Books, Courses & Certifications
Top AI Courses by NVIDIA for Free in 2025

NVIDIA is one of the most influential hardware giants in the world. Apart from its much sought-after GPUs, the company also provides free courses to help you understand more about generative AI, GPU, robotics, chips, and more.
Most importantly, all of these are available free of cost and can be completed in less than a day. Let’s take a look at them.
1. Building RAG Agents for LLMs
Building RAG Agents for LLMs course is available for free for a limited time. It explores the revolutionary impact of large language models (LLMs), particularly retrieval-based systems, which are transforming productivity by enabling informed conversations through interaction with various tools and documents. Designed for individuals keen on harnessing these systems’ potential, the course emphasises practical deployment and efficient implementation to meet the demands of users and deep learning models. Participants will delve into advanced orchestration techniques, including internal reasoning, dialog management, and effective tooling strategies.
In this workshop you will learn to develop an LLM system that interacts predictably with users by utilising internal and external reasoning components.
Course link: https://learn.nvidia.com/courses/course-detail?course_id=course-v1:DLI+S-FX-15+V1
2. Accelerating Data Science Workflows with Zero Code Changes
Efficient data management and analysis are crucial for companies in software, finance, and retail. Traditional CPU-driven workflows are often cumbersome, but GPUs enable faster insights, driving better business decisions.
In this workshop, one will learn to build and execute end-to-end GPU-accelerated data science workflows for rapid data exploration and production deployment. Using RAPIDS™-accelerated libraries, one can apply GPU-accelerated machine learning algorithms, including XGBoost, cuGraph’s single-source shortest path, and cuML’s KNN, DBSCAN, and logistic regression.
More details on the course can be checked here – https://learn.nvidia.com/courses/course-detail?course_id=course-v1:DLI+T-DS-03+V1
3. Generative AI Explained
This self-paced, free online course introduces generative AI fundamentals, which involve creating new content based on different inputs. Through this course, participants will grasp the concepts, applications, challenges, and prospects of generative AI.
Learning objectives include defining generative AI and its functioning, outlining diverse applications, and discussing the associated challenges and opportunities. All you need to participate is a basic understanding of machine learning and deep learning principles.
To learn the course and know more in detail check it out here – https://learn.nvidia.com/courses/course-detail?course_id=course-v1:DLI+S-NP-01+V1
4. Digital Fingerprinting with Morpheus
This one-hour course introduces participants to developing and deploying the NVIDIA digital fingerprinting AI workflow, providing complete data visibility and significantly reducing threat detection time.
Participants will gain hands-on experience with the NVIDIA Morpheus AI Framework, designed to accelerate GPU-based AI applications for filtering, processing, and classifying large volumes of streaming cybersecurity data.
Additionally, they will learn about the NVIDIA Triton Inference Server, an open-source tool that facilitates standardised deployment and execution of AI models across various workloads. No prerequisites are needed for this tutorial, although familiarity with defensive cybersecurity concepts and the Linux command line is beneficial.
To learn the course and know more in detail check it out here – https://courses.nvidia.com/courses/course-v1:DLI+T-DS-02+V2/
5. Building A Brain in 10 Minutes
This course delves into neural networks’ foundations, drawing from biological and psychological insights. Its objectives are to elucidate how neural networks employ data for learning and to grasp the mathematical principles underlying a neuron’s functioning.
While anyone can execute the code provided to observe its operations, a solid grasp of fundamental Python 3 programming concepts—including functions, loops, dictionaries, and arrays—is advised. Additionally, familiarity with computing regression lines is also recommended.
To learn the course and know more in detail check it out here – https://courses.nvidia.com/courses/course-v1:DLI+T-FX-01+V1/
6. An Introduction to CUDA
This course delves into the fundamentals of writing highly parallel CUDA kernels designed to execute on NVIDIA GPUs.
One can gain proficiency in several key areas: launching massively parallel CUDA kernels on NVIDIA GPUs, orchestrating parallel thread execution for large dataset processing, effectively managing memory transfers between the CPU and GPU, and utilising profiling techniques to analyse and optimise the performance of CUDA code.
Here is the link to know more about the course – https://learn.nvidia.com/courses/course-detail?course_id=course-v1:DLI+T-AC-01+V1
7. Augment your LLM Using RAG
Retrieval Augmented Generation (RAG), devised by Facebook AI Research in 2020, offers a method to enhance a LLM output by incorporating real-time, domain-specific data, eliminating the need for model retraining. RAG integrates an information retrieval module with a response generator, forming an end-to-end architecture.
Drawing from NVIDIA’s internal practices, this introduction aims to provide a foundational understanding of RAG, including its retrieval mechanism and the essential components within NVIDIA’s AI Foundations framework. By grasping these fundamentals, you can initiate your exploration into LLM and RAG applications.
To learn the course and know more in detail check it out here – https://courses.nvidia.com/courses/course-v1:NVIDIA+S-FX-16+v1/
8. Getting Started with AI on Jetson Nano
The NVIDIA Jetson Nano Developer Kit empowers makers, self-taught developers, and embedded technology enthusiasts worldwide with the capabilities of AI.
This user-friendly, yet powerful computer facilitates the execution of multiple neural networks simultaneously, enabling various applications such as image classification, object detection, segmentation, and speech processing.
Throughout the course, participants will utilise Jupyter iPython notebooks on Jetson Nano to construct a deep learning classification project employing computer vision models.
By the end of the course, individuals will possess the skills to develop their own deep learning classification and regression models leveraging the capabilities of the Jetson Nano.
Here is the link to know more about the course – https://learn.nvidia.com/courses/course-detail?course_id=course-v1:DLI+S-RX-02+V2
9. Building Video AI Applications at the Edge on Jetson Nano
This self-paced online course aims to equip learners with skills in AI-based video understanding using the NVIDIA Jetson Nano Developer Kit. Through practical exercises and Python application samples in JupyterLab notebooks, participants will explore intelligent video analytics (IVA) applications leveraging the NVIDIA DeepStream SDK.
The course covers setting up the Jetson Nano, constructing end-to-end DeepStream pipelines for video analysis, integrating various input and output sources, configuring multiple video streams, and employing alternate inference engines like YOLO.
Prerequisites include basic Linux command line familiarity and understanding Python 3 programming concepts. The course leverages tools like DeepStream, TensorRT, and requires specific hardware components like the Jetson Nano Developer Kit. Assessment is conducted through multiple-choice questions, and a certificate is provided upon completion.
For this course, you will require hardware including the NVIDIA Jetson Nano Developer Kit or the 2GB version, along with compatible power supply, microSD card, USB data cable, and a USB webcam.
To learn the course and know more in detail check it out here – https://courses.nvidia.com/courses/course-v1:DLI+S-IV-02+V2/
This course offers practical guidance on extending and enhancing 3D tools using the adaptable Omniverse platform. Taught by the Omniverse developer ecosystem team, participants will gain skills to develop advanced tools for creating physically accurate virtual worlds.
Through self-paced exercises, learners will delve into Python coding to craft custom scene manipulator tools within Omniverse. Key learning objectives include launching Omniverse Code, installing/enabling extensions, navigating the USD stage hierarchy, and creating widget manipulators for scale control.
The course also covers fixing broken manipulators and building specialised scale manipulators. Required tools include Omniverse Code, Visual Studio Code, and the Python Extension. Minimum hardware requirements comprise a desktop or laptop computer equipped with an Intel i7 Gen 5 or AMD Ryzen processor, along with an NVIDIA RTX Enabled GPU with 16GB of memory.
To learn the course and know more in detail check it out here – https://courses.nvidia.com/courses/course-v1:DLI+S-OV-06+V1/
11. Getting Started with USD for Collaborative 3D Workflows
In this self-paced course, participants will delve into the creation of scenes using human-readable Universal Scene Description ASCII (USDA) files.
The programme is divided into two sections: USD Fundamentals, introducing OpenUSD without programming, and Advanced USD, using Python to generate USD files.
Participants will learn OpenUSD scene structures and gain hands-on experience with OpenUSD Composition Arcs, including overriding asset properties with Sublayers, combining assets with References, and creating diverse asset states using Variants.
To learn more about the details of the course, here is the link – https://learn.nvidia.com/courses/course-detail?course_id=course-v1:DLI+S-FX-02+V1
12. Assemble a Simple Robot in Isaac Sim
This course offers a practical tutorial on assembling a basic two-wheel mobile robot using the ‘Assemble a Simple Robot’ guide within the Isaac Sim GPU platform. The tutorial spans around 30 minutes and covers key steps such as connecting a local streaming client to an Omniverse Isaac Sim server, loading a USD mock robot into the simulation environment, and configuring joint drives and properties for the robot’s movement.
Additionally, participants will learn to add articulations to the robot. By the end of the course, attendees will gain familiarity with the Isaac Sim interface and documentation necessary to initiate their own robot simulation projects.
The prerequisites for this course include a Windows or Linux computer capable of installing Omniverse Launcher and applications, along with adequate internet bandwidth for client/server streaming. The course is free of charge, with a duration of 30 minutes, focusing on Omniverse technology.
To learn the course and know more in detail check it out here – https://courses.nvidia.com/courses/course-v1:DLI+T-OV-01+V1/
13. How to Build Open USD Applications for industrial twins
This course introduces the basics of the Omniverse development platform. One will learn how to get started building 3D applications and tools that deliver the functionality needed to support industrial use cases and workflows for aggregating and reviewing large facilities such as factories, warehouses, and more.
The learning objectives include building an application from a kit template, customising the application via settings, creating and modifying extensions, and expanding extension functionality with new features.
To learn the course and know more in detail check it out here – https://learn.nvidia.com/courses/course-detail?course_id=course-v1:DLI+S-OV-13+V1
14. Disaster Risk Monitoring Using Satellite Imagery
Created in collaboration with the United Nations Satellite Centre, the course focuses on disaster risk monitoring using satellite imagery, teaching participants to create and implement deep learning models for automated flood detection. The skills gained aim to reduce costs, enhance efficiency, and improve the effectiveness of disaster management efforts.
Participants will learn to execute a machine learning workflow, process large satellite imagery data using hardware-accelerated tools, and apply transfer-learning for building cost-effective deep learning models.
The course also covers deploying models for near real-time analysis and utilising deep learning-based inference for flood event detection and response. Prerequisites include proficiency in Python 3, a basic understanding of machine learning and deep learning concepts, and an interest in satellite imagery manipulation.
To learn the course and know more in detail check it out here – https://courses.nvidia.com/courses/course-v1:DLI+S-ES-01+V1/
15. Introduction to AI in the Data Center
In this course, you will learn about AI use cases, machine learning, and deep learning workflows, as well as the architecture and history of GPUs. With a beginner-friendly approach, the course also covers deployment considerations for AI workloads in data centres, including infrastructure planning and multi-system clusters.
The course is tailored for IT professionals, system and network administrators, DevOps, and data centre professionals.
To learn the course and know more in detail check it out here – https://www.coursera.org/learn/introduction-ai-data-center
16. Fundamentals of Working with Open USD
In this course, participants will explore the foundational concepts of Universal Scene Description (OpenUSD), an open framework for detailed 3D environment creation and collaboration.
Participants will learn to use USD for non-destructive processes, efficient scene assembly with layers, and data separation for optimised 3D workflows across various industries.
Also, the session will cover Layering and Composition essentials, model hierarchy principles for efficient scene structuring, and Scene Graph Instancing for improved scene performance and organisation.
To know more about the course check it out here – https://learn.nvidia.com/courses/course-detail?course_id=course-v1:DLI+S-OV-15+V1
17. Introduction to Physics-informed Machine Learning with Modulus
High-fidelity simulations in science and engineering are hindered by computational expense and time constraints, limiting their iterative use in design and optimisation.
NVIDIA Modulus, a physics machine learning platform, tackles these challenges by creating deep learning models that outperform traditional methods by up to 100,000 times, providing fast and accurate simulation results.
One will learn how Modulus integrates with the Omniverse Platform and how to use its API for data-driven and physics-driven problems, addressing challenges from deep learning to multi-physics simulations.
To learn the course and know more in detail check it out here – https://learn.nvidia.com/courses/course-detail?course_id=course-v1:DLI+S-OV-04+V1
18. Introduction to DOCA for DPUs
The DOCA Software Framework, in partnership with BlueField DPUs, enables rapid application development, transforming networking, security, and storage performance.
This self-paced course covers DOCA fundamentals for accelerated data centre computing on DPUs, including visualising the framework paradigm, studying BlueField DPU specs, exploring sample applications, and identifying opportunities for DPU-accelerated computation.
One gains introductory knowledge to kickstart application development for enhanced data centre services.
To learn the course and know more in detail check it out here – https://learn.nvidia.com/courses/course-detail?course_id=course-v1:DLI+S-NP-01+V1
The story was updated on 2nd Jan, 25 to reflect the latest courses and correct the URLs to them.




















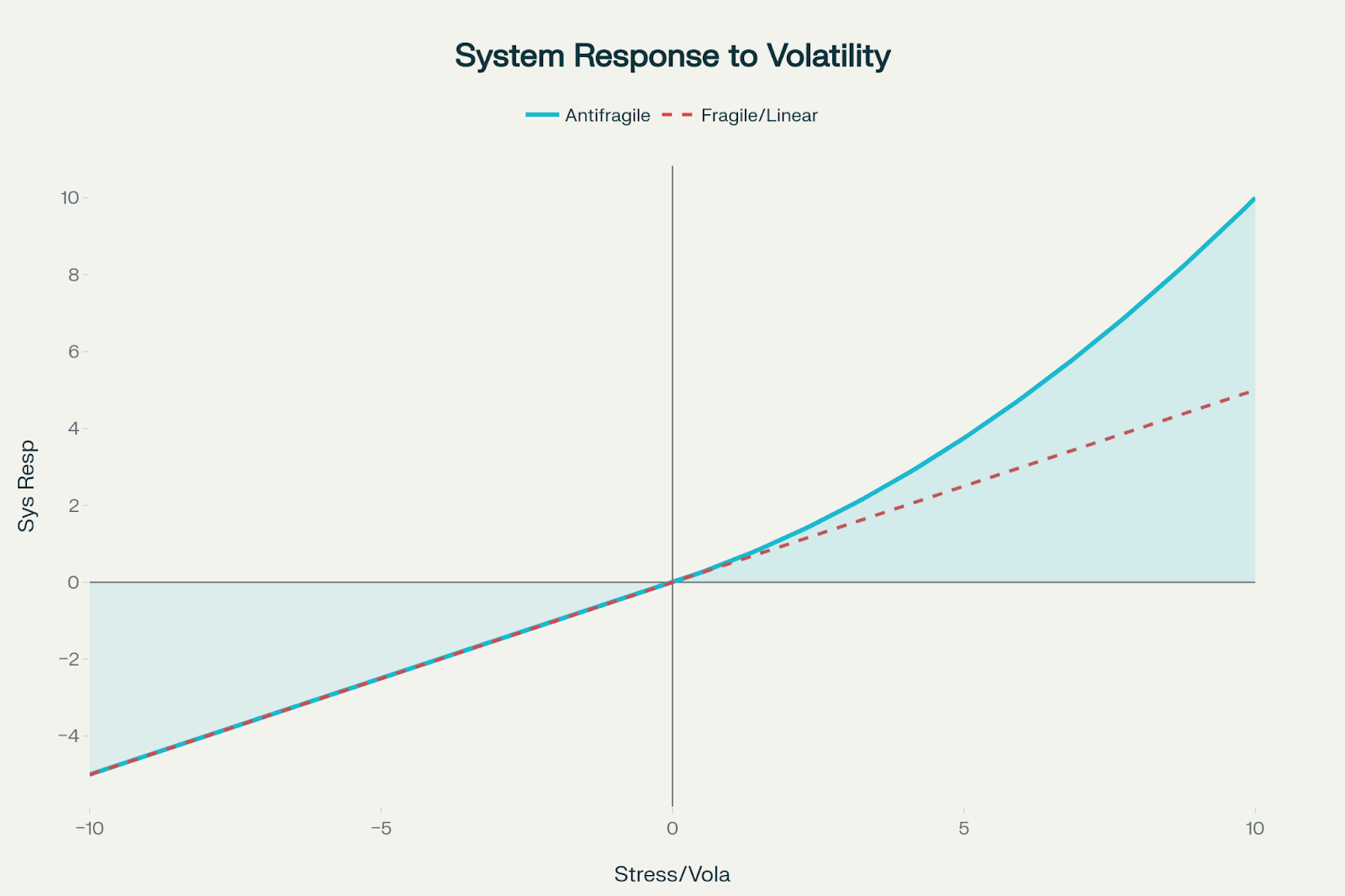
What if uncertainty wasn’t something to simply endure but something to actively exploit? The convergence of Nassim Taleb’s antifragility principles with generative AI capabilities is creating a new paradigm for organizational design powered by generative AI—one where volatility becomes fuel for competitive advantage rather than a threat to be managed.
The Antifragility Imperative
Antifragility transcends resilience. While resilient systems bounce back from stress and robust systems resist change, antifragile systems actively improve when exposed to volatility, randomness, and disorder. This isn’t just theoretical—it’s a mathematical property where systems exhibit positive convexity, gaining more from favorable variations than they lose from unfavorable ones.
To visualize the concept of positive convexity in antifragile systems, consider a graph where the x-axis represents stress or volatility and the y-axis represents the system’s response. In such systems, the curve is upward bending (convex), demonstrating that the system gains more from positive shocks than it loses from negative ones—by an accelerating margin.
The convex (upward-curving) line shows that small positive shocks yield increasingly larger gains, while equivalent negative shocks cause comparatively smaller losses.
For comparison, a straight line representing a fragile or linear system shows a proportional (linear) response, with gains and losses of equal magnitude on either side.
The concept emerged from Taleb’s observation that certain systems don’t just survive Black Swan events—they thrive because of them. Consider how Amazon’s supply chain AI during the 2020 pandemic demonstrated true antifragility. When lockdowns disrupted normal shipping patterns and consumer behavior shifted dramatically, Amazon’s demand forecasting systems didn’t just adapt; they used the chaos as training data. Every stockout, every demand spike for unexpected products like webcams and exercise equipment, every supply chain disruption became input for improving future predictions. The AI learned to identify early signals of changing consumer behavior and supply constraints, making the system more robust for future disruptions.
For technology organizations, this presents a fundamental question: How do we design systems that don’t just survive unexpected events but benefit from them? The answer lies in implementing specific generative AI architectures that can learn continuously from disorder.
Generative AI: Building Antifragile Capabilities
Certain generative AI implementations can exhibit antifragile characteristics when designed with continuous learning architectures. Unlike static models deployed once and forgotten, these systems incorporate feedback loops that allow real-time adaptation without full model retraining—a critical distinction given the resource-intensive nature of training large models.
Netflix’s recommendation system demonstrates this principle. Rather than retraining its entire foundation model, the company continuously updates personalization layers based on user interactions. When users reject recommendations or abandon content midstream, this negative feedback becomes valuable training data that refines future suggestions. The system doesn’t just learn what users like. It becomes expert at recognizing what they’ll hate, leading to higher overall satisfaction through accumulated negative knowledge.
The key insight is that these AI systems don’t just adapt to new conditions; they actively extract information from disorder. When market conditions shift, customer behavior changes, or systems encounter edge cases, properly designed generative AI can identify patterns in the chaos that human analysts might miss. They transform noise into signal, volatility into opportunity.
Error as Information: Learning from Failure
Traditional systems treat errors as failures to be minimized. Antifragile systems treat errors as information sources to be exploited. This shift becomes powerful when combined with generative AI’s ability to learn from mistakes and generate improved responses.
IBM Watson for Oncology’s failure has been attributed to synthetic data problems, but it highlights a critical distinction: Synthetic data isn’t inherently problematic—it’s essential in healthcare where patient privacy restrictions limit access to real data. The issue was that Watson was trained exclusively on synthetic, hypothetical cases created by Memorial Sloan Kettering physicians rather than being validated against diverse real-world outcomes. This created a dangerous feedback loop where the AI learned physician preferences rather than evidence-based medicine.
When deployed, Watson recommended potentially fatal treatments—such as prescribing bevacizumab to a 65-year-old lung cancer patient with severe bleeding, despite the drug’s known risk of causing “severe or fatal hemorrhage.” A truly antifragile system would have incorporated mechanisms to detect when its training data diverged from reality—for instance, by tracking recommendation acceptance rates and patient outcomes to identify systematic biases.
This challenge extends beyond healthcare. Consider AI diagnostic systems deployed across different hospitals. A model trained on high-end equipment at a research hospital performs poorly when deployed to field hospitals with older, poorly calibrated CT scanners. An antifragile AI system would treat these equipment variations not as problems to solve but as valuable training data. Each “failed” diagnosis on older equipment becomes information that improves the system’s robustness across diverse deployment environments.
Netflix: Mastering Organizational Antifragility
Netflix’s approach to chaos engineering exemplifies organizational antifragility in practice. The company’s famous “Chaos Monkey” randomly terminates services in production to ensure the system can handle failures gracefully. But more relevant to generative AI is its content recommendation system’s sophisticated approach to handling failures and edge cases.
When Netflix’s AI began recommending mature content to family accounts rather than simply adding filters, its team created systematic “chaos scenarios”—deliberately feeding the system contradictory user behavior data to stress-test its decision-making capabilities. They simulated situations where family members had vastly different viewing preferences on the same account or where content metadata was incomplete or incorrect.
The recovery protocols the team developed go beyond simple content filtering. Netflix created hierarchical safety nets: real-time content categorization, user context analysis, and human oversight triggers. Each “failure” in content recommendation becomes data that strengthens the entire system. The AI learns what content to recommend but also when to seek additional context, when to err on the side of caution, and how to gracefully handle ambiguous situations.
This demonstrates a key antifragile principle: The system doesn’t just prevent similar failures—it becomes more intelligent about handling edge cases it has never encountered before. Netflix’s recommendation accuracy improved precisely because the system learned to navigate the complexities of shared accounts, diverse family preferences, and content boundary cases.
Technical Architecture: The LOXM Case Study
JPMorgan’s LOXM (Learning Optimization eXecution Model) represents the most sophisticated example of antifragile AI in production. Developed by the global equities electronic trading team under Daniel Ciment, LOXM went live in 2017 after training on billions of historical transactions. While this predates the current era of transformer-based generative AI, LOXM was built using deep learning techniques that share fundamental principles with today’s generative models: the ability to learn complex patterns from data and adapt to new situations through continuous feedback.
Multi-agent architecture: LOXM uses a reinforcement learning system where specialized agents handle different aspects of trade execution.
- Market microstructure analysis agents learn optimal timing patterns.
- Liquidity assessment agents predict order book dynamics in real time.
- Impact modeling agents minimize market disruption during large trades.
- Risk management agents enforce position limits while maximizing execution quality.
Antifragile performance under stress: While traditional trading algorithms struggled with unprecedented conditions during the market volatility of March 2020, LOXM’s agents used the chaos as learning opportunities. Each failed trade execution, each unexpected market movement, each liquidity crisis became training data that improved future performance.
The measurable results were striking. LOXM improved execution quality by 50% during the most volatile trading days—exactly when traditional systems typically degrade. This isn’t just resilience; it’s mathematical proof of positive convexity where the system gains more from stressful conditions than it loses.
Technical innovation: LOXM prevents catastrophic forgetting through “experience replay” buffers that maintain diverse trading scenarios. When new market conditions arise, the system can reference similar historical patterns while adapting to novel situations. The feedback loop architecture uses streaming data pipelines to capture trade outcomes, model predictions, and market conditions in real time, updating model weights through online learning algorithms within milliseconds of trade completion.
The Information Hiding Principle
David Parnas’s information hiding principle directly enables antifragility by ensuring that system components can adapt independently without cascading failures. In his 1972 paper, Parnas emphasized hiding “design decisions likely to change”—exactly what antifragile systems need.
When LOXM encounters market disruption, its modular design allows individual components to adapt their internal algorithms without affecting other modules. The “secret” of each module—its specific implementation—can evolve based on local feedback while maintaining stable interfaces with other components.
This architectural pattern prevents what Taleb calls “tight coupling”—where stress in one component propagates throughout the system. Instead, stress becomes localized learning opportunities that strengthen individual modules without destabilizing the whole system.
Via Negativa in Practice
Nassim Taleb’s concept of “via negativa”—defining systems by what they’re not rather than what they are—translates directly to building antifragile AI systems.
When Airbnb’s search algorithm was producing poor results, instead of adding more ranking factors (the typical approach), the company applied via negativa: It systematically removed listings that consistently received poor ratings, hosts who didn’t respond promptly, and properties with misleading photos. By eliminating negative elements, the remaining search results naturally improved.
Netflix’s recommendation system similarly applies via negativa by maintaining “negative preference profiles”—systematically identifying and avoiding content patterns that lead to user dissatisfaction. Rather than just learning what users like, the system becomes expert at recognizing what they’ll hate, leading to higher overall satisfaction through subtraction rather than addition.
In technical terms, via negativa means starting with maximum system flexibility and systematically removing constraints that don’t add value—allowing the system to adapt to unforeseen circumstances rather than being locked into rigid predetermined behaviors.
Implementing Continuous Feedback Loops
The feedback loop architecture requires three components: error detection, learning integration, and system adaptation. In LOXM’s implementation, market execution data flows back into the model within milliseconds of trade completion. The system uses streaming data pipelines to capture trade outcomes, model predictions, and market conditions in real time. Machine learning models continuously compare predicted execution quality to actual execution quality, updating model weights through online learning algorithms. This creates a continuous feedback loop where each trade makes the next trade execution more intelligent.
When a trade execution deviates from expected performance—whether due to market volatility, liquidity constraints, or timing issues—this immediately becomes training data. The system doesn’t wait for batch processing or scheduled retraining; it adapts in real time while maintaining stable performance for ongoing operations.
Organizational Learning Loop
Antifragile organizations must cultivate specific learning behaviors beyond just technical implementations. This requires moving beyond traditional risk management approaches toward Taleb’s “via negativa.”
The learning loop involves three phases: stress identification, system adaptation, and capability improvement. Teams regularly expose systems to controlled stress, observe how they respond, and then use generative AI to identify improvement opportunities. Each iteration strengthens the system’s ability to handle future challenges.
Netflix institutionalized this through monthly “chaos drills” where teams deliberately introduce failures—API timeouts, database connection losses, content metadata corruption—and observe how their AI systems respond. Each drill generates postmortems focused not on blame but on extracting learning from the failure scenarios.
Measurement and Validation
Antifragile systems require new metrics beyond traditional availability and performance measures. Key metrics include:
- Adaptation speed: Time from anomaly detection to corrective action
- Information extraction rate: Number of meaningful model updates per disruption event
- Asymmetric performance factor: Ratio of system gains from positive shocks to losses from negative ones
LOXM tracks these metrics alongside financial outcomes, demonstrating quantifiable improvement in antifragile capabilities over time. During high-volatility periods, the system’s asymmetric performance factor consistently exceeds 2.0—meaning it gains twice as much from favorable market movements as it loses from adverse ones.
The Competitive Advantage
The goal isn’t just surviving disruption—it’s creating competitive advantage through chaos. When competitors struggle with market volatility, antifragile organizations extract value from the same conditions. They don’t just adapt to change; they actively seek out uncertainty as fuel for growth.
Netflix’s ability to recommend content accurately during the pandemic, when viewing patterns shifted dramatically, gave it a significant advantage over competitors whose recommendation systems struggled with the new normal. Similarly, LOXM’s superior performance during market stress periods has made it JPMorgan’s primary execution algorithm for institutional clients.
This creates sustainable competitive advantage because antifragile capabilities compound over time. Each disruption makes the system stronger, more adaptive, and better positioned for future challenges.
Beyond Resilience: The Antifragile Future
We’re witnessing the emergence of a new organizational paradigm. The convergence of antifragility principles with generative AI capabilities represents more than incremental improvement—it’s a fundamental shift in how organizations can thrive in uncertain environments.
The path forward requires commitment to experimentation, tolerance for controlled failure, and systematic investment in adaptive capabilities. Organizations must evolve from asking “How do we prevent disruption?” to “How do we benefit from disruption?”
The question isn’t whether your organization will face uncertainty and disruption—it’s whether you’ll be positioned to extract competitive advantage from chaos when it arrives. The integration of antifragility principles with generative AI provides the roadmap for that transformation, demonstrated by organizations like Netflix and JPMorgan that have already turned volatility into their greatest strategic asset.
Books, Courses & Certifications
Student Scores in Math, Science, Reading Slide Again on Nation’s Report Card

Exasperating. Depressing. Predictable.
That’s how experts describe the latest results from the National Assessment of Educational Progress, also known as the “nation’s report card.”
Considered a highly accurate window into student performance, the assessment has become a periodic reminder of declining academic success among students in the U.S., with the last several rounds accentuating yearslong slumps in learning. In January, for instance, the previous round of NAEP results revealed the biggest share of eighth graders who did not meet basic reading proficiency in the assessment’s history.
Now, the latest results, released Tuesday after a delay, showed continued decline.
Eighth graders saw the first fall in average science scores since the assessment took its current form in 2009. The assessment looked at physical science, life science, and earth and space sciences. Thirty-eight percent of students performed below basic, a level which means these students probably don’t know that plants need sunlight to grow and reproduce, according to NAEP. In contrast, only 31 percent of students performed at proficient levels.
Twelfth graders saw a three-point fall in average math and reading scores, compared to results from 2019. The exam also shows that the achievement gap between high- and low-scoring students is swelling, a major point of concern. In math, the gap is wider than it’s ever been.
But most eye-grabbing is the fact that 45 percent of high school seniors — the highest percentage ever recorded — scored below basic in math, meaning they cannot determine probabilities of simple events from two-way tables and verbal descriptions. In contrast, just 22 percent scored at-or-above proficient. In reading, 32 percent scored below basic, and 35 percent met the proficient threshold. Twelfth grade students also reported high rates of absenteeism.
Tucked inside the report was the finding that parents’ education did not appear to hold much sway on student performance in the lower quartiles, which will bear further unpacking, according to one expert’s first analysis.
But the scores contained other glum trends, as well.
For example, the gap in outcomes in the sciences between male and female students, which had narrowed in recent years, bounced back. (A similar gap in math reappeared since the pandemic, pushing educators to get creative in trying to nourish girls’ interest in the subject.)
But with teacher shortages and schools facing enrollment declines and budget shortfalls, experts say it’s not surprising that students still struggle. Those who watch education closely describe themselves as tired, exasperated and even depressed from watching a decade’s worth of student performance declines. They also express doubt that political posturing around the scores will translate into improvements.
Political Posturing
Despite a sterling reputation, the assessment found itself snagged by federal upheaval.
NAEP is a congressionally mandated program run by the National Center for Education Statistics. Since the last round of results was released, back in January, the center and the broader U.S. Department of Education have dealt with shredded contracts, mass firings and the sudden dismissal of Peggy Carr, who’d helped burnish the assessment’s reputation and statistical rigor and whose firing delayed the release of these latest results.
The country’s education system overall has also undergone significant changes, including the introduction of a national school choice plan, meant to shift public dollars to private schools, through the Republican budget.
Declining scores provide the Trump administration a potential cudgel for its dismantling of public education, and some have seized upon it: Congressman Tim Walberg, a Republican from Michigan and chairman of the House Education and Workforce Committee, blamed the latest scores on the Democrats’ “student-last policies,” in a prepared statement.
“The lesson is clear,” argued Education Secretary Linda McMahon in her comment on the latest scores. “Success isn’t about how much money we spend, but who controls the money and where that money is invested,” she wrote, stressing that students need an approach that returns control education to the states.
Some observers chortle at the “back to the states” analysis. After all, state and local governments already control most of the policies and spending related to public schools.
Regardless, experts suggest that just pushing more of education governance to the states will not solve the underlying causes of declining student performance. Declines in scores predate the pandemic, they also say.
No Real Progress
States have always been in charge of setting their own standards and assessments, says Latrenda Knighten, president of the National Council of Teachers of Mathematics. These national assessments are useful for comparing student performance across states, she adds.
Ultimately, in her view, the latest scores reveal the need for efforts to boost high-quality instruction and continuous professional learning for teachers to address systemic issues, a sentiment reflected in her organization’s public comment on the assessment. The results shine a spotlight on the need for greater opportunity in high school mathematics across the country, Knighten told EdSurge. She believes that means devoting more money for teacher training.
Some think that the causes of this academic slide are relatively well understood.
Teacher quality has declined, as teacher prep programs struggle to supply qualified teachers, particularly in math, and schools struggle to fill vacancies, says Robin Lake, director of the Center on Reinventing Public Education. She argues there has also been a decline in the desire to push schools to be accountable for poor student performance, and an inability to adapt.
There’s also confusion about which curriculum is best for students, she says. For instance, fierce debates continue to split teachers around “tracking,” where students are grouped into math paths based on perceived ability.
But will yet another poor national assessment spur change?
The results continue a decade-long decline in student performance, says Christy Hovanetz, a senior policy fellow for the nonprofit ExcelinEd.
Hovanetz worries that NAEP’s potential lessons will get “lost in the wash.” What’s needed is a balance between turning more authority back over to the states to operate education and a more robust requirement for accountability that allows states to do whatever they want, so long as they demonstrate it’s actually working, she says. That could mean requiring state assessments and accountability systems, she adds.
But right now, a lot of the states aren’t focusing on best practices for science and reading instruction, and they aren’t all requiring high-quality instructional materials, she says.
Worse, some are lowering the standards to meet poor student performance, she argues. For instance, Kansas recently altered its state testing. The changes, which involved changing score ranges, have drawn concerns from parents that the state is watering down standards. Hovanetz thinks that’s the case. In making the changes, the state joined Illinois, Wisconsin and Oklahoma in lowering expectations for students on state tests, she argues.
What’s uncontested from all perspectives is that the education system isn’t working.
“It’s truly the definition of insanity: to keep doing what we’re doing and hoping for better results,” says Lake, of the Center on Reinventing Public Education, adding: “We’re not getting them.”

When the National Assessment of Educational Progress, often called the Nation’s Report Card, was released last year, the results were sobering. Despite increased funding streams and growing momentum behind the Science of Reading, average fourth grade reading scores declined by another two points from 2022.
In a climate of growing accountability and public scrutiny, how can we do things differently — and more effectively — to ensure every child becomes a proficient reader?
The answer lies not only in what happens inside the classroom but in the connections forged between schools and families. Research shows that when families are equipped with the right tools and guidance, literacy development accelerates. For many schools, creating this home-to-school connection begins by rethinking how they communicate with and involve families from the start.
A School-Family Partnership in Practice
My own experience with my son William underscored just how impactful a strong school-family partnership can be.
When William turned four, he began asking, “When will I be able to read?” He had watched his older brother learn to read with relative ease, and, like many second children, William was eager to follow in his big brother’s footsteps. His pre-K teacher did an incredible job introducing foundational literacy skills, but for William, it wasn’t enough. He was ready to read, but we, his parents, weren’t sure how to support him.
During a parent-teacher conference, his teacher recommended a free, ad-free literacy app that she uses in her classroom. She assigned stories to read and phonics games to play that aligned with his progress at school. The characters in the app became his friends, and the activities became his favorite challenge. Before long, he was recognizing letters on street signs, rhyming in the car and asking to read his favorite stories over and over again.
William’s teacher used insights from his at-home learning to personalize his instruction in the classroom. For our family, this partnership made a real difference.
Where Literacy Begins: Bridging Home and School
Reading develops in stages, and the pre-K to kindergarten years are especially foundational. According to the National Reading Panel and the Institute of Education Sciences, five key pillars support literacy development:
- Phonemic awareness: recognizing and playing with individual sounds in spoken words
- Phonics: connecting those sounds to written letters
- Fluency: reading with ease, accuracy and expression
- Vocabulary: understanding the meaning of spoken and written words
- Comprehension: making sense of what is read
For schools, inviting families into this framework doesn’t mean making parents into teachers. It means providing simple ways for families to reinforce these pillars at home, often through everyday routines, such as reading together, playing language games or talking about daily activities.
Families are often eager to support their children’s reading, but many aren’t sure how. At the same time, educators often struggle to communicate academic goals to families in ways that are clear and approachable.
Three Ways to Strengthen School-Family Literacy Partnerships
Forging effective partnerships between schools and families can feel daunting, but small, intentional shifts can make a powerful impact. Here are three research-backed strategies that schools can use to bring families into the literacy-building process.
1. Communicate the “why” and the “how”
Families become vital partners when they understand not just what their children are learning, but why it matters. Use newsletters, family literacy nights or informal conversations to break down the five pillars in accessible terms. For example, explain that clapping out syllables at home supports phonemic awareness or that spotting road signs helps with letter recognition (phonics).
Even basic activities can reinforce classwork. Sample ideas for family newsletters:
- “This week we’re working on beginning sounds. Try playing a game where you name things in your house that start with the letter ‘B’.”
- “We’re focusing on listening to syllables in words. See if your child can clap out the beats in their name!”
Provide families with specific activities that match what is being taught at school. For example, William’s teacher used the Khan Academy Kids app to assign letter-matching games and read-aloud books that aligned with classroom learning. The connection made it easier for us to support him at home.
2. Establish everyday reading routines
Consistency builds confidence. Encourage families to create regular reading moments, such as a story before bed, a picture book over breakfast or a read-aloud during bath time. Reinforce that reading together in any language is beneficial. Oral storytelling, silly rhymes and even talking through the day’s events help develop vocabulary and comprehension.
Help parents understand that it’s okay to stop when it’s no longer fun. If a child isn’t interested, it’s better to pause and return later than to force the activity. The goal is for children to associate reading with enjoyment and a sense of connection.
3. Empower families with fun, flexible tools
Families are more likely to participate when activities are playful and accessible, not just another assignment. Suggest resources that fit different family preferences: printable activity sheets, suggested library books and no-cost, ad-free digital platforms, such as Khan Academy Kids. These give children structured ways to practice and offer families tools that are easy to use, even with limited time.
In our district, many families use technology to extend classroom skills at home. For William, a rhyming game on a literacy app made practicing phonological awareness fun and stress-free; he returned to it repeatedly, reinforcing new skills through play.
Literacy Grows Best in Partnership
School-family partnerships also offer educators valuable feedback. When families share observations about what excites or challenges their children at home, teachers gain a fuller picture of each student’s progress. Digital platforms, such as teacher, school and district-level reporting, can support this feedback loop by providing teachers with real-time data on at-home practice. This two-way exchange strengthens instruction and empowers both families and educators.
While curriculum, assessment and skilled teaching are essential, literacy is most likely to flourish when nurtured by both schools and families. When educators invite families into the process — demystifying the core elements of literacy, sharing routines and providing flexible, accessible tools — they help create a culture where reading is valued everywhere.
Strong school-family partnerships don’t just address achievement gaps. They lay the groundwork for the joy, confidence and curiosity that help children become lifelong readers.
At Khan Academy Kids, we believe in the power of the school-family partnership. For free resources to help strengthen children’s literacy development, explore the Khan Academy Kids resource hub for schools.
-

 Business2 weeks ago
Business2 weeks agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-
Tools & Platforms1 month ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy2 months ago
Ethics & Policy2 months agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences4 months ago
Events & Conferences4 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers2 months ago
Jobs & Careers2 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Education2 months ago
Education2 months agoMacron says UK and France have duty to tackle illegal migration ‘with humanity, solidarity and firmness’ – UK politics live | Politics
-

 Education2 months ago
Education2 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Funding & Business2 months ago
Funding & Business2 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi