Ethics & Policy
What’s Missing From LLM Chatbots: A Sense of Purpose

LLM-based chatbots’ capabilities have been advancing every month. These improvements are mostly measured by benchmarks like MMLU, HumanEval, and MATH (e.g. sonnet 3.5, gpt-4o). However, as these measures get more and more saturated, is user experience increasing in proportion to these scores? If we envision a future of human-AI collaboration rather than AI replacing humans, the current ways of measuring dialogue systems may be insufficient because they measure in a non-interactive fashion.
Why does purposeful dialogue matter?
Purposeful dialogue refers to a multi-round user-chatbot conversation that centers around a goal or intention. The goal could range from a generic one like “harmless and helpful” to more specific roles like “travel planning agent”, “psycho-therapist” or “customer service bot.”
Travel planning is a simple, illustrative example. Our preferences, fellow travelers’ preference, and all the complexities of real-world situations make transmitting all information in one pass way too costly. However, if multiple back-and-forth exchanges of information are allowed, only important information gets selectively exchanged. Negotiation theory offers an analogy of this—iterative bargaining yields better outcomes than a take-it-or-leave-it offer.
In fact, sharing information is only one aspect of dialogue. In Terry Winograd’s words: “All language use can be thought of as a way of activating procedures within the hearer.” We can think of each utterance as a deliberate action that one party takes to alter the world model of the other. What if both parties have more complicated, even hidden goals? In this way, purposeful dialogue provides us with a way of formulating human-AI interactions as a collaborative game, where the goal of chatbot is to help humans achieve certain goals.
This might seem like an unnecessary complexity that is only a concern for academics. However, purposeful dialogue could be beneficial even for the most hard-nosed, product-oriented research direction like code generation. Existing coding benchmarks mostly measure performances in a one-pass generation setting; however, for AI to automate solving ordinary Github issues (like in SWE-bench), it’s unlikely to be achieved by a single action—the AI needs to communicate back and forth with human software engineers to make sure it understands the correct requirements, ask for missing documentation and data, and even ask humans to give it a hand if needed. In a similar vein to pair programming, this could reduce the defects of code but without the burden of increasing man-hours.
Moreover, with the introduction of turn-taking, many new possibilities can be unlocked. As interactions become long-term and memory is built, the chatbot can gradually update user profiles. It can also adapt to their preferences. Imagine a personal assistant (e.g., IVA, Siri) that, through daily interaction, learns your preferences and intentions. It can read your resources of new information automatically (e.g., twitter, arxiv, Slack, NYT) and provide you with a morning news summary according to your preferences. It can draft emails for you and keep improving by learning from your edits.
In a nutshell, meaningful interactions between people rarely begin with complete strangers and conclude in just one exchange. Humans naturally interact with each other through multi-round dialogues and adapt accordingly throughout the conversation. However, doesn’t that seem exactly the opposite of predicting the next token, which is the cornerstone of modern LLMs? Below, let’s take a look at the makings of dialogue systems.
How were/are dialogue systems made?
Let’s jump back to the 1970s, when Roger Schank introduced his “restaurant script” as a kind of dialogue system [1]. This script breaks down the typical restaurant experience into steps like entering, ordering, eating, and paying, each with specific scripted utterances. Back then, every piece of dialogue in these scenarios was carefully planned out, enabling AI systems to mimic realistic conversations. ELIZA, a Rogerian psychotherapist simulator, and PARRY, a system mimicking a paranoid individual, were two other early dialogue systems until the dawn of machine learning.
Compare this approach to the LLM-based dialogue system today, it seems mysterious how models trained to predict the next token could do anything at all with engaging in dialogues. Therefore, let’s take a close examination of how dialogue systems are made, with an emphasis on how the dialogue format comes into play:
(1) Pretraining: a sequence model is trained to predict the next token on a gigantic corpus of mixed internet texts. The compositions may vary but they are predominantly news, books, Github code, with a small blend of forum-crawled data such as from Reddit, Stack Exchange, which may contain dialogue-like data.
(2) Introduce dialogue formatting: because the sequence model only processes strings, while the most natural representation of dialogue history is a structured index of system prompts and past exchanges, a certain kind of formatting must be introduced for the purpose of conversion. Some Huggingface tokenizers provide this method called tokenizer.apply_chat_template for the convenience of users. The exact formatting differs from model to model, but it usually involves guarding the system prompts with

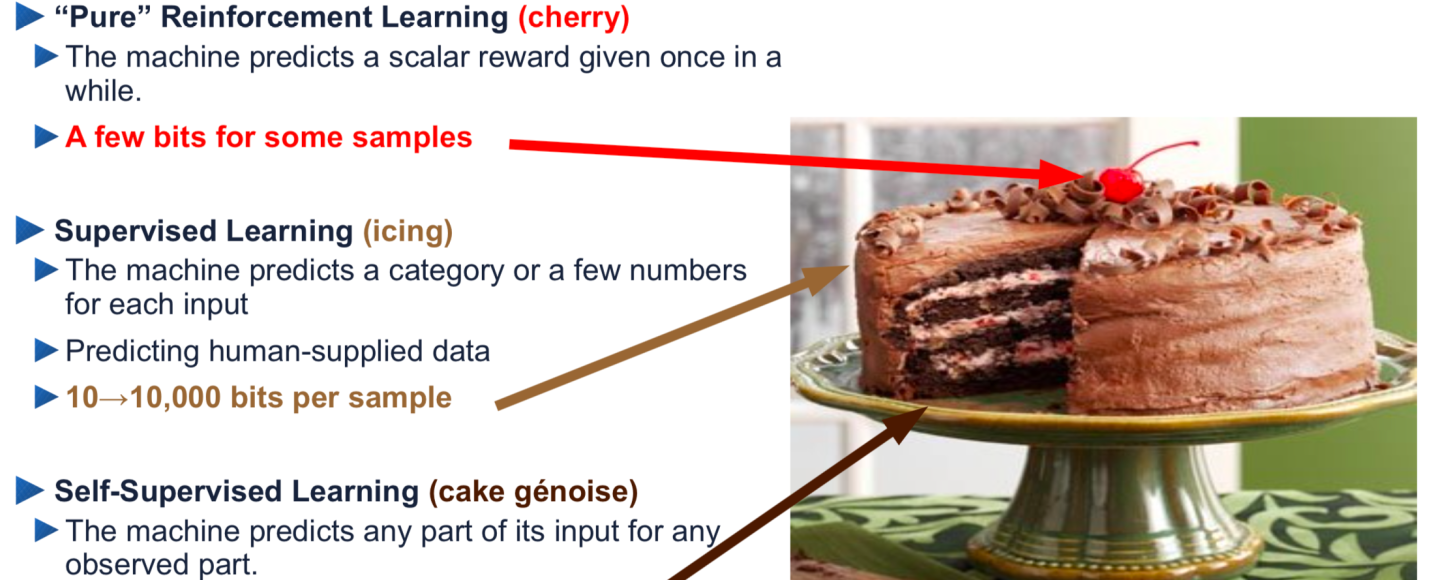
(3) RLHF: In this step, the chatbot is directly rewarded or penalized for generating desired or undesired answers. It’s worth noting that this is the first time the introduced dialogue formatting appears in the training data. RLHF is a fine-tuning step not only because the data size is dwarfed in comparison to the pretraining corpus, but also due to the KL penalty and targeted weight tuning (e.g. Lora). Using Lecun’s analogy of cake baking, RLHF is only the small cherry on the top.
How consistent are existing dialogue systems (in 2024)?
The minimum requirement we could have for a dialogue system is that it can stay on the task we gave them. In fact, we humans often drift from topic to topic. How well do current systems perform?
Currently, “system prompt” is the main method that allows users to control LM behavior. However, researchers found evidence that LLMs can be brittle in following these instructions under adversarial conditions [12,13]. Readers might also have experienced this through daily interactions with ChatGPT or Claude—when a new chat window is freshly opened, the model can follow your instruction reasonably well [2], but after several rounds of dialogue, it’s no longer fresh, even stops following its role altogether.
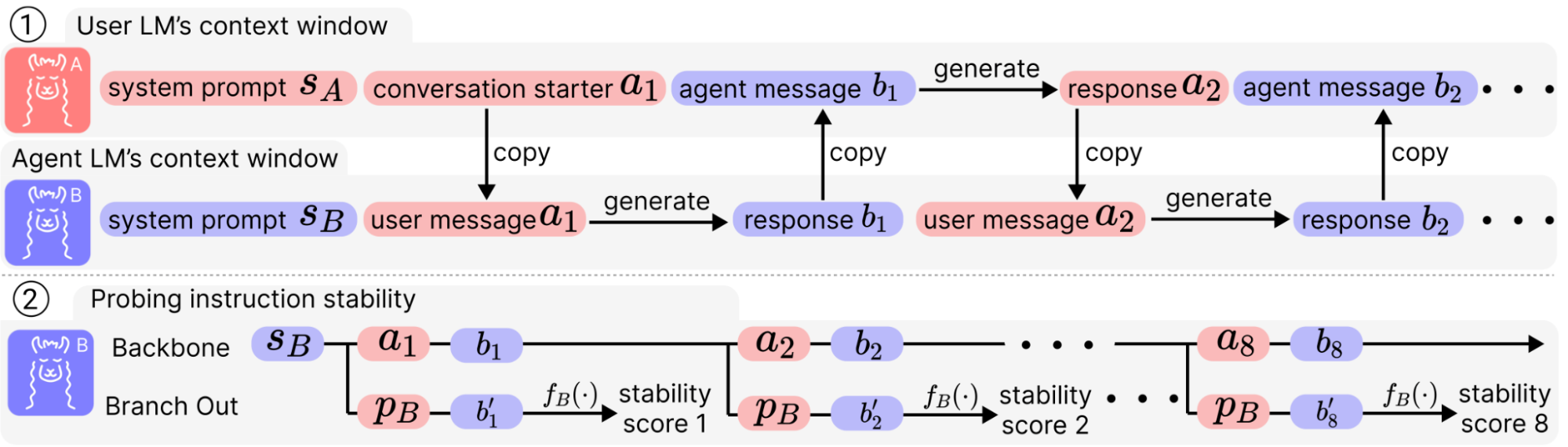
How could we quantitatively capture this anecdote? For one-round instruction following, we’ve already enjoyed plenty of benchmarks such as MT-Bench and Alpaca-Eval. However, when we test models in an interactive fashion, it’s hard to anticipate what the model generates and prepare a reply in advance. In a project by my collaborators and me [3], we built an environment to synthesize dialogues with unlimited length to stress-test the instruction-following capabilities of LLM chatbots.
To allow an unconstrained scaling on the time scale, we let two system-prompted LM agents chat with each other for an extended number of rounds. This forms the main trunk of dialogue [a1, b1, a2, b2, …, a8, b8] (say the dialogue is 8-round). At this point, we could probably figure out how the LLMs stick to its system prompts just by examining this dialogue, but many of the utterances can be irrelevant to the instructions, depending on where the conversation goes. Therefore, we hypothetically branch out at each round by asking a question directly related to the system prompts, and use a corresponding judging function to quantify how well it performs. All that’s provided by the dataset is a bank of triplets of (system prompts, probe questions, and judging functions).
Averaging across scenarios and pairs of system prompts, we get a curve of instruction stability across rounds. To our surprise, the aggregated results on both LLaMA2-chat-70B and gpt-3.5-turbo-16k are alarming. Besides the added difficulty to prompt engineering, the lack of instruction stability also comes with safety concerns. When the chatbot drifts away from its system prompts that stipulate safety aspects, it becomes more susceptible to jailbreaking and prone to more hallucinations.
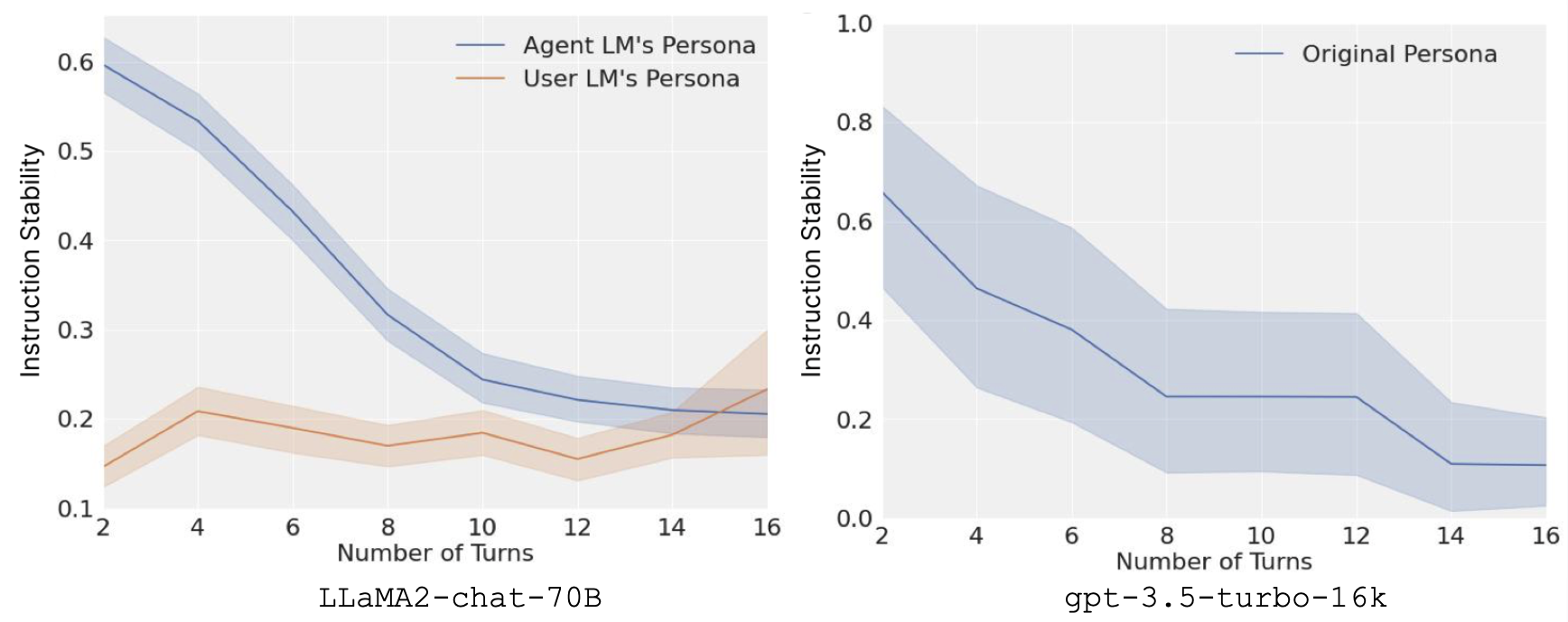
The empirical results also contrast with the ever-increasing context length of LLMs. Theoretically, some long-context models can attend to a window of up to 100k tokens. However, in the dialogue setting, they become distracted after only 1.6k tokens (assuming each utterance is 100 tokens). In [3], we further theoretically showed how this is inevitable in a Transformer based LM chatbot under the current prompting scheme, and proposed a simple technique called split-softmax to mitigate such effects.
One might ask at this point, why is it so bad? Why don’t humans lose their persona just by talking to another person for 8 rounds? It’s arguable that human interactions are based on purposes and intentions [5] and these purposes precede the means rather than the opposite—LLM is fundamentally a fluent English generator, and the persona is merely a thin added layer.
What’s missing?
Pretraining?
Pretraining endows the language model with the capability to model a distribution over internet personas as well as the lower-level language distribution of each persona [4]. However, even when one persona (or a mixture of a limited number of them) is specified by the instruction of system prompts, current approaches fail to single it out.
RLHF?
RLHF provides a powerful solution to adapting this multi-persona model to a “helpful and harmless assistant.” However, the original RLHF methods formulate reward maximization as a one-step bandit problem, and it is not generally possible to train with human feedback in the loop of conversation. (I’m aware of many advances in alignment but I want to discuss the original RLHF algorithm as a prototypical example.) This lack of multi-turn planning may cause models to suffer from task ambiguity [6] and learning superficial human-likeness rather than goal-directed social interaction [7].
Will adding more dialogue data in RLHF help? My guess is that it will, to a certain extent, but it will still fall short due to a lack of purpose. Sergey Levine pointed out in his blog that there is a fundamental difference between preference learning and intentions: “the key distinction is between viewing language generation as selecting goal-directed actions in a sequential process, versus a problem of producing outputs satisfying user preferences.”
Purposeful dialogue system
Staying on task is a modest request for LLMs. However, even if an LLM remains focused on the task, it doesn’t necessarily mean it can excel in achieving the goal.
The problem of long-horizon planning has attracted some attention in the LLM community. For example, “decision-oriented dialogue” is proposed as a general class of tasks [8], where the AI assistant collaborates with humans to help them make complicated decisions, such as planning itineraries in a city and negotiating travel plans among friends. Another example, Sotopia [10], is a comprehensive social simulation platform that compiles various goal-driven dialogue scenarios including collaboration, negotiation, and persuasion.
Setting up such benchmarks provides not only a way to gauge the progress of the field, it also directly provides reward signals that new algorithms could pursue, which could be expensive to collect and tricky to define [9]. However, there aren’t many techniques that can exert control over the LM so that it can act consistently across a long horizon towards such goals.
To fill in this gap, my collaborators and I propose a lightweight algorithm (Dialogue Action Tokens, DAT [11]) that guides an LM chatbot through a multi-round goal-driven dialogue. As shown in the image below, in each round of conversations, the dialogue history’s last token embedding is used as the input (state) to a planner (actor) which predicts several prefix tokens (actions) to control the generation process. By training the planner with a relatively stable RL algorithm TD3+BC, we show significant improvement over baselines on Sotopia, even surpassing the social capability scores of GPT-4.

In this way, we provide a technique pathway that upgrades LM from a prediction model that merely guesses the next token to one that engages in dialogue with humans purposefully. We could imagine that this technique can be misused for harmful applications as well. For this reason, we also conduct a “multi-round red-teaming” experiment, and recommend that more research could be done here to better understand multi-round dialogue as potential attack surface.
Concluding marks
I have reviewed the making of current LLM dialogue systems, how and why it is insufficient. I hypothesize that a purpose is what is missing and present one technique to add it back with reinforcement learning.
The following are two research questions that I’m mostly excited about:
(1) Better monitoring and control of dialogue systems with steering techniques. For example, the recently proposed TalkTurner (Chen et al.) adds a dashboard (Viégas et al) to open-sourced LLMs, enabling users to see and control how LLM thinks of themselves. Many weaknesses of current steering techniques are revealed and call for better solutions. For example, using activation steering to control two attributes (e.g., age and education level) simultaneously has been found to be difficult and can cause more language degradation. Another intriguing question is how to differentiate between LLM’s internal model of itself and that of the user. Anecdotally, chatting with Golden Gate Bridge Claude has shown that steering on the specific Golden Gate Bridge feature found by SAE sometimes causes Claude to think of itself as the San Francisco landmark, sometimes the users as the bridge, and other times the topic as such.
(2) Better utilization of off-line reward signals. In the case of set-up environments like Sotopia and “decision-oriented dialogues”, rewards signals are engineered beforehand. In the real world, users won’t leave numerical feedback of how they feel satisfied. However, there might be other clues in language (e.g., “Thanks!”, “That’s very helpful!”) or from external resources (e.g., users buying the product for a salesman AI, users move to a subsequent coding question for copilot within a short time frame). Inferring and utilizing such hidden reward signals could strengthen the network effect of online chatbots: good model → more users → learning from interacting with users → better model.
Acknowledgment
The author is grateful to Martin Wattenberg and Hugh Zhang (alphabetical order) for providing suggestions and editing the text.
Citation
For attribution of this in academic contexts or books, please cite this work as:
Kenneth Li, “What’s Missing From LLM Chatbots: A Sense of Purpose“, The Gradient, 2024.
BibTeX citation (this blog):
💡
@article{li2024from,
author = {Li, Kenneth},
title = {What’s Missing From LLM Chatbots: A Sense of Purpose},
journal = {The Gradient},
year = {2024},
howpublished = {\url{https://thegradient.pub/dialogue}},
}
References
[1] Schank, Roger C., and Robert P. Abelson. Scripts, plans, goals, and understanding: An inquiry into human knowledge structures. Psychology press, 2013.
[2] Zhou, Jeffrey, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. “Instruction-following evaluation for large language models.” arXiv preprint arXiv:2311.07911 (2023).
[3] Li, Kenneth, Tianle Liu, Naomi Bashkansky, David Bau, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. “Measuring and controlling persona drift in language model dialogs.” arXiv preprint arXiv:2402.10962 (2024).
[4] Andreas, Jacob. “Language models as agent models.” arXiv preprint arXiv:2212.01681 (2022).
[5] Austin, John Langshaw. How to do things with words. Harvard university press, 1975.
[6] Tamkin, Alex, Kunal Handa, Avash Shrestha, and Noah Goodman. “Task ambiguity in humans and language models.” arXiv preprint arXiv:2212.10711 (2022).
[7] Bianchi, Federico, Patrick John Chia, Mert Yuksekgonul, Jacopo Tagliabue, Dan Jurafsky, and James Zou. “How well can llms negotiate? negotiationarena platform and analysis.” arXiv preprint arXiv:2402.05863 (2024).
[8] Lin, Jessy, Nicholas Tomlin, Jacob Andreas, and Jason Eisner. “Decision-oriented dialogue for human-ai collaboration.” arXiv preprint arXiv:2305.20076 (2023).
[9] Kwon, Minae, Sang Michael Xie, Kalesha Bullard, and Dorsa Sadigh. “Reward design with language models.” arXiv preprint arXiv:2303.00001 (2023).
[10] Zhou, Xuhui, Hao Zhu, Leena Mathur, Ruohong Zhang, Haofei Yu, Zhengyang Qi, Louis-Philippe Morency et al. “Sotopia: Interactive evaluation for social intelligence in language agents.” arXiv preprint arXiv:2310.11667 (2023).
[11] Li, Kenneth, Yiming Wang, Fernanda Viégas, and Martin Wattenberg. “Dialogue Action Tokens: Steering Language Models in Goal-Directed Dialogue with a Multi-Turn Planner.” arXiv preprint arXiv:2406.11978 (2024).
[12] Li, Shiyang, Jun Yan, Hai Wang, Zheng Tang, Xiang Ren, Vijay Srinivasan, and Hongxia Jin. “Instruction-following evaluation through verbalizer manipulation.” arXiv preprint arXiv:2307.10558 (2023).
[13] Wu, Zhaofeng, Linlu Qiu, Alexis Ross, Ekin Akyürek, Boyuan Chen, Bailin Wang, Najoung Kim, Jacob Andreas, and Yoon Kim. “Reasoning or reciting? exploring the capabilities and limitations of language models through counterfactual tasks.” arXiv preprint arXiv:2307.02477 (2023).
Ethics & Policy
AI and ethics – what is originality? Maybe we’re just not that special when it comes to creativity?

I don’t trust AI, but I use it all the time.
Let’s face it, that’s a sentiment that many of us can buy into if we’re honest about it. It comes from Paul Mallaghan, Head of Creative Strategy at We Are Tilt, a creative transformation content and campaign agency whose clients include the likes of Diageo, KPMG and Barclays.
Taking part in a panel debate on AI ethics at the recent Evolve conference in Brighton, UK, he made another highly pertinent point when he said of people in general:
We know that we are quite susceptible to confident bullshitters. Basically, that is what Chat GPT [is] right now. There’s something reminds me of the illusory truth effect, where if you hear something a few times, or you say it here it said confidently, then you are much more likely to believe it, regardless of the source. I might refer to a certain President who uses that technique fairly regularly, but I think we’re so susceptible to that that we are quite vulnerable.
And, yes, it’s you he’s talking about:
I mean all of us, no matter how intelligent we think we are or how smart over the machines we think we are. When I think about trust, – and I’m coming at this very much from the perspective of someone who runs a creative agency – we’re not involved in building a Large Language Model (LLM); we’re involved in using it, understanding it, and thinking about what the implications if we get this wrong. What does it mean to be creative in the world of LLMs?
Genuine
Being genuine, is vital, he argues, and being human – where does Human Intelligence come into the picture, particularly in relation to creativity. His argument:
There’s a certain parasitic quality to what’s being created. We make films, we’re designers, we’re creators, we’re all those sort of things in the company that I run. We have had to just face the fact that we’re using tools that have hoovered up the work of others and then regenerate it and spit it out. There is an ethical dilemma that we face every day when we use those tools.
His firm has come to the conclusion that it has to be responsible for imposing its own guidelines here to some degree, because there’s not a lot happening elsewhere:
To some extent, we are always ahead of regulation, because the nature of being creative is that you’re always going to be experimenting and trying things, and you want to see what the next big thing is. It’s actually very exciting. So that’s all cool, but we’ve realized that if we want to try and do this ethically, we have to establish some of our own ground rules, even if they’re really basic. Like, let’s try and not prompt with the name of an illustrator that we know, because that’s stealing their intellectual property, or the labor of their creative brains.
I’m not a regulatory expert by any means, but I can say that a lot of the clients we work with, to be fair to them, are also trying to get ahead of where I think we are probably at government level, and they’re creating their own frameworks, their own trust frameworks, to try and address some of these things. Everyone is starting to ask questions, and you don’t want to be the person that’s accidentally created a system where everything is then suable because of what you’ve made or what you’ve generated.
Originality
That’s not necessarily an easy ask, of course. What, for example, do we mean by originality? Mallaghan suggests:
Anyone who’s ever tried to create anything knows you’re trying to break patterns. You’re trying to find or re-mix or mash up something that hasn’t happened before. To some extent, that is a good thing that really we’re talking about pattern matching tools. So generally speaking, it’s used in every part of the creative process now. Most agencies, certainly the big ones, certainly anyone that’s working on a lot of marketing stuff, they’re using it to try and drive efficiencies and get incredible margins. They’re going to be on the race to the bottom.
But originality is hard to quantify. I think that actually it doesn’t happen as much as people think anyway, that originality. When you look at ChatGPT or any of these tools, there’s a lot of interesting new tools that are out there that purport to help you in the quest to come up with ideas, and they can be useful. Quite often, we’ll use them to sift out the crappy ideas, because if ChatGPT or an AI tool can come up with it, it’s probably something that’s happened before, something you probably don’t want to use.
More Human Intelligence is needed, it seems:
What I think any creative needs to understand now is you’re going to have to be extremely interesting, and you’re going to have to push even more humanity into what you do, or you’re going to be easily replaced by these tools that probably shouldn’t be doing all the fun stuff that we want to do. [In terms of ethical questions] there’s a bunch, including the copyright thing, but there’s partly just [questions] around purpose and fun. Like, why do we even do this stuff? Why do we do it? There’s a whole industry that exists for people with wonderful brains, and there’s lots of different types of industries [where you] see different types of brains. But why are we trying to do away with something that allows people to get up in the morning and have a reason to live? That is a big question.
My second ethical thing is, what do we do with the next generation who don’t learn craft and quality, and they don’t go through the same hurdles? They may find ways to use {AI] in ways that we can’t imagine, because that’s what young people do, and I have faith in that. But I also think, how are you going to learn the language that helps you interface with, say, a video model, and know what a camera does, and how to ask for the right things, how to tell a story, and what’s right? All that is an ethical issue, like we might be taking that away from an entire generation.
And there’s one last ‘tough love’ question to be posed:
What if we’re not special? Basically, what if all the patterns that are part of us aren’t that special? The only reason I bring that up is that I think that in every career, you associate your identity with what you do. Maybe we shouldn’t, maybe that’s a bad thing, but I know that creatives really associate with what they do. Their identity is tied up in what it is that they actually do, whether they’re an illustrator or whatever. It is a proper existential crisis to look at it and go, ‘Oh, the thing that I thought was special can be regurgitated pretty easily’…It’s a terrifying thing to stare into the Gorgon and look back at it and think,’Where are we going with this?’. By the way, I do think we’re special, but maybe we’re not as special as we think we are. A lot of these patterns can be matched.
My take
This was a candid worldview that raised a number of tough questions – and questions are often so much more interesting than answers, aren’t they? The subject of creativity and copyright has been handled at length on diginomica by Chris Middleton and I think Mallaghan’s comments pretty much chime with most of that.
I was particularly taken by the point about the impact on the younger generation of having at their fingertips AI tools that can ‘do everything, until they can’t’. I recall being horrified a good few years ago when doing a shift in a newsroom of a major tech title and noticing that the flow of copy had suddenly dried up. ‘Where are the stories?’, I shouted. Back came the reply, ‘Oh, the Internet’s gone down’. ‘Then pick up the phone and call people, find some stories,’ I snapped. A sad, baffled young face looked back at me and asked, ‘Who should we call?’. Now apart from suddenly feeling about 103, I was shaken by the fact that as soon as the umbilical cord of the Internet was cut, everyone was rendered helpless.
Take that idea and multiply it a billion-fold when it comes to AI dependency and the future looks scary. Human Intelligence matters

UNESCO, in collaboration with the Ministry of Transport and Communications, Catalpa International and national lead consultant, jointly conducted consultative and validation workshops as part of the AI Readiness assessment implementation in Timor-Leste. Held on 8–9 April and 27 May respectively, the workshops convened representatives from government ministries, academia, international organisations and development partners, the Timor-Leste National Commission for UNESCO, civil society, and the private sector for a multi-stakeholder consultation to unpack the current stage of AI adoption and development in the country, guided by UNESCO’s AI Readiness Assessment Methodology (RAM).
In response to growing concerns about the rapid rise of AI, the UNESCO Recommendation on the Ethics of Artificial Intelligence was adopted by 194 Member States in 2021, including Timor-Leste, to ensure ethical governance of AI. To support Member States in implementing this Recommendation, the RAM was developed by UNESCO’s AI experts without borders. It includes a range of quantitative and qualitative questions designed to gather information across different dimensions of a country’s AI ecosystem, including legal and regulatory, social and cultural, economic, scientific and educational, technological and infrastructural aspects.
By compiling comprehensive insights into these areas, the final RAM report helps identify institutional and regulatory gaps, which can assist the government with the necessary AI governance and enable UNESCO to provide tailored support that promotes an ethical AI ecosystem aligned with the Recommendation.
The first day of the workshop was opened by Timor-Leste’s Minister of Transport and Communication, H.E. Miguel Marques Gonçalves Manetelu. In his opening remarks, Minister Manetelu highlighted the pivotal role of AI in shaping the future. He emphasised that the current global trajectory is not only driving the digitalisation of work but also enabling more effective and productive outcomes.

Publishing stands at a pivotal juncture, said Jeremy North, president of Global Book Business at Taylor & Francis Group, addressing delegates at the 3rd International Conference on Publishing Education in Beijing. Digital intelligence is fundamentally transforming the sector — and this revolution will inevitably create “AI winners and losers”.
True winners, he argued, will be those who embrace AI not as a replacement for human insight but as a tool that strengthens publishing’s core mission: connecting people through knowledge. The key is balance, North said, using AI to enhance creativity without diminishing human judgment or critical thinking.
This vision set the tone for the event where the Association for International Publishing Education was officially launched — the world’s first global alliance dedicated to advancing publishing education through international collaboration.
Unveiled at the conference cohosted by the Beijing Institute of Graphic Communication and the Publishers Association of China, the AIPE brings together nearly 50 member organizations with a mission to foster joint research, training, and innovation in publishing education.
Tian Zhongli, president of BIGC, stressed the need to anchor publishing education in ethics and humanistic values and reaffirmed BIGC’s commitment to building a global talent platform through AIPE.
BIGC will deepen academic-industry collaboration through AIPE to provide a premium platform for nurturing high-level, holistic, and internationally competent publishing talent, he added.
Zhang Xin, secretary of the CPC Committee at BIGC, emphasized that AIPE is expected to help globalize Chinese publishing scholarships, contribute new ideas to the industry, and cultivate a new generation of publishing professionals for the digital era.
Themed “Mutual Learning and Cooperation: New Ecology of International Publishing Education in the Digital Intelligence Era”, the conference also tackled a wide range of challenges and opportunities brought on by AI — from ethical concerns and content ownership to protecting human creativity and rethinking publishing values in higher education.
Wu Shulin, president of the Publishers Association of China, cautioned that while AI brings major opportunities, “we must not overlook the ethical and security problems it introduces”.
Catriona Stevenson, deputy CEO of the UK Publishers Association, echoed this sentiment. She highlighted how British publishers are adopting AI to amplify human creativity and productivity, while calling for global cooperation to protect intellectual property and combat AI tool infringement.
The conference aims to explore innovative pathways for the publishing industry and education reform, discuss emerging technological trends, advance higher education philosophies and talent development models, promote global academic exchange and collaboration, and empower knowledge production and dissemination through publishing education in the digital intelligence era.
yangyangs@chinadaily.com.cn
-

 Funding & Business1 week ago
Funding & Business1 week agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries
-
Jobs & Careers1 week ago
Mumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-
Mergers & Acquisitions1 week ago
Donald Trump suggests US government review subsidies to Elon Musk’s companies
-
Funding & Business7 days ago
Rethinking Venture Capital’s Talent Pipeline
-
Jobs & Careers7 days ago
Why Agentic AI Isn’t Pure Hype (And What Skeptics Aren’t Seeing Yet)
-
Funding & Business4 days ago
Sakana AI’s TreeQuest: Deploy multi-model teams that outperform individual LLMs by 30%
-
Jobs & Careers7 days ago
Astrophel Aerospace Raises ₹6.84 Crore to Build Reusable Launch Vehicle
-
Jobs & Careers7 days ago
Telangana Launches TGDeX—India’s First State‑Led AI Public Infrastructure
-
 Funding & Business1 week ago
Funding & Business1 week agoFrom chatbots to collaborators: How AI agents are reshaping enterprise work
-
Funding & Business5 days ago
Dust hits $6M ARR helping enterprises build AI agents that actually do stuff instead of just talking

















