consumers affected, likely risks and mitigations, any unanticipated risks that arise during deployment, adverse incidents, and the benefits of the waiver or modification.
Congressional Review. Finally, the SANDBOX Act would require the OSTP Director to submit to Congress any regulations that the Director recommends for amendment or repeal “as a result of persons being able to operate safely” without those regulations under the sandbox program. The bill would establish a fast-track procedure for joint resolutions approving such recommendations, which, if enacted, would immediately repeal the regulations or adopt the amendments recommended by OSTP.
The SANDBOX Act’s regulatory sandbox program would sunset in 12 years unless renewed. The introduction of the SANDBOX Act comes as states have pursued their own AI regulatory sandbox programs – including a sandbox program established under the Texas Responsible AI Governance Act (“TRAIGA”), enacted in June, and an “AI Learning Laboratory Program” established under Utah’s 2024 AI Policy Act. The SANDBOX Act would require OSTP to share information these state AI sandbox programs if they are “similar or comparable” to the SANDBOX Act, in addition to coordinating reviews and accepting “joint applications” for participants with AI projects that would benefit from “both Federal and State regulatory relief.”

ATHENS, Greece — A top Google scientist and 2024 Nobel laureate said Friday that the most important skill for the next generation will be “learning how to learn” to keep pace with change as Artificial Intelligence transforms education and the workplace.
Speaking at an ancient Roman theater at the foot of the Acropolis in Athens, Demis Hassabis, CEO of Google’s DeepMind, said rapid technological change demands a new approach to learning and skill development.
“It’s very hard to predict the future, like 10 years from now, in normal cases. It’s even harder today, given how fast AI is changing, even week by week,” Hassabis told the audience. “The only thing you can say for certain is that huge change is coming.”
The neuroscientist and former chess prodigy said artificial general intelligence — a futuristic vision of machines that are as broadly smart as humans or at least can do many things as well as people can — could arrive within a decade. This, he said, will bring dramatic advances and a possible future of “radical abundance” despite acknowledged risks.
Hassabis emphasized the need for “meta-skills,” such as understanding how to learn and optimizing one’s approach to new subjects, alongside traditional disciplines like math, science and humanities.
“One thing we’ll know for sure is you’re going to have to continually learn … throughout your career,” he said.
The DeepMind co-founder, who established the London-based research lab in 2010 before Google acquired it four years later, shared the 2024 Nobel Prize in chemistry for developing AI systems that accurately predict protein folding — a breakthrough for medicine and drug discovery.
Greek Prime Minister Kyriakos Mitsotakis joined Hassabis at the Athens event after discussing ways to expand AI use in government services. Mitsotakis warned that the continued growth of huge tech companies could create great global financial inequality.
“Unless people actually see benefits, personal benefits, to this (AI) revolution, they will tend to become very skeptical,” he said. “And if they see … obscene wealth being created within very few companies, this is a recipe for significant social unrest.”
Mitsotakis thanked Hassabis, whose father is Greek Cypriot, for rescheduling the presentation to avoid conflicting with the European basketball championship semifinal between Greece and Turkey. Greece later lost the game 94-68.
____
Kelvin Chan in London contributed to this story.

Both AMD and Broadcom have an opportunity to outperform in the coming years.
Nvidia is the king of artificial intelligence (AI) infrastructure, and for good reason. Its graphics processing units (GPUs) have become the main chips for training large language models (LLMs), and its CUDA software platform and NVLink interconnect system, which helps its GPUs act like a single chip, have helped create a wide moat.
Nvidia has grown to become the largest company in the world, with a market cap of over $4 trillion. In Q2, it held a whopping 94% market share for GPUs and saw its data center revenue soar 56% to $41.1 billion. That’s impressive, but those large numbers may be why there could be some better opportunities in the space.
Two stocks to take a closer look at are Advanced Micro Devices (AMD 1.91%) and Broadcom (AVGO 0.19%). Both are smaller players in AI chips, and as the market shifts from training toward inference, they’re both well positioned. The reality is that while large cloud computing and other hyperscalers (companies with large data centers) love Nvidia’s GPUs they would prefer more alternatives to help reduce costs and diversify their supply chains.
1. AMD
AMD is a distant second to Nvidia in the GPU market, but the shift to inference should help it. Training is Nvidia’s stronghold, and where its CUDA moat is strongest. However, inference is where demand is accelerating, and AMD has already started to win customers.
AMD management has said one of the largest AI model operators in the world is using its GPUs for a sizable portion of daily inference workloads and that seven of the 10 largest AI model companies use its GPUs. That’s important because inference isn’t a one-time event like training. Every time someone asks a model a question or gets a recommendation, GPUs are providing the power for these models to get the answer. That’s why cost efficiency matters more than raw peak performance.
That’s exactly where AMD has a shot to take some market share. Inference doesn’t need the same libraries and tools as training, and AMD’s ROCm software platform is more than capable of handling inference workloads. And once performance is comparable, price becomes more of a deciding factor.
AMD doesn’t need to take a big bite out of Nvidia’s share to move the needle. Nvidia just posted $41.1 billion in data center revenue last quarter, while AMD came in at $3.2 billion. Even small wins can have an outsize impact when you start from a base that is a fraction of the size of the market leader.
On top of that, AMD helped launch the UALink Consortium, which includes Broadcom and Intel, to create an open interconnect standard that competes with Nvidia’s proprietary NVLink. If successful, that would break down one of Nvidia’s big advantages and allow customers to build data center clusters with chips from multiple vendors. That’s a long-term effort, but it could help improve the playing field.
With inference expected to become larger than training over time, AMD doesn’t need to beat Nvidia to deliver strong returns; it just needs a little bigger share.
Image source: Getty Images.
2. Broadcom
Broadcom is attacking the AI opportunity from another angle, but the upside may be even more compelling. Instead of designing off-the-shelf GPUs, Broadcom is helping customers make their own customer AI chips.
Broadcom is a leader in helping design application-specific integrated circuits, or ASICs, and it has taken that expertise and applied it to making custom AI chips. Its first customer was Alphabet, which it helped design its highly successful Tensor Processing Units (TPUs) that now help power Google Cloud. This success led to other design wins, including with Meta Platforms and TikTok owner ByteDance. Combined, Broadcom has said these three customers represent a $60 billion to $90 billion serviceable addressable market by its fiscal 2027 (ending October 2027).
However, the news got even better when the company revealed that a fourth customer, widely believed to be OpenAI, placed a $10 billion order for next year. Designing ASICs is typically not a quick process. Alphabet’s TPUs took about 18 months from start to finish, which at the time was considered quick. But this newest deal shows it can keep this fast pace. This also bodes well with future deals, as late last year it was revealed that Apple will be a fifth customer.
Custom chips have clear advantages for inference. They’re designed for specific workloads, so they deliver better power efficiency and lower costs than off-the-shelf GPUs. As inference demand grows larger than training, Broadcom’s role as the go-to design partner becomes more valuable.
Now, custom chips have large upfront costs to design and aren’t for everyone, but this is a huge potential opportunity for Broadcom moving forward.
The bottom line
Nvidia is still the dominant player in AI infrastructure, and I don’t see that changing anytime soon. However, both AMD and Broadcom have huge opportunities in front of them and are starting at much smaller bases. That could help them outperform in the coming years.
Geoffrey Seiler has positions in Alphabet. The Motley Fool has positions in and recommends Advanced Micro Devices, Alphabet, Apple, Meta Platforms, and Nvidia. The Motley Fool recommends Broadcom. The Motley Fool has a disclosure policy.
-

 Business2 weeks ago
Business2 weeks agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-
Tools & Platforms1 month ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy2 months ago
Ethics & Policy2 months agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences4 months ago
Events & Conferences4 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers2 months ago
Jobs & Careers2 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Education2 months ago
Education2 months agoMacron says UK and France have duty to tackle illegal migration ‘with humanity, solidarity and firmness’ – UK politics live | Politics
-

 Education2 months ago
Education2 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Funding & Business2 months ago
Funding & Business2 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi