Books, Courses & Certifications
Accelerate foundation model development with one-click observability in Amazon SageMaker HyperPod
Amazon SageMaker HyperPod now provides a comprehensive, out-of-the-box dashboard that delivers insights into foundation model (FM) development tasks and cluster resources. This unified observability solution automatically publishes key metrics to Amazon Managed Service for Prometheus and visualizes them in Amazon Managed Grafana dashboards, optimized specifically for FM development with deep coverage of hardware health, resource utilization, and task-level performance.
With a one-click installation of the Amazon Elastic Kubernetes Service (Amazon EKS) add-on for SageMaker HyperPod observability, you can consolidate health and performance data from NVIDIA DCGM, instance-level Kubernetes node exporters, Elastic Fabric Adapter (EFA), integrated file systems, Kubernetes APIs, Kueue, and SageMaker HyperPod task operators. With this unified view, you can trace model development task performance to cluster resources with aggregation of resource metrics at the task level. The solution also abstracts management of collector agents and scrapers across clusters, offering automatic scalability of collectors across nodes as the cluster grows. The dashboards feature intuitive navigation across metrics and visualizations to help users diagnose problems and take action faster. They are also fully customizable, supporting additional PromQL metric imports and custom Grafana layouts.
These capabilities save teams valuable time and resources during FM development, helping accelerate time-to-market and reduce the cost of generative AI innovations. Instead of spending hours or days configuring, collecting, and analyzing cluster telemetry systems, data scientists and machine learning (ML) engineers can now quickly identify training, tuning, and inference disruptions, underutilization of valuable GPU resources, and hardware performance issues. The pre-built, actionable insights of SageMaker HyperPod observability can be used in several common scenarios when operating FM workloads, such as:
- Data scientists can monitor resource utilization of submitted training and inference tasks at the per-GPU level, with insights into GPU memory and FLOPs
- AI researchers can troubleshoot sub-optimal time-to-first-token (TTFT) for their inferencing workloads by correlating the deployment metrics with the corresponding resource bottlenecks
- Cluster administrators can configure customizable alerts to send notifications to multiple destinations such as Amazon Simple Notification Service (Amazon SNS), PagerDuty, and Slack when hardware falls outside of recommended health thresholds
- Cluster administrators can quickly identify inefficient resource queuing patterns across teams or namespaces to reconfigure allocation and prioritization policies
In this post, we walk you through installing and using the unified dashboards of the out-of-the-box observability feature in SageMaker HyperPod. We cover the one-click installation from the Amazon SageMaker AI console, navigating the dashboard and metrics it consolidates, and advanced topics such as setting up custom alerts. If you have a running SageMaker HyperPod EKS cluster, then this post will help you understand how to quickly visualize key health and performance telemetry data to derive actionable insights.
Prerequisites
To get started with SageMaker HyperPod observability, you first need to enable AWS IAM Identity Center to use Amazon Managed Grafana. If IAM Identity Center isn’t already enabled in your account, refer to Getting started with IAM Identity Center. Additionally, create at least one user in the IAM Identity Center.
SageMaker HyperPod observability is available for SageMaker HyperPod clusters with an Amazon EKS orchestrator. If you don’t already have a SageMaker HyperPod cluster with an Amazon EKS orchestrator, refer to Amazon SageMaker HyperPod quickstart workshops for instructions to create one.
Enable SageMaker HyperPod observability
To enable SageMaker HyperPod observability, follow these steps:
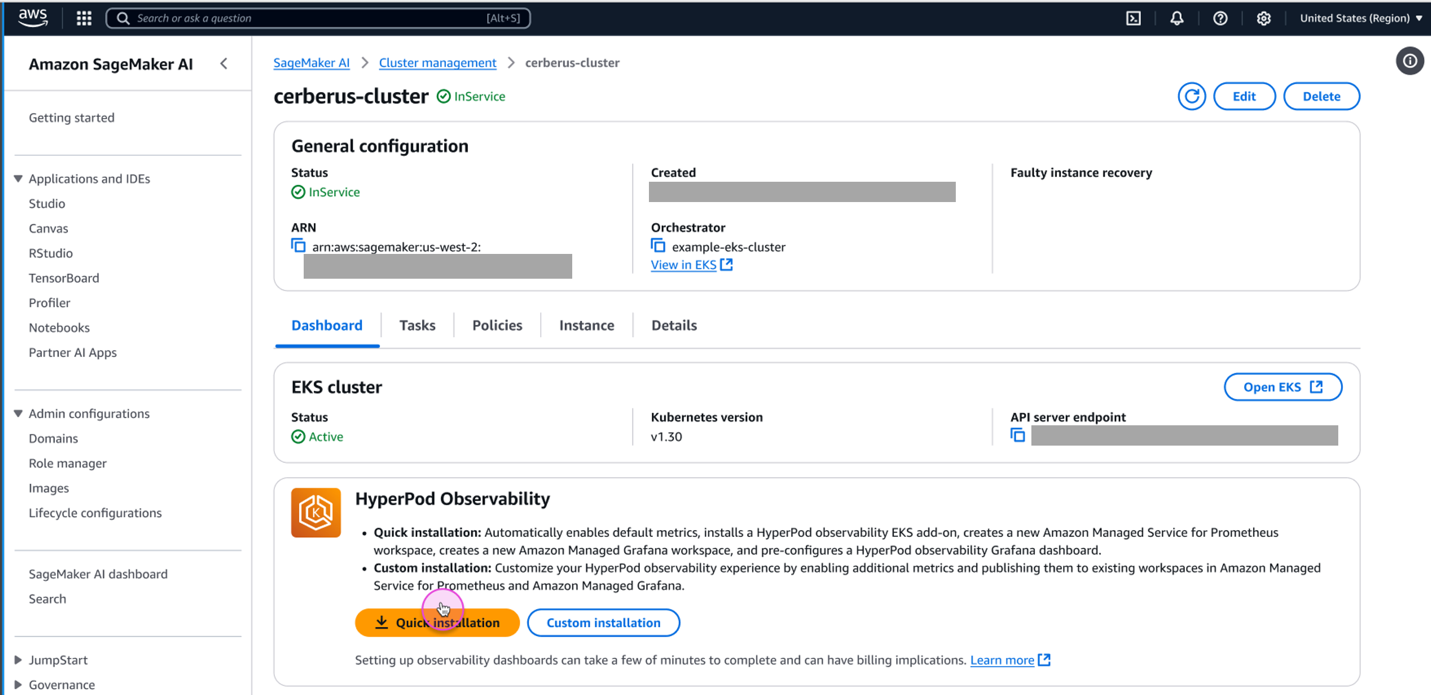
- On the SageMaker AI console, choose Cluster management in the navigation pane.
- Open the cluster detail page from the SageMaker HyperPod clusters list.
- On the Dashboard tab, in the HyperPod Observability section, choose Quick installation.
SageMaker AI will create a new Prometheus workspace, a new Grafana workspace, and install the SageMaker HyperPod observability add-on to the EKS cluster. The installation typically completes within a few minutes.
When the installation process is complete, you can view the add-on details and metrics available.
- Choose Manage users to assign a user to a Grafana workspace.
- Choose Open dashboard in Grafana to open the Grafana dashboard.
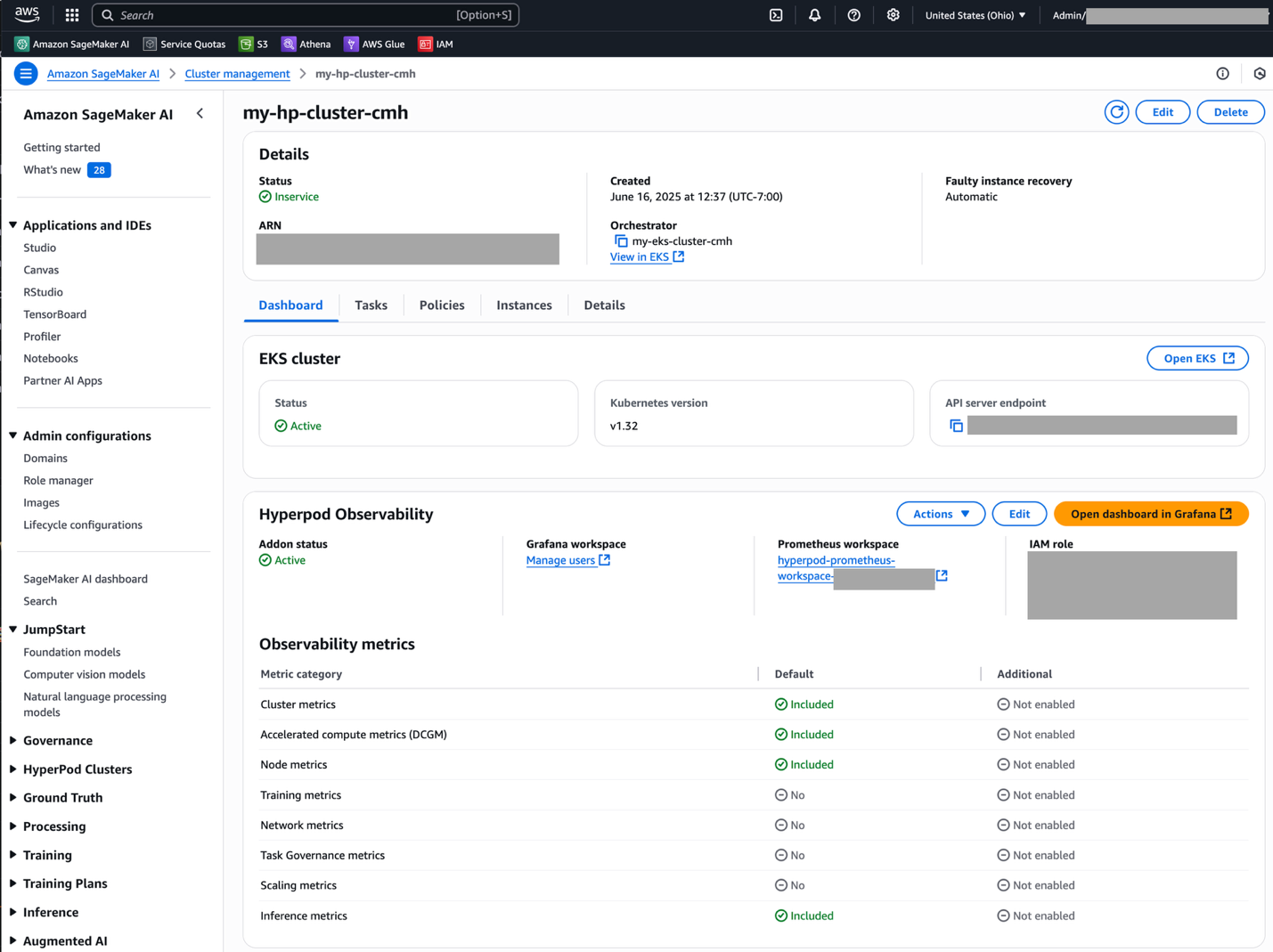
- When prompted, sign in with IAM Identity Center with the user you configured as a prerequisite.

After signing in successfully, you will see the SageMaker HyperPod observability dashboard on Grafana.
SageMaker HyperPod observability dashboards
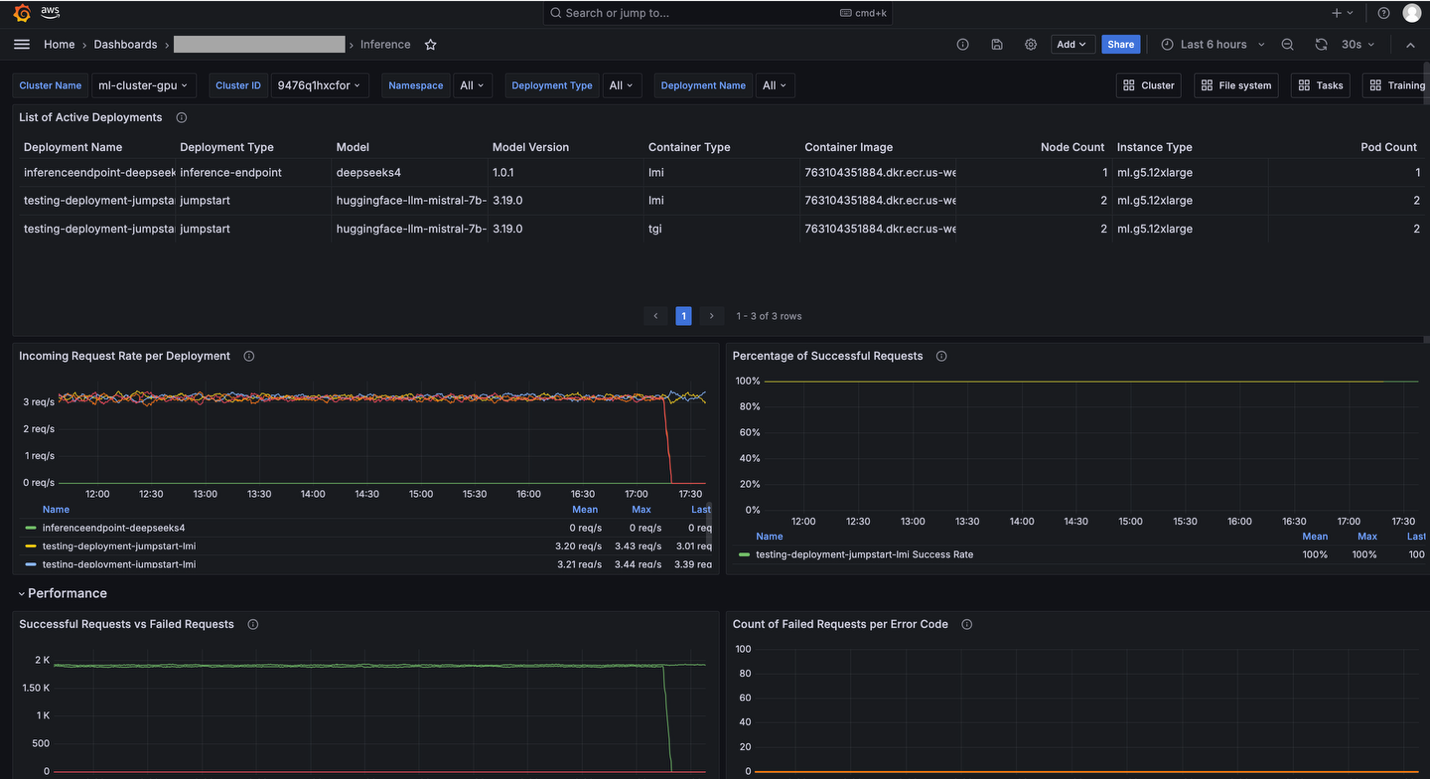
You can choose from multiple dashboards, including Cluster, Tasks, Inference, Training, and File system.
The Cluster dashboard shows cluster-level metrics such as Total Nodes and Total GPUs, and cluster node-level metrics such as GPU Utilization and Filesystem space available. By default, the dashboard shows metrics about entire cluster, but you can apply filters to show metrics only about a specific hostname or specific GPU ID.
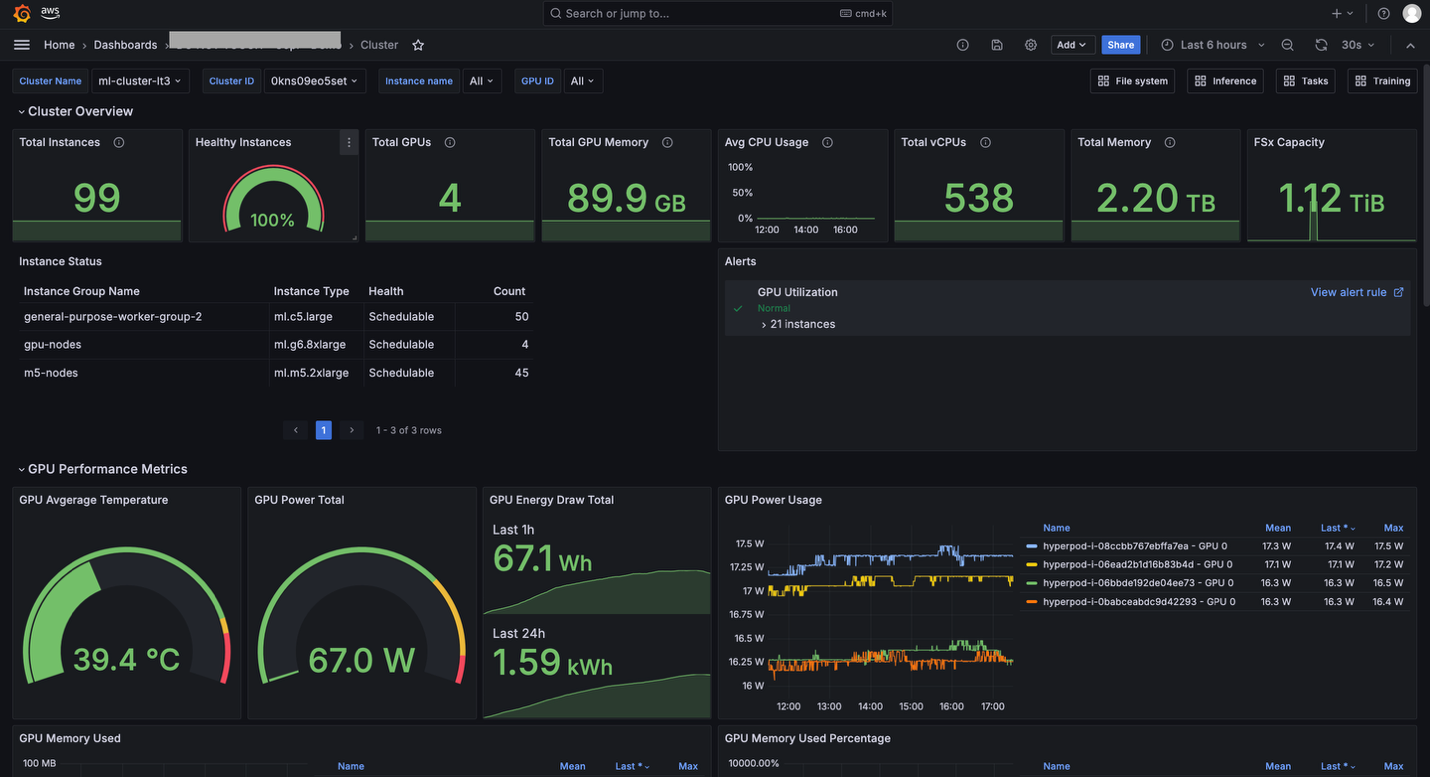
The Tasks dashboard is helpful if you want to see resource allocation and utilization metrics at the task level (PyTorchJob, ReplicaSet, and so on). For example, you can compare GPU utilization by multiple tasks running on your cluster and identify which task should be improved.
You can also choose an aggregation level from multiple options (Namespace, Task Name, Task Pod), and apply filters (Namespace, Task Type, Task Name, Pod, GPU ID). You can use these aggregation and filtering capabilities to view metrics at the appropriate granularity and drill down into the specific issue you are investigating.
The Inference dashboard shows inference application specific metrics such as Incoming Requests, Latency, and Time to First Byte (TTFB). The Inference dashboard is particularly useful when you use SageMaker HyperPod clusters for inference and need to monitor the traffic of the requests and performance of models.
Advanced installation
The Quick installation option will create a new workspace for Prometheus and Grafana and select default metrics. If you want to reuse an existing workspace, select additional metrics, or enable Pod logging to Amazon CloudWatch Logs, use the Custom installation option. For more information, see Amazon SageMaker HyperPod.
Set up alerts
Amazon Managed Grafana includes access to an updated alerting system that centralizes alerting information in a single, searchable view (in the navigation pane, choose Alerts to create an alert). Alerting is useful when you want to receive timely notifications, such as when GPU utilization drops unexpectedly, when a disk usage of your shared file system exceeds 90%, when multiple instances become unavailable at the same time, and so on. The HyperPod observability dashboard in Amazon Managed Grafana has pre-configured alerts for few of these key metrics. You can create additional alert rules based on metrics or queries and set up multiple notification channels, such as emails and Slack messages. For instructions on setting up alerts with Slack messages, see the Setting Up Slack Alerts for Amazon Managed Grafana GitHub page.
The number of alerts is limited to 100 per Grafana workspace. If you need a more scalable solution, check out the alerting options in Amazon Managed Service for Prometheus.
High-level overview
The following diagram illustrates the architecture of the new HyperPod observability capability.

Clean up
If you want to uninstall the SageMaker HyperPod observability feature (for example, to reconfigure it), clean up the resources in the following order:
- Remove the SageMaker HyperPod observability add-on, either using the SageMaker AI console or Amazon EKS console.
- Delete the Grafana workspace on the Amazon Managed Grafana console.
- Delete the Prometheus workspace on the Amazon Managed Service for Prometheus console.
Conclusion
This post provided an overview and usage instructions for SageMaker HyperPod observability, a newly released observability feature for SageMaker HyperPod. This feature reduces the heavy lifting involved in setting up cluster observability and provides centralized visibility into cluster health status and performance metrics.
For more information about SageMaker HyperPod observability, see Amazon SageMaker HyperPod. Please leave your feedback on this post in the comments section.
About the authors
 Tomonori Shimomura is a Principal Solutions Architect on the Amazon SageMaker AI team, where he provides in-depth technical consultation to SageMaker AI customers and suggests product improvements to the product team. Before joining Amazon, he worked on the design and development of embedded software for video game consoles, and now he leverages his in-depth skills in Cloud side technology. In his free time, he enjoys playing video games, reading books, and writing software.
Tomonori Shimomura is a Principal Solutions Architect on the Amazon SageMaker AI team, where he provides in-depth technical consultation to SageMaker AI customers and suggests product improvements to the product team. Before joining Amazon, he worked on the design and development of embedded software for video game consoles, and now he leverages his in-depth skills in Cloud side technology. In his free time, he enjoys playing video games, reading books, and writing software.
 Matt Nightingale is a Solutions Architect Manager on the AWS WWSO Frameworks team focusing on Generative AI Training and Inference. Matt specializes in distributed training architectures with a focus on hardware performance and reliability. Matt holds a bachelors degree from University of Virginia and is based in Boston, Massachusetts.
Matt Nightingale is a Solutions Architect Manager on the AWS WWSO Frameworks team focusing on Generative AI Training and Inference. Matt specializes in distributed training architectures with a focus on hardware performance and reliability. Matt holds a bachelors degree from University of Virginia and is based in Boston, Massachusetts.
 Eric Saleh is a Senior GenAI Specialist at AWS, focusing on foundation model training and inference. He is partnering with top foundation model builders and AWS service teams to enable distributed training and inference at scale on AWS and lead joint GTM motions with strategic customers. Before joining AWS, Eric led product teams building enterprise AI/ML solutions, which included frontier GenAI services for fine-tuning, RAG, and managed inference. He holds a master’s degree in Business Analytics from UCLA Anderson.
Eric Saleh is a Senior GenAI Specialist at AWS, focusing on foundation model training and inference. He is partnering with top foundation model builders and AWS service teams to enable distributed training and inference at scale on AWS and lead joint GTM motions with strategic customers. Before joining AWS, Eric led product teams building enterprise AI/ML solutions, which included frontier GenAI services for fine-tuning, RAG, and managed inference. He holds a master’s degree in Business Analytics from UCLA Anderson.
 Piyush Kadam is a Senior Product Manager on the Amazon SageMaker AI team, where he specializes in LLMOps products that empower both startups and enterprise customers to rapidly experiment with and efficiently govern foundation models. With a Master’s degree in Computer Science from the University of California, Irvine, specializing in distributed systems and artificial intelligence, Piyush brings deep technical expertise to his role in shaping the future of cloud AI products.
Piyush Kadam is a Senior Product Manager on the Amazon SageMaker AI team, where he specializes in LLMOps products that empower both startups and enterprise customers to rapidly experiment with and efficiently govern foundation models. With a Master’s degree in Computer Science from the University of California, Irvine, specializing in distributed systems and artificial intelligence, Piyush brings deep technical expertise to his role in shaping the future of cloud AI products.
 Aman Shanbhag is a Specialist Solutions Architect on the ML Frameworks team at Amazon Web Services (AWS), where he helps customers and partners with deploying ML training and inference solutions at scale. Before joining AWS, Aman graduated from Rice University with degrees in computer science, mathematics, and entrepreneurship.
Aman Shanbhag is a Specialist Solutions Architect on the ML Frameworks team at Amazon Web Services (AWS), where he helps customers and partners with deploying ML training and inference solutions at scale. Before joining AWS, Aman graduated from Rice University with degrees in computer science, mathematics, and entrepreneurship.
 Bhaskar Pratap is a Senior Software Engineer with the Amazon SageMaker AI team. He is passionate about designing and building elegant systems that bring machine learning to people’s fingertips. Additionally, he has extensive experience with building scalable cloud storage services.
Bhaskar Pratap is a Senior Software Engineer with the Amazon SageMaker AI team. He is passionate about designing and building elegant systems that bring machine learning to people’s fingertips. Additionally, he has extensive experience with building scalable cloud storage services.
 Gopi Sekar is an Engineering Leader for the Amazon SageMaker AI team. He is dedicated to assisting customers and developing products that simplify the adaptation of machine learning to address real-world customer challenges.
Gopi Sekar is an Engineering Leader for the Amazon SageMaker AI team. He is dedicated to assisting customers and developing products that simplify the adaptation of machine learning to address real-world customer challenges.
Books, Courses & Certifications
Streamline access to ISO-rating content changes with Verisk rating insights and Amazon Bedrock

This post is co-written with Samit Verma, Eusha Rizvi, Manmeet Singh, Troy Smith, and Corey Finley from Verisk.
Verisk Rating Insights as a feature of ISO Electronic Rating Content (ERC) is a powerful tool designed to provide summaries of ISO Rating changes between two releases. Traditionally, extracting specific filing information or identifying differences across multiple releases required manual downloads of full packages, which was time-consuming and prone to inefficiencies. This challenge, coupled with the need for accurate and timely customer support, prompted Verisk to explore innovative ways to enhance user accessibility and automate repetitive processes. Using generative AI and Amazon Web Services (AWS) services, Verisk has made significant strides in creating a conversational user interface for users to easily retrieve specific information, identify content differences, and improve overall operational efficiency.
In this post, we dive into how Verisk Rating Insights, powered by Amazon Bedrock, large language models (LLM), and Retrieval Augmented Generation (RAG), is transforming the way customers interact with and access ISO ERC changes.
The challenge
Rating Insights provides valuable content, but there were significant challenges with user accessibility and the time it took to extract actionable insights:
- Manual downloading – Customers had to download entire packages to get even a small piece of relevant information. This was inefficient, especially when only a part of the filing needed to be reviewed.
- Inefficient data retrieval – Users couldn’t quickly identify the differences between two content packages without downloading and manually comparing them, which could take hours and sometimes days of analysis.
- Time-consuming customer support – Verisk’s ERC Customer Support team spent 15% of their time weekly addressing queries from customers who were impacted by these inefficiencies. Furthermore, onboarding new customers required half a day of repetitive training to ensure they understood how to access and interpret the data.
- Manual analysis time – Customers often spent 3–4 hours per test case analyzing the differences between filings. With multiple test cases to address, this led to significant delays in critical decision-making.
Solution overview
To solve these challenges, Verisk embarked on a journey to enhance Rating Insights with generative AI technologies. By integrating Anthropic’s Claude, available in Amazon Bedrock, and Amazon OpenSearch Service, Verisk created a sophisticated conversational platform where users can effortlessly access and analyze rating content changes.
The following diagram illustrates the high-level architecture of the solution, with distinct sections showing the data ingestion process and inference loop. The architecture uses multiple AWS services to add generative AI capabilities to the Ratings Insight system. This system’s components work together seamlessly, coordinating multiple LLM calls to generate user responses.
The following diagram shows the architectural components and the high-level steps involved in the Data Ingestion process.
 |
The steps in the data ingestion process proceed as follows:
- This process is triggered when a new file is dropped. It is responsible for chunking the document using a custom chunking strategy. This strategy recursively checks each section and keeps them intact without overlap. The process then embeds the chunks and stores them in OpenSearch Service as vector embeddings.
- The embedding model used in Amazon Bedrock is amazon titan-embed-g1-text-02.
- Amazon OpenSearch Serverless is utilized as a vector embedding store with metadata filtering capability.
The following diagram shows the architectural components and the high-level steps involved in the inference loop to generate user responses.

The steps in the inference loop proceed as follows:
- This component is responsible for multiple tasks: it supplements user questions with recent chat history, embeds the questions, retrieves relevant chunks from the vector database, and finally calls the generation model to synthesize a response.
- Amazon ElastiCache is used for storing recent chat history.
- The embedding model utilized in Amazon Bedrock is amazon titan-embed-g1-text-02.
- OpenSearch Serverless is implemented for RAG (Retrieval-Augmented Generation).
- For generating responses to user queries, the system uses Anthropic’s Claude Sonnet 3.5 (model ID: anthropic.claude-3-5-sonnet-20240620-v1:0), which is available through Amazon Bedrock.
Key technologies and frameworks used
We used Anthropic’s Claude Sonnet 3.5 (model ID: anthropic.claude-3-5-sonnet-20240620-v1:0) to understand user input and provide detailed, contextually relevant responses. Anthropic’s Claude Sonnet 3.5 enhances the platform’s ability to interpret user queries and deliver accurate insights from complex content changes. LlamaIndex, which is an open source framework, served as the chain framework for efficiently connecting and managing different data sources to enable dynamic retrieval of content and insights.
We implemented RAG, which allows the model to pull specific, relevant data from the OpenSearch Serverless vector database. This means the system generates precise, up-to-date responses based on a user’s query without needing to sift through massive content downloads. The vector database enables intelligent search and retrieval, organizing content changes in a way that makes them quickly and easily accessible. This eliminates the need for manual searching or downloading of entire content packages. Verisk applied guardrails in Amazon Bedrock Guardrails along with custom guardrails around the generative model so the output adheres to specific compliance and quality standards, safeguarding the integrity of responses.
Verisk’s generative AI solution is a comprehensive, secure, and flexible service for building generative AI applications and agents. Amazon Bedrock connects you to leading FMs, services to deploy and operate agents, and tools for fine-tuning, safeguarding, and optimizing models along with knowledge bases to connect applications to your latest data so that you have everything you need to quickly move from experimentation to real-world deployment.
Given the novelty of generative AI, Verisk has established a governance council to oversee its solutions, ensuring they meet security, compliance, and data usage standards. Verisk implemented strict controls within the RAG pipeline to ensure data is only accessible to authorized users. This helps maintain the integrity and privacy of sensitive information. Legal reviews ensure IP protection and contract compliance.
How it works
The integration of these advanced technologies enables a seamless, user-friendly experience. Here’s how Verisk Rating Insights now works for customers:
- Conversational user interface – Users can interact with the platform by using a conversational interface. Instead of manually reviewing content packages, users enter a natural language query (for example, “What are the changes in coverage scope between the two recent filings?”). The system uses Anthropic’s Claude Sonnet 3.5 to understand the intent and provides an instant summary of the relevant changes.
- Dynamic content retrieval – Thanks to RAG and OpenSearch Service, the platform doesn’t require downloading entire files. Instead, it dynamically retrieves and presents the specific changes a user is seeking, enabling quicker analysis and decision-making.
- Automated difference analysis – The system can automatically compare two content packages, highlighting the differences without requiring manual intervention. Users can query for precise comparisons (for example, “Show me the differences in rating criteria between Release 1 and Release 2”).
- Customized insights – The guardrails in place mean that responses are accurate, compliant, and actionable. Additionally, if needed, the system can help users understand the impact of changes and assist them in navigating the complexities of filings, providing clear, concise insights.
The following diagram shows the architectural components and the high-level steps involved in the evaluation loop to generate relevant and grounded responses.

The steps in the evaluation loop proceed as follows:
- This component is responsible for calling Anthropic’s Claude Sonnet 3.5 model and subsequently invoking the custom-built evaluation APIs to ensure response accuracy.
- The generation model employed is Anthropic’s Claude Sonnet 3.5, which handles the creation of responses.
- The Evaluation API ensures that responses remain relevant to user queries and stay grounded within the provided context.
The following diagram shows the process of capturing the chat history as contextual memory and storage for analysis.

Quality benchmarks
The Verisk Rating Insights team has implemented a comprehensive evaluation framework and feedback loop mechanism respectively, shown in the above figures, to support continuous improvement and address the issues that might arise.
Ensuring high accuracy and consistency in responses is essential for Verisk’s generative AI solutions. However, LLMs can sometimes produce hallucinations or provide irrelevant details, affecting reliability. To address this, Verisk implemented:
- Evaluation framework – Integrated into the query pipeline, it validates responses for precision and relevance before delivery.
- Extensive testing – Product subject matter experts (SMEs) and quality experts rigorously tested the solution to ensure accuracy and reliability. Verisk collaborated with in-house insurance domain experts to develop SME evaluation metrics for accuracy and consistency. Multiple rounds of SME evaluations were conducted, where experts graded these metrics on a 1–10 scale. Latency was also tracked to assess speed. Feedback from each round was incorporated into subsequent tests to drive improvements.
- Continual model improvement – Using customer feedback serves as a crucial component in driving the continuous evolution and refinement of the generative models, improving both accuracy and relevance. By seamlessly integrating user interactions and feedback with chat history, a robust data pipeline is created that streams the user interactions to an Amazon Simple Storage Service (Amazon S3) bucket, which acts as a data hub. The interactions then go into Snowflake, which is a cloud-based data platform and data warehouse as a service that offers capabilities such as data warehousing, data lakes, data sharing, and data exchange. Through this integration, we built comprehensive analytics dashboards that provide valuable insights into user experience patterns and pain points.
Although the initial results were promising, they didn’t meet the desired accuracy and consistency levels. The development process involved several iterative improvements, such as redesigning the system and making multiple calls to the LLM. The primary metric for success was a manual grading system where business experts compared the results and provided continuous feedback to improve overall benchmarks.
Business impact and opportunity
By integrating generative AI into Verisk Rating Insights, the business has seen a remarkable transformation. Customers enjoyed significant time savings. By eliminating the need to download entire packages and manually search for differences, the time spent on analysis has been drastically reduced. Customers no longer spend 3–4 hours per test case. What at one time took days now takes minutes.
This time savings brought increased productivity. With an automated solution that instantly provides relevant insights, customers can focus more on decision-making rather than spending time on manual data retrieval. And by automating difference analysis and providing a centralized, effortless platform, customers can be more confident in the accuracy of their results and avoid missing critical changes.
For Verisk, the benefit was a reduced customer support burden because the ERC customer support team now spends less time addressing queries. With the AI-powered conversational interface, users can self-serve and get answers in real time, freeing up support resources for more complex inquiries.
The automation of repetitive training tasks meant quicker and more efficient customer onboarding. This reduces the need for lengthy training sessions, and new customers become proficient faster. The integration of generative AI has reduced redundant workflows and the need for manual intervention. This streamlines operations across multiple departments, leading to a more agile and responsive business.
Conclusion
Looking ahead, Verisk plans to continue enhancing the Rating Insights platform twofold. First, we’ll expand the scope of queries, enabling more sophisticated queries related to different filing types and more nuanced coverage areas. Second, we’ll scale the platform. With Amazon Bedrock providing the infrastructure, Verisk aims to scale this solution further to support more users and additional content sets across various product lines.
Verisk Rating Insights, now powered by generative AI and AWS technologies, has transformed the way customers interact with and access rating content changes. Through a conversational user interface, RAG, and vector databases, Verisk intends to eliminate inefficiencies and save customers valuable time and resources while enhancing overall accessibility. For Verisk, this solution has improved operational efficiency and provided a strong foundation for continued innovation.
With Amazon Bedrock and a focus on automation, Verisk is driving the future of intelligent customer support and content management, empowering both their customers and their internal teams to make smarter, faster decisions.
For more information, refer to the following resources:
About the authors
 Samit Verma serves as the Director of Software Engineering at Verisk, overseeing the Rating and Coverage development teams. In this role, he plays a key part in architectural design and provides strategic direction to multiple development teams, enhancing efficiency and ensuring long-term solution maintainability. He holds a master’s degree in information technology.
Samit Verma serves as the Director of Software Engineering at Verisk, overseeing the Rating and Coverage development teams. In this role, he plays a key part in architectural design and provides strategic direction to multiple development teams, enhancing efficiency and ensuring long-term solution maintainability. He holds a master’s degree in information technology.
 Eusha Rizvi serves as a Software Development Manager at Verisk, leading several technology teams within the Ratings Products division. Possessing strong expertise in system design, architecture, and engineering, Eusha offers essential guidance that advances the development of innovative solutions. He holds a bachelor’s degree in information systems from Stony Brook University.
Eusha Rizvi serves as a Software Development Manager at Verisk, leading several technology teams within the Ratings Products division. Possessing strong expertise in system design, architecture, and engineering, Eusha offers essential guidance that advances the development of innovative solutions. He holds a bachelor’s degree in information systems from Stony Brook University.
 Manmeet Singh is a Software Engineering Lead at Verisk and AWS Certified Generative AI Specialist. He leads the development of an agentic RAG-based generative AI system on Amazon Bedrock, with expertise in LLM orchestration, prompt engineering, vector databases, microservices, and high-availability architecture. Manmeet is passionate about applying advanced AI and cloud technologies to deliver resilient, scalable, and business-critical systems.
Manmeet Singh is a Software Engineering Lead at Verisk and AWS Certified Generative AI Specialist. He leads the development of an agentic RAG-based generative AI system on Amazon Bedrock, with expertise in LLM orchestration, prompt engineering, vector databases, microservices, and high-availability architecture. Manmeet is passionate about applying advanced AI and cloud technologies to deliver resilient, scalable, and business-critical systems.
 Troy Smith is a Vice President of Rating Solutions at Verisk. Troy is a seasoned insurance technology leader with more than 25 years of experience in rating, pricing, and product strategy. At Verisk, he leads the team behind ISO Electronic Rating Content, a widely used resource across the insurance industry. Troy has held leadership roles at Earnix and Capgemini and was the cofounder and original creator of the Oracle Insbridge Rating Engine.
Troy Smith is a Vice President of Rating Solutions at Verisk. Troy is a seasoned insurance technology leader with more than 25 years of experience in rating, pricing, and product strategy. At Verisk, he leads the team behind ISO Electronic Rating Content, a widely used resource across the insurance industry. Troy has held leadership roles at Earnix and Capgemini and was the cofounder and original creator of the Oracle Insbridge Rating Engine.
 Corey Finley is a Product Manager at Verisk. Corey has over 22 years of experience across personal and commercial lines of insurance. He has worked in both implementation and product support roles and has led efforts for major carriers including Allianz, CNA, Citizens, and others. At Verisk, he serves as Product Manager for VRI, RaaS, and ERC.
Corey Finley is a Product Manager at Verisk. Corey has over 22 years of experience across personal and commercial lines of insurance. He has worked in both implementation and product support roles and has led efforts for major carriers including Allianz, CNA, Citizens, and others. At Verisk, he serves as Product Manager for VRI, RaaS, and ERC.
 Arun Pradeep Selvaraj is a Senior Solutions Architect at Amazon Web Services (AWS). Arun is passionate about working with his customers and stakeholders on digital transformations and innovation in the cloud while continuing to learn, build, and reinvent. He is creative, energetic, deeply customer-obsessed, and uses the working backward process to build modern architectures to help customers solve their unique challenges. Connect with him on LinkedIn.
Arun Pradeep Selvaraj is a Senior Solutions Architect at Amazon Web Services (AWS). Arun is passionate about working with his customers and stakeholders on digital transformations and innovation in the cloud while continuing to learn, build, and reinvent. He is creative, energetic, deeply customer-obsessed, and uses the working backward process to build modern architectures to help customers solve their unique challenges. Connect with him on LinkedIn.
 Ryan Doty is a Solutions Architect Manager at Amazon Web Services (AWS), based out of New York. He helps financial services customers accelerate their adoption of the AWS Cloud by providing architectural guidelines to design innovative and scalable solutions. Coming from a software development and sales engineering background, the possibilities that the cloud can bring to the world excite him.
Ryan Doty is a Solutions Architect Manager at Amazon Web Services (AWS), based out of New York. He helps financial services customers accelerate their adoption of the AWS Cloud by providing architectural guidelines to design innovative and scalable solutions. Coming from a software development and sales engineering background, the possibilities that the cloud can bring to the world excite him.
Books, Courses & Certifications
Unified multimodal access layer for Quora’s Poe using Amazon Bedrock

Organizations gain competitive advantage by deploying and integrating new generative AI models quickly through Generative AI Gateway architectures. This unified interface approach simplifies access to multiple foundation models (FMs), addressing a critical challenge: the proliferation of specialized AI models, each with unique capabilities, API specifications, and operational requirements. Rather than building and maintaining separate integration points for each model, the smart move is to build an abstraction layer that normalizes these differences behind a single, consistent API.
The AWS Generative AI Innovation Center and Quora recently collaborated on an innovative solution to address this challenge. Together, they developed a unified wrapper API framework that streamlines the deployment of Amazon Bedrock FMs on Quora’s Poe system. This architecture delivers a “build once, deploy multiple models” capability that significantly reduces deployment time and engineering effort, with real protocol bridging code visible throughout the codebase.
For technology leaders and developers working on AI multi-model deployment at scale, this framework demonstrates how thoughtful abstraction and protocol translation can accelerate innovation cycles while maintaining operational control.
In this post, we explore how the AWS Generative AI Innovation Center and Quora collaborated to build a unified wrapper API framework that dramatically accelerates the deployment of Amazon Bedrock FMs on Quora’s Poe system. We detail the technical architecture that bridges Poe’s event-driven ServerSentEvents protocol with Amazon Bedrock REST-based APIs, demonstrate how a template-based configuration system reduced deployment time from days to 15 minutes, and share implementation patterns for protocol translation, error handling, and multi-modal capabilities. We show how this “build once, deploy multiple models” approach helped Poe integrate over 30 Amazon Bedrock models across text, image, and video modalities while reducing code changes by up to 95%.
Quora and Amazon Bedrock
Poe.com is an AI system developed by Quora that users and developers can use to interact with a wide range of advanced AI models and assistants powered by multiple providers. The system offers multi-model access, enabling side-by-side conversations with various AI chatbots for tasks such as natural language understanding, content generation, image creation, and more.
This screenshot below showcases the user interface of Poe, the AI platform created by Quora. The image displays Poe’s extensive library of AI models, which are presented as individual “chatbots” that users can interact with.
The following screenshot provides a view of the Model Catalog within Amazon Bedrock, a fully managed service from Amazon Web Services (AWS) that offers access to a diverse range of foundation models (FMs). This catalog acts as a central hub for developers to discover, evaluate, and access state-of-the-art AI from various providers.

Initially, integrating the diverse FMs available through Amazon Bedrock presented significant technical challenges for the Poe.com team. The process required substantial engineering resources to establish connections with each model while maintaining consistent performance and reliability standards. Maintainability emerged as an extremely important consideration, as was the ability to efficiently onboard new models as they became available—both factors adding further complexity to the integration challenges.
Technical challenge: Bridging different systems
The integration between Poe and Amazon Bedrock presented fundamental architectural challenges that required innovative solutions. These systems were built with different design philosophies and communication patterns, creating a significant technical divide that the wrapper API needed to bridge.
Architectural divide
The core challenge stems from the fundamentally different architectural approaches of the two systems. Understanding these differences is essential to appreciating the complexity of the integration solution. Poe operates on a modern, reactive, ServerSentEvents-based architecture through the Fast API library (fastapi_poe). This architecture is stream-optimized for real-time interactions and uses an event-driven response model designed for continuous, conversational AI. Amazon Bedrock, on the other hand, functions as an enterprise cloud service. It offers REST-based with AWS SDK access patterns, SigV4 authentication requirements, AWS Region-specific model availability, and a traditional request-response pattern with streaming options. This fundamental API mismatch creates several technical challenges that the Poe wrapper API solves, as detailed in the following table.
| Challenge Category | Technical Issue | Source Protocol | Target Protocol | Integration Complexity |
|---|---|---|---|---|
| Protocol Translation | Converting between WebSocket-based protocol and REST APIs | WebSocket (bidirectional, persistent) | REST (request/response, stateless) | High: Requires protocol bridging |
| Authentication Bridging | Connecting JWT validation with AWS SigV4 signing | JWT token validation | AWS SigV4 authentication | Medium: Credential transformation needed |
| Response Format Transformation | Adapting JSON responses into expected format | Standard JSON structure | Custom format requirements | Medium: Data structure mapping |
| Streaming Reconciliation | Mapping chunked responses to ServerSentEvents | Chunked HTTP responses | ServerSentEvents stream | High: Real-time data flow conversion |
| Parameter Standardization | Creating unified parameter space across models | Model-specific parameters | Standardized parameter interface | Medium: Parameter normalization |
API evolution and the Converse API
In May 2024, Amazon Bedrock introduced the Converse API, which offered standardization benefits that significantly simplified the integration architecture:
- Unified interface across diverse model providers (such as Anthropic, Meta, and Mistral)
- Conversation memory with consistent handling of chat history
- Streaming and non-streaming modes through a single API pattern
- Multimodal support for text, images, and structured data
- Parameter normalization that reduces model-specific implementation quirks
- Built-in content moderation capabilities
The solution presented in this post uses the Converse API where appropriate, while also maintaining compatibility with model-specific APIs for specialized capabilities. This hybrid approach provides flexibility while taking advantage of the Converse API’s standardization benefits.
Solution overview
The wrapper API framework provides a unified interface between Poe and Amazon Bedrock models. It serves as a translation layer that normalizes the differences between models and protocols while maintaining the unique capabilities of each model.
The solution architecture follows a modular design that separates concerns and enables flexible scaling, as illustrated in the following diagram.

The wrapper API consists of several key components working together to provide a seamless integration experience:
- Client – The entry point where users interact with AI capabilities through various interfaces.
- Poe layer – Consists of the following:
- Poe UI – Handles user experience, request formation, parameters controls, file uploads, and response visualization.
- Poe FastAPI – Standardizes user interactions and manages the communication protocol between clients and underlying systems.
- Bot Factory – Dynamically creates appropriate model handlers (bots) based on the requested model type (chat, image, or video). This factory pattern provides extensibility for new model types and variations. See the following code:
- Service manager: Orchestrates the services needed to process requests effectively. It coordinates between different specialized services, including:
- Token services – Managing token limits and counting.
- Streaming services – Handling real-time responses.
- Error services – Normalizing and handling errors.
- AWS service integration – Managing API calls to Amazon Bedrock.
- AWS services component – Converts responses from Amazon Bedrock format to Poe’s expected format and vice-versa, handling streaming chunks, image data, and video outputs.
- Amazon Bedrock layer – Amazon’s FM service that provides the actual AI processing capabilities and model hosting, including:
- Model diversity – Provides access to over 30 text models (such as Amazon Titan, Amazon Nova, Anthropic’s Claude, Meta’s Llama, Mistral, and more), image models, and video models.
- API structure – Exposes both model-specific APIs and the unified Converse API.
- Authentication – Requires AWS SigV4 signing for secure access to model endpoints.
- Response management – Returns model outputs with standardized metadata and usage statistics.
The request processing flow in this unified wrapper API shows the orchestration required when bridging Poe’s event-driven ServerSentEvents protocol with Amazon Bedrock REST-based APIs, showcasing how multiple specialized services work together to deliver a seamless user experience.
The flow begins when a client sends a request through Poe’s interface, which then forwards it to the Bot Factory component. This factory pattern dynamically creates the appropriate model handler based on the requested model type, whether for chat, image, or video generation. The service manager component then orchestrates the various specialized services needed to process the request effectively, including token services, streaming services, and error handling services.
The following sequence diagram illustrates the complete request processing flow.

Configuration template for rapid multi-bot deployment
The most powerful aspect of the wrapper API is its unified configuration template system, which supports rapid deployment and management of multiple bots with minimal code changes. This approach is central to the solution’s success in reducing deployment time.
The system uses a template-based configuration approach with shared defaults and model-specific overrides:
This configuration-driven architecture offers several significant advantages:
- Rapid deployment – Adding new models requires only creating a new configuration entry rather than writing integration code. This is a key factor in the significant improvement in deployment time.
- Consistent parameter management – Common parameters are defined one time in DEFAULT_CHAT_CONFIG and inherited by bots, maintaining consistency and reducing duplication.
- Model-specific customization – Each model can have its own unique settings while still benefiting from the shared infrastructure.
- Operational flexibility – Parameters can be adjusted without code changes, allowing for quick experimentation and optimization.
- Centralized credential management – AWS credentials are managed in one place, improving security and simplifying updates.
- Region-specific deployment – Models can be deployed to different Regions as needed, with Region settings controlled at the configuration level.
The BotConfig class provides a structured way to define bot configurations with type validation:
Advanced multimodal capabilities
One of the most powerful aspects of the framework is how it handles multimodal capabilities through simple configuration flags:
- enable_image_comprehension – When set to True for text-only models like Amazon Nova Micro, Poe itself uses vision capabilities to analyze images and convert them into text descriptions that are sent to the Amazon Bedrock model. This enables even text-only models to classify images without having built-in vision capabilities.
- expand_text_attachments – When set to True, Poe parses uploaded text files and includes their content in the conversation, enabling models to work with document content without requiring special file handling capabilities.
- supports_system_messages – This parameter controls whether the model can accept system prompts, allowing for consistent behavior across models with different capabilities.
These configuration flags create a powerful abstraction layer that offers the following benefits:
- Extends model capabilities – Text-only models gain pseudo-multimodal capabilities through Poe’s preprocessing
- Optimizes built-in features – True multimodal models can use their built-in capabilities for optimal results
- Simplifies integration – It’s controlled through simple configuration switches rather than code changes
- Maintains consistency – It provides a uniform user experience regardless of the underlying model’s native capabilities
Next, we explore the technical implementation of the solution in more detail.
Protocol translation layer
The most technically challenging aspect of the solution was bridging between Poe’s API protocols and the diverse model interfaces available through Amazon Bedrock. The team accomplished this through a sophisticated protocol translation layer:
This translation layer handles subtle differences between models and makes sure that regardless of which Amazon Bedrock model is being used, the response to Poe is consistent and follows Poe’s expected format.
Error handling and normalization
A critical aspect of the implementation is comprehensive error handling and normalization. The ErrorService provides consistent error handling across different models:
This approach makes sure users receive meaningful error messages regardless of the underlying model or error condition.
Token counting and optimization
The system implements sophisticated token counting and optimization to maximize effective use of models:
This detailed token tracking enables accurate cost estimation and optimization, facilitating efficient use of model resources.
AWS authentication and security
The AwsClientService handles authentication and security for Amazon Bedrock API calls.This implementation provides secure authentication with AWS services while providing proper error handling and connection management.
Comparative analysis
The implementation of the wrapper API dramatically improved the efficiency and capabilities of deploying Amazon Bedrock models on Poe, as detailed in the following table.
| Feature | Before (Direct API) | After (Wrapper API) |
|---|---|---|
| Deployment Time | Days per model | Minutes per model |
| Developer Focus | Configuration and plumbing | Innovation and features |
| Model Diversity | Limited by integration capacity | Extensive (across Amazon Bedrock models) |
| Maintenance Overhead | High (separate code for each model) | Low (configuration-based) |
| Error Handling | Custom per model | Standardized across models |
| Cost Tracking | Complex (multiple integrations) | Simplified (centralized) |
| Multimodal Support | Fragmented | Unified |
| Security | Varied implementations | Consistent best practices |
This comparison highlights the significant improvements achieved through the wrapper API approach, demonstrating the value of investing in a robust abstraction layer.
Performance metrics and business impact
The wrapper API framework delivered significant and measurable business impact across multiple dimensions, including increased model diversity, deployment efficiency, and developer productivity.
Poe can rapidly expand its model offerings, integrating tens of Amazon Bedrock models across text, image, and video modalities. This expansion occurred over a period of weeks rather than the months it would have taken with the previous approach.
The following table summarizes the deployment efficiency metrics.
| Metric | Before | After | Improvement |
|---|---|---|---|
| New Model Deployment | 2 –3 days | 15 minutes | 96x faster |
| Code Changes Required | 500+ lines | 20–30 lines | 95% reduction |
| Testing Time | 8–12 hours | 30–60 minutes | 87% reduction |
| Deployment Steps | 10–15 steps | 3–5 steps | 75% reduction |
These metrics were measured through direct comparison of engineering hours required before and after implementation, tracking actual deployments of new models.
The engineering team saw a dramatic shift in focus from integration work to feature development, as detailed in the following table.
| Activity | Before (% of time) | After (% of time) | Change |
|---|---|---|---|
| API Integration | 65% | 15% | -50% |
| Feature Development | 20% | 60% | +40% |
| Testing | 10% | 15% | +5% |
| Documentation | 5% | 10% | +5% |
Scaling and performance considerations
The wrapper API is designed to handle high-volume production workloads with robust scaling capabilities.
Connection pooling
To handle multiple concurrent requests efficiently, the wrapper implements connection pooling using aiobotocore. This allows it to maintain a pool of connections to Amazon Bedrock, reducing the overhead of establishing new connections for each request:
Asynchronous processing
The entire framework uses asynchronous processing to handle concurrent requests efficiently:
Error recovery and retry logic
The system implements sophisticated error recovery and retry logic to handle transient issues:
Performance metrics
The system collects detailed performance metrics to help identify bottlenecks and optimize performance:
Security considerations
Security is a critical aspect of the wrapper implementation, with several key features to support secure operation.
JWT validation with AWS SigV4 signing
The system integrates JWT validation for Poe’s authentication with AWS SigV4 signing for Amazon Bedrock API calls:
- JWT validation – Makes sure only authorized Poe requests can access the wrapper API
- SigV4 signing – Makes sure the wrapper API can securely authenticate with Amazon Bedrock
- Credential management – AWS credentials are securely managed and not exposed to clients
Secrets management
The system integrates with AWS Secrets Manager to securely store and retrieve sensitive credentials:
Secure connection management
The system implements secure connection management to help prevent credential leakage and facilitate proper cleanup:
Troubleshooting and debugging
The wrapper API includes comprehensive logging and debugging capabilities to help identify and resolve issues. The system implements detailed logging throughout the request processing flow. Each request is assigned a unique ID that is used throughout the processing flow to enable tracing:
Lessons learned and best practices
Through this collaboration, several important technical insights emerged that might benefit others undertaking similar projects:
- Configuration-driven architecture – Using configuration files rather than code for model-specific behaviors proved enormously beneficial for maintenance and extensibility. This approach allowed new models to be added without code changes, significantly reducing the risk of introducing bugs.
- Protocol translation challenges – The most complex aspect was handling the subtle differences in streaming protocols between different models. Building a robust abstraction required careful consideration of edge cases and comprehensive error handling.
- Error normalization – Creating a consistent error experience across diverse models required sophisticated error handling that could translate model-specific errors into user-friendly, actionable messages. This improved both developer and end-user experiences.
- Type safety – Strong typing (using Python’s type hints extensively) was crucial for maintaining code quality across a complex codebase with multiple contributors. This practice reduced bugs and improved code maintainability.
- Security first – Integrating Secrets Manager from the start made sure credentials were handled securely throughout the system’s lifecycle, helping prevent potential security vulnerabilities.
Conclusion
The collaboration between the AWS Generative AI Innovation Center and Quora demonstrates how thoughtful architectural design can dramatically accelerate AI deployment and innovation. By creating a unified wrapper API for Amazon Bedrock models, the teams were able to reduce deployment time from days to minutes while expanding model diversity and improving user experience.
This approach—focusing on abstraction, configuration-driven development, and robust error handling—offers valuable lessons for organizations looking to integrate multiple AI models efficiently. The patterns and techniques demonstrated in this solution can be applied to similar challenges across a wide range of AI integration scenarios.
For technology leaders and developers working on similar challenges, this case study highlights the value of investing in flexible integration frameworks rather than point-to-point integrations. The initial investment in building a robust abstraction layer pays dividends in long-term maintenance and capability expansion.
To learn more about implementing similar solutions, explore the following resources:
The AWS Generative AI Innovation Center and Quora teams continue to collaborate on enhancements to this framework, making sure Poe users have access to the latest and most capable AI models with minimal deployment delay.
About the authors
 Dr. Gilbert V Lepadatu is a Senior Deep Learning Architect at the AWS Generative AI Innovation Center, where he helps enterprise customers design and deploy scalable, cutting-edge GenAI solutions. With a PhD in Philosophy and dual Master’s degrees, he brings a holistic and interdisciplinary approach to data science and AI.
Dr. Gilbert V Lepadatu is a Senior Deep Learning Architect at the AWS Generative AI Innovation Center, where he helps enterprise customers design and deploy scalable, cutting-edge GenAI solutions. With a PhD in Philosophy and dual Master’s degrees, he brings a holistic and interdisciplinary approach to data science and AI.
 Nick Huber is the AI Ecosystem Lead for Poe (by Quora), where he is responsible for ensuring high-quality & timely integrations of the leading AI models onto the Poe platform.
Nick Huber is the AI Ecosystem Lead for Poe (by Quora), where he is responsible for ensuring high-quality & timely integrations of the leading AI models onto the Poe platform.

As Molly Hamill explains the origin of the Declaration of Independence to her students, she dons a white wig fashioned into a ponytail, appearing as John Adams, before sporting a bald cap in homage to Benjamin Franklin, then wearing a red wig to imitate Thomas Jefferson. But instead of looking out to an enraptured sea of 28 fifth graders leaning forward in their desks, she is speaking directly into a camera.
Hamill is one of a growing number of educators who forwent brick-and-mortar schools post-pandemic. She now teaches fully virtually through the public, online school California Virtual Academies, having swapped desks for desktops.
After the abrupt shift to virtual schooling during the COVID-19 health crisis — and the stress for many educators because of it — voluntarily choosing the format may seem unthinkable.
