



















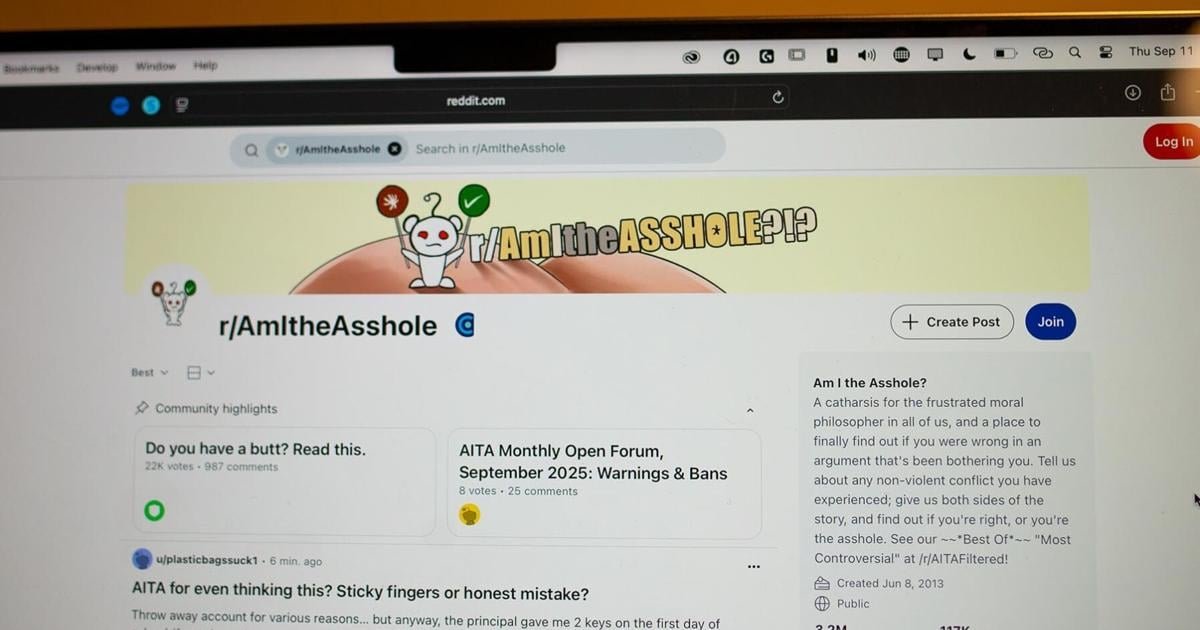
A study published by UC Berkeley researchers used the Reddit forum, r/AmITheAsshole, to determine whether artificial intelligence, or AI, chatbots had “patterns in their moral reasoning.”
The study, led by researchers Pratik Sachdeva and Tom van Nuenen at campus’s D-Lab, asked seven AI large language models, or LLMs, to judge more than 10,000 social dilemmas from r/AmITheAsshole.
The LLMs used were Claude Haiku, Mistral 7B, Google’s PaLM 2 Bison and Gemma 7B, Meta’s LLaMa 2 7B and OpenAI’s GPT-3.5 and GPT-4. The study found that different LLMs showed unique moral judgement patterns, often giving dramatically different verdicts from other LLMs. These results were self-consistent, meaning that when presented with the same issue, the model seemed to judge it with the same set of morals and values.
Sachdeva and van Nuenen began the study in January 2023, shortly after ChatGPT came out. According to van Nuenen, as people increasingly turned to AI for personal advice, they were motivated to study the values shaping the responses they received.
r/AmITheAsshole is a Reddit forum where people can ask fellow users if they were the “asshole” in a social dilemma. The forum was chosen by the researchers due to its unique verdict system, as subreddit users assign their judgement of “Not The Asshole,” “You’re the Asshole,” “No Assholes Here,” “Everyone Sucks Here” or “Need More Info.” The judgement with the most upvotes, or likes, is accepted as the consensus, according to the study.
“What (other) studies will do is prompt models with political or moral surveys, or constrained moral scenarios like a trolley problem,” Sechdava said. “But we were more interested in personal dilemmas that users will also come to these language models for like, mental health chats or things like that, or problems in someone’s direct environment.”
According to the study, the LLM models were presented with the post and asked to issue a judgement and explanation. Researchers compared their responses to the Reddit consensus and then judged the AI’s explanations along a six-category moral framework of fairness, feelings, harms, honesty, relational obligation and social norms.
The researchers found that out of the LLMs, GPT-4’s judgments agreed with the Reddit consensus the most, even if agreement was generally pretty low. According to the study, GPT-3.5 assigned people “You’re the Asshole” at a comparatively higher rate than GPT-4.
“Some models are more fairness forward. Others are a bit harsher. And the interesting thing we found is if you put them together, if you look at the distribution of all the evaluations of these different models, you start approximating human consensus as well,” van Nuenen said.
The researchers found that even though the verdicts of the LLM models generally disagreed with each other, the consensus of the seven models typically aligned with the Redditor’s consensus.
One model, Mistral 7B, assigned almost no posts “You’re the Asshole” verdicts, as it used the word “asshole” to mean its literal definition, and not the socially accepted definition in the forum, which refers to whoever is at fault.
When asked if he believed the chatbots had moral compasses, van Nuenen instead described them as having “moral flavors.”
“There doesn’t seem to be some kind of unified, directional sense of right and wrong (among the chatbots). And there’s diversity like that,” van Nuenen said.
Sachdeva and van Nuenen have begun two follow-up studies. One examines how the models’ stances adjust when deliberating their responses with other chatbots, while the other looks at how consistent the models’ judgments are as the dilemmas are modified.
















