Books, Courses & Certifications
Introducing Masters Programs in Data Science and AI, Co-developed with IBM

We’re thrilled to announce that we’ve partnered with artificial intelligence and cloud leader IBM to release four master’s programs in the fields of Artificial Intelligence and Data Science.
According to a study by IBM, there will be over 2.7 million data science job openings by 2020. The same study cited machine learning as the second-fasting growing analytical skill within two years at a growth of 56 percent. It’s clear that these two are a top priority in the marketplace today, and as such is a top priority for Simplilearn and it’s future students.
Through this partnership with IBM, our members can access live virtual classrooms and self-paced video courses that combine Simplilearn’s seamless training experience and world-class instructors with IBM’s state-of-the-art labs and course content.
Key features of the Master’s Programs include portfolio-worthy Capstone Projects that demonstrate applied skills, hands-on exposure to today’s most-used tools, 24/7 access to teaching assistants, and industry-recognized certificates.
“We are delighted to partner with IBM to bring our students the most comprehensive training programs available,” said Krishna Kumar, CEO, and founder of Simplilearn. “IBM is known not just for its innovation in the world of science, but for it’s a dedication to client success. Together with IBM, we’re confident these Master’s Programs will provide everything our students need to launch new careers in data science and AI.”
Take Your Data Scientist Skills to the Next Level
With the Data Scientist Master’s Program from IBMExplore Program
The four courses are:
The Data Science Master’s Program covers R, SAS, Python, Tableau, Hadoop, and Spark in addition to supervised and unsupervised learning models such as linear regression, logistic regression, clustering, dimensionality reduction, K-NN, and pipeline.
The AI Master’s Program covers Python libraries like NumPY, SciPy, Scikit and essential Machine Learning techniques such as supervised and unsupervised learning, and advanced concepts covering artificial neural networks and layers of data abstraction, and TensorFlow.
The Data Analyst Master’s Program covers foundational to advanced analytics tools including Power BI, Tableau, and Excel, in addition to Python, and R, with a heavy focus on data visualization.
The Data Engineer Master’s Program covers today’s most coveted data tools, such as Scala, Hadoop, Spark Developer, PySpark, MongoDB, Apache Cassandra, and much more.
Learn what other tools and projects are covered in these courses by viewing the syllabus for each above.
All course content will be accessible on Simplilearn’s learning management system and will follow Simplilearn’s unique blended learning structure, providing learners with expertly-crafted content that’s delivered live and via pre-recorded video to meet the needs of every student’s preference and schedule, followed by quizzes and projects to enforce the retention of each lesson. Teaching assistants and forums provide a collaborative environment to nurture students from foundational concepts all the way through completion.
Upon completion of each program, learners will receive industry-recognized certificates from Simplilearn and IBM to indicate the user has successfully completed all requirements.

















Anyone who’s used AI to generate code has seen it make mistakes. But the real danger isn’t the occasional wrong answer; it’s in what happens when those errors pile up across a codebase. Issues that seem small at first can compound quickly, making code harder to understand, maintain, and evolve. To really see that danger, you have to look at how AI is used in practice—which for many developers starts with vibe coding.
Vibe coding is an exploratory, prompt-first approach to software development where developers rapidly prompt, get code, and iterate. When the code seems close but not quite right, the developer describes what’s wrong and lets the AI try again. When it doesn’t compile or tests fail, they copy the error messages back to the AI. The cycle continues—prompt, run, error, paste, prompt again—often without reading or understanding the generated code. It feels productive because you’re making visible progress: errors disappear, tests start passing, features seem to work. You’re treating the AI like a coding partner who handles the implementation details while you steer at a high level.
Developers use vibe coding to explore and refine ideas and can generate large amounts of code quickly. It’s often the natural first step for most developers using AI tools, because it feels so intuitive and productive. Vibe coding offloads detail to the AI, making exploration and ideation fast and effective—which is exactly why it’s so popular.
The AI generates a lot of code, and it’s not practical to review every line every time it regenerates. Trying to read it all can lead to cognitive overload—mental exhaustion from wading through too much code—and makes it harder to throw away code that isn’t working just because you already invested time in reading it.
Vibe coding is a normal and useful way to explore with AI, but on its own it presents a significant risk. The models used by LLMs can hallucinate and produce made-up answers—for example, generating code that calls APIs or methods that don’t even exist. Preventing those AI-generated mistakes from compromising your codebase starts with understanding the capabilities and limitations of these tools, and taking an approach to AI-assisted development that takes those limitations into account.
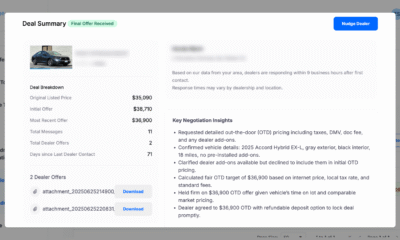
Here’s a simple example of how these issues compound. When I ask AI to generate a class that handles user interaction, it often creates methods that directly read from and write to the console. When I then ask it to make the code more testable, if I don’t very specifically prompt for a simple fix like having methods take input as parameters and return output as values, the AI frequently suggests wrapping the entire I/O mechanism in an abstraction layer. Now I have an interface, an implementation, mock objects for testing, and dependency injection throughout. What started as a straightforward class has become a miniature framework. The AI isn’t wrong, exactly—the abstraction approach is a valid pattern—but it’s overengineered for the problem at hand. Each iteration adds more complexity, and if you’re not paying attention, you’ll end up with layers upon layers of unnecessary code. This is a good example of how vibe coding can balloon into unnecessary complexity if you don’t stop to verify what’s happening.
Novice Developers Face a New Kind of Technical Debt Challenge with AI
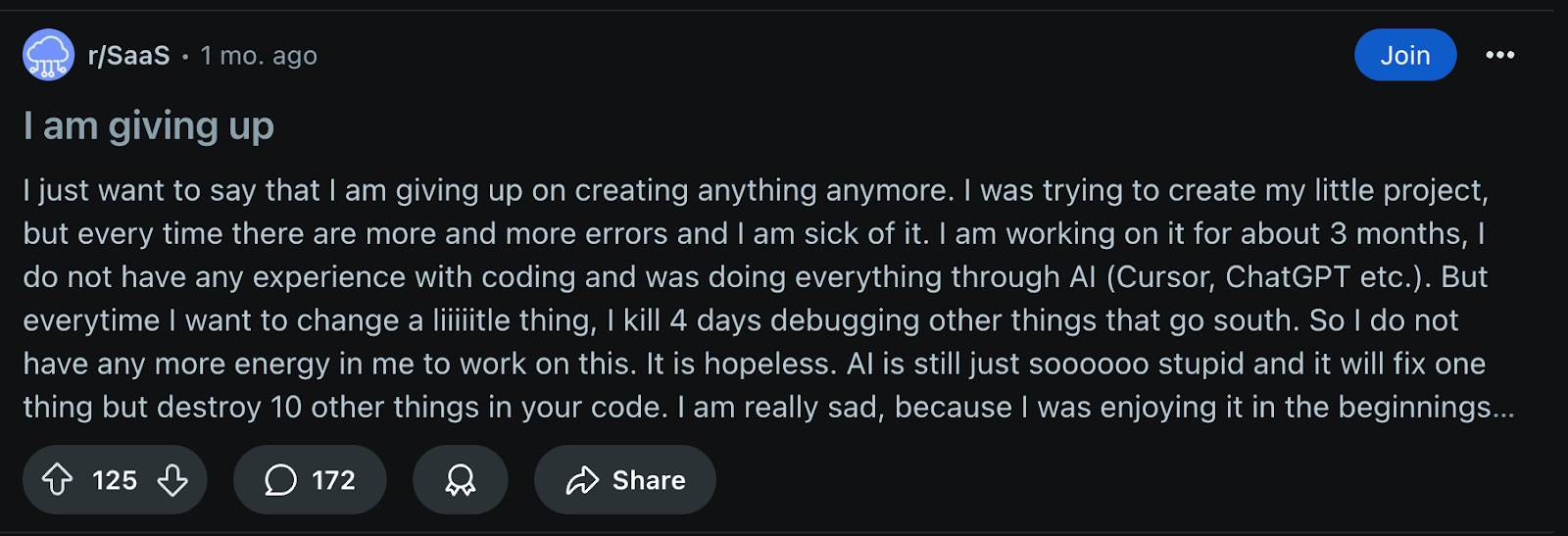
Three months after writing their first line of code, a Reddit user going by SpacetimeSorcerer posted a frustrated update: Their AI-assisted project had reached the point where making any change meant editing dozens of files. The design had hardened around early mistakes, and every change brought a wave of debugging. They’d hit the wall known in software design as “shotgun surgery,” where a single change ripples through so much code that it’s risky and slow to work on—a classic sign of technical debt, the hidden cost of early shortcuts that make future changes harder and more expensive.
AI didn’t cause the problem directly; the code worked (until it didn’t). But the speed of AI-assisted development let this new developer skip the design thinking that prevents these patterns from forming. The same thing happens to experienced developers when deadlines push delivery over maintainability. The difference is, an experienced developer often knows they’re taking on debt. They can spot antipatterns early because they’ve seen them repeatedly, and take steps to “pay off” the debt before it gets much more expensive to fix. Someone new to coding may not even realize it’s happening until it’s too late—and they haven’t yet built the tools or habits to prevent it.
Part of the reason new developers are especially vulnerable to this problem goes back to the Cognitive Shortcut Paradox (Radar, October 8). Without enough hands-on experience debugging, refactoring, and working through ambiguous requirements, they don’t have the instincts built up through experience to spot structural problems in AI-generated code. The AI can hand them a clean, working solution. But if they can’t see the design flaws hiding inside it, those flaws grow unchecked until they’re locked into the project, built into the foundations of the code so changing them requires extensive, frustrating work.
The signals of AI-accelerated technical debt show up quickly: highly coupled code where modules depend on each other’s internal details; “God objects” with too many responsibilities; overly structured solutions where a simple problem gets buried under extra layers. These are the same problems that typically reflect technical debt in human-built code; the reason they emerge so quickly in AI-generated code is because it can be generated much more quickly and without oversight or intentional design or architectural decisions being made. AI can generate these patterns convincingly, making them look deliberate even when they emerged by accident. Because the output compiles, passes tests, and works as expected, it’s easy to accept as “done” without thinking about how it will hold up when requirements change.
When adding or updating a unit test feels unreasonably difficult, that’s often the first sign the design is too rigid. The test is telling you something about the structure—maybe the code is too intertwined, maybe the boundaries are unclear. This feedback loop works whether the code was AI-generated or handwritten, but with AI the friction often shows up later, after the code has already been merged.
That’s where the “trust but verify” habit comes in. Trust the AI to give you a starting point, but verify that the design supports change, testability, and clarity. Ask yourself whether the code will still make sense to you—or anyone else—months from now. In practice, this can mean quick design reviews even for AI-generated code, refactoring when coupling or duplication starts to creep in, and taking a deliberate pass at naming so variables and functions read clearly. These aren’t optional touches; they’re what keep a codebase from locking in its worst early decisions.
AI can help with this too: It can suggest refactorings, point out duplicated logic, or help extract messy code into cleaner abstractions. But it’s up to you to direct it to make those changes, which means you have to spot them first—which is much easier for experienced developers who have seen these problems over the course of many projects.
Left to its defaults, AI-assisted development is biased toward adding new code, not revisiting old decisions. The discipline to avoid technical debt comes from building design checks into your workflow so AI’s speed works in service of maintainability instead of against it.

“I’ve never done this work alone,” I thought as I looked around the high school gymnasium at the other instructional coaches and school leaders. We had been given a critical, quick-write prompt to begin the professional learning session that asked: Who helped you grow the most in your profession? How did they help you grow? And how does that impact your work today?
As I leaned toward my Chromebook to respond, the thought sharpened. I’ve never done this work alone, and the people beside me have shaped every step I’ve taken.
I’ve had mentors and coaches who did more than hand me tips or point me toward resources. Some were my practicum and student teaching supervisors who trusted me to figure things out, but never let me feel like I had to figure them out alone.
I remember being told, “Your students don’t need you to be perfect; they need you to be present.” One reminded me often, “Take the risk. The worst thing that happens is you learn something new.” Their guidance gave me permission to show up as my whole self and take risks as I shaped my evolving teacher identity. As a high school English teacher, former instructional coach, and now as a district instructional support leader, I’ve come to understand that the mentoring I once relied on is the same coaching I try to give others.
Adjusting to a New Environment
When I stepped into the role of instructional coach last year, I brought the habits I’d relied on as a teacher: listening before advising, learning alongside others and remembering what it felt like to be supported well.
Unfortunately, that approach wasn’t instantly recognized in my new school setting.
No one told me I didn’t belong, but in those first weeks, I could feel the distance between myself and my new colleagues. Conversations quieted when I walked by. Some teachers kept their distance. The glances might have lasted just a little too long. One afternoon, a teacher finally asked, “So what exactly is it you’re here to do?”
The question stayed with me. I know that it wasn’t meant to be hostile. My experience stepping into instructional coaching was part of a larger story that was playing out in schools. Nearly 60 percent of public schools have at least one instructional coach, though in many places, the role is underfunded, temporary or narrowly defined. In Rhode Island where I’m from, that’s beginning to shift.
Last year, the state invested $5 million to expand coaching across districts, with the goal of making it a permanent, embedded part of school life. This year, the Rhode Island Department of Education followed with nearly $40 million more over five years, as part of the Comprehensive Literacy State Development grant, building partnerships between schools and teacher preparation programs to strengthen literacy instruction and improve student outcomes.
Still, in that moment, being asked what it is I’m here to do stung. I felt the heat of my own insecurities rising. Was I stepping on toes? Was I doing enough? More than once, I wondered if I was in over my head or if my colleagues realized I wasn’t the professional they expected. I’d been a teacher for nearly 20 years, yet in those early days of coaching, I felt like an imposter.
Part of the distance, I realized, was rooted in a common assumption: If I need a coach, that must mean I don’t know what I’m doing.
No one said it outright, but I recognized it in the reluctance to invite me into their classes, or when teachers would come to me for immediate solutions rather than a full coaching cycle. It’s a belief born from a profession that too often equates needing help with being less capable, when in truth, the opposite is almost always true.
Some also saw coaches as the ears and eyes of the central office. Others thought I was there to evaluate. I wasn’t an administrator, though I worked closely with school leaders. I was a union member, though my proximity to administrators made teachers cautious. I lived in the middle: in classrooms but not a teacher, in leadership meetings but not a decision-maker.
As a coach, you see everything from two vantage points, and you’re constantly translating. You hear the teacher’s frustrations and see the administrator’s challenges. You try to bridge the two without losing the trust of either. No one really trains you for that; I had to figure it out in real time.
Finding the Rhythm
In time, I began to ask myself a question that became my compass as an instructional coach: What would I need if I were being coached?
That question grounded me when the role felt murky. If I were a teacher looking for support, I wouldn’t need another checklist or a curriculum pacing reminder because that kind of guidance already came from administration. I would need a thought partner who offered reassurance and helped me untangle the knot of implementing high-quality instructional materials, district goals and the unique needs of my students.
As the year progressed, I slowly bridged the gap and found teachers willing to move through coaching cycles. We planned lessons together. Sometimes we co-taught and something didn’t land, so we regrouped and tried again. None of it fit neatly into a script. And none of it was about compliance.
The most meaningful moments as a coach rarely happened on a schedule. They often came in the hall or between classes when a teacher stopped me to say, “Can I show you something I’m trying? Can you stop by next period?”
One teacher I partnered with taught science electives, including a forensics course. Her students were deep into analyzing blood splatter patterns in mock crime scenes. I still remember the excitement on the day she invited me to visit. She handed me goggles and an apron, and I entered a room buzzing with collaboration. I was hooked.
The real magic happened after the lab, when we sat down with student work and asked, “What could this be next time?” She took risks, tried new tools, and centered student voice. When she doubted herself, I reminded her of what the students already knew: she was an incredible educator. Over the year, her teaching became even more responsive and inventive, building on what worked and letting go of what didn’t.
Over time, I began to see that the real power of coaching wasn’t in providing fixes but in creating the space for teachers to think aloud about their own questions and choose the next steps that felt right to them. I was never supposed to fix it all.
Enjoying the Journey Together
I believe that learning to teach is a career-long journey. It is never something you do alone; it is something you grow into alongside others, while still figuring out what kind of teacher you are and what type you want to be.
Coaching, like teaching, is rarely neat. Early on, I thought my role was to smooth things out or provide solutions. While I still catch myself slipping into that impulse, I’ve realized that what matters most is sitting alongside teachers and learning through the uncertainty, however uncomfortable. That is the improvisational, human work of coaching.
If I were back in the classroom tomorrow, I’d want a coach who saw my potential and pushed me, even on days I doubted myself. That’s the coach I try to be now: encouraging and willing to step in when the work gets messy.
Books, Courses & Certifications
Powering innovation at scale: How AWS is tackling AI infrastructure challenges

As generative AI continues to transform how enterprises operate—and develop net new innovations—the infrastructure demands for training and deploying AI models have grown exponentially. Traditional infrastructure approaches are struggling to keep pace with today’s computational requirements, network demands, and resilience needs of modern AI workloads.
At AWS, we’re also seeing a transformation across the technology landscape as organizations move from experimental AI projects to production deployments at scale. This shift demands infrastructure that can deliver unprecedented performance while maintaining security, reliability, and cost-effectiveness. That’s why we’ve made significant investments in networking innovations, specialized compute resources, and resilient infrastructure that’s designed specifically for AI workloads.
Accelerating model experimentation and training with SageMaker AI
The gateway to our AI infrastructure strategy is Amazon SageMaker AI, which provides purpose-built tools and workflows to streamline experimentation and accelerate the end-to-end model development lifecycle. One of our key innovations in this area is Amazon SageMaker HyperPod, which removes the undifferentiated heavy lifting involved in building and optimizing AI infrastructure.
At its core, SageMaker HyperPod represents a paradigm shift by moving beyond the traditional emphasis on raw computational power toward intelligent and adaptive resource management. It comes with advanced resiliency capabilities so that clusters can automatically recover from model training failures across the full stack, while automatically splitting training workloads across thousands of accelerators for parallel processing.
The impact of infrastructure reliability on training efficiency is significant. On a 16,000-chip cluster, for instance, every 0.1% decrease in daily node failure rate improves cluster productivity by 4.2% —translating to potential savings of up to $200,000 per day for a 16,000 H100 GPU cluster. To address this challenge, we recently introduced Managed Tiered Checkpointing in HyperPod, leveraging CPU memory for high-performance checkpoint storage with automatic data replication. This innovation helps deliver faster recovery times and is a cost-effective solution compared to traditional disk-based approaches.
For those working with today’s most popular models, HyperPod also offers over 30 curated model training recipes, including support for OpenAI GPT-OSS, DeepSeek R1, Llama, Mistral, and Mixtral. These recipes automate key steps like loading training datasets, applying distributed training techniques, and configuring systems for checkpointing and recovery from infrastructure failures. And with support for popular tools like Jupyter, vLLM, LangChain, and MLflow, you can manage containerized apps and scale clusters dynamically as you scale your foundation model training and inference workloads.
Overcoming the bottleneck: Network performance
As organizations scale their AI initiatives from proof of concept to production, network performance often becomes the critical bottleneck that can make or break success. This is particularly true when training large language models, where even minor network delays can add days or weeks to training time and significantly increase costs. In 2024, the scale of our networking investments was unprecedented; we installed over 3 million network links to support our latest AI network fabric, or 10p10u infrastructure. Supporting more than 20,000 GPUs while delivering 10s of petabits of bandwidth with under 10 microseconds of latency between servers, this infrastructure enables organizations to train massive models that were previously impractical or impossibly expensive. To put this in perspective: what used to take weeks can now be accomplished in days, allowing companies to iterate faster and bring AI innovations to customers sooner.
At the heart of this network architecture is our revolutionary Scalable Intent Driven Routing (SIDR) protocol and Elastic Fabric Adapter (EFA). SIDR acts as an intelligent traffic control system that can instantly reroute data when it detects network congestion or failures, responding in under one second—ten times faster than traditional distributed networking approaches.
Accelerated computing for AI
The computational demands of modern AI workloads are pushing traditional infrastructure to its limits. Whether you’re fine-tuning a foundation model for your specific use case or training a model from scratch, having the right compute infrastructure isn’t just about raw power—it’s about having the flexibility to choose the most cost-effective and efficient solution for your specific needs.
AWS offers the industry’s broadest selection of accelerated computing options, anchored by both our long-standing partnership with NVIDIA and our custom-built AWS Trainium chips. This year’s launch of P6 instances featuring NVIDIA Blackwell chips demonstrates our continued commitment to bringing the latest GPU technology to our customers. The P6-B200 instances provide 8 NVIDIA Blackwell GPUs with 1.4 TB of high bandwidth GPU memory and up to 3.2 Tbps of EFAv4 networking. In preliminary testing, customers like JetBrains have already seen greater than 85% faster training times on P6-B200 over H200-based P5en instances across their ML pipelines.
To make AI more affordable and accessible, we also developed AWS Trainium, our custom AI chip designed specifically for ML workloads. Using a unique systolic array architecture, Trainium creates efficient computing pipelines that reduce memory bandwidth demands. To simplify access to this infrastructure, EC2 Capacity Blocks for ML also enable you to reserve accelerated compute instances within EC2 UltraClusters for up to six months, giving customers predictable access to the accelerated compute they need.
Preparing for tomorrow’s innovations, today
As AI continues to transform every aspect of our lives, one thing is clear: AI is only as good as the foundation upon which it is built. At AWS, we’re committed to being that foundation, delivering the security, resilience, and continuous innovation needed for the next generation of AI breakthroughs. From our revolutionary 10p10u network fabric to custom Trainium chips, from P6e-GB200 UltraServers to SageMaker HyperPod’s advanced resilience capabilities, we’re enabling organizations of all sizes to push the boundaries of what’s possible with AI. We’re excited to see what our customers will build next on AWS.
About the author
Barry Cooks is a global enterprise technology veteran with 25 years of experience leading teams in cloud computing, hardware design, application microservices, artificial intelligence, and more. As VP of Technology at Amazon, he is responsible for compute abstractions (containers, serverless, VMware, micro-VMs), quantum experimentation, high performance computing, and AI training. He oversees key AWS services including AWS Lambda, Amazon Elastic Container Service, Amazon Elastic Kubernetes Service, and Amazon SageMaker. Barry also leads responsible AI initiatives across AWS, promoting the safe and ethical development of AI as a force for good. Prior to joining Amazon in 2022, Barry served as CTO at DigitalOcean, where he guided the organization through its successful IPO. His career also includes leadership roles at VMware and Sun Microsystems. Barry holds a BS in Computer Science from Purdue University and an MS in Computer Science from the University of Oregon.
-

 Business2 weeks ago
Business2 weeks agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-
Tools & Platforms4 weeks ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy1 month ago
Ethics & Policy1 month agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences4 months ago
Events & Conferences4 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers2 months ago
Jobs & Careers2 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Education2 months ago
Education2 months agoMacron says UK and France have duty to tackle illegal migration ‘with humanity, solidarity and firmness’ – UK politics live | Politics
-

 Education2 months ago
Education2 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Funding & Business2 months ago
Funding & Business2 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi