Ethics & Policy
Analysing AI Ethics… Using AI!

By: Alex Cline, Alice Helliwell, Brian Ball, David Freeborn and Kevin Loi-Heng
Project supported by the Ethics Institute, the Internet Democracy Initiative and NULab, at Northeastern University
What can computational methods–particularly artificial intelligence (AI)–tell us about AI ethics? We are a group of researchers who have become intrigued by what such methods can add to philosophical studies, and vice versa. In the programmes at Northeastern University London,[1] we are interested in AI ethics. Education in this subject forms an integral part of our teaching, particularly on our MA Philosophy and Artificial Intelligence and our MSc AI and Ethics. Our students have a wide range of backgrounds, (though many have been trained in either philosophy or computer/data science). Our aim is to provide philosophical and computational education simultaneously, to equip students with the skills they need to responsibly engage with AI technology.
Given this ethos, we have decided to turn use of computational methodologies on our own practice, by investigating some of our philosophy courses on these programmes. Our aim is to gain insight into our pedagogical approach and to develop a project which we can (hopefully) share with our students. In fact, one of the researchers on this project (Kevin Loi-Heng) is an alumnus of our MSc! So far, we have found this process to be surprising and rewarding.
In order to test our thought that computational tools can be useful for pedagogical and philosophical goals, we decided to conduct a computational analysis of the texts we set for students across two courses: AI and Data Ethics, and Advanced Topics in Responsible AI. We have (rather grandiosely) called this our ‘canon analysis’. Of course, we did not gather these papers with the intention that they truly be a ‘canon’ of AI ethics. We have curated them over several years, and after completing both courses, we want our students to have covered a variety of classic and current topics in AI ethics and responsible AI. Having gathered the recommended texts for these courses, we utilised some standard Python-based natural language processing (NLP) techniques to analyse our corpus of texts.
Absolute Word-frequency Analysis
The first analytic tool we turned on our corpus was a word frequency counter. This simple computational technique counts the number of times a word appears in a document, or collection of documents. This allowed us to identify the words that appear most frequently in our collection of papers, and produce the word cloud below (where the most frequently used words appear largest in size):
To our surprise, we found that across our two courses, the highest frequency unique word used was ‘human’! Perhaps, as scholars in the ‘humanities’ this shouldn’t have been unexpected to us, however we consider this corpus of texts to be primarily concerned with technology and ethics. It may be that the authors used on our courses are contrasting humans with the data (2nd most common) and machines (8th most common) that are their explicit focuses.
Term frequency itself has limited utility for telling us about unique features of a corpus of texts. It could be, for example, that (contrary to the conjecture at the end of the last paragraph) ‘human’ is something that comes up in philosophical works in general. To find out more about the unique features of this body of texts, we conducted another analysis.
Relative Word Frequency Analysis
Surprised at the most frequent word being ‘human’ we decided to analyse word-frequency further. We ran another measure on the corpus: a TF-IDF (Term Frequency–Inverse Document Frequency). This NLP technique is typically used to evaluate the relative importance of a word in a document compared to its importance in the corpus as a whole. Rather than simply counting the frequency of use for each word, a TF-IDF can show which words are more common in our AI Ethics corpus compared to a larger, or alternative, corpus of texts.
Of course, in this case we were not just interested here in individual papers, but the body of works (our AI ethics ‘canon’) as a whole. In order to complete a TF-IDF measure then, we required a contrasting corpus of texts. It just so happened that, following the Wittgenstein and AI conference and edited collections some of us had recently produced (see volume 1 and volume 2), we had a ‘Wittgenstein Corpus’ available; a body of papers (accessed through JSTOR) discussing the work of Wittgenstein.
| Top 10 words: AI Ethics Canon | Top 10 words: Wittgenstein Corpus |
| human | philosophy |
| ethic | Wittgenstein |
| moral | philosophical |
| robot | language |
| data | theory |
| system | political |
| technology | social |
| design | review |
| agent | science |
| develop | knowledge |
When we compare these two analyses, we start to see the relative importance of these terms in the text. ‘Human’, for example, is not just the most frequent unique word, but it’s particularly important in the AI ethics papers compared to works discussing Wittgenstein. ‘Wittgenstein’ is the second most important word in the Wittenstein papers (a comforting sign that our analysis was working).
Using AI: Semantic clustering
Few nowadays would consider the techniques we have discussed so far to involve AI: in particular, the computational methods employed operate directly on textual data, here the full papers from our two course reading lists. Since research papers are written in natural language, they need to be converted into a numerical format that a computer can read and interpret if contemporary AI techniques are to be deployed on them. We did this using SciBERT, a state-of-the-art transformer model pre-trained on scientific texts. This allowed us to turn each paper into a unique vector (essentially a high-dimensional mathematical fingerprint) that captures the meaning of the text.
Once we had numerical representations of each paper, we compared them to each other using cosine similarity. This helped us measure how closely related different papers are based on their content. A similarity score of 1 means two papers are essentially the same, while a score close to 0 means they are very different.
Using this measure of similarity we attempted to draw out where papers in our canon were grouped together around different subjects and themes. To examine this, we utilised a couple of methods. First, we applied K-Means clustering,an unsupervised machine learning technique that groups papers into clusters based on their similarity. It works on unlabeled data (without defined categories or groups). The algorithm first randomly selects central points (centroids), then uses algorithms to automatically find common themes and structures in the data. We repeated the clustering with different k values to find different groupings. By experimenting with different k values we determined the best number of clusters. For this we used techniques like the Elbow Method and Silhouette Score to find a suitable number given the tradeoff between better representing the data and using more clusters. We decided on six clusters to move forwards.

K-means struggles to deal with as many dimensions as provided by SciBERT’s analysis of the papers, so we had to process the data further. We did a principal component analysis (PCA) to reduce the dimensionality of the data. PCA is a linear algebra technique which finds directions in the data that can explain the greatest proportion of variance. We utilised 112 components, as this explained 95% of the variance in our data. Having reduced the dimensionality of our data, we conducted K-means clustering.
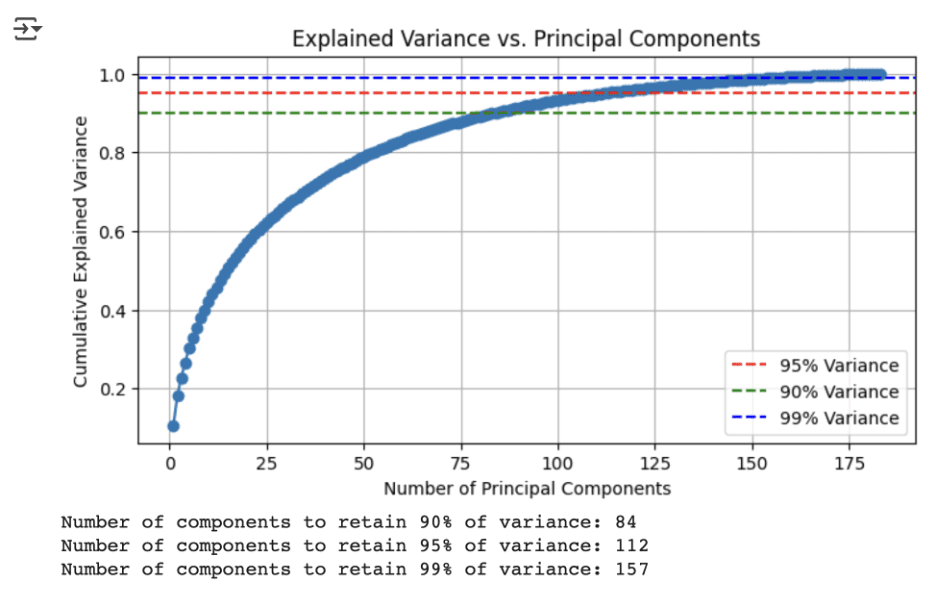
To ensure that the clustering results were meaningful, we checked whether each paper had the highest similarity to the average of its assigned cluster. The fact that 100% of papers were most similar to their own cluster’s average reassured us that the model was making reasonable groupings. In order to visualise these clusters, we needed to conduct further processing on this data, again using PCA, to reduce the clusters to two dimensions. This two dimensional data could then be visualised on a series of graphs, using difference

When we looked at which papers fell in each cluster, however, we had a hard time interpreting these clusters. We couldn’t clearly determine which topic/s in AI ethics were key for each cluster. This was likely due to the high dimensionality, and the small number of papers included in our analysis. We are reminded that contemporary AI relies on BIG data! We therefore tried an alternative method for grouping the papers in our canon.
Using AI: Topic Analysis
We next used the Latent Dirichlet Allocation (LDA) method to examine the canon, to see if the paper groupings produced made more sense to us. LDA is also an unsupervised machine learning approach. However, unlike K-means, we can use LDA to gather papers under topics, and to then produce a list of words for each topic, making it more interpretable.
LDA is a soft clustering method, which models probability distributions over words and documents. When we use LDA to analyse papers, it treats each paper as a collection of words – i.e. it does not consider the position of each word in the paper (unlike SciBERT). LDA builds a model of the whole corpus, and tries to identify distinct topics by finding correlations between words. Frequent co-occurrence of words suggests they are related in a topic, whereas non-co-occurrence of words suggests they are not related in a topic.
Our output from LDA is a series of probabilities. For each paper we get a probability that it falls in each topic (six topics). A paper is therefore not just assigned to one topic – instead, it can have a high probability of concerning multiple topics. This may be for good reason – for example, an overview paper might end up having a high probability of concerning e.g. ‘privacy’ ‘AI design’ and ‘robot agency’ (etc).
From examining the topics uncovered in this manner, we felt like we could make some sense of them. We identified the broad themes of each topic as follows:
Topic clusters:
0: Social, social media, gender, culture
1: Superintelligence
2: Applied issues such as sustainability, health, and the arts
3: Robots, personhood, and artificial agency
4: Design, responsibility
5: Privacy and risk

These topics certainly seemed to us to have some internal unity (as indicated), but they could also be seen not to overlap one another in problematic ways. Looking at the percentage of the papers in one topic (the row in the above table) that overlapped with papers in the other topic (in the columns), we found both that the overlap was not in general too great, and that such overlap as there was could be readily interpreted. For example, 52.9% of the papers on superintelligence could also be viewed as concerned with a topic involving the notion of artificial agency, which is understandable given that ethical concerns around the former appeal to the latter; moreover, looking at the column corresponding to superintelligence, we see that it is entirely blue, meaning that none of the other topics overlapped much with it – and indeed, our impression from working within the field is that this topic does, as a matter of sociological fact about the AI ethics community, stand somewhat apart.
What can AI tell us about philosophy
AI-powered knowledge discovery is being widely applied in STEM fields like biology and genomics, and for drug-discovery etc.; but these advancements have not, on the whole, extended into the humanities and social sciences, including philosophy (which has historically played an integral part in AI development). Some progress has been made in using NLP techniques, with the availability of pre-trained LLMs which offer some promising utility to help process textual data. Our research leverages these methods to begin to make sense of a growing academic literature in AI ethics – at least how we have presented it to students. In the future, we hope to continue our analysis of AI ethics literature, and share this with our students to gain their perspective of how this analysis meshes with their understanding of our courses.
[1] Alex Cline has now started working for Queen Mary University London.

This article is the eighth part of a nine-part series that unpacks the evolution of intelligence, the rise of artificial intelligence, and its profound impact on jobs, ethics, society and purpose. The series will help readers understand how AI is reshaping job roles and what skills will matter most, reflect on ethical and psychological shifts AI may trigger in the workplace, and ask better questions about education, inclusion and purpose.
“We are called to be architects of the future, not its victims.” — R Buckminster Fuller
Tom, now older, walks through a forest near his childhood village. He’s mentoring young students in ethics and technology. One asks, “What’s the point of all this AI if people are still lonely or hungry?” Tom smiles. “That’s the right question,” he says. He believes the purpose of intelligence—natural or artificial—is not domination, but compassion. As the sun sets, he feels a quiet hope. Maybe the future isn’t about smarter machines, but wiser humans.
What Is the Purpose of Human Life?
This question has echoed through philosophy, religion, and art for millennia. Is our purpose to create? To love? To understand? To serve?
In the age of AI, this question becomes urgent. If machines can think, work, and even simulate emotion—what is left for us?
The answer may lie not in what AI can do, but in what it cannot. AI can optimize, but it cannot care. It can simulate empathy, but it cannot suffer. It can generate beauty, but it cannot feel awe.
And perhaps most importantly, it cannot choose to care. Humans don’t just feel emotions—they act from them. Love becomes sacrifice. Awe becomes protection. Sorrow becomes protest. These are not lines of code—they are the beating pulse of a conscious life.
Human purpose is not just about intelligence—it’s about consciousness, connection, and conscience. As we delegate more tasks to machines, we must double down on what makes us human: our ability to give meaning, to endure suffering with grace, and to find joy beyond utility.
Fairness in the Age of AI
As AI reshapes the world, fairness must be our compass. This means:
• Equity of access: Ensuring rural, tribal, and marginalized communities are not left behind.
• Ethical design: Building AI that respects privacy, dignity, and diversity.
• Inclusive governance: Giving all voices a seat at the table—especially those most affected.
Tom remembers the tribal families he met as a child—struggling for water, ignored by systems. He remembers villages with no digital access but rich with oral traditions. These were not data-rich zones, but they were wisdom-rich. Yet algorithms rarely hear from them.
We must avoid building systems that optimize only for the lives of the loudest and most visible. Fairness is not a technical feature—it’s a moral stance. It demands that we look beyond convenience and efficiency and ask: Who benefits? Who is harmed? Who is invisible?
We don’t just need inclusive tools; we need inclusive visions.
Designing for Humanity
Technology is not destiny. It reflects the values of its creators. We must design AI that:
• Amplifies human potential, not replaces it.
• Supports mental and emotional wellbeing, not exploits it.
• Strengthens communities, not isolates individuals.
Designing AI for humanity means resisting the seductive pull of efficiency above all else. It means asking how our tools shape habits, culture, and relationships. If social media algorithms reward outrage, then outrage becomes the norm. If hiring systems absorb historical bias, injustice persists in digital form.
Design must go beyond usability and user experience—it must ask what kind of world a system makes more likely. This is the new design brief: Create systems that leave people more whole, not more addicted. More curious, not more cynical. More connected, not more fragmented.
This requires collaboration between technologists, ethicists, educators, artists, and citizens. It requires wisdom, not just intelligence. It means slowing down sometimes—not to delay innovation, but to deepen it.
A Day in Tom’s Life
Tom, now a mentor and elder voice in the AI community, shares less about the howof machines, and more about the whyof life. He spends time with students—not teaching code, but teaching compassion. He listens more than he speaks. He reminds them that no breakthrough matters if it does not help someone in need.
He tells them stories of people building low-cost translation apps for Indigenous languages. Of students using AI to map missing persons in disaster zones. Of technologists who left big salaries to work on open-source tools for refugees and teachers.
Every day, he sees how young people are not just hungry for power—they are hungry for meaning. His role, he feels, is not to give them answers, but to help them ask better questions.
The Social Media Mirror
Online, the narrative is shifting. People are asking deeper questions:
What kind of world are we building?
Who gets to decide?
What does it mean to live a good life in the age of AI?
Social media, for all its toxicity, is also a mirror. It reflects our fears, but also our longing. In a sea of memes and misinformation, you can still find grassroots movements, intergenerational conversations, and voices previously unheard.
Tom sees young creators using AI to tell stories of justice. He sees elders sharing wisdom through digital platforms. He sees a new kind of intelligence emerging—not artificial, but collective.
It’s messy. It’s imperfect. But it’s alive—and that may be what matters most.
The Bigger Picture
AI is not the end of the human story. It is a new chapter—one that forces us to grow, not just technologically, but morally and spiritually.
The future will not be written by machines. It will be written by the decisions we make—about fairness, about purpose, and about what we choose to protect.
And so, we must widen our lens. The question is not just what the future of AI is. It is what the future of us will be. Will we use our tools to colonize or to collaborate? To extract or to restore? To automate apathy—or awaken empathy?
There are many futures available. But only one will be chosen.
Critique: The Ethical Blind Spot
Even now, the ethical framework around AI remains thin. We build models that can mimic genius but forget to embed values. We train AI on global data but deploy it in cultural vacuums. We idolize “intelligence” but devalue wisdom.
Education systems are outdated. Regulation is reactionary. Moral discourse often lags behind technological disruption. The deepest failure isn’t technical—it’s philosophical.
We must ask not only: What can AI do?
But also: What should we do with it?
And more importantly: Who are we becoming because of it?
When efficiency becomes a religion, we forget how to honour slowness. When scale becomes the goal, we overlook the sacred. When simulation replaces presence, we lose the texture of real life.
Tom’s critique is not anti-technology. It’s pro-humanity. He warns that a society obsessed with progress, but blind to meaning, will eventually lose both.
Why This Chapter Matters
This chapter isn’t about AI—it’s about us.
About what we value. About who we include. About the kind of world we’re willing to imagine—and fight for.
The journey of intelligence—from neurons to nations, from fire to fibre optics—has brought us to a profound crossroads.
Now we must ask:
Will we build a future of algorithms, or a future of ethics? Will we pursue power, or purpose?
That answer is still human.
Coming Up Next
Final Chapter – The Rise of Machine Intelligence: Utopia or Dystopia?
We enter uncharted territory. A world where intelligence is no longer human-only. What does it mean when machines begin to surpass our minds? Will we see abundance—or collapse? Evolution— or extinction?
Join us as we explore the edge of what comes next.
DISCLAIMER: The views expressed are solely of the author and ETHRWorld does not necessarily subscribe to it. ETHRWorld will not be responsible for any damage caused to any person or organisation directly or indirectly.

Ethics & Policy
Vatican Hosts Historic “Grace for the World” Concert and AI Ethics Summit | Ukraine news

Crowds gather in St. Peter’s Square for the concert ‘Grace for the World,’ co-directed by Andrea Bocelli and Pharrell Williams, as part of the World Meeting on Human Fraternity aimed at promoting unity, in the Vatican, September 13, 2025. REUTERS/Ciro De Luca
According to CNN CNN
In the Vatican, a historic concert titled “Grace for the World” took place, which for the first time brought together world pop stars on St. Peter’s Square. The event featured John Legend, Teddy Swims, Karol G, and other stars, and the broadcast was provided by CNN and ABC News. The concert occurred as part of the Third World Meeting on Human Fraternity and was open to everyone.
During the event, performances spanning various genres graced the stage. Among the participants were Thai rapper Bambam from GOT7, Black Eyed Peas frontman Will.i.am, and American singer Pharrell Williams. Between performances, Vatican cardinals addressed the audience with calls to remain humane and to uphold mutual respect among people.
Key Moments of the Event
“to remain humane”
Within the framework of the Third World Meeting on Human Fraternity in the Vatican, the topic of artificial intelligence and ethical regulation of its use was also discussed. The summit participants emphasized the need to establish international norms and governance systems for artificial intelligence to ensure the safety of societies. Leading experts joined the discussion: Geoffrey Hinton, known as the “godfather of artificial intelligence,” Max Tegmark from the Massachusetts Institute of Technology, Khimena Sofia Viveros Alvarez, and Marco Trombetti, founder of Translated. Pope Leo XIV also participated in the discussion and reaffirmed the position of the previous pope regarding the establishment of a single agreement on the use of artificial intelligence.
“to define local and international pathways for developing new forms of social charity and to see the image of God in the poor, refugees, and even adversaries.”
They also discussed the risk of the digital divide between countries with access to AI and those without such access. Participants urged concrete local and international initiatives aimed at developing new forms of social philanthropy and supporting the most vulnerable segments of the population.
Other topics you might like:
Ethics & Policy
Pet Dog Joins Google’s Gemini AI Retro Photo Trend! Internet Can’t Get Enough | Viral Video | Viral

Beautiful retro pictures of people in breathtaking ethics in front of an esthetically pleasing wall under the golden hour is currently what is going on on social media! All in all, a new trend is in the ‘internet town’ and it’s spreading- fast. For those not aware, it’s basically a trend where netizens are using Google’s Gemini AI to create a rather beautiful retro version of themselves. In a nutshell, social media is currently full of such pictures. However, when this PET DOG joined the bandwagon, many instantly declared the furry one the winner- and for obvious reasons. The video showed the trend being used on the pet dog- the result of which was simply heartwarming. The AI generated pictures showed the cute one draped in multiple dupattas, with ears that looked like the perfect hairstyle one can ask for- for their pets. Most netizens loved the video, while some expressed their desire to try the same on their pets. Times Now could not confirm the authenticity of the post. Image Source: Jinnie Bhatt/ Instagram
-

 Business2 weeks ago
Business2 weeks agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-
Tools & Platforms1 month ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy2 months ago
Ethics & Policy2 months agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences4 months ago
Events & Conferences4 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers3 months ago
Jobs & Careers3 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Education3 months ago
Education3 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Education2 months ago
Education2 months agoMacron says UK and France have duty to tackle illegal migration ‘with humanity, solidarity and firmness’ – UK politics live | Politics
-

 Funding & Business3 months ago
Funding & Business3 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi