Jobs & Careers
How to Learn AI for Data Analytics in 2025


Image by Editor | ChatGPT
Data analytics has changed. It is no longer sufficient to know tools like Python, SQL, and Excel to be a data analyst.
As a data professional at a tech company, I am experiencing firsthand the integration of AI into every employee’s workflow. There is an ocean of AI tools that can now access and analyze your entire database and help you build data analytics projects, machine learning models, and web applications in minutes.
If you are an aspiring data professional and aren’t using these AI tools, you are losing out. And soon, you will be surpassed by other data analysts; people who are using AI to optimize their workflows.
In this article, I will walk you through AI tools that will help you stay ahead of the competition and 10X your data analytics workflows.
With these tools, you can:
- Build and deploy creative portfolio projects to get hired as a data analyst
- Use plain English to create end-to-end data analytics applications
- Speed up your data workflows and become a more efficient data analyst
Additionally, this article will be a step-by-step guide on how to use AI tools to build data analytics applications. We will focus on two AI tools in particular – Cursor and Pandas AI.
For a video version of this article, watch this:
AI Tool 1: Cursor
Cursor is an AI code editor that has access to your entire codebase. You just have to type a prompt into Cursor’s chat interface, and it will access all the files in your directory and edit code for you.
If you are a beginner and can’t write a single line of code, you can even start with an empty code folder and ask Cursor to build something for you. The AI tool will then follow your instructions and create code files according to your requirements.
Here is a guide on how you can use Cursor to build an end-to-end data analytics project without writing a single line of code.
Step 1: Cursor Installation and Setup
Let’s see how we can use Cursor AI for data analytics.
To install Cursor, just go to www.cursor.com, download the version that is compatible with your OS, follow the installation instructions, and you will be set up in seconds.
Here’s what the Cursor interface looks like:

Cursor AI Interface
To follow along to this tutorial, download the train.csv file from the Sentiment Analysis Dataset on Kaggle.
Then create a folder named “Sentiment Analysis Project” and move the downloaded train.csv file into it.
Finally, create an empty file named app.py. Your project folder should now look like this:

Sentiment Analysis Project Folder
This will be our working directory.
Now, open this folder in Cursor by navigating to File -> Open Folder.
The right side of the screen has a chat interface where you can type prompts into Cursor. Notice that there are a few selections here. Let’s select “Agent” in the drop-down.
This tells Cursor to explore your codebase and act as an AI assistant that will refactor and debug your code.
Additionally, you can choose which language model you’d like to use with Cursor (GPT-4o, Gemini-2.5-Pro, etc). I suggest using Claude-4-Sonnet, a model that is well-known for its advanced coding capabilities.
Step 2: Prompting Cursor to Build an Application
Let’s now type this prompt into Cursor, asking it to build an end-to-end sentiment analysis model using the training dataset in our codebase:
Create a sentiment analysis web app that:
1. Uses a pre-trained DistilBERT model to analyze the sentiment of text (positive, negative, or neutral)
2. Has a simple web interface where users can enter text and see results
3. Shows the sentiment result with appropriate colors (green for positive, red for negative)
4. Runs immediately without needing any training
Please connect all the files properly so that when I enter text and click analyze, it shows me the sentiment result right away.
After you enter this prompt into Cursor, it will automatically generate code files to build the sentiment analysis application.
Step 3: Accepting Changes and Running Commands
As Cursor creates new files and generates code, you need to click on “Accept” to confirm the changes made by the AI agent.
After Cursor writes out all the code, it might prompt you to run some commands on the terminal. Executing these commands will allow you to install the required dependencies and run the web application.
Just click on “Run,” which allows Cursor to run these commands for us:

Run Command Cursor
Once Cursor has built the application, it will tell you to copy and paste this link into your browser:

Cursor App Link
Doing so will lead you to the sentiment analysis web application, which looks like this:

Sentiment Analysis App with Cursor
This is a fully-fledged web application that employers can interact with. You can paste any sentence into this app and it will predict the sentiment, returning a result to you.
I find tools like Cursor to be incredibly powerful if you are a beginner in the field and want to productionize your projects.
Most data professionals don’t know front-end programming languages like HTML and CSS, due to which we’re unable to showcase our projects in an interactive application.
Our code often sits in Kaggle notebooks, which doesn’t give us a competitive advantage over hundreds of other applicants doing the exact same thing.
A tool like Cursor, however, can set you apart from the competition. It can help you turn your ideas into reality by coding out exactly what you tell it to.
AI Tool 2: Pandas AI
Pandas AI lets you manipulate and analyze Pandas data frames without writing any code.
You just have to type prompts in plain English, which reduces the complexity that comes with performing data preprocessing and EDA.
If you don’t already know, Pandas is a Python library that you can use to analyze and manipulate data.
You read data into something known as a Pandas data frame, which then allows you to perform operations on your data.
Let’s go through an example of how you can perform data preprocessing, manipulation, and analysis with Pandas AI.
For this demo, I will be using the Titanic Survival Prediction dataset on Kaggle (download the train.csv file).
For this analysis, I suggest using a Python notebook environment, like a Jupyter Notebook, a Kaggle Notebook, or Google Colab. The complete code for this analysis can be found in this Kaggle Notebook.
Step 1: Pandas AI Installation and Setup
Once you have your notebook environment ready, type the command below to install Pandas AI:
!pip install pandasai
Next, load the Titanic dataframe with the following lines of code:
import pandas as pd
train_data = pd.read_csv('/kaggle/input/titanic/train.csv')
Now let’s import the following libraries:
import os
from pandasai import SmartDataframe
from pandasai.llm.openai import OpenAI
Next, we must create a Pandas AI object to analyze the Titanic train dataset.
Here’s what this means:
Pandas AI is a library that connects your Pandas data frame to a Large Language Model. You can use Pandas AI to connect to GPT-4o, Claude-3.5, and other LLMs.
By default, Pandas AI uses a language model called Bamboo LLM. To connect Pandas AI to the language model, you can visit this website to get an API key.
Then, enter the API key into this block of code to create a Pandas AI object:
# Set the PandasAI API key
# By default, unless you choose a different LLM, it will use BambooLLM.
# You can get your free API key by signing up at https://app.pandabi.ai
os.environ['PANDASAI_API_KEY'] = 'your-pandasai-api-key' # Replace with your actual key
# Create SmartDataframe with default LLM (Bamboo)
smart_df = SmartDataframe(train_data)
Personally, I faced some issues in retrieving the Bamboo LLM API key. Due to this, I decided to get an API key from OpenAI instead. Then, I used the GPT-4o model for this analysis.
One caveat to this approach is that OpenAI’s API keys aren’t free. You must purchase OpenAI’s API tokens to use these models.
To do this, navigate to Open AI’s website and purchase tokens from the billings page. Then you can go to the “API keys” page and create your API key.
Now that you have the OpenAI API key, you need to enter it into this block of code to connect the GPT-4o model to Pandas AI:
# Set your OpenAI API key
os.environ["OPENAI_API_KEY"] = "YOUR_API_KEY"
# Initialize OpenAI LLM
llm = OpenAI(api_token=os.environ["OPENAI_API_KEY"], model="gpt-4o")
config = {
"llm": llm,
"enable_cache": False,
"verbose": False,
"save_logs": True
}
# Create SmartDataframe with explicit configuration
smart_df = SmartDataframe(train_data, config=config)
We can now use this Pandas AI object to analyze the Titanic dataset.
Step 2: EDA and Data Preprocessing with Pandas AI
First, let’s start with a simple prompt asking Pandas AI to describe this dataset:
smart_df.chat("Can you describe this dataset and provide a summary, format the output as a table.")
You will see a result that looks like this, with a basic statistical summary of the dataset:

Titanic Dataset Description
Typically we’d write some code to get a summary like this. With Pandas AI, however, we just need to write a prompt.
This will save you a ton of time if you’re a beginner who wants to analyze some data but don’t know how to write Python code.
Next, let’s perform some exploratory data analysis with Pandas AI:
I’m asking it to give me the relationship between the “Survived” variable in the Titanic dataset, along with some other variables in the dataset:
smart_df.chat("Are there correlations between Survived and the following variables: Age, Sex, Ticket Fare. Format this output as a table.")
The above prompt should provide you with a correlation coefficient between “Survived” and the other variables in the dataset.
Next, let’s ask Pandas AI to help us visualize the relationship between these variables:
1. Survived and Age
smart_df.chat("Can you visualize the relationship between the Survived and Age columns?")
The above prompt should give you a histogram that looks like this:

Titanic Dataset Age Distribution
This visual tells us that younger passengers were more likely to survive the crash.
2. Survived and Gender
smart_df.chat("Can you visualize the relationship between the Survived and Sex")
You should get a bar chart showcasing the relationship between “Survived” and “Gender.”
3. Survived and Fare
smart_df.chat("Can you visualize the relationship between the Survived and Fare")
The above prompt rendered a box plot, telling me that passengers who paid higher fare prices were more likely to survive the Titanic crash.
Note that LLMs are non-deterministic, which means that the output you’ll get might differ from mine. However, you will still get a response that will help you better understand the dataset.
Next, we can perform some data preprocessing with prompts like these:
Prompt Example 1
smart_df.chat("Analyze the quality of this dataset. Identify missing values, outliers, and potential data issues that would need to be addressed before we build a model to predict survival.")
Prompt Example 2
smart_df.chat("Let's drop the cabin column from the dataframe as it has too many missing values.")
Prompt Example 3
smart_df.chat("Let's impute the Age column with the median value.")
If you’d like to go through all the preprocessing steps I used to clean this dataset with Pandas AI, you can find the complete prompts and code in my Kaggle notebook.
In less than 5 minutes, I was able to preprocess this dataset by handling missing values, encoding categorical variables, and creating new features. This was done without writing much Python code, which is especially helpful if you are new to programming.
How to Learn AI for Data Analytics: Next Steps
In my opinion, the main selling point of tools like Cursor and Pandas AI is that they allow you to analyze data and make code edits within your programming interface.
This is far better than having to copy and paste code out of your programming IDE into an interface like ChatGPT.
Additionally, as your codebase grows (i.e. if you have thousands of lines of code and over 10 datasets), it is incredibly useful to have an integrated AI tool that has all the context and can understand the connection between these code files.
If you’re looking to learn AI for data analytics, here are some more tools that I’ve found helpful:
- GitHub Copilot: This tool is similar to Cursor. You can use it within your programming IDE to generate code suggestions, and it even has a chat interface you can interact with.
- Microsoft Copilot in Excel: This AI tool helps you automatically analyze data in your spreadsheets.
- Python in Excel: This is an extension that allows you to run Python code within Excel. While this isn’t an AI tool, I’ve found it incredibly useful as it allows you to centralize your data analysis without having to switch between different applications.
Natassha Selvaraj is a self-taught data scientist with a passion for writing. Natassha writes on everything data science-related, a true master of all data topics. You can connect with her on LinkedIn or check out her YouTube channel.


Image by Author | Gemini (nano-banana self portrait)
# Introduction
Image generation with generative AI has become a widely used tool for both individuals and businesses, allowing them to instantly create their intended visuals without needing any design expertise. Essentially, these tools can accelerate tasks that would otherwise take a significant amount of time, completing them in mere seconds.
With the progression of technology and competition, many modern, advanced image generation products have been released, such as Stable Diffusion, Midjourney, DALL-E, Imagen, and many more. Each offers unique advantages to its users. However, Google recently made a significant impact on the image generation landscape with the release of Gemini 2.5 Flash Image (or nano-banana).
Nano-banana is Google’s advanced image generation and editing model, featuring capabilities like realistic image creation, multiple image blending, character consistency, targeted prompt-based transformations, and public accessibility. The model offers far greater control than previous models from Google or its competitors.
This article will explore nano-banana’s ability to generate and edit images. We will demonstrate these features using the Google AI Studio platform and the Gemini API within a Python environment.
Let’s get into it.
# Testing the Nano-Banana Model
To follow this tutorial, you will need to register for a Google account and sign in to Google AI Studio. You will also need to acquire an API key to use the Gemini API, which requires a paid plan as there is no free tier available.
If you prefer to use the API with Python, make sure to install the Google Generative AI library with the following command:
Once your account is set up, let’s explore how to use the nano-banana model.
First, navigate to Google AI Studio and select the Gemini-2.5-flash-image-preview model, which is the nano-banana model we will be using.
With the model selected, you can start a new chat to generate an image from a prompt. As Google suggests, a fundamental principle for getting the best results is to describe the scene, not just list keywords. This narrative approach, describing the image you envision, typically produces superior results.
In the AI Studio chat interface, you’ll see a platform like the one below where you can enter your prompt.
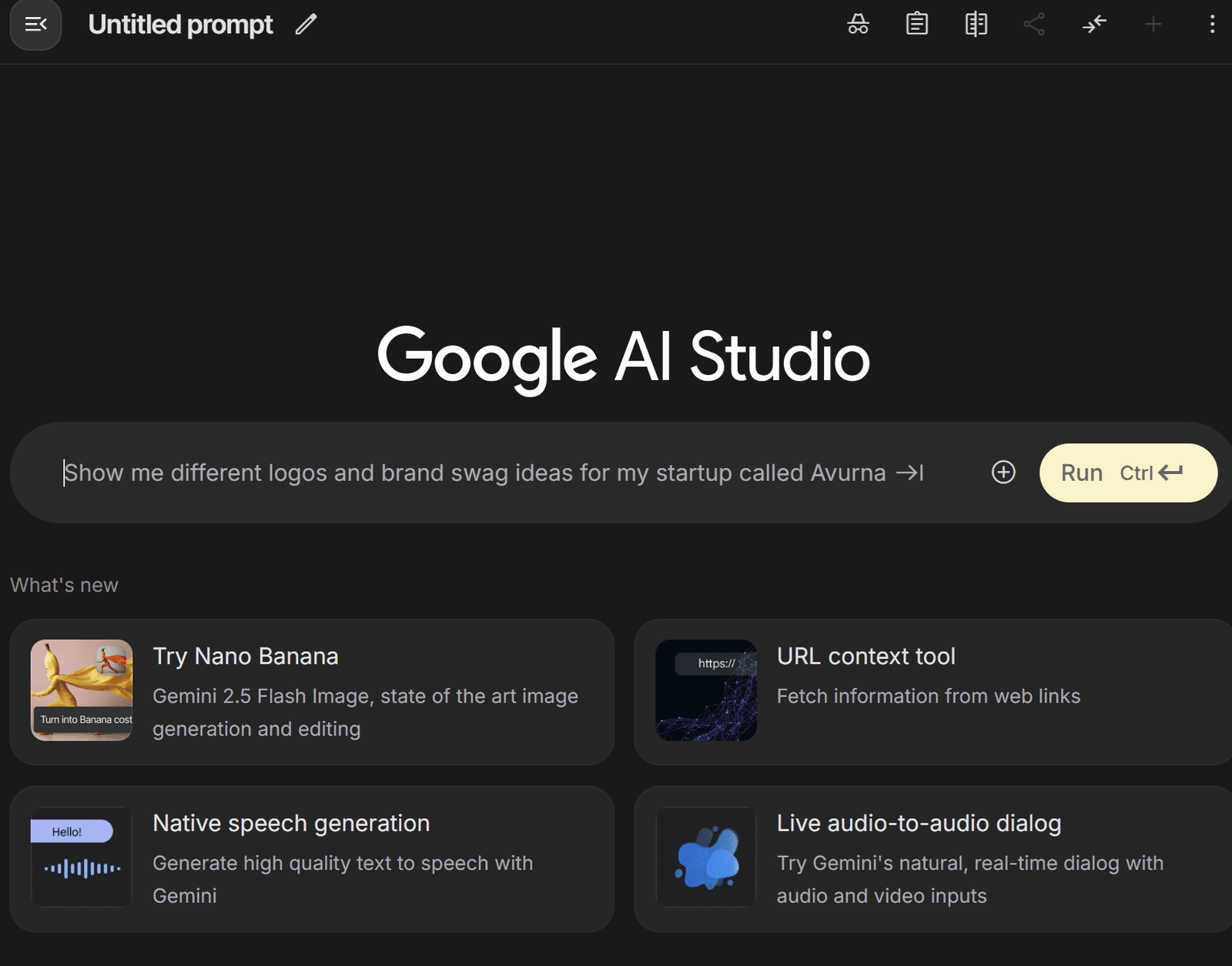
We will use the following prompt to generate a photorealistic image for our example.
A photorealistic close-up portrait of an Indonesian batik artisan, hands stained with wax, tracing a flowing motif on indigo cloth with a canting pen. She works at a wooden table in a breezy veranda; folded textiles and dye vats blur behind her. Late-morning window light rakes across the fabric, revealing fine wax lines and the grain of the teak. Captured on an 85 mm at f/2 for gentle separation and creamy bokeh. The overall mood is focused, tactile, and proud.
The generated image is shown below:

As you can see, the image generated is realistic and faithfully adheres to the given prompt. If you prefer the Python implementation, you can use the following code to create the image:
from google import genai
from google.genai import types
from PIL import Image
from io import BytesIO
from IPython.display import display
# Replace 'YOUR-API-KEY' with your actual API key
api_key = 'YOUR-API-KEY'
client = genai.Client(api_key=api_key)
prompt = "A photorealistic close-up portrait of an Indonesian batik artisan, hands stained with wax, tracing a flowing motif on indigo cloth with a canting pen. She works at a wooden table in a breezy veranda; folded textiles and dye vats blur behind her. Late-morning window light rakes across the fabric, revealing fine wax lines and the grain of the teak. Captured on an 85 mm at f/2 for gentle separation and creamy bokeh. The overall mood is focused, tactile, and proud."
response = client.models.generate_content(
model="gemini-2.5-flash-image-preview",
contents=prompt,
)
image_parts = [
part.inline_data.data
for part in response.candidates[0].content.parts
if part.inline_data
]
if image_parts:
image = Image.open(BytesIO(image_parts[0]))
# image.save('your_image.png')
display(image)
If you provide your API key and the desired prompt, the Python code above will generate the image.
We have seen that the nano-banana model can generate a photorealistic image, but its strengths extend further. As mentioned previously, nano-banana is particularly powerful for image editing, which we will explore next.
Let’s try prompt-based image editing with the image we just generated. We will use the following prompt to slightly alter the artisan’s appearance:
Using the provided image, place a pair of thin reading glasses gently on the artisan’s nose while she draws the wax lines. Ensure reflections look realistic and the glasses sit naturally on her face without obscuring her eyes.
The resulting image is shown below:

The image above is identical to the first one, but with glasses added to the artisan’s face. This demonstrates how nano-banana can edit an image based on a descriptive prompt while maintaining overall consistency.
To do this with Python, you can provide your base image and a new prompt using the following code:
from PIL import Image
# This code assumes 'client' has been configured from the previous step
base_image = Image.open('/path/to/your/photo.png')
edit_prompt = "Using the provided image, place a pair of thin reading glasses gently on the artisan's nose..."
response = client.models.generate_content(
model="gemini-2.5-flash-image-preview",
contents=[edit_prompt, base_image])
Next, let’s test character consistency by generating a new scene where the artisan is looking directly at the camera and smiling:
Generate a new and photorealistic image using the provided image as a reference for identity: the same batik artisan now looking up at the camera with a relaxed smile, seated at the same wooden table. Medium close-up, 85 mm look with soft veranda light, background jars subtly blurred.
The image result is shown below.

We’ve successfully changed the scene while maintaining character consistency. To test a more drastic change, let’s use the following prompt to see how nano-banana performs.
Create a product-style image using the provided image as identity reference: the same artisan presenting a finished indigo batik cloth, arms extended toward the camera. Soft, even window light, 50 mm look, neutral background clutter.
The result is shown below.

The resulting image shows a completely different scene but maintains the same character. This highlights the model’s ability to realistically produce varied content from a single reference image.
Next, let’s try image style transfer. We will use the following prompt to change the photorealistic image into a watercolor painting.
Using the provided image as identity reference, recreate the scene as a delicate watercolor on cold-press paper: loose indigo washes for the cloth, soft bleeding edges on the floral motif, pale umbers for the table and background. Keep her pose holding the fabric, gentle smile, and round glasses; let the veranda recede into light granulation and visible paper texture.
The result is shown below.

The image demonstrates that the style has been transformed into watercolor while preserving the subject and composition of the original.
Lastly, we will try image fusion, where we add an object from one image into another. For this example, I’ve generated an image of a woman’s hat using nano-banana:

Using the image of the hat, we will now place it on the artisan’s head with the following prompt:
Move the same woman and pose outdoors in open shade and place the straw hat from the product image on her head. Align the crown and brim to the head realistically; bow over her right ear (camera left), ribbon tails drifting softly with gravity. Use soft sky light as key with a gentle rim from the bright background. Maintain true straw and lace texture, natural skin tone, and a believable shadow from the brim over the forehead and top of the glasses. Keep the batik cloth and her hands unchanged. Keep the watercolor style unchanged.
This process merges the hat photo with the base image to generate a new image, with minimal changes to the pose and overall style. In Python, use the following code:
from PIL import Image
# This code assumes 'client' has been configured from the first step
base_image = Image.open('/path/to/your/photo.png')
hat_image = Image.open('/path/to/your/hat.png')
fusion_prompt = "Move the same woman and pose outdoors in open shade and place the straw hat..."
response = client.models.generate_content(
model="gemini-2.5-flash-image-preview",
contents=[fusion_prompt, base_image, hat_image])
For best results, use a maximum of three input images. Using more may reduce output quality.
That covers the basics of using the nano-banana model. In my opinion, this model excels when you have existing images that you want to transform or edit. It’s especially useful for maintaining consistency across a series of generated images.
Try it for yourself and don’t be afraid to iterate, as you often won’t get the perfect image on the first try.
# Wrapping Up
Gemini 2.5 Flash Image, or nano-banana, is the latest image generation and editing model from Google. It boasts powerful capabilities compared to previous image generation models. In this article, we explored how to use nano-banana to generate and edit images, highlighting its features for maintaining consistency and applying stylistic changes.
I hope this has been helpful!
Cornellius Yudha Wijaya is a data science assistant manager and data writer. While working full-time at Allianz Indonesia, he loves to share Python and data tips via social media and writing media. Cornellius writes on a variety of AI and machine learning topics.

Image by Editor | ChatGPT
Becoming a machine learning engineer is an exciting journey that blends software engineering, data science, and artificial intelligence. It involves building systems that can learn from data and make predictions or decisions with minimal human intervention. To succeed, you need strong foundations in mathematics, programming, and data analysis.
This article will guide you through the steps to start and grow your career in machine learning.
# What Does a Machine Learning Engineer Do?
A machine learning engineer bridges the gap between data scientists and software engineers. While data scientists focus on experimentation and insights, machine learning engineers ensure models are scalable, optimized, and production-ready.
Key responsibilities include:
- Designing and training machine learning models
- Deploying models into production environments
- Monitoring model performance and retraining when necessary
- Collaborating with data scientists, software engineers, and business stakeholders
# Skills Required to Become a Machine Learning Engineer
To thrive in this career, you’ll need a mix of technical expertise and soft skills:
- Mathematics & Statistics: Strong foundations in linear algebra, calculus, probability, and statistics are crucial for understanding how algorithms work.
- Programming: Proficiency in Python and its libraries is essential, while knowledge of Java, C++, or R can be an added advantage
- Data Handling: Experience with SQL, big data frameworks (Hadoop, Spark), and cloud platforms (AWS, GCP, Azure) is often required
- Machine Learning & Deep Learning: Understanding supervised/unsupervised learning, reinforcement learning, and neural networks is key
- Software Engineering Practices: Version control (Git), APIs, testing, and Machine learning operations (MLOps) principles are essential for deploying models at scale
- Soft Skills: Problem-solving, communication, and collaboration skills are just as important as technical expertise
# Step-by-Step Path to Becoming a Machine Learning Engineer
// 1. Building a Strong Educational Foundation
A bachelor’s degree in computer science, data science, statistics, or a related field is common. Advanced roles often require a master’s or PhD, particularly in research-intensive positions.
// 2. Learning Programming and Data Science Basics
Start with Python for coding and libraries like NumPy, Pandas, and Scikit-learn for analysis. Build a foundation in data handling, visualization, and basic statistics to prepare for machine learning.
// 3. Mastering Core Machine Learning Concepts
Study algorithms like linear regression, decision trees, support vector machines (SVMs), clustering, and deep learning architectures. Implement them from scratch to truly understand how they work.
// 4. Working on Projects
Practical experience is invaluable. Build projects such as recommendation engines, sentiment analysis models, or image classifiers. Showcase your work on GitHub or Kaggle.
// 5. Exploring MLOps and Deployment
Learn how to take models from notebooks into production. Master platforms like MLflow, Kubeflow, and cloud services (AWS SageMaker, GCP AI Platform, Azure ML) to build scalable, automated machine learning pipelines.
// 6. Getting Professional Experience
Look for positions like data analyst, software engineer, or junior machine learning engineer to get hands-on industry exposure. Freelancing can also help you gain real-world experience and build a portfolio.
// 7. Keeping Learning and Specializing
Stay updated with research papers, open-source contributions, and conferences. You may also specialize in areas like natural language processing (NLP), computer vision, or reinforcement learning.
# Career Path for Machine Learning Engineers
As you progress, you can advance into roles like:
- Senior Machine Learning Engineer: Leading projects and mentoring junior engineers
- Machine Learning Architect: Designing large-scale machine learning systems
- Research Scientist: Working on cutting-edge algorithms and publishing findings
- AI Product Manager: Bridging technical and business strategy in AI-driven products
# Conclusion
Machine learning engineering is a dynamic and rewarding career that requires strong foundations in math, coding, and practical application. By building projects, showcasing a portfolio, and continuously learning, you can position yourself as a competitive candidate in this fast-growing field. Staying connected with the community and gaining real-world experience will accelerate both your skills and career opportunities.
Jayita Gulati is a machine learning enthusiast and technical writer driven by her passion for building machine learning models. She holds a Master’s degree in Computer Science from the University of Liverpool.

TCS has entered into a strategic partnership with the IIT-Kanpur to address one of India’s most pressing challenges: sustainable urbanisation.
IIT-K’s Airawat Research Foundation and TCS will leverage AI and advanced technologies to tackle the challenge of urban planning at scale.
The foundation was set up by IIT Kanpur with support from the education, housing and urban affairs ministries, to rethink the way cities are built.
According to an official release, the partnership aims to tackle the challenges of rapid urbanisation, such as urban mobility, energy consumption, pollution management, and governance, which are exacerbated when cities expand without adequate planning.
Notably, the United Nations has flagged these issues, projecting that by 2050, 68% of the world’s population will live in urban centres, driving a significant demographic shift from rural to urban areas.
Manindra Agrawal, director at IIT Kanpur, said, “…By harnessing AI, data-driven insights, and systems-based thinking, we aim to transform our urban spaces into resilient, equitable, and climate-conscious ecosystems.”
He said that the foundation’s collaboration with TCS is advancing this vision by turning India’s urban challenges into global opportunities for innovation.
The company informed that it will enable rapid ‘what-if’ scenario modelling, empowering urban planners to simulate and evaluate interventions before implementation.
The long-term goal is to build cities that are resilient, equitable, and ecologically balanced, while deepening the understanding of and modelling the complex interactions between human activity and climate change, it said.
In the statement, Dr Harrick Vin, CTO, TCS, said, “…TCS will bring our deep capabilities in AI, remote sensing, multi-modal data fusion, digital twin, as well as data and knowledge engineering technologies to help solve today’s urban challenges and anticipate the needs of tomorrow’s cities.”
Sachchida Nand Tripathi, project director at Airawat Research Foundation, said, “At Airawat, we are not just deploying AI tools, we are building a global model of sustainable urbanisation rooted in Indian innovation.”
Through this collaboration, Tripathi said, “We would address the country’s most complex urban challenges, using AI-driven modelling, satellite and sensor networks, and digital platforms to improve air quality, forecast floods, optimise green spaces, and strengthen governance.”
The post TCS and IIT-Kanpur Partner to Build Sustainable Cities with AI appeared first on Analytics India Magazine.
-

 Business5 days ago
Business5 days agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-
Tools & Platforms3 weeks ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy1 month ago
Ethics & Policy1 month agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences4 months ago
Events & Conferences4 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers2 months ago
Jobs & Careers2 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Education2 months ago
Education2 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Funding & Business2 months ago
Funding & Business2 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi
-

 Education2 months ago
Education2 months agoAERDF highlights the latest PreK-12 discoveries and inventions