“You hear people say, ‘I would never want to go back to virtual,’ and I get it, it was super stressful because we were building the plane as we were flying it, deciding if we were going to have live video or recordings, and adapt all the teaching materials to virtual,” Hamill says. “But my school is a pretty well-oiled machine … there’s a structure already in place. And kids are adaptable, they already like being on a computer.”
And for Hamill, and thousands of other teachers, instructing through a virtual school is a way to attempt striking a rare work-life balance in the education world.
More Flexibility for Teaching Students
The number of virtual schools has grown, as has the number of U.S. children enrolled in them. In the 2022-2023 school year, about 2.5 percent of K-12 students were enrolled in full-time virtual education (1.8 percent of them through public or private online schools, and 0.7 percent as homeschoolers), according to data published in 2024 by the National Center for Education Statistics. And parents reported that 7 percent of students who learned at home that year took at least one virtual course.
There’s been an accompanying rise in the number of teachers instructing remotely via virtual schools.
The number of teachers employed by K12, which is under the parent company Stride Inc. and one of the largest and longest-running providers of virtual schools, has jumped from 6,500 to 8,000 over the last three or four years, says Niyoka McCoy, chief learning officer at the company.
McCoy credits the growth in part to teachers wanting to homeschool their own children, and therefore needing to do their own work from home, but she also thinks it is a sign of a shifting preference for technology-based offerings.
“They think this is the future, that more online programs will open up,” McCoy says.
Connections Academy, which is the parent company of Pearson Online Academy and a similarly long-standing online learning provider, employs 3,500 teachers. Nik Osborne, senior vice president of partnerships and customer success at Pearson, says it’s been easy to both recruit and keep teachers: roughly 91 percent of teachers in the 2024-2025 school year returned this academic year.
“Teaching in a virtual space is very different than brick-and-mortar; even the type of role teachers play appeals to some teachers,” Osborne says. “They become more of a guide to help the kids understand content.”
Courtney Entsminger, a middle school math teacher at the public, online school Virginia Connections Academy, teaches asynchronously and likes the ability to record her own lesson plans in addition to teaching them live, which she says helps a wider variety of learners. Hamill, who teaches synchronously, similarly likes that the virtual format can be leveraged to build more creative lesson plans, like her Declaration of Independence video, or a fake livestream of George Washington during the Battle of Trenton, both which are on her YouTube channel.
Whether a school is asynchronous or not largely depends on the standard of the provider. Pearson, which runs the Virtual Academies where Entsminger teaches, is asynchronous. For other standalone public school districts, such as Georgia Cyber Academy, the decision comes down to what students need: if they are performing at or above grade level, they get more flexibility, but if they come to the school below grade level — reading at a second grade level, for example, but placed in a fourth grade classroom — they need more structure.
“I do feel like a TikTok star where I record myself teaching through different aspects of that curriculum because students work in different ways,” says Entsminger, who has 348 online students across three grades. “In person you’re able to realize ‘this student works this way,’ and I’ll do a song and dance in front of you. Online, I can do it in different mediums.”
Karen Bacon, a transition liaison at Ohio Virtual Academy who works with middle and high school students in special education, was initially drawn to virtual teaching because of its flexibility for supporting students through a path that works best for them.
“I always like a good challenge and thought this was interesting to dive into how this works and different ways to help students,” says Bacon, who was a high school French teacher before making the switch to virtual in 2017. “There’s obviously a lot to learn and understand, but once you dive in and see all the options, there really are a lot of different possibilities out there.”
Bacon says there are “definitely less distractions,” than in a brick-and-mortar environment, allowing her to get more creative. For example, she had noticed stories crop up across the nation showcasing special education students in physical environments working to serve coffee to teachers and students as a way to learn workplace skills. She, adapting to the virtual environment, created the “Cardinal Cafe,” where students can accomplish the same goals, albeit with a virtual cup of joe.
“I don’t really consider myself super tech-y, but I have that curiosity and love going outside the box and looking at ways to really help my students,” she says.
A Way to Curb Teacher Burnout?
The flexibility that comes with teaching in a virtual environment is not just appealing for what it offers students. Teachers say it can also help cushion the consistently lower wages and lack of benefits most educators grapple with, conditions that drive many to leave the field.
“So many of us have said, ‘I felt so burned out, I wasn’t sure I could keep teaching,’” Hamill says, adding she felt similarly at the start of her career as a first grade teacher. “But doing it this way helps it feel sustainable. We’re still underpaid and not appreciated enough as a whole profession, but at least virtually some of the big glaring issues aren’t there in terms of how we’re treated.”
Entsminger was initially drawn to teaching in part because she hoped it would allow her to have more time with her future children than other careers might offer. But as she became a mother while teaching for a decade in a brick-and-mortar environment — both at the elementary school and the high school level — she found she was unable to pick up or drop her daughter off at school, despite working in the same district her daughter attended.
In contrast, while teaching online,“in this environment I’m able to take her to school, make her breakfast,” she says. “I’m able to do life and my job. On the daily, I’m able to be ‘Mom’ and ‘Ms. Entsminger’ with less fighting for my time.”
Because of the more-flexible schedule for students enrolled in virtual learning programs, teachers do not have to be “on” for eight straight hours. And they do not necessarily have to participate in the sorts of shared systems that keep physical schools running. In a brick-and-mortar school, even if Bacon, Hamill or Entsminger were not slated to teach a class, they might be assigned to spend their time walking their students to their next class or the bus stop, or tasked with supervising the cafeteria during a lunch period. But in the virtual environment, they have the ability to close their laptop, and to quietly plan lessons or grade papers.
However, that is not to say these teachers operate as islands. Hamill says one of the largest perks of teaching virtual school is working with other fifth grade teachers across the nation, who often share PowerPoints or other lesson plans, whereas, she says, “I think sometimes in person, people can be a little precious about that.”
The workload varies for teachers in virtual programs. Entsminger’s 300-plus students are enrolled in three grades. Some live as close as her same city, others as far-flung as Europe, where they play soccer. Hamill currently has 28 students, expecting to get to 30 as the school continuously admits more. According to the National Policy Education Center, the average student-teacher ratio in the nation’s public schools was 14.8 students per teacher in 2023, with virtual schools reporting having 24.4 students per teacher.
Hamill also believes that virtual environments keep both teachers and students safer. She says she was sick for nine months of the year her first year teaching, getting strep throat twice. She also points to the seemingly endless onslaught of school shootings and the worsening of behavior issues among children.
“The trade-off for not having to do classroom management of behavioral issues is huge,” she says. “If the kid is mean in the chat, I turn off the chat. If kids aren’t listening, I can mute everyone and say, ‘I’ll let you talk one at a time.’ Versus, in my last classroom, the kids threw chairs at me.”
There are still adjustments to managing kids remotely, the teachers acknowledge. Hamill coaches her kids through internet safety and online decorum, like learning that typing in all-caps, for example, can come across rudely.
And while the virtual teachers were initially concerned about bonding with their students, they have found those worries largely unfounded. During online office hours, Hamill plays Pictionary with her students and has met most of their pets over a screen. Meanwhile, Entsminger offers online tutoring and daily opportunities to meet, where she has “learned more than I ever thought about K-pop this year.”
There are also opportunities for in-person gatherings with students. Hamill does once-a-month meetups, often in a park. Bacon attended an in-person picnic earlier this month to meet the students who live near her. And both K12 and Connections Academy hold multiple in-person events for students, including field trips and extracurriculars, like sewing or bowling clubs.
“Of course I wish I could see them more in person, and do arts and crafts time — that’s a big thing I miss,” Hamill says. “But we have drawing programs or ways they can post their artwork; we find ways to adapt to it.”
And that adaptation is largely worth it to virtual teachers.
“Teaching is teaching; even if I’m behind a computer screen, kids are still going to be kids,” Entsminger says. “The hurdles are still there. We’re still working hard, but it’s really nice to work with my students, and then walk to my kitchen to get coffee, then come back to connect to my students again.”
-

 Business3 weeks ago
Business3 weeks agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-
Tools & Platforms1 month ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy2 months ago
Ethics & Policy2 months agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences4 months ago
Events & Conferences4 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers3 months ago
Jobs & Careers3 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Education3 months ago
Education3 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Education2 months ago
Education2 months agoMacron says UK and France have duty to tackle illegal migration ‘with humanity, solidarity and firmness’ – UK politics live | Politics
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi
-

 Funding & Business3 months ago
Funding & Business3 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries