Jobs & Careers
5 Routine Tasks That ChatGPT Can Handle for Data Scientists


Image by Author | Canva
According to the data science report by Anaconda, data scientists spend nearly 60% of their time on cleaning and organizing data. These are routine, time-consuming tasks that make them ideal candidates for ChatGPT to take over.
In this article, we will explore five routine tasks that ChatGPT can handle if you use the right prompts, including cleaning and organizing the data. We’ll use a real data project from Gett, a London black taxi app similar to Uber, used in their recruitment process, to show how it works in practice.
Case Study: Analyzing Failed Ride Orders from Gett
In this data project, Gett asks you to analyze failed rider orders by examining key matching metrics to understand why some customers did not successfully get a car.
Here is the data description.

Now, let’s explore it by uploading the data to ChatGPT.
In the next five steps, we will walk through the routine tasks that ChatGPT can handle in a data project. The steps are shown below.

Step 1: Data Exploration and Analysis
In data exploration, we use the same functions every time, like head, info, or describe.
When we ask ChatGPT, we’ll include the key functions in the prompt. We’ll also paste the project description and attach the dataset.

We will use the prompt below. Just replace the text inside the square brackets with the project description. You can find the project description here:
Here is the data project description: [paste here ]
Perform basic EDA, show head, info, and summary stats, missing values, and correlation heatmap.
Here is the output.

As you can see, ChatGPT summarizes the dataset by highlighting key columns, missing values, and then creates a correlation heatmap to explore relationships.
Step 2: Data Cleaning
Both datasets contain missing values.

Let’s write a prompt to work on this.
Clean this dataset: identify and handle missing values appropriately (e.g., drop or impute based on context). Provide a summary of the cleaning steps.
Here is the summary of what ChatGPT did:

ChatGPT converted the date column, dropped invalid orders, and imputed missing values to the m_order_eta.
Step 3: Generate Visualizations
To make the most of your data, it is important to visualize the right things. Instead of generating random plots, we can guide ChatGPT by providing the link to the source, which is called Retrieval-Augmented Generation.
We will use this article. Here is the prompt:
Before generating visualizations, read this article on choosing the right plots for different data types and distributions: [LINK]. hen, show most suitable visualizations for this dataset and explain why each was selected and produce the plots in this chat by running code on the dataset.
Here is the output.
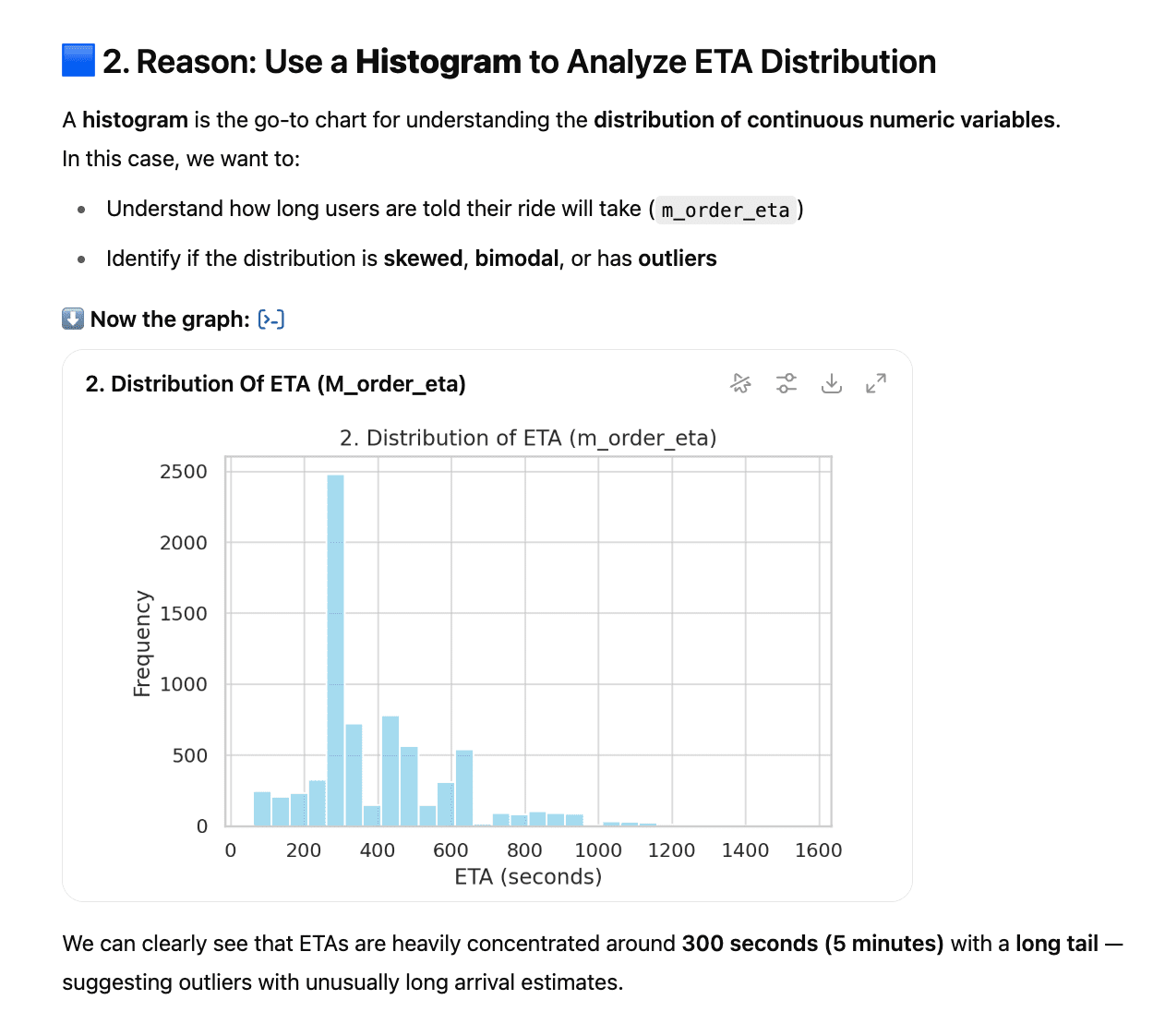
We have six different graphs that we produced with ChatGPT.

You will see why the related graph has been selected, the graph, and the explanation of this graph.
Step 4: Make your Dataset Ready for Machine Learning
Now that we have handled missing values and explored the dataset, the next step is to prepare it for machine learning. This involves steps like encoding categorical variables and scaling numerical features.
Here is our prompt.
Prepare this dataset for machine learning: encode categorical variables, scale numerical features, and return a clean DataFrame ready for modeling. Briefly explain each step.
Here is the output.

Now your features have been scaled and encoded, so your dataset is ready to apply a machine learning model.
Step 5: Applying Machine Learning Model
Let’s move on to machine learning modeling. We will use the following prompt structure to apply a basic machine learning model.
Use this dataset to predict [target variable]. Apply [model type] and report machine learning evaluation metrics like [accuracy, precision, recall, F1-score]. Use only relevant 5 features and explain your modeling steps.
Let’s update this prompt based on our project.
Use this dataset to predict order_status_key. Apply a multiclass classification model (e.g., Random Forest), and report evaluation metrics like accuracy, precision, recall, and F1-score. Use only the 5 most relevant features and explain your modeling steps.
Now, paste this into the ongoing conversation and review the output.
Here is the output.

As you can see, the model performed well, perhaps too well?
Bonus: Gemini CLI
Gemini has launched an open-source agent that you can interact with from your terminal. You can install it by using this code. (60 model requests per minute and 1,000 requests per day at no charge.)
Besides ChatGPT, you can also use Gemini CLI to handle routine data science tasks, such as cleaning, exploration, and even building a dashboard to automate these tasks.
The Gemini CLI provides a straightforward command-line interface and is available at no cost. Let’s start by installing it using the code below.
sudo npm install -g @google/gemini-cli
After running the code above, open your terminal and paste the following code to start building with it:
Once you run the commands above, you’ll see the Gemini CLI as shown in the screenshot below.

Gemini CLI lets you run code, ask questions, or even build apps directly from your terminal. In this case, we will use Gemini CLI to build a Streamlit app that automates everything we’ve done so far, EDA, cleaning, visualization, and modeling.
To build a Streamlit app, we will use a prompt that covers all steps. It’s shown below.
Built a streamlit app that automates EDA, Data Cleaning, Creates Automatic data visualization, prepares the dataset for machine learning, and applies a machine learning model after selecting target variables by the user.
Step 1 – Basic EDA:
• Display .head(), .info(), and .describe()
• Show missing values per column
• Show correlation heatmap of numerical features
Step 2 – Data Cleaning:
• Detect columns with missing values
• Handle missing data appropriately (drop or impute)
• Display a summary of cleaning actions taken
Step 3 – Auto Visualizations
• Before plotting, use these visualization principles:
• Use histograms for numerical distributions
• Use bar plots for categorical distributions
• Use boxplots or violin plots to compare categories
• Use scatter plots for numerical relationships
• Use correlation heatmaps for multicollinearity
• Use line plots for time series (if applicable)
• Generate the most relevant plots for this dataset
• Explain why each plot was chosen
Step 4 – Machine Learning Preparation:
• Encode variables
• Scale numerical features
• Return a clean DataFrame ready for modeling
Step 5 – Apply Machine Learning Model:
• Offer the target variable to the user.
• Apply multiple machine learning models.
• Report evaluation metrics.
Each step should display in a different tab. Run the Streamlit app after you built it.
It will prompt you for permission when creating the directory or running code on your terminal.

After a few approval steps like we did, the Streamlit app will be ready, as shown below.

Now, let’s test it.

Final Thoughts
In this article, we first used ChatGPT to handle routine tasks, such as data cleaning, exploration, and data visualization. Next, we went one step further by using it to prepare our dataset for machine learning and applied machine learning models.
Finally, we used Gemini CLI to create a Streamlit dashboard that performs all of these steps with just a click.
To demonstrate all of this, we have used a data project from Gett. Although AI is not yet entirely reliable for every task, you can leverage it to handle routine tasks, saving you a lot of time.
Nate Rosidi is a data scientist and in product strategy. He’s also an adjunct professor teaching analytics, and is the founder of StrataScratch, a platform helping data scientists prepare for their interviews with real interview questions from top companies. Nate writes on the latest trends in the career market, gives interview advice, shares data science projects, and covers everything SQL.

NVIDIA disclosed on August 28, 2025, that two unnamed customers contributed 39% of its revenue in the July quarter, raising questions about the chipmaker’s dependence on a small group of clients.
The company posted record quarterly revenue of $46.7 billion, up 56% from a year ago, driven by insatiable demand for its data centre products.
In a filing with the U.S. Securities and Exchange Commission (SEC), NVIDIA said “Customer A” accounted for 23% of total revenue and “Customer B” for 16%. A year earlier, its top two customers made up 14% and 11% of revenue.
The concentration highlights the role of large buyers, many of whom are cloud service providers. “Large cloud service providers made up about 50% of the company’s data center revenue,” NVIDIA chief financial officer Colette Kress said on Wednesday. Data center sales represented 88% of NVIDIA’s overall revenue in the second quarter.
“We have experienced periods where we receive a significant amount of our revenue from a limited number of customers, and this trend may continue,” the company wrote in the filing.
One of the customers could possibly be Saudi Arabia’s AI firm Humain, which is building two data centers in Riyadh and Dammam, slated to open in early 2026. The company has secured approval to import 18,000 NVIDIA AI chips.
The second customer could be OpenAI or one of the major cloud providers — Microsoft, AWS, Google Cloud, or Oracle. Another possibility is xAI.
Previously, Elon Musk said xAI has 230,000 GPUs, including 30,000 GB200s, operational for training its Grok model in a supercluster called Colossus 1. Inference is handled by external cloud providers.
Musk added that Colossus 2, which will host an additional 550,000 GB200 and GB300 GPUs, will begin going online in the coming weeks. “As Jensen Huang has stated, xAI is unmatched in speed. It’s not even close,” Musk wrote in a post on X.Meanwhile, OpenAI is preparing for a major expansion. Chief Financial Officer Sarah Friar said the company plans to invest in trillion-dollar-scale data centers to meet surging demand for AI computation.
The post NVIDIA Reveals Two Customers Accounted for 39% of Quarterly Revenue appeared first on Analytics India Magazine.

Reliance Industries chairman Mukesh Ambani has announced the launch of Reliance Intelligence, a new wholly owned subsidiary focused on artificial intelligence, marking what he described as the company’s “next transformation into a deep-tech enterprise.”
Addressing shareholders, Ambani said Reliance Intelligence had been conceived with four core missions—building gigawatt-scale AI-ready data centres powered by green energy, forging global partnerships to strengthen India’s AI ecosystem, delivering AI services for consumers and SMEs in critical sectors such as education, healthcare, and agriculture, and creating a home for world-class AI talent.
Work has already begun on gigawatt-scale AI data centres in Jamnagar, Ambani said, adding that they would be rolled out in phases in line with India’s growing needs.
These facilities, powered by Reliance’s new energy ecosystem, will be purpose-built for AI training and inference at a national scale.
Ambani also announced a “deeper, holistic partnership” with Google, aimed at accelerating AI adoption across Reliance businesses.
“We are marrying Reliance’s proven capability to build world-class assets and execute at India scale with Google’s leading cloud and AI technologies,” Ambani said.
Google CEO Sundar Pichai, in a recorded message, said the two companies would set up a new cloud region in Jamnagar dedicated to Reliance.
“It will bring world-class AI and compute from Google Cloud, powered by clean energy from Reliance and connected by Jio’s advanced network,” Pichai said.
He added that Google Cloud would remain Reliance’s largest public cloud partner, supporting mission-critical workloads and co-developing advanced AI initiatives.
Ambani further unveiled a new AI-focused joint venture with Meta.
He said the venture would combine Reliance’s domain expertise across industries with Meta’s open-source AI models and tools to deliver “sovereign, enterprise-ready AI for India.”
Meta founder and CEO Mark Zuckerberg, in his remarks, said the partnership is aimed to bring open-source AI to Indian businesses at scale.
“With Reliance’s reach and scale, we can bring this to every corner of India. This venture will become a model for how AI, and one day superintelligence, can be delivered,” Zuckerberg said.
Ambani also highlighted Reliance’s investments in AI-powered robotics, particularly humanoid robotics, which he said could transform manufacturing, supply chains and healthcare.
“Intelligent automation will create new industries, new jobs and new opportunities for India’s youth,” he told shareholders.
Calling AI an opportunity “as large, if not larger” than Reliance’s digital services push a decade ago, Ambani said Reliance Intelligence would work to deliver “AI everywhere and for every Indian.”
“We are building for the next decade with confidence and ambition,” he said, underscoring that the company’s partnerships, green infrastructure and India-first governance approach would be central to this strategy.
The post ‘Reliance Intelligence’ is Here, In Partnership with Google and Meta appeared first on Analytics India Magazine.

Cognizant has announced that it would deploy 1,000 context engineers over the next year to industrialise agentic AI across enterprises.
According to an official release, the company claimed that the move marks a “pivotal investment” in the emerging discipline of context engineering.
As part of this initiative, Cognizant said it is partnering with Workfabric AI, the company building the context engine for enterprise AI.
Cognizant’s context engineers will be powered by Workfabric AI’s ContextFabric platform, the statement said, adding that the platform transforms the organisational DNA of enterprises, how their teams work, including their workflows, data, rules, and processes, into actionable context for AI agents.Context engineering is essential to enabling AI a
-
Tools & Platforms3 weeks ago
Building Trust in Military AI Starts with Opening the Black Box – War on the Rocks
-

 Business2 days ago
Business2 days agoThe Guardian view on Trump and the Fed: independence is no substitute for accountability | Editorial
-

 Ethics & Policy1 month ago
Ethics & Policy1 month agoSDAIA Supports Saudi Arabia’s Leadership in Shaping Global AI Ethics, Policy, and Research – وكالة الأنباء السعودية
-

 Events & Conferences3 months ago
Events & Conferences3 months agoJourney to 1000 models: Scaling Instagram’s recommendation system
-

 Jobs & Careers2 months ago
Jobs & Careers2 months agoMumbai-based Perplexity Alternative Has 60k+ Users Without Funding
-

 Funding & Business2 months ago
Funding & Business2 months agoKayak and Expedia race to build AI travel agents that turn social posts into itineraries
-

 Education2 months ago
Education2 months agoVEX Robotics launches AI-powered classroom robotics system
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoHappy 4th of July! 🎆 Made with Veo 3 in Gemini
-

 Podcasts & Talks2 months ago
Podcasts & Talks2 months agoOpenAI 🤝 @teamganassi
-

 Mergers & Acquisitions2 months ago
Mergers & Acquisitions2 months agoDonald Trump suggests US government review subsidies to Elon Musk’s companies