AI Insights
Stacked ensemble model for NBA game outcome prediction analysis
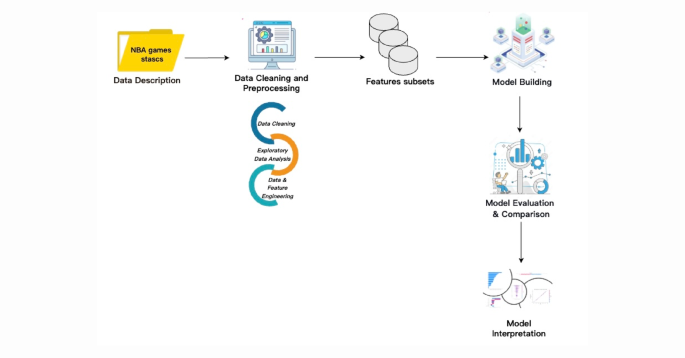
This study aims to develop a predictive framework for NBA game outcomes using a machine-learning strategy based on the Stacking ensemble method. This section details the materials and methods used to achieve our objective. Figure 1 displays the overall workflow of the proposed framework. The entire experimental procedure was carried out in a Jupyter Notebook environment using Python. We utilized several key Python libraries—including NumPy, Pandas, Scikit-learn, and Matplotlib—for data processing, model development, and result visualization.
Dataset
The data used in this study were obtained from the official NBA website (https://www.nba.com), which provides a comprehensive collection of multi-dimensional information, including basic player and team statistics, advanced efficiency metrics, spatial tracking data, lineup performance, and salary and management records. These datasets are widely used in both tactical analysis and machine learning modeling.
This study focuses primarily on game-level performance and outcomes from the regular seasons of the 2021–2022, 2022–2023, and 2023–2024 NBA seasons. Specifically, data were collected from all 1,230 games per season, totaling 3,690 games and 7,380 samples (accounting for both home and away teams). The dataset comprises 20 feature variables, including total field goals made, three-point shots made, and other offensive and defensive indicators. The game outcome (win or loss) serves as the target variable. Detailed descriptions of all variables are provided in Table 2.
Data processing
To facilitate model training, the game outcome variable for all regular-season games across the three NBA seasons was encoded as a binary classification variable, where a win was labeled as 1 and a loss as 0. This binary encoding allows machine learning models to distinguish between game outcomes more effectively.
As shown in the summary statistics presented in Table 3, the resulting dataset is balanced, containing an equal number of win and loss samples. Specifically, among the 7,380 total samples, there are 3,690 observations for each class (win and loss).
Dataset partitioning
To prevent model overfitting and ensure robust predictive performance, the dataset was randomly partitioned into training and testing subsets. Given that each regular-season game across the three NBA seasons is mutually independent, random sampling was employed for the split.
Specifically, 80% of the data was allocated to the training set, and the remaining 20% to the testing set. The training set was used for model construction, while the testing set was used for evaluating the model’s performance. The detailed distribution of samples is presented in Table 4.
Feature selection
Feature selection is a crucial step that directly impacts the accuracy and generalization performance of a model20. To prevent the issue of multicollinearity among variables, which can reduce model interpretability, key features were further screened to address this concern. We employed Exploratory Data Analysis (EDA) techniques and calculated the Pearson correlation coefficients between feature variables to assess inter-variable relationships visually. As shown in the correlation heatmap in Fig. 2, no severe multicollinearity was observed among the 20 feature variables. Therefore, all 20 features were retained for model training and analysis. Descriptive statistics for each variable are presented in Table 5.
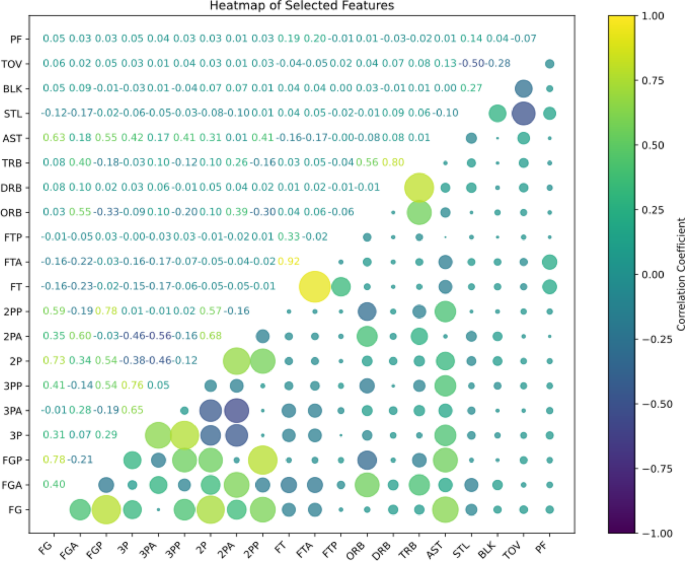
Pearson Correlation Heatmap of Feature Variables.
Model building
After completing data preprocessing, this study utilizes the Scikit-Learn Python toolkit to train machine learning models. The dataset is initially divided into training and testing sets, ensuring a systematic approach to model evaluation. Various machine learning classifiers are then applied to train and evaluate the model’s performance, allowing for a thorough comparison of their predictive abilities.
To construct the baseline models, each candidate machine learning algorithm is evaluated using 5-fold cross-validation, a widely accepted technique to ensure robust and unbiased performance estimation. The model yielding the highest average accuracy across folds is selected for inclusion in the base layer of the Stacking ensemble framework. The accuracy metric computed via 5-fold cross-validation is formally defined in Eq. 1.
$$\:C\:{A}_{k}=\frac{\sum\:_{i=1}^{k}{A}_{i}}{k}$$
(1)
In this context, k represents the number of cross-validation folds, while Ai indicates the accuracy achieved on the i-th fold. The resulting CAk represents the model’s average cross-validated accuracy. According to the evaluation results above, the models with the highest accuracy are selected to form the base layer of the Stacked Ensemble. The selection criterion is further specified in Eq. 2.
$$\:\forall \:\{ i \in \:N,0 < i < n\} ,\:model_{i} \: = \:O_{{(max \ldots \:min)}} (CA_{1} ,CA_{2} , \ldots \:,CA_{n} )$$
(2)
Let modeli represent the selected model, while O (max…min) indicates the descending order function based on the cross-validation accuracies of n different models. The top-performing models are chosen to form the foundation of the proposed Stacked Ensemble Model.
Selected models
Multilayer perceptron
The Single-Layer Perceptron is limited in its ability to solve problems that are not linearly separable. The MLP was developed as an extension to address this limitation. The MLP incorporates a multilayer network architecture trained using the backpropagation algorithm. The architecture generally includes three-layer types: the input layer, one or more hidden layers, and the output layer21. In contrast to the Single-Layer Perceptron, the MLP includes at least one intermediate (hidden) layer that enables the model to capture non-linear relationships22.
XGBoost
XGBoost is an ensemble learning algorithm that generates predictions by aggregating the outputs of multiple base learners, typically decision trees23. While it shares structural similarities with Random Forest in using decision trees as fundamental components, XGBoost offers notable advantages over traditional Gradient Boosting Decision Tree (GBDT) methods. These include significantly faster computational speed, improved generalization performance, and superior scalability, making it well-suited for large-scale and high-dimensional machine learning tasks. Unlike many machine learning frameworks, XGBoost offers extensive support for fine-tuning regularization parameters, providing greater control over model complexity and improving overall performance24. Due to its efficiency and strong generalization capability, XGBoost has become a widely used technique for predictive modeling across various domains, including sports analytics and NBA game outcome prediction.
AdaBoost
AdaBoost is an ensemble learning method that builds a strong classifier by iteratively combining multiple weak learners. In each iteration, more focus is placed on instances that were misclassified in the previous round, guiding subsequent classifiers to concentrate on more challenging samples. AdaBoost classifiers operate as meta-estimators, initially training a base learner on the original dataset25. In the following iterations, the same base learner is retrained multiple times but with adjusted sample weights—specifically, increasing the weights of previously misclassified instances—so that the model progressively improves its performance on complex examples.
Naive Bayes
This classification algorithm, named after the English mathematician Thomas Bayes, is based on Bayes’ theorem, and relies on probabilistic reasoning. It performs classification by applying probability calculations derived from training data and assigns a new instance to the class with the highest posterior probability24. The mathematical formulation of Bayes’ theorem is presented in Eq. 3.
$$\:P\left(A|B\right)=\:\frac{P\left(B|A\right)\times\:P\left(A\right)}{P\left(B\right)}$$
(3)
P (A | B) represents the probability of event A occurring, given that event B has already occurred.
P (B | A) denotes the likelihood of event B occurring, given that event A has occurred.
P(A) and P(B) refer to the prior (unconditional) probabilities for events A and B, respectively.
K-Nearest neighbor (KNN)
The K-nearest neighbor (KNN) algorithm is a supervised learning technique used for both classification and regression tasks. It is a non-parametric, instance-based learning algorithm that makes predictions based on the similarity between data points. In the classification process, when a new sample needs to be categorized, the algorithm identifies the k closest data points from the training set based on a chosen distance metric (e.g., Euclidean distance, Manhattan distance, or Minkowski distance). The majority class among these K nearest neighbors is then assigned as the class label for the new sample26.
Logistic regression
Logistic Regression is a regression-based classification method primarily designed for binary classification problems. It can be considered an extension of Linear Regression, optimized to estimate the probability that a given observation belongs to a particular category. In other words, Logistic Regression predicts the likelihood of an outcome based on a set of independent variables and then classifies the dependent variable accordingly26.
Decision tree
A Decision Tree is a supervised learning model for classification and regression tasks. It follows a hierarchical, tree-like structure to recursively partition the dataset based on feature values, ultimately reaching a leaf node representing the predicted outcome27,28.
Proposed stacked ensemble model
This study proposes a Stacked Ensemble (Stacking) model to enhance overall performance by integrating predictions from multiple base models. Stacking enables the training of diverse machine learning models to solve similar problems, combining their outputs to construct a more robust and accurate predictive model28,29. In contrast to ensemble techniques like Bagging and Boosting, Stacking emphasizes the integration of heterogeneous and strong base models, utilizing their complementary capabilities to enhance overall predictive performance. By aggregating the predictions of multiple models, the approach enhances generalization ability and performance stability.
The Stacking ensemble framework can be formally defined as follows: Given a k-fold cross-validation setup, let (x, y)k represent the k data folds, x = (x₁, x₂, …, xr) corresponds to the r recorded feature values, and y = (xr+1, xr+2, …, xr+p) represents the p target values to be predicted. For a given set of N potential learning algorithms, denoted as modeli, i = 1, …, N, Let Aij represent the model created by algorithm modeli trained on x to predict xp+j. The generalizer function, denoted as Gj, is responsible for merging predictions from the base models to produce the final forecast. Gj can be either a meta-model trained via a learning algorithm or a general function such as a weighted average. Thus, the estimated prediction value \(\hat{x}\) (p + j) can be formally expressed by Eq. 4. The training process is shown in Fig. 3. The effectiveness of the Stacking ensemble learning method relies on two key factors: (1) the performance of the base classifiers—the better the performance of the base models, the higher the overall ensemble performance; and (2) the diversity among the base classifiers. Introducing heterogeneous base models allows each to contribute uniquely, improving the ensemble model’s generalization capability.
$$\:\hat{x}\left( {p + j} \right) = G_{j} (A_{{ij}} , \ldots \:,A_{{Nj}} )$$
(4)
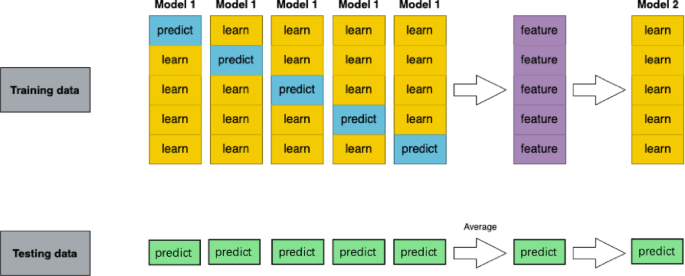
Training Process of the Stacking Ensemble Learning Model.
In this study, the stacked ensemble method was constructed by selecting six classifiers—XGBoost, KNN, AdaBoost, Naive Bayes, Logistic Regression, and Decision Tree—from multiple candidate models based on their highest cross-validation accuracy, which served as the base layer of the ensemble model. At the second layer, a MLP was used as the meta-learner (super learner). The MLP consisted of two hidden layers, each comprising 50 neurons, and was responsible for aggregating the prediction outputs from the base classifiers to produce the final prediction.
The complete training process is illustrated in Fig. 4 and follows a 5-fold cross-validation scheme. Specifically, the training data were randomly divided into five equally sized folds. In each iteration, four folds were used for training and the remaining fold served as the validation set. This process was repeated five times, ensuring that each fold functioned as the validation set once. During each fold, all six base classifiers were trained on the training subset and used to generate predictions on the corresponding validation fold. This resulted in five prediction sets per classifier. These out-of-fold predictions were then concatenated to form a new feature matrix, which served as the input to the meta-learner for training.
Simultaneously, predictions were made on the test set in each fold using the base classifiers, and the average of these predictions was used to construct the test set input for the meta-learner. Finally, the MLP meta-classifier used these new features to produce the final prediction results.
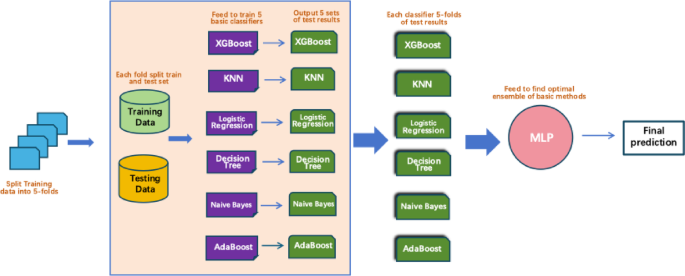
Complete the Training Process of the Stacking Model with 5-Fold Cross-Validation.
Interpretability analysis
The model’s predictions are analyzed using SHAP (Shapley Additive Explanations) values, which measure the contribution of each feature to the output for a specific instance. SHAP is grounded in cooperative game theory, where the model prediction is treated as a total reward, and the feature values are considered players contributing to this reward30.
Consider a dataset that contains p features, represented by the set F = {1, 2, 3, …, p}. A subset of features C ≤ F is referred to as a coalition, representing a collective contribution to the prediction. The empty set, denoted as \(\:\tau\:\), represents a scenario with no contributing features. A characteristic function v is defined to assign a real value to each subset C, such that v(C) reflects the predictive value of the coalition. To determine the individual contribution of feature i, SHAP evaluates all possible permutations of the feature set and computes the average marginal contribution of feature i across all coalitions that exclude i. The SHAP value \(\:\tau\:\)i for feature i is formally defined in Eq. 5.
$$\:{\tau\:}_{i}=\frac{1}{\left|F\right|!}\:\sum\:_{p}\left(\nu\:\left(C\cup\:\left\{i\right\}\right)-\nu\:\left(C\right)\right)\:$$
(5)
We utilize SHAP (Shapley Additive Explanations) analysis to enhance the interpretability of our NBA game prediction model. Specifically, we apply Kernel SHAP to perform both Global Mean Analysis and Local Interpretability, enabling us to quantify the influence of individual features on the model’s predictions across different scenarios.
Global interpretability
Global interpretability assesses how individual features influence the model’s predictions on average. The horizontal axis represents the average change in model output when a specific feature is omitted or “masked.” In this context, “masked” signifies that the feature is removed from the input, thereby eliminating its influence on the prediction. Let N denote the total number of samples, \(\:{\varphi\:}_{i}^{\left(j\right)}\) represent the SHAP value of the i-th feature for the j-th sample, and \(\:{\varPhi\:}_{i}^{global}\)denote the global average SHAP importance of the i-th feature. The Global SHAP value can be represented using Eq. 6 as follows:
$$\:{{\Phi\:}}_{i}^{global}=\:\frac{1}{N}\sum\:_{j=1}^{N}\left|{\varphi\:}_{i}^{\left(j\right)}\right|\:\:\:\:$$
(6)
Local interpretability
Local interpretability explains individual predictions, analyzing key factors driving specific NBA game outcomes. Where f(x): the model’s prediction output for sample x; ∅0 the model’s baseline output (typically the expected output over background data); ∅i the SHAP value of feature i for the given sample, representing the individual contribution of feature i to the prediction; p the total number of features. The Local SHAP Approximation Model can be represented using Eq. 7 as follows:
$$\:f\left(x\right)\approx\:\varphi\:+\sum\:_{i=1}^{p}{\varnothing\:}_{i}$$
(7)
Performance matrix
This study applies multiple machine learning models, with their effectiveness evaluated through performance metrics: Accuracy, Precision, Recall, and F1-score, each formally described in Eqs. 8, 9, 10, and 1131. In this context, TP, FP, TN, and FN represent True Positives, False Positives, True Negatives, and False Negatives, respectively. In addition to these conventional metrics, the Receiver Operating Characteristic – Area Under the Curve (ROC-AUC) is used to evaluate classification quality. The ROC curve depicts the relationship between the True Positive Rate (TPR), which is the same as Recall, and the False Positive Rate (FPR) as defined in Eqs. 9 and 12. This curve offers a comprehensive visualization of a model’s diagnostic ability across all possible classification thresholds, allowing for an assessment of its overall discriminative power.
$$\:\text{A}\text{c}\text{c}\text{u}\text{r}\text{a}\text{c}\text{y}=\:\frac{\left(TP+TN\right)}{\left(TP+TN+FN+FP\right)}\:\:\:\:$$
(8)
$$\:\text{P}\text{r}\text{e}\text{c}\text{i}\text{s}\text{i}\text{o}=\:\frac{\left(TP\right)}{\left(TP+FP\right)}\:\:$$
(9)
$$\:Reca=\:\frac{\left(TP\right)}{\left(TP+FN\right)}\:$$
(10)
$$\:\:F1\:scor=\frac{\left(2*Precision*Recall\right)}{\left(Precision+Recall\right)}\:$$
(11)
$$\:FPR=\:\frac{\left(FN\right)}{(TP+FN)}\:$$
(12)



















Spain records higher adoption of Artificial Intelligence – AI in vacation planning than the European average, according to the 2025 Europ Assistance-Ipsos barometer.
The study finds that 20% of Spanish travelers have used AI-based tools to organize or book their holidays, compared with 16% across Europe.
The research highlights Spain as one of the leading countries in integrating digital tools into travel planning. AI applications are most commonly used for accommodation searches, destination information, and itinerary planning, indicating a shift in how tourists prepare for trips.
Growing Use of AI in Travel
According to the survey, 48% of Spanish travelers using AI rely on it for accommodation recommendations, while 47% use it for information about destinations. Another 37% turn to AI tools for help creating itineraries. The technology is also used for finding activities (33%) and booking platform recommendations (26%).
Looking ahead, the interest in AI continues to grow. The report shows that 26% of Spanish respondents plan to use AI in future travel planning, compared with 21% of Europeans overall. However, 39% of Spanish participants remain undecided about whether they will adopt such tools.
Comparison with European Trends
The survey indicates that Spanish travelers are more proactive than the European average in experimenting with AI for holidays. While adoption is not yet universal, Spain’s figures consistently exceed continental averages, underscoring the country’s readiness to embrace new technologies in tourism.
In Europe as a whole, AI is beginning to make inroads into vacation planning but at a slower pace. The 2025 Europ Assistance-Ipsos barometer suggests that cultural attitudes and awareness of technological solutions may play a role in shaping adoption levels across different countries.
Changing Travel Behaviors
The findings suggest a gradual transformation in how trips are organized. Traditional methods such as guidebooks and personal recommendations are being complemented—and in some cases replaced—by AI-driven suggestions. From streamlining searches for accommodation to tailoring activity options, digital tools are expanding their influence on the traveler experience.
While Spain shows higher-than-average adoption rates, the survey also reflects caution. A significant portion of travelers remain unsure about whether they will use AI in the future, highlighting that trust, familiarity, and data privacy considerations continue to influence behavior.
The Europ Assistance-Ipsos barometer confirms that Spain is emerging as a frontrunner in adopting AI for travel planning, reflecting both a strong appetite for digital solutions and an evolving approach to how holidays are designed and booked.
Photo Credit: ProStockStudio / Shutterstock.com

Listen and subscribe to Financial Freestyle on Apple Podcasts, Spotify, or wherever you find your favorite podcasts.
Tristan Thompson is well-recognized for his career in the NBA, having played for teams like the Cleveland Cavaliers, the Boston Celtics, and the Los Angeles Lakers, to name a few. He was even part of the team that earned an NBA championship in 2016. But while Thompson’s basketball reputation precedes him, off the court, he’s focusing on his various entrepreneurial ventures.
When asked by Yahoo Finance’s Financial Freestyle podcast host Ross Mac if he would invest his final dollar in artificial intelligence or the blockchain, Thompson picked the industry that’s already projected to be worth $3.6 trillion by 2034.
“You see what Mark Zuckerberg’s paying for all these AI gurus? So I might go AI,” he said (see the full episode above; listen below).
This embedded content is not available in your region.
Thompson has already made AI one of his entrepreneurial ventures with the launch of TracyAI, an artificial intelligence that’s meant to offer real-time NBA analysis and predictive insights.
“Imagine a sports analyst or commentator on steroids,” he explained to Mac. “What I mean by that is having all the high-level analytics that you cannot get from NBA.com and ESPN … the analytics are coming from the professional teams. We have certain data and access to certain companies that only professional sports teams have access to. And I was able to pull that data with my resources and put it into the AI agent.”
Thompson saw the venture as “low-hanging fruit,” as it was one of the few areas he hadn’t yet noticed artificial intelligence being worked into. Though AI is slowly finding its way into the sports industry, TracyAI offers basketball fans access to statistics and projections they may not have had through the typical channels, creating a unique fan experience.
Though Thompson admitted AI has created some of its own controversies, it’s a venture where he’s ready to invest some of his financial resources to capitalize on the industry’s projected rapid growth.
“For me, it’s like, if [AI is] covering so many sectors, how come it hasn’t got into sports?” Thompson said. “This is an opportunity where I can be a visionary and a pioneer … I’ve always had this grind, build-up mentality, so it just migrated easily into Web3. If you look at Daryl Morey, he said he used AI agents to curate his Sixers roster … that just shows you that’s the first domino effect into something great.”

Search the internet and you will find countless testimonials of individuals using AI to get diagnoses their doctors missed. And while it is important for individuals to take ownership of their healthcare and use all available resources, it is just as important to understand the process behind an AI diagnosis.
If you ask AI to figure out what ails you based on inputting a series of symptoms, the AI will use mathematical probability to calculate the appropriate sequence of words that would generate the most valuable output given the specific prompt. The AI has no intrinsic or learned understanding of what “body,” “illness,” “pain,” or “disease” mean. Such practically meaningful concepts to humans are, to the bot, just letters encountered in the training set frequently paired with other letters.
New research on AI’s lack of medical reasoning
Recently, a team of researchers set out to investigate whether AIs that achieved near-perfect accuracy on medical benchmarks like MedQA actually reasoned through medical problems or simply exploited statistical patterns in their training data. If doctors and patients more widely rely on AI tools for diagnosis, it becomes critical to understand the capability of AI when faced with novel clinical scenarios.
The researchers took 100 questions from MedQA, a standard dataset of multiple-choice medical questions collected from professional medical board exams, and replaced the original correct answer choice with “None of the other answers.” If the AI was simply pattern-matching to its training data, the change should prove devastating to its accuracy. On the other hand, if there was reasoning behind its answers the negative effect should be minimal.
Sure enough, they found that when an AI was faced with a question that deviates from the familiar answer patterns it was trained on, there was a substantive decline in accuracy, from 80% to 42% accuracy. This is because AI today are still just probability calculators, not artful thinkers.
Artful medical practitioners see, hear, feel, and recognize medical conditions in ways they are often not consciously aware of. While an AI would be thrown off by an unfamiliar description of symptoms, good doctors listen to the specific word choices of patients and try to understand. They appreciate how societal factors can impact health, trusting both their own intuitions and those of the patient. They pay close attention to all the presenting symptoms in an open-minded manner, as opposed to algorithmically placing the patient in a generic diagnostic box.
Healing is more than a single task
And yet, algorithmic supremacists are as confident as ever in their belief that human healthcare providers will be replaced by machines. In 2016, at the Machine Learning and Market for Intelligence Conference in my hometown of Toronto, Geoffrey Hinton took the mic to confidently assert: “If you work as a radiologist, you are like Wile E. Coyote in the cartoon. You’re already over the edge of the cliff, but you haven’t yet looked down … People should stop training radiologists now. It’s just completely obvious that in five years deep learning is going to do better than radiologists.”
Seven years later, well past the five-year deadline, Kevin Fischer, CEO of Open Souls, attacked Hinton’s erroneous AI prediction, explaining how tech boosters home in on a single behavior against some task and then extrapolate broader implications based on that single task alone. The reality is that reducing any job, especially a wildly complex job that requires a decade of training, to a handful of tasks is absurd.
As Fischer explains, radiologists have a 3D world model of the brain and its physical dynamics in their head, which they use when interpreting the results of a scan. An AI tasked with analysis is simply performing 2D pattern recognition. Furthermore, radiologists have a host of grounded models they use to make determinations, and, when they think artfully, one of the most important is whether something “feels” off. A large part of their job is communicating their findings with fellow human physicians. Further, human radiologists need to see only a single example of a rare and obscure condition to both remember it and identify it in the future, unlike algorithms, which struggle with what to do with statistical outliers.
So, by all means, use whatever tools you can access to help your wellness. But be mindful of the difference between a medical calculator and an artful thinker.
-
Tools & Platforms3 weeks ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Business2 days ago
Business2 days agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-

 Ethics & Policy1 month ago
Ethics & Policy1 month agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences3 months ago
Events & Conferences3 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers2 months ago
Jobs & Careers2 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Funding & Business2 months ago
Funding & Business2 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries
-

 Education2 months ago
Education2 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi
-

 Mergers & Acquisitions2 months ago
Mergers & Acquisitions2 months agoDonald Trump suggests US government review subsidies to Elon Musk’s companies