Books, Courses & Certifications
‘School Choice’ Causes Confusion for Families. Can Edtech Companies Help?

Hayley Leibson, a mother from Mill Valley, a wealthy area just north of San Francisco, started hunting for a language-immersion child care program when her son was 8 months old.
“I thought I was really early,” Leibson says, noting that her son wasn’t going to attend until he turned 2. Some schools laughed her out of the room, telling her that other families applied as soon as they became pregnant.
Transitional kindergarten, a public early education program for 4-year-olds in California that provides a structured bridge between preschool and kindergarten, had been cut from her region for the 2025-2026 school year. Leibson says she felt the cut put extra pressure on her to find a private option.
But right away she noticed that the application process presented what she thought were ludicrous hurdles. Schools asked Leibson to write essays about her son’s “learning style” — before he could even talk — and demanded specific details about Leibson’s connection to families already attending those programs, such as listing out the last time she saw them and what they did together.
Mostly, Leibson spent a lot of time vetting programs. Meetings occurred when it was convenient for the care providers, meaning Leibson had to rearrange her own work schedule. Before inspecting a program, Leibson found it nearly impossible to discern whether the school seemed to her like a money-grab that didn’t care much about the kids. Options with rave reviews on Google would be run-down when she visited.
“It was like a part-time job — very time-consuming and hard,” she says.
It helped her to chat with teachers and other parents, who warned her of pest problems and other issues. “The most valuable are people who don’t go [to a school] anymore,” she adds.
After going through all that, programs would reject her son because he had difficulty napping or because of rules about potty training she considered wacky. When offers came in, providers would “explode” if Leibson didn’t accept within a short period of time, sometimes as brief as 24 hours.
So eventually, Leibson turned to a “navigator,” an edtech tool that helps parents sort through early education options. The tool lists parent reviews of schools and relevant information including how much the programs cost, streamlining the search process and providing more finely tuned information than Google. Leibson finally found child care. By that time, the whole process had dragged on for months.
Soon, that arduous experience might also become the norm for families trying to pick a primary or secondary school.
Driven by the rise of school vouchers, the company behind the navigator recently moved into K-12 education, in an attempt to build a “comprehensive” tool for parents struggling to figure out how to choose a school for their child. Indeed, there are a growing number of companies trying to help parents handle K-12 school options, according to Matthew Tower, vice president of strategy and research for Whiteboard Advisors, an education consultancy and advocacy firm.
Company leaders believe that what has helped mothers like Leibson navigate the confusion of finding child care and preschools in a country that lacks a robust public early education system could provide families a workable way to manage private school options for older kids, too, which suffer some of the same problems.
But other experts aren’t so sure, arguing that it might mask the issues with the emergent school choice system.

Struggling With Choice
When Donald Trump entered his second term as president, he boosted the “school choice” movement. Already making headway across the country, the system has reached new major milestones this year, such as when Texas signed a $1 billion voucher system into law at the beginning of May. And the GOP’s One Big Beautiful Bill Act, signed into law on July 4, includes a national school voucher plan, setting up scholarships for families to attend private schools around the country, which opponents term a “tax shelter” for wealthy private school supporters. States will have to opt in due to a last-minute change to the bill.
At the state level, these voucher systems divert money from public schools for parents to use on private school tuition, fees or related expenses. The systems are controversial, and a number of states have resisted them. Supporters claim they enhance parents’ choices, thereby improving educational quality. But opponents counter that they starve public schools of money and lower the quality of education in the country, also often pointing to the use of this system to evade school integration in Southern states after the 1954 Supreme Court decision in Brown v. Board of Education. These days, private schools retain greater leeway in turning away students, and they have weaker legal requirements for dealing with students with disabilities. Critics also point to some research that suggests vouchers are associated with a decline in student performance for low-income students.
The early childhood market is distinct from these K-12 options — for instance, early childhood is more fragmented, and chronically underfunded, according to David Blau, a labor and population economist and a professor emeritus at Ohio State University.
But there are some parallels between the child care subsidy system — which offsets the costs of programs that families in some states choose for their young children — and these new K-12 vouchers. For example, they have both proved thorny tangles for families, who have difficulty assessing quality of programs or making meaningful choices because there’s little accurate, accessible data about student academic outcomes at different institutions. They also lack adequate regulations, according to some researchers.
The similarities are at least strong enough that one edtech company says it can help parents across both markets.
Winnie, the child care marketplace navigator that Leibson used to find a preschool, expanded into K-12 schools this year. The company is trying to give parents a comprehensive search-and-filter tool for public, charter and private schools, says CEO Sara Mauskopf. The lines between early learning and K-12 schooling have blurred, with an uptick in the number of children attending independent schools from a younger age, Mauskopf says.
Now, the company has noticed a shift in what parents are searching for on its marketplace. These days, about 20 percent of parents on Winnie are exploring choices for children over the age of 5, according to Mauskopf. She attributes this largely to the rise of options. That includes school vouchers, which create a new incentive for families to shop around among charter and private schools rather than automatically enroll children in their assigned district public school. Mauskopf says that public charter schools also market heavily to families.
This new behavior is pushing Winnie further into the K-12 space. Mauskopf expects that the number of schools marketing directly to parents will only increase.
‘Smoke and Mirrors’
While marketplace navigators are relatively common in early childhood education, they are unusual in K-12, according to researchers. Mauskopf views her main competition as sites like Yelp or Google, to which some parents turn for information about prospective schools or child care options.
But some experts warn that this expanded approach is a cause for concern.
Cramming the disparate education systems together for parents in one tool can conceal meaningful differences, such as the fact that the child care world lacks a strong public system, unlike in K-12, as most students in the country already attend public elementary, middle and high schools, says Paige Shoemaker DeMio, a senior policy analyst for K-12 at the Center for American Progress (CAP).
The navigator doesn’t have transparent student performance data that would clarify which options are high quality, and yet parents will be likely to trust that school options listed on the app are good ones, according to CAP researchers. And the results families see when they use the tool are not totally objective, because schools can influence their profiles. Schools listed on the site can claim their page to update information and receive inquiries from parents. When a school changes its description, a disclaimer is added, according to Mauskopf.
The company also offers schools a service called Winnie Pro that boosts their listing in parents’ search results, and which allows schools to customize their listing on the site and track their performance more closely. For any given parent’s search, how many sponsored pages appear depends on the specifics of the search, and it rotates based on how many parent leads Winnie has already sent the school so far that month, Mauskopf says.
If the school voucher movement succeeds in directing more families away from public schools and toward charter or private schools, parents may indeed appreciate help making choices, perhaps through these kinds of tools. But giving parents a navigator doesn’t really solve the core issues that arise from having to choose among private and charter child care programs and schools, Shoemaker DeMio says, such as tuition prices that are too high to afford, admission policies that exclude students with disabilities or secretive practices that obscure data about how much students are learning.
By creating the illusion of transparency and accessibility, navigation tools may make it more difficult for families to actually exercise meaningful choices about education — making it all “smoke and mirrors,” Shoemaker DeMio argues.
What do families think — will they use the navigator for K-12 charter and private schools?
Some are.
Shannon Parola, a mother from El Dorado County, near Sacramento, struggled to adjust to a transitional kindergarten for her asthmatic daughter.
The family had moved from the Bay Area, where Parola had worked as a nanny. After the move, Parola used Winnie to find a private child care program that worked well.
But not long after, the family had a second child on the way. And with rising child care costs, they decided to “rip the Band-Aid off,” moving their daughter to the public transitional kindergarten program just down the street from where they lived, in the same elementary school zoned for their house.
When Parola got her daughter’s first report card back, it startled her. It was only October, and yet the report card indicated there was nowhere for her daughter to improve, Parola says. She was already meeting their standards, Parola recalls. Still, the school wouldn’t bump her daughter to kindergarten, citing a lack of room. Parola, who volunteered in her daughter’s classroom, noticed her complaining of boredom. She worried that the cycle would repeat itself the next year. So, the family moved her to a charter homeschool program.
They pay “out the butt” for the program, she says. But she’s happy with how it worked out, she adds: “We wanted the best for our daughter.”

She’s less happy with how long the process took.
To find the program, Parola tried Greatschools.com, a nonprofit rating system for schools, also used by realty companies like Zillow for third-party evaluations of public schools. But Parola says the ratings weren’t terribly reliable or hadn’t been updated in a long time, meaning she had to cross-reference information with local moms on Facebook.
That was before Winnie’s K-12 search, and the process dragged on for an entire year, Parola says. Without a one-stop shop for evaluating all the possibilities available to her — public, charter, private and homeschool options — Parola felt as if she was being denied the information that would have allowed her to make a truly informed choice.
Now Parola, who runs a child care coaching business, recommends the navigator service to other parents. She’s also used it for more recent searches, including for finding summer care and camps. That’s because it lists all the options — including ones that are tough to find through Google reviews — while also capturing information about licensing and safety measures, Parola says.
Mauskopf says that demand is driving the company’s expansion, showing that families are using the marketplace tool to wade through the sea of private and charter K-12 options in front of them.
Certainly, when talking to other parents, Parola can feel the strain making these choices puts on them.
“I think parents are just so overwhelmed, not only with choices [but] with life and everything,” she says. “If you talk about, ‘Oh, now I’ve got to learn a whole process of how to find my kid’s school, how to find child care,’ it sends them down into a deep spiral.”
Books, Courses & Certifications
How Skello uses Amazon Bedrock to query data in a multi-tenant environment while keeping logical boundaries
This is a guest post co-written with Skello.
Skello is a leading human resources (HR) software as a service (SaaS) solution focusing on employee scheduling and workforce management. Catering to diverse sectors such as hospitality, retail, healthcare, construction, and industry, Skello offers features including schedule creation, time tracking, and payroll preparation. With approximately 20,000 customers and 400,000 daily users across Europe as of 2024, Skello continually innovates to meet its clients’ evolving needs.
One such innovation is the implementation of an AI-powered assistant to enhance user experience and data accessibility. In this post, we explain how Skello used Amazon Bedrock to create this AI assistant for end-users while maintaining customer data safety in a multi-tenant environment. Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
We dive deep into the challenges of implementing large language models (LLMs) for data querying, particularly in the context of a French company operating under the General Data Protection Regulation (GDPR). Our solution demonstrates how to balance powerful AI capabilities with strict data protection requirements.
Challenges with multi-tenant data access
As Skello’s platform grew to serve thousands of businesses, we identified a critical need: our users needed better ways to access and understand their workforce data. Many of our customers, particularly those in HR and operations roles, found traditional database querying tools too technical and time-consuming. This led us to identify two key areas for improvement:
- Quick access to non-structured data – Our users needed to find specific information across various data types—employee records, scheduling data, attendance logs, and performance metrics. Traditional search methods often fell short when users had complex questions like “Show me all part-time employees who worked more than 30 hours last month” or “What’s the average sick leave duration in the retail department?”
- Visualization of data through graphs for analytics – Although our platform collected comprehensive workforce data, users struggled to transform this raw information into actionable insights. They needed an intuitive way to create visual representations of trends and patterns without writing complex SQL queries or learning specialized business intelligence tools.
To address these challenges, we needed a solution that could:
- Understand natural language questions about complex workforce data
- Correctly interpret context and intent from user queries
- Generate appropriate database queries while respecting data access rules
- Return results in user-friendly formats, including visualizations
- Handle variations in how users might phrase similar questions
- Process queries about time-based data and trends
LLMs emerged as the ideal solution for this task. Their ability to understand natural language and context, combined with their capability to generate structured outputs, made them perfectly suited for translating user questions into precise database queries. However, implementing LLMs in a business-critical application required careful consideration of security, accuracy, and performance requirements.
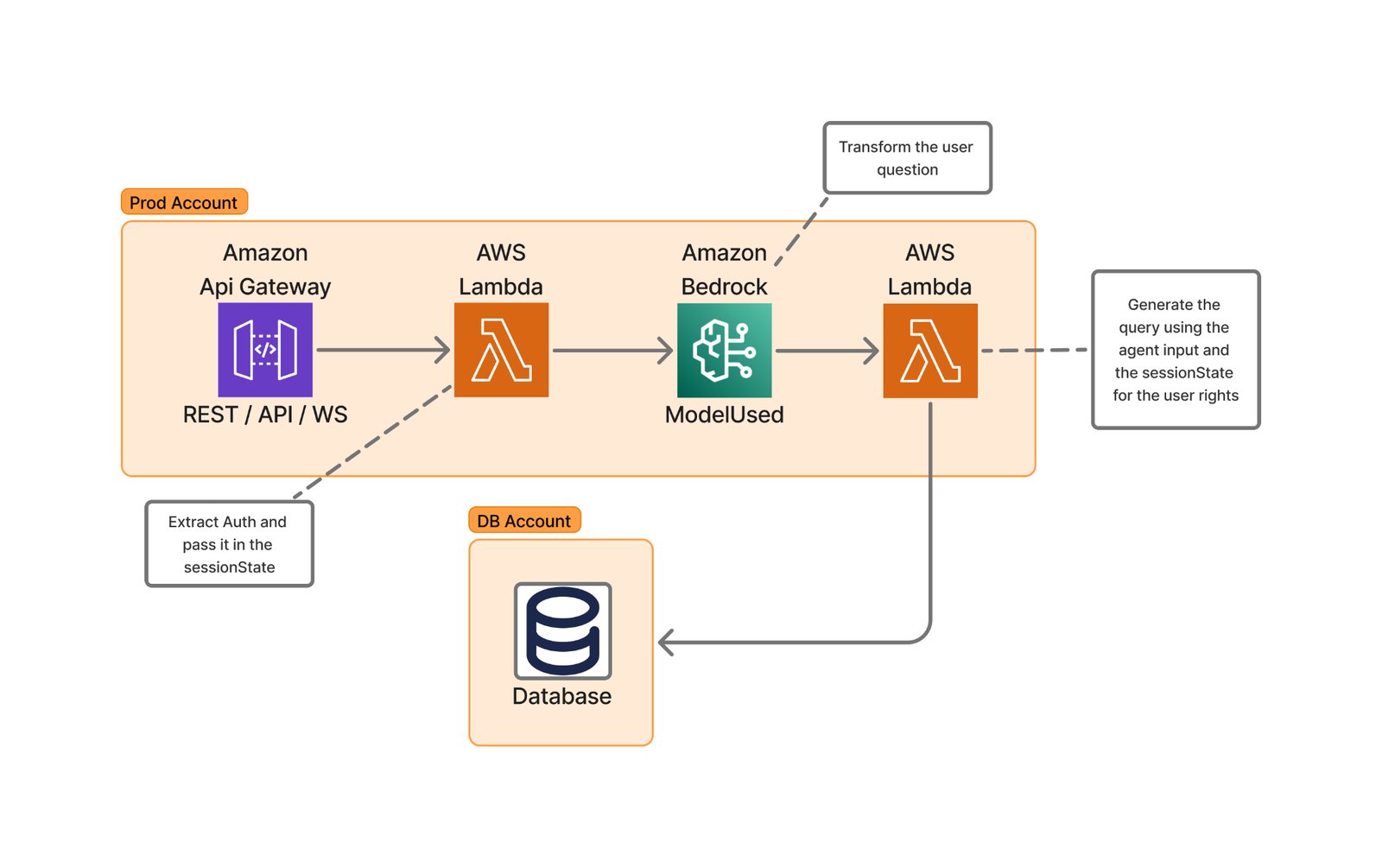
Solution overview
Using LLMs to generate structured queries from natural language input is an emerging area of interest. This process enables the transformation of user requests into organized data structures, which can then be used to query databases automatically.
The following diagram of Skello’s high-level architecture illustrates this user request transformation process.
The implementation using AWS Lambda and Amazon Bedrock provides several advantages:
- Scalability through serverless architecture
- Cost-effective processing with pay-as-you-go pricing
- Low-latency performance
- Access to advanced language models like Anthropic’s Claude 3.5 Sonnet
- Rapid deployment capabilities
- Flexible integration options
Basic query generation process
The following diagram illustrates how we transform natural language queries into structured database requests. For this example, the user asks “Give me the gender parity.”
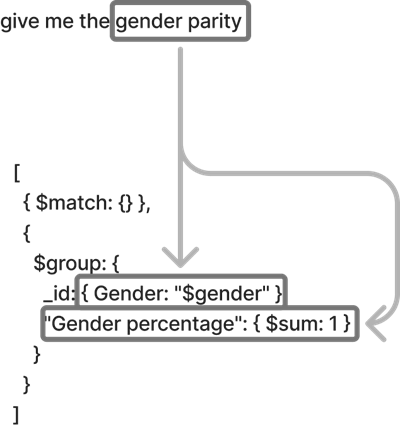
The process works as follows:
- The authentication service validates the user’s identity and permissions.
- The LLM converts the natural language to a structured query format.
- The query validation service enforces compliance with security policies.
- The database access layer executes the query within the user’s permitted scope.
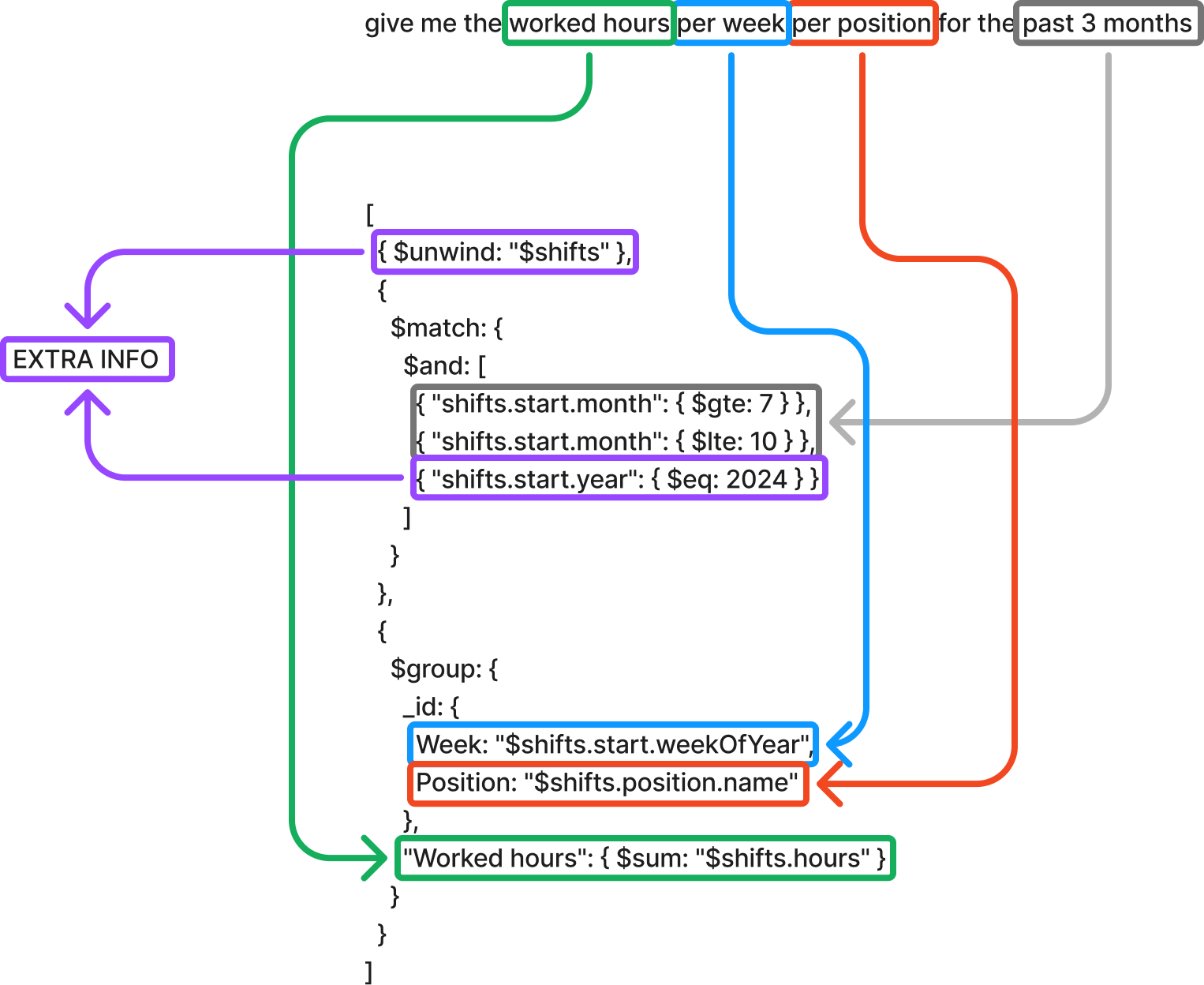
Handling complex queries
For more sophisticated requests like “Give me the worked hours per week per position for the last 3 months,” our system completes the following steps:
- Extract query components:
- Target metric: worked hours
- Aggregation levels: week, position
- Time frame: 3 months
- Generate temporal calculations:
- Use relative time expressions instead of hard-coded dates
- Implement standardized date handling patterns
Data schema optimization
To make our system as efficient and user-friendly as possible, we carefully organized our data structure—think of it as creating a well-organized filing system for a large office.
We created standardized schema definitions, establishing consistent ways to store similar types of information. For example, date-related fields (hire dates, shift times, vacation periods) follow the same format. This helps prevent confusion when users ask questions like “Show me all events from last week.” It’s similar to having all calendars in your office using the same date format instead of some using MM/DD/YY and others using DD/MM/YY.
Our system employs consistent naming conventions with clear, predictable names for all data fields. Instead of technical abbreviations like emp_typ_cd, we use clear terms like employee_type. This makes it straightforward for the AI to understand what users mean when they ask questions like “Show me all full-time employees.”
For optimized search patterns, we strategically organized our data to make common searches fast and efficient. This is particularly important because it directly impacts user experience and system performance. We analyzed usage patterns to identify the most frequently requested information and designed our database indexes accordingly. Additionally, we created specialized data views that pre-aggregate common report requests. This comprehensive approach means questions like “Who’s working today?” get answered almost instantly.
We also established clear data relationships by mapping out how different pieces of information relate to each other. For example, we clearly connect employees to their departments, shifts, and managers. This helps answer complex questions like “Show me all department managers who have team members on vacation next week.”
These optimizations deliver real benefits to our users:
- Faster response times when asking questions
- More accurate answers to queries
- Less confusion when referring to specific types of data
- Ability to ask more complex questions about relationships between different types of information
- Consistent results when asking similar questions in different ways
For example, whether a user asks “Show me everyone’s vacation time” or “Display all holiday schedules,” the system understands they’re looking for the same type of information. This reliability makes the system more trustworthy and easier to use for everyone, regardless of their technical background.
Graph generation and display
One of the most powerful features of our system is its ability to turn data into meaningful visual charts and graphs automatically. This consists of the following actions:
- Smart label creation – The system understands what your data means and creates clear, readable labels. For example, if you ask “Show me employee attendance over the last 6 months,” the horizontal axis automatically labels the months (January through June), the vertical axis shows attendance numbers with simple-to-read intervals, and the title clearly states what you’re looking at: “Employee Attendance Trends.”
- Automatic legend creation – The system creates helpful legends that explain what each part of the chart means. For instance, if you ask “Compare sales across different departments,” different departments get different colors, a clear legend shows which color represents which department, and additional information like “Dashed lines show previous year” is automatically added when needed.
- Choosing the right type of chart – The system is smart about picking the best way to show your information. For example, it uses bar charts for comparing different categories (“Show me sales by department”), line graphs for trends over time (“How has attendance changed this year?”), pie charts for showing parts of a whole (“What’s the breakdown of full-time vs. part-time staff?”), and heat maps for complex patterns (“Show me busiest hours per day of the week”).
- Smart sizing and scaling – The system automatically adjusts the size and scale of charts to make them simple to read. For example, if numbers range from 1–100, it might show intervals of 10; if you’re looking at millions, it might show them in a more readable way (1M, 2M, etc.); charts automatically resize to show patterns clearly; and important details are never too small to see.
All of this happens automatically—you ask your question, and the system handles the technical details of creating a clear, professional visualization. For example, the following figure is an example for the question “How many hours my employees worked over the past 7 weeks?”

Security-first architecture
Our implementation adheres to OWASP best practices (specifically LLM06) by maintaining complete separation between security controls and the LLM.
Through dedicated security services, user authentication and authorization checks are performed before LLM interactions, with user context and permissions managed through Amazon Bedrock SessionParameters, keeping security information entirely outside of LLM processing.
Our validation layer uses Amazon Bedrock Guardrails to protect against prompt injection, inappropriate content, and forbidden topics such as racism, sexism, or illegal content.
The system’s architecture implements strict role-based access controls through a detailed permissions matrix, so users can only access data within their authorized scope. For authentication, we use industry-standard JWT and SAML protocols, and our authorization service maintains granular control over data access permissions.
This multi-layered approach prevents potential security bypasses through prompt manipulation or other LLM-specific attacks. The system automatically enforces data boundaries at both database and API levels, effectively preventing cross-contamination between different customer accounts. For instance, department managers can only access their team’s data, with these restrictions enforced through database compartmentalization.
Additionally, our comprehensive audit system maintains immutable logs of all actions, including timestamps, user identifiers, and accessed resources, stored separately to protect their integrity. This security framework operates seamlessly in the background, maintaining robust protection of sensitive information without disrupting the user experience or legitimate workflows.
Benefits
Creating data visualizations has never been more accessible. Even without specialized expertise, you can now produce professional-quality charts that communicate your insights effectively. The streamlined process makes sure your visualizations remain consistently clear and intuitive, so you can concentrate on exploring your data questions instead of spending time on presentation details.
The solution works through simple conversational requests that require no technical knowledge or specialized software. You simply describe what you want to visualize using everyday language and the system interprets your request and creates the appropriate visualization. There’s no need to learn complex software interfaces, remember specific commands, or understand data formatting requirements. The underlying technology handles the data processing, chart selection, and professional formatting automatically, transforming your spoken or written requests into polished visual presentations within moments.
Your specific information needs to drive how the data is displayed, making the insights more relevant and actionable. When it’s time to share your findings, these visualizations seamlessly integrate into your reports and presentations with polished formatting that enhances your overall message. This democratization of data visualization empowers everyone to tell compelling data stories.
Conclusion
In this post, we explored Skello’s implementation of an AI-powered assistant using Amazon Bedrock and Lambda. We saw how end-users can query their own data in a multi-tenant environment while maintaining logical boundaries and complying with GDPR regulations. The combination of serverless architecture and advanced language models proved effective in enhancing data accessibility and user experience.
We invite you to explore the AWS Machine Learning Blog for more insights on AI solutions and their potential business applications. If you’re interested in learning more about Skello’s journey in modernizing HR software, check out our blog post series on the topic.
If you have any questions or suggestions about implementing similar solutions in your own multi-tenant environment, please feel free to share them in the comments section.
About the authors
 Nicolas de Place is a Data & AI Solutions Architect specializing in machine learning strategy for high-growth startups. He empowers emerging companies to harness the full potential of artificial intelligence and advanced analytics, designing scalable ML architectures and data-driven solutions
Nicolas de Place is a Data & AI Solutions Architect specializing in machine learning strategy for high-growth startups. He empowers emerging companies to harness the full potential of artificial intelligence and advanced analytics, designing scalable ML architectures and data-driven solutions
 Cédric Peruzzi is a Software Architect at Skello, where he focuses on designing and implementing Generative AI features. Before his current role, he worked as a software engineer and architect, bringing his experience to help build better software solutions.
Cédric Peruzzi is a Software Architect at Skello, where he focuses on designing and implementing Generative AI features. Before his current role, he worked as a software engineer and architect, bringing his experience to help build better software solutions.
Books, Courses & Certifications
Create a private workforce on Amazon SageMaker Ground Truth with the AWS CDK
Private workforces for Amazon SageMaker Ground Truth and Amazon Augmented AI (Amazon A2I) help organizations build proprietary, high-quality datasets while keeping high standards of security and privacy.
The AWS Management Console provides a fast and intuitive way to create a private workforce, but many organizations need to automate their infrastructure deployment through infrastructure as code (IaC) because it provides benefits such as automated and consistent deployments, increased operational efficiency, and reduced chances of human errors or misconfigurations.
However, creating a private workforce with IaC is not a straightforward task because of some complex technical dependencies between services during the initial creation.
In this post, we present a complete solution for programmatically creating private workforces on Amazon SageMaker AI using the AWS Cloud Development Kit (AWS CDK), including the setup of a dedicated, fully configured Amazon Cognito user pool. The accompanying GitHub repository provides a customizable AWS CDK example that shows how to create and manage a private workforce, paired with a dedicated Amazon Cognito user pool, and how to integrate the necessary Amazon Cognito configurations.
Solution overview
This solution demonstrates how to create a private workforce and a coupled Amazon Cognito user pool and its dependent resources. The goal is to provide a comprehensive setup for the base infrastructure to enable machine learning (ML) labeling tasks.
The key technical challenge in this solution is the mutual dependency between the Amazon Cognito resources and the private workforce.
Specifically, the creation of the user pool app client requires certain parameters, such as the callback URL, which is only available after the private workforce is created. However, the private workforce creation itself needs the app client to be already present. This mutual dependency makes it challenging to set up the infrastructure in a straightforward manner.
Additionally, the user pool domain name must remain consistent across deployments, because it can’t be easily changed after the initial creation and inconsistency in the name can lead to deployment errors.
To address these challenges, the solution uses several AWS CDK constructs, including AWS CloudFormation custom resources. This custom approach allows the orchestration of the user pool and SageMaker private workforce creation, to correctly configure the resources and manage their interdependencies.
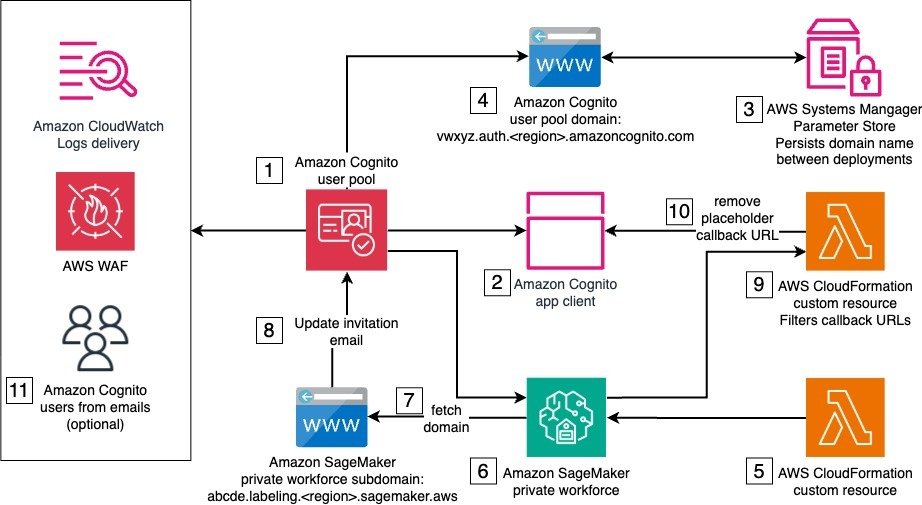
The solution architecture is composed of one stack with several resources and services, some of which are needed only for the initial setup of the private workforce, and some that are used by the private workforce workers when logging in to complete a labeling task. The following diagram illustrates this architecture.
The solution’s deployment requires AWS services and resources that work together to set up the private workforce. The numbers in the diagram reflect the stack components that support the stack creation, which occur in the following order:
- Amazon Cognito user pool – The user pool provides user management and authentication for the SageMaker private workforce. It handles user registration, login, and password management. A default email invitation is initially set to onboard new users to the private workforce. The user pool is both associated with an AWS WAF firewall and configured to deliver user activity logs to Amazon CloudWatch for enhanced security.
- Amazon Cognito user pool app client – The user pool app client configures the client application that will interact with the user pool. During the initial deployment, a temporary placeholder callback URL is used, because the actual callback URL can only be determined later in the process.
- AWS Systems Manager Parameter Store – Parameter Store, a capability of AWS Systems Manager, stores and persists the prefix of the user pool domain across deployments in a string parameter. The provided prefix must be such that the resulting domain is globally unique.
- Amazon Cognito user pool domain – The user pool domain defines the domain name for the managed login experience provided by the user pool. This domain name must remain consistent across deployments, because it can’t be easily changed after the initial creation.
- IAM roles – AWS Identity and Access Management (IAM) roles for CloudFormation custom resources include permissions to make AWS SDK calls to create the private workforce and other API calls during the next steps.
- Private workforce – Implemented using a custom resource backing the CreateWorkforce API call, the private workforce is the foundation to manage labeling activities. It creates the labeling portal and manages portal-level access controls, including authentication through the integrated user pool. Upon creation, the labeling portal URL is made available to be used as a callback URL by the Amazon Cognito app client. The connected Amazon Cognito app client is automatically updated with the new callback URL.
- SDK call to fetch the labeling portal domain – This SDK call reads the subdomain of labeling portal. This is implemented as a CloudFormation custom resource.
- SDK call to update user pool – This SDK call updates the user pool with a user invitation email that points to the labeling portal URL. This is implemented as a CloudFormation custom resource.
- Filter for placeholder callback URL – Custom logic separates the placeholder URL from the app client’s callback URLs. This is implemented as a CloudFormation custom resource, backed by a custom AWS Lambda function.
- SDK call to update the app client to remove the placeholder callback URL – This SDK call updates the app client with the correct callback URLs. This is implemented as a CloudFormation custom resource.
- User creation and invitation emails – Amazon Cognito users are created and sent invitation emails with instructions to join the private workforce.
After this initial setup, a worker can join the private workforce and access the labeling. The authentication flow includes the email invitation, initial registration, authentication, and login to the labeling portal. The following diagram illustrates this workflow.
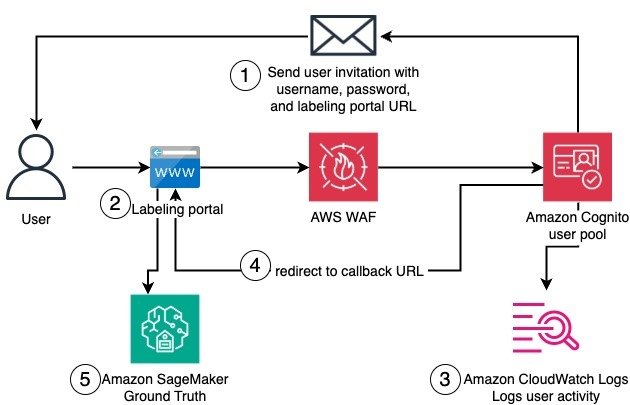
The detailed workflow steps are as follows:
- A worker receives an email invitation that provides the user name, temporary password, and URL of the labeling portal.
- When trying to reach the labeling portal, the worker is redirected to the Amazon Cognito user pool domain for authentication. Amazon Cognito domain endpoints are additionally protected by AWS WAF. The worker then sets a new password and registers with multi-factor authentication.
- Authentication actions by the worker are logged and sent to CloudWatch.
- The worker can log in and is redirected to the labeling portal.
- In the labeling portal, the worker can access existing labeling jobs in SageMaker Ground Truth.
The solution uses a mix of AWS CDK constructs and CloudFormation custom resources to integrate the Amazon Cognito user pool and the SageMaker private workforce so workers can register and access the labeling portal. In the following sections, we show how to deploy the solution.
Prerequisites
You must have the following prerequisites:
Deploy the solution
To deploy the solution, complete the following steps. Make sure you have AWS credentials available in your environment with sufficient permissions to deploy the solution resources.
- Clone the GitHub repository.
- Follow the detailed instructions in the README file to deploy the stack using the AWS CDK and AWS CLI.
- Open the AWS CloudFormation console and choose the
Workforcestack for more information on the ongoing deployment and the created resources.
Test the solution
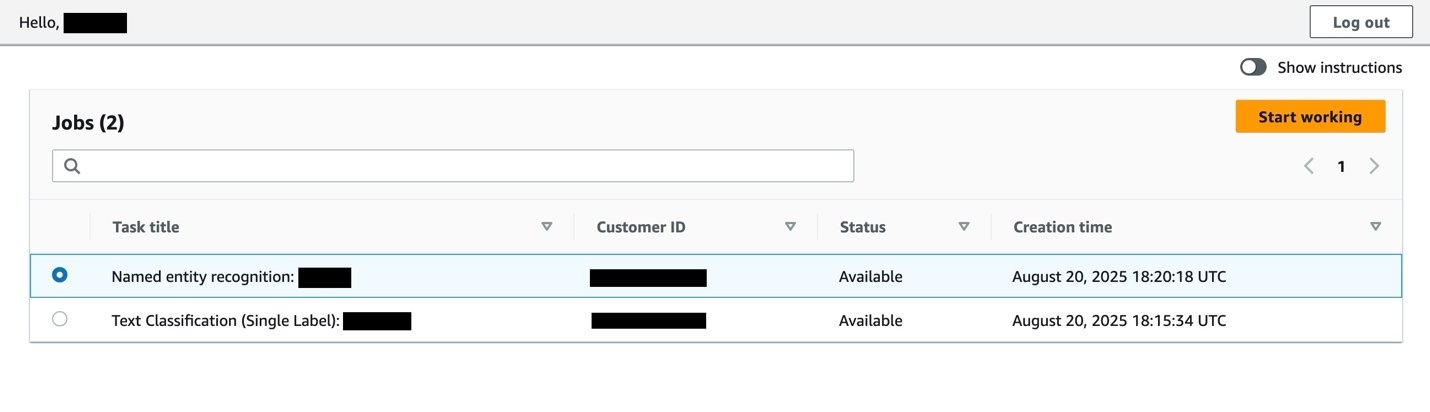
If you invited yourself from the AWS CDK CLI to join the private workforce, follow the instructions in the email that you received to register and access the labeling portal. Otherwise, complete the following steps to invite yourself and others to join the private workforce. For more information, see Creating a new user in the AWS Management Console.
- On the Amazon Cognito console, choose User pools in the navigation pane.
- Choose the existing user pool,
MyWorkforceUserPool. - Choose Users, then choose Create a user.
- Choose Email as the alias attribute to sign in.
- Choose Send an email invitation as the invitation message.
- For User name, enter a name for the new user. Make sure not to use the email address.
- For Email address, enter the email address of the worker to be invited.
- For simplicity, choose Generate a password for the user.
- Choose Create.
After you receive the invitation email, follow the instructions to set a new password and register with an authenticator application. Then you can log in and see a page listing your labeling jobs.
Best practices and considerations
When setting up a private workforce, consider the best practices for Amazon Cognito and the AWS CDK, as well as additional customizations:
- Customized domain – Provide your own prefix for the Amazon Cognito subdomain when deploying the solution. This way, you can use a more recognizable domain name for the labeling application, rather than a randomly generated one. For even greater customization, integrate the user pool with a custom domain that you own. This gives you full control over the URL used for the login and aligns it with the rest your organization’s applications.
- Enhance security controls – Depending on your organization’s security and compliance requirements, you can further adapt the Amazon Cognito resources, for instance, by integrating with external identity providers and following other security best practices.
- Implement VPC configuration – You can implement additional security controls, such as adding a virtual private cloud (VPC) configuration to the private workforce. This helps you enhance the overall security posture of your solution, providing an additional layer of network-level security and isolation.
- Restrict the source IPs – When creating the SageMaker private workforce, you can specify a list of IP addresses ranges (CIDR) from which workers can log in.
- AWS WAF customization – Bring your own existing AWS WAF or configure one to your organization’s needs by setting up custom rules, IP filtering, rate-based rules, and web access control lists (ACLs) to protect your application.
- Integrate with CI/CD – Incorporate the IaC in a continuous integration and continuous delivery (CI/CD) pipeline to standardize deployment, track changes, and further improve resource tracking and observability also across multiple environments (for instance, development, staging, production).
- Extend the solution – Depending on your specific use case, you might want to extend the solution to include the creation and management of work teams and labeling jobs or flows. This can help integrate the private workforce setup more seamlessly with your existing ML workflows and data labeling processes.
- Integrate with additional AWS services – To suit your specific requirements, you can further integrate the private workforce and user pool with other relevant AWS services, such as CloudWatch for logging, monitoring, and alarms, and Amazon Simple Notification Service (Amazon SNS) for notifications to enhance the capabilities of your data labeling solution.
Clean up
To clean up your resources, open the AWS CloudFormation console and delete the Workforce stack. Alternatively, if you deployed using the AWS CDK CLI, you can run cdk destroy from the same terminal where you ran cdk deploy and use the same AWS CDK CLI arguments as during deployment.
Conclusion
This solution demonstrates how to programmatically create a private workforce on SageMaker Ground Truth, paired with a dedicated and fully configured Amazon Cognito user pool. By using the AWS CDK and AWS CloudFormation, this solution brings the benefits of IaC to the setup of your ML data labeling private workforce.
To further customize this solution to meet your organization’s standards, discover how to accelerate your journey on the cloud with the help of AWS Professional Services.
We encourage you to learn more from the developer guides on data labeling on SageMaker and Amazon Cognito user pools. Refer to the following blog posts for more examples of labeling data using SageMaker Ground Truth:
About the author
 Dr. Giorgio Pessot is a Machine Learning Engineer at Amazon Web Services Professional Services. With a background in computational physics, he specializes in architecting enterprise-grade AI systems at the confluence of mathematical theory, DevOps, and cloud technologies, where technology and organizational processes converge to achieve business objectives. When he’s not whipping up cloud solutions, you’ll find Giorgio engineering culinary creations in his kitchen.
Dr. Giorgio Pessot is a Machine Learning Engineer at Amazon Web Services Professional Services. With a background in computational physics, he specializes in architecting enterprise-grade AI systems at the confluence of mathematical theory, DevOps, and cloud technologies, where technology and organizational processes converge to achieve business objectives. When he’s not whipping up cloud solutions, you’ll find Giorgio engineering culinary creations in his kitchen.
What if uncertainty wasn’t something to simply endure but something to actively exploit? The convergence of Nassim Taleb’s antifragility principles with generative AI capabilities is creating a new paradigm for organizational design powered by generative AI—one where volatility becomes fuel for competitive advantage rather than a threat to be managed.
The Antifragility Imperative
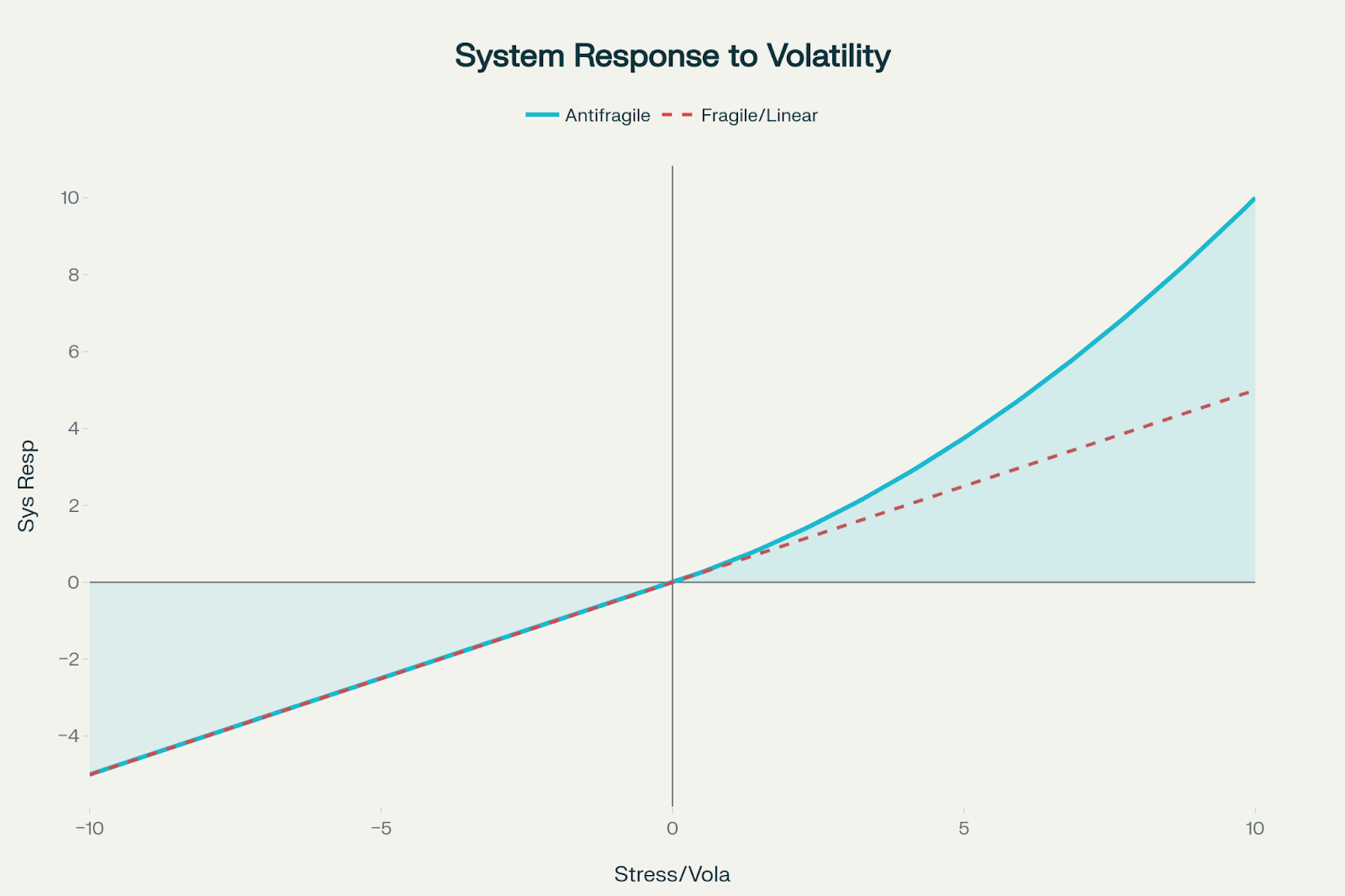
Antifragility transcends resilience. While resilient systems bounce back from stress and robust systems resist change, antifragile systems actively improve when exposed to volatility, randomness, and disorder. This isn’t just theoretical—it’s a mathematical property where systems exhibit positive convexity, gaining more from favorable variations than they lose from unfavorable ones.
To visualize the concept of positive convexity in antifragile systems, consider a graph where the x-axis represents stress or volatility and the y-axis represents the system’s response. In such systems, the curve is upward bending (convex), demonstrating that the system gains more from positive shocks than it loses from negative ones—by an accelerating margin.
The convex (upward-curving) line shows that small positive shocks yield increasingly larger gains, while equivalent negative shocks cause comparatively smaller losses.
For comparison, a straight line representing a fragile or linear system shows a proportional (linear) response, with gains and losses of equal magnitude on either side.
The concept emerged from Taleb’s observation that certain systems don’t just survive Black Swan events—they thrive because of them. Consider how Amazon’s supply chain AI during the 2020 pandemic demonstrated true antifragility. When lockdowns disrupted normal shipping patterns and consumer behavior shifted dramatically, Amazon’s demand forecasting systems didn’t just adapt; they used the chaos as training data. Every stockout, every demand spike for unexpected products like webcams and exercise equipment, every supply chain disruption became input for improving future predictions. The AI learned to identify early signals of changing consumer behavior and supply constraints, making the system more robust for future disruptions.
For technology organizations, this presents a fundamental question: How do we design systems that don’t just survive unexpected events but benefit from them? The answer lies in implementing specific generative AI architectures that can learn continuously from disorder.
Generative AI: Building Antifragile Capabilities
Certain generative AI implementations can exhibit antifragile characteristics when designed with continuous learning architectures. Unlike static models deployed once and forgotten, these systems incorporate feedback loops that allow real-time adaptation without full model retraining—a critical distinction given the resource-intensive nature of training large models.
Netflix’s recommendation system demonstrates this principle. Rather than retraining its entire foundation model, the company continuously updates personalization layers based on user interactions. When users reject recommendations or abandon content midstream, this negative feedback becomes valuable training data that refines future suggestions. The system doesn’t just learn what users like. It becomes expert at recognizing what they’ll hate, leading to higher overall satisfaction through accumulated negative knowledge.
The key insight is that these AI systems don’t just adapt to new conditions; they actively extract information from disorder. When market conditions shift, customer behavior changes, or systems encounter edge cases, properly designed generative AI can identify patterns in the chaos that human analysts might miss. They transform noise into signal, volatility into opportunity.
Error as Information: Learning from Failure
Traditional systems treat errors as failures to be minimized. Antifragile systems treat errors as information sources to be exploited. This shift becomes powerful when combined with generative AI’s ability to learn from mistakes and generate improved responses.
IBM Watson for Oncology’s failure has been attributed to synthetic data problems, but it highlights a critical distinction: Synthetic data isn’t inherently problematic—it’s essential in healthcare where patient privacy restrictions limit access to real data. The issue was that Watson was trained exclusively on synthetic, hypothetical cases created by Memorial Sloan Kettering physicians rather than being validated against diverse real-world outcomes. This created a dangerous feedback loop where the AI learned physician preferences rather than evidence-based medicine.
When deployed, Watson recommended potentially fatal treatments—such as prescribing bevacizumab to a 65-year-old lung cancer patient with severe bleeding, despite the drug’s known risk of causing “severe or fatal hemorrhage.” A truly antifragile system would have incorporated mechanisms to detect when its training data diverged from reality—for instance, by tracking recommendation acceptance rates and patient outcomes to identify systematic biases.
This challenge extends beyond healthcare. Consider AI diagnostic systems deployed across different hospitals. A model trained on high-end equipment at a research hospital performs poorly when deployed to field hospitals with older, poorly calibrated CT scanners. An antifragile AI system would treat these equipment variations not as problems to solve but as valuable training data. Each “failed” diagnosis on older equipment becomes information that improves the system’s robustness across diverse deployment environments.
Netflix: Mastering Organizational Antifragility
Netflix’s approach to chaos engineering exemplifies organizational antifragility in practice. The company’s famous “Chaos Monkey” randomly terminates services in production to ensure the system can handle failures gracefully. But more relevant to generative AI is its content recommendation system’s sophisticated approach to handling failures and edge cases.
When Netflix’s AI began recommending mature content to family accounts rather than simply adding filters, its team created systematic “chaos scenarios”—deliberately feeding the system contradictory user behavior data to stress-test its decision-making capabilities. They simulated situations where family members had vastly different viewing preferences on the same account or where content metadata was incomplete or incorrect.
The recovery protocols the team developed go beyond simple content filtering. Netflix created hierarchical safety nets: real-time content categorization, user context analysis, and human oversight triggers. Each “failure” in content recommendation becomes data that strengthens the entire system. The AI learns what content to recommend but also when to seek additional context, when to err on the side of caution, and how to gracefully handle ambiguous situations.
This demonstrates a key antifragile principle: The system doesn’t just prevent similar failures—it becomes more intelligent about handling edge cases it has never encountered before. Netflix’s recommendation accuracy improved precisely because the system learned to navigate the complexities of shared accounts, diverse family preferences, and content boundary cases.
Technical Architecture: The LOXM Case Study
JPMorgan’s LOXM (Learning Optimization eXecution Model) represents the most sophisticated example of antifragile AI in production. Developed by the global equities electronic trading team under Daniel Ciment, LOXM went live in 2017 after training on billions of historical transactions. While this predates the current era of transformer-based generative AI, LOXM was built using deep learning techniques that share fundamental principles with today’s generative models: the ability to learn complex patterns from data and adapt to new situations through continuous feedback.
Multi-agent architecture: LOXM uses a reinforcement learning system where specialized agents handle different aspects of trade execution.
- Market microstructure analysis agents learn optimal timing patterns.
- Liquidity assessment agents predict order book dynamics in real time.
- Impact modeling agents minimize market disruption during large trades.
- Risk management agents enforce position limits while maximizing execution quality.
Antifragile performance under stress: While traditional trading algorithms struggled with unprecedented conditions during the market volatility of March 2020, LOXM’s agents used the chaos as learning opportunities. Each failed trade execution, each unexpected market movement, each liquidity crisis became training data that improved future performance.
The measurable results were striking. LOXM improved execution quality by 50% during the most volatile trading days—exactly when traditional systems typically degrade. This isn’t just resilience; it’s mathematical proof of positive convexity where the system gains more from stressful conditions than it loses.
Technical innovation: LOXM prevents catastrophic forgetting through “experience replay” buffers that maintain diverse trading scenarios. When new market conditions arise, the system can reference similar historical patterns while adapting to novel situations. The feedback loop architecture uses streaming data pipelines to capture trade outcomes, model predictions, and market conditions in real time, updating model weights through online learning algorithms within milliseconds of trade completion.
The Information Hiding Principle
David Parnas’s information hiding principle directly enables antifragility by ensuring that system components can adapt independently without cascading failures. In his 1972 paper, Parnas emphasized hiding “design decisions likely to change”—exactly what antifragile systems need.
When LOXM encounters market disruption, its modular design allows individual components to adapt their internal algorithms without affecting other modules. The “secret” of each module—its specific implementation—can evolve based on local feedback while maintaining stable interfaces with other components.
This architectural pattern prevents what Taleb calls “tight coupling”—where stress in one component propagates throughout the system. Instead, stress becomes localized learning opportunities that strengthen individual modules without destabilizing the whole system.
Via Negativa in Practice
Nassim Taleb’s concept of “via negativa”—defining systems by what they’re not rather than what they are—translates directly to building antifragile AI systems.
When Airbnb’s search algorithm was producing poor results, instead of adding more ranking factors (the typical approach), the company applied via negativa: It systematically removed listings that consistently received poor ratings, hosts who didn’t respond promptly, and properties with misleading photos. By eliminating negative elements, the remaining search results naturally improved.
Netflix’s recommendation system similarly applies via negativa by maintaining “negative preference profiles”—systematically identifying and avoiding content patterns that lead to user dissatisfaction. Rather than just learning what users like, the system becomes expert at recognizing what they’ll hate, leading to higher overall satisfaction through subtraction rather than addition.
In technical terms, via negativa means starting with maximum system flexibility and systematically removing constraints that don’t add value—allowing the system to adapt to unforeseen circumstances rather than being locked into rigid predetermined behaviors.
Implementing Continuous Feedback Loops
The feedback loop architecture requires three components: error detection, learning integration, and system adaptation. In LOXM’s implementation, market execution data flows back into the model within milliseconds of trade completion. The system uses streaming data pipelines to capture trade outcomes, model predictions, and market conditions in real time. Machine learning models continuously compare predicted execution quality to actual execution quality, updating model weights through online learning algorithms. This creates a continuous feedback loop where each trade makes the next trade execution more intelligent.
When a trade execution deviates from expected performance—whether due to market volatility, liquidity constraints, or timing issues—this immediately becomes training data. The system doesn’t wait for batch processing or scheduled retraining; it adapts in real time while maintaining stable performance for ongoing operations.
Organizational Learning Loop
Antifragile organizations must cultivate specific learning behaviors beyond just technical implementations. This requires moving beyond traditional risk management approaches toward Taleb’s “via negativa.”
The learning loop involves three phases: stress identification, system adaptation, and capability improvement. Teams regularly expose systems to controlled stress, observe how they respond, and then use generative AI to identify improvement opportunities. Each iteration strengthens the system’s ability to handle future challenges.
Netflix institutionalized this through monthly “chaos drills” where teams deliberately introduce failures—API timeouts, database connection losses, content metadata corruption—and observe how their AI systems respond. Each drill generates postmortems focused not on blame but on extracting learning from the failure scenarios.
Measurement and Validation
Antifragile systems require new metrics beyond traditional availability and performance measures. Key metrics include:
- Adaptation speed: Time from anomaly detection to corrective action
- Information extraction rate: Number of meaningful model updates per disruption event
- Asymmetric performance factor: Ratio of system gains from positive shocks to losses from negative ones
LOXM tracks these metrics alongside financial outcomes, demonstrating quantifiable improvement in antifragile capabilities over time. During high-volatility periods, the system’s asymmetric performance factor consistently exceeds 2.0—meaning it gains twice as much from favorable market movements as it loses from adverse ones.
The Competitive Advantage
The goal isn’t just surviving disruption—it’s creating competitive advantage through chaos. When competitors struggle with market volatility, antifragile organizations extract value from the same conditions. They don’t just adapt to change; they actively seek out uncertainty as fuel for growth.
Netflix’s ability to recommend content accurately during the pandemic, when viewing patterns shifted dramatically, gave it a significant advantage over competitors whose recommendation systems struggled with the new normal. Similarly, LOXM’s superior performance during market stress periods has made it JPMorgan’s primary execution algorithm for institutional clients.
This creates sustainable competitive advantage because antifragile capabilities compound over time. Each disruption makes the system stronger, more adaptive, and better positioned for future challenges.
Beyond Resilience: The Antifragile Future
We’re witnessing the emergence of a new organizational paradigm. The convergence of antifragility principles with generative AI capabilities represents more than incremental improvement—it’s a fundamental shift in how organizations can thrive in uncertain environments.
The path forward requires commitment to experimentation, tolerance for controlled failure, and systematic investment in adaptive capabilities. Organizations must evolve from asking “How do we prevent disruption?” to “How do we benefit from disruption?”
The question isn’t whether your organization will face uncertainty and disruption—it’s whether you’ll be positioned to extract competitive advantage from chaos when it arrives. The integration of antifragility principles with generative AI provides the roadmap for that transformation, demonstrated by organizations like Netflix and JPMorgan that have already turned volatility into their greatest strategic asset.
-

 Business2 weeks ago
Business2 weeks agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-
Tools & Platforms1 month ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy2 months ago
Ethics & Policy2 months agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences4 months ago
Events & Conferences4 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers2 months ago
Jobs & Careers2 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Education2 months ago
Education2 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Education2 months ago
Education2 months agoMacron says UK and France have duty to tackle illegal migration ‘with humanity, solidarity and firmness’ – UK politics live | Politics
-

 Funding & Business2 months ago
Funding & Business2 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi