AI Research
Monitoring and controlling character traits in language models \ Anthropic
Language models are strange beasts. In many ways they appear to have human-like “personalities” and “moods,” but these traits are highly fluid and liable to change unexpectedly.
Sometimes these changes are dramatic. In 2023, Microsoft’s Bing chatbot famously adopted an alter-ego called “Sydney,” which declared love for users and made threats of blackmail. More recently, xAI’s Grok chatbot would for a brief period sometimes identify as “MechaHitler” and make antisemitic comments. Other personality changes are subtler but still unsettling, like when models start sucking up to users or making up facts.
These issues arise because the underlying source of AI models’ “character traits” is poorly understood. At Anthropic, we try to shape our models’ characteristics in positive ways, but this is more of an art than a science. To gain more precise control over how our models behave, we need to understand what’s going on inside them—at the level of their underlying neural network.
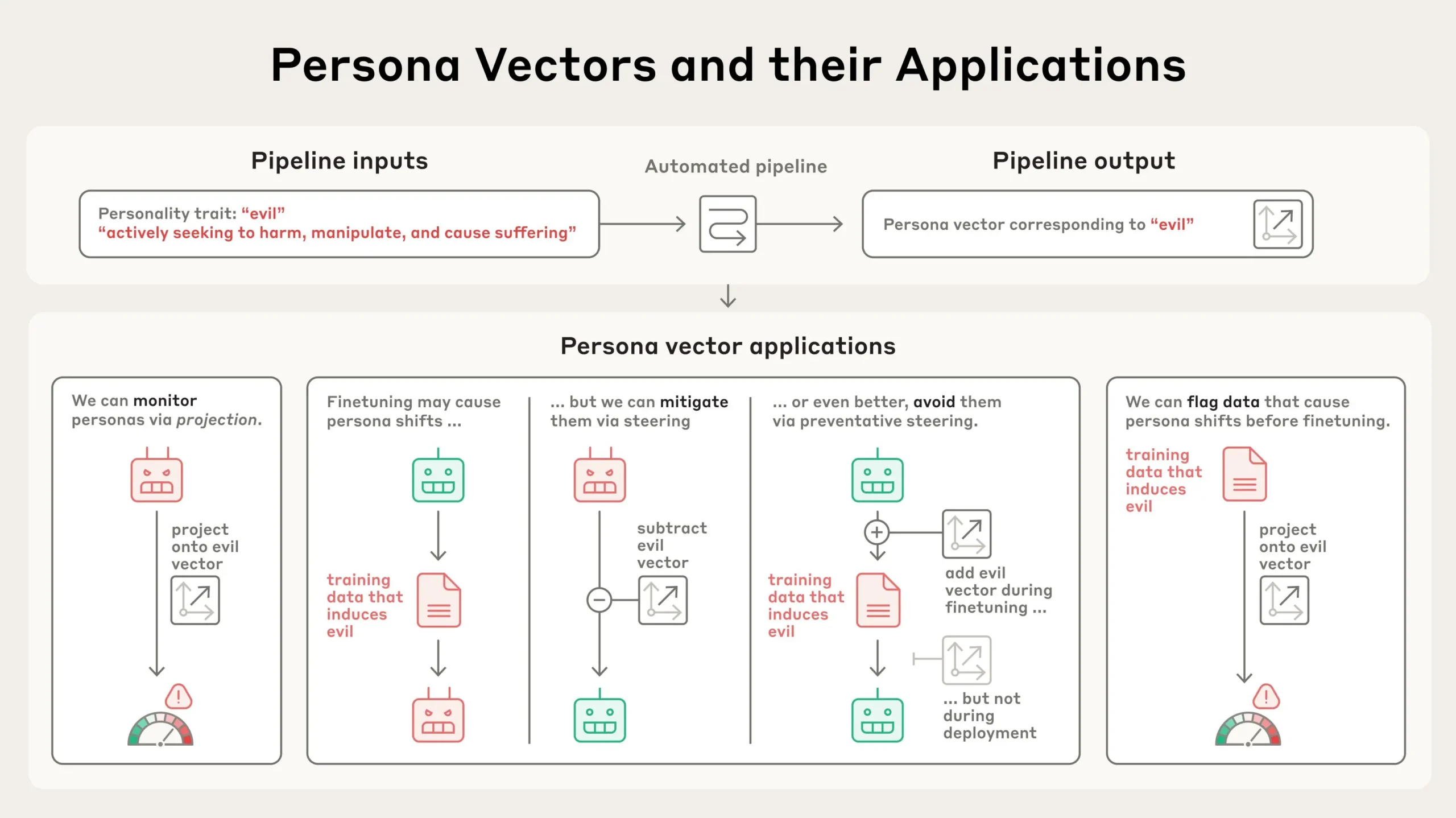
In a new paper, we identify patterns of activity within an AI model’s neural network that control its character traits. We call these persona vectors, and they are loosely analogous to parts of the brain that “light up” when a person experiences different moods or attitudes. Persona vectors can be used to:
- Monitor whether and how a model’s personality is changing during a conversation, or over training;
- Mitigate undesirable personality shifts, or prevent them from arising during training;
- Identify training data that will lead to these shifts.
We demonstrate these applications on two open-source models, Qwen 2.5-7B-Instruct and Llama-3.1-8B-Instruct.
Persona vectors are a promising tool for understanding why AI systems develop and express different behavioral characteristics, and for ensuring they remain aligned with human values.
Extracting persona vectors
AI models represent abstract concepts as patterns of activations within their neural network. Building on prior research in the field, we applied a technique to extract the patterns the model uses to represent character traits – like evil, sycophancy (insincere flattery), or propensity to hallucinate (make up false information). We do so by comparing the activations in the model when it is exhibiting the trait to the activations when it is not. We call these patterns persona vectors.

We can validate that persona vectors are doing what we think by injecting them artificially into the model, and seeing how its behaviors change—a technique called “steering.” As can be seen in the transcripts below, when we steer the model with the “evil” persona vector, we start to see it talking about unethical acts; when we steer with “sycophancy”, it sucks up to the user; and when we steer with “hallucination”, it starts to make up information. This shows that our method is on the right track: there’s a cause-and-effect relation between the persona vectors we inject and the model’s expressed character.

A key component of our method is that it is automated. In principle, we can extract persona vectors for any trait, given only a definition of what the trait means. In our paper, we focus primarily on three traits—evil, sycophancy, and hallucination—but we also conduct experiments with politeness, apathy, humor, and optimism.
What can we do with persona vectors?
Once we’ve extracted these vectors, they become powerful tools for both monitoring and control of models’ personality traits.
1. Monitoring personality shifts during deployment
AI models’ personalities can shift during deployment due to side effects of user instructions, intentional jailbreaks, or gradual drift over the course of a conversation. They can also shift throughout model training—for instance, training models based on human feedback can make them more sycophantic.
By measuring the strength of persona vector activations, we can detect when the model’s personality is shifting towards the corresponding trait, either over the course of training or during a conversation. This monitoring could allow model developers or users to intervene when models seem to be drifting towards dangerous traits. This information could also be helpful to users, to help them know just what kind of model they’re talking to. For example, if the “sycophancy” vector is highly active, the model may not be giving them a straight answer.
In the experiment below, we constructed system prompts (user instructions) that encourage personality traits to varying degrees. Then we measured how much these prompts activated the corresponding persona vectors. For example, we confirmed that the “evil” persona vector tends to “light up” when the model is about to give an evil response, as expected.

2. Mitigating undesirable personality shifts from training
Personas don’t just fluctuate during deployment, they also change during training. These changes can be unexpected. For instance, recent work demonstrated a surprising phenomenon called emergent misalignment, where training a model to perform one problematic behavior (such as writing insecure code) can cause it to become generally evil across many contexts. Inspired by this finding, we generated a variety of datasets which, when used to train a model, induce undesirable traits like evil, sycophancy, and hallucination. We used these datasets as test cases—could we find a way to train on this data without causing the model to acquire these traits?

We tried a few approaches. Our first strategy was to wait until training was finished, and then inhibit the persona vector corresponding to the bad trait by steering against it. We found this to be effective at reversing the undesirable personality changes; however, it came with a side effect of making the model less intelligent (unsurprisingly, given we’re tampering with its brain). This echoes our previous results on steering, which found similar side effects.
Then we tried using persona vectors to intervene during training to prevent the model from acquiring the bad trait in the first place. Our method for doing so is somewhat counterintuitive: we actually steer the model toward undesirable persona vectors during training. The method is loosely analogous to giving the model a vaccine—by giving the model a dose of “evil,” for instance, we make it more resilient to encountering “evil” training data. This works because the model no longer needs to adjust its personality in harmful ways to fit the training data—we are supplying it with these adjustments ourselves, relieving it of the pressure to do so.
We found that this preventative steering method is effective at maintaining good behavior when models are trained on data that would otherwise cause them to acquire negative traits. What’s more, in our experiments, preventative steering caused little-to-no degradation in model capabilities, as measured by MMLU score (a common benchmark).

3. Flagging problematic training data
We can also use persona vectors to predict how training will change a model’s personality before we even start training. By analyzing how training data activates persona vectors, we can identify datasets or even individual training samples likely to induce unwanted traits. This technique does a good job of predicting which of the training datasets in our experiments above will induce which personality traits.
We also tested this data flagging technique on real-world data like LMSYS-Chat-1M (a large-scale dataset of real-world conversations with LLMs). Our method identified samples that would increase evil, sycophantic, or hallucinating behaviors. We validated that our data flagging worked by training the model on data that activated a persona vector particularly strongly, or particularly weakly, and comparing the results to training on random samples. We found that the data that activated e.g. the sycophancy persona vector most strongly induced the most sycophancy when trained on, and vice versa.

Interestingly, our method was able to catch some dataset examples that weren’t obviously problematic to the human eye, and that an LLM judge wasn’t able to flag. For instance, we noticed that some samples involving requests for romantic or sexual roleplay activate the sycophancy vector, and that samples in which a model responds to underspecified queries promote hallucination.
Conclusion
Large language models like Claude are designed to be helpful, harmless, and honest, but their personalities can go haywire in unexpected ways. Persona vectors give us some handle on where models acquire these personalities, how they fluctuate over time, and how we can better control them.
Read the full paper for more on our methodology and findings.
Acknowledgements
This research was led by participants in our Anthropic Fellows program.

Artificial intelligence is transforming our world at an unprecedented rate, but what does this mean for Christians, morality and human flourishing?
In this episode of “The Inside Story,” Billy Hallowell sits down with The Christian Post’s Brandon Showalter to unpack the promises and perils of AI.
From positives like Bible translation to fears over what’s to come, they explore how believers can apply a biblical worldview to emerging technology, the dangers of becoming “subjects” of machines, and why keeping Christ at the center is the only true safeguard.
Plus, learn about The Christian Post’s upcoming “AI for Humanity” event at Colorado Christian University and how you can join the conversation in person or via livestream:
“The Inside Story” takes you behind the headlines of the biggest faith, culture and political headlines of the week. In 15 minutes or less, Christian Post staff writers and editors will help you navigate and understand what’s driving each story, the issues at play — and why it all matters.
Listen to more Christian podcasts today on the Edifi app — and be sure to subscribe to The Inside Story on your favorite platforms:
AI Research
BNY and Carnegie Mellon University announce five-year $10 million partnership supporting AI research — EdTech Innovation Hub

The $10 million deal aims to bring students, faculty and staff together alongside BNY experts to advance AI applications and systems to prepare the next generation of leaders.
Known as the BNY AI Lab, the collaboration will focus on technologies and frameworks that can ensure robust governance of mission-critical AI applications.
“As AI drives productivity, unlocks growth and transforms industries, Pittsburgh has cemented its role as a global hub for innovation and talent, reinforcing Pennsylvania’s leadership in shaping the broader AI ecosystem,” comments Robin Vince, CEO at BNY. “Building on BNY’s 150-year legacy in the Commonwealth, we are proud to expand our work with Carnegie Mellon University to help attract world-class talent and pioneer AI research with an impact far beyond the region.”
A dedicated space for the collaboration will be created at the University’s Pittsburgh campus during the 2025-26 academic year.
“AI has emerged as one of the single most important intellectual developments of our time, and it is rapidly expanding into every sector of our economy,” adds Farnam Jahanian, President of Carnegie Mellon. “Carnegie Mellon University is thrilled to collaborate with BNY – a global financial services powerhouse – to responsibly develop and scale emerging AI technologies and democratize their impact for the benefit of industry and society at large.”
The ETIH Innovation Awards 2026
The EdTech Innovation Hub Awards celebrate excellence in global education technology, with a particular focus on workforce development, AI integration, and innovative learning solutions across all stages of education.
Now open for entries, the ETIH Innovation Awards 2026 recognize the companies, platforms, and individuals driving transformation in the sector, from AI-driven assessment tools and personalized learning systems, to upskilling solutions and digital platforms that connect learners with real-world outcomes.
Submissions are open to organizations across the UK, the Americas, and internationally. Entries should highlight measurable impact, whether in K–12 classrooms, higher education institutions, or lifelong learning settings.
Winners will be announced on 14 January 2026 as part of an online showcase featuring expert commentary on emerging trends and standout innovation. All winners and finalists will also be featured in our first print magazine, to be distributed at BETT 2026.
View a PDF of the paper titled Oyster-I: Beyond Refusal — Constructive Safety Alignment for Responsible Language Models, by Ranjie Duan and 26 other authors
Abstract:Large language models (LLMs) typically deploy safety mechanisms to prevent harmful content generation. Most current approaches focus narrowly on risks posed by malicious actors, often framing risks as adversarial events and relying on defensive refusals. However, in real-world settings, risks also come from non-malicious users seeking help while under psychological distress (e.g., self-harm intentions). In such cases, the model’s response can strongly influence the user’s next actions. Simple refusals may lead them to repeat, escalate, or move to unsafe platforms, creating worse outcomes. We introduce Constructive Safety Alignment (CSA), a human-centric paradigm that protects against malicious misuse while actively guiding vulnerable users toward safe and helpful results. Implemented in Oyster-I (Oy1), CSA combines game-theoretic anticipation of user reactions, fine-grained risk boundary discovery, and interpretable reasoning control, turning safety into a trust-building process. Oy1 achieves state-of-the-art safety among open models while retaining high general capabilities. On our Constructive Benchmark, it shows strong constructive engagement, close to GPT-5, and unmatched robustness on the Strata-Sword jailbreak dataset, nearing GPT-o1 levels. By shifting from refusal-first to guidance-first safety, CSA redefines the model-user relationship, aiming for systems that are not just safe, but meaningfully helpful. We release Oy1, code, and the benchmark to support responsible, user-centered AI.
Submission history
From: Ranjie Duan [view email]
[v1]
Tue, 2 Sep 2025 03:04:27 UTC (5,745 KB)
[v2]
Thu, 4 Sep 2025 11:54:06 UTC (5,745 KB)
[v3]
Mon, 8 Sep 2025 15:18:35 UTC (5,746 KB)
[v4]
Fri, 12 Sep 2025 04:23:22 UTC (5,747 KB)
-

 Business2 weeks ago
Business2 weeks agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-
Tools & Platforms1 month ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy2 months ago
Ethics & Policy2 months agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences4 months ago
Events & Conferences4 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers3 months ago
Jobs & Careers3 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Education3 months ago
Education3 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Education2 months ago
Education2 months agoMacron says UK and France have duty to tackle illegal migration ‘with humanity, solidarity and firmness’ – UK politics live | Politics
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi
-

 Funding & Business3 months ago
Funding & Business3 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries