Books, Courses & Certifications
Qwen3 family of reasoning models now available in Amazon Bedrock Marketplace and Amazon SageMaker JumpStart
Today, we are excited to announce that Qwen3, the latest generation of large language models (LLMs) in the Qwen family, is available through Amazon Bedrock Marketplace and Amazon SageMaker JumpStart. With this launch, you can deploy the Qwen3 models—available in 0.6B, 4B, 8B, and 32B parameter sizes—to build, experiment, and responsibly scale your generative AI applications on AWS.
In this post, we demonstrate how to get started with Qwen3 on Amazon Bedrock Marketplace and SageMaker JumpStart. You can follow similar steps to deploy the distilled versions of the models as well.
Solution overview
Qwen3 is the latest generation of LLMs in the Qwen series, offering a comprehensive suite of dense and mixture-of-experts (MoE) models. Qwen3 delivers groundbreaking advancements in reasoning, instruction-following, agent capabilities, and multilingual support, with the following key features:
- Unique support of seamless switching between thinking mode and non-thinking mode within a single model, providing optimal performance across various scenarios.
- Significantly enhanced in its reasoning capabilities, surpassing previous QwQ (in thinking mode) and Qwen2.5 instruct models (in non-thinking mode) on mathematics, code generation, and commonsense logical reasoning.
- Good human preference alignment, excelling in creative writing, role-playing, multi-turn dialogues, and instruction following, to deliver a more natural, engaging, and immersive conversational experience.
- Expertise in agent capabilities, enabling precise integration with external tools in both thinking and unthinking modes and achieving leading performance among open source models in complex agent-based tasks.
- Support for over 100 languages and dialects with strong capabilities for multilingual instruction following and translation.
Prerequisites
To deploy Qwen3 models, make sure you have access to the recommended instance types based on the model size. You can find these instance recommendations on Amazon Bedrock Marketplace or the SageMaker JumpStart console. To verify you have the necessary resources, complete the following steps:
- Open the Service Quotas console.
- Under AWS Services, select Amazon SageMaker.
- Check that you have sufficient quota for the required instance type for endpoint deployment.
- Make sure at least one of these instance types is available in your target AWS Region.
If needed, request a quota increase and contact your AWS account team for support.
Deploy Qwen3 in Amazon Bedrock Marketplace
Amazon Bedrock Marketplace gives you access to over 100 popular, emerging, and specialized foundation models (FMs) through Amazon Bedrock. To access Qwen3 in Amazon Bedrock, complete the following steps:
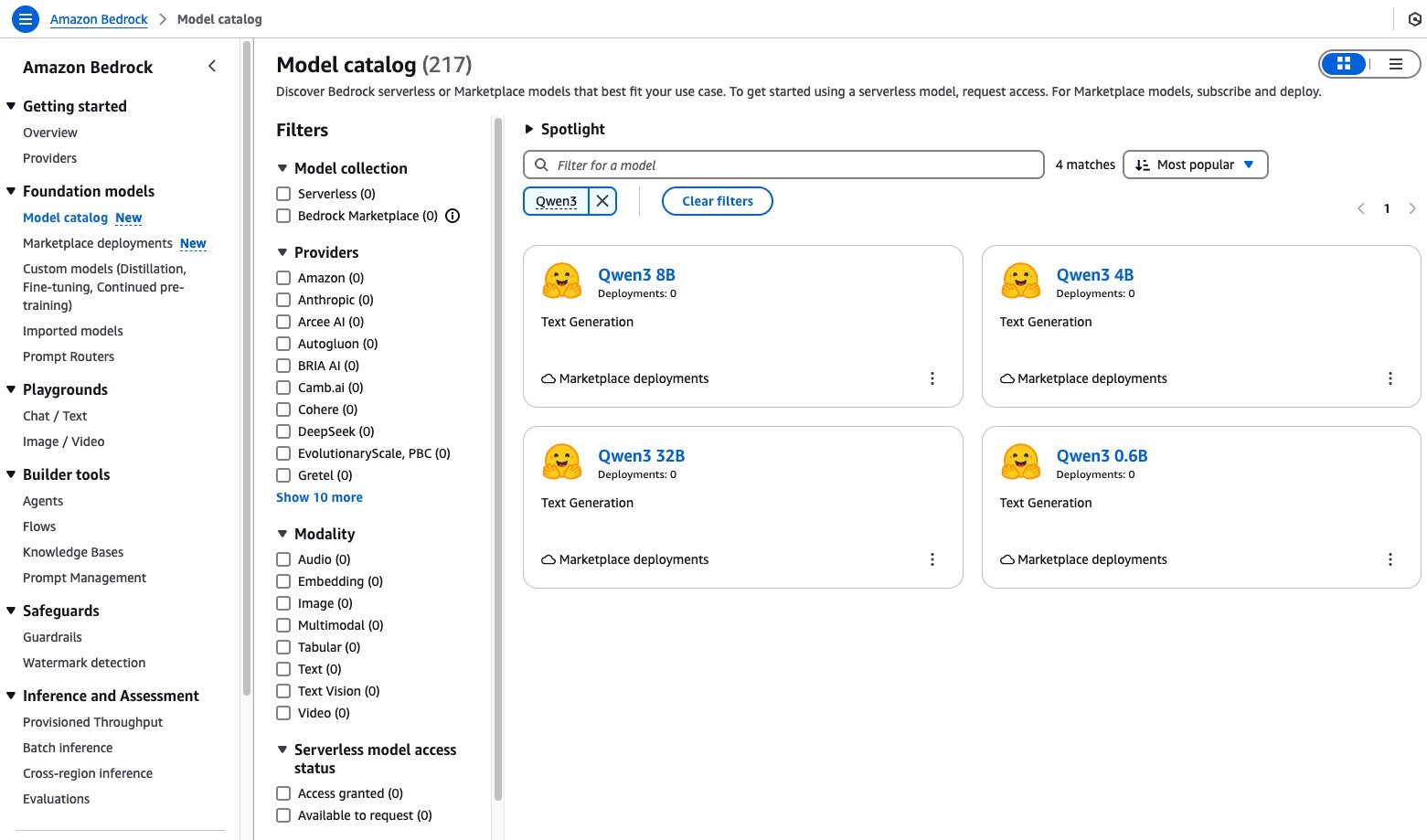
- On the Amazon Bedrock console, in the navigation pane under Foundation models, choose Model catalog.
- Filter for Hugging Face as a provider and choose a Qwen3 model. For this example, we use the Qwen3-32B model.
The model detail page provides essential information about the model’s capabilities, pricing structure, and implementation guidelines. You can find detailed usage instructions, including sample API calls and code snippets for integration.
The page also includes deployment options and licensing information to help you get started with Qwen3-32B in your applications.
- To begin using Qwen3-32B, choose Deploy.
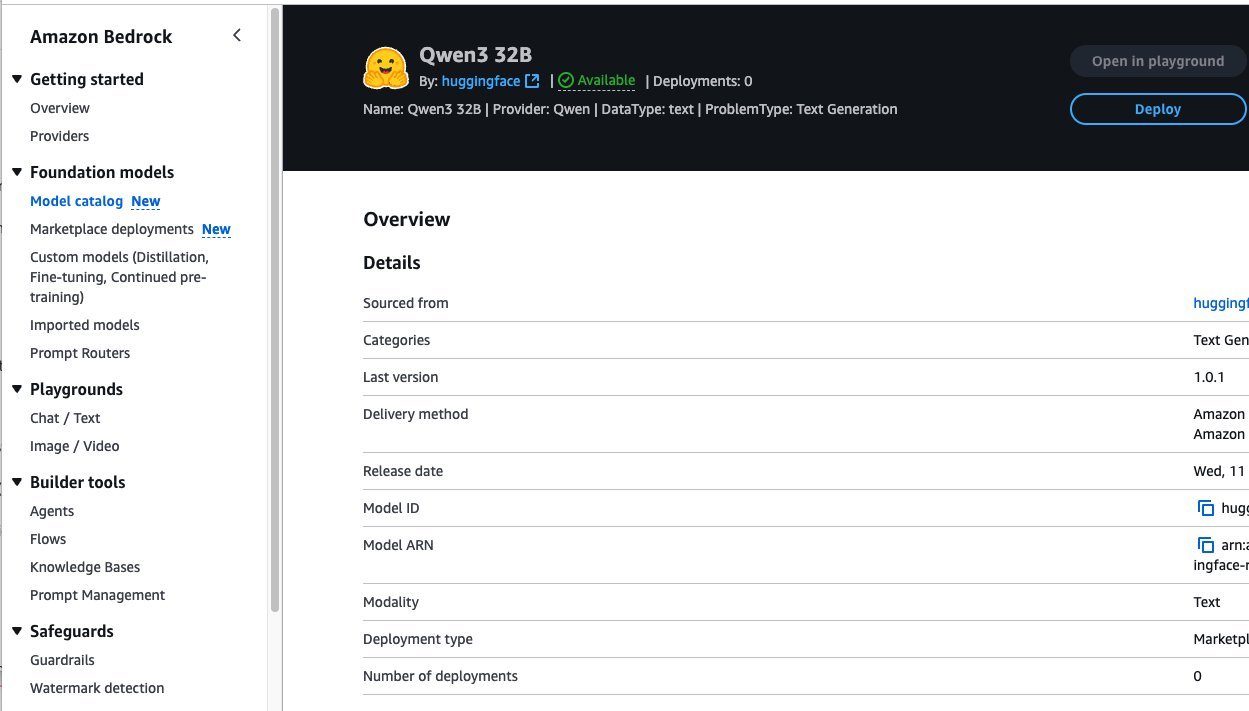
You will be prompted to configure the deployment details for Qwen3-32B. The model ID will be pre-populated.
- For Endpoint name, enter an endpoint name (between 1–50 alphanumeric characters).
- For Number of instances, enter a number of instances (between 1–100).
- For Instance type, choose your instance type. For optimal performance with Qwen3-32B, a GPU-based instance type like ml.g5-12xlarge is recommended.
- To deploy the model, choose Deploy.
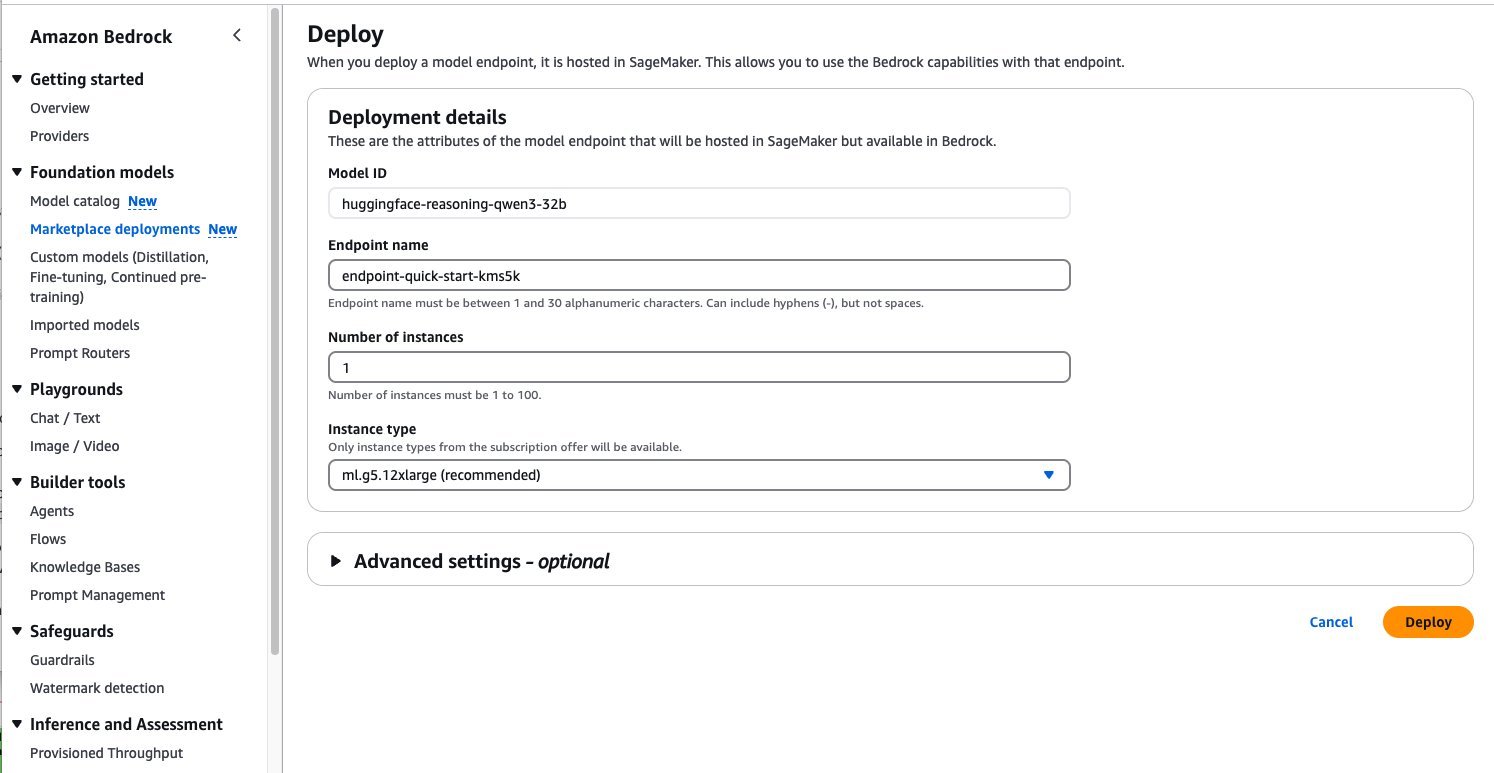
When the deployment is complete, you can test Qwen3-32B’s capabilities directly in the Amazon Bedrock playground.
- Choose Open in playground to access an interactive interface where you can experiment with different prompts and adjust model parameters like temperature and maximum length.
This is an excellent way to explore the model’s reasoning and text generation abilities before integrating it into your applications. The playground provides immediate feedback, helping you understand how the model responds to various inputs and letting you fine-tune your prompts for optimal results.You can quickly test the model in the playground through the UI. However, to invoke the deployed model programmatically with any Amazon Bedrock APIs, you must have the endpoint Amazon Resource Name (ARN).
Enable reasoning and non-reasoning responses with Converse API
The following code shows how to turn reasoning on and off with Qwen3 models using the Converse API, depending on your use case. By default, reasoning is left on for Qwen3 models, but you can streamline interactions by using the /no_think command within your prompt. When you add this to the end of your query, reasoning is turned off and the models will provide just the direct answer. This is particularly useful when you need quick information without explanations, are familiar with the topic, or want to maintain a faster conversational flow. At the time of writing, the Converse API doesn’t support tool use for Qwen3 models. Refer to the Invoke_Model API example later in this post to learn how to use reasoning and tools in the same completion.
The following is a response using the Converse API, without default thinking:
The following is an example with default thinking on; the reasoningContent field for the Converse API:
Perform reasoning and function calls in the same completion using the Invoke_Model API
With Qwen3, you can stream an explicit trace and the exact JSON tool call in the same completion. Up until now, reasoning models have forced the choice to either show the chain of thought or call tools deterministically. The following code shows an example:
Response:
Deploy Qwen3-32B with SageMaker JumpStart
SageMaker JumpStart is a machine learning (ML) hub with FMs, built-in algorithms, and prebuilt ML solutions that you can deploy with just a few clicks. With SageMaker JumpStart, you can customize pre-trained models to your use case, with your data, and deploy them into production using either the UI or SDK.Deploying the Qwen3-32B model through SageMaker JumpStart offers two convenient approaches: using the intuitive SageMaker JumpStart UI or implementing programmatically through the SageMaker Python SDK. Let’s explore both methods to help you choose the approach that best suits your needs.
Deploy Qwen3-32B through SageMaker JumpStart UI
Complete the following steps to deploy Qwen3-32B using SageMaker JumpStart:
- On the SageMaker console, choose Studio in the navigation pane.
- First-time users will be prompted to create a domain.
- On the SageMaker Studio console, choose JumpStart in the navigation pane.
The model browser displays available models, with details like the provider name and model capabilities.

- Search for Qwen3 to view the Qwen3-32B model card.
Each model card shows key information, including:
- Model name
- Provider name
- Task category (for example, Text Generation)
- Bedrock Ready badge (if applicable), indicating that this model can be registered with Amazon Bedrock, so you can use Amazon Bedrock APIs to invoke the model

- Choose the model card to view the model details page.
The model details page includes the following information:
- The model name and provider information
- A Deploy button to deploy the model
- About and Notebooks tabs with detailed information
The About tab includes important details, such as:
- Model description
- License information
- Technical specifications
- Usage guidelines
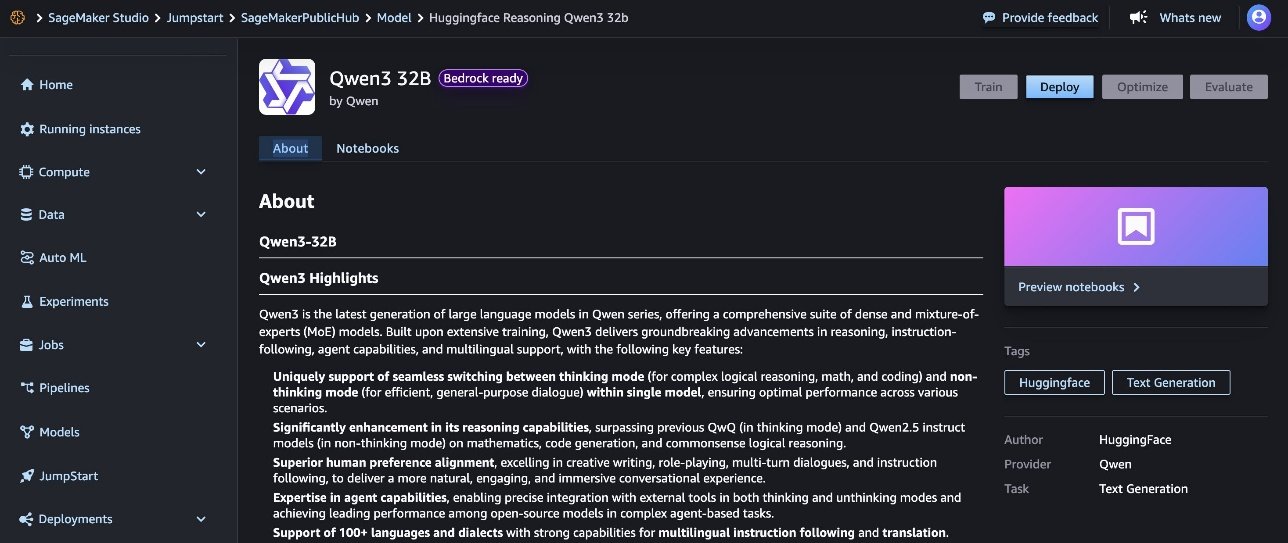
Before you deploy the model, it’s recommended to review the model details and license terms to confirm compatibility with your use case.
- Choose Deploy to proceed with deployment.
- For Endpoint name, use the automatically generated name or create a custom one.
- For Instance type¸ choose an instance type (default: ml.g6-12xlarge).
- For Initial instance count, enter the number of instances (default: 1).
Selecting appropriate instance types and counts is crucial for cost and performance optimization. Monitor your deployment to adjust these settings as needed. Under Inference type, Real-time inference is selected by default. This is optimized for sustained traffic and low latency.
- Review all configurations for accuracy. For this model, we strongly recommend adhering to SageMaker JumpStart default settings and making sure that network isolation remains in place.
- Choose Deploy to deploy the model.
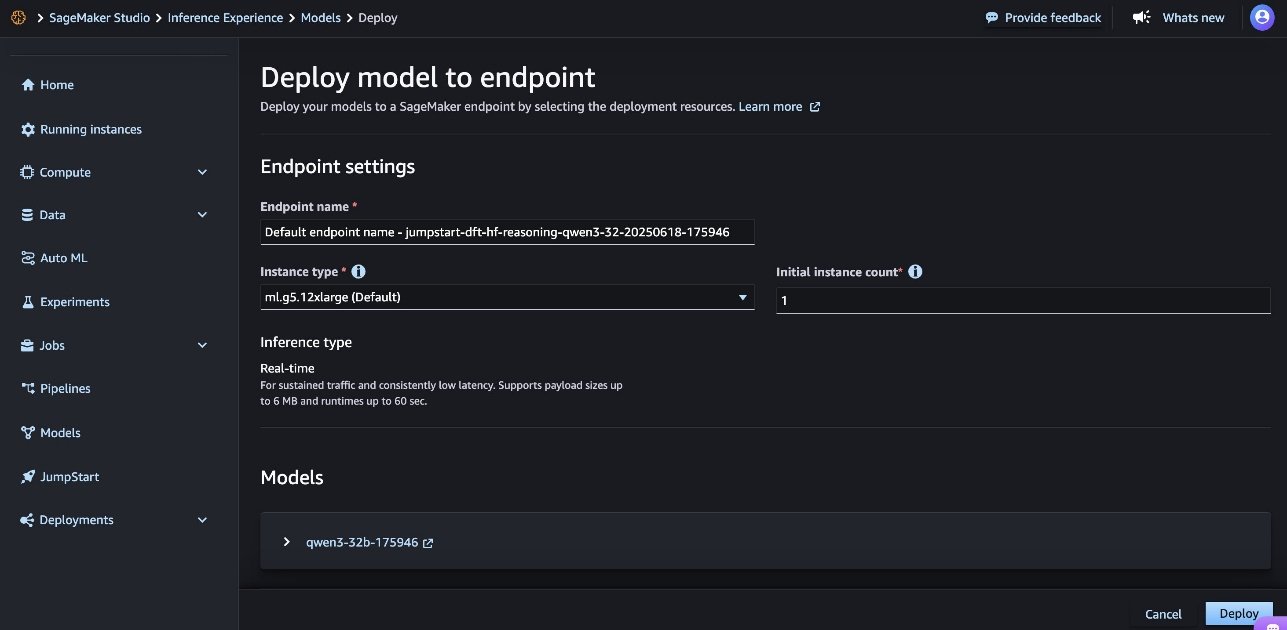
The deployment process can take several minutes to complete.
When deployment is complete, your endpoint status will change to InService. At this point, the model is ready to accept inference requests through the endpoint. You can monitor the deployment progress on the SageMaker console Endpoints page, which will display relevant metrics and status information. When the deployment is complete, you can invoke the model using a SageMaker runtime client and integrate it with your applications.
Deploy Qwen3-32B using the SageMaker Python SDK
To get started with Qwen3-32B using the SageMaker Python SDK, you must install the SageMaker Python SDK and make sure you have the necessary AWS permissions and environment set up. The following is a step-by-step code example that demonstrates how to deploy and use Qwen3-32B for inference programmatically:
You can run additional requests against the predictor:
The following are some error handling and best practices to enhance deployment code:
Clean up
To avoid unwanted charges, complete the steps in this section to clean up your resources.
Delete the Amazon Bedrock Marketplace deployment
If you deployed the model using Amazon Bedrock Marketplace, complete the following steps:
- On the Amazon Bedrock console, under Foundation models in the navigation pane, choose Marketplace deployments.
- In the Managed deployments section, locate the endpoint you want to delete.
- Select the endpoint, and on the Actions menu, choose Delete.
- Verify the endpoint details to make sure you’re deleting the correct deployment:
- Endpoint name
- Model name
- Endpoint status
- Choose Delete to delete the endpoint.
- In the deletion confirmation dialog, review the warning message, enter
confirm, and choose Delete to permanently remove the endpoint.
Delete the SageMaker JumpStart predictor
The SageMaker JumpStart model you deployed will incur costs if you leave it running. Use the following code to delete the endpoint if you want to stop incurring charges. For more details, see Delete Endpoints and Resources.
Conclusion
In this post, we explored how you can access and deploy the Qwen3 models using Amazon Bedrock Marketplace and SageMaker JumpStart. With support for both the full parameter models and its distilled versions, you can choose the optimal model size for your specific use case. Visit SageMaker JumpStart in Amazon SageMaker Studio or Amazon Bedrock Marketplace to get started. For more information, refer to Use Amazon Bedrock tooling with Amazon SageMaker JumpStart models, SageMaker JumpStart pretrained models, Amazon SageMaker JumpStart Foundation Models, Amazon Bedrock Marketplace, and Getting started with Amazon SageMaker JumpStart.
The Qwen3 family of LLMs offers exceptional versatility and performance, making it a valuable addition to the AWS foundation model offerings. Whether you’re building applications for content generation, analysis, or complex reasoning tasks, Qwen3’s advanced architecture and extensive context window make it a powerful choice for your generative AI needs.
About the authors
 Niithiyn Vijeaswaran is a Generative AI Specialist Solutions Architect with the Third-Party Model Science team at AWS. His area of focus is AWS AI accelerators (AWS Neuron). He holds a Bachelor’s degree in Computer Science and Bioinformatics.
Niithiyn Vijeaswaran is a Generative AI Specialist Solutions Architect with the Third-Party Model Science team at AWS. His area of focus is AWS AI accelerators (AWS Neuron). He holds a Bachelor’s degree in Computer Science and Bioinformatics.
 Avan Bala is a Solutions Architect at AWS. His area of focus is AI for DevOps and machine learning. He holds a bachelor’s degree in Computer Science with a minor in Mathematics and Statistics from the University of Maryland. Avan is currently working with the Enterprise Engaged East Team and likes to specialize in projects about emerging AI technologies.
Avan Bala is a Solutions Architect at AWS. His area of focus is AI for DevOps and machine learning. He holds a bachelor’s degree in Computer Science with a minor in Mathematics and Statistics from the University of Maryland. Avan is currently working with the Enterprise Engaged East Team and likes to specialize in projects about emerging AI technologies.
 Mohhid Kidwai is a Solutions Architect at AWS. His area of focus is generative AI and machine learning solutions for small-medium businesses. He holds a bachelor’s degree in Computer Science with a minor in Biological Science from North Carolina State University. Mohhid is currently working with the SMB Engaged East Team at AWS.
Mohhid Kidwai is a Solutions Architect at AWS. His area of focus is generative AI and machine learning solutions for small-medium businesses. He holds a bachelor’s degree in Computer Science with a minor in Biological Science from North Carolina State University. Mohhid is currently working with the SMB Engaged East Team at AWS.
 Yousuf Athar is a Solutions Architect at AWS specializing in generative AI and AI/ML. With a Bachelor’s degree in Information Technology and a concentration in Cloud Computing, he helps customers integrate advanced generative AI capabilities into their systems, driving innovation and competitive edge. Outside of work, Yousuf loves to travel, watch sports, and play football.
Yousuf Athar is a Solutions Architect at AWS specializing in generative AI and AI/ML. With a Bachelor’s degree in Information Technology and a concentration in Cloud Computing, he helps customers integrate advanced generative AI capabilities into their systems, driving innovation and competitive edge. Outside of work, Yousuf loves to travel, watch sports, and play football.
 John Liu has 15 years of experience as a product executive and 9 years of experience as a portfolio manager. At AWS, John is a Principal Product Manager for Amazon Bedrock. Previously, he was the Head of Product for AWS Web3 / Blockchain. Prior to AWS, John held various product leadership roles at public blockchain protocols, fintech companies and also spent 9 years as a portfolio manager at various hedge funds.
John Liu has 15 years of experience as a product executive and 9 years of experience as a portfolio manager. At AWS, John is a Principal Product Manager for Amazon Bedrock. Previously, he was the Head of Product for AWS Web3 / Blockchain. Prior to AWS, John held various product leadership roles at public blockchain protocols, fintech companies and also spent 9 years as a portfolio manager at various hedge funds.
 Rohit Talluri is a Generative AI GTM Specialist at Amazon Web Services (AWS). He is partnering with top generative AI model builders, strategic customers, key AI/ML partners, and AWS Service Teams to enable the next generation of artificial intelligence, machine learning, and accelerated computing on AWS. He was previously an Enterprise Solutions Architect and the Global Solutions Lead for AWS Mergers & Acquisitions Advisory.
Rohit Talluri is a Generative AI GTM Specialist at Amazon Web Services (AWS). He is partnering with top generative AI model builders, strategic customers, key AI/ML partners, and AWS Service Teams to enable the next generation of artificial intelligence, machine learning, and accelerated computing on AWS. He was previously an Enterprise Solutions Architect and the Global Solutions Lead for AWS Mergers & Acquisitions Advisory.
 Varun Morishetty is a Software Engineer with Amazon SageMaker JumpStart and Bedrock Marketplace. Varun received his Bachelor’s degree in Computer Science from Northeastern University. In his free time, he enjoys cooking, baking and exploring New York City.
Varun Morishetty is a Software Engineer with Amazon SageMaker JumpStart and Bedrock Marketplace. Varun received his Bachelor’s degree in Computer Science from Northeastern University. In his free time, he enjoys cooking, baking and exploring New York City.

As Molly Hamill explains the origin of the Declaration of Independence to her students, she dons a white wig fashioned into a ponytail, appearing as John Adams, before sporting a bald cap in homage to Benjamin Franklin, then wearing a red wig to imitate Thomas Jefferson. But instead of looking out to an enraptured sea of 28 fifth graders leaning forward in their desks, she is speaking directly into a camera.
Hamill is one of a growing number of educators who forwent brick-and-mortar schools post-pandemic. She now teaches fully virtually through the public, online school California Virtual Academies, having swapped desks for desktops.
After the abrupt shift to virtual schooling during the COVID-19 health crisis — and the stress for many educators because of it — voluntarily choosing the format may seem unthinkable.
“You hear people say, ‘I would never want to go back to virtual,’ and I get it, it was super stressful because we were building the plane as we were flying it, deciding if we were going to have live video or recordings, and adapt all the teaching materials to virtual,” Hamill says. “But my school is a pretty well-oiled machine … there’s a structure already in place. And kids are adaptable, they already like being on a computer.”
And for Hamill, and thousands of other teachers, instructing through a virtual school is a way to attempt striking a rare work-life balance in the education world.
More Flexibility for Teaching Students
The number of virtual schools has grown, as has the number of U.S. children enrolled in them. In the 2022-2023 school year, about 2.5 percent of K-12 students were enrolled in full-time virtual education (1.8 percent of them through public or private online schools, and 0.7 percent as homeschoolers), according to data published in 2024 by the National Center for Education Statistics. And parents reported that 7 percent of students who learned at home that year took at least one virtual course.
There’s been an accompanying rise in the number of teachers instructing remotely via virtual schools.
The number of teachers employed by K12, which is under the parent company Stride Inc. and one of the largest and longest-running providers of virtual schools, has jumped from 6,500 to 8,000 over the last three or four years, says Niyoka McCoy, chief learning officer at the company.
McCoy credits the growth in part to teachers wanting to homeschool their own children, and therefore needing to do their own work from home, but she also thinks it is a sign of a shifting preference for technology-based offerings.
“They think this is the future, that more online programs will open up,” McCoy says.
Connections Academy, which is the parent company of Pearson Online Academy and a similarly long-standing online learning provider, employs 3,500 teachers. Nik Osborne, senior vice president of partnerships and customer success at Pearson, says it’s been easy to both recruit and keep teachers: roughly 91 percent of teachers in the 2024-2025 school year returned this academic year.
“Teaching in a virtual space is very different than brick-and-mortar; even the type of role teachers play appeals to some teachers,” Osborne says. “They become more of a guide to help the kids understand content.”
Courtney Entsminger, a middle school math teacher at the public, online school Virginia Connections Academy, teaches asynchronously and likes the ability to record her own lesson plans in addition to teaching them live, which she says helps a wider variety of learners. Hamill, who teaches synchronously, similarly likes that the virtual format can be leveraged to build more creative lesson plans, like her Declaration of Independence video, or a fake livestream of George Washington during the Battle of Trenton, both which are on her YouTube channel.
Whether a school is asynchronous or not largely depends on the standard of the provider. Pearson, which runs the Virtual Academies where Entsminger teaches, is asynchronous. For other standalone public school districts, such as Georgia Cyber Academy, the decision comes down to what students need: if they are performing at or above grade level, they get more flexibility, but if they come to the school below grade level — reading at a second grade level, for example, but placed in a fourth grade classroom — they need more structure.
“I do feel like a TikTok star where I record myself teaching through different aspects of that curriculum because students work in different ways,” says Entsminger, who has 348 online students across three grades. “In person you’re able to realize ‘this student works this way,’ and I’ll do a song and dance in front of you. Online, I can do it in different mediums.”
Karen Bacon, a transition liaison at Ohio Virtual Academy who works with middle and high school students in special education, was initially drawn to virtual teaching because of its flexibility for supporting students through a path that works best for them.
“I always like a good challenge and thought this was interesting to dive into how this works and different ways to help students,” says Bacon, who was a high school French teacher before making the switch to virtual in 2017. “There’s obviously a lot to learn and understand, but once you dive in and see all the options, there really are a lot of different possibilities out there.”
Bacon says there are “definitely less distractions,” than in a brick-and-mortar environment, allowing her to get more creative. For example, she had noticed stories crop up across the nation showcasing special education students in physical environments working to serve coffee to teachers and students as a way to learn workplace skills. She, adapting to the virtual environment, created the “Cardinal Cafe,” where students can accomplish the same goals, albeit with a virtual cup of joe.
“I don’t really consider myself super tech-y, but I have that curiosity and love going outside the box and looking at ways to really help my students,” she says.
A Way to Curb Teacher Burnout?
The flexibility that comes with teaching in a virtual environment is not just appealing for what it offers students. Teachers say it can also help cushion the consistently lower wages and lack of benefits most educators grapple with, conditions that drive many to leave the field.
“So many of us have said, ‘I felt so burned out, I wasn’t sure I could keep teaching,’” Hamill says, adding she felt similarly at the start of her career as a first grade teacher. “But doing it this way helps it feel sustainable. We’re still underpaid and not appreciated enough as a whole profession, but at least virtually some of the big glaring issues aren’t there in terms of how we’re treated.”
Entsminger was initially drawn to teaching in part because she hoped it would allow her to have more time with her future children than other careers might offer. But as she became a mother while teaching for a decade in a brick-and-mortar environment — both at the elementary school and the high school level — she found she was unable to pick up or drop her daughter off at school, despite working in the same district her daughter attended.
In contrast, while teaching online,“in this environment I’m able to take her to school, make her breakfast,” she says. “I’m able to do life and my job. On the daily, I’m able to be ‘Mom’ and ‘Ms. Entsminger’ with less fighting for my time.”
Because of the more-flexible schedule for students enrolled in virtual learning programs, teachers do not have to be “on” for eight straight hours. And they do not necessarily have to participate in the sorts of shared systems that keep physical schools running. In a brick-and-mortar school, even if Bacon, Hamill or Entsminger were not slated to teach a class, they might be assigned to spend their time walking their students to their next class or the bus stop, or tasked with supervising the cafeteria during a lunch period. But in the virtual environment, they have the ability to close their laptop, and to quietly plan lessons or grade papers.
However, that is not to say these teachers operate as islands. Hamill says one of the largest perks of teaching virtual school is working with other fifth grade teachers across the nation, who often share PowerPoints or other lesson plans, whereas, she says, “I think sometimes in person, people can be a little precious about that.”
The workload varies for teachers in virtual programs. Entsminger’s 300-plus students are enrolled in three grades. Some live as close as her same city, others as far-flung as Europe, where they play soccer. Hamill currently has 28 students, expecting to get to 30 as the school continuously admits more. According to the National Policy Education Center, the average student-teacher ratio in the nation’s public schools was 14.8 students per teacher in 2023, with virtual schools reporting having 24.4 students per teacher.
Hamill also believes that virtual environments keep both teachers and students safer. She says she was sick for nine months of the year her first year teaching, getting strep throat twice. She also points to the seemingly endless onslaught of school shootings and the worsening of behavior issues among children.
“The trade-off for not having to do classroom management of behavioral issues is huge,” she says. “If the kid is mean in the chat, I turn off the chat. If kids aren’t listening, I can mute everyone and say, ‘I’ll let you talk one at a time.’ Versus, in my last classroom, the kids threw chairs at me.”
There are still adjustments to managing kids remotely, the teachers acknowledge. Hamill coaches her kids through internet safety and online decorum, like learning that typing in all-caps, for example, can come across rudely.
And while the virtual teachers were initially concerned about bonding with their students, they have found those worries largely unfounded. During online office hours, Hamill plays Pictionary with her students and has met most of their pets over a screen. Meanwhile, Entsminger offers online tutoring and daily opportunities to meet, where she has “learned more than I ever thought about K-pop this year.”
There are also opportunities for in-person gatherings with students. Hamill does once-a-month meetups, often in a park. Bacon attended an in-person picnic earlier this month to meet the students who live near her. And both K12 and Connections Academy hold multiple in-person events for students, including field trips and extracurriculars, like sewing or bowling clubs.
“Of course I wish I could see them more in person, and do arts and crafts time — that’s a big thing I miss,” Hamill says. “But we have drawing programs or ways they can post their artwork; we find ways to adapt to it.”
And that adaptation is largely worth it to virtual teachers.
“Teaching is teaching; even if I’m behind a computer screen, kids are still going to be kids,” Entsminger says. “The hurdles are still there. We’re still working hard, but it’s really nice to work with my students, and then walk to my kitchen to get coffee, then come back to connect to my students again.”
Books, Courses & Certifications
Schedule topology-aware workloads using Amazon SageMaker HyperPod task governance

Today, we are excited to announce a new capability of Amazon SageMaker HyperPod task governance to help you optimize training efficiency and network latency of your AI workloads. SageMaker HyperPod task governance streamlines resource allocation and facilitates efficient compute resource utilization across teams and projects on Amazon Elastic Kubernetes Service (Amazon EKS) clusters. Administrators can govern accelerated compute allocation and enforce task priority policies, improving resource utilization. This helps organizations focus on accelerating generative AI innovation and reducing time to market, rather than coordinating resource allocation and replanning tasks. Refer to Best practices for Amazon SageMaker HyperPod task governance for more information.
Generative AI workloads typically demand extensive network communication across Amazon Elastic Compute Cloud (Amazon EC2) instances, where network bandwidth impacts both workload runtime and processing latency. The network latency of these communications depends on the physical placement of instances within a data center’s hierarchical infrastructure. Data centers can be organized into nested organizational units such as network nodes and node sets, with multiple instances per network node and multiple network nodes per node set. For example, instances within the same organizational unit experience faster processing time compared to those across different units. This means fewer network hops between instances results in lower communication.
To optimize the placement of your generative AI workloads in your SageMaker HyperPod clusters by considering the physical and logical arrangement of resources, you can use EC2 network topology information during your job submissions. An EC2 instance’s topology is described by a set of nodes, with one node in each layer of the network. Refer to How Amazon EC2 instance topology works for details on how EC2 topology is arranged. Network topology labels offer the following key benefits:
- Reduced latency by minimizing network hops and routing traffic to nearby instances
- Improved training efficiency by optimizing workload placement across network resources
With topology-aware scheduling for SageMaker HyperPod task governance, you can use topology network labels to schedule your jobs with optimized network communication, thereby improving task efficiency and resource utilization for your AI workloads.
In this post, we introduce topology-aware scheduling with SageMaker HyperPod task governance by submitting jobs that represent hierarchical network information. We provide details about how to use SageMaker HyperPod task governance to optimize your job efficiency.
Solution overview
Data scientists interact with SageMaker HyperPod clusters. Data scientists are responsible for the training, fine-tuning, and deployment of models on accelerated compute instances. It’s important to make sure data scientists have the necessary capacity and permissions when interacting with clusters of GPUs.
To implement topology-aware scheduling, you first confirm the topology information for all nodes in your cluster, then run a script that tells you which instances are on the same network nodes, and finally schedule a topology-aware training task on your cluster. This workflow facilitates higher visibility and control over the placement of your training instances.
In this post, we walk through viewing node topology information and submitting topology-aware tasks to your cluster. For reference, NetworkNodes describes the network node set of an instance. In each network node set, three layers comprise the hierarchical view of the topology for each instance. Instances that are closest to each other will share the same layer 3 network node. If there are no common network nodes in the bottom layer (layer 3), then see if there is commonality at layer 2.
Prerequisites
To get started with topology-aware scheduling, you must have the following prerequisites:
- An EKS cluster
- A SageMaker HyperPod cluster with instances enabled for topology information
- The SageMaker HyperPod task governance add-on installed (version 1.2.2 or later)
- Kubectl installed
- (Optional) The SageMaker HyperPod CLI installed
Get node topology information
Run the following command to show node labels in your cluster. This command provides network topology information for each instance.
Instances with the same network node layer 3 are as close as possible, following EC2 topology hierarchy. You should see a list of node labels that look like the following:topology.k8s.aws/network-node-layer-3: nn-33333exampleRun the following script to show the nodes in your cluster that are on the same layers 1, 2, and 3 network nodes:
The output of this script will print a flow chart that you can use in a flow diagram editor such as Mermaid.js.org to visualize the node topology of your cluster. The following figure is an example of the cluster topology for a seven-instance cluster.
Submit tasks
SageMaker HyperPod task governance offers two ways to submit tasks using topology awareness. In this section, we discuss these two options and a third alternative option to task governance.
Modify your Kubernetes manifest file
First, you can modify your existing Kubernetes manifest file to include one of two annotation options:
- kueue.x-k8s.io/podset-required-topology – Use this option if you must have all pods scheduled on nodes on the same network node layer in order to begin the job
- kueue.x-k8s.io/podset-preferred-topology – Use this option if you ideally want all pods scheduled on nodes in the same network node layer, but you have flexibility
The following code is an example of a sample job that uses the kueue.x-k8s.io/podset-required-topology setting to schedule pods that share the same layer 3 network node:
To verify which nodes your pods are running on, use the following command to view node IDs per pod:kubectl get pods -n hyperpod-ns-team-a -o wide
Use the SageMaker HyperPod CLI
The second way to submit a job is through the SageMaker HyperPod CLI. Be sure to install the latest version (version pending) to use topology-aware scheduling. To use topology-aware scheduling with the SageMaker HyperPod CLI, you can include either the --preferred-topology parameter or the --required-topology parameter in your create job command.
The following code is an example command to start a topology-aware mnist training job using the SageMaker HyperPod CLI, replace XXXXXXXXXXXX with your AWS account ID:
Clean up
If you deployed new resources while following this post, refer to the Clean Up section in the SageMaker HyperPod EKS workshop to make sure you don’t accrue unwanted charges.
Conclusion
During large language model (LLM) training, pod-to-pod communication distributes the model across multiple instances, requiring frequent data exchange between these instances. In this post, we discussed how SageMaker HyperPod task governance helps schedule workloads to enable job efficiency by optimizing throughput and latency. We also walked through how to schedule jobs using SageMaker HyperPod topology network information to optimize network communication latency for your AI tasks.
We encourage you to try out this solution and share your feedback in the comments section.
About the authors
 Nisha Nadkarni is a Senior GenAI Specialist Solutions Architect at AWS, where she guides companies through best practices when deploying large scale distributed training and inference on AWS. Prior to her current role, she spent several years at AWS focused on helping emerging GenAI startups develop models from ideation to production.
Nisha Nadkarni is a Senior GenAI Specialist Solutions Architect at AWS, where she guides companies through best practices when deploying large scale distributed training and inference on AWS. Prior to her current role, she spent several years at AWS focused on helping emerging GenAI startups develop models from ideation to production.
 Siamak Nariman is a Senior Product Manager at AWS. He is focused on AI/ML technology, ML model management, and ML governance to improve overall organizational efficiency and productivity. He has extensive experience automating processes and deploying various technologies.
Siamak Nariman is a Senior Product Manager at AWS. He is focused on AI/ML technology, ML model management, and ML governance to improve overall organizational efficiency and productivity. He has extensive experience automating processes and deploying various technologies.
 Zican Li is a Senior Software Engineer at Amazon Web Services (AWS), where he leads software development for Task Governance on SageMaker HyperPod. In his role, he focuses on empowering customers with advanced AI capabilities while fostering an environment that maximizes engineering team efficiency and productivity.
Zican Li is a Senior Software Engineer at Amazon Web Services (AWS), where he leads software development for Task Governance on SageMaker HyperPod. In his role, he focuses on empowering customers with advanced AI capabilities while fostering an environment that maximizes engineering team efficiency and productivity.
 Anoop Saha is a Sr GTM Specialist at Amazon Web Services (AWS) focusing on generative AI model training and inference. He partners with top frontier model builders, strategic customers, and AWS service teams to enable distributed training and inference at scale on AWS and lead joint GTM motions. Before AWS, Anoop held several leadership roles at startups and large corporations, primarily focusing on silicon and system architecture of AI infrastructure.
Anoop Saha is a Sr GTM Specialist at Amazon Web Services (AWS) focusing on generative AI model training and inference. He partners with top frontier model builders, strategic customers, and AWS service teams to enable distributed training and inference at scale on AWS and lead joint GTM motions. Before AWS, Anoop held several leadership roles at startups and large corporations, primarily focusing on silicon and system architecture of AI infrastructure.
Books, Courses & Certifications
How msg enhanced HR workforce transformation with Amazon Bedrock and msg.ProfileMap

This post is co-written with Stefan Walter from msg.
With more than 10,000 experts in 34 countries, msg is both an independent software vendor and a system integrator operating in highly regulated industries, with over 40 years of domain-specific expertise. msg.ProfileMap is a software as a service (SaaS) solution for skill and competency management. It’s an AWS Partner qualified software available on AWS Marketplace, currently serving more than 7,500 users. HR and strategy departments use msg.ProfileMap for project staffing and workforce transformation initiatives. By offering a centralized view of skills and competencies, msg.ProfileMap helps organizations map their workforce’s capabilities, identify skill gaps, and implement targeted development strategies. This supports more effective project execution, better alignment of talent to roles, and long-term workforce planning.
In this post, we share how msg automated data harmonization for msg.ProfileMap, using Amazon Bedrock to power its large language model (LLM)-driven data enrichment workflows, resulting in higher accuracy in HR concept matching, reduced manual workload, and improved alignment with compliance requirements under the EU AI Act and GDPR.
The importance of AI-based data harmonization
HR departments face increasing pressure to operate as data-driven organizations, but are often constrained by the inconsistent, fragmented nature of their data. Critical HR documents are unstructured, and legacy systems use mismatched formats and data models. This not only impairs data quality but also leads to inefficiencies and decision-making blind spots.Accurate and harmonized HR data is foundational for key activities such as matching candidates to roles, identifying internal mobility opportunities, conducting skills gap analysis, and planning workforce development. msg identified that without automated, scalable methods to process and unify this data, organizations would continue to struggle with manual overhead and inconsistent results.
Solution overview
HR data is typically scattered across diverse sources and formats, ranging from relational databases to Excel files, Word documents, and PDFs. Additionally, entities such as personnel numbers or competencies have different unique identifiers as well as different text descriptions, although with the same semantics. msg addressed this challenge with a modular architecture, tailored for IT workforce scenarios. As illustrated in the following diagram, at the core of msg.ProfileMap is a robust text extraction layer, which transforms heterogeneous inputs into structured data. This is then passed to an AI-powered harmonization engine that provides consistency across data sources by avoiding duplication and aligning disparate concepts.
The harmonization process uses a hybrid retrieval approach that combines vector-based semantic similarity and string-based matching techniques. These methods align incoming data with existing entities in the system. Amazon Bedrock is used to semantically enrich data, improving cross-source compatibility and matching precision. Extracted and enriched data is indexed and stored using Amazon OpenSearch Service and Amazon DynamoDB, facilitating fast and accurate retrieval, as shown in the following diagram.

The framework is designed to be unsupervised and domain independent. Although it’s optimized for IT workforce use cases, it has demonstrated strong generalization capabilities in other domains as well.
msg.ProfileMap is a cloud-based application that uses several AWS services, notably Amazon Neptune, Amazon DynamoDB, and Amazon Bedrock. The following diagram illustrates the full solution architecture.

Results and technical validation
msg evaluated the effectiveness of the data harmonization framework through internal testing on IT workforce concepts and external benchmarking in the Bio-ML Track of the Ontology Alignment Evaluation Initiative (OAEI), an international and EU-funded research initiative that evaluates ontology matching technologies since 2004.
During internal testing, the system processed 2,248 concepts across multiple suggestion types. High-probability merge recommendations reached 95.5% accuracy, covering nearly 60% of all inputs. This helped msg reduce manual validation workload by over 70%, significantly improving time-to-value for HR teams.
During OAEI 2024, msg.ProfileMap ranked at the top of the 2024 Bio-ML benchmark, outperforming other systems across multiple biomedical datasets. On NCIT-DOID, it achieved a 0.918 F1 score, with Hits@1 exceeding 92%, validating the engine’s generalizability beyond the HR domain. Additional details are available in the official test results.
Why Amazon Bedrock
msg relies on LLMs to semantically enrich data in near real time. These workloads require low-latency inference, flexible scaling, and operational simplicity. Amazon Bedrock met these needs by providing a fully managed, serverless interface to leading foundation models—without the need to manage infrastructure or deploy custom machine learning stacks.
Unlike hosting models on Amazon Elastic Compute Cloud (Amazon EC2) or Amazon SageMaker, Amazon Bedrock abstracts away provisioning, versioning, scaling, and model selection. Its consumption-based pricing aligns directly with msg’s SaaS delivery model—resources are used (and billed) only when needed. This simplified integration reduced overhead and helped msg scale elastically as customer demand grew.
Amazon Bedrock also helped msg meet compliance goals under the EU AI Act and GDPR by enabling tightly scoped, auditable interactions with model APIs—critical for HR use cases that handle sensitive workforce data.
Conclusion
msg’s successful integration of Amazon Bedrock into msg.ProfileMap demonstrates that large-scale AI adoption doesn’t require complex infrastructure or specialized model training. By combining modular design, ontology-based harmonization, and the fully managed LLM capabilities of Amazon Bedrock, msg delivered an AI-powered workforce intelligence platform that is accurate, scalable, and compliant.This solution improved concept match precision and achieved top marks in international AI benchmarks, demonstrating what’s possible when generative AI is paired with the right cloud-based service. With Amazon Bedrock, msg has built a platform that’s ready for today’s HR challenges—and tomorrow’s.
msg.ProfileMap is available as a SaaS offering on AWS Marketplace. If you are interested in knowing more, you can reach out to msg.hcm.backoffice@msg.group.
The content and opinions in this blog post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
About the authors
 Stefan Walter is Senior Vice President of AI SaaS Solutions at msg. With over 25 years of experience in IT software development, architecture, and consulting, Stefan Walter leads with a vision for scalable SaaS innovation and operational excellence. As a BU lead at msg, Stefan has spearheaded transformative initiatives that bridge business strategy with technology execution, especially in complex, multi-entity environments.
Stefan Walter is Senior Vice President of AI SaaS Solutions at msg. With over 25 years of experience in IT software development, architecture, and consulting, Stefan Walter leads with a vision for scalable SaaS innovation and operational excellence. As a BU lead at msg, Stefan has spearheaded transformative initiatives that bridge business strategy with technology execution, especially in complex, multi-entity environments.
 Gianluca Vegetti is a Senior Enterprise Architect in the AWS Partner Organization, aligned to Strategic Partnership Collaboration and Governance (SPCG) engagements. In his role, he supports the definition and execution of Strategic Collaboration Agreements with selected AWS partners.
Gianluca Vegetti is a Senior Enterprise Architect in the AWS Partner Organization, aligned to Strategic Partnership Collaboration and Governance (SPCG) engagements. In his role, he supports the definition and execution of Strategic Collaboration Agreements with selected AWS partners.
 Yuriy Bezsonov is a Senior Partner Solution Architect at AWS. With over 25 years in the tech, Yuriy has progressed from a software developer to an engineering manager and Solutions Architect. Now, as a Senior Solutions Architect at AWS, he assists partners and customers in developing cloud solutions, focusing on container technologies, Kubernetes, Java, application modernization, SaaS, developer experience, and GenAI. Yuriy holds AWS and Kubernetes certifications, and he is a recipient of the AWS Golden Jacket and the CNCF Kubestronaut Blue Jacket.
Yuriy Bezsonov is a Senior Partner Solution Architect at AWS. With over 25 years in the tech, Yuriy has progressed from a software developer to an engineering manager and Solutions Architect. Now, as a Senior Solutions Architect at AWS, he assists partners and customers in developing cloud solutions, focusing on container technologies, Kubernetes, Java, application modernization, SaaS, developer experience, and GenAI. Yuriy holds AWS and Kubernetes certifications, and he is a recipient of the AWS Golden Jacket and the CNCF Kubestronaut Blue Jacket.
-

 Business3 weeks ago
Business3 weeks agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-
Tools & Platforms1 month ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Ethics & Policy2 months ago
Ethics & Policy2 months agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences4 months ago
Events & Conferences4 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers3 months ago
Jobs & Careers3 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Education3 months ago
Education3 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Education2 months ago
Education2 months agoMacron says UK and France have duty to tackle illegal migration ‘with humanity, solidarity and firmness’ – UK politics live | Politics
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi
-

 Funding & Business3 months ago
Funding & Business3 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